基于百度地图API 的纯电动汽车未来行驶能耗预测
2024-01-13黄新朝
黄新朝,张 毅
(重庆理工大学 车辆工程学院,重庆 400054,中国)
随着能源紧缺与环境问题的不断突出,电动汽车成为了各国的发展焦点[1]。然而,电动汽车的续航里程有限、充电时间长、充电设施不足等问题阻碍了其应用。而车辆未来能耗预测可以为电池尺寸优化[2]、节能路线规划[3]和充电设施建设[4]等提供指导性参数。同时,电动汽车能耗的准确实时预测也有助于缓解驾驶员的里程焦虑。
实现未来能耗预测的方法有2 大类,即基于车辆仿真模型的方法和基于实测数据的方法。对于前者,通常以驾驶员的操作为输入,并在车辆仿真工具上实现车辆建模,以进行整车仿真和能耗分析[5]。例如,WU Xinkai 等人提出了一种基于纵向动力学的电动汽车需求功率模型来估算电动汽车的瞬时功率和能量消耗[6]。车辆模型驱动的能耗预测方法通常依赖于各种预设条件,例如新欧洲驾驶循环周期(New European Driving Cycle,NEDC)等固定工况,因此,其难以适应复杂多变的现实行驶工况。
随着车联网(internet of vehicle,IOV)的快速发展,实时获取单个车辆以及环境(包括交通流)信息成为可能,因此,基于数据驱动的能耗预测逐渐成为主流。其主要基于各种统计和机器学习算法,并使用大量真实世界的行驶数据以及道路、天气和交通数据,来预测复杂行驶工况下电动汽车的能耗。例如,QI Xuewei等人提出了正负动能分解位置的数据驱动模型,并且基于实时车速信息实现了高精度能耗预测[7]。C. De Cauwer 等人先使用神经网络预测出发前各路段微观驾驶参数,然后使用多元线性回归预测能量消耗[8]。由于车辆动力系统与行驶环境中普遍存在的非线性关系,机器学习方法在复杂条件下表现更好。
然而,现有的电动汽车未来能耗的估计方法皆未考虑实时车流状况数据对于整车能耗的影响,即缺乏对于实时交通路况的信息感知能力。此外,目前的研究大都是基于理想情况的软件仿真验证,而没有进行实车上路验证,故缺乏真实性与可靠性。
本文作者使用了百度地图的智能交通系统,作为实时交通信息的来源用以完善预测模型,以提高预测的实时性与准确性。同时搭建了实车平台进行上路验证测试,并且通过能耗预测值计算得到电池荷电状态(state of charge,SOC)预测值。通过将SOC 预测值与实际值进行对比,对预测模型的准确性进行验证。
1 实验平台
1.1 未来行驶能耗预测模型整体结构
本文设计的未来行驶能耗预测模型如图1 所示。将从实车在环(in-loop)车辆获取的单个测试车的行驶数据以及百度地图应用程序接口(application program interface,API)提供的车流拥堵数据进行预处理并提取特征参数;然后通过k-means 聚类分析将历史数据分成6 种行驶工况;再将这6 种行驶工况数据用以训练支持向量机(support vector machine,SVM)分类器,训练完成的分类器可以根据百度地图API 所提供的实时车流信息预测实验车辆的未来平均能耗。

图1 基于百度地图实时车流信息的能量消耗预测模型
此外,由于车载控制器的计算能力及存储空间无法满足实时车辆预测算法的需求,因此本文在云端服务器运行相对复杂的机器学习算法,以预测未来车辆行驶能耗以及及电池SOC 变化量,如图2 所示。

