将行为依赖融入多任务学习的个性化推荐模型
2024-01-11顾军华李宁宁王鑫鑫张素琪
顾军华,李宁宁,王鑫鑫,张素琪
1.河北工业大学 人工智能与数据科学学院,天津 300401
2.河北省大数据计算重点实验室(河北工业大学),天津 300401
3.天津商业大学 理学院,天津 300134
4.天津商业大学 信息工程学院,天津 300134
在互联网技术快速发展的时代背景下,每天都会产生海量数据,对数据进行筛选和过滤已经成为系统中必不可少的环节。推荐系统应运而生,它可以帮助用户方便地获取需要的项目和服务,因此受到广泛关注。
在各类推荐系统中,协同过滤算法的应用最为广泛。协同过滤推荐算法[1]利用用户的历史交互行为学习用户偏好并形成推荐结果,然而现有的推荐算法仅仅基于单一的行为类型对用户和项目进行建模,忽略了真实的应用场景中用户和项目之间存在着多种行为类型[2-3]。图1 是在线商城用户-项目的多行为交互示例,其中ui表示用户i,vj表示项目j,e1、e2、e3、e4分别表示查看、加购、收藏和购买行为,用户可以通过查看、加购、收藏等方式与项目进行交互[4]。多种行为类型数据的引入,可以有效缓解数据稀疏和冷启动问题。联合并挖掘多行为之间复杂的依赖关系,有助于获取更准确的用户偏好特征。多行为推荐算法中通常将购买作为目标行为,查看、收藏、加购等其他行为作为辅助行为。
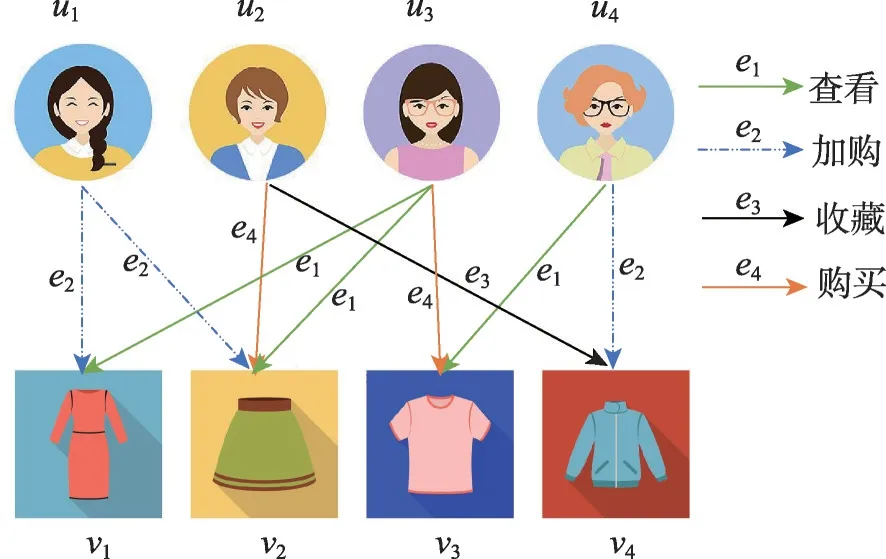
图1 在线商城用户-项目的多行为交互Fig.1 User-item multi-behavior interaction in online retail
近年来,基于深度学习框架的推荐算法成为大量推荐平台首选,它能通过用户的交互历史以及各种辅助信息有效地学习用户和项目特征。目前基于深度学习的多行为推荐算法主要是基于图神经网络的方法,首先构建多行为交互图,如图2(a)所示,是根据图1 中多行为交互数据构建的以用户u1为中心的多行为交互图,再利用图神经网络对多行为交互图进行建模,捕获用户和项目高阶协同信息。例如MBGCN(multi-behavior graph convolutional network)[5]和GHCF(graph heterogeneous collaborative filtering)[6]均利用图卷积网络处理多行为交互图。另一个是基于循环神经网络的方法,首先构建用户多行为交互序列,如图2(b)是按照用户u1交互时间顺序排列的多行为交互序列,再利用循环神经网络对序列建模学习数据的时序特征,例如DUPN(deep user perception network)[7]和DIPN(deep intent prediction network)[8]分别利用长短期记忆网络(long short-term memory,LSTM)[9]和双向门控循环单元(bi-directional gated recurrent unit,Bi-GRU)[10]处理多行为交互序列,捕获数据的时序特征。
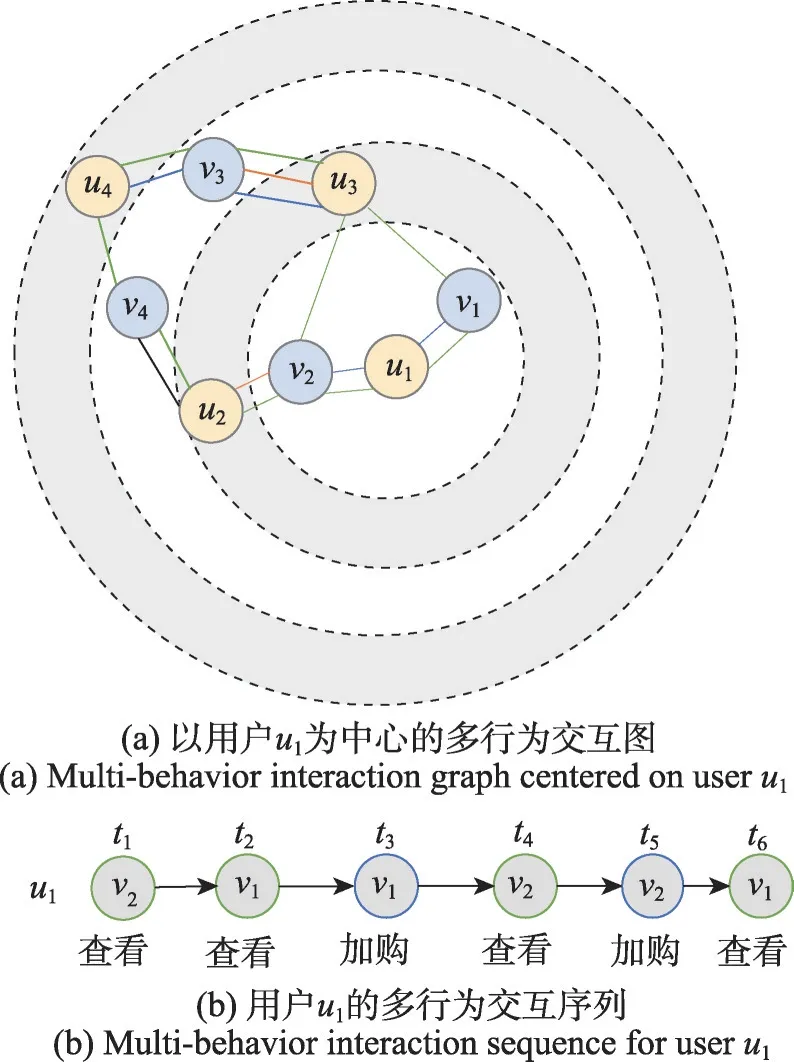
图2 多行为交互图和多行为交互序列示例Fig.2 Examples of multi-behavior interaction graph and multi-behavior interaction sequence
基于图神经网络和基于循环神经网络的多行为推荐方法都有效提高了推荐的准确率,但是也存在两个问题:
