通用域适应综述
2024-01-12何秋妍邓明华
何秋妍 邓明华,2,3
1 (北京大学数学科学学院 北京 100871)
2 (北京大学统计科学中心 北京 100871)
3 (北京大学定量生物学中心 北京 100871)
(heqy@pku.edu.cn)
近年来,机器学习方法在现实中获得了越来越多的应用,这些方法的成功是基于模型在大量有标签数据上的训练. 现如今,数据获取手段更加多样、方式更加快捷,但这些数据通常不具有研究人员所需要的标签信息,例如相机、摄像头等设备可以提供大量图片,但无法直接提供图片中的内容信息,图片的准确标签往往需借助人工手动标记. 简单的图片数据集标注可以通过众包来人工完成,对参与标记的人员没有较高的专业知识要求. 但实际应用中很多数据集,如医疗图片数据,则需要对该领域较为了解的专业人员提供标签信息. 在大数据时代,通过人工进行标注耗时长、成本高,难以满足需求. 值得注意的是,许多待注释的无标签数据集与部分现有已标记数据集在类别上存在一定交集,因此每次单独给无标签数据集寻求人工等方式的注释则显得低效,且对已有信息利用率低. 因此,在假设已有标签数据集的标签集合与待标注数据集的标签集合交集非空时,若将已有标签数据集上的标签内容自动迁移到待标记数据集上,则可以更高效地满足数据使用者的需求. 而这一目标,则与机器学习的目的不谋而合.本文将围绕解决前述问题的通用域适应(universal domain adaptation, UniDA)方法展开问题描述、方法分析、实验对比、应用研究和前景探讨.
1 背 景
传统的机器学习方法在训练数据上学习模型,以使得模型在测试数据上表现最好,即在某一目标函数衡量下损失最少. 但传统的机器学习方法假设训练样本和测试样本来自于同一分布. 而在实际应用中,数据集往往在不同时间、由不同方式收集起来,同分布的假设很难满足. 为解决训练数据和测试数据分布存在差异的问题,域适应(domain adaptation,DA)问题被提出并获得了广泛的关注.
简言之,给定特征分布存在差异、标签集合交集非空的2 域数据,域适应方法要在富有标签的源域(source domain)上学习模型,并克服域间差异,将源域上的标签信息迁移到标签稀缺的目标域(target domain)上,使得模型在目标域上的预测尽可能准确.域适应本质上是一种特殊的迁移学习,二者之间的区别在于,迁移学习研究的问题中除了存在源域和目标域的差异,也可能存在源任务和目标任务的差异,而域适应中不同域上的任务相同[1-2].
在域适应问题中,不同的域有着不同的边际分布,导致了域间差异(domain gap,domain shift 或 domain bias)的存在;此外,不同域的标签空间往往也不同,即存在类别差异(category gap 或 category shift). 传统的域适应假设源域和目标域的标签空间相同,而仅考虑不同域上特征与标签联合分布的差异,这种情形又被称为闭集域适应(closed set domain adaptation,CDA). 然而,给定目标域,找到与目标域有着相同标签空间的源域在现实中很难实现. 为放宽关于源域和目标域标签空间相同的约束,部分域适应(partial domain adaptation, PDA)[3-4]和开集域适应(open set domain adaptation, ODA)[5-6]被相继提出. 部分域适应假设源域的标签集合包含目标域的标签集合,模型在目标域上进行预测时,需要避免目标域样本被划分到源域私有类中. 这种情形下,源域被视为包含众多类别的更为一般的域,而目标域仅包含其中一些类别. 与此相对的开集域适应最早被Busto 等人[5]提出,其考虑源域和目标域标签集合交集非空,且各自具有私有类的情形;现如今更为广泛应用的开集域适应定义则是参照Saito 等人[6]的定义,考虑目标域标签集合包含源域标签集合的情形. 相较于部分域适应中目标域标签均属于已知的源域标签,开集域适应中目标域存在相对于源域而言未知的类别,这就要求模型既要给属于源域类别的样本进行准确注释,还要找出属于目标域私有类的样本. 虽然部分域适应和开集域适应均对闭集域适应进行了拓展,考虑了源域或目标域各自存在私有类的情形,但在实际应用中,关于源域和目标域标签集合相对关系的先验信息往往是缺乏的,因此,通用域适应[7]仅假设源域和目标域标签集交集非空,而不对2 域标签集合做更多约束,如图1 所示. 作为更为一般的情形,通用域适应方法首先需要寻找源域和目标域的共有类. 在测试时,模型需要准确预测目标域中属于共有类的样本,并在目标域私有类存在的情况下准确判别出目标域私有类样本.
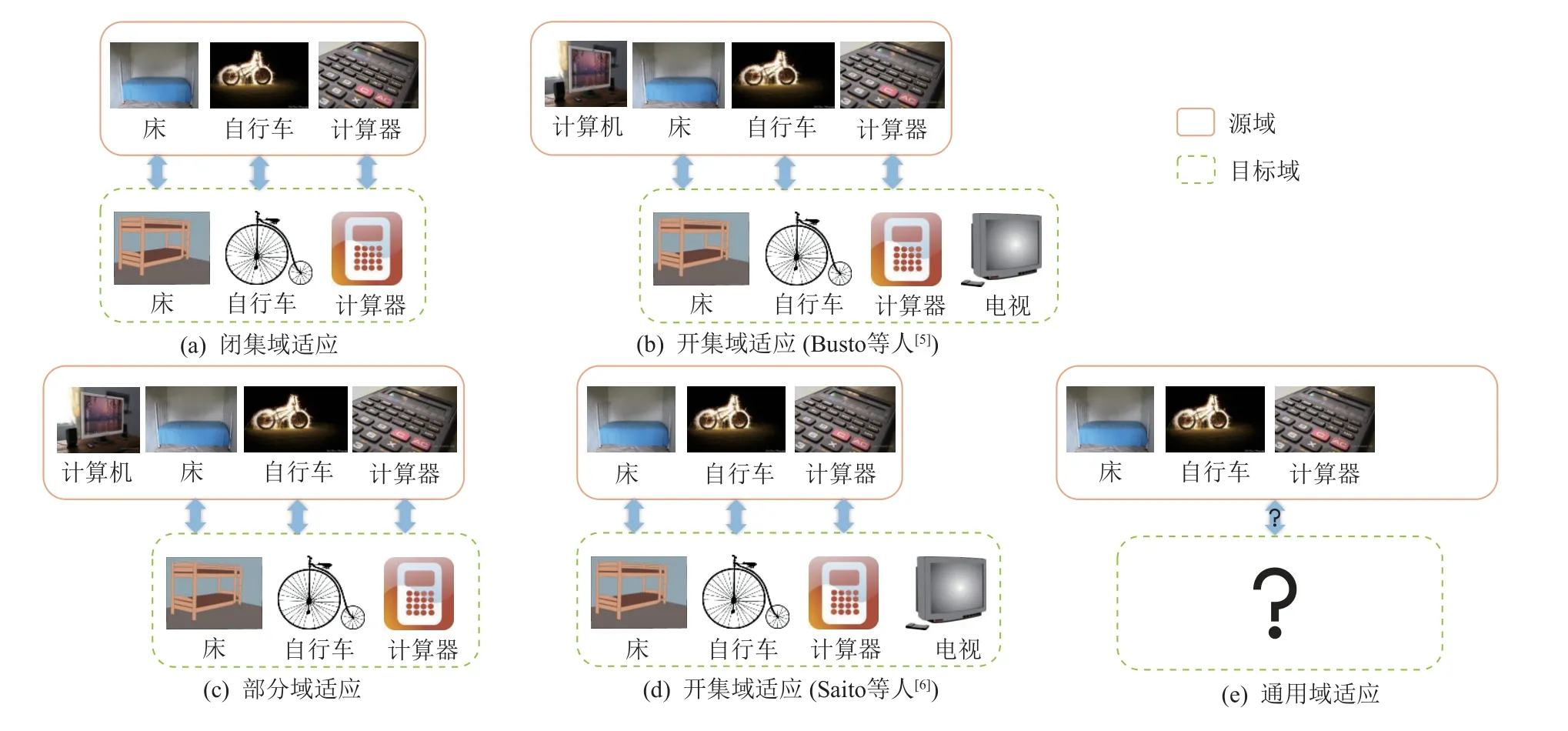
Fig.1 Classification of domain adaptation by the relationship of label sets of source domain and target domain图1 按源域和目标域标签集合相对关系对域适应问题进行分类
2 符号与问题重述
2.1 符 号
记特征空间为 X,标签空间为 Y,特征x和标签y的联合概率密度和分布函数分别记为p(x,y)和P(x,y),我们参照Farahani 等人[8]的定义,定义域(domain)为D={X,Y,p(x,y)}. 本文所考虑的通用域适应以分类为任务,即要利用源域特征数据和标签,学习一个从特征空间到标签空间的映射函数h:X →Y,使得其在目标域上的期望损失最小,这种映射函数又被称为假设函数(hypothesis function).
2.2 问题重述
具体地,记源域和目标域为 Ds和 Dt,其标签集合为Ls和Lt,2 域特征与标签的联合分布函数分别为Ps(x,y)和Pt(x,y),衡量预测标签与真实标签差距的损失函数为ℓ:X×Y →R. 通用域适应假设Ls∩Lt≠∅,而Ps(x,y)与Pt(x,y)不一定相同,通常我们称源域标签为已知类,目标域私有类为未知类. 可得模型在目标域上的期望损失为
同时,模型的训练需借助于源域标签信息的监督,即假设函数需要使得源域上的预测误差尽可能小:
由式(1)和式(2)可见,想要模型在目标域上取得好的预测效果,首先需要对目标域样本进行初步判断,尽可能准确判断样本是否属于2 域共有类. 然后,在源域和目标域的共有类上对齐2 域的分布,以利用源域标签对属于共有类的目标域样本进行准确预测. 当目标域私有类存在,且训练中无法获得具体标签时,损失函数通常只衡量模型是否将目标域私有类样本正确标记为未知类,由式(1)可见,全部将样本划分为未知类或无法判别出未知类都会导致模型泛化效果很差.
3 研究现状
3.1 问题设置
就问题框架而言,传统的通用域适应一般假设仅有一个带标签的源域和一个未知标签集合的目标域[7],在实际应用中,这一假设仍有一定局限性. 考虑到现实情形中数据隐私受到保护,且数据获取受渠道和成本限制,良好标注的数据集在进行训练时往往无法获得,但用其训练得到的模型相对易得,故USFDA[9]和 UMAD[10]将通用域适应推广到无源域数据(source-free)的情形,即在目标域数据上训练时,仅可获得源域上预训练得到的模型,而无法获取源域数据.UB2DA[11]则进一步放宽限制,考虑仅可获得源域模型接口的情形,又称黑箱(black-box)情形,在此情形下,训练模型时无法获取源域模型的参数作为参考,仅可获得源域模型在目标域数据上的预测结果,即仅有该预测结果包含源域信息,而这一结果又会受未知的域间偏差影响,因而存在噪声,进一步增加了问题的难度.
从源域入手放宽通用域适应原设置,除了数据和模型的可及性,源域个数也可由1 个推广至多个[12].因为各个源域与目标域的共有类并不一致,同时利用多个源域可以尽可能给目标域上更多类标记,所以多源域相对于单源域假设,在现实中更有实际意义. 此外,即使是同一个类别,包含该类的各源域所能提供的有效信息量也有差异,多源域同时训练即为整合多方信息,可以增加预测结果的可靠性. 但多源域通用域适应相对于单源域情形,除了需要解决多个源域与目标域之间的偏差问题,还需注意不同源域之间也会存在域偏差和类别偏差. 因此相对于单源域问题,多源域设置下模型在学习特征表示时,需消除各源域之间以及各源域与目标域间的域间偏差,提取各源域和目标域公共类中样本的特征来标记目标域样本,并对无法注释的目标域样本标记为未知类.
除了从源域个数着眼,也可以从源域标签入手.通用域适应问题一般假设获得的源域标签即为真实标签,但即使是人工标注的数据集,也会受诸多因素影响因而存在误差,因而源域的标签极有可能是有噪声的. 因而Yu 等人[13]考虑了源域标签有一部分错误的情形,在此情形下,方法需在训练过程中找出带噪声的源域标签,以避免使用错误标签训练给模型带来负面影响,因此方法不仅要有判断目标域样本是否属于未知类的能力,还要有判断源域样本的标签是否正确的能力.
