融合知识图谱的影视视频标签分类算法研究
2024-01-11蒋洪迅孙彩虹
蒋洪迅,张 琳,孙彩虹
中国人民大学 信息学院,北京 100872
随着视频的形式越来越成为互联网信息主体,文本的比例越来越低,视频内容理解和识别变得越来越重要。内容理解(content understanding)是计算机的一种能力,包括对内容的吸收、处理、关联,最后形成结构化数据。在影视场景下,视频的类目体系是视频网站运营中的重要工具,也是进行数据分析和推荐算法中提升冷启动效果的重要手段,因此构建一套合理、准确率高、覆盖率高的视频标签类目体系必不可少。
视频标签可以理解成描述一个视频的几个关键词,当看到视频标签的时候就可以大概知道这个视频的内容,作为内容理解的一环,层级分类的视频标签是很有效的一种管理方式,可以达到让机器理解海量的视频中的关键信息的目的,有助于视频网站中基于内容的推荐和分发。具体来说,类目体系是一套类目的划分标准,这个标准具有多层次的、经过讨论定义明确的、视频内容涵盖全面的特点。在影视场景下,一般来说会构建一个如图1所示的三级类目体系,包括类型标签、题材标签和实体标签;其中类型标签、题材标签、实体标签都是内容标签的更细粒度标签。
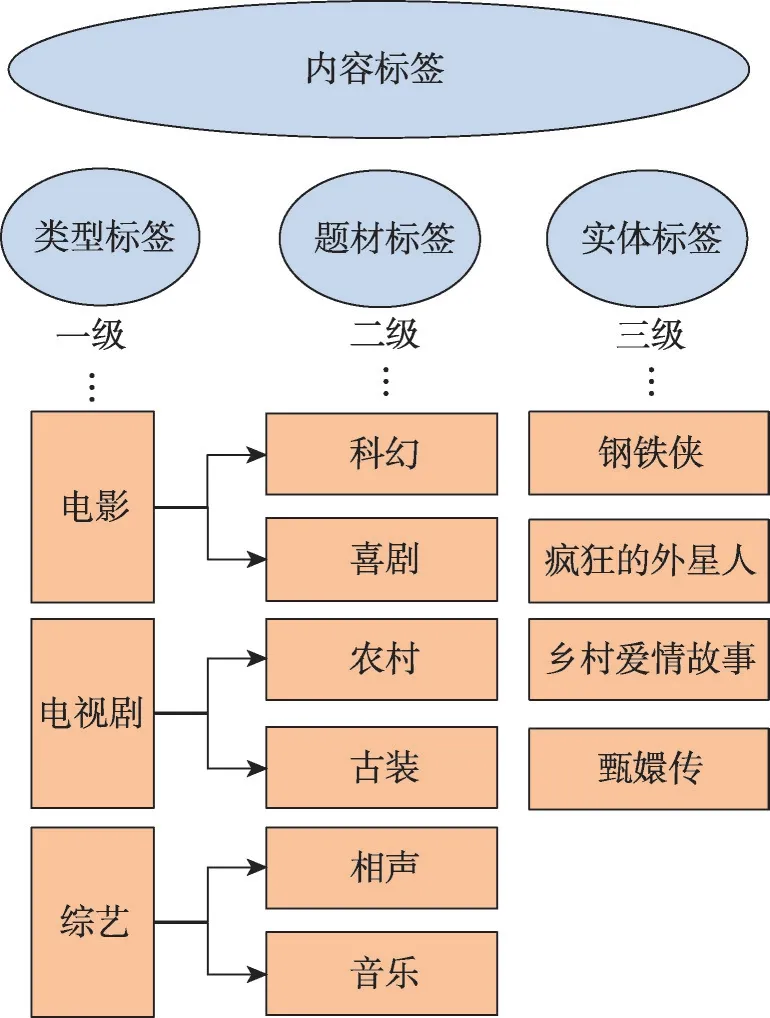
图1 影视视频标签体系示意图Fig.1 Diagram of video labeling system
标签分类模型是依据标签类目体系构建的,通过算法赋能,使得视频标签类目体系可以在各个业务方面发挥价值。根据实践的经验发现,当前影视场景下的视频标签分类模型存在以下两个问题:(1)数据标注少。互联网用户上传的视频在内容和质量方面存在很大的差异,用户生成的标题通常不完整或者模棱两可,并且可能包含错误。虽然有很多的视频影视剧,但是高质量数据标注量较少。(2)实体标签细粒度不够。虽然当前一些视频标签分类的基线模型在影视场景下整体的标签识别上得到不错的效果,但对于一些在视觉上相似的剧集处理得不好,需要增加特征做进一步识别。
本文的贡献主要体现在多任务标签预测的研究角度和最细粒度内容标签的实体纠错处理上。相比以往的同类研究,本文跳脱了通常的大规模语料训练标签分类算法,更多着眼于实体纠错的新研究角度,在方法上也不再局限于传统的按级别的分层标签预测分析,而是基于多模态预训练模型和影视资料知识图谱提出了一个两阶段的视频标签分类框架和实施方法,如图2 所示。具体来说,创新点主要体现在三个方面:在特征输入方面,使用了基于大规模通用数据训练的多模态预训练模型提取视觉和文本的特征,训练了一个多任务的视频标签预测模型,同时获取视频的类型、题材和实体三级标签;在模型结构方面,提出了一种基于多任务学习框架的视频标签分类模型,在多任务学习网络中引入相似性任务提高了分类模型训练的难度,使得同类样本特征更加紧密,同时保证所学特征能更好地表达样本差异,避免了样本偏斜造成的局限性和过拟合,保证预测效果、客观性和泛化能力;在实体纠错方面,不再局限于现有语料内的孤立信息,而是引入外部知识图谱的共现信息,通过一个局部注意力头扩展的实体纠错模型,对前置模型的预测结果做修正,得到更准确的实体标签预测结果。本文后续的多任务消融实验也验证了所提方法在较细粒度标签分类问题上的有效性,而且新方法可以在少量样本上达到较好的分类效果,表明该模型也适用于其他领域内的数据集较少的情况下的分类任务。
