细粒度云数据自适应去重方法研究
2024-01-14王小红
王小红
(宜春职业技术学院,江西 宜春 336000)
1 引言
数据粒度能够有效地描述数据的详细程度,粒度越小,数据包含的信息越具体,对于获取数据本质与规律越有帮助[1]。细粒度云数据指的是各个方面信息都非常详细具体的云数据,具有多层次化与高效化的特点。与传统意义上的云数据存在一定差异,细粒度云数据获取的难度较高,需要经过大量的训练与学习才能获得。随着数据量的快速增长,细粒度云数据中不可避免会存在各类重复数据。相似重复的数据一方面消耗了大量不必要的存储空间与人力开支,另一方面增大了云数据的管理难度,降低了云数据管理的效率与质量[2]。
基于此,科学合理的细粒度云数据去重方法至关重要。当前,传统的云数据去重方法逐步成熟完善,在实际应用过程中,重复数据去除效果较好。文献[3]采用哈希算法聚类、监督判别投影降维、代数签名预估数据和最小哈希树生成校验值等技术路径,实现对网络单信道数据的高效去重。文献[4]采用基于广义去重的跨用户安全去重框架,通过将原始数据分解为基和偏移量,对基进行跨用户去重,并在云端对偏移量进行去重。
然而,传统的去重方法在细粒度云数据去重操作中仍然存在不足,主要体现在去重覆盖范围有限,不能从多个维度对细粒度云数据中重复的数据作出处理,去重质量较低,实时性较差。针对上述问题,本文在传统数据去重方法的基础上,开展了细粒度云数据自适应去重方法的深入研究。
2 细粒度云数据自适应去重方法设计
2.1 检测相似重复细粒度云数据
本文设计的细粒度云数据自适应去重方法中,首先,需要采用相似重复数据检测方法,对细粒度云数据作出全方位的检测,判断云数据集中是否存在相似重复数据,为后续的数据自适应去重奠定基础。
通常情况下,重复的细粒度云数据包括两种类型,分别为细粒度云数据完全重复与细粒度云数据相似重复[7]。本文对两种重复类型的特征作出了分析:
(1)细粒度云数据完全重复,指的是云数据标记相同,标记的属性及元素内容也相同的记录。
(2)细粒度云数据相似重复。由于细粒度云数据的灵活性较强,同一实体会有不同的表现形式,受到云数据格式差异、拼写差异、完整性差异等因素影响,数据库无法准确地识别出数据部分属性及元素内容,即为细粒度云数据相似重复[8]。
综合考虑两种类型的重复细粒度云数据特征后,本文采用基于边界距离的云数据字段匹配检测算法。该算法是基于一系列字符串编辑操作而实现的,通过计算细粒度云数据字符串之间的边界距离,来判断字符串之间的相似重复性。
边界距离是一种衡量字符串相似性的度量方法,它考虑了字符串中字符之间的位置关系。通过比较字符串的边界距离,我们可以判断字符串之间是否存在相似的重复数据。
通过采用基于边界距离的云数据字段匹配检测算法,本文能够有效地发现并识别细粒度云数据中的相似重复数据。这种算法的应用可以提高数据处理的准确性和效率,并为后续的数据去重和优化提供基础[9]。本文设计的相似重复细粒度云数据检测流程,如图1所示。
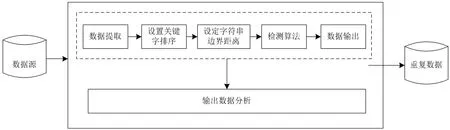