从目标域入手考虑通用域适应问题,当目标域私有类存在,且缺乏关于目标域数据的任何标签时,通用域适应方法只能判断哪些样本为目标域私有,并标记它们为未知类样本,而无法给出具体的类别标注,有的甚至无法区分目标域不同的私有类以做好目标域内的聚类. 若在现实应用过程中,有条件通过外部查询一小部分目标域样本标签,如何挑选样本用以外部标记,使得获得标签的这些目标域样本再次参与到模型的训练中后,让模型获得最佳的预测表现,也值得进一步研究,而这一思想即为主动学习(active learning). ADCL[14]便将主动学习框架应用到通用域适应问题中,挑选预测最不确定且特征最为多样的一部分样本,在获取外部注释后,用这些标记好的数据参与训练. 若目标域私有类存在,为使模型预测能力提升,我们希望被挑选的目标域样本均为目标域私有,且类别尽可能包含所有私有类,使得这些样本从外部获取标签后参与训练,可以让其余私有类样本获得准确的类别,而非笼统的未知类标记.从数据本身入手,一般通用域适应问题中的分类任务都潜在假设各类之间相互独立,但在应用中并非如此. 相反,类别之间的相对关系有时也具有实际意义,例如通过人脸图片判定年龄,此时标签即为年龄,而年龄有着天然的递增顺序,若模型将20 岁的人脸预测成40 岁或预测成30 岁,虽然均为预测错误的情形,但体现的模型错误程度却不一样,预测成40 岁显然比预测成30 岁更不合理. 因此,Chidlovskii等人[15]便考虑通用域适应在有序回归(ordinal regression, OR)中的应用,即分类任务中各类不相互独立,而是存在着序关系. 针对此类数据,Chidlovskii等人[15]假设输入的高维数据实际位于一个低维流形上,在此流形上类别之间保持着序关系,而图片之间的差异是与域偏移无关的单调函数. 由于有序回归中,在低维流形上进行类别标记时一般会利用阈值进行逐步划分以保证序关系,如果直接使用熵(entropy)进行优化容易导致2 域共有类和私有类划分错误,进而导致特征错误对齐. 使用现有通用域适应方法把类别当作相互独立处理,也容易使预测标签相对顺序出错.
3.2 研究方法
通用域适应方法通常假设存在一个低维特征空间,使得来自不同域的同类数据在此低维流形上聚成一簇,而不同类的数据相互疏远. 各方法则需学习从原始特征空间到此低维流形的映射,以及从低维特征空间到标签空间的映射,使得这2 个映射复合后在目标域上的表现最佳. 从网络构架上看,为学习到源域和目标域共同类的特征表示,常用的框架有对抗生成网络、自编码结构;从分类器设置看,有多分类器设置,以及分类器包含目标域未知类的网络构架;从隐空间特征表示的学习过程看,常见的策略有寻找相似样本使得样本局部聚类良好,也有寻找互近邻减少域间差异、促进标签迁移,还有利用对比学习(contrastive learning)加强相似样本对和不相似样本的区分,以及利用熵等统计量划分样本来区别对待,利用数据增广(data augmentation)提高特征学习能力,利用数据混合模拟数据等. 由于通用域适应需同时解决消除域间偏差、划分目标域样本并标记等问题,所以各模型通常综合采用多种策略,如表1和表2 所示,我们将在下文进行详细分析.

Table 1 Strategies and Unknown Classes Detection Ways Used in Adversarial UniDA Methods表1 对抗类通用域适应方法使用的策略及未知类判别方法

Table 2 Strategies and Unknown Classes Detection Ways Used in Non-Adversarial UniDA Methods表2 非对抗类通用域适应方法使用的策略和未知类判别方法
3.2.1 基于对抗生成
通用域适应中的对抗生成方法,把输入数据从高维空间投影到低维特征空间的映射当作生成器,又称特征提取器,与二元分类器即域判别器进行对抗,其目标是学习域不变特征,以使得域判别器无法区分共有类样本来自源域还是目标域. 在此过程中,模型还会利用源域标签监督特征提取器和分类器的训练. 理想情况下,当训练完成时,特征提取器学习到的域不变特征应为源域和目标域共有类样本的公共特征,但由于通用域适应问题下缺少关于各域类别的先验信息,故利用对抗生成思想学习隐层表示时,还需判断各域样本是否属于2 域共有类. 由于在训练中直接判断并选取可能属于共有类的2 域样本参与对抗生成学习,在预测错误时容易因共有类样本被误判为私有类造成信息丢失,故早期对抗生成类方法估计各样本属于2 域共有类的可能性,并依此定义权重以用于对抗生成的判别损失中,使得各域属于共有类样本的权重高于同域中域私有类样本权重的期望,而具体的权重定义则因模型而异,如表3和表4 所示.

Table 3 Adversarial Loss of Adversarial UniDA Methods表3 对抗类通用域适应方法的对抗损失

Table 4 Weights in Adversarial Loss and Unknown Classes Detection Ways of Adversarial UniDA Methods表4 对抗类通用域适应方法对抗损失中的权重及未知类判别方法 ①
此类方法通用的框架如图2 所示,主要由特征提取器G、域判别器D和维数为源域类别数的分类器C组成. 训练中,一般用源域标签通过交叉熵损失进行网络的监督训练( LC),各方法除此之外还会配有自己的优化损失函数(Lother),对抗部分体现在判别损失( LD)上,特征提取器G想让域判别器D的判别误差尽可能大,而域判别器D则与之相反:

Fig.2 The general network structure, adversarial idea and inference method of adversarial methods图2 对抗类方法的一般网络架构、对抗思想与预测方法
其中式(3)中的Lcrs为交叉熵损失,式(4)中的ws(x)和wt(x)分别为源域和目标域样本在域判别损失中的权重. 式(5)的优化可借助于Ganin 等人[31]提出的梯度翻转层(gradient reversal layer, GRL). 通常划分目标域未知类可以借助权重wt(x),例如式(6)中将权重与自定义阈值相比较,或利用自定义的其他统计量.
UAN[7]最早提出通用域适应问题并将对抗生成思想运用其中,除了用于对抗学习的域判别器,UAN[7]还使用了一个非对抗的域判别器来估计样本属于2 域共有类的概率,该概率与分类器预测结果的熵一起构成了样本在判别损失中的权重,并以此权重与给定阈值比较,判别目标域样本是否属于私有类.Uni3DA[23]在划分共有类和目标域私有类时采用了和UAN[7]一样的网络架构与权重定义,但Uni3DA[23]为使得样本远离类边界,对高置信度的样本,极大化其权重与给定阈值的差异,使得属于共有类样本的权重相对于给定阈值更大,反之则更小.CMU[16]则分析了熵、一致性(consistency)及置信度(confidence)3 种衡量预测结果不确定性的指标各自的利弊,并用该3 种指标重新定义了衡量样本预测结果可靠程度的统计量,从而得到各样本在域判别器损失中的权重,使得属于共有类的样本获得较高的权重,而当权重低于给定阈值时,样本类别被视为未知.I-UAN[17]则基于样本属于不同类别概率的差异,定义了PMV(pseudo-margin vector),并在此向量的基础上估计源域各类是2 域共有类的可能性.I-UAN[17]还定义了TPMR(target pseudo-margin register)以在训练中存储和更新PMV,然后用TPMR 定义源域各类样本和目标域各样本在对抗损失中的权重,仍是当权重低于给定阈值时判定样本为目标域私有.UMAN[12]随后将I-UAN[17]推广到多源域情形,使用一个包含所有源域类别的分类器来定义PMV 和TPMR,因源域各样本的权重仅依赖于其所属类的权重,故UMAN[12]不会因源域个数的增加而复杂化. 相较于I-UAN[17],UMAN[12]用pseudo-margin 和TPMR 重新定义了目标域样本的权重,并用pseudo-margin 代替权重作为判定未知类的依据.
DCN[18]为解决部分方法重视2 域类别差异而忽视域间差异,以及源域私有类和公共类区分不佳的问题,除了利用对抗生成结构,还定义虚拟样本及对比模块(contrastive module)、使用CDD (contrastive domain discrepancy)[32],以进一步减少域间差异. 在DCN[18]中,域判别器的输出、分类结果和熵被用于衡量目标域样本的“迁移性”(transferability),迁移性越高则表示其越有可能属于共有类,而高于指定阈值的伪标签则进一步被用于监督训练以及域判别器的优化中.
Zhang 等人[19]在定义对抗训练的权重时,除了考虑域判别器的预测误差,还从拓扑角度考虑样本与其类中心的距离,不依据权重作为判别未知类的直接指标,而是用其划分目标域样本以训练一个二元分类器识别例外点(outlier),即识别未知类样本. 为减少训练带来的信息损失,Zhang 等人[19]还构建了重构网络,与特征提取器形成自编码结构(autoencoder),保证特征提取器学习到足够的特征信息. ADCL[14]则使用域判别器结果和预测概率向量最大分量来定义样本权重,权重除了应用于对抗损失中,还作为训练中划分未知类样本的依据. 此外,ADCL[14]还利用目标域类中心和隐空间梯度范数(gradient embeddings)挑选不确定性和多样性高的目标域样本寻求外部标记,并利用外部获得的标签训练目标域类中心,给目标域可能属于未知类的样本具体的注释.
针对有序数据时,Chidlovskii 等人[15]除了利用对抗生成网络结构将2 域数据投影到一个低维特征空间并学习域不变(domain-invariant)特征,还提出了顺序模型,估计样本属于共有类和私有类的概率,并以此作为域判别器损失中的权重. 不同于传统通用域适应中的分类问题,为解决序关系存在时的标签预测,Chidlovskii 等人[15]借鉴Niu 等人[33]的做法,将顺序回归转换为多个二元分类问题,并用Coral (consistent rank logits)方法[34]确保预测一致性.
如在使用全样本进行对抗生成时不定义权重,则需在学习特征时进一步地约束,使模型尽可能区分目标域里属于共有类和私有类的样本,以避免受到2 域类别差异的影响;或在对抗生成前直接对样本进行筛选,让可能属于2 域共有类的样本参与对抗生成训练. Lifshitz 等人[20]在域判别器的对抗损失中不单独定义权重,而是用域判别器的输出与分类器的最大预测概率得到自定义指标(score),并设置上下2 个动态阈值筛选样本. 随着训练的进行,Lifshitz等人[20]筛选高置信度样本并用其伪标签进行自监督训练以利用目标域信息,同时找出可能属于未知类的样本来降低其预测置信度. 与Lifshitz 等人[20]直接筛选样本不同,HFDN[21]认为源域和目标域数据在同一隐空间的特征差异是由域间差异和类别差异同时引起的,因而选择对特征空间进行分层解耦. HFDN[21]首先将样本在隐空间的特征表示分解成与域有关(domain-relevant)的特征和与类别有关(class-relevant)的特征,再将与域有关的特征进一步分解成域特有(domain-specific)特征和类别偏移(category-shift)特征,然后用对抗生成网络对齐域特有的特征,以避免受到2 域类别差异的影响. 因此,HFDN[21]未在对抗生成中单独定义权重,但在学习类别有关的特征时,通过域判别器作用于类别偏移特征来估计样本属于2域共有类的概率,并依此使得模型在特征学习时更关注共有类样本,从而令学习到的类别有关特征主要为2 域共有类特征,而与域有关的特征则被进一步分解. 与HFDN[21]进行解耦避免对抗生成时错误对齐不同,GATE[22]通过寻找2 域间的互近邻对(mutual nearest neighbors, MNN)和利用随机游走拓展的互近邻对(rwMNN),认为跨域的互近邻对更有可能属于2 域共有类,因而在近邻对上进行对抗学习,对齐2域共有类特征分布. 在近邻对的基础上,GATE[22]还借助于对比学习使得从拓扑上看,样本聚类更好. 不同于单独定义指标识别未知类,GATE[22]使用manifold mixup[35]混合源域样本来模拟未知数据训练分类器,让分类器直接估计样本属于未知类的概率.