图2 云端数据处理过程示意图
具体而言,实车在环的实验车辆通过4G LTE 无线通讯网络将实时行驶数据上传至云端服务器。再结合云端存储的历史数据(包括单车行驶数据和百度地图提供的车流数据),在云端服务器上使用人工智能算法预测未来的能量消耗。
本文的预测对象为一段长21 km 且耗时大约1 h的行驶路径的未来行驶能耗。云端服务器的计算延迟(即SVM 分类器计算时耗)约10 ms 和传输延迟约100 ms[9]对于整个行驶工况,即1 h 行驶过程,可以忽略不计。但是,本文的拓扑结构暂时无法应对通讯中断等问题。后续研究计划在本文的基础上建立一个具有两层结构的预测算法,即云端负责长时间跨度预测,而车载端负责短期实时预测,以解决此类问题。
1.2 实车在环子系统
本实验选用长安逸动EV460 纯电动汽车(见图3)作为实车在环测试对象。子系统的驱动电机为永磁同步电动机,其他参数见表1。实车在环车辆的改装细节如图4 所示。其中,车载诊断系统(on-board diagnostics,OBD)接口负责提供车辆行驶过程中各种实时状态数据。

表1 实车在环车辆子系统参数

图3 实车在环仿真的纯电动汽车

图4 实车在环车辆配置
通用串行总线(universal serial bus,USB)与控制器局域网总线(controller area network,CAN)接口卡,将汽车实时状态数据从OBD 接口处传输至负责现场数据采集的笔记本电脑。全球定位系统(global positioning system,GPS)模块用于定位当前汽车行驶位置,同时记录汽车行驶轨迹。而4G LTE USB上网卡将这些数据上传至云端服务器。具体改装细节参见文献[9]。
1.3 电池软件仿真子系统
本文的实车在环车辆车载电池管理系统的SOC 检测精度仅到个位数。在实车路试中,这样低的检测精度会导致测试车辆行驶完一个路段后SOC 的变化值为0 的情况,故本文在云端服务器上搭建了一个基于安时积分法的电池软件仿真模型,其SOC 精度可达0.01 %。该模型根据在环中车辆的实时驱动功率,实时计算电池SOC 的变化量。
如图5 所示,电池内阻模型可以等效成一个理想电压源和一个内部等效电阻的串联组合。模型中电池开路电压VOC和等效电阻Rin皆为SOC 的函数。本团队通过循环充放电实验,完成的磷酸铁锂电池的VOC与Rin的数据标定[10]。结果如图6 所示。
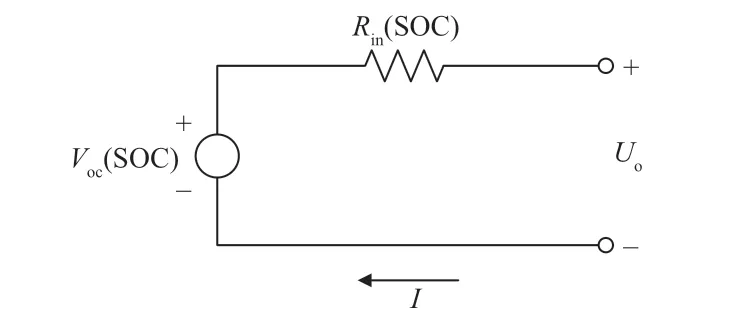
图5 电池等效电路模型

图6 电池开路电压与等效内阻
根据图5 的电池模型与图6 的实验数据,使用安时法可得
其中:Qbat为电池额定容量;Pbat为电池输入电功率,可由车辆驱动功率求得;正为放电,负为充电。
1.4 基于车载OBD 的实车行驶数据
完成实车测试平台和云端服务器搭建后,还需要规划实验道路,以便采集历史数据并提取特征值。本文选取重庆理工大学附近一段约20.6 km 的闭环复杂路线(见图7),并且选定测试时间为17:30下班高峰时段。