第一个问题,未能全面捕获行为之间复杂的依赖关系。MBGCN[5]和GHCF[6]都强调不同行为有不同重要性,通过区分行为的权重值聚合高阶邻域信息。这种方式只学习了行为的重要程度。KHGT(knowledge-enhanced hierarchical graph transformer network)[11]既强调了行为的重要程度,又强调行为之间的相互影响,首先利用图注意力机制获取行为权重,再利用注意力机制捕获行为特征相关性,即行为间的相互依赖关系,但这些方法都忽略了行为间的时序相关性,即行为的时序特征。DUPN[7]和DIPN[8]强调行为发生的先后顺序,用循环神经网络对多行为交互序列建模,可以有效捕获行为间的时序相关性,但无法捕获行为间的特征相关性。综上,两种多行为推荐方法都存在片面性,实际上同时捕获行为间的特征相关性和时序相关性有利于学习准确的用户特征。
第二个问题,忽略了行为特征与用户和商品的相关性。MBGCN[5]是根据用户在不同行为下的交互次数学习行为权重,只考虑了行为与用户的相关性。GHCF[6]中设置通用的行为向量,图卷积时根据行为和项目特征学习聚合权重,只考虑了行为与项目的相关性。实际上行为特征与用户和项目都存在相关性,行为与用户的相关性是指每个用户有不同的行为特征,行为与项目的相关性是指同一用户在交互不同项目时有不同的行为特征。例如用户u1买水果时往往先查看,然后直接购买。而购买笔记本电脑时则相对谨慎,通过查看、收藏和加购,然后才购买。即除了考虑不同用户有不同行为特征之外,还需要考虑同一个用户在购买不同商品时有不同的行为特征,因此同时捕获行为与用户和项目的相关性有助于获取更准确的用户和项目特征。
为了解决目前方法存在的主要问题,本文提出将行为依赖融入多任务学习的个性化推荐模型(integrating behavioral dependencies into multi-task learning for personalized recommendations,BDMR)。首先设置用户个性化行为向量来表示行为特征,利用图卷积网络处理多个单行为交互图,联合用户、项目和行为特征获取行为权重,聚合邻域高阶信息,获得基于行为的用户和项目特征,再通过自注意力机制学习多行为间的特征相关性;然后,将用户行为特征和项目特征构成的交互序列输入循环神经网络,挖掘多行为间的时序相关性;最终,将用户个性化行为特征融入多任务学习框架中获取更准确的用户、行为和项目特征,从而提高推荐性能。
1 相关工作
根据目前多行为推荐算法对多行为交互数据的处理方式不同,将其分为基于图神经网络和基于循环神经网络的多行为推荐算法。本章将介绍这两种多行为推荐算法,并分析目前研究中存在的问题,提出本文方法的解决思路,然后介绍多任务学习框架的功能以及其在多行为推荐中的应用。
1.1 基于图神经网络的多行为推荐算法
近年来,基于图神经网络的模型在推荐系统中得到了广泛的应用。图神经网络主要思想是采用深度神经网络来聚合邻居节点的特征信息,获取更丰富的用户和项目向量[12]。例如,GCN[13]、GraphSAGE[14]和GAT[15]分别采用卷积算子、长短期记忆网络和自注意力机制来聚合邻居节点的特征信息。目前图神经网络在多行为推荐中的应用日益广泛,MBGCN[5]利用图卷积网络对用户多行为交互图进行建模,通过用户交互次数学习行为权重聚合高阶邻域信息。KHGT[11]利用图注意力网络对用户多个单行为交互图进行建模,聚合高阶邻域信息时通过用户对项目的偏好学习聚合权重;再结合注意力机制学习多个行为之间的特征相关性。GHCF[6]中除了考虑图中节点信息,还引入边信息,图卷积时根据行为和项目特征学习聚合权重聚合高阶邻域信息。
利用图神经网络可以捕获节点的高阶邻域信息,获取更准确的用户和项目表示,但在计算行为权重时,未能同时考虑行为特征与用户和项目的相关性。并且基于图神经网络的多行为推荐算法需要基于预定义的图结构数据,因此无法有效地捕获节点的时序特征。
1.2 基于循环神经网络的多行为推荐算法
