改进YOLOv5s的磁瓦表面缺陷检测算法
2024-01-15邹易航朱顺痣黄智财
邹易航,朱顺痣*,黄智财
(1. 厦门理工学院计算机与信息工程学院,福建 厦门 361024;2. 厦门华厦学院信息与智能机电学院,福建 厦门 361024)
磁瓦作为汽车发动机中电机的重要零件,其表面缺陷的检测在生产过程中非常关键。在当前的工业生产环境中,磁瓦表面缺陷的检测大多数仍然依靠人工检测,效率低下且漏检率高。
有关磁瓦表面缺陷检测,相关研究人员已进行了一系列研究,并取得了一定进展。张露滨等[1]提出一种微型磁瓦表面线缺陷检测方法,结合背景纹理抑制和掩膜技术技术,有效提高了检测精度,但不能完全排除噪声点对划痕图像提取的干扰。杨成立等[2]提出一种基于非下采样Shearlet变换的磁瓦表面缺陷检测方法,该方法能够有效去除不均匀背景、磨削纹理和噪声干扰,提升了检测的精确度和鲁棒性,但该方法仅仅适用于单个缺陷及缺陷背景简单的场景下。丁龙飞等[3]提出了一种融合多重注意力机制磁瓦缺陷检测算法,通过建立网络特征之间的空间相关性,增强了算法的精确度,但该算法仅适用于对缺陷进行分类,无法精准地标注出不同缺陷的位置。胡浩等[4]提出基于机器视觉的小磁瓦表面微缺陷检测方法研究,将磁瓦缺陷分为3 类,且针对相应类别设计了对应的缺陷提取方法,但该方法对裂纹、气孔的识别精度较低。
近年来,随着深度学习的不断发展,深度学习技术被逐渐运用到目标检测领域。目前,目标检测算法大致分为两类:以高精度著称的双阶段算法和兼顾检测速度与精度的单阶段检测算法。双阶段检测算法如Mask R-CNN[5]、Fast R-CNN[6]和Faster R-CNN[7],它们通过预先生成候选框来提升检测精度,但检测速度慢,计算复杂,难以满足实时检测要求。单阶段检测算法如SSD[8]、YOLO9000[9]、YOLOv3[10]、YOLOv4[11]、YOLOv5 等,在提升检测速率的同时兼顾了检测精度。为此,针对磁瓦图像高对比度和不同缺陷类别的差异较大、工业生产环境中磁瓦检测方式漏检率高、检测效率低下的问题,考虑到磁瓦检测环境及速率要求,本文以YOLOv5s 为基础,先在neck 端引入GSconv[12]代替标准卷积(standard convolution, SCONV)操作,使卷积计算的输出尽可能接近标准卷积,同时降低计算成本;然后,添加注意力机制,对网络进行改进,增加网络的特征提取能力;最后,替换原有损失函数,使模型收敛更快。