图7 实验道路规划
该路线同时包含了多条畅通和拥堵路段,能使测试车辆工作于不同的行驶工况下,从而确保测得的历史数据能够包含不同的路况类型。为了方便后续数据处理并增加数据稳定性,本文按照地理特征(如红绿灯或者十字路口等),将采集的历史数据分割成16 个子路段。测试车流按照逆时针方向行驶。
由于驾驶员的个人风格会显著影响能耗结果,尤其是偏爱急加速的驾驶员会导致能耗显著偏高。因而识别不同驾驶习惯需要建立一个驾驶员模型,用以修正预测结果,但是本文出于简化设计的考虑,并未配置驾驶员模型。所以在收集历史数据和测试时都使用同一个驾驶员,并且要求其在不违反交规和安全的前提下,尽可能与车流保持一致,以此降低驾驶员驾驶习惯对数据的影响。
图8 为测得的实车采集的历史数据,其中:S为行驶距离,v为车速,α为油门开度,Pveh为整车功率,Pmot为电机功率。为了方便后续进行聚类分析,将历史数据提取其特征值。特征值的选取参考了文献[11]的研究结果,尽量选取与整车行驶能量消耗显著相关的特征值,其中包括平均速度、平均加速度、平均减速度、怠速占比、0~20 km/h 占比、20~40 km/h 占比、40~60 km/h 占比、>60 km/h 占比、单位距离平均能耗、单位距离平均时耗。
1.5 基于百度API 的道路车流数据
百度地图API 是基于百度地图服务的应用接口,包括定位SDK、车联网API、Web 服务API 等多种开发工具与服务。云端服务器可以通过百度地图提供的应用程序接口获取实时路况信息。其与1.3 节通过车载OBD 获取的单车行驶数据一起作为数据样本,以训练在云端搭建的机器学习预测算法。本文使用了实时路况查询服务(Traffic API)和批量算路服(Route-Matrix API)以获取车流信息。百度API 特征数据见表2。
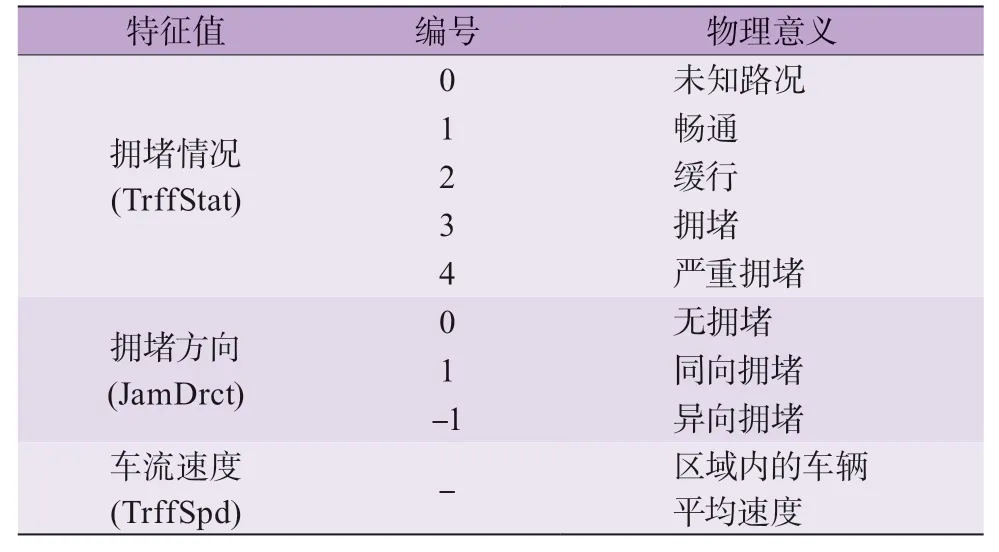
表2 百度API 特征数据
实时路况查询服务用于查询当前路段及区域的实时拥堵情况和趋势。由于实车在环车辆与同侧车流共同行驶,异向拥堵情况对本次测试数据没有影响。批量算路服务可以进行路线距离规划和车流速度估算。车流速度是通过将一段行驶路径的里程数除以车流通过时间得到,其中车流通过时间包括汽车停车等待时间。这与单车数据中的平均速度(不包含等待时间)不同。因此表2 中的车流速度会略慢于单车数据中的平均速度。
实车行驶过程中同步收集的百度API 车流信息:拥堵情况(TrffStat)、拥堵方向(JamDrct)以及车流速度(TrffSpd),其历史数据如图9 所示。实车测试平台用以获取行车历史数据,而百度地图API 用以获取实时路况信息。这2 种数据被预处理后将上传至云端服务器用于训练基于机器学习的预测算法模型。

