长三角人才集聚与区域经济增长效应研究
2024-01-12王天宇
□ 王天宇 钟 晶
党的二十大报告提出,“深入实施人才强国战略”。坚持人才是第一资源,发挥人才引领驱动中国式现代化建设的作用,方能开辟发展新领域新赛道,不断塑造发展新动能新优势。作为我国经济发展最活跃、开放程度最高、创新能力最强的区域之一,长三角已逐步成为人才强国雁阵格局中的重要战略支点。本文系统分析了党的十八大以来经济发展成效和人才集聚效应,以长三角地区三省一市为研究对象,通过引入工具变量,构建面板数据模型进行实证分析,探究人才集聚对区域经济增长的影响,提出集聚人才助力经济高质量发展的建议。
| 长三角地区经济增长与人才集聚主要情况
(一)经济发展卓有成效
1.区域经济总量实现翻番,安徽首进全国第一方阵。新时代十年长三角一体化发展取得新成效,2022 年长三角地区GDP 总量为29 万亿元,比2012 年增加16.2万亿元,其中江苏、浙江、安徽和上海分别增加6.9 万亿元、4.3 万亿元、2.7 万亿元和2.3 万亿元。长三角地区GDP 总量占全国的比重由2012 年的23.7%提升至2022年的24%,提高0.3 个百分点,其中安徽、江苏分别提高0.3 个和0.2个百分点,浙江持平,上海下降0.2个百分点。
党的十八大以来安徽经济持续稳定较快增长,2022 年GDP 总量由2012 年的18341.7 亿元连跨三个万亿台阶,达45045 亿元,首次进入全国第一方阵,居全国第10 位,首次超过上海,居长三角地区第3 位。安徽GDP 总量占长三角地区的15.5%,比2012 年提高1.1 个百分点;相当于上海的100.9%、浙江的58%和江苏的36.7%,比2012年分别提高14.8个、4.6 个和2.5 个百分点,与江苏、浙江经济总量差距进一步缩小。
2.区域人均GDP 持续增长,安徽仍低于全国平均水平。2022 年长三角地区人均GDP①长三角地区人均GDP 取上海、江苏、浙江和安徽人均GDP 的中位数。为131443元/人,比2012年增加67628元/人,其中上海、江苏、浙江和安徽分别增加90294 元/人、77857 元/人、57399 元/人和42906 元/人。长三角地区人均GDP 相当于全国人均GDP 的 比 重 由2012 年 的160.5%下降至2022 年的153.4%,下降7.1个百分点,其中安徽、江苏分别提高8.7 个和1.2 个百分点,浙江、上海分别下降15.3 个和15.4 个百分点。
2022 年安徽人均GDP 由2012 年的30697 元/人增加至73063 元/人,居全国位次由2012 年的第21 位提升至2022 年的第14 位,实现从人均靠后向人均居中的历史性转变,但在长三角地区仍居末位。安徽人均GDP 相当于全国人均GDP 的85.9%,比2012 年提高8.7 个百分点;相当于浙江的62.1%、江苏的51%和上海的40.9%,比2012 年分别提高11.9 个、4.9 个和6.6 个百分点,与沪苏浙仍存在较大差距。
(二)人才集聚效应显现
