机器学习与知识图谱在藏医药领域的应用研究
2024-01-13普布玉珍高屹
普布玉珍 高屹,2
1.西藏民族大学信息工程学院;2.西藏光信息处理与可视化技术重点实验室,陕西 咸阳 712082
随着人们进一步开发人工智能技术。医疗领域机器学习技术的应用日益受到重视。被广泛应用于医疗数据分析、诊断决策、疾病预测等多个领域。在医疗数据分析方面,机器学习技术可以从大数据中提取出有用信息,可以有效地实现分类、聚类、连续量推断等功能。在诊断决策方面,机器学习技术可以支持医疗决策的客观性和准确性,有助于提高历史诊疗数据的价值和从数据中获取准确有效的推断信息。在疾病预测方面,机器学习技术也可以有效帮助实现精准预测。机器学习技术可以自动学习输入特征与输出标签之间的复杂关系,从而有效地概述病情和发病预测。随着信息技术的发展,人们对健康问题的愈发重视,由于近几年人工智能的飞速发展以及精准医疗、智慧医疗的提出,医学知识图谱应用正受到国内外企业、学界的广泛关注,[1]知识图谱在医学领域中有着广泛的应用。
机器学习是一种通过计算机程序从数据中学习,并做出预测和决策的方法。知识图谱则是一种以图形化的方式呈现出来的知识库,可以用来表示实体、概念以及它们之间的关系。在藏医药领域中,机器学习和知识图谱具有重要的应用价值。通过机器学习算法对藏医药数据进行挖掘和分析,我们可以发现隐藏在数据中的规律和趋势,为藏医药学的深入研究提供有力支持。而通过构建藏医药知识图谱,可以将零散的藏医药知识整合成完整的知识体系,方便学者们进行系统的学习和研究。
本文主要以攻破制约藏医学发展的瓶颈,实现既能够保存藏族重要的传统医药学成果,又能够利用新策略、新工具研究藏医学。
1 研究现状
在现有的研究中,机器学习方法在藏医药领域的应用主要包括分类、聚类和关联规则分析等。此外,研究人员肖宗明[2]等人采用频次分析、关联规则分析、聚类分析等方法来寻找藏医药的用药规律。关联规则目前常用于传统医药领域,主要是从大量日复杂的传统医药信息中发掘不同数据集之间潜在的联系,常见于方剂配伍规律的研究。藏药之间有着各式各样不同的联系,通过聚类分析,可以从不同藏药中找出共同点。还有一些研究者王雪茜[3]利用聚类算法对藏医药古籍进行整理和挖掘,以便更好地传承和发展藏医药学。研究人员袁凯琦[4]等人提出医学知识图谱将知识图谱与医学知识进行结合,并会推进医学数据的自动化与智能化处理,为医疗行业带来新的发展契机。虽然目前对于医疗知识图谱的研究工作有了很多很有意义的尝试,但总的来说还不够完善和深入,需要更进一步的研究。
虽然这些研究取得了一定的成果,但仍存在一些问题和不足之处。首先,机器学习算法的应用主要集中在某一具体领域,缺乏对整个藏医药学领域的全面研究。其次,现有的知识图谱建设还处于起步阶段,知识库的完备性和准确性有待进一步提高。最后,机器学习与知识图谱在藏医药领域的结合应用尚处于探索阶段,仍有很大的发展空间。
2 概述
2.1 机器学习概念
机器学习就是利用电脑算法。让计算机从大量数据中学习规律和模式,以应用到新的数据中,并且具有自我调节、自我学习、自我优化的功能。可以理解为,通过计算机学习一定的模型,让电脑自动从资料中提取特征,并且能够快速地进行预测和决策。
2.2 机器学习的常用算法