图1 相似重复细粒度云数据检测流程
如图1所示,首先,从海量数据源中提取云数据,并根据云数据的结构特征,设置关键字排序。设定dist(a,b)表示细粒度云数据字符串A与字符串B之间的边界距离,其中,a、b均表示字符串A与字符串B的长度。依据动态规范思想,获取细粒度云数据动态规划的状态转移方程式,如下:
通过细粒度云数据动态规划的状态转移方程式,获取云数据字符串A与字符串B之间的边界距离,此时,dist(a,b)即为云数据字符串A与字符串B的重复相似度。当云数据字符串重复相似度超过一定的值,则认为这些细粒度云数据存在相似重复。根据相似度,判定细粒度云数据是否存在相似重复,输出检测结果。
2.2 提取细粒度云数据去重特征
在上述相似重复细粒度云数据检测完毕后,可以得知云数据是否存在相似重复,并根据字符串相似度,判定云数据重复类型。接下来,压缩存在相似重复性质的细粒度云数据,提取云数据去重特征。
首先,设定Ya表示引用细粒度云数据块;Yb表示相似细粒度云数据块,利用差量压缩方法,对上述输出的相似重复数据进行压缩,压缩过程表达式为:
其中,⊗表示差量编码;△a,b表示细粒度云数据差量数据。通过该表达式,获取细粒度云数据块与相似细粒度云数据块之间的差量数据。相似重复云数据压缩完毕后,提取云数据的超级指纹,即去重超级特征值,能够表示多个细粒度云数据的多个去重特征。基于云数据特征指纹,进行相似重复细粒度云数据的数据融合,融合后的特征即能够代表一类相似重复云数据的去重特征,进而实现细粒度云数据去重特征提取的目标。
2.3 删除重复数据
完成细粒度云数据去重特征提取后,能够获取各类相似重复云数据的去重特征。在此基础上,采用重复数据删除技术,删除细粒度云数据中的相似重复数据。本文采用的是重复数据删除技术中的数据分块去重技术,其技术原理示意图,如图2所示。
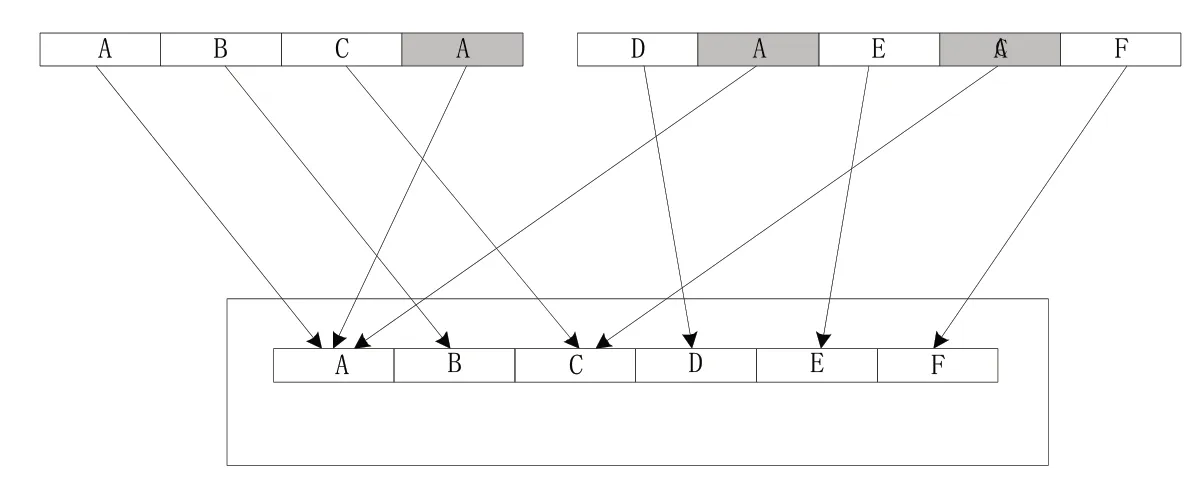
图2 重复数据分块去重技术原理示意图
如图2所示,本文采用的技术能够多维度地将相同数据块指向唯一的实例,避免数据集内存储相同数据,进而节省存储空间。
本文采用了一种基于细粒度云数据分块去重的新方法,旨在解决云存储系统中的数据冗余和存储效率问题。传统的去重方法通常是以文件为单位进行去重,而这种细粒度的分块去重方法可以更精细地处理数据,提高去重的准确性和效率。
具体而言,本文首先对细粒度云数据备份流中的所有文件进行分块处理。通过将大文件划分为更小的数据块,可以实现对数据的精细管理和处理。接下来,采用哈希算法计算每个数据块的哈希指纹,并将其与之前提取到的超级指纹共同设置为该数据块的标识。哈希指纹是数据块的唯一标识,可以用于后续的去重比对。
当云存储系统接收到每个数据块时,会将该数据块的指纹与系统中已有的数据块指纹进行比对。如果数据块指纹已经存在于系统中,说明接收到的数据块是冗余的,即已经存在相同的数据块。为了避免存储重复数据,云存储系统需要在网络的两个端点,即发送端和接收端,消除冗余数据包,并对该数据包进行编码。通过编码技术,可以将冗余数据包转换为校验信息,减少上传到服务器端的数据传输量,提高云数据去重的效率和速度。