在现实生活中,用户的行为前后都存在极强的关联性甚至因果性,因此可以将用户和项目的交互建模为一个动态的序列并且利用序列的依赖性来捕捉用户的交互特征。推荐系统中常常利用循环神经网络来捕获用户行为的时序特征。目前常见的循环神经网络结构有循环神经网络(recurrent neural network,RNN)[16]、LSTM[9]、门控循环单元(gated recurrent unit,GRU)[17]以及它们的变体Bi-GRU[10]等。DUPN[7]中提出利用长短期记忆网络处理多行为交互序列,长短期记忆网络中同时输入项目特征以及对应的行为特征来捕获多行为交互的上下文信息和时序特征。DIPN[8]对DUPN 进行改进,提出利用Bi-GRU 捕获多行为交互序列的时序特征,并结合注意力机制进行信息整合,从而提高推荐性能。
将包含项目和行为特征的交互序列输入循环神经网络中,可以有效捕获项目上下文信息和行为的时序相关性。
1.3 基于多任务学习框架的多行为推荐算法
多任务学习(multi-task learning,MTL)是一种对不同但相关的任务进行联合训练的模式,多个任务并行训练并且相互影响[18]。多任务学习有很多形式,如联合学习、自主学习、借助辅助任务学习等[19]。在多行为推荐中,将每种行为的训练作为一个任务,借助辅助任务加强目标任务的学习,其中将训练辅助行为的预测模型作为辅助任务,将训练目标行为的预测模型作为目标任务。辅助任务的目标在于学习到共享参数的表示,来帮助目标任务的学习。辅助行为和目标行为的产生都是源于用户的兴趣,因此辅助任务与目标任务密切相关,在训练时可以学到有利于目标任务的表示。NMTR(neural multi-task recommendation)[2]根据行为发生的顺序设计级联关系,学习行为之间相关性,利用多任务学习框架改进辅助行为的预测模型,再进一步改进目标行为的预测模型。但NMTR 只通过行为发生顺序考虑多行为的相关性,未能充分发挥辅助任务的作用。因此EHCF(efficient heterogeneous collaborative filtering)[20]
提出利用映射机制将辅助行为映射到目标行为空间,可以充分学习辅助行为对目标行为的影响,从而更好地利用辅助任务加强目标任务的训练。
综上,目前多行为推荐算法未能全面捕获多行为之间特征相关性和时序相关性,并且只考虑了行为与用户的相关性或行为与项目的相关性,未能同时考虑行为特征与用户和项目的相关性。而有效捕获以上信息可以更好地利用多任务学习框架学习用户、行为、项目特征,为目标用户提供更准确的推荐。
2 提出的方法
2.1 问题定义
多行为交互图和多行为交互序列是本模型的重要输入。本文定义用户集合U={u1,u2,…,ui,…,uM}、项目集合V={v1,v2,…,vj,…,vN},ui和vj分别表示用户i和项目j。多行为交互图G={U,V,E},其中E代表图中边的集合,一个多行为交互图G包含多个单行为交互图Gk,Gk={U,V,Ek}表示k行为下的交互图,其中Ek代表k行为边的集合。边表示ui和vj在k行为下的交互情况,如果=1表示存在交互,=0表示不存在交互。多行为交互序列可以定义为Seq={s1,s2,…,st,…,sT},由用户的近期T个交互组成,其中st表示第t个交互,st包含两部分信息,表示为<vt,pt>,其中vt表示第t个交互中的项目信息,pt表示第t个交互中的行为类型。
通过输入多行为交互图G和多行为交互序列Seq,输出目标行为下用户u交互待推荐项目v的概率。
2.2 BDMR模型介绍