1 YOLOv5算法简述
YOLO 系列算法从v1发展至今,已经实现速度与精度的平衡。YOLOv5一共包括4个版本的模型,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这些模型通过控制网络的深度和宽度以适应不同场景下的检测要求。考虑到磁瓦检测环境及速率要求,本文选择YOLOv5s 作为基准模型,构建磁瓦表面缺陷检测算法。
YOLOv5s网络结构包括输入端、特征提取网络(backbone网络)、neck网络、head网络4个部分。
输入端会对输入的图片进行预处理。它以每4个为一组,通过随机缩放,再随机分布进行拼接的方式进行mosaic数据增强,可有效增加数据的多样性。而且,由于随机缩放增加了许多小目标,故网络的鲁棒性更好。
backbone 部分则用于图像特征提取,主要由CBS 结构、C3 结构、SPPF 结构组成。CBS 由卷积层(conv)、批量归一化层(batch normalization, BN)、激活函数(silu)组成。C3 结构由3 个标准卷积层及多个bottleneck 结构组合而成,相较于以往的CSP 模块仅仅在修正单元选择上的不同,C3 结构能够减少网络计算复杂度,并增强网络学习性能。SPPF 结构是将输入串行通过多个5×5 大小的maxpool层,相对于以往的SPP 通过并行输入多个不同大小的maxpool,SPPF 在保证相同精度的情况下,速率也得到了极大的提升。
neck 部分由FPN(feature pyramid networks)[13]和New CSP-PAN 组成。FPN 结构通过构造一系列不同尺度的图像或特征图进行模型训练和测试,能够有效提升检测算法对于不同尺寸检测目标的鲁棒性。New CSP-PAN结构则是在PAN(path aggregation networks)结构中引入CSP结构。
head 部分为最后检测结果的输出,由3 个大小为80×80、40×40、20×20 的检测头组成,分别对应小、中、大目标的检测。
2 改进的YOLOv5s算法