另一方面,如果数据块指纹在云存储系统中不存在,则存储该数据块,并及时更新系统的指纹库。这样就能保证云存储系统中只保存唯一的数据块,避免了冗余存储,节省了存储空间。
综上所述,本文所采用的细粒度云数据分块去重方法能够有效地解决云存储系统中的数据冗余和存储效率问题。通过分块处理、哈希指纹比对、冗余数据包消除和数据编码等关键步骤,可以实现高效的云数据去重,提高存储效率和数据处理速度。这种方法在大规模的云存储系统中具有重要的应用价值。
3 实验分析
3.1 实验准备
上述内容,便是本文提出的细粒度云数据自适应去重方法的全部设计流程。在提出的数据去重方法投入实际使用前,进行了如下文所示的实验分析,检验方法的可行性与去重效果,确认整个去重过程中无异常问题后,方可投入使用。
首先,对细粒度云数据自适应去重实验的环境配置进行设置,为实验的顺利开展奠定良好基础。实验环境配置如表1所示。

表1 细粒度云数据自适应去重实验环境配置
按照表1的配置,设置好实验所需环境。其次,为了提高此次去重实验测试的准确性,选用重复度较大的细粒度云数据集,如表2所示。

表2 细粒度云数据集说明
表2 中的Web 数据集中包含了100,000 个网页,其中包括不同主题的新闻、博客、论坛等页面。每个网页的URL、标题和正文内容都被提取存储在数据集中。此外,还记录了网页之间的链接关系,如页面A链接到页面B等;同时,还包含了网页的HTML 结构和标签信息,用于进一步的分析和处理。Linux 源码数据集中包含了Linux 操作系统的源代码文件。每个源代码文件包含了函数定义、变量定义以及相关的注释。源代码组织成目录结构,每个目录代表不同的子系统或功能模块;此外,还包含了Makefile、README文件等辅助信息。
实验所需的细粒度云数据集准备完毕后,按照上述本文提出的云数据自适应去重方法步骤,对云数据集进行去重处理,获取细粒度云数据去重结果,进而检验方法的有效性与去重效果。
3.2 结果分析
在此次实验中,本文特意引入了文献[2]提出的基于最小哈希的数据去重方法、文献[3]提出的基于Reed-Solomon 数据去重方法,分别作为对照组1与对照组2,将上述本文提出的细粒度云数据自适应去重方法设置为实验组,分别对比三种方法应用后云数据的去重结果。采用对比分析的实验方法,能够更加直观地得出此次云数据去重实验的结果,避免结果存在偶然性,增强说服力。本次实验选取细粒度云数据的空间压缩率作为此次实验的性能评价指标,云数据空间压缩率越高,说明细粒度云数据中重复数据自适应去重效果越好,反之则说明去重效果越差,不能有效消除数据集中的相似重复数据。
分别在云数据集1与云数据集2中,选取3个不同大小的细粒度云数据文件,将其编号为SJJ-101、SJJ-102、SJJ-103、SJJ-201、SJJ-202、SJJ-203。利用上述三种数据去重方法,对6个细粒度云数据文件进行去重处理,通过MATLAB 软件的模拟作用与SPSS 软件的数据统计作用,模拟云数据去重全过程,并统计三种方法的空间压缩率,绘制成如图3所示的性能评价指标对比图。
