多变背景噪音对声纹识别技术的影响探讨
2024-01-12曾繁祥杨璐铭廖云根
曾繁祥 杨璐铭 扶 楠 廖云根
(1.梅州市公安局刑警支队,广东 梅州 514000 2.广东省公安厅刑事技术中心,广东 广州 510000)
声纹原指借助有关科学仪器分析、显示出来的语音的图像,即语音的频谱图。声纹现指作为诉讼证据的声音特征的集合[1]。声纹识别是一种语音识别技术,它的特点在于该技术并不分析语音的内容,只在意说话人的身份,其原理是为每个说话人建立一个声纹模型,先将语音信号中能反映说话人身份特征的个性特征参数提取出来,再进行一定的处理后,然后按一定规则加以匹配,从而确认或鉴别出说话人的身份。
随着技术的进步,犯罪手段也在不断创新,变声器等各种干扰手段层出不穷,影响了部分语音的质量,导致识别比对效果欠佳。笔者在办案过程中,发现不少语音存在背景噪声、伪装等可能影响比对效果的现象。
1 实验目的
为研究不同的念读状态、背景噪声、伪装、情绪状态等因素对声纹识别技术的影响,本文利用小样本数据,针对其中的三类影响因素进行初步研究:一是被试念读的距离与状态,二是被试念读时的背景噪音,三是人声语音叠加。
2 使用工具
讯飞声纹采集设备(V2.0);真我手机自带的录音功能;国音智能声纹鉴定专家系统(V2.10.5);MixPad 多轨道混音软件(V10.24.CN);采集的实验语音与样本语音采样率均为16000Hz;不同被试均使用统一的念读文本;参与实验的被试:样本1 ~3 为男性,样本4 ~5为女性。
3 实验过程和结果
3.1 实验一
在安静的语音环境下,使用真我手机录制以下实验样本语音:
3.1.1 不同的被试距离:真我手机10cm(近距离)、50cm、100cm 三种距离进行念读。
3.1.2 不同的被试分别进行快速、慢速念读。由于每名被试本身语速存在差异,因此快速、慢速念读的速度均为相对值。
3.1.3 不同的被试分别伪装(捏鼻子)念读。
3.1.4 不同被试均录制10s 的短时长念读语音。
3.1.5 不同被试均使用客家方言念读。
3.1.6 不同被试在不同情绪状态下进行念读。
3.1.7 实验结果。分别将实验语音与被试正常念读的样本语音导入国音智能声纹鉴定专家系统(V2.0),采样率均设置为16000Hz。利用系统自带的声纹比对功能,对不同的实验语音与样本语音进行比对识别,观察分值的差异(百分制)。结果如表1 所示。
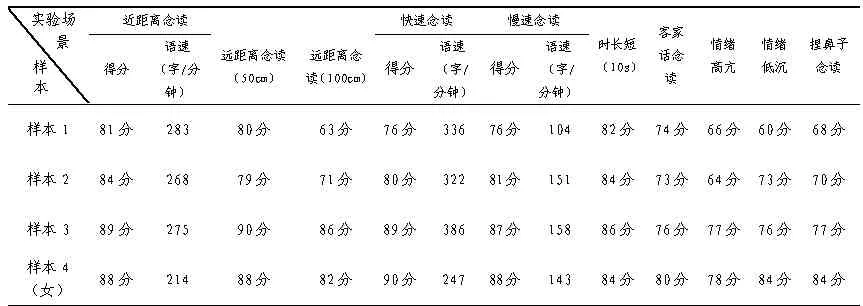
表1 实验一结果
从表1 可以看出,远距离(50cm)、快、慢速念读、语音时长因素对声纹识别分值干扰较小;远距离(100cm)、方言、伪装(捏鼻子)、情绪对声纹识别分值影响较大。远距离(100cm)使声音变得微弱,对声纹特征产生了显著影响,降低了识别的分值。方言是人们从小习得的母语,经过多年听、说的沉浸,一个人的听觉、发音器官的神经和肌肉已形成定势,方言部分音的发音方式与普通话发音方式存在明显差别,因此造成方言的实验语音与普通话样本识别比对分值差别大。捏鼻子的伪装方式改变了鼻腔共鸣模式,影响了个体声音特征,导致比对分值差别大。不同情绪会影响声音的频率、强度、韵律、语速和语调等特征,高亢的情绪使声音变得更高更快、更尖锐、更强烈;低沉的情绪会使声音变得更低、更柔和、缓慢,因此声纹特征变得不稳定,会对声纹识别比对产生明显的影响。但在伪装(捏鼻子)、情绪低落的实验语音比对结果中发现男性被试比对分值影响显著,女性被试比对分值影响较小,可能与个体部分语音特征相关,由于样本数量有限,有待进一步研究。
3.2 实验二
将日常生活中常见的背景噪音,利用MixPad 多轨道混音软件(V10.24.CN)叠加入样本语音,合成导出为实验语音,叠加参数如图1 所示,研究多变背景环境音对声纹识别的影响。
图1 实验语音叠加参数