2.1 使用GSconv结构
GSconv 是一种混合卷积,由标准卷积(standard convolution,Sconv)和深度可分离卷积(depth-wise separable convolution,DWconv)[14]组成。标准卷积是不同的卷积核同时对3 个通道进行卷积,它在运行卷积过程时,1 个卷积核只能得到1 个特征。DWconv操作是首先用3个卷积对3个通道分别做卷积,在1 次卷积后,输出3 个数,然后输出的这3 个数,再通过1 个1×1×3 的卷积核,得到最后结果。DWconv 可以很好地减少参数和浮点运算(floating-point,FLOP)的数量。但是,DWconv 输入图像的通道信息在计算过程中会被分离,使磁瓦表面缺陷检测精度有所下降。而GSconv 则可以在保证检测速度达到DWconv水准的同时,使检测精度不会下降得太多。GSconv的结构具体如图1所示。
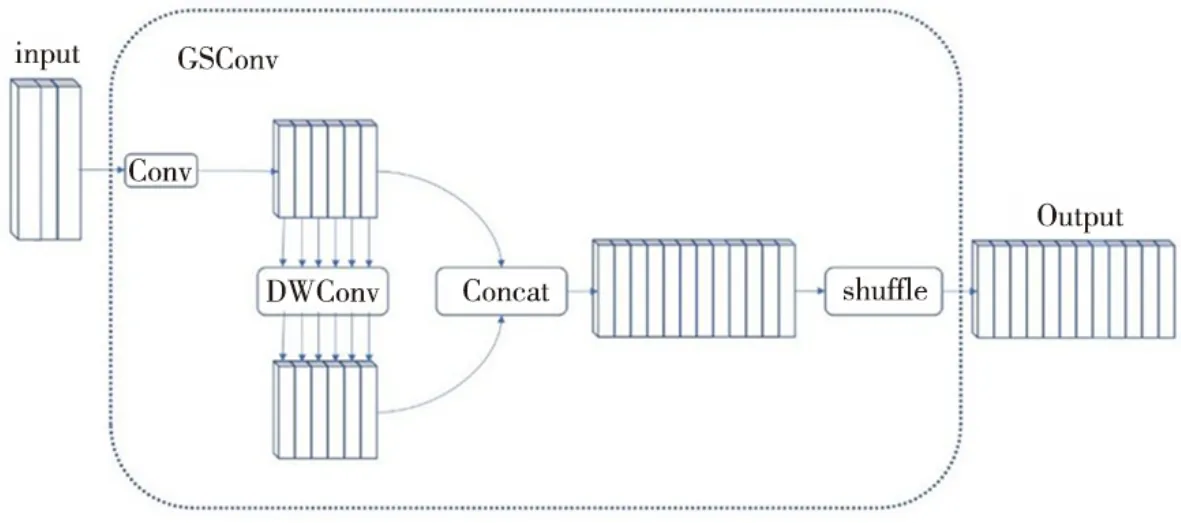
图 1 GSconv结构Fig.1 GSconv structure
本文在neck端引入GSconv结构。因为在neck端引入GSconv结构,可以最大程度地保留每个通道之间的隐藏链接,从而在保证模型准确率的情况下,降低计算成本。由于特征图在neck 端的通道维度最大,因此,GSconv 结构可以更好地处理这种情况,提高模型的效率和准确性。但是,如果在网络的所有部分都运用GSconv结构,则会使模型的网络更深,增加模型的推理时间。
2.2 添加CA注意力机制模块
注意力机制是一种源于人类视觉研究的资源分配方案,它可以在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题。通过添加注意力机制,模型可以更加高效地处理输入数据,从而提升计算能力和性能。CA 注意力机制[15]是一种新颖的轻量级通道注意力机制,能够同时考虑通道间的关系及长距离的位置信息,从而更好地捕捉特征之间的关系,提高模型的性能。CA 注意力机制结构如图2 所示。图2 中,C 代表卷积操作中提取出的特征图的通道数,H 和W 分别代表特征图的高度和宽度。