3.2.2 基于自编码结构
自编码器通过特征提取器在将数据从高维空间投影到低维特征空间后,再使用重构网络将其重新映射到原高维空间,希望在经过降维即编码过程(encoder)和重构即解码过程(decoder)后样本的特征表示尽可能不变,如图3 所示. 这一做法可以在无标签监督的情况下,尽可能地使特征提取网络学习到数据的关键特征. Zhang 等人[19]使用自编码结构参与训练,以完善特征的学习,避免神经网络随着训练进行发生信息遗忘的问题. HFDN[21]则是在分解域有关特征时添加重构网络,确保域有关特征分解成域特有特征和类别偏移特征后可以由二者重构出来,使得特征空间的解耦成立.
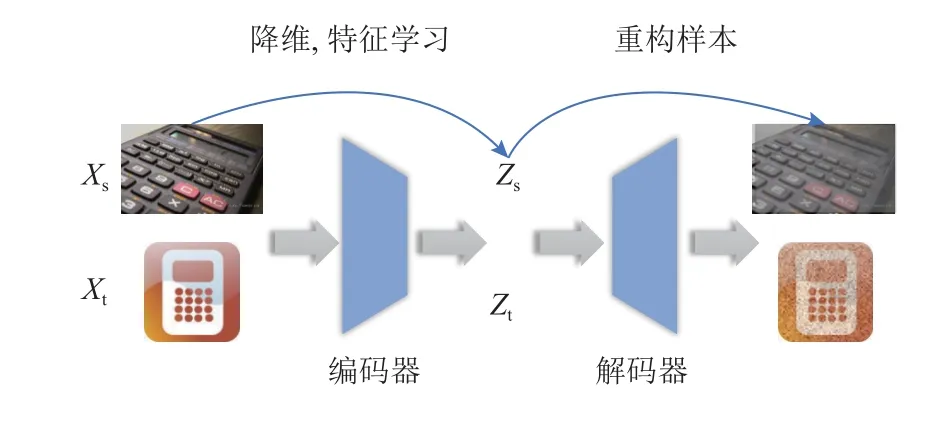
Fig.3 The network structure of autoencoder图3 自编码网络结构
除了直接对数据使用自编码结构,也可以利用变分自编码(variational autoencoder,VAE)估计分布的参数,实现对数据的特征学习与重构.USFDA[9]为使模型在目标域上适应时可以识别未知类,通过对源域原始图片数据(也称正样本)进行随机抽取和拼接得到负样本,使得模型具有预测未知类的能力. 模型在源域上进行预训练时,假设源域各类数据在低维特征空间服从高斯分布,并从该先验分布随机抽样,利用变分自编码结构进行重构,使得最终学习到的特征提取器偏向于正样本,避免测试时所有样本被预测成未知类别.
3.2.3 基于隐空间特征学习
当不借助特定网络结构减少域间差异时,通用域适应模型需利用多种策略使得目标域可以良好聚类,即特征空间中源域和目标域同类样本相互混合,异类样本彼此分离. 常见的方法有对比学习以极小化类内(intra-class)差异、极大化类间(inter-class)差异;基于自训练(self-training)思想,通过在类中心或指定样本范围内寻找近邻,确保相似样本在特征空间中相近;寻找互近邻对以寻找2 域共有类. 在判定目标域私有类时,依据源域已知类与目标域私有类在统计上的差异,不同模型通常定义不同统计量作为判别指标,例如预测结果的熵,或增加分类器输出维度,使其直接估计样本属于未知类的概率.
在对使用这些策略的通用域适应方法进行梳理和分析之前,我们先简要地介绍一下对比学习的主要思想,如图4 所示. 对隐空间中任一样本zi,记与其构成正样本对的样本集合为Pos(zi),与之构成负样本对的样本集合为Neg(zi). 正样本对中的2 个样本应属于相同的类别或为同一样本不同的增广形式,负样本对中的2 个样本应属异类或为不同样本的增广形式. 图片的增广一般指旋转、裁剪等一系列不改变原始数据类别的变换,在对比学习中用以加强类别特征的学习.
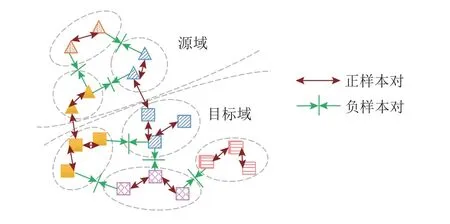
Fig.4 The idea diagram of contrastive learning图4 对比学习概念图
对比学习的损失一般可以写成:
其中 τ为温度参数(temperature parameter),sim(zi,uj)一般使用cosine 相似度,即为 L2范数.wij为非负权重,可设为1.由于qij关于负样本对的相似度递减,而关于正样本的相似度递增,极小化对比学习损失可以极大化负样本对的特征差异以及正样本对的特征相似性,如图4 所示. 随着后文分析,我们可以看到各个模型如何使用对比学习思想,下面我们开始梳理各方法对策略的使用.
USFDA[9]在源域上预训练模型时模拟了负样本,即不属于源域已知类的样本,并定义了负样本对应的标签,构建了维度为源域类别数与负样本类别数之和的分类器,并依此得到样本属于源域各类以及各负样本类别的概率,基于这2 种概率的熵,USFDA[9]在训练中对目标域样本进行私有类和共有类的划分.与对抗类方法相似的是,USFDA[9]利用分类器预测最大概率,定义了样本与源域类别的相似度指标(source similarity metric, SSM),并以此作为权重用于样本的预测概率与熵的优化损失中.
DANCE[24]认为已有方法过度侧重于对齐源域和目标域的特征分布,而忽略了目标域自身的数据特征,故DANCE[24]首先通过邻域聚类,让目标域样本寻找与其最相似的源域类中心或目标域内最近邻,来保证目标域聚类良好,如图5 所示. 其次,DANCE[24]假设属于未知类的目标域样本通过源域分类器得到的预测结果不确定性较高,而熵是表征预测不确定性的统计量,故DANCE[24]利用熵进行样本划分,认为在训练过程中熵高于指定阈值一定范围的样本更有可能是未知类样本,反之,则更有可能是2 域共有类样本,因此在样本划分后,DANCE[24]进一步增加高于给定阈值的样本的熵,降低低于阈值的样本的熵,并以熵作为最终划分未知类的依据. 图6 使用ResNet50 网络作为特征提取器,输出维度为源域类别数的单层线性网络作为分类器,在OfficeHome[36]数据集上,参照DANCE[24]在2 域均有私有类时训练数据的划分,以Art 数据集为源域,以Real World 数据集为目标域,利用源域标签和交叉熵损失训练20次(整个数据集参与1 遍训练作为1 次),得到的目标域未知类样本和已知类样本熵的直方图,以及DANCE[24]所采用的熵划分与训练法的示意图.
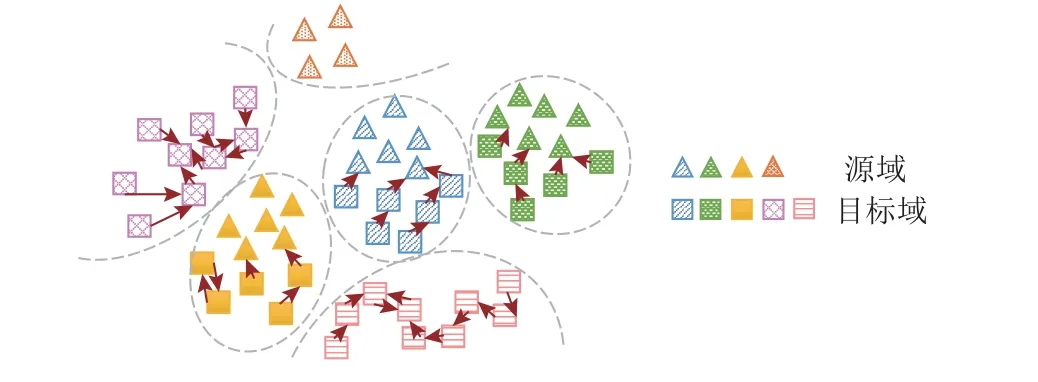
Fig.5 Neighborhood clustering: Find the most similar sample or centroid to approach图5 寻找最相似样本或类中心来靠近的邻域聚类
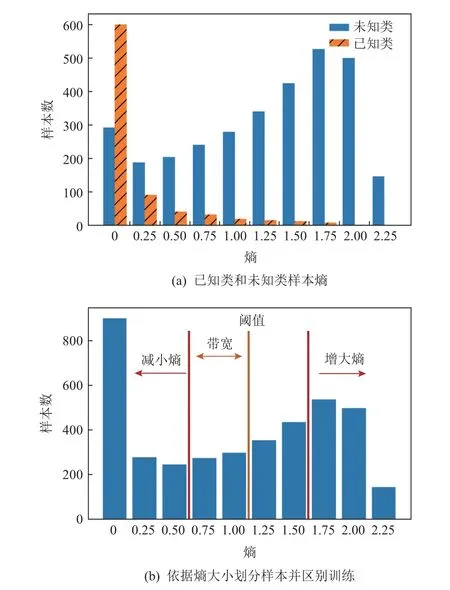
Fig.6 Separating target domain samples by entropy for training图6 依据熵划分目标域样本以训练
Cho[25]与Zhu 等人[26]均对DANCE[24]做出了改进. Cho[25]在DANCE[24]基础上对目标域数据使用了对比学习策略,让同一样本不同形式增广得到的特征表示相似,而不同样本则尽可能被区分开来. Zhu等人[26]则通过不同程度的数据增广保证预测结果的一致性. 此外,为了改善DANCE[24]邻域搜寻范围过大的问题,Zhu 等人[26]依据熵将目标域样本划分为属于共有类、属于未知类和不确定3 种,并对每种样本设定邻域搜寻范围,使得邻域搜索更自适应,同时减少了计算复杂度. Yu 等人[13]认为不同网络有不同的学习角度和能力,所以不同的网络对标签错误的源域样本和属于未知类的样本往往给出不同的预测结果,因此Yu 等人[13]基于无监督域适应问题中2 分类器训练框架[37],除参照DANCE[24]利用预测熵划分可能属于未知类和共有类的样本的思想,还同时利用不同分类器预测差异划分目标域样本并筛选标签可靠的源域样本. 预测时,Yu 等人[13]仅使用熵作为判定指标,认为熵过高的样本预测不确定性仍较高,应属于未知类. 由前所述,通用域适应方法需要划分出目标域中属于源域类别和不属于源域类别的样本,并赋予属于源域类别的样本以标签,故UB2DA[11]把通用域适应任务分解为in-class discrimination 和outclass detection,其借鉴DANCE[24]用熵划分样本、判断未知类,并用熵进行自训练. 在此基础上,UB2DA[11]假设样本预测结果在其邻域间应保持一致性,故定义可学习的目标域类中心来发掘域内样本的预测状况. 此外,UB2DA[11]还使用知识蒸馏(knowledge distillation),基于源域预训练模型在目标域上的预测结果,在目标域上优化特征网络.
在进行聚类或分类任务时,实现标签的转移离不开这一假设:同类样本具有相似的特征表示并在某低维流形上距离相近,而异类样本则特征相异且距离较远. 因此,挖掘样本在隐空间的局部信息、寻找互近邻对,往往有助于模型纠正学习错误,由前述可见,这一思想已为多数域适应方法所采用. 但由于域偏差的存在,2 个不同域的同类样本,被同一映射投影到共同的特征空间后,其距离也可能大于同域中异类样本的距离. 因此,学习特征表示和消除域间差异需同时进行. 但在训练伊始,如何在特征空间中寻求“突破口”以拉近不同域同类样本的距离,并仍保持模型区分不同类的能力,则极具挑战. 此外,虽然从样本角度进行共有类的对齐更为细致,但数据集体量较大时,若在全数据集范围内为每个目标域样本搜寻最相似的样本,如DANCE[24],则会使运行内存和时间显著增加. 故有方法转而使用类中心,如UB2DA[11],但在流形上简单使用均值表示类中心也存在着表示不准确的问题,为此,DCC[27]尝试在训练中确定目标域类别个数并优化类中心. 其首先用均值定义源域类中心,并用k-均值聚类获取目标域类中心初值,通过在类中心间跨域寻找互近邻来寻找2域共有类,再定义domain consensus score,利用样本层面的一致性信息判断目标域个数. 在识别属于共有类样本后,DCC 也引入CDD (contrastive domain discrepancy)[32]来对齐共有类样本,使得聚类更紧凑,并添加正则项优化目标域类中心表示. 在预测时,DCC 直接使用目标域上类中心给样本赋予标签,不仅可以划分出共有类样本,还可以区分目标域不同的私有类.MATHS[28]则从样本角度出发消除域间差异,其通过在源域和目标域间以及各域域内构建样本间邻接矩阵进行对比学习,拉近相似的样本对和分离不相似的样本对,如图7 所示. 在预训练后,初步消除域间差异,将通用域适应问题转为分布外检测(out-ofdistribution detection,OOD)问题,然后用高斯分布拟合最大预测概率的分布,并用Hartigan’s dip test 检验[38]是否存在未知类. 随后,MATHS[28]分别构建源域类中心和目标域私有类类中心(若判断私有类存在),使样本靠近与其相似的类中心,以增强聚类效果. 最后在统计检测结果显著认为目标域私有类存在时,用最大预测概率和3- σ原则设定阈值标记未知类.