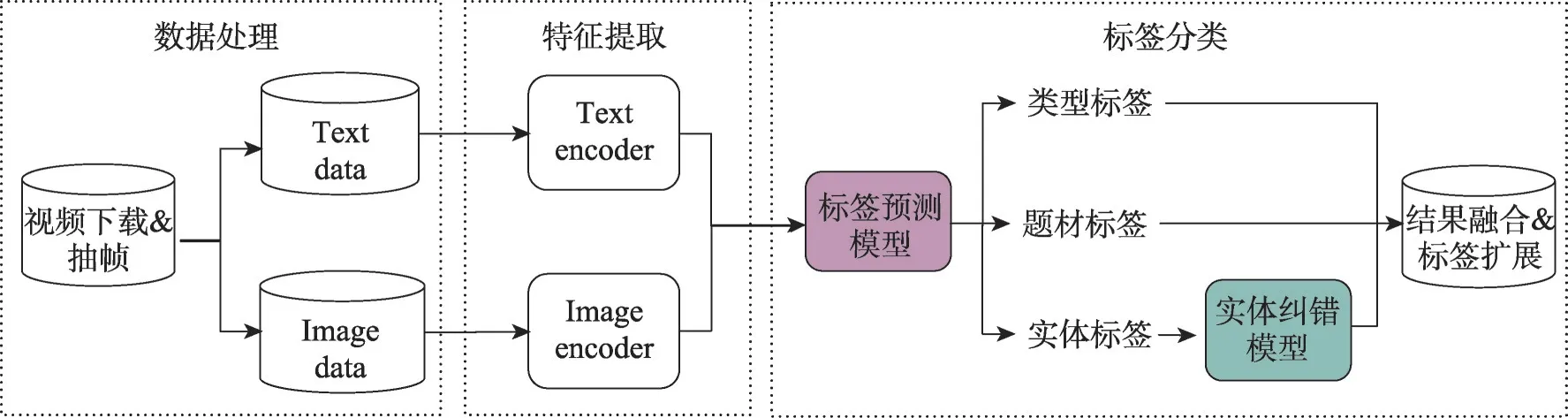
图2 影视视频标签分类模型架构图Fig.2 Architecture diagram of proposed video labeling model
1 影视视频标签分类相关工作
1.1 视频标签分类模型
视频标签研究属于分类任务,学术界中视频标签分类算法的研究经过了长时间的发展。一般来说,视频标签分类的处理流程可以分为以下三个步骤:第一,数据的采样和预处理;第二,学习视频的时间和空间特征;第三,时序特征的动态融合。视频标签研究可以分为纯视频标签分类算法和多模态预训练模型两个方向。
传统视频标签分类算法是指只涉及视频图像帧输入的算法。得益于近些年深度学习的快速发展和机器性能的大幅提升,视频标签分类主流算法已经从传统手工设计特征变成端到端深度学习的方法。视频标签分类的相关工作中,使用深度卷积神经网络和时间序列模型相结合的方式学习时间和空间特征是目前的研究热点。一般的做法是,将视频抽帧之后,用二维的卷积神经网络(two dimensional convolutional neural network,2D-CNN)抽取视频里面每一帧的特征,然后将所有帧的特征平均池化到一起变成视频特征进行分类[1]。但是这种做法的问题在于视频往往包含的帧数非常多,对每一帧都抽取特征会有非常大的计算开销,并且对特征做平均池化难以捕捉视频的时序信息。针对视频抽帧问题,TSN(temporal segment networks)模型[2]提出基于片段间隔采样的方法来解决连续抽帧导致计算开销大的问题,同时采用分段共识函数来聚合采样片段中的信息,在整个视频上对长时间依赖的结构进行建模。针对视频时序信息,引入了循环神经网络来学习视频序列数据,TT-RNN(tensor-train recurrent neural networks)模型[3]将张量分解的方式应用于循环神经网络模型,使用训练好的张量替换原始输入层到隐藏层的权重矩阵,在同样效果下计算复杂度低于原始循环神经网络模型。NetVLAD(net vector of locally aggregated descriptors)模 型[4]、NextVLAD(next vector of locally aggregated descriptors)模型[5]使用聚类算法聚合视频帧中图像局部特征,在降低特征维度的同时还能很好地保证模型的性能。由于NetVLAD模型的缺点是特征维度高且计算复杂,分类模型需要上百万的参数。