改进过滤模型解决音变问题研究
2024-01-14程兆亮沈雅婷唐俊杰王泽铭
程兆亮 沈雅婷 唐俊杰 王泽铭
(南京理工大学紫金学院,江苏 南京 210023)
1 引言
在实际应用中,需要从大量的文本数据中过滤出特定信息,如搜索引擎、广告识别、情感分析[1]等。特定信息的正确理解和准确表达对于信息处理、搜索引擎、自动化翻译等应用具有重要意义。
其中运用的中文文本特定信息过滤是一种文本处理技术,用于从中文文本中提取出特定的信息。常用的自然语言处理技术[2]技术包括命名实体识别、关键词提取[3]、文本分类、词向量和卷积神经网络等。这些技术可以用于信息检索、自然语言处理、计算机视觉等领域,具有广泛的应用前景。
2 研究背景和意义
在实际应用中,中文是一种复杂的语言,存在相同发音的汉字,因此在处理中存在一个挑战:音变。引发特定信息的音变现象是因为中文作为一种复杂的语言,存在相同发音的汉字。此外,拼音拼写错误也是导致特定信息音变的常见原因之一。这些音变现象给信息处理和语言理解任务带来了巨大的挑战,尤其是在自然语言处理领域,输错一个拼音,文字便不同。因此在进行文本信息过滤时需要考虑到音变带来的影响。
GCNN 模型[4]是一种结合了卷积神经网络[5](Convolutional Neural Networks,CNN)与门控机制(Gate Mechanism)的深度学习模型。门控卷积神经网络在处理语言数据时具有较强的表达能力和鲁棒性,在实际应用中能够取得良好的效果。
本文将研究一种基于门控卷积神经网络的音变的中文文本特定信息过滤模型[6],使用添加了平滑参数的SmoothL1Loss作为损失函数,并将由交叉熵计算的样本隶属度融入其中,旨在提高中文文本处理的准确性和效率。
3 相关概念和理论介绍
3.1 门控卷积神经网络
门控卷积神经网络(Gated Convolutional Neural Network,GCNN)是卷积神经网络(CNN)的一种变体,对序列数据和文本数据的处理进行了改进,以提升模型对序列信息的处理能力。其中卷积层中引入了门控机制,可对信息的流动和过滤进行控制。
图1表明了模型的体系结构,单词由存储在查找表中的向量表示D|V|×m,其中m和|V|分别是词嵌入大小和词汇表中的单词数,模型输入的单词序列W0,...,Wn可以用嵌入向量表示为E=Dw。