Fig.7 Find MNN to reduce domain bias and transfer labels图7 寻找互近邻消除域间差异进行标记
由于多数通用域适应方法依赖自行设定的阈值区分未知类,但在对目标域数据没有先验信息的情况下,人工设定阈值容易受主观因素影响,准确性低.故近年来许多方法致力于利用分类器或类中心直接估计样本属于未知类的概率. 前述GATE[22]定义了Ks+1维的分类器,用Ks+1维表示属于未知类概率,其中Ks为源域类别个数.OVANet[29]则除定义一个Ks维分类器外,针对每个源域类别,定义了一个二元分类器以估计样本属于该类和不属于该类的概率. 推断时则依据分类器预测的类别,查询二元分类器判断样本属于该类的概率,若概率低于0.5 则被视为不属于该类,即应为未知类.OVANet[29]在训练中注意区分各类和其最相似的异类,通过是否接受属于该类的二元判断解决阈值主观难以设置的问题.UMAD[10]则定义2 个分类器,利用2 个分类器预测结果的一致性定义划分指标iscore,并用mixup[39]进行样本混合,把混合样本的平均iscore 作为阈值. 对得到的可能属于共有类的样本,UMAD[10]定义局部互信息使得目标域中属于共有类样本与源域中对应类样本更为相似,减少域偏差.
除从统计角度检验未知类存在,也可以从构建统计模型入手估计样本预测的不确定性以区分未知类.TNT[30]引入EDL(evidential deep learning)[40]构建multinomial-Dirichlet 分层模型,估计样本属于各类的概率及预测的不确定性,并由模型定义total evidence score 作为判定未知类的统计量,利用3- σ原则确定阈值. 与GATE[22]和MATHS[28]类似,TNT[30]也通过在域间和域内寻找互近邻对并应用对比学习的方式,从样本层面对齐2 域特征分布,使聚类更为紧凑.
4 实验分析
4.1 实验设置
1)数据集. 我们选取在域适应领域广泛使用的3个图片数据集OfficeHome[36], VisDA[41],Office[42]对提供源代码的典型方法进行对比. 其中Office[42]包含3个数据子集(amazon,dslr,webcam),OfficeHome[36]包含4 个数据子集(Art,Clipart,Product,Real World),我们用数据集首字母作为简写,例如以P2R 表示源域为Product,目标域为Real World 的实验. 此外,我们把VisDA[41]中包含虚拟图片的train 数据集作为源域,包含真实图片的validation 数据集作为目标域.
我们参照OVANet[29],将数据集的标签集合划分成2 域共有部分(Ls∩Lt),源域私有部分(Ls-Lt)和目标域私有部分(Lt-Ls)并在实验结果表中以Ls∩Lt/Ls-Lt/Lt-Ls形式展现. 简记Ls=Lt为CDA 情形,Lt⊂Ls为PDA 情形,Ls⊂Lt为ODA 情形,Ls∩Lt≠∅,Ls-Lt≠∅,Lt-Ls≠∅为 OPDA(open partial domain adaptation)情形.
2)评价指标. 对于CDA 和PDA 情形,我们采用各类准确度的均值(average accuracy)进行衡量. 对于目标域存在未知类的ODA 和OPDA 情形,为同时衡量共有类预测平均准确度以及未知类划分准确度,我们参照CMU[16],使用共有类平均准确度(acccom)和未知类划分准确度(accun)的调和平均(H-score):
其中
表示共有类各类准确度均值,kcom为共有类个数.
3)对比方法. 目前提供源代码的方法有UAN[7]、CMU[16]、I-UAN[17]、UMAN[12]、Uni3DA[23]、USFDA[9]、DANCE[24]、DCC[27]、OVANet[29]、文献[13]和UB2DA[11]. 因为大多数方法都可解决传统单源域情形下的通用域适应问题,故本文主要针对单源域且源域数据训练时可获得的问题设置开展实验. UMAN[12]作为IUAN[17]优化后针对多源域情形的方法,不参与单源域的比较. 而Uni3DA[23]应用于3 维点云数据,故不参与图片数据上的比较. 虽然Yu 等人[13]针对源域标签有噪声情形进行建模,但该方法也可应用于源域标签无噪声情形,我们用clean 表示无噪声情形. 对于各类方法,我们采用原作者提供的参数进行实验,实验过程中发现UAN[7],CMU[16],I-UAN[17]使用原参数结果较差,调整参数后获得相对更好的结果,故默认汇报的是使用新参数后的结果. 为避免使用目标域标签信息以选取最好结果,各方法均汇报训练结束后的测试结果. 具体结果参见表5~17.

Table 5 Average Accuracy of Each Method over OfficeHome and VisDA Under CDA表5 CDA 情形下各方法在OfficeHome 和VisDA 上的平均准确度 %
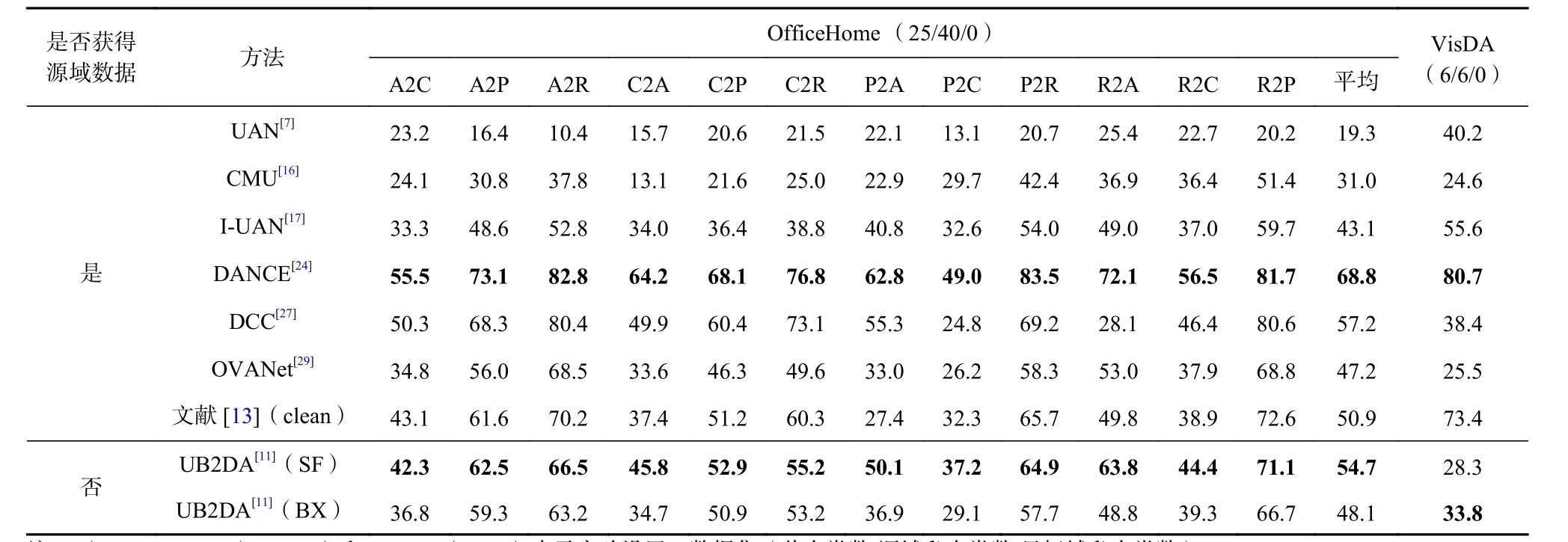
Table 6 Average Accuracy of Each Method over OfficeHome and VisDA Under PDA表6 PDA 情形下各方法在OfficeHome 和VisDA 上的平均准确度 %

Table 7 Average Accuracy of Each Method over Office Under CDA and PDA表7 CDA 和PDA 情形下各方法在Office 上的平均准确度 %

Table 8 Average Accuracy of Each Method over OfficeHome and VisDA Under ODA表8 ODA 情形下各方法在OfficeHome 和VisDA 上的平均准确度 %