1.区域人才①根据本文研究,人才指大专及以上学历的就业人员。规模不断扩大,安徽保持平稳增长。党的十八大以来,习近平总书记把人才工作摆在党和国家事业发展全局的突出位置来抓,区域人才规模不断壮大。2021 年长三角地区人才总量为3762.3 万人,比2012 年增加1637.1 万人,其中江苏、浙江、上海和安徽分别增加610 万人、460.9 万人、342.2 万人和224 万人。长三角地区人才总量占全国的比重由2012 年的20.4%提升至2021年的21.8%,提高1.4 个百分点,其中江苏、上海和浙江分别提高0.7个、0.6 个和0.4 个百分点,而安徽下降0.3 个百分点。
2021 年,安徽人才总量由2012年的409.3 万人增加至633.3 万人,居长三角地区末位。安徽人才总量占长三角地区的16.8%,比2012年下降2.5 个百分点;相当于上海的88.2%、浙江的59.5%和江苏的47%,比2012 年分别下降20.7 个、8.5 个和8.4 个百分点,与沪苏浙人才总量差距进一步扩大。
2.区域人才文化素质稳步提高,安徽仍存在较大差距。教育事业的快速发展,带动区域就业人员学历结构持续优化,为劳动力市场提供了丰富的高素质人才。2021 年长三角地区就业人员中,大专及以上、高中受教育程度人员所占比重分别为28.2%和17.8%,比2012 年分别上升12.5 个和1.2个百分点;初中、小学及以下受教育程度人员所占比重分别为37.6%和16.4%,分别下降9.1 个和4.6个百分点。长三角地区就业人员平均受教育年限由2012 年的9.8 年提高到2021 年的10.9 年。
2021 年安徽就业人员中,大专及以上、高中受教育程度人员所占比重分别为19.7%和14.3%,比2012 年分别上升10 个和3.5 个百分点;初中、小学及以下受教育程度人员所占比重分别为41.8%和24.2%,分别下降10.7 个和2.8 个百分点。2021 年,安徽就业人员平均受教育年限由2012 年的9 年提高到9.8 年,居长三角地区末位。安徽就业人员平均受教育年限比长三角地区少1.1 年,比最高的上海少3.2 年,比江苏、浙江分别少1.2年和1 年。
3.区域人才科创能力持续提升,安徽呈现指数级增长。党的十八大以来,科技体制机制改革全面发力、纵深推进。科技创新人才队伍不断壮大。2021 年,按折合全时工作量计算的长三角地区R&D 人员总量为180.2 万人年,比2012 年增加86.6 万人年,其中江苏、浙江、安徽和上海分别增加35.4 万 人 年、29.8 万 人 年、13.2万人年和8.2 万人年。长三角地区R&D 人员总量占全国的比重由2012 年的28.8%提升至2021 年的31.5%,提高2.7 个百分点,其中浙江、安徽和江苏分别提高1.5 个、0.9 个和0.9 个百分点,上海下降0.6个百分点。2021 年,安徽R&D 人员总量由2012 年的10.3 万人年增加至23.5 万人年,增长1.3 倍,增幅居长三角地区首位。
科技创新产出质量不断提升。2021 年,长三角地区发明专利申请授权量为18.2 万件,比2012 年增加14 万件,其中江苏、浙江、安徽和上海分别增加5.3 万件、4.5万件、2.1 万件和2.1 万件。长三角地区发明专利申请授权量占全国的比重由2012 年的29.4%提升至2021 年的31.1%,提高1.7 个百分点,其中安徽、浙江和江苏分别提高1.9 个、1.6 个和0.5 个百分点,而上海下降2.3 个百分点。2021 年,安徽发明专利申请授权量由2012年的0.3 万件增加至2.4 万件,增长7 倍,增幅居长三角地区首位。
| 面板数据模型构建与实证