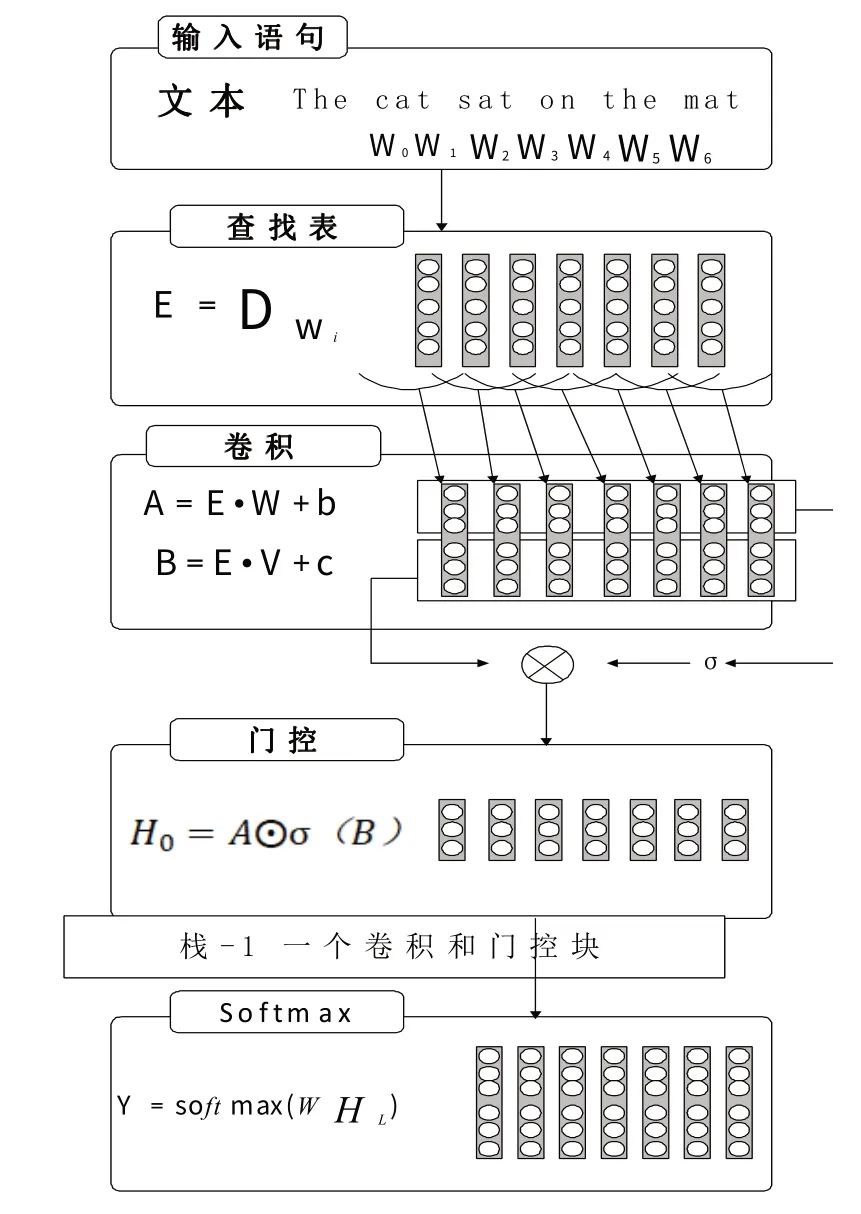
图1 用于语言建模的门控卷积网络的架构
可以由hi(X)=(X*W+b)⊗σ(X*V+c) 计算隐层,其中X∈RN×m是hi层的输入(单词嵌入或前一层的输出),W∈R(k×m×n),b∈Rn,V∈R(k×m×n),c∈Rn是学习参数,σ是sigmoid 函数,⊗是矩阵之间的逐元素乘积。在输入时确保hi没有来自未来单词的信息。移动卷积输入解决卷积核从未来单词中提取信息的问题。
每个层的输出都是一个线性投影(X*V+c),由门控σ(X*V+c)调节。
门控卷积神经网络的基本结构包括卷积层和池化层,卷积层由CGU和GCU 两个子层组成,可以自适应地学习特征和控制信息的流动和过滤[7]。
基于门控卷积神经网络的音变的中文文本特定信息过滤模型的特征表示方式具有较高的灵活性、可解释性和计算效率,能够有效地提取中文文本中的特定信息,实现对文本的过滤和分类。
3.2 文本分类
常用的文本分类方法包括朴素贝叶斯分类[8]、支持向量机分类[9]、决策树分类和深度学习模型等[10]。
从图2中看到,文本分类主要有文本输入、分词(未登录词识别)、特征提取和选择、文本表示、文本分类五个步骤。
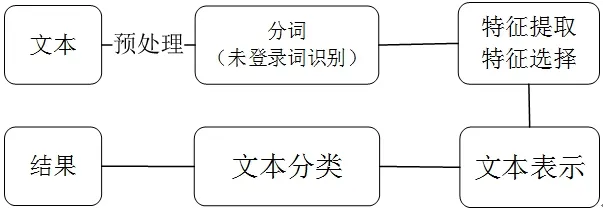
图2 文本分类的五个步骤
3.3 SmoothL1Loss损失函数的相关概念与介绍
本文所使用的损失函数Smooth L1 Loss(平滑L1 损失)是由Ross Girshick[11]在2015 年的论文《Fast R-CNN》中提出。SmoothL1Loss(平滑L1损失)在深度学习领域得到了广泛的研究和应用。
SmoothL1Loss 损失无法根据具体任务进行调整,在一些场景下无法适应数据的特点。因此,添加一个平滑参数β提高模型性能和精度,在处理异常值时更稳定,也具有连续性,更好地适应不同任务;并引入加权损失函数使模型更加关注重要的样本。添加了平滑参数后的SmoothL1Loss的公式如下:
公式1中,yi是真实值,f(xi)是模型输出(预测值),β为平滑参数。SmoothL1Loss 根据预测值与真实值之间的差异来决定,当差异较大(大于等于1)时采用线性函数进行惩罚,将误差的绝对值减去一个0.5β,对较大的误差进行更严格的惩罚。MAE的原公式如下:
公式2 中,yi是真实值,f(xi) 是模型输出(预测值),MAE是把二者之差的绝对值作为误差。
当差异较小(小于1)时,采用平方函数也就是L2Loss(MSE)进行惩罚。对较小的误差进行较小的惩罚,让损失更加平滑,增强模型的稳定性。MSE的原公式如下:
公式3 中,yi是真实值,f(xi) 是模型输出(预测值),SmoothL1Loss在对异常值的处理上更加鲁棒性。它对于较大的误差具有较强的惩罚能力,能够减小异常值对损失函数的影响。平滑特性可以使得梯度下降算法更加稳定,更容易收敛。
从图3可以看到,当预测值和ground truth差别较小的时候,其实使用的是L2 Loss(MSE);而当差别大的时候,是L1 Loss(MAE)的平移。因此可以看出,SmoothL1Loss是一种比较优秀的回归损失函数,尤其适用于存在异常点和离散值的回归问题。
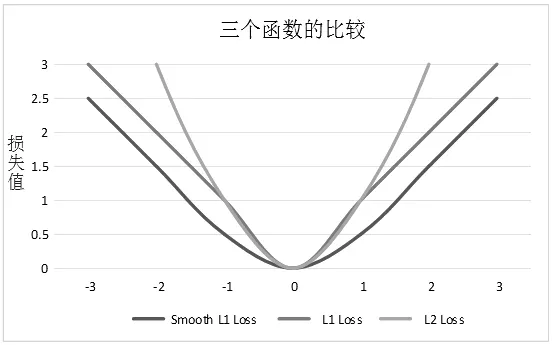
图3 L1Loss、L2Loss与SmoothL1Loss的函数图像对比
总的来说,SmoothL1Loss在各种深度学习任务中展现出了良好的性能和适应性。其平滑性质使得它对于异常值更加鲁棒。
4 算法的设计与创新
4.1 样本隶属度
本文在SmoothL1Loss 中融入了样本隶属度[12]命名为DOM-SmoothL1Loss,交叉熵函数[13]将一组原始分数(或称为logits)转换为概率分布,使得所有类别的概率之和等于1。交叉熵(Cross Entropy)常用于评估分类问题中模型预测结果与真实标签之间的差异,因此也可以用来计算样本隶属于不同类别的概率。
样本隶属度的计算公式如下:
假设有N个样本,每个样本属于K个类别中的某一个,其中第i个样本属于第j个类别的概率为pij,对应的真实标签为yi,yij表示第i个样本是否属于第j个类别,当该样本属于第j个类别时,yij=1,否则yij=0。log 表示自然对数函数。
概率分布pij可以通过模型的输出得到。方法是使用softmax 函数将模型的原始输出转换为概率分布。使用softmax函数计算概率pij的公式如下:
公式5 中zi、zj表示模型对第i个样本属于第j个类别的原始输出。