目前的多行为推荐算法,主要对行为之间的相关性进行研究。本文将行为之间的复杂依赖关系分为特征相关性和时序相关性。特征相关性是指行为与行为之间的相互影响,例如:加购行为比查看行为更能决定用户的兴趣,并且加购的商品更可能被购买。时序相关性是前一个行为的发生会对下一个行为产生影响,主要强调行为发生的时序特征,例如查看的商品可能被加购、收藏或直接购买。
目前多行为推荐算法中,利用图神经网络对多行为交互图进行建模或者利用循环神经网络对多行为交互序列进行建模,都未能全面地捕获多行为复杂的依赖关系,并且未同时学习行为特征与用户和项目相关性。本文提出将行为依赖融入多任务学习的个性化推荐模型(BDMR),提出用户个性化行为向量,利用图卷积聚合高阶邻域信息,联合用户、行为和项目特征计算聚合权重,结合自注意力机制学习行为之间的特征相关性。并利用长短期记忆网络捕获行为的时序相关性。
图3 中展示了该模型架构,模型主要分为三部分:(1)多行为图卷积层,分别对多个行为下的交互图进行图卷积,联合用户、行为和项目特征获取行为权重,聚合高阶信息,获得基于行为的用户和项目特征,再结合自注意力机制学习不同行为下的用户和项目特征相关性;(2)多行为循环神经网络层,将用户近期交互序列中的行为和项目特征同时输入长短期记忆网络学习多行为交互的上下文信息,获得多行为的时序相关性,再结合注意力机制获得与待推荐项目相关的用户特征;(3)多任务预测层,将(1)和(2)层中获得的用户特征整合获得用户最终特征,结合用户个性化行为向量以及多任务学习框架预测用户在目标行为下交互待推荐项目的概率。
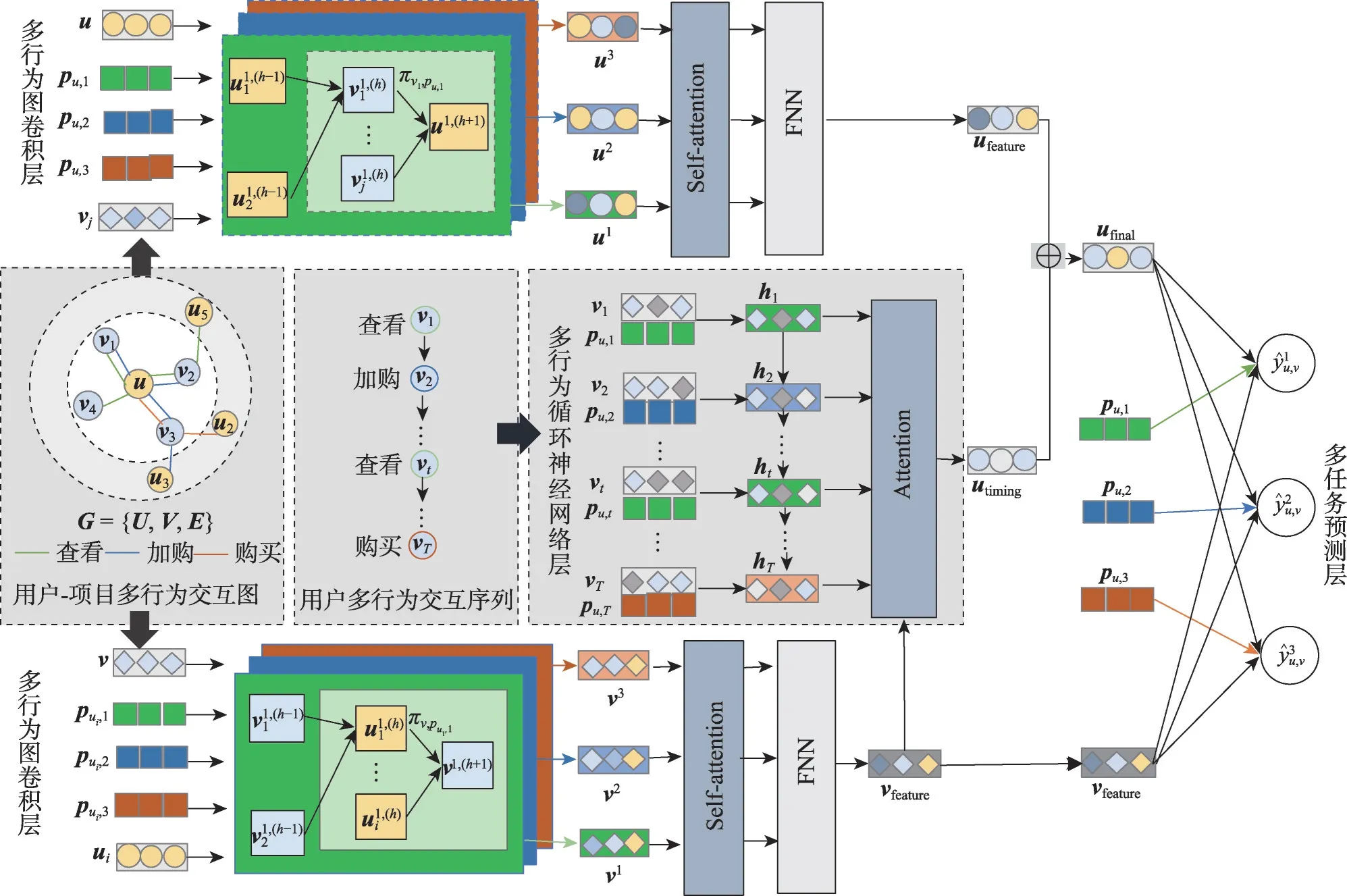
图3 BDMR模型架构Fig.3 Model architecture of BDMR
2.2.1 多行为图卷积层
图卷积网络的作用是加强用户和项目特征的学习。多行为图卷积层利用图卷积网络分别对K个单行为交互图进行建模,学习k行为下的用户特征uk和项目特征vk。利用图卷积对k行为下的交互图Gk={U,V,Ek}建模,建模时考虑到不同的用户存在不同的行为特征,因此设置了用户个性化行为向量pu,k,表示针对用户的k行为特征。在图Gk卷积过程中,将(u,pu,k,vj)作为三元组的(头节点,关系,尾节点),通过计算三者内积获得关系权重,以用户为例,聚合权重由用户u和(pu,k+vj)的内积得到。如图4所示。

图4 多行为图卷积层Fig.4 Multi-behavior graph convolution layer
其中,vj表示用户的交互项目,πvj,pu,k表示用户u在行为k下交互项目vj的权重,的值越大表示项目vj越符合用户在k行为下的兴趣特征。表示用户u在k行为下的邻居信息。是经过归一化后的权重值。
根据权重值将对应的邻域特征加权求和,更新用户和项目在k行为下的嵌入表示。
其中,uk,(h)和vk,(h)分别表示行为k下用户u和v在第h层的表示。其中uk,(0)即用户的初始嵌入u,其中vk,(0)即项目的初始嵌入v,经过H层的传播后,得到单个行为下多个用户和项目的表示,将这些表示合并得到用户和项目多个行为下的表示,以行为k下的用户表示为例:
然后,利用自注意力机制学习多行为之间的相关性,利用一层前馈神经网络(feedforward neural network,FNN),融合多行为下的用户交互特征,获得用户特征ufeature,ufeature捕获了多行为下的用户特征相关性。
2.2.2 多行为循环神经网络层
为了捕获行为之间的时序相关性,利用循环神经网络处理用户近期的交互序列,从而学习多行为交互的上下文信息以及行为的时序相关性。如图5所示:本文选取用户u的近期T个交互组成序列Seq={s1,s2,…,st,…,sT},其中每个交互st包含行为向量pu,t和项目向量vt,并按照时间顺序同时输入长短期记忆网络,长短期记忆网络的门控机制公式如下:
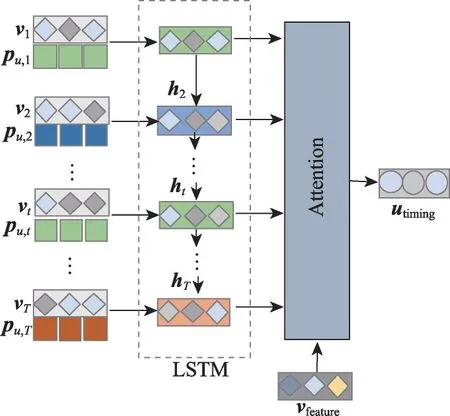
图5 多行为循环神经网络层Fig.5 Multi-behavior recurrent neural networks layer
其中,it、ft和ot分别表示t时刻的记忆门、忘记门和输出门。其中ct记录着长期稳定的信息,ht记录着短期局部的信息。将t时刻的行为特征pt和项目特征vt输入记忆门it和忘记门ft,选择ct-1需要保留和遗忘的特征。再经过输出门更新得到短期记忆ht。
同时为了更准确地判断当前用户交互待推荐项目的可能性,本文利用长短期记忆网络每层的隐藏层输出ht,输入注意力机制学习每个时刻的历史交互特征与待推荐项目的相关性。首先定义注意力机制中的Q∈Rd×d,K∈Rd×d,V∈Rd×d,计算每个交互输入值的权重。由查询值和键值的内积决定,具体实现公式如下:
其中,βv,ht是待推荐项目v和t时刻的记忆ht的相关性得分。根据归一化后的进行加权聚合,获得utiming,utiming捕获了多行为之间的时序相关性。
2.2.3 多任务预测层
多行为图卷积层通过捕获多行为之间的特征相关性学习用户表示ufeature,多行为循环神经网络层通过捕获多行为之间的时序相关性学习用户表示utiming,将两者结合在一起得到用户u的最终表示:
模型采用内积来计算用户u在k行为下交互待推荐项目v的概率得分:
最后,利用多任务学习框架,同时训练多个行为的预测模型,在训练阶段,采用Adam 算法来优化以下目标函数:
其中,K表示行为类型总数,λk是超参数。λk可以根据数据集进行调整,用来控制k行为对整体训练的影响,其中。
2.2.4 BDMR模型训练过程
算法1BDMR
2.2.5 BDMR复杂度分析
BDMR 模型主要包括多行为图卷积层和多行为循环神经网络层,因此整体计算复杂度是两部分复杂度之和。多行为图卷积层包含图卷积和自注意力运算,其中图卷积的计算复杂度为O(K×(M+N)×d2+|E|×d),K表示行为个数,M和N分别表示用户和项目个数,|E|表示交互图中边的个数,d为嵌入维度;自注意力运算的复杂度为O(K×d2+K2×d)。多行为循环神经网络层包含LSTM 和注意力运算,计算复杂度为O(2×T×d2+T×d),其中T为多行为序列输入个数。另外,本文模型中K的取值在[1,4]之间,T的取值在[15,30]之间。综上,多行为图卷积层的复杂度远远大于多行为循环神经网络层的计算复杂度。因此,BDMR 的计算复杂度相当于基于图神经网络的多行为推荐算法(MBGCN、KHGT、MBGMN(multibehavior with graph meta network)、GHCF)和其他多行为推荐算法(NMTR、DIPN、EHCF)的计算复杂度。总之,本文模型BDMR 的计算复杂度可以达到与最先进的多行为推荐算法(EHCF、MBGMN、GHCF)相当的计算复杂度。
3 实验及分析
本章主要介绍实验数据集、评估指标、实验基准和参数设置,在Yelp、ML20M 和Tmall 数据集上进行对比实验,并对实验结果进行分析,最终验证BDMR模型能有效提高推荐性能。
3.1 数据集
Yelp:美国著名商户点评网站。根据用户对商户的评论数据和评分数据分为四种行为类型:(1)评价表示用户对商户进行了评论;(2)不喜欢表示用户对商户进行了评分且评分r≤2;(3)中立表示用户对商户的评分2 <r<4;(4)喜欢表示用户对商户的评分r≥4。这里将{喜欢}设置为目标行为。
ML20M:MovieLens 公共数据集存储了用户对电影的评分信息,被广泛用在推荐系统中,本文选取ML20M 作为实验数据集,按照用户的评分使用与Yelp相同的划分标准。共划分为三种行为类型{不喜欢,中立,喜欢},并将{喜欢}设置为目标行为。