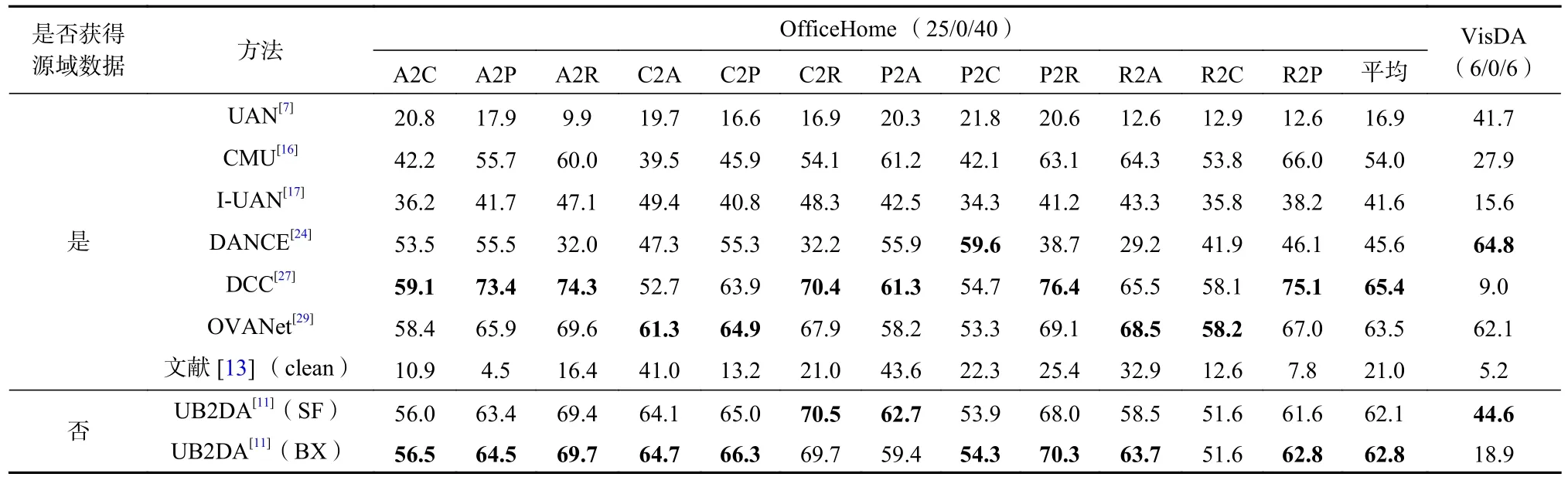
Table 9 H - score of Each Method over OfficeHome and VisDA Under ODA表9 ODA 情形下各方法在OfficeHome 和VisDA 上的 H - score %
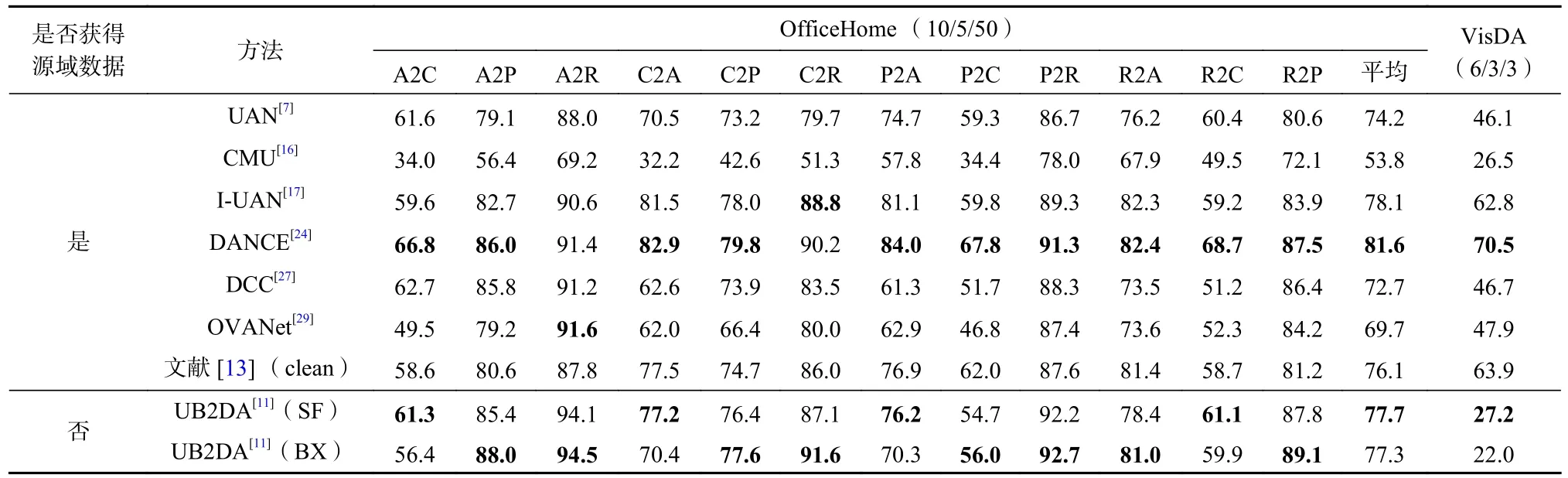
Table 10 Average Accuracy of Each Method over OfficeHome and VisDA Under OPDA表10 OPDA 情形下各方法在OfficeHome 和VisDA 上的平均准确度 %

Table 11 H - score of Each Method over OfficeHome and VisDA Under OPDA表11 OPDA 情形下各方法在OfficeHome 和VisDA 上的 H - score %

Table 12 Average Accuracy of Each Method over Office Under ODA and OPDA表12 ODA 和OPDA 情形下各方法在Office 上的平均准确度 %
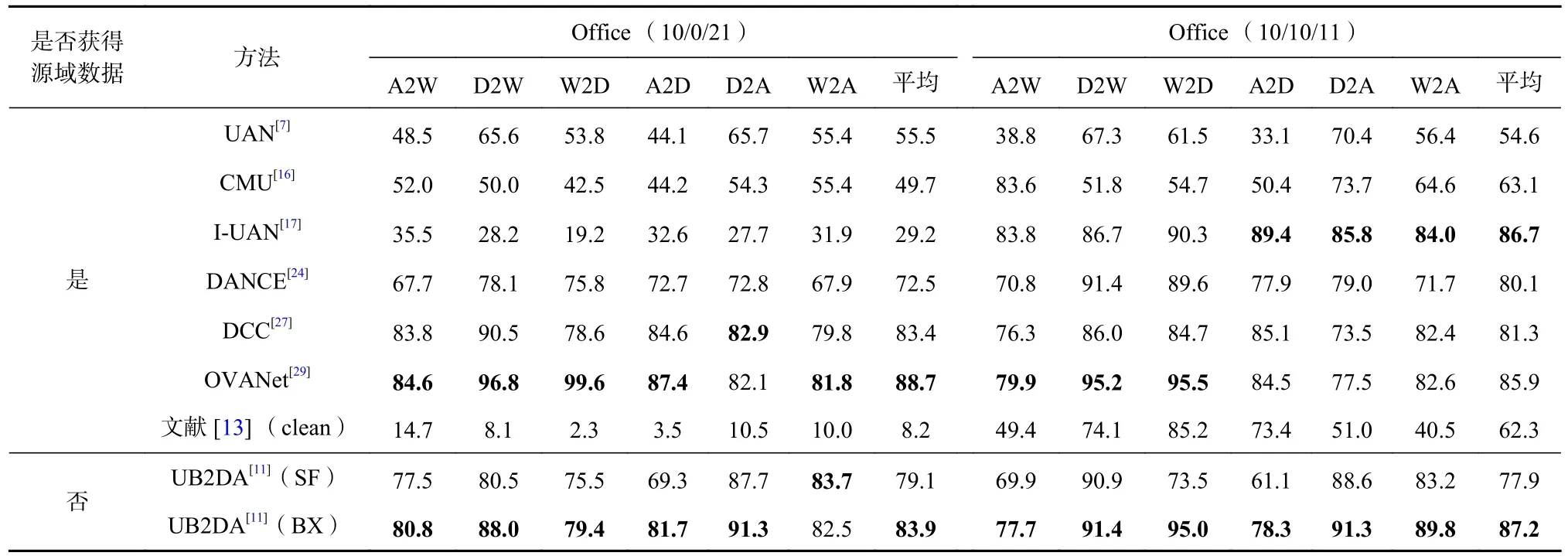
表13 ODA 和OPDA 情形下各方法在Office 上的 H - score %Table 13 H - score of Each Method over Office Under ODA and OPDA

Table 14 Performance of Reference[13] Given Different Noise Settings Where Source is Art and Target is Clipart Under OPDA表14 源域为Art、目标域为Clipart 的OPDA 情形中文献[13]在不同噪声设置下的表现
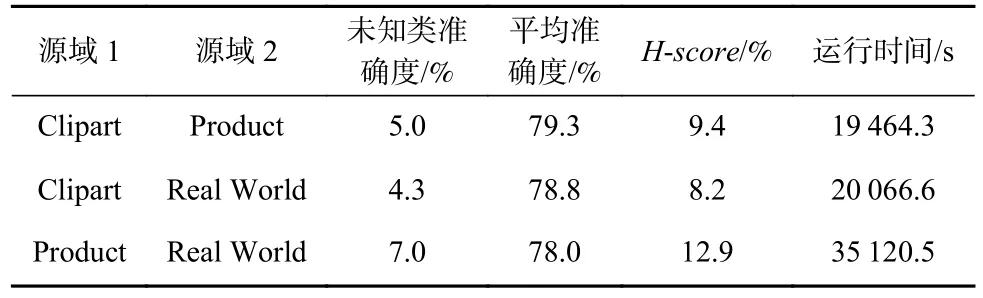
Table 15 UMAN Performance Under OPDA Given Two Source Domains Where Target Domain is Art表15 目标域为Art 的双源域OPDA 情形下UMAN 的表现
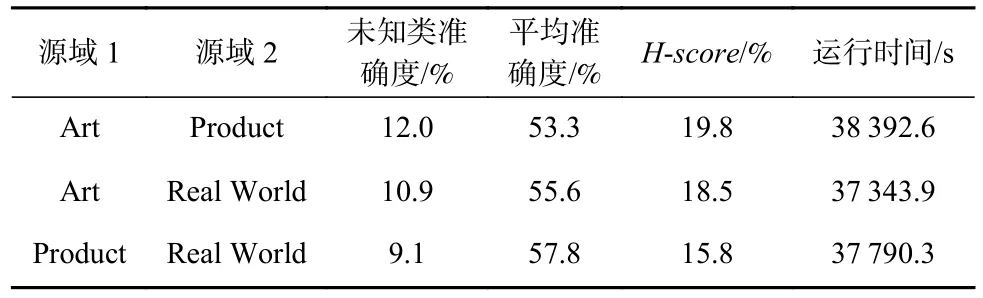
Table 16 UMAN Performance Under OPDA Given Two Source Domains Where Target Domain is Clipart表16 目标域为Clipart 的双源域OPDA 下UMAN 的表现
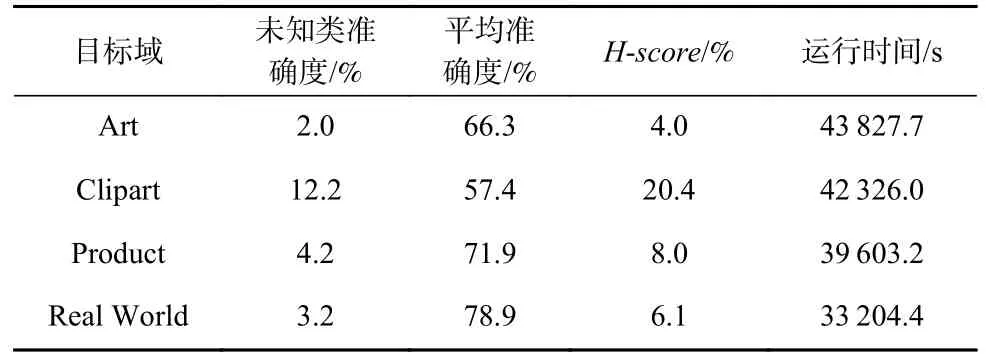
Table 17 UMAN Performance Under OPDA Given Three Source Domains表17 3 源域OPDA 情形下UMAN 的表现
4.2 单源域方法结果
针对单源域的通用域适应问题的开源方法有UAN[7]、CMU[16]、I-UAN[17]、DANCE[24]、DCC[27]、OVANet[29]和文献[13],其中UAN[7],CMU[16],I-UAN[17]均为典型的对抗生成类方法,而文献[13]的方法为对齐源域和目标域,训练过程中也存在将分类器当作判别器与特征提取器对抗的步骤,属于借鉴了对抗思想. 而DANCE[24],DCC[27],OVANet[29]都未涉及对抗生成思想.
对于CDA 和PDA 情形,由表5~7 可见,在Office[42],>OfficeHome[36],VisDA[41]数据集上,对抗生成类方法表现普遍差于非对抗生成类方法. 值得注意的是,虽然文献[13](无噪声版本)既借鉴了DANCE[24]依据熵划分样本的方法,又参考了对抗的思想对齐2 域,但在源域标签无噪声时,未明显优于DANCE[29],如表5和表6 所示.OfficeHome[36],VisDA[41]数据集上,对抗生成类方法表现普遍差于非对抗生成类方法. 值得注意的是,虽然文献[13](无噪声版本)既借鉴了DANCE[24]依据熵划分样本的方法,又参考了对抗的思想对齐2 域,但在源域标签无噪声时,未明显优于DANCE[29],如表5和表6 所示.
在ODA 和OPDA 情形下,对抗类方法与非对抗类方法准确度差距减小,如表8~13 所示,但总体上对抗类方法准确度仍差于非对抗类方法. 但从H-score上看,如表8、表10 和表13 所示,非对抗类方法明显优于对抗类方法,说明对抗类方法在目标域存在新类时判别能力较低. 而非对抗类方法中,DANCE[24]也存在着未知类判别准确度低的问题,使得其虽然在ODA 和OPDA 下拥有较高的平均准确度,但H-score却明显低于DCC[27]和OVANet[29]. 而文献[13]也呈现了类似DANCE[24]的高准确度、低H-score的表现.
结合训练过程看,对抗类方法在训练初期,各类预测准确度通常极低,这是因为特征提取器还未较好地学习到数据的低维表示;随着源域标签信息在训练中起到监督作用,特征提取器逐渐能够学习到各类内在的特征,达到同类相聚、异类相斥的目标,预测准确度也随之上升. 但此类方法中,特征提取器还需与域判别器对抗. 在CDA 和PDA 情形下,即Lt⊆Ls时,特征提取器为使域判别器区分不出2 域数据,会混淆不同类数据,尤其是当类别个数较多时,类边界不清晰会导致各类预测准确度都较低. 而在未知类存在时,目标域上未知类样本相对于已知类样本应更能代表目标域自身特性,即更能被判别出所在域,若特征提取器在低维特征空间拉近了未知类样本与源域已知类样本的距离,则不用过多地混淆已知类样本,也可以达到迷惑域判别器的目的,因此,即使此时预测准确度尚可,但未知类的判别准确度很低.