CA 为了获取图像宽度和高度上的注意力并对位置信息进行编码,会先将原始特征图xc在宽度和高度两个方面,使用尺寸为(H,1)和(1,W)池化核分别进行平均池化,从而得到在宽度w处第c个通道的输出和在高度h处第c个通道的输出。其计算公式为
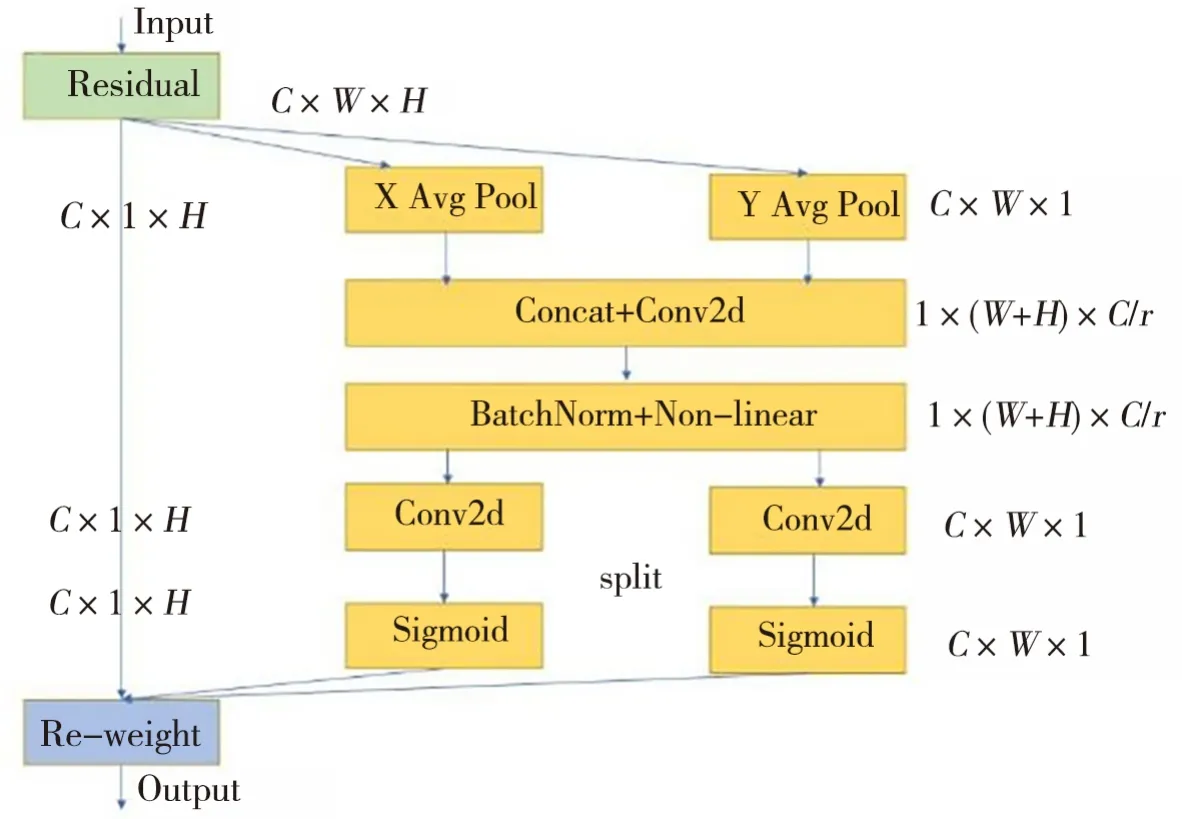
图 2 CA注意力机制结构Fig.2 CA structure
式(1)~(2)中:h、w、j、i都是代表索引变量。其中,h 和 w 分别表示高度的位置和宽度的位置,而j和i是进行求和操作的循环变量。
公式(1)中,j 作为循环变量,从0 到H-1,对每个位置进行平均池化操作。公式(2)中,i 作为循环变量,从0到W-1,对每个位置进行平均池化操作。
然后,将获得全局感受野宽度和高度两个方向的特征图拼接在一起,并将它们送入共享的卷积核为 1×1 的卷积模块,通过1个缩减因子r将其维度降低为原来的 C/r;再将经过批量归一化处理的特征图 F1送入Sigmoid激活函数δ,得到形如 1 ×(W + H) × C/r的特征图 ƒ。其计算公式为
接着,特征图ƒ再依照原来的宽高,对它用1×1的卷积核卷积,分别得到通道数与原来相同的特征图Fh和Fw,再经过Sigmoid 激活函数σ 之后,获得在高度和宽度方向上,与输入特征图xc具有相同通道数的张量g。其计算公式为
最终,在原始特征图xc上进行乘法加权计算,得到在宽度和高度方向上带有注意力权重的特征图yc。其计算公式为
本文通过选用CA 注意力机制,检测时不仅获取了通道间信息,还考虑了方向相关的位置信息,从而在磁瓦数据集上,使模型能更好地定位和识别缺陷目标。
2.3 改进损失函数
YOLOv5s中采用的边界框回归损失函数为CIoU,其计算公式为
式(7)中:b 和bgt表示预测框和真实框中心点坐标;ρ 表示求欧式距离;α 是权重函数,而v 用来度量长宽比的相似性。采用w、h和wgt、hgt分别表示预测框高宽和真实框高宽,则有
当真实框和预测框的长宽比越接近时,v 越小。v 不变时,IoU 越大,α 越大,损失越大,说明高IoU时,更加关注长宽比,低IoU时,更关注IoU。但是这种方式没有考虑到所需真实框与预测框之间不匹配的方向。这种不足会导致收敛速度较慢且效率较低,因为预测框可能在训练过程中到处移动,并最终产生更差的模型。因此,本文采用SIoU[16]。它考虑到所需回归之间的向量角度,并重新定义了惩罚指标。SIoU的定义为