Tmall:在线商城网站,本数据集从天池平台获取,为保证每个用户有足够的训练数据,过滤掉了交互数量少于5 个的用户和项目。数据集中主要包含四种行为{查看,加购,收藏,购买},并将{购买}设置为目标行为。
表1展示了这些数据集的详细信息,其中字体加粗部分表示目标行为。
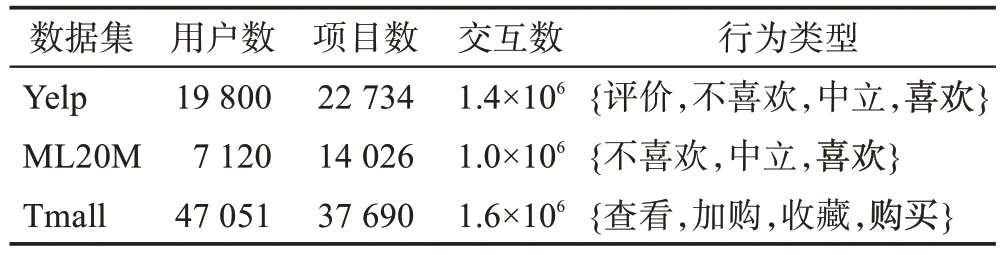
表1 数据集详细数据Table 1 Detailed data of dataset
3.2 评估指标
实验中采用了两种常用的评价指标来评估模型性能,分别为命中率(hit ratio,HR)和归一化折扣累计增益(normalized discounted cumulative gain,NDCG)。
HR 表示测试集中出现在Top-K推荐列表中的项目个数占测试集中总项目个数的比例。HR 值越大说明命中率越高。
其中,GT为测试集合中的项目总数,Number of Hits@K表示Top-K推荐列表中包含的测试集项目数量。
NDCG 表示测试集中项目在Top-K推荐列表中相关性和排序的综合评估得分。NDCG 值越大说明排序结果越优。
其中,reli表示项目i的相关性得分,DCGu@K同时考虑相关性和顺序因素,计算用户u推荐列表中前K个项目的得分,IDCGu@K是DCGu@K归一化后的结果,NDCG@K是将所有用户的平均值作为最终分值。
3.3 实验基准
为了验证本文提出模型BDMR 的有效性,共对比了7个方法。
(1)NMTR[20]:按照行为发生顺序设置级联关系,引入多任务学习框架同时训练多个行为的预测模型,借助辅助任务加强目标任务的学习。
(2)EHCF[2]:利用Trans 方式学习多行为间的相关性,引入多任务学习框架对多个行为的预测模型联合训练。
(3)DIPN[8]:利用双向递归网络学习用户交互序列的上下文信息,并结合注意力机制来学习行为序列之间的依赖关系。
(4)MBGCN[5]:利用图神经网络学习用户和项目特征,根据用户在不同行为下的交互次数学习行为权重,行为权重决定了行为对用户偏好的影响程度。
(5)KHGT[11]:利用图注意力网络捕捉每个行为语义特征,并结合注意力机制学习行为之间的相关性。
(6)MBGMN[21]:利用图神经网络对行为语义编码,利用注意力机制学习行为之间的依赖关系以及个性化多行为模式。
(7)GHCF[6]:利用图神经网络学习用户和项目特征,行为和项目特征决定聚合权重,并结合多任务学习框架,同时提高其他行为和目标行为的推荐准确率。
3.4 参数设置
实验中,模型基于TensorFlow 框架实现,三个数据集的设置见表2。epoch 指模型训练次数,三个数据集的训练次数都是120;lr指学习率;batch_size指批次大小;d指用户、项目和行为特征的嵌入维度;H指图卷积层数;T表示近期交互个数。另外分别将Yelp、ML20M 和Tmall 数据集中多任务权重参数λk设置为[1/6,1/6,1/6,3/6],[1/3,1/3,1/3],[1/4,1/4,1/4,1/4]。每个数据集的λk之所以不同,是因为不同数据集中每个任务对用户和项目特征优化的影响程度不同。同时为了保证实验结果的准确性,本模型以及其他对比基准都在相同环境配置下运行。

表2 模型参数设置Table 2 Model parameter setting
3.5 模型性能评估