为了解决NetVLAD 中参数爆炸的问题,在NetVLAD 模型的基础上,在其VLAD 层增加了非线性参数,降低了其输出层参数[6],从而整体参数量下降,但性能并不下降。同时还使用了注意力机制来聚合时间维度的信息,得到视频中不同帧的分类贡献度。在最近的研究中,3D CNN(three dimensional convolutional neural network)对图像序列采用3D 卷积核进行卷积操作,同时捕获视频中的时间和空间特征信息。I3D 模型[7]在网络中加入了光流信息作为输入,将特征提取网络里面的2D 卷积核展开成3D 卷积核来处理整个视频,视频图像和堆叠的光流两个流的结果融合作为最终输出结果。Non-Local模型[8]则在3D ResNet 模型里面引入了自注意力机制,通过注意力学习时间和空间的全局信息,相当于扩大了卷积核的感受野。同样基于注意力机制,Attention Cluster 模型[9]将经过卷积神经网络模型抽取的特征使用堆叠的注意力模块集成局部关键特征。Slow-Fast模型[10]引入快和慢两个不同时间分辨率的通道,分开处理空间维度信息和时间维度信息,学习视频的静态和动态变化。同时,通过快和慢两个分支,SlowFast 模型探讨了不同采样率下双流信息交互融合的方式。此外,Regularized-DNN(regularized deep neural networks)模型[11]提出了一种正则化特征融合网络,在神经网络中加入正则化来利用特征之间的关系和类别之间的关系自动学习维度特征相关性,可见多特征融合也是一个研究的方向。
在视频标签分类领域,多模态预训练模型通常包括图像模态的信息和文本模态的信息。对于图片和文本的多模态预训练模型,从模态的交互方式上,可以分为单流模型和双流模型两种。在单流模型中,语言模态的信息和视觉模态的信息融合之后整体作为输入,然后直接输入到编码器中。单流模型代表的模型有VisualBERT(visual bidirectional encoder representation from transformers)[12]、Unicoder-VL(universal encoder for vision and language)[13]、ImageBERT(image bidirectional encoder representation from transformers)[14]、VL-BERT(vision and language bidirectional encoder representation from transformers)[15]等。基于图像切块投影的ViL-Transformer(vision-and-language transformer without convolution or region supervision)模型[16]也延用了单流交互方式,减少引入额外的计算量,将图片拆分成若干个Token 进行编码。