DANCE[24]依据熵划分样本,并在训练中强化高置信度样本的熵,即使得极有可能属于未知类的样本的熵更低,同时使大概率属于已知类的样本预测结果更确定、熵更小. 文献[13]除了借鉴DANCE[24]、用熵划分样本的思想,还利用了2 个分类器预测的差异对目标域样本进行划分并区别训练. 但有新类存在时,DANCE[24]与文献[13]在训练中均出现了初期未知类划分准确度高、已知类准确度低,随着训练进行,未知类样本判别准确度大幅度下降、已知类预测准确度有所上升,但H-score总体下降的问题. 这是由于在训练伊始,特征提取器还未学到有效的特征信息,因此预测的不确定性高,导致具有较高熵的样本多,在熵划分的原则下,未知类样本容易被判别出,而此时的已知类预测准确度就相对不高. 随着源域标签信息逐渐被网络学习到,已知类样本的预测不确定性会随之下降. 但当训练持续进行时,神经网络会出现过于自信(over-confident)的情况,即以较高的概率将未知类样本划分到某一已知类,此时具有较低熵的未知类样本在随后的训练中会被进一步强化为已知类样本,而与之类似的未知类样本也会随之靠近已知类,导致未知类判别准确度下降.
相对于DANCE[24],DCC[27],OVANet[29]在未知类存在时,未知类划分以及已知类预测的能力都较好. 但DCC[27]在训练过程中需要多次聚类,CPU 占用率高.而OVANet[29]则不具备DCC[27]区分目标域不同的未知类的能力.
4.3 源域标签存在噪声时文献[13]的结果
在与其他单源域方法进行对比时,文献[13]使用的是源域标签无噪声的数据集,为考察不同噪声类型、不同噪声比例下文献[13]的表现,我们考虑源域为OfficeHome[36]数据集中的Art 数据,目标域为Clipart 数据集的OPDA 情形. 并分别选择了Yu 等人[13]提供的pairflip 和symmetric 共2 种噪声类型,以及0.2 和0.5 这2 种噪声比例(噪声比例越高,源域真实标签越少).
由表14 可知,相对于无噪声情形,噪声水平较低时,文献[13]表现并没有明显差异,甚至源域标签噪声的存在让模型学习到各类特征信息的难度增加,进而使得模型不易以较高置信度把未知类划分成已知类,因此区分未知类的准确度相对于无噪声时更高. 而当噪声水平持续上升至0.5 时,已知类预测的准确度相对于低噪声水平(0.2 时)或无噪声时都出现了大幅度下降. 这是因为源域标签错误数量过高时,筛选源域样本的难度增大,若错误的源域标签被忽视而参与到模型学习的监督中,则直接导致预测错误. 此外,高噪声情形下可被利用的具有真实标签的源域样本数目较少,使得模型学到的有效的已知类信息量低,因此预测准确度低.
4.4 多源域方法结果
UMAN 是Yin 等人[12]在I-UAN[17]的基础上进行的改进,针对多源域通用域适应问题的方法. 我们选取OfficeHome[36]数据集,参照Yin 等人[12]在UMAN原文中的设置,考虑源域数目为2 和源域数目为3 时的表现. 其中源域数目为2 时,我们以Art 和Clipart数据集为目标域. 需注意的是,在Yin 等人[12]设置下,各域相对之间均有私有类和共有类.
由表15~17 可见,总体而言,3 源域情形下未知类划分准确度和已知类预测平均准确度都略逊于双源域情形. 这是因为随着源域数目的增多,不同源域之间既有“共性”又有“个性”. 共性来自于2 域共有的类,而个性则来自于域私有类以及域内数据的特征分布,综合各源域类别信息具有难度. 从源域上迁移已知类别特征还需克服目标域与不同源域的域间差异,当模型想要对齐目标域与源域整体的特征分布时,难度会显著增大.
除了模型表现,作为对抗生成类方法,UMAN[12]本身就需要较多的训练步数,而当源域数目增加时,训练步数相较于单源域的I-UAN[17]更多,运行时间也更长,计算量更大.
4.5 source-free 与black-box 情形
为对比源域数据参与训练的方法与无源域数据参与训练的通用域适应方法,我们选择UB2DA[11],除了考虑UB2DA[11]本身所针对的黑箱(black-box)情形,即仅可获得源域模型接口的情况;我们还考虑了UB2DA[11]在仅可获得源域模型参数(source-free)时的表现,在此情景下,除了可以使用源域模型在目标域数据上的预测结果,还可使用源域模型参数初始化特征提取器. 我们用UB2DA[11](SF)和UB2DA[11](BX)分别表示 source-free 和black-box 设置下的UB2-DA[11]方法.根据表5~13 结果发现,UB2DA[11](SF)和UB2DA[11](BX)在ODA 和OPDA 情形下都具有比CDA 和PDA更高的平均准确度. 这是因为CDA 和PDA 情形下Lt⊆Ls,而源域数据特征以及标签信息在训练时无法直接获取,这就直接削弱了模型对各已知类特征的学习和划分能力,尤其是在域间差异存在的情况下,将源域上共有类信息迁移到目标域上的各类就更具难度,容易导致预测准确度低.
但在未知类存在时,UB2DA[11](SF)和UB2DA[11](BX)并没有表现出远差于有源域数据参与训练的方法. 这是因为在无法获取源域数据时,UB2DA[11]会更注重挖掘目标域自身的数据特征,例如除了熵划分外,还使用了类中心来强化类结构的学习. 所以当共有类占目标域类别总数比例相对于CDA 和PDA 情形并不高时,源域数据的缺失带来的负面影响在一定程度上被削弱. 而利用目标域数据的特征,也有利于未知类的发掘.
4.6 实验小结
从不同问题设置看,除UMAN[12]外,现有的通用域适应方法都是针对单源域问题. 在用UMAN[12]解决多源域问题时,使用者也需考虑耗时与计算资源. 若源域数据无法参与训练,可考虑USFDA[9]和UB2DA[11].但需注意的是,USFDA[9]在训练源模型前需要用源域数据生成并存储负样本,源域样本量大时,会带来极大的存储负担;此外,USFDA[9]在目标域数据上训练时,还会使用到增广图片,也会增加存储压力. 负样本或增广图片的生成都在训练外预先设置好,这种非在线的方式也增加了方法使用上的复杂度. 相较之下,UB2DA[11]使用更便捷,且可用于仅可获得源域模型接口的黑箱情形,应用范围更广.
从训练过程看,对抗生成类方法(如UAN[7],CMU[16],I-UAN[17])或包含对抗思想的方法(如文献[13])结果极大地依赖于参数选择,且模型收敛所需训练步数多,计算量高且耗时. 例如CMU[16]训练中使用了多个分类器,以及对源域数据做了多种增广,以计算其使用的3 个指标,相较于UAN[7]和I-UAN[17]存储需求更大、运行时间更长. 基于隐空间特征学习的方法相对来说参数依赖度低,结果更鲁棒,但是这类方法若在训练时涉及到记录历史低维特征表示,用以计算样本间相似度(如DANCE[24])或进行聚类操作(如DCC[27])等时,则会占据一定的存储空间、减缓运行速度.
从结果看,传统的对抗类方法(如UAN[7],CMU[16],I-UAN[17])没有在已知类准确度和未知类划分准确度上展现出明显的优势. 而模型的“过自信”问题也会使得预测准确度高的方法判别未知类能力差,极易影响依据熵进行样本划分的方法(如DANCE[24]和文献[13]). 在新类存在时,DCC[27]和OVANet[29]总体而言比DANCE[24]和文献[13]更稳健. 若选取已有通用域适应方法进行应用,除考虑准确度需求外,还需考虑数据量大小与可用计算资源,若数据量大或计算资源不足,则DCC[27]会更为费时.
5 研究难点
5.1 对抗生成学习容易混淆聚类边界
利用特征提取器和域判别器对抗学习域不变特征,是消除域间特征差异最广为应用的方法,但为了让域判别器无法判断样本来自哪个域,特征提取器在学习过程中易使特征空间中各类边界模糊,不同类样本混合在一起,导致聚类效果差,如图8 所示.实验也显示对抗类方法即使在未知类不存在时,相对于非对抗方法,预测准确度也更低;未知类存在时,判别能力也更弱,如表5~13 所示.
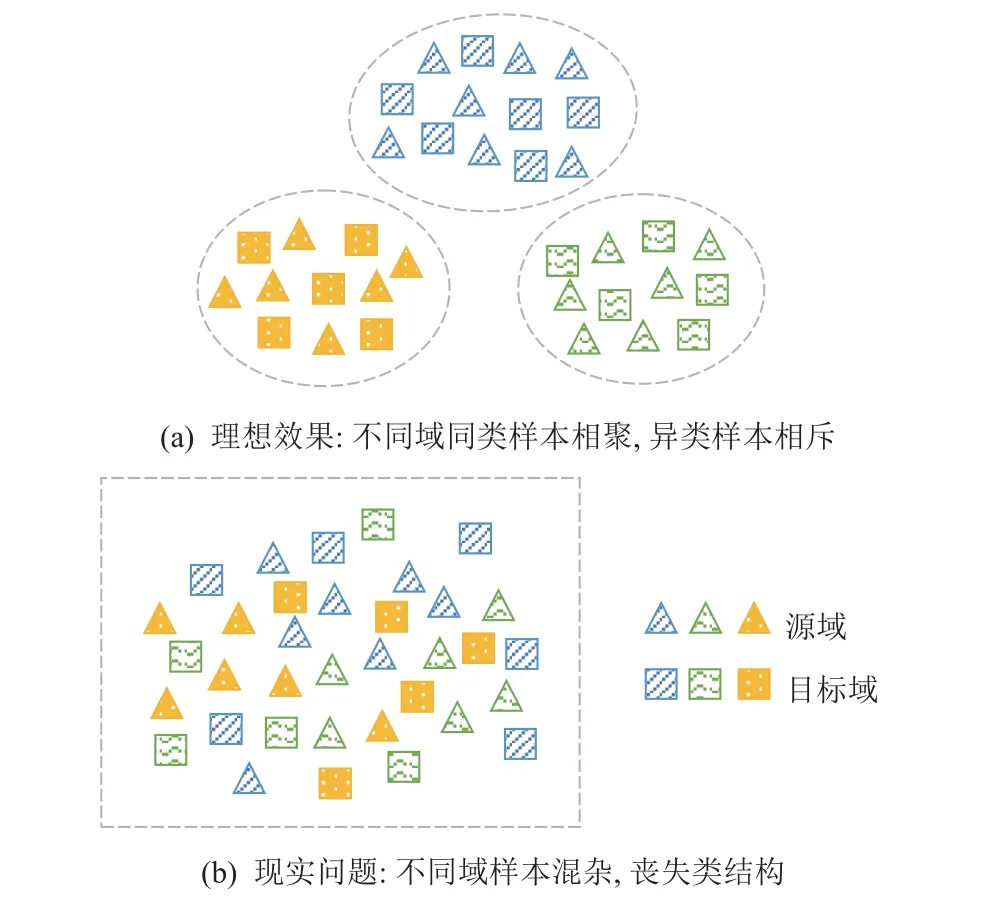
Fig.8 Ideal result and realistic problems of adversarial methods图8 对抗学习的理想效果与现实问题
为保证聚类良好,即保证同类样本距离相近、不同类的簇相距较远,不少域适应方法寻找最相似的样本,并使其在拓扑空间中靠得更近[24],或寻找互近邻对[22,28],并用跨域样本彼此相似的相对关系寻找公共类,其基本假设即为输入的高维数据本质位于一个低维流形上,而在这低维流形上,同类数据具有相似的特征表示和相近的几何距离. 但对域适应而言,涉及拓扑空间中的距离或相似性时均要考虑到不同域在特征上存在着域间差异,故用邻域思维进行域间迁移和特征学习的前提是在源域和目标域中寻找高置信度样本作为可靠的突破口,例如彼此邻域内标签或预测标签均相同的源域和目标域样本对,以其作为锚点,作为其他样本预测的参考,在训练中逐步“拉近”其他同类不同域样本.