图9 百度API 车流信息历史数据
2 车辆未来能耗预测算法
实车历史数据(图8)与车流历史数据(图9)上传至云端服务器后,使用k-means 与SVM 算法对其进行处理,以建立未来行驶能耗预测模型。通过k-means聚类分析将历史行车数据聚类为若干种典型工况。将聚类所得的带有工况类型标签的数据样本用于训练SVM 分类器。训练好的SVM 分类器作为预测器,根据百度地图API 提供的实时车流数据对实车在环车辆的未来工况进行预测。
2.1 k-means 聚类算法
本文利用k-means 算法,对汽车OBD 单车数据与百度地图API 数据进行聚类分析,以确定各个样本数据所应归属的典型工况。k-means 算法是一种典型的基于划分的聚类算法,也是一种无监督学习算法。其核心流程如图10 所示。

图10 k-means 聚类分析算法流程
k-means 算法对给定的样本集,用Euclide 距离作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,相似度越大,距离越小。空间中数据对象与聚类中心间的Euclide 距离为
预先指定初始聚类数(本文中为6)以及对应数目的初始聚类中心。按照样本与不同聚类中心的距离,把样本划分进距离最近的簇。并根据上一次样本集划分结果,不断更新聚类中心的位置,进而完成一下迭代并降低类簇的误差平方和为
其中:ci为质心中点坐标;x为每个数据样本的坐标。当SSE 不再变化或目标函数收敛时,聚类迭代结束并输出最终结果。
本文中k-means 聚类的数据来源为百度地图API的车流数据和OBD 接口的单车数据。具体数据见图8、9。根据特征值数据的重要程度,赋予不同权重,并进行标准化。停车等待时间、单位距离能量消耗(Es)和单位距离行驶时间(Ts)是本次聚类分析的重点,因此赋予较高的权重。利用k-means 算法将样本数据分成6 个簇集。表3 为6 种典型子交通工况。
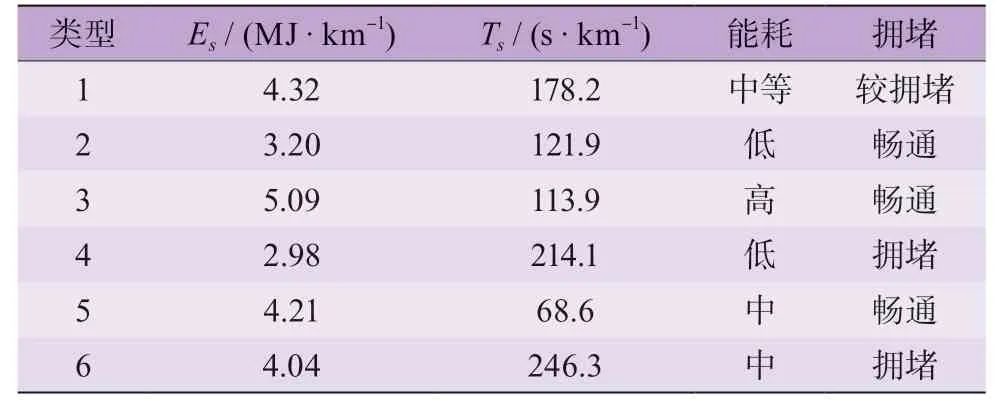
表3 典型子工况类型
每个簇集中的平均能耗概率分布和平均时耗概率分布见图11。图11 中红色实线、虚线分别表示数学期望以及1σ上、下限。将使用聚类后的带工况类型标签的样本数据来训练SVM 分类器,以此达成预测未来行驶能耗与时耗的目的。