3.2.1 叠加背景音乐,音乐类型为平缓的无人声音乐。
3.2.2 叠加风噪声。
3.2.3 叠加电视播放声,播放内容为纪录片。
3.2.4 叠加物体摩擦、敲击声。
3.2.5 实验结果。分别将实验语音与被试正常念读的样本语音导入国音智能声纹鉴定专家系统(V2.0),采样率均设置为16000Hz。利用系统自带的声纹比对功能对不同的实验语音与样本语音进行比对评分,观察分值的差异(百分制)。结果如表2 所示。

表2 实验二结果
从表2 可以看出,叠加背景音乐、风噪声、电视播放声、物体摩擦敲击声等加性噪音均会对声纹识别产生明显的影响。加性噪音[2]会影响原始语音的特征,在提取特征时,特征也会受到噪音的影响;噪音还会引起语音质量下降,使其模糊、失真;噪音与原始语音信息混合在一起,会导致语音信噪比下降,使声纹识别系统难以分辨语音信号和噪音信号,进而影响声纹识别评分的准确率。
3.3 实验三
采用MixPad 多轨道混音软件(V10.24.CN)将2 名不同被试在安静的语音环境下采集的实验语音与样本语音进行叠加,并从叠加语段中随机选取2min 时长的语音,合成导出为实验语音,叠加参数如图1 所示,与其原始样本语音的识别分值进行分析比对。
3.3.1 同一被试在样本语音与实验语音中念读的是不同的文本。
3.3.2 为了研究女性与女性声音的叠加,增加了女性被试5。
3.3.3 实验结果
分别将实验语音与被试正常念读的样本语音导入国音智能声纹鉴定专家系统(V2.0),采样率均设置为16000Hz。利用系统自带的声纹比对功能对不同的实验语音与样本语音进行比对评分,观察分值的差异(百分制)。结果如表3 所示(标红的数据为同一人叠加比对分数)。

表3 实验三结果
从表3 的实验数据可以看出,叠加他人语音后的实验语音与原样本语音相比,分值均有降低,其中叠加他人语音后样本1、3、4 比对分值下降较明显,这是由于一个人说话的语音信号被另一个人所覆盖,干扰了系统对声纹特征的提取和匹配,从而影响声纹识别的准确性。虽然有他人的语音叠加,但是样本2 的比对分值下降相对较小,样本1 的分值下降显著,说明声纹识别度并不是一成不变的,而是与自身语音在混合音中的强度有关,自身语音被他人说话声淹没程度低的,则自身语音被识别程度高,反之,自身语音淹没程度高的,被识别程度就低。
此外,从实验结果可以看出,同一被试叠加了他人语音后,明显降低了识别比对分值。但无论是男女叠加、男男叠加或女女叠加后,识别比对所降低的分差之间的差异都不明显,这说明在该算法下,只要混合了他人语音均会降低识别比对分数,但分数的下降程度与所混合语音的性别无关。
4 总结
通过上述三个实验可以得出,念读状态、背景噪声、语音叠加等因素对声纹识别技术有明显影响,但是程度各有不同。例如在实验三中,样本1说话人识别分值受语音叠加的影响显著,样本3 的说话人无论在实验二、实验三中,受实验因素影响相对不大,比对分数较稳定。说明有的人存在部分不易受外界影响较稳定的声纹特征,同时部分人的声纹特征容易被影响受波动,此外还可能与特征算法相关。由于这次实验样本较少,有待进一步扩大样本深入研究。
通过以上实验数据可知,实际案件中的语音存在着远距离说话、各种情绪状态、伪装说话、背景噪音、多人语音叠加等各种情况影响,对目标人物的声纹识别造成一定干扰。针对上述较低质量的语音,在进行声纹识别比对前,可以将低质量的语音进行优化清洗,进而提升语音识别度,例如:(1)对于录制设备离声源较远距离、能量较低的语音进行增益调节来提升语音的识别度;(2)对于存在较多背景噪音的语音,可以将语音的背景噪音删除,若噪音与目标人无法分离,可对背景噪音进行降噪处理[3],适当地削弱背景噪音;(3)对于多人说话音,可先对语音进行分离分类,后将目标人物分离后的语音聚类后再进行声纹比对;(4)分析评判时需要结合考虑特定情绪因素下的语音特征,提高识别精确度。