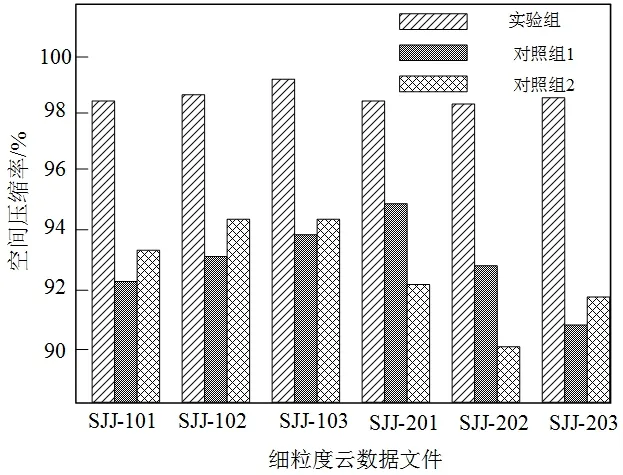
图3 实验性能评价指标对比结果
通过图3的性能评价指标对比结果可以得知,三种云数据去重方法应用后,性能指标结果存在较大的差异。其中,本文提出的云数据自适应去重方法应用后,6 个不同大小的细粒度云数据文件的空间压缩率始终高于对照组1与对照组2 提出的方法,空间压缩率均达到了98%以上。由此对比结果不难看出,本文提出的细粒度云数据自适应去重方法具有较高的可行性,能够最大限度地去除细粒度云数据中的重复数据,去重准确性优势显著,可以大规模投入使用。
某个算法在相同数据集规模下处理时间较短,即呈现较低的计算开销,相对于其他算法来说更高效,具有更高的去重效率。根据给定的实验组别编号对不同组别的实验结果进行了测量,并将结果汇总如表3所示。

表3 去重耗时对比/ms
通过对表3中的数据进行分析,可以得到以下结论:实验组的平均去重耗时为254.8ms,对照组1 的平均去重耗时为485ms,对照组2 的平均去重耗时为492.5ms。由此可见,实验组采用的细粒度云数据分块去重方法相较于对照组1和对照组2的文件级别去重方法,在平均去重耗时上具有更好的性能表现,进一步说明实验组的计算开销较小,可以有效提高去重效率。因此,根据实验结果的平均值分析,得出结论:实验组采用的细粒度云数据分块去重方法相较于传统的文件级别去重方法,在平均去重耗时上具有更好的性能表现。
存储开销是一个关键指标,可以影响系统的性能和扩展性。较低的存储开销意味着在处理数据时,所需的存储空间较小,从而减少了存储引擎的负载和磁盘IO操作,提高了系统的响应速度和吞吐量。此外,较低的存储开销也意味着系统具有更大的扩展能力,能够适应更大规模的数据处理需求。为了进一步验证本文提出的细粒度云数据自适应去重方法的应用性能,对比同一细粒度云数据文件下不同算法所需的存储空间。如图4所示。
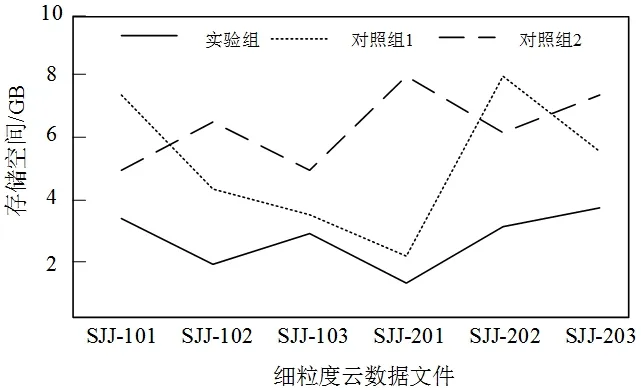
图4 存储空间对比结果
通过图4的存储空间对比结果可知,三种云数据去重方法应用后,对云数据进行去重处理时所占用的存储空间有所不同。其中,应用本文提出的云数据自适应去重方法后,对于不同云数据文件进行去重处理时,所占用的存储空间低于4GB;对照组1和对照组2所占用的存储空间均低于8GB,较实验组占用的存储空间较大,表明本文提出的细粒度云数据自适应去重方法具有较低的储存开销,相对于其他算法来说更高效。
4 结语
在当前云数据存储能力指数级不断提升的背景下,用户对云数据私密性、安全性的重视程度大幅度提升。由于网络信息安全系统长期处于工作运行状态,会实时产生大量的云数据,其中存在较多的重复细粒度云数据,占用存储空间的同时,降低了云数据传输、加密、解密的效率。为了改善这一问题,本文提出了细粒度云数据自适应去重方法的研究。通过本文的研究,有效地降低了细粒度云数据的重复率,且去重正确率较高,全方位满足了网络信息安全系统细粒度云数据去重实时性与准确性的要求,具有良好的应用前景。