SIoU 由4 个Cost 函数组成:Angle cost、Distance cost、Shape cost 和IoU cost。Angle cost 描述了真实框和预测框中心点连接与x-y 轴之间的最小角度;Distance cost 描述了中心点之间的距离;Shape cost则考虑了两框之间的长宽比,它是通过计算两框之间宽度差和二者之间最大宽度比(长同理)来定义的;IoU cost是预测框和真实框之间的交并比。
改进后的YOLOv5s网络结构如图3所示。由图3可见,与原来的网络相比,改进后的算法在neck端引入了GSconv结构,以降低计算的成本;在backbone端引入了CA注意力机制,以改进边界框回归的损失函数,加快模型的收敛速度。
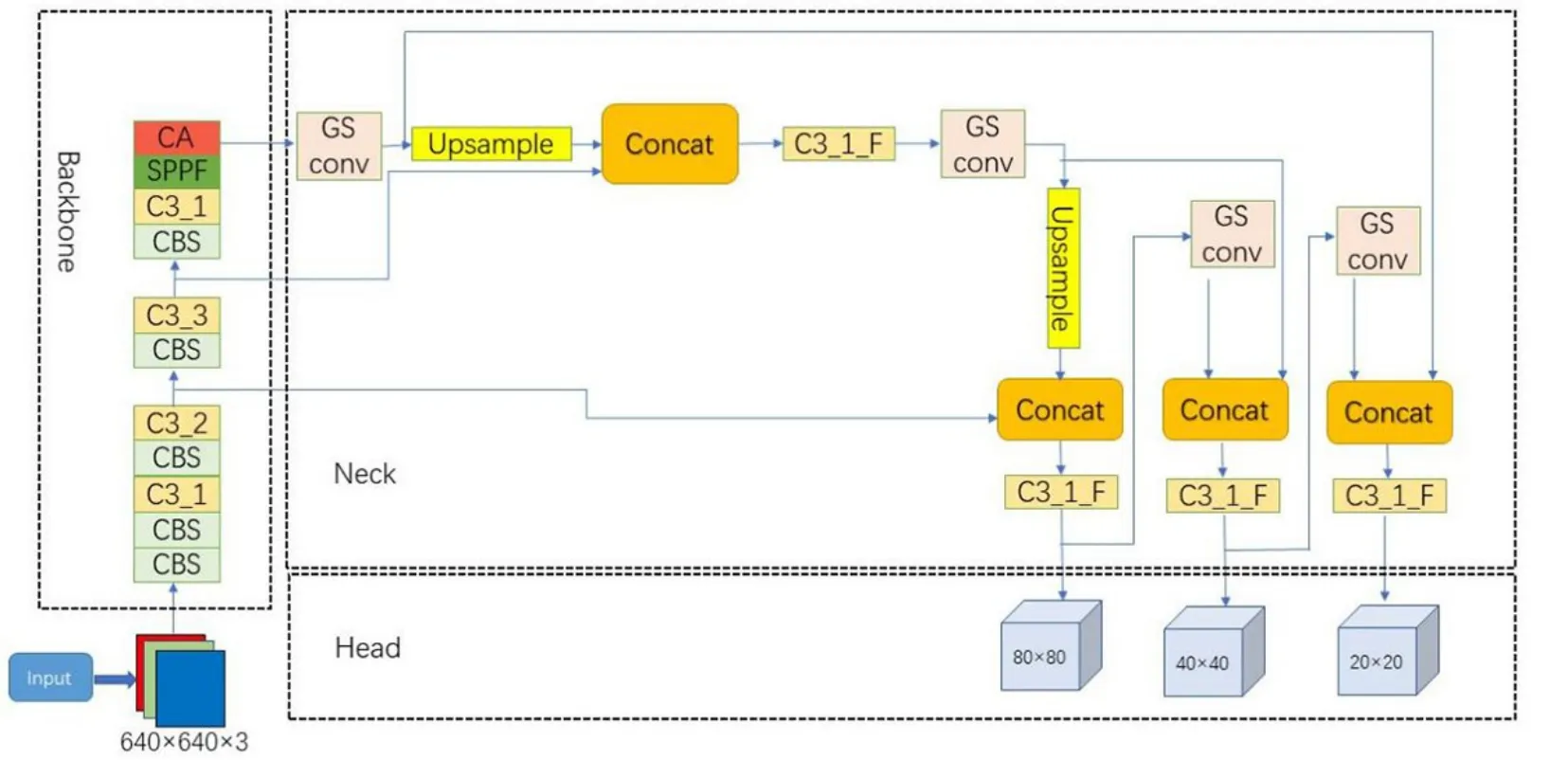
图 3 改进的YOLOv5s算法结构Fig.3 Improved YOLOv5s algorithm
3 实验结果与分析
3.1 实验数据集与数据增强
本文数据集来自文献[17],由人工拍摄,为了模拟实际装配线上的制造过程,文献中对1个给定的磁瓦在多种照明条件下采集图像。其包括5 种缺陷类别:气孔、破损、裂纹、磨损和起层。其中,气孔和裂纹对磁瓦质量的影响最大,这两种缺陷有很多共同之处,它们的颜色比周围的环境暗。起层最难检测,因为它的颜色和纹理与背景高度相似。磨损的颜色和质地与深色表面污垢非常相似。数据集共计383张图片。由于原始缺陷样本数据不足,因此采用平移、翻转,裁剪,缩放等方法对原始数据进行数据增强,扩充后的数据集达到2 340张。最终,将数据集划分为训练和测试集,比例为8∶2。其中,训练集包含1 872张图片,测试集包含468张图片。部分图片如图4所示。

图 4 磁瓦缺陷图片Fig.4 Magnetic tile defects
3.2 实验环境
本文的实验环境配置为:Ubuntu18.04 操作系统,Intel(R) Xeon(R) Silver 4110 CPU @ 2.10 GHzCPU,GPU 为NVIDIA GeForce RTX 2080Ti 显卡,基于深度学习框架pytorch 下运行。实验中,输入图片分辨率为640 px×640 px,batchsize为48,epoch为400。