5.2 消除域偏移并保持目标域类结构具有难度
对目标域而言,对其样本进行标注也可以视为聚类以及聚类簇与标签的配对2 个任务,由此可见,目标域标签标注准确的前提是其自身聚类良好,域内同类样本在特征空间中形成同一个簇,类内距离大于类间距离. 如此,当簇内有样本以较高置信度被源域样本注释后,同簇样本则可获得较为可靠的标签,目标域的注释过程也成了同一特征空间中目标域上各簇和源域各类的匹配过程. 为了提高目标域的聚类效果,现有通用域适应方法中常用的策略包括对比学习、类中心法和近邻法. 利用对比学习提高特征提取器能力[22,25,28,30],旨在使得相似的样本对距离更近、不相似的距离更远. 或者利用类中心法,使得各样本靠近对应簇的中心法,然后对齐各域类中心[11,27-28].若直接计算类中心,常用的方法为计算同一标签或伪标签样本的均值,由于源域有标签监督,即使用均值表示类中心也比较准确,而目标域上,在训练初始预测准确度低时,使用均值计算类中心误差较大,尤其是当未知类存在时,目标域的私有类样本会与各共有类样本混合在一起;若目标域中存在较为严重的类大小不均衡问题,依据预测伪标签计算类中心容易导致各簇都由样本量大的类别所主导,以致类中心不准确. 也有方法不直接计算类中心,而是提出优化目标,让模型自行学习类中心[11,28],若学习的目标域类中心包含目标域共有类类中心法,则还涉及目标域共有类类中心的标记问题,模型还需防止部分应为不同类的类中心都对应到同一类,以及部分共有类在学习后缺乏与之对应的类中心.
为样本寻找其最相似的样本或寻找一定范围内的邻居样本,然后拉近与之相似的样本、远离与之不相似的样本,这种策略是从样本角度消除域差异,让各样本邻域内聚类良好. 从样本出发,可以避免使用类中心带来的类中心表示不准确的问题,但因保存各样本最新的特征表示,会占用较多的存储空间,且若每次迭代都计算当前批次与全样本的相似性,也会极大地增加计算量与时长,这在一定程度上降低了方法的效率.
5.3 类别不均衡导致预测偏向多样本类别
如在计算类中心时所提到的,目标域上各类的大小即各类样本数不尽相同,以VisDA 数据集[41]为例,参照OVANet[29]实验中在源域和目标域均存在私有类时类别划分,2 域共有类有6 类(标签0~5),源域私有类有3 类(标签6~8),目标域私有类有3 类(标签9~11,也可都视为一类,标为9),各类样本数如图9所示. 图9 中各域内各类样本数相差较大,且目标域私有类样本总数远高于其他类. 但当某类样本数显著地高于其他类时,在特征学习过程中,该类样本易与其他各类样本混杂在一簇,且因数量占据优势而使得预测时其他类样本被预测成该类,这一现象在训练初期或该类特征较难学习时表现得尤为明显.为此,现有的方法往往使样本被预测成已知类的概率尽可能趋近均匀分布[10]. 此外,因为通用域适应问题将目标域中所有不出现在源域中的类别都视为私有类,故目标域私有类常因包含多个类而样本量远高于目标域中其他类,且大量的私有类样本会影响目标域内共有类样本与源域内对应类的配对,导致模型把几乎所有目标域样本都预测成未知类. 故而模型不仅要避免目标域共有类样本预测时都预测成某一已知类或某些已知类,还要防止所有样本被划分为未知类.
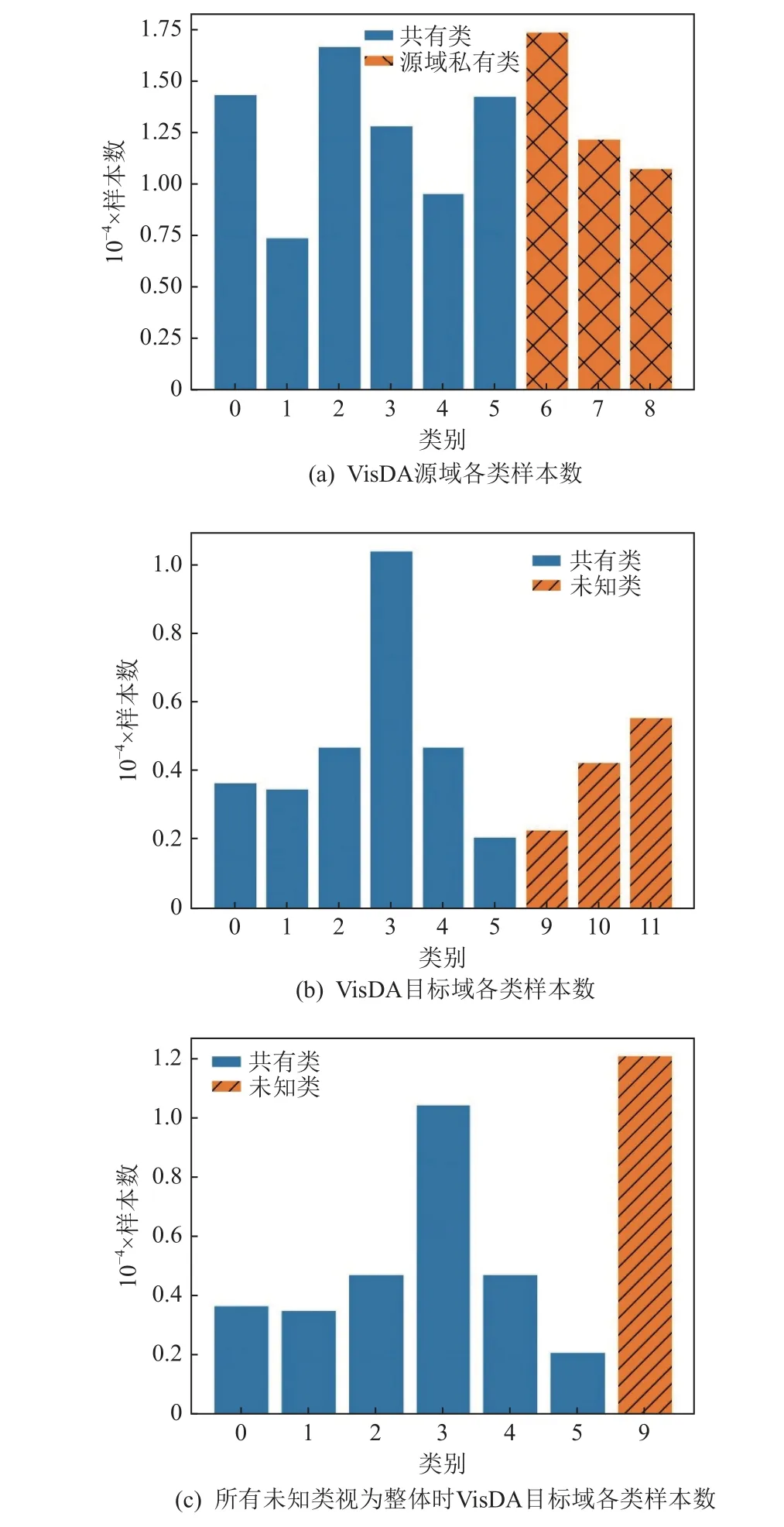
Fig.9 Sample numbers of each class when each domain contains its private classes using VisDA图9 使用VisDA 时每种域均含私有类的各类样本数
虽然类别不均衡(class imbalance)问题在源域和目标域中都有可能出现,但源域数据标签已知,可在划分批次(batch)时按照各类样本多少进行抽样使得各类样本出现概率尽可能相同,避免类大小差异过大使得样本数少的类在训练中被忽视,而目标域数据在进行批次抽样时则难以避免此类问题. 更重要的是,由于目标域上各类的真实大小未知,模型依赖于由源域标签监督训练的分类器给出的预测结果,但即使是2 域共有类,源域和目标域上共有类各类大小的相对情况也不一样,源域上样本较少的类在目标域中可能拥有较多的样本,而当模型没有从源域数据较好地学习到该类的独特特征时,目标域上属于此类的大量样本都易被错误预测.
5.4 模型偏向源域且预测过自信
要实现标签的迁移注释,往往需要将源域和目标域样本投影到同一特征空间,而在特征提取器这一映射的学习过程中,因为有源域标签监督学习,故而模型在学习低维特征表示时易偏向于学习源域数据的主要特征,使得在同一特征空间,源域的各类样本更有区分性而目标域样本更易杂乱无章. 当模型的训练策略需要先用源域数据进行预训练时,预训练后模型偏向源域数据的问题则会更为明显.
而在预测时,通用域适应方法一般定义的分类器维度恰为源域类别个数,因为分类器的训练依赖于源域数据的标签,所以分类器容易对目标域私有类样本做出“过于自信”(over-confident)的预测. 仍以VisDA[41]数据集为例,在源域和目标域均有私有类的情形下,按照图9 中类别划分,仅用源域标签训练特征提取器(ResNet50)和分类器(输出维度为源域类别数的单层线性网络),得到的预测概率的最大分量见图10,从图10 中可以看到许多目标域样本,尤其是属于未知类的样本,被以较高的概率预测到了错误的标签上. 这些被错误划分到源域类别中的目标域私有类样本,在后续训练中难以被模型发现并予以纠正. 这也是使得DANCE[24]和文献[13]的未知类判别准确度随着训练进行逐渐下降的原因.

Fig.10 Maximum probability predicted by the classifier trained only using source labels on VisDA图10 以VisDA 为例仅用源域标签训练分类器得到的预测最大概率
5.5 目标域私有类划分依赖自定义阈值
提到预测,就不得不提目标域私有类的判断和划分. 大多数通用域适应方法依据某一假设或原则定义指标,再与自行设定的阈值比较,如对抗生成学习中的权重[7,14,16-17]、熵[11,24-26]等. 在这一过程中,由于对数据集缺乏先验知识,阈值往往依据使用者的经验在训练前被确定,并在训练中保持不变. 当模型应用到不同数据集上时,这种阈值选择方法则容易带来较大的误差. 为了减少数据划分的误差,很多通用域适应方法在划分样本时还会设定带宽(band width),如图6 所示,使得指标与阈值差值在某一范围内的样本视为不确定样本,从而与其他更确定的样本区别对待,但带宽与阈值一样由人为设置,可能需要多次实验才能在某一源域和目标域数据组合上找到表现较好的参数值,不利于方法应用到多种数据集上.为改变阈值在训练中单一不变的情况,文献[14,20]定义了动态阈值,使得目标域私有类样本的筛选随着训练的进行由严格逐渐宽松. 但仍未改变阈值设定的另一大问题,即缺乏统计意义. 为此,MATHS[28]使用Hartigan’s dip test 检验是否可能存在未知类,TNT[30]则用贝叶斯模型刻画样本的不确定性,在设定阈值时,二者均应用3- σ原则,以较高置信度去划分未知类样本. 但是,依据3- σ依赖指标服从高斯分布或近高斯分布的假设,仍具有一定的局限性.
也有模型定义分类器时使得最后一维或后几维表示目标域的私有类[9,27],希望分类器在训练后直接给出样本属于未知类的概率估计. 但在训练分类器时,源域数据中没有目标域私有类样本,而目标域中属于私有类的样本未知,所以往往需要借助于模拟的未知类样本来训练分类器,常见的策略即为图片的拼接[9]或混合[28,38]. 但不论是拼接还是混合,得到的数据与真实的私有类数据往往相差很大,如图11 所示,就图片数据而言,目标域私有类样本是指这些图片中的物体与源域图片中的物体类别不一致,拼接或混合后则难以得到描述具体内容的图片,缺乏实际意义. 更重要的是,由于模拟样本与私有类样本可能并无相似性或无类别关系,目标域私有类样本仍会因其与模拟的私有样本不相似而被预测成已知类.此外,过分依赖模拟样本训练分类器,也容易使大部分目标域样本被归为私有类.