(一)变量选取和预处理
1.变量选取。
被解释变量:人均GDP(pgdp)。人均GDP 指GDP 与常住人口的比值,它能较好地反映一个地区的富裕程度和经济发展水平。
解释变量:(1)人才集聚度(ta)。本文定义人才集聚度指大专及以上学历的就业人员占全部就业人员的比重。(2)科技创新效率(patent):由于科技创新效率难以有效测量,按照国际通用做法,本文选用发明专利申请授权量作为科技创新效率的替代变量。
2.变量预处理。由于搜集到的原始数据单位具有数量级差异,从而使数据大小产生波动,因此选择对所有变量取对数处理。需要说明的是,人均GDP 取对数之后,可以解释成增长率的变化。本文数据处理和实证分析均使用Eviews10.0软件。
(二)面板数据模型构建
1.模型构建。本文构建面板数据模型,实证研究人才集聚度对人均GDP 增长率的影响。假定面板数据模型的一般形式如下:
其中,yit为被解释变量,xit为解释变量,σ是总体效应,μi是截面效应,ωt是时期效应,φit是随机扰动项。
2.单位根检验。本文的面板数据模型是N=4,T=10,T>N 结构,可能存在面板数据是非平稳的问题。对面板数据进行单位根检验,本文采 用LLC 检 验、Breitung 检 验 和Hadri 检验进行同质单位根检验,同时采用IPS 检验、Fisher-ADF 检验和Fisher-PP 检验进行异质单位根检验。结果表明,所有变量都存在单位根,但一阶差分序列都是平稳的(表1)。

表1 单位根检验结果
3.解释变量内生性检验。本文利用Durbin-Wu-Hausman test 外生性检验,结果表明,lnta 和lnpatent都是内生变量(表2)。
4.工具变量选择与检验。本文引入工资水平、高等教育水平和医疗水平作为工具变量。工具变量定义如下:
工资水平(wage):衡量地区工资水平选用的指标是城镇单位就业人员平均工资。
高等教育水平(hedu):衡量地区高等教育水平选用的指标是每十万人口高等学校平均在校生数。
医疗水平(medical):衡量地区医疗水平选用的指标是每万人医疗机构床位数。
本文采用过度识别Hansen J检验用于检验工具变量的外生性,其中过度识别检验仅在工具变量个数大于内生变量个数时生效。结果表明,p 值大于0.05,所有工具变量都是外生的(表3)。

表3 过度识别检验
5.面板数据模型类型选择。面板数据模型类型有三种,分别是混合POOL 模型、固定效应FE 模型和随机效应RE 模型。结果表明,F 检验呈现出5%显著性水平下p值为0,意味着相对POOL 模型而言,FE 模型更优。BP 检验呈现出5%显著性水平下p 值为0,意味着相对POOL 模型而言,RE 模型更优。Hausman 检验得出在5%显著性水平下p 值为0.304,意味着相对FE 模型而言,RE 模型更优。综合上述分析,最终选择随机效应RE 模型(表4)。

表4 模型类型选择结果
(三)实证分析
1.数据来源。本文所用数据主要由长三角地区三省一市2012—2021 年度《中国统计年鉴》《中国社会统计年鉴》《中国科技统计年鉴》《上海统计年鉴》《江苏统计年鉴》《浙江统计年鉴》《安徽统计年鉴》整理所得。