在双流模型中,语言模态的信息和视觉模态的信息会先分别经过两个独立的编码器,得到编码特征后再输入到模态的交互层,不同模态的信息在语义上的对齐和融合是在模态交互层上完成的。在交互编码层中,模型使用共同注意力机制,即自注意力模块中的查询向量(Query)来自一个模态,而键向量(Key)和值向量(Value)来自另一个模态。经过交互层的编码后,图像特征和语言特征会分别再经过一个自注意力网络层来学习高阶特征。双流模型代表有ViLBERT[17]等模型。目前单流模型和双流模型的特征编码器都是基于Transformer 框架搭建的,不同在于模态融合时是否进行了关键向量的交互学习。这些多模态预模型在训练时需要标签类别信息进行有监督训练,依然存在对大规模标签类别标注的依赖性。而对比自监督训练方式则可以较好地解决这个问题。对比自监督学习是一种训练编码器的简单思路,关键思想是在特征空间中最小化正样本对之间的距离,最大化负样本对之间的距离,使得编码器对相似内容输出相似的结果。基于对比自监督学习的思想,通过编码点积计算即可获得两个内容之间的匹配程度。CLIP(contrastive language-image pre-training)模型[18]基于比对自监督方式采用4 亿对图像-文字进行预训练,将分类模型转换为图文匹配任务,用文本弱监督图片分类,学习文本与图片相关性,在多个下游任务中获得了非常好的实验效果。
1.2 多任务学习
多任务学习是指基于共享表示,同时训练多个任务的机器学习方法。训练过程中,多个任务共享样本信息、模型参数以及底层的表征信息,多个任务的损失值合并计算后同时驱动梯度进行反向传播,从而完成层次结构信息的使用,优化模型的网络层参数[19]。细粒度识别的关键挑战是生成有效的特征表示,以减少类同图像之间的差异,同时扩大不同类图像之间的差异。Parkhi 等人[20]提出首先使用分类损失函数学习人脸分类的同时使用相似性损失函数来微调和提升性能,最终提升了人脸识别的准确性。秦佳佳[21]也在心理研究角度说明了相似性任务在类别学习中的有效性。在本文中,细粒度的图像理解旨在区分每一个影视剧集,这个任务存在两个挑战:一方面,许多影视剧集之间具有高度相关性,并且场景图像之间存在细微差异难以区分(类间方差小);另一方面,同一部影视剧存在场景、人物、背景的转换,当以不同的姿势、光照、场景、人物和遮挡物呈现时,同一部剧集的画面看起来会有很大不同,视觉上效果差异较大(类内方差大)。在分类预测阶段,本文设计了一个多任务深度学习框架,将多个任务合并学习,通过分层非线性映射来学习细粒度图像识别的有效特征。
基于视觉信息训练的单模态视频标签分类模型一般是对数据进行端到端的训练,需要较大规模的数据量。不过数据标注成本较大并且大规模数据集的训练也非常消耗算力[22],零样本学习、基于预训练模型的迁移学习逐渐成为新的研究趋势,旨在达到从已知样本到未知类别的知识泛化学习[23]。基于图片、文本等信息的多模态视频标签分类模型则可以很好地利用文本和图片信息的交互知识,但有监督学习仍然存在数据依赖,而CLIP 可以利用文本对图片进行弱监督学习。