3.3 实验评估指标
为了更好地评价模型的性能,本文采用目标检测领域常用的评估指标:精确度P、平均精确度AP,平均精确率均值mAP。精确度指的是在预测过程中,预测正确的部分占预测结果的比例。平均精确率是每个类别精确率的平均值。相关计算公式为
式(11)~(13)中:TP(true positive)表示将正类预测为正类的数量;FP(false positive)表示将负类预测为正类的数量;N表示所有可能的预测结果的数量。
3.4 实验结果与分析
3.4.1 对比实验
为了进一步验证本文算法模型的性能,选取几种常用的目标检测算法,在同一配置环境和相同数据集下进行对比试验,以mAP和权重文件大小作为指标。对比结果如表1所示。
由表1 可以看出,本文算法YOLOv5s_GCS在mAP上表现优异,高于其他算法。相较于YOLOv3,提高了5.1%;相较于Faster R-CNN,提高了6.1%;相较于SSD 算法,提高了12.0%。此外,本文算法的权重文件大小也低于这3 种算法。与目前较新的YOLOv8 算法比较,YOLOv5s_GCS 在mAP 上也高出了0.6%,且权重文件大小也要小于YOLOv8 算法。可见,YOLOv5s_GCS 具有较高的平均精度,能够满足磁瓦表面缺陷的精确识别,同时保持较低的权重文件大小,能够更好地满足工业化环境下磁瓦缺陷检测的部署需求。
YOLOv5s 和YOLOv5s_GCS 的各类别平均精度对比情况如图5 所示。由图5 可以看出,除了在Blowhole 类的缺陷上,改进后的YOLOv5s_GCS 略微地下降了0.2%,其他缺陷类别均有不同程度的提升。其中在Fray 类别缺陷上,改进后的算法相对于YOLOv5s提高了8.5%。
为了进一步验证本文算法引入CA 注意力机制的可行性,本文选取几种常用的注意力机制,与改进后的算法进行对比实验,结果如表2所示。
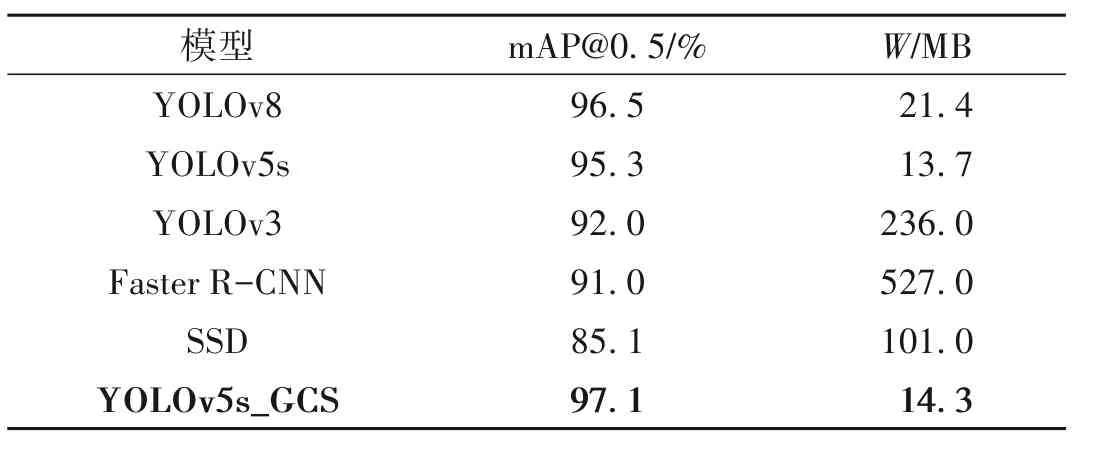
表 1 主流算法对比实验Table 1 Mainstream algorithms compared
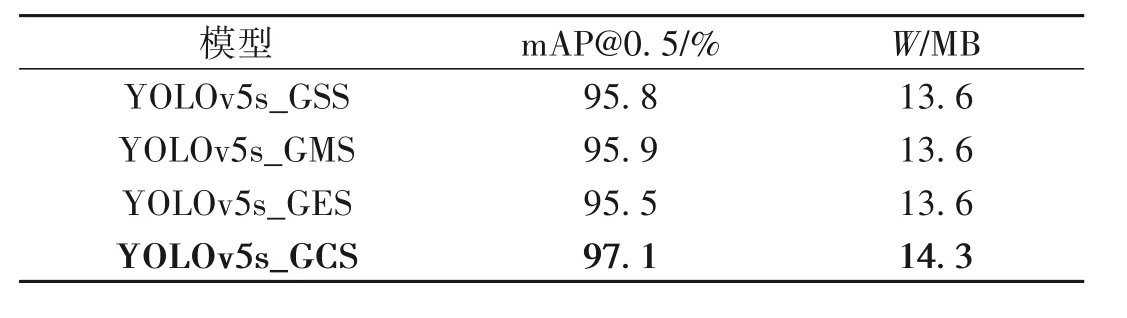