2.2.1 监督学习是最常见的机器学习算法之一。其基本思想是让计算机通过已知的特征值和标签值的数据对模型进行训练,以便对未来的数据进行预测。监督学习包括两种类型:分类和回归。在分类中,目标变量是离散的,比如判断一张照片中的物品是猫还是狗;在回归中,目标变量是连续的,比如根据房屋的面积、位置等特征预测售价。
2.2.2 无监督学习(unsupervisedlearning)与监督学习的区别在于。无监督学习不需要已知数据标签,而是通过对数据特征的提取和模型的训练来寻找数据中的内在规律和结构。无监督学习包括聚类(clustering)和降维(dimensionality reduction)两种类型。在聚类中,通过将数据分成不同的簇,挖掘数据内在的结构和规律;在降维中,通过去除数据中的噪声和冗余信息,减少数据量和计算复杂度。
2.2.3 强化学习是一种特殊的无监督学习方法。其目标是让计算机通过与环境的交互来学习并选择最佳的行为策略,以最大化长期的奖励[5]。强化学习包括状态、动作、奖励三个要素,通过这三个要素的交互来训练模型。应用场景包括游戏、自动控制等。
2.3 知识图谱的概念
知识图谱(knowledgeGraph)是基于图结构的知识表示模型,用于实体间关系和存储和表示。它通过将现实世界的知识转化为图中的节点和边,以便于机器理解和推理。
知识图谱是结构化的语义数据库,用来以符号方式说明在物理世界中的概念,以及彼此关联。其基本构成单元为“实体关系实体”三元组,内容包括实体的关联属性值等,[7]将实体之间的联系互相联结,形成网状的知识结构。
元组的基本形式主要包括:实体—关系—实体;实体—属性—属性值等,如图1和图2表示。[8]
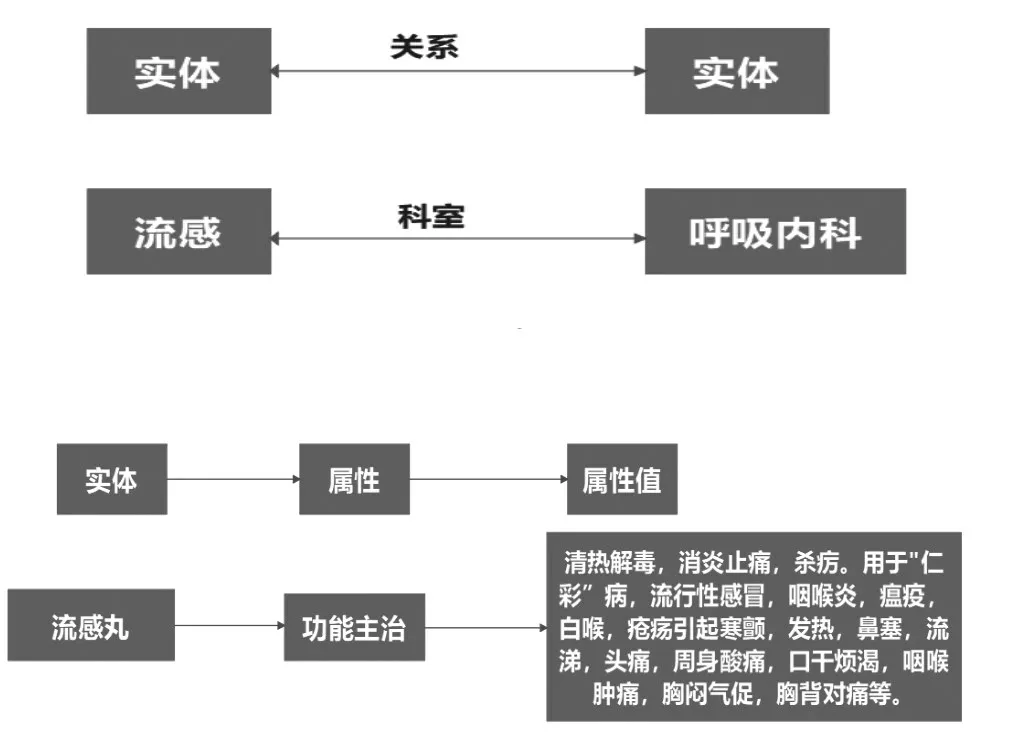
图1 实体关系实体举例
图2 实体属性属性值举例
概念:
(1)实体(Entity):在知识图谱中,实体代表人、地点、组织、事件等现实世界中的具体事物;(2)属性(attribute):属性描述的的特性和性质,例如一个人的年龄、身高、职业等;(3)关系(Relation)。关系表示实体之间的连接和相互作用,例如人与人之间的家庭关系、组织与人之间的雇佣关系等。
2.4 知识图谱方法
实体抽取(Entity Extraction)。在文字数据中,确定并抽取出与实物有关的信息,比如个人姓名、地址、工作单位等。
关系抽取(RelationExtraction)。识别和提取文本数据中实体之间的关系。例如雇佣关系、合作关系等。
属性抽取(Attribute Extraction)。从文本数据中识别和提取出实体的特征和属性,例如年龄、性别、学历等。
本体建模(Ontology Modeling)。构建一个本体(ontology)来定义实体的类别、属性和关系,并进行分类和层次化。
图形数据库存储(图形数据库存储)。使用图数据库来存储和表示知识图谱,以便于高效的查询和推理。
知识推理(知识推理)。通过对知识图谱的结构和规则进行推理和推断,发现隐藏在知识中的模式和规律。
应用开发(Application Development)。基于知识图谱,开发各种应用,如智能问答系统、推荐系统、决策支持系统等。
知识图谱的技术架构,如图3所示。

图3 知识图谱技术框架