1.3 待解决问题
本文要研究的影视视频标签分类算法属于视频标签分类任务,即从一段视频提取若干关键帧,为它们打若干标签后再聚成该视频的标签。但是影视视频标签分类与通用领域的视频标签分类不同的是,其关键区分特征多与画面内容、人物关系、场景布局、台词字幕等因素有关,不能直接使用在通用领域数据集上预训练的模型完成预测。况且影视领域目前还没有一个标注好的大规模数据集,本文将在CLIP 图文预训练模型下游添加影视数据集,采用图文预训练模型+下游分类任务微调的形式,将多层级标签视为多个分类任务,每一个分类任务同时结合分类损失函数和相似性度量损失函数进行标签预测,在少量样本上达到较好的分类效果。
2 融合知识图谱的影视视频标签分类算法
本文提出了一种融合知识图谱的影视视频标签分类模型,该模型旨在通过图像-文本两个模态建模,利用视频中丰富的语义信息为视频内容打上多层次的标签;同时,针对更细粒度标签识别的困难样本,结合知识图谱信息完成进一步的知识推理过程,最终得到影视视频更准确的内容标签。
2.1 标签预测模型
本文构建的标签预测模型,其总体架构如图3所示,由输入模块、特征提取模块、模态融合模块和多任务分类预测模块组成。具体来说,模型采用了图文预训练模型+下游分类任务微调的形式,将多层级标签的识别视为多个孤立的分类任务,对于每一个分类任务都结合分类损失函数和相似性度量损失函数进行预测。
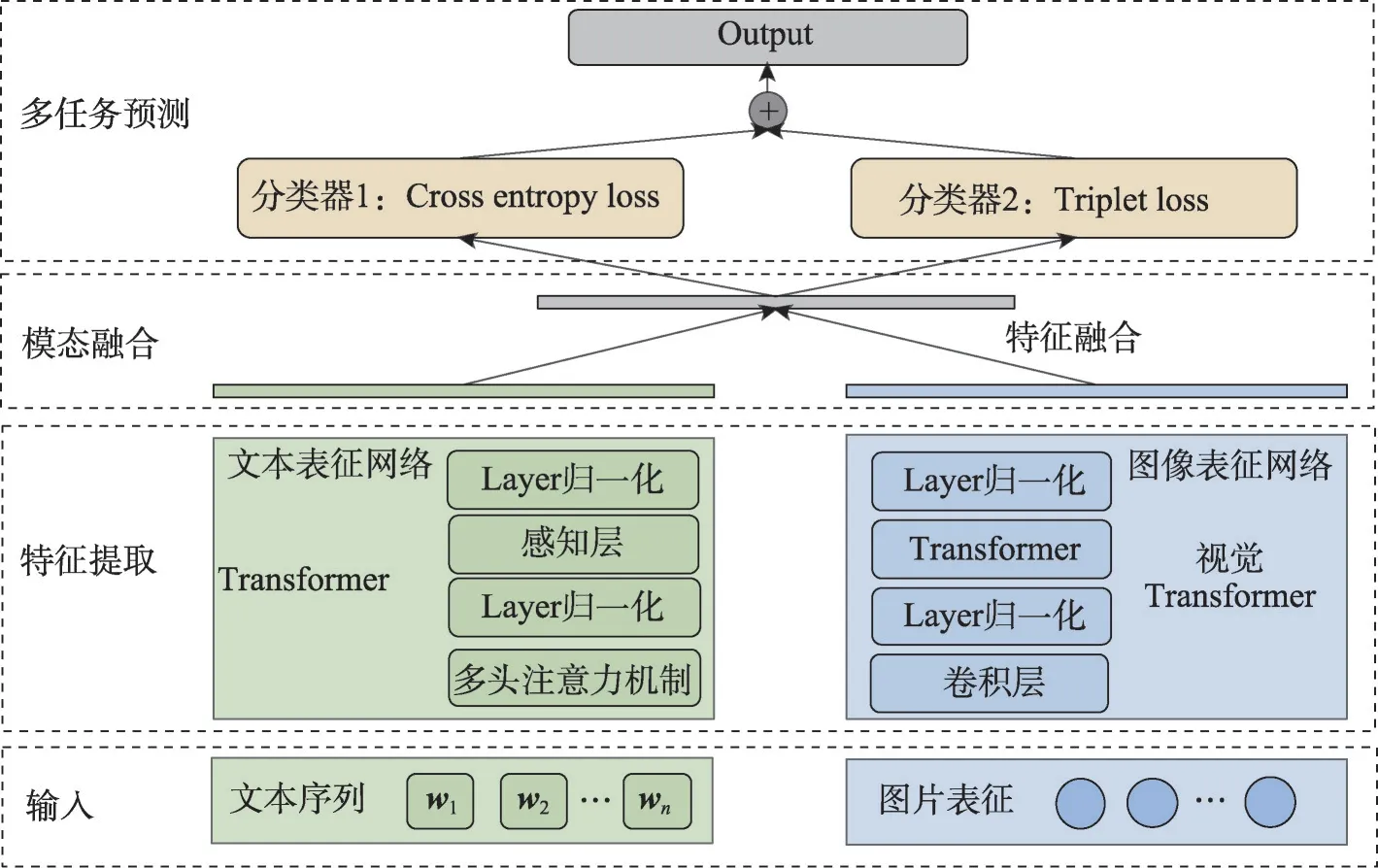
图3 标签预测模型的算法框架图Fig.3 Algorithmic framework diagram of label prediction model
标签预测流程可以概括为,给定一组图文对输入,包括文本序列{w1,w2,…,wn}和图片编码{r1,r2,…,rn},其中每条文本会被切分为若干个Token 进行编码,两个序列分别经过文本和图像特征提取分支,训练获得同一语义空间下的表征,特征融合后馈送到下游任务层进行预测,优化模型参数最小化损失值,最终得到预测结果。
2.1.1 特征提取网络
特征提取模块采用了基于大规模通用图文数据训练出的多模态预训练模型,文本、图像表征网络接收文本、图片两个模态的输入,分别通过一个图像编码器和一个文本编码器计算图像和文本的特征,再分别进行L2 范数的归一化操作,让文本特征和图像特征的特征尺度保持一致,得到文本特征Embt和图像特征Embi。具体过程参见算法1。
算法1特征提取网络