图11 典型工况平均能耗概率分布和平均时耗概率分布
2.2 SVM 分类算法(预测器)
使用由k-means 算法聚类后的带有工况类型标签(表3 )的历史数据,以训练SVM 分类器,进而实现在线预测未来行驶能耗。训练过程中,数据样本对应的车流信息的特征值(表2 )作为SVM 的输入,数据样本对应的工况类型标签(表3 )则作为SVM 的输出。这样训练完成后的SVM 分类器,可根据从百度API 获取的各个路段的车流信息预测其所对应的行驶工况类型。根据图11 各个工况类型对应的能耗与时耗的概率分布,可预测未来能耗与时耗的期望值。
SVM 的基本思想是在样本空间中找到一个最大边缘超平面,并利用该超平面将2 个预定义的训练样本数据分类。最大边缘超平面可通过求解凸二次规划优化问题获得,如下:
其中:αi为Lagrange乘子,yi为样本xi的类,m为样本量。采用径向基函数(radial basis function,RBF)核作为核函数:
其中,σ是径向基函数的方差。基于核函数,由式(4)可得
其中,b为分离的最大边缘超平面的位移。完成SVM离线训练后,可以根据百度地图API 提供的各路段的实时车流数据,预测相应各路段的未来工况属于6 种典型工况中的哪一种。根据图11 对应工况的时耗和能耗的概率分布,来预测车辆未来的时耗与能耗的概率分布与数学期望。
3 实车上路实验
3.1 实验条件与流程
进行实际的道路行驶测试,以验证预测算法的可靠性。实验条件如表4 所示。