2.实证分析。本文对随机效应RE 模型进行GMM 估计,可以看出模型R2为0.939,意味着lnta 和 lnpatent 可 以 解 释lnpgdp 的93.9%变化原因。对模型进行Wald卡方检验时发现模型通过Wald 卡方检验p 值为0 小于0.05,也即说明lnta 和lnpatent 中至少一项会对lnpgdp 产生影响关系。lnta 的回归系数值为0.859(p=0<0.01),意味着lnta 会对lnpgdp 产生显著的正向影响关系;lnpatent 的回归系数值为0.229(p=0<0.01), 意 味 着lnpatent会对lnpgdp 产生显著的正向影响关系。因此,lnta 和lnpatent 全部会对lnpgdp 产生显著的正向影响关系(表5)。
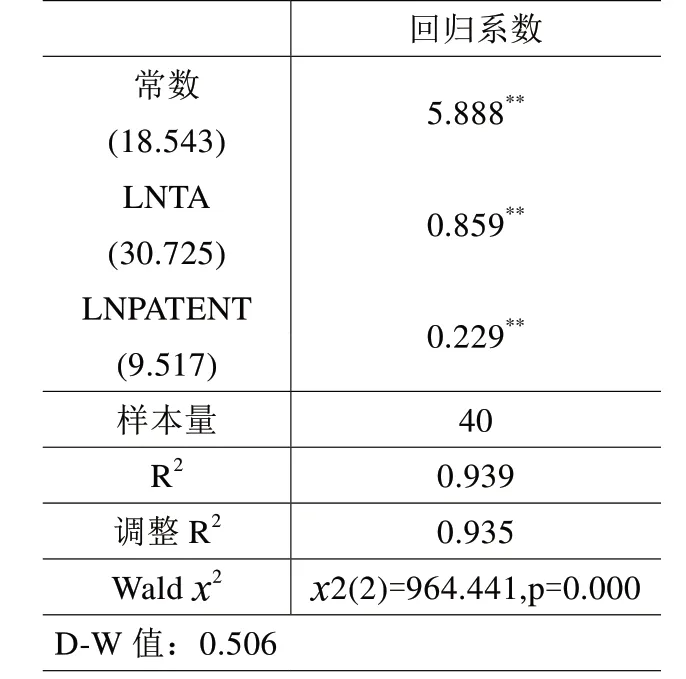
表5 随机效应RE模型GMM估计结果
3.主要结论。通过观察模型可以得到如下结论:人才集聚度和科技创新效率都与长三角地区经济增长呈正相关关系,两个解释变量都对人均GDP 起到促进作用。其中,人才集聚度对人均GDP 的影响程度最大。具体来说,人才集聚度的回归系数为0.859,表明人才集聚度每提高1 个单位,人均GDP将提高0.859 个单位;科技创新效率的回归系数为0.229,表明科技创新效率每提高1 个单位,人均GDP 将提高0.229 个单位。
| 期望与建议
(一)聚焦一体化,精准联动聚合力
一是推动人才市场共建。探索共同成立长三角人才集团,成立“长三角人才发展基金”,通过市场化主体对接人才政策、人才服务、用人主体,精准匹配产业需求,以市场化的手段高效配置人才。二是推动人才标准共定。建立健全长三角地区人才交流合作工作机制,推进人才评价标准统一。进一步深化长三角地区专业技术人才和技能人才资格、职称和继续教育学时互认,实现“一次评审、四地互认”。三是推动人才资源共享。坚持“不求所有、但求所用”,支持企业采取项目合作、技术咨询、挂职兼职、周末工程师等方式柔性引智。高标准建设区域创新中心,打造服务长三角的人才创新“共同体”,鼓励科技人才在区域内自主流动、择业创业。
(二)聚焦产才融合,精准施策强引力
一是等高对接集聚人才。围绕重点产业发展需求,常态化分析研究国内外人才政策,对标对表定期迭代升级。进一步破解人才政策部门化、碎片化问题,优化整合人才计划,集成出台人才政策,实现“一口出”“一单清”。二是夯实平台吸引人才。聚焦新兴产业,支持建设国家级创新中心、重点实验室等重大创新载体,提升众创空间、孵化器能级。进一步加强与国内外一流大学、知名科研院所战略合作,设立天使基金、种子基金,深化政产学研合作机制。三是赋权企业激活人才。打破固有模式,探索在政策框架内将人才认定权交给企业、还给市场。进一步完善企业职称评价自主权,构建新兴产业人才评价体系,实现人才“企业自评、政府审批、全国通用”。
(三)聚焦人才关切,精准服务提动力
一是健全人才服务云平台。推进上线“长三角人才码”,建立健全惠企惠才云平台,实现各类人才政策“一站查”,各项人才补贴“一站领”,各种涉才服务“一站办”。实现一码在手、人才无忧。二是完善人才谈心交流制度。完善党委联系服务专家人才制度,为重点企业和人才提供专班服务,对高层次人才实行“一事一议”。定期邀请各类人才与党委和政府主要负责同志面对面谈心交流,顶格倾听企业人才诉求,顶格推进涉才事项办理。三是优化人才服务绿色通道。建立“人才白名单”,为重点产业领域专家人才颁发“人才绿卡”,在医疗卫生、子女入学、配偶安置等方面开辟绿色通道。