表3 展示了所有基准方法在三个数据集上的实验结果。首先,本文提出的模型BDMR 相对于其他基于多任务的多行为推荐模型(NMTR、EHCF)结果更好,主要是因为NMTR 只能捕获多行为交互之间的顺序依赖特征;EHCF 利用映射机制学习了行为之间相互依赖关系,但未能捕获用户个性化行为模式,两种多任务模型都存在局限性,未能完全捕获行为之间的复杂依赖关系。其次,BDMR 相对于其他图神经网络模型(MBGCN、KHGT、MBGMN、GHCF)的实验结果高,证明了捕获行为时序相关性的有效性。在图神经网络基础上应用多任务学习框架的模型(MBGMN、GHCF)相对于只使用图神经网络的模型(MBGCN、KHGT)整体性能更优,说明多任务学习框架能有效提高多行为推荐性能。同时BDMR 的实验结果较循环神经网络模型(DIPN)的实验结果有明显提升,证明了BDMR 中利用图神经网络捕获了用户和项目的高阶协同信息能有效提高推荐性能。
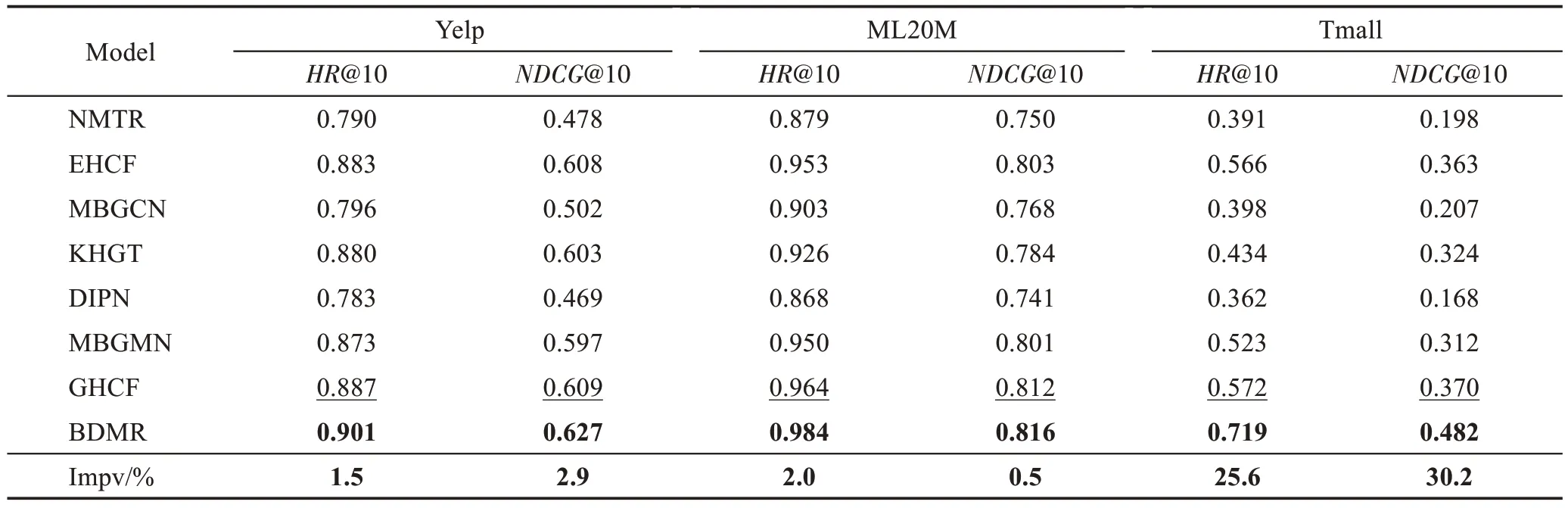
表3 在不同数据集上的NDCG@10和HR@10性能比较Table 3 Performance comparison on different datasets in terms of NDCG@10 and HR@10
同时EHCF 和GHCF 相对其他模型性能较优,原因是这两种模型采用非采样学习机制,有效利用了所有交互数据。总体来看,BDMR 的推荐性能高于其他基准的性能。本模型的主要优势是:能有效利用图神经网络中的高阶邻域信息,增强用户和项目的表示;并且有效学习多行为之间的复杂依赖关系,利用自注意力机制学习行为之间的特征相关性,利用循环神经网络学习行为的时序相关性;同时设置用户个性化行为向量,捕获了用户个性化行为特征,图卷积时利用用户、行为和项目计算权重,学习行为与用户和项目的关联特征。
为了进一步验证模型BDMR 的有效性,并且使实验结果直观和清晰,根据表3 的实验结果,本文从基于多任务学习框架(NMTR、EHCF)、基于图神经网络(MBGCN、KHGT)、结合了图神经网络和多任务学习框架(MBGMN、GHCF)以及基于循环神经网络(DIPN)的多行为推荐算法中选择了性能较优的4 个算法,分别是EHCF、KHGT、GHCF、DIPN,然后改变K值评估模型性能。图6 显示了Tmall 数据集下的评估结果,从实验结果中看出BDMR 在不同K值的实验结果始终高于其他模型,说明BDMR 能有效捕获行为与用户和项目的关联特征,以及行为之间复杂的依赖关系,从而能准确地给用户推荐更符合其偏好的项目。

图6 Tmall数据集上Top-K推荐的性能比较Fig.6 Performance comparison of Top-K recommendations on Tmall dataset
3.6 子模块消融研究
为了验证图卷积神经网络、循环神经网络以及多任务学习框架对本文模型BDMR 性能的影响,使用BDMR 模型的3个变体W/O GCN、W/OLSTM 以及W/OMTL 在3 个数据集上进行比较,实验结果在表4中展示,其中:

表4 BDMR子模块的消融研究Table 4 Ablation studies of sub-modules in BDMR
W/O GCN 取消多行为图卷积层,保留循环神经网络和多任务学习框架;
W/O LSTM 取消多行为循环神经网络层,保留多行为图卷积层和多任务学习框架;
W/O MTL 取消多任务学习框架,只保留购买行为的目标函数。
表4 展示了消融实验的研究结果,3 个变体模型相对于整体模型BDMR 实验结果都有降低。可以得到如下结论:移除模型中任意一个模块都导致模型的推荐性能下降,说明模型中捕获多行为之间的复杂依赖关系、行为与用户和项目的相关性,都能提升模型的推荐性能。同时多任务学习框架的应用可以有效提高目标行为的推荐性能。
3.7 超参数效果研究
为了评估不同参数对推荐性能的影响,本文展示了BDMR 在不同超参数设置和不同数据集下的实验结果。主要对以下4个超参数进行调整。