表4 试验条件参数表
实验过程中的数据处理流程如下:
1) 离线训练的SVM 分类器在行驶前接收百度地图API 传输的车流信息,预测电动汽车在各个路段(即图7 中的16 个路段)所属的工况类型(即表3 中的6种工况之一 )。
2) 根据图11 中各个工况类型的单位距离时耗、能耗的概率分布中求得预测的时耗、能耗的数学期望以及对应的1σ上下限。
3) 根据实车采集的实际能耗与预测所得能耗,在云端的的电池仿真模型(见图5、6 ),实时计算电池ΔSOC 的实际值与预测值。
3.2 实验结果与分析
实验结果分别在展示在空间域与时间域中,如图12 所示。图12 中:竖直虚线对应图7 中的路段分割点,S为行驶距离,t为行驶时间。
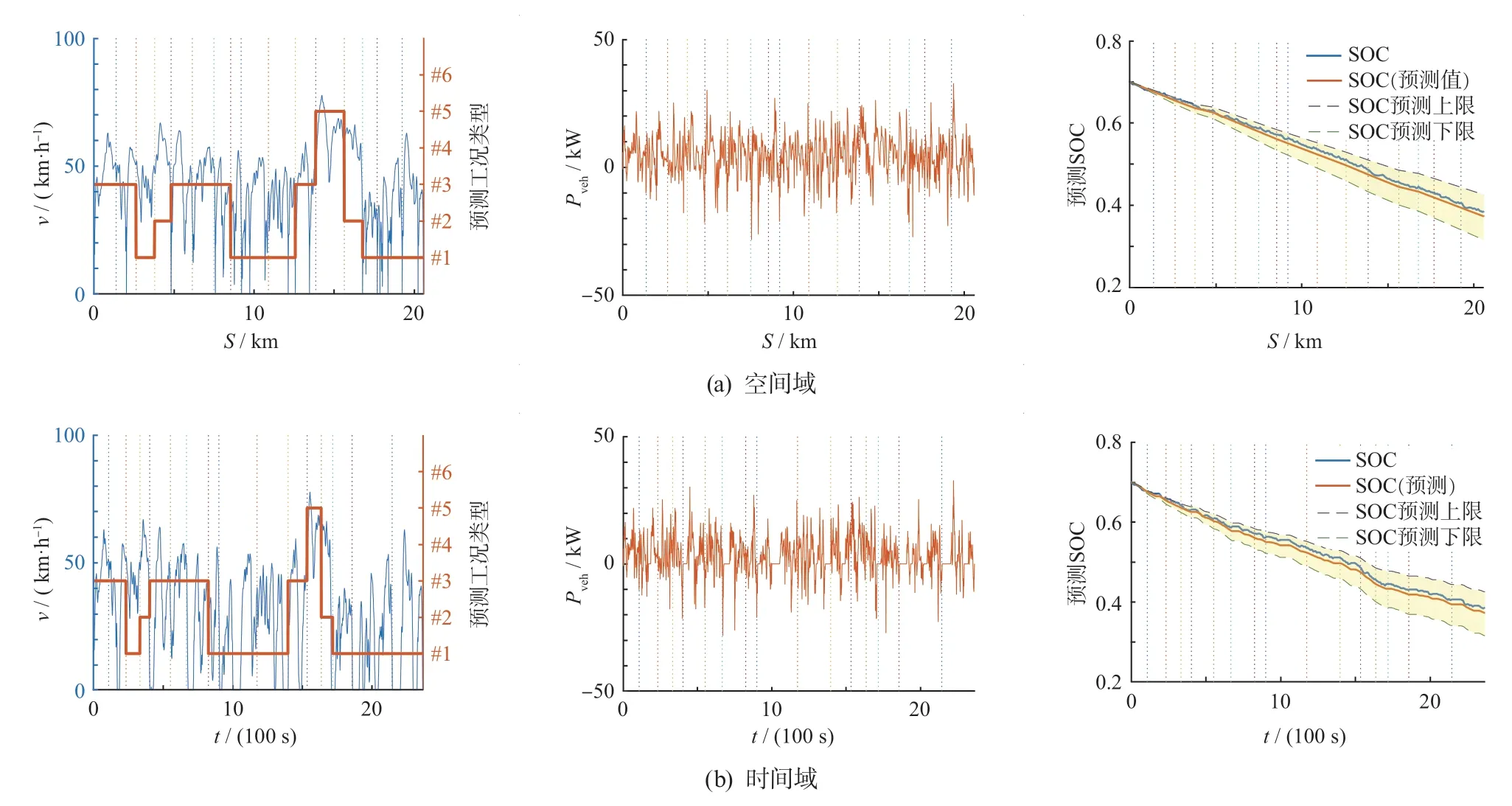
图12 实车上路实验结果
利用SVM 分类器基于百度地图API 提供的实时车流信息对各个路段进行的行驶工况预测,而所得的结果对应图12 第1 列子图的红线。第2 列子图为通过车载OBD 实时测得的整车驱动功率(Pveh)。其对应整车实时能耗,也即第3 列中电池SOC 的下降率。第3列子图包含了SOC 实际值、SOC 预测值以及根据3σ原则[12]求得的SOC 预测1σ上下限。
根据3.1 节给出的计算流程,由图12a 第1 列子图中16 个子路段对应预测工况类型和图11 中各个工况类型对应的单位距离平均能耗,以及公式(1)的电池内阻模型,可得图12a 第3 列子图中由16 段折线构成的SOC 预测曲线。而图12a 第3 列子图的2 条虚线在横轴区间坐标位置分别为预测的期望值μ减去或者加上一个标准差σ,即SOC 预测上下限曲线。由图12a 可知:SOC 实际值全程位于1σ上下限之间,即实际值与预测值的偏差小于1σ。这说明本次实验预测结果较为准确。
而图12b 中时间域的结果是由图12a 中空间域的预测结果换算所得。图12a 中的SOC 实际值曲线相较图12b 不但波动较小,而且整体也更为线性。这说明:在空间域上对电动汽车能耗预测相对时域更容易也更能保证预测精度,进而证明了本文选择空间域进行能耗预测的合理性。
4 结 论
为了预测电动汽车的未来行驶能耗,本研究建立了基于车联网与云计算系统的实车在环仿真系统,并且使用了百度地图提供的实时交通信息。提出的未来行驶能耗预测算法能够在融合实时车流数据与单车数据的基础上,使用机器学习算法根据实时交通数据,在线预测电动汽车未来行驶能耗。同时搭建的实车在环平台基于实车上路实验证明了本文预测算法的准确性与可行性。
但需要指出,本研究的拓扑结构暂不能应对网络失效的情况。所以在后续研究中准备引入一种两层拓扑结构的预测算法来应对此类情况。