交叉熵损失函数[14]的意义在于,如果模型的预测结果与真实标签相符,那么损失函数的值将趋近于0。交叉熵损失函数使得模型的预测结果更加接近真实标签,进而提高模型的分类准确率。
对于一个给定的样本,交叉熵损失函数的值可以看作样本在不同类别上的隶属度概率分布与真实标签之间的距离。当样本在真实标签对应的类别上的隶属度概率最大时,交叉熵损失函数的值最小,这也意味着模型对该样本的分类结果最为自信。
融入了样本隶属度后的函数公式如下
公式6为融入了由交叉熵函数计算的隶属度之后损失函数,它有以下几个优点:
(1)能够更直观地理解模型对不同类别的判断。
(2)可以直接在训练过程中优化模型的性能。
(3)它对于模型输出的概率分布与真实标签之间的差异进行度量,能够更好地捕捉到问题中不同样本之间的相对关系。
(4)使得模型输出的概率更具有可靠性和可解释性。
4.2 输入与输出的向量化
本文将输入和输出视为向量,并采用向量处理的方式来解决中文文本特定信息音变的过滤问题。
通过将输入和输出视为向量,可以利用向量化的表示来捕捉文本的结构和语义信息,并将其应用于信息音变过滤任务。使用向量化的表示还可以提供更多的灵活性和扩展性,将输入和输出都视为向量,并基于此进行信息音变过滤的研究,具有一定的创新性。
总的来说,创新主要在于将中文文本信息音变过滤问题转化为向量处理,并利用向量化的表示方式来处理文本的连续性、上下文信息和语义关联。
5 实验
5.1 数据集
本文采用中文对话数据集zhddline,是由搜狗翻译API翻译自DailyDialog数据集。
图4是数据集中的部分中文对话内容。选择这个数据集是因为它提供足够的样本量可以帮助训练出一个准确度高和鲁棒性强的模型。

图4 部分数据集内容
5.2 数据预处理
将原始数据集按照7:1.5:1.5的比例划分训练集、验证集和测试集。
数据清洗:使用jieba[15]分词工具得到文本的词汇表和词向量表示。
数据转换:在进行数据预处理时,还需要对文本进行转换,以便能够被模型所处理。具体地,需要将文本转换成词向量的形式,以便能够输入到模型中进行训练和预测。
同时,需要的是音变的中文文本,所以需要改变一些文本的拼音,判断给定的字符是否是中文字符。然后从数据集中读取词语,将其中的每个汉字转换成拼音,并将这些拼音作为字典的键,值为一个列表,包含拼音对应的所有词语。
数据预处理可以对原始数据进行清洗和转换,使得数据更加适合进行模型训练和应用,提高模型的准确度和鲁棒性。