用户和项目的嵌入维度d:适中的维度可以有效学习用户和项目的特征,而过高的维度可能导致过拟合,并且时间复杂度较高。本文将用户、项目、行为设置为相同的嵌入维度,并在8~32 范围内修改维度,使模型结果达到最优。如图7(a)、(b)所示,随着嵌入维度的增加,模型性能逐渐增加,当嵌入维度为32时,模型取得较优结果,并且嵌入维度由16增加到32 时,性能提升幅度较小,为了保障模型的运行效率,本文将3个数据集的最优嵌入维度都设为32。

图7 嵌入维度d对性能的影响Fig.7 Impact of embedding dimension d on performance
多行为图卷积层中图卷积层数H:通过叠加卷积层数可以有效学习用户-项目的高阶协同信息,使推荐性能提高。如图8(a)、(b)所示,3 个数据集在图卷积层数为2 时,性能达到最优。当层数增加到3 时,性能反而下降,其原因是经过多层卷积之后获得的节点特征变得相似,从而无法提升性能。
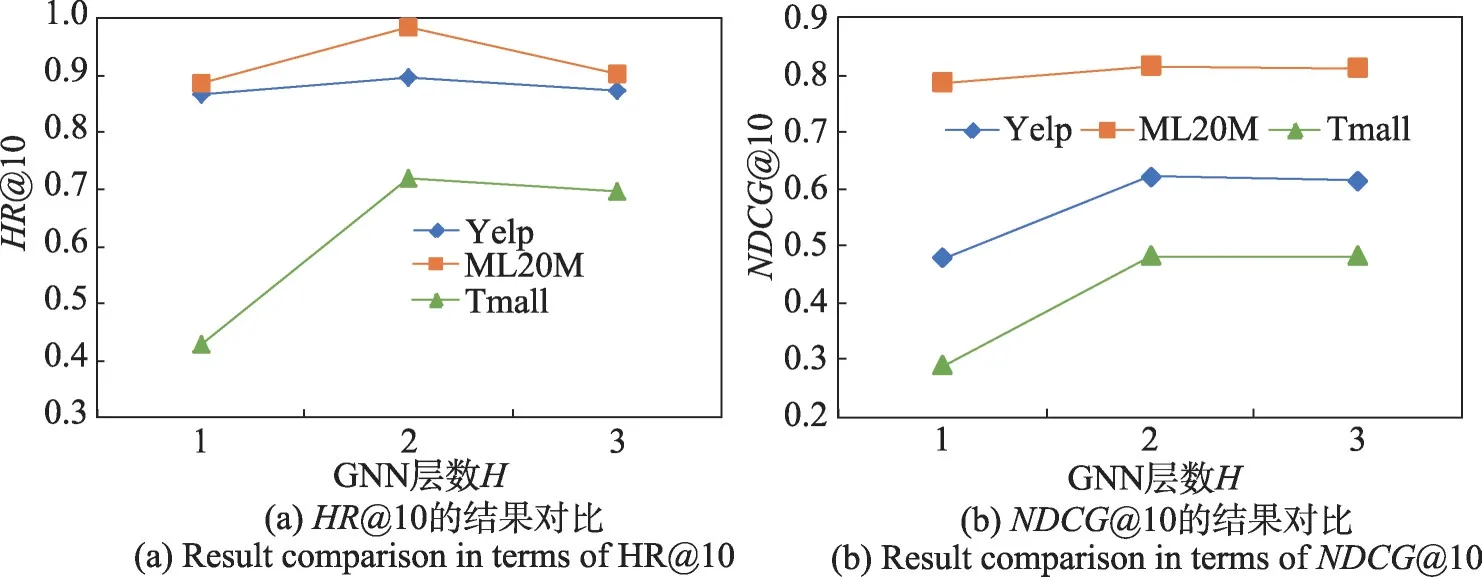
图8 GNN层数对性能的影响Fig.8 Impact of GNN layers on performance
多行为交互序列中近期交互个数T:Yelp、ML20M、Tmall 的平均交互数分别是70、52、34。图9中展示了模型在3 个数据集下的近期交互个数T分别为30、20、15 时结果为最优,说明近期交互个数并非越高越好,多行为循环神经网络层除了能有效捕获行为的时序相关性之外,还能有效捕获用户近期偏好。

图9 近期交互个数对性能的影响Fig.9 Impact of number of recent interactions on performance
目标函数中多任务的分配权重λk:在多任务学习框架中λk的分配很大程度影响着BDMR 的推荐性能。在数据集Yelp 和Tmall 中有4 种行为类型,需要设置4 个权重参数λ1、λ2、λ3、λ4,其中每个λk参数从[1/6,1/4,1/3,1/2]中选值,并保证λ1+λ2+λ3+λ4=1,同理,ML20M 数据集需要设置3 个权重参数λ1、λ2、λ3。每个λk参数从[1/6,1/3,1/2]中选值,并保证λ1+λ2+λ3=1。本模型根据实验结果调整λk使结果达到最优,最终Yelp 数据集中λ1、λ2、λ3、λ4分别设置为[1/6,1/6,1/6,3/6]时达到最优值;ML20M数据集中λ1、λ2、λ3分别设置为[1/3,1/3,1/3]时达到最优值;Tmall 数据集中λ1、λ2、λ3、λ4分别设置为[1/4,1/4,1/4,1/4]时达到最优值。
4 结束语
针对目前多行为推荐算法中未能全面捕获多行为之间复杂的依赖关系,忽略了行为特征与用户和项目的相关性等问题,本文提出将行为依赖融入多任务学习的个性化推荐模型(BDMR)。首先,设置针对用户的行为向量,学习用户个性化行为特征;其次,利用图卷积神经网络捕获不同行为下用户和项目的高阶协同信息,并且同时考虑用户、行为和项目三者相关性获取行为权重,再结合自注意力机制学习行为的特征相关性;然后,利用长短期记忆网络学习行为的时序相关性;最后,将个性化行为特征融入多任务学习框架获取更准确的用户、行为和项目特征。为了验证本模型的有效性,对比了多种多行为推荐模型,实验结果显示,在3个真实数据集上BDMR都比KHGT 和DIPN 的结果更优,说明BDMR 模型能有效捕获行为之间的复杂依赖关系。同时相比MBGCN和GHCF取得更好结果,说明BDMR模型有效学习了行为与用户和项目的相关性。
尽管BDMR 模型能有效提升推荐性能,但是利用多任务学习框架需要人工调整多任务的权重参数,并且为使模型达到最优性能,需要为不同模型设置不同的权重分配方案。因此下一步的工作是对模型中多任务的权重参数的分配方案进行改进,使其能够自适应学习权重,从而为用户提供更优更精准的推荐。