表2 注意力机制对比实验Table 2 Attention mechanisms compared
表2 中,YOLOv5s_GSS 表示添加了SE注意力机制,YOLOv5s_GMS 则是添加CBAM 注意机制,YOLOv5s_GES表示添加了ECA 注意力机制。通过表2 可以看出,YOLOv5s_GCS 的mAP 值要优于其他3 种算法。其中,相比YOLOv5s_GSS,mAP 要高出1.3%。这是因为SE 注意力机制仅仅考虑了通道间的信息,而忽略了位置信息,而CA 中加入位置信息能更好的捕捉到缺陷信息,从而提高了检测精度。与YOLOv5s_GMS 相比,YOLOv5s_GCS 的mAP 值要高出1.2%,比YOLOv5s_GES 要高出1.6%。虽然在权重文件大小上YOLOv5s_GCS要稍高于这3种算法,但在实际生产过程中,对缺陷检测速率影响不大。
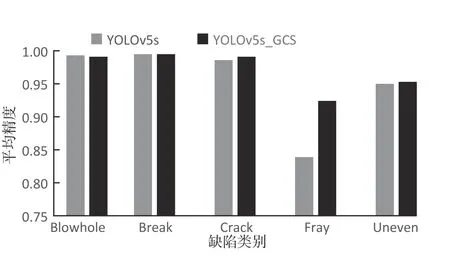
图 5 不同缺陷类别对比Fig.5 Defect categories compared
最后,设计对比实验,通过将主流的基础损失函数与本文改进算法进行对比分析,以更深入地验证本文算法中添加SIoU损失函数的有效性。结果如表3所示。
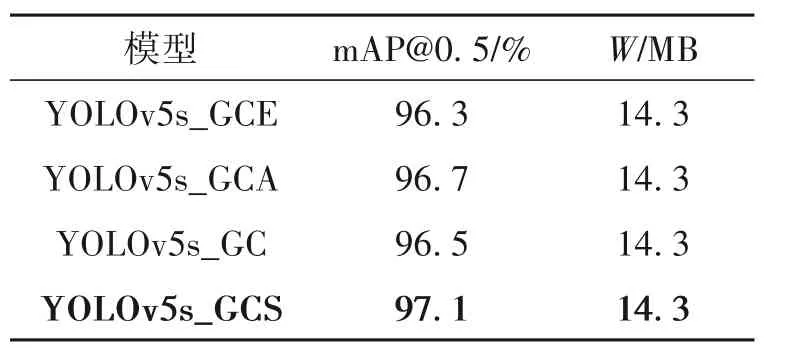
表3 损失函数对比实验结果Table 3 Results of loss function compared

表 4 网络结构消融实验结果Table 4 Experimental results of network structure ablation
表3 中,YOLOv5s_GCE 表示加入了EIoU 损失函数,YOLOv5s_GCA 为添加AlphaIoU 损失函数,YOLOv5s_GC 表示使用原有YOLOv5s 损失函数CIoU,YOLOv5s_GCS 则是本文改进算法。通过表3 实验数据可以看出,加入SIoU 损失函数后,mAP 值要明显优于加入其他3 种损失函数后的效果。这是由于SIoU 能够更好地反映两个边界框的交叠程度。SIoU不仅关注重叠区域,还关注其他的非重合区域,能更好地反映两者的重合度,使模型能够更全面地掌握缺陷信息,从而提高了检测精度。