知识图谱的方法和技术可以应用于多个领域,包括搜索引擎、智能助理、医疗健康、金融风控等,提供更智能和个性化的服务。
3 机器学习与知识图谱在藏医药领域的应用
3.1 药物研发
机器学习可以通过分析大量的化学数据和生物数据,辅助药物研发过程。例如,通过机器学习算法预测潜在的靶点,加速药物筛选和设计过程。同时,知识图谱可以整合藏医药领域的各种知识,包括药物的性质、功效、毒副作用等,为药物研发提供参考。
3.2 疾病诊断与治疗
机器学习算法可以通过分析临床数据,识别和预测疾病。例如,利用机器学习方法分析患者的体征和病历等数据,快速准确地进行疾病诊断。同时,知识图谱可以整合藏医药领域的临床经验和专家知识,辅助医生进行诊断和治疗决策。
3.3 患者健康管理
机器学习可以通过分析患者的生理指标和行为数据,对患者的健康进行监测和管理。例如,通过机器学习算法分析患者的运动数据和饮食记录,提供个性化的健康建议和预防措施。同时,知识图谱可以整合患者的健康档案和医疗信息,实现患者的全面管理。
3.4 医学知识推荐
机器学习和知识图谱可以结合,根据医生和患者的需求,推荐相关的医学知识。例如,基于机器学习算法对医学文献进行分析,提取出与某个疾病或药物相关的知识,并通过知识图谱的方式呈现给医生和患者,帮助他们更好地了解和应用相关知识。
总之,机器学习与知识图谱在藏医药领域的应用可以提高药物研发效率、优化疾病诊断与治疗、改善患者健康管理,并提供个性化推荐医疗知识的服务。
3.5 构建藏医药知识图谱的步骤
知识图谱是在“大数据”时代背景下出现的一项新颖的知识管理技术[8]。知识图谱构建的方式有很多,有基于Protege去构建,是使用本体去一层层构建,手动定义一层一层关系,最终的结果是RDF 或者OW文件保存。另一种方法可以使用工业界比较常用的Neo4j图数据库管理工具,它操作简单,分为桌面版本和社区版本。构建知识图谱的步骤,如图4所示。
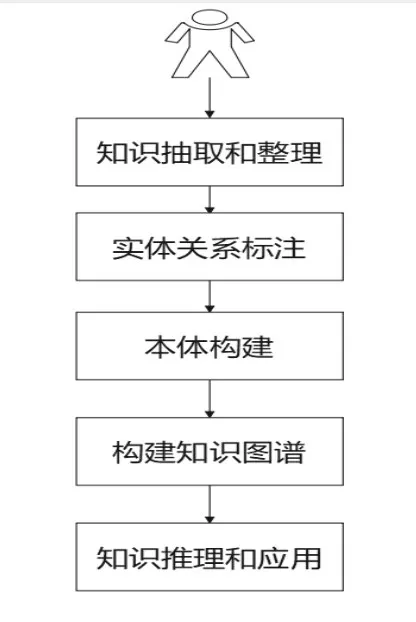
图4 构建知识图谱步骤
构建藏医药知识图谱步骤有以下几方面:(1)知识抽取和整理:收集和整理藏医药的数据集、相关文献、专家知识和医案等信息,识别出文本中的藏医药相关实体,如草药、疾病、方剂等。将抽取的实体和它们之间的关系,如使用药物进行治疗、症状与病因的关系等;(2)实体关系标注:从大量的数据集、文献和专家经验中提取出藏医药知识图谱中实体之间的关系信息。对抽取的实体和关系进行标注,将病名标注为疾病类别,将草药标注为药物类别,将诊断方法标注为诊断方法类别等;(3)本体构建:根据标注藏医药的实体和关系,构建一个本体。将药物和草药分为不同的类别,并定义它们的功效、用法、剂量等属性;(4)构建知识图谱:将抽取和整理的藏医药知识按照本体的定义,构建成实体和关系之间连接的知识图谱;(5)知识推理和应用:基于构建好的知识图谱,进行推理和分析,发现隐藏在知识中的规律和模式。通过知识图谱可以推断出某个草药适用于治疗哪些疾病,或者诊断某种疾病时应该使用哪些方法。
3.6 机器学习方法在藏医药知识分析和挖掘中的应用
3.6.1 收集和整理藏医药领域的相关文献、专家知识和医案等信息。通过机器学习算法可以对藏医药文献进行分析,将文本进行分类,识别出相关的实体。例如,通过训练一个文本分类模型,可以将藏医药文献自动分类为药物、疾病或治疗方法等。同时,通过实体识别算法,可以从文本中提取出相关的草药、方剂、症状等实体。