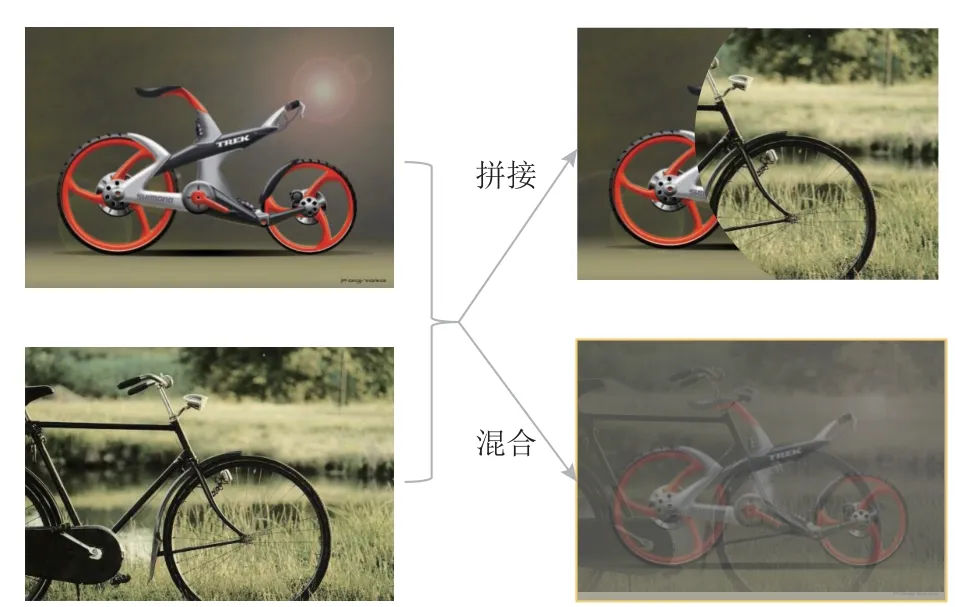
Fig.11 Demo of merging split images and mixing up images in raw feature space图11 原特征空间中图片的拼接与混合示例
由于类中心与分类器的权重都有表征类别的作用,故在预测时也有方法直接使用目标域上的类中心进行标记. 例如DCC[27],不仅可用目标域类中心标记目标域中已知类样本,还能区分目标域中不同的私有类,揭示目标域私有类的结构. 但是,使用类中心给样本做预测的前提是做好类中心的标记,即对目标域上共有类的类中心做好与源域类别的匹配,以及对私有类类中心做好其与源域共有类和其他私有类的区分. 如前所述,类中心在特征空间中表示的正确性也需注意,避免多类被预测成一类.
5.6 私有类样本与预测错误的共有类样本难以区分
在训练过程中,不论是依据熵[24]还是多分类器的差异[13]去识别可能属于未知类的样本,都存在一个问题,即目标域中属于共有类但被预测错误的样本,与目标域的私有类样本,从分类器预测结果看,二者往往具有相似的统计特征,例如被预测属于源域各类的概率的熵都较高. 以VisDA[41]数据集上源域和目标域均有私有类的情形(如图9 所示),在利用源域标签训练特征提取器(ResNet50)和分类器(输出维度为源域类别数的单层线性网络)后,目标域私有样本以及属于共有类但被错误预测的样本的熵如图12 所示,可见预测错误的共有类样本的熵总体也偏高. 若此时把熵高于指定阈值的样本视为未知类样本,则会使得大量共有类样本被划分错误.
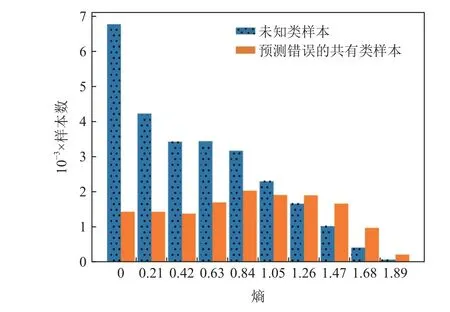
Fig.12 Entropy of target samples when only training with source data on VisDA图12 以VisDA 为例仅用源域数据训练后的目标样本熵
因此,如何防止目标域中被预测成源域中其他类的共有类样本被划分为未知类,以及如何防止目标域私有类样本以较高的置信度被归为源域的某类,连同如何识别并纠正被错误预测的目标域样本,都是通用域适应训练中的难点.
5.7 目标域私有类各类差异被忽视
由于缺乏目标域的标签信息,通用域适应方法往往只能做到判定哪些目标域样本类别不属于源域,并统一将其标记为未知类. 但实际应用中,目标域的私有类常为多个类构成的整体,且不同的私有类之间可能存在着显著的特征差异,因而在特征空间中,私有类样本难以聚成一簇,若强行使所有目标域私有类样本混杂在一起,有时反而会给特征映射的学习带来负面影响. 正是因为目标域私有的各类不尽相同,部分私有类样本因与其他私有类特征差异可能大于其与源域各类的特征差异,因而被误判为属于源域中的某类.
此外,目标域私有类个数未知,使得探索目标域各类之间的关系更为艰难. 因目标域私有类间潜在的特征差异性,若使用单一类中心表示目标域私有类则会非常不准确,现有的域适应做法通常在初步得到可能属于私有类的样本后,使用k-均值聚类,得到私有类类中心的初始值,然后使用指数平滑或梯度下降学习等方法更新私有类的类中心[9,11,28],通过各个类中心使得同在一个私有类的样本距离相近,不同的私有类得以区分. 而在这一过程中,k-均值聚类中私有类个数的设置缺乏先验信息,较难选择,类别过少仍会导致不同私有类混杂在一起,过多则增加计算复杂度,同时也会使得聚类趋于平凡.DCC[27]定义指标consencus score 来辅助选择目标域类别个数,但仍需在训练中多次尝试不同的聚类个数,存在运行时间长、计算量大的问题,因此如何兼具高效性与准确性去发掘目标域私有类的结构,并在有机会获取部分标签信息后使得模型能给目标域私有类以准确注释,也是通用域适应方法需考虑的突破之处.
6 相关应用
广为提及的域适应方法大多以图片分类为任务,但域适应的问题框架现在也更多地被应用到不同领域、不同任务之上. 在计算机视觉(computer vision,CV)领域,针对图片数据,除了图片分类,还有目标识别(object detection)[43-45]、图片分割(image segmentation)[46-48]、图片生成(image generation)[49]等问题[50]. 当数据由2 维变成3 维时,则有针对3 维点云(point cloud)数据的目标识别[51]和分割任务[52-53]. 当数据并非静止的图片,而是动态的视频时,则有相应的视频分析任务,包括动作识别(action recognition)[54-55]、动作分割(action segmentation)[56]、行人重识别(person reidentification)[57-58]、视频描述(video captioning)[59]、视频质量评价(video quality assessment)[60]等[50]. 在自然语言处理(natural language processing, NLP)中,可对图片数据进行描述(image captioning)[61-62],也可对文本进行情感分析(sentiment analysis)[63]. 此外,域适应的思想还可以应用于时间序列数据[64],在语音识别(speech recognition)[65]、驾驶操纵预测(driving maneuver prediction)[66]和情绪识别(emotion recognition)[67]等方面均有应用[50]. 在医疗领域,存在着诸如核磁共振图等医疗数据[46],也得到了域适应概念的应用[68-69],以进行疾病诊断等.
虽然传统无监督域适应的问题框架已经推广到了除图片分类外的多种任务上,通用域适应方法的研究还主要集中于给图片做标记,但也呈现了向其他领域推广的趋势. Chidlovskii 等人[15]针对标签有序的数据进行标记,将通用域适应与有序回归(ordinal regression, OR)结合. 文献[19]则着眼于对工业机器的图片数据集的应用,以解决工业界机器故障诊断(fault diagnostics)问题. Uni3DA[23]则针对3 维点云数据进行目标识别. 对于2 维图片数据的分类任务,模型往往只需要考虑图片的全局特征,而点云数据的局部特征却具有明确的语义信息,不可忽略,且共有类和私有类样本也许有相似或共同的局部特征,这就使得通用域适应问题应用到3 维点云数据上时,特征的学习和私有类的判别都更具难度.
除此之外,通用域适应问题与生物信息学中细胞类别注释问题也有着互通之处. 传统的细胞标记方法需要对数据集进行预处理、降维和聚类后,寻找标记基因(marker gene)并查阅文献,给出细胞类别.这就要求使用者掌握一定的生物学知识,且过程耗时、低效,不适合处理大量数据集. 现在的细胞注释方法更多寻求把良好标注的基因表达数据集作为参考集,自动对未知细胞类别的数据集进行预测. 由于未标记数据集细胞类型缺少先验信息,且新数据集中往往易包含新的细胞类别,这些新细胞的发现又对下游分析具有重要意义,因而细胞注释方法也朝着对参考集和待注释集标签关系不做要求且增强发现新类能力[70-73]的方向发展,这恰与通用域适应的问题假设类似. 而且目前的单细胞注释方法除要求能发现新类外,也有假设参考集在待注释集合上训练时不可得、有多个参考集[74]等研究方向,其与sourcefree 通用域适应、多源域通用域适应假设相似.
但由于基因测序数据自身的特点,计算机领域的域适应方法不能简单应用于细胞注释问题. 首先,对基因测序数据而言,不同的数据集差异来源除了数据背后潜在的生物差异,还有实验环境等技术因素带来的干扰,因而跨数据集进行细胞注释时需要识别并排除干扰因素,保留有用的生物信息. 其次,基因测序数据具有高维度、高稀疏性、高噪声的特点,研究者往往还需要针对测序数据进行建模,如ZINB(zero-inflated negative binomial)模型[75],以降维和去噪. 此外,细胞的分化往往导致细胞内基因表达量随时间连续变化,因此细胞注释时还需保证能得到具有生物意义的细胞轨迹,这相比图片数据的离散分类则更具难度. 简言之,通用域适应方法对于缺少参考数据集和待注释数据集标签的先验信息、想要能发现细胞新类的细胞注释方法研究具有启发意义,但因为生物数据的自身特点,以及对细胞注释的生物意义具有要求,研究者需要从生物研究需求与数据特点出发进行建模.
7 未来发展
通过前文对目前通用域适应研究方法问题框架的整理和分析,我们可以发现,目前通用域适应方法有逐步放宽假设以使问题更具实际意义、更换数据集来拓展通用域适应实际应用的趋势,已有的问题设置包括:域适应时仅可获得源域模型的source-free情形[9-10]、仅可获得源域模型接口的black-box 情形[11]、多源域情形[12]、源域标签带噪声情形[13]、标签有序情形[15],但因为这些问题框架相对于通用域适应原假设更具难度,关于它们的研究方法还不够丰富,值得进一步深入研究.
此外,ADCL[14]将主动学习框架与通用域适应问题结合,也给通用域适应的研究提供了新的思路. 在实际应用中,从主动学习(active learning)的角度思考,如果有机会获得一小部分目标域样本的标签,模型应如何选取样本去获得外部注释,以使得这些标签参与训练后最大程度地提升模型效果. 从半监督学习(semi-supervised learning)的角度思考,如果目标域数据集中有一小部分样本具有标签,又应如何利用这少数的标签和源域标签,学习数据特征并完成标签迁移. 这些都可以进一步地研究.
当通用域适应问题考虑训练时源域数据是否可获得时,可以得到source-free 通用域适应,而与域适应问题紧密相关的领域泛化(domain generalization,DG)则考虑训练时目标域数据不可获得的情形. 领域泛化利用多个源域的数据进行特征学习,希望模型在未知的目标样本上表现良好,这一目标具有极大的挑战性. 但相对于域适应更为方便的是,每获取一个目标数据集,领域泛化方法不需要重新训练模型,实际应用中更有前景. 当然,注重普遍的泛化能力可能会导致领域泛化模型在某一目标数据集上的预测准确度,相对于同时利用源域和目标域数据进行训练的域适应方法有所降低. 由于不利用目标域进行训练,本质上领域泛化问题中对于源域和目标域标签集的先验信息是未知的,模型所泛化的数据集也很有可能含有私有类,因此,通用域适应的问题框架可以与领域泛化相结合,开展更具实际应用前景的研究.
最后,从前述应用分析可见,通用域适应相对于传统域适应问题的应用范围而言,应用场景还较为局限,还可以应用于目标识别、视频描述等无监督域适应已经应用到的各类任务. 也可着眼于工业界、医疗、生物等领域的问题,用通用域适应的思路辅助解决对应领域的实际问题,例如机器故障诊断、自动驾驶预测、影像学图片分析、疾病诊断、细胞类别注释等.
8 总 结
通用域适应放宽了传统无监督域适应中对于源域和目标域标签集合相对包含关系的假设,使得域适应问题更加一般化. 本文对近年来通用域适应领域的各类模型,从问题设置和方法策略上分别进行了梳理,开展实验分析了典型方法,并指出了通用域适应问题解决的难点与可改进之处. 然后对通用域适应目前应用的场景和与之相关的应用领域进行了梳理,同时对通用域适应未来的发展方向进行了分析. 总而言之,通用域适应相较于传统域适应更具实际意义,也更具难度. 目前已经获得了越来越多的关注,但还有较多方向与应用问题有待挖掘,在未来一定时间内仍极具研究前景.
作者贡献声明:何秋妍负责论文的撰写与修改;邓明华负责指导论文结构与内容.