3.4.2 消融实验
为了验证各个改进模块对磁瓦缺陷检测的有效性及改进算法的性能,对改进算法进行消融实验,结果如表4所示。
表5 中,YOLOv5s_G 表示YOLOv5s 添加GSconv 结构,YOLOv5s_GC 表示添加GSconv 结构和CA注意力机制,最后的YOLOv5s_GCS 是本文的改进后的算法。本实验以YOLOv5s 为基准模型, 通过YOLOv5s_G模型实验结果可以看出,在neck添加GSconv结构后,模型的权重大小减少了5.8%,mAP值提升了0.6%。这是因为GSconv结构通过SC卷积和DW 卷积的混合,使得减轻网络的同时提升检测精度。而从YOLOv5s_GC模型的实验结果可以看出,模型权重增加了4%,这是因为添加了CA注意力机制,所以模型参数量有一定程度的增加。但与此同时,mAP 值提升了1.2%,这证明了CA 注意力机制的有效性,能够更好地捕捉缺陷特征,从而提高检测精度。再看本文改进后的YOLOv5s_GCS,由于引入了SIoU 损失函数的计算,相对于原始模型,其mAP 提升了1.8%。这是由于SIoU 定义了新的惩罚指标,使得网络能够更快、更准确的定位缺陷目标,有效提升了模型的精度。
3.4.3 检测效果对比
分别使用本文算法和Yolov5s算法对磁瓦图片进行检测,结果如图6所示。
从图6可以看出,相对于YOLOv5s算法,改进后的算法能够正确检测更多的缺陷,并且,在几种缺陷类别检测置信度上都有相应的提高。特别是最后一组对比图6(e),在无缺陷样本的情况下,YOLOv5s 错误地识别出了缺陷。表明改进算法比YOLOv5s 算法表现得更优异,对缺陷的误检率要低于原YOLOv5s算法。
4 结论
为提高磁瓦表面缺陷检测的速度和精度,本文先通过轻量化neck 端,减轻网络负担;再引入注意力机制,加强网络计算能力,提升模型精度;同时,引入新的损失函数,加快网络收敛速度,并通过消融实验验证了改进的可行性。与主流目标检测算法的对比实验结果表明,改进后的算法在mAP上达到97.1%,均优于相关算法。本文算法能够很好地满足工业磁瓦缺陷检测任务的需求,并且相对于原有的Yolov5s模型,平均精度提高了1.8%。此外,较小的权重文件也易于部署到生产环境中。