3.6.2 对抽取的实体和关系进行标注。机器学习方法可以通过分析藏医药领域的文本数据,提取出实体之间的关系。例如,通过训练一个关系抽取模型,可以从藏医药文献中抽取出草药与疾病之间的关联关系,或者草药与药理作用之间的关联关系。这些关系的提取可以帮助了解藏医药中的治疗机制和相互作用。
3.6.3 根据标注的实体和关系,构建一个本体(ontology)作为知识图谱的基础,包括定义各个实体的概念、属性和关系,并进行分类和层次化。机器学习方法可以辅助构建藏医药领域的知识图谱。通过对文本数据进行处理和分析,能够提取实体和关系,构建节点和边缘的知识图谱。例如,将药物、疾病、症状等实体作为节点,将它们之间的关联关系作为边,构建一个藏医药知识图谱。
3.6.4 利用机器学习方法,可以对构建好的藏医药知识图谱进行推理和问答。可以自动回答用户对藏医药知识图谱的问题。通过知识的学习,并对知识进行推理。可根据用户提出的问题进行提问,给出准确的答案或建议,并能够解释其推理过程。通过建立模型,可以根据查询问题,从知识图谱中找出相关实体及其相互关联的关系,并提供答案或相关知识。这种方式可以帮助人们更快地获取有关藏医药的信息。
3.6.5 通过对藏医药领域知识图谱的建构,可以帮助医生和研究人员更好地理解和应用藏医药知识,提供个性化的诊断和治疗方案,促进该领域的研究和发展。机器学习可以应用于基于藏医药知识图谱的应用开发,如药物研究、疾病预测、治疗方案推荐等。通过机器学习算法的辅助,可以挖掘出潜在的关联关系,为藏医药领域的研究和应用提供决策支持。
综上所述,机器学习方法在藏医药知识分析和挖掘中可以应用于文本分类和实体识别、关系抽取、知识图谱构建、基于知识图谱的推理和问答以及知识图谱应用,为藏医药领域的研究和应用提供支持。
4 总结与展望
藏医学是一门古老学科,是四大传统医学体系之一,是经过不停地实践和钻研,逐步形成的人体生理、病理、诊断、治疗、方剂等为一体的民族医药学[10]。藏医学是中国医药学重要组成部分[10],是人类发展史上重要的医疗宝库,是中国医学系统完整的重要医药系统。藏医药研究始于1992 年,藏医药的发展大致经历了两个时期,最开始以经典典籍的数据整理、翻译为主,逐渐演变为多热点,多学科的综合性研究。在二十年间,藏医药不仅是在基础理论研究和药物开发应用研究上都取得了可喜的成绩,但作为民族医药的重要一环,藏医药的研究和开发仍存在众多待解决的问题[11]。充分的理解藏医学的深入研究与发展还面临许多有待克服的困难。充分地认识藏医学中传统学科对现代研究的意义,多学科协作研究优势得以发挥。
总之,本文初步探讨了机器学习与知识图谱在藏医药领域中的应用,旨在为藏医药知识的传承与发展提供新的思路和方法。尽管研究中存在一些不足,但我们相信随着技术的不断进步和完善,这一领域将会有更加广阔的研究前景。
未来的研究方向应该是多方面的。首先,需要对整个藏医药领域进行全面的机器学习研究,包括药物研发、疾病诊断和预防等方面。其次,需要进一步完善现有的藏医药知识图谱,提高知识库的完备性和准确性。最后,积极探索机器学习与知识图谱在藏医药领域的结合应用,为藏医药学的发展提供更强大的技术支持。