5.3 实验设置
数据集:使用了中文对话数据集,其中包含了大量的中文文本数据,包括日常生活、商场购物、朋友聊天等内容。
模型参数:使用了2个门控卷积层作为特征提取器,分别为self.conv_gate和self.conv_info,使用了2个卷积核,每个卷积核[16]的数量为output_dim,由输入参数指定,这里为y_tensor.shape。两个卷积核的大小均为3,步长因为没有指定stride,所以为1,门卷积层使用Sigmoid 作为激活函数,信息卷积层使用Tanh作为激活函数。
训练参数:Adam(Adaptive Moment Estimation)优化器[17],学习率为0.001,批次大小为32,训练轮次为10。
5.4 模型整体结构介绍
门控卷积神经网络可以有效克服循环神经网络的单向计算的缺点。使用了门控卷积神经网络来进行损失函数优化前后的性能对比。
基于门控卷积神经网络的音变的中文文本特定信息过滤模型是一种深度学习模型,主要用于处理中文文本数据。
单层门控卷积神经网络的计算过程如图5所示。整个模型能够有效地提取中文文本的特定信息,还具有较好的可解释性和可视化性,更好地比较模型优化前后的性能和特点。
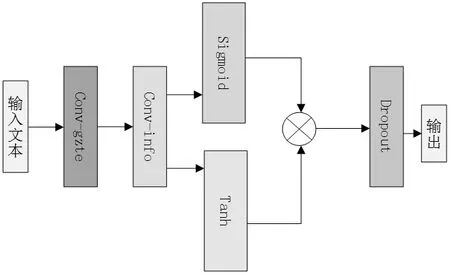
图5 模型的整体结构
6 实验结果的对比与分析
6.1 融入隶属度前后损失值的对比
将融入隶属度前后的模型的loss 值分别测试,进行对比,对比结果如图6。

图6 未添加隶属度的loss值
从图6 可以看出,没有隶属度时,loss 变化率很小,并且在训练集和测试集的第8轮就完成收敛,之后测试集上的波动说明模型开始过拟合。较快收敛说明模型并没有很好地学习特征,陷入局部解。
图7可以看出,添加隶属度后,收敛时间延迟,且测试集上的波动减少,表明模型的泛化性能得到改善,并且对过拟合有更好的控制,提高了模型的稳定性和鲁棒性,并减少了过拟合[18]现象。
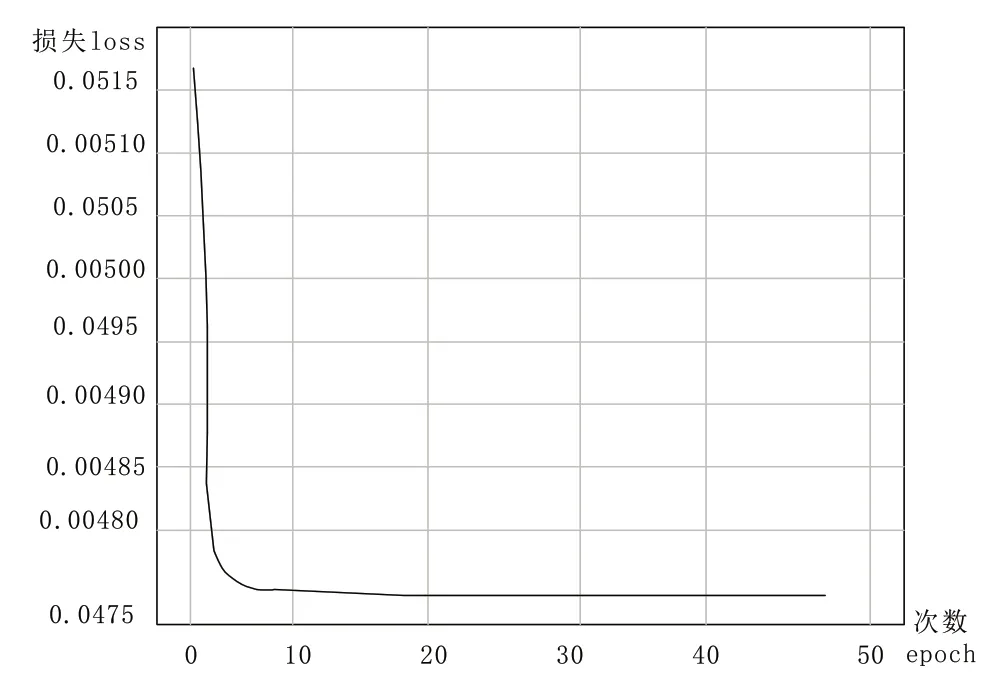
图7 添加隶属度的loss值
总之,添加隶属度对模型的训练和泛化能力产生了积极影响,提高了模型的稳定性和鲁棒性,并减少了过拟合现象。这表明隶属度的引入对模型的学习和性能具有正面效果。
6.2 调整学习率前后损失值的对比
将学习率分别设为0.01 和0.001 的模型进行对比,实验结果如图8所示。
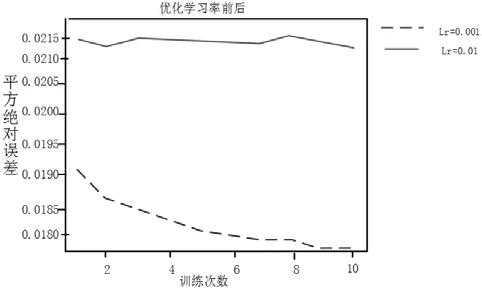
图8 优化学习率前后的MAE误差结果
图8 中显示的是学习率[19]优化前后MAE 指标的实验结果,从中可以看出平方绝对误差(MAE)较改进前的结果有着明显提升。
图9中显示的是学习率优化前后MSE指标的实验结果,从中看出均方误(MSE)相交改进之前的结果有了显著提升。
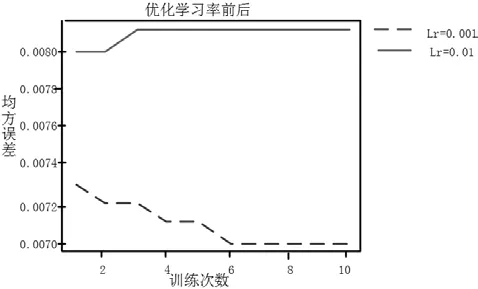
图9 优化学习率前后的MSE误差结果
从图8与图9的对比可以看出学习率参数优化后的模型能够更好地适应中文文本数据,实现对文本的自动分类和过滤,具有较好的性能和应用效果。
6.3 不同模型的结果对比
将融入了隶属度[20]的GCNN_DOM模型与未添加平滑参数的模型,以及朴素贝叶斯三个算法进行比较,得到的平方绝对误差和均方误差结果如表1所示。

表1 三个算法的平均绝对误差比较结果
从表1 可以看出,融入了隶属度L 的GCNN_DOM 的MAE 指标相较于未添加时的模型提升了3.8%左右,比起朴素贝叶斯更是有了显著的提升。
表1、表2 中结果对比突显出改进后的GCNN_DOM 模型的优越,反映出DOM_SmoothL1Loss损失函数的改进结果值得肯定。
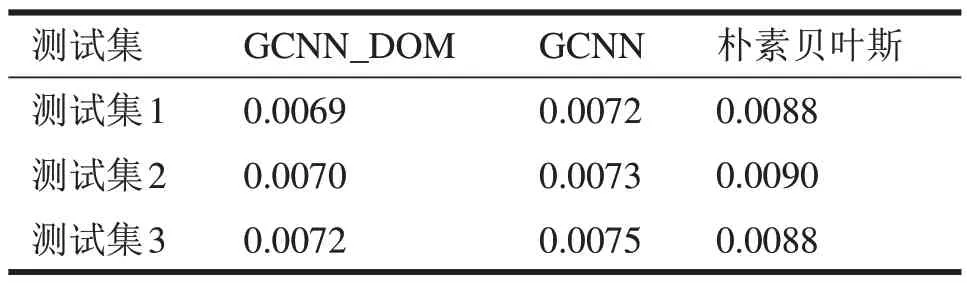
表2 三个算法的均方误差比较结果
6.4 模型过滤效果
如图10过滤前的文本中存在着音变问题,例如“出去想收”“锅的真快”,这些都存在音变问题。

图10 过滤前的文本
从图10 和图11 的对比可以看出,本模型对于产生音变的特定信息的过滤非常有效,可以有效避免输入错误造成的有害结果,具有一定的实际应用价值。

图11 过滤后的文本
7 结语
本文对提取特定信息音变的过滤问题,介绍了一种具有并行计算、多层特征提取和门控机制等优点的门控卷积神经网络算法,并对其中的SmoothL1Loss(平滑L1 损失)作为损失函数进行改进,提出了DOM_SmoothL1Loss,它是一种融入了样本隶属度的损失函数。实验证明该模型在特定信息音变过滤任务中取得了显著的性能提升。未来的工作可以进一步探索和优化该模型,以适应更广泛的音变过滤需求。