在文本分支中,将{w1,w2,…,wn}中每个token 的词向量和位置向量相加作为输入向量。文本是有序的,位置向量是指将token 的前后语序信息编码成特征向量的形式,把单词的位置关系信息引入到模型中,从而获取文本天生的有序信息。然后将输入向量馈送到Transformer的Encoder中来编码输入,每一个Encoder 中包含两个子层:第一层是多头自注意力机制,包括12 个注意力头;第二层是前向传播层,用来提高模型的非线性拟合能力。每个子层都使用了残差网络,在训练过程中可以缓解梯度消失的问题,使之可以构建更深层的网络。整个Transformer 共堆叠了12 个这样的Encoder 结构。最后将Transformer的输入馈送到layer norm 网络中对样本特征做归一化,得到1 024维特征Embt。
在图像分支中,深度卷积网络中的卷积和池化操作用于分层提取视觉特征。输入是单张图片,首先调整输入图片的大小格式,将给定图像缩放到224×224 的大小,按比例裁剪图片,保留最中间的图像部分,再对图片每个通道的像素值执行归一化操作。这里使用由若干个残差模块构成的ResNet-50网络作为图像特征提取的骨干结构。ResNet-50包含49 个2D 卷积操作和一个全连接层,首先对输入做卷积操作,然后输入到4个不同卷积核尺寸的残差模块中,最后进行全连接操作以便进行分类任务。在2D网络中,卷积和池化的操作主要在空间上进行,最终得到1 024维特征Embi。
2.1.2 模态融合网络
本文采用中间融合的方式,将上一层特征提取网络得到的文本特征Embt(N,1 024) 和图像特征Embi(N,512)分别看作两个token,将这两个token 拼接之后得到Emb(N,2,1 024),再馈送到Transformer的Encoder模块中对两个token融合。
本质上,基于Encoder 模块做特征之间的融合,可以解释为将查询向量Query、键向量Key、值向量Value 3 个向量在注意力的多个输出头分别进行点积计算,并分别得到自适应的加权方案。对于不同区域的信息,按照不同的加权值结合起来最终得到整体的向量表达[24]。在这里,Encoder 的主要作用是学习同一样本中文本token和图片token的交互特征,最终得到一个固定长度的向量表示Embattention。
其中,Emb*Wq为查询向量Query,Emb*Wk为键向量Key,Emb*Wv即值向量Value,Wq、Wk、Wv分别代表3组不同的参数矩阵,用于将输入的同一个Emb映射到3个不同的向量空间。本文的特征融合Encoder堆叠了6 层这样的编码层,每一层使用了8-head 的注意力模块,相当于在8 个不同的通道进行了图片、文本模态特征的融合学习。
2.1.3 多任务预测网络
标签预测模型学习的目的就是学习一组参数,使得模型预测的结果与样本的真实标签一致,也就是损失函数的值最小。本文将分类任务的交叉熵损失函数和相似性损失函数结合在同一个网络中进行多任务训练和联合优化。如图4 所示是多任务网络层的结构图,经过模态融合之后的特征先经过若干个全连接层,然后被输入到分类网络和相似性网络同时进行训练。

图4 多任务网络层结构Fig.4 Layer-structure of multitasking network
交叉熵损失函数(cross entropy loss)是经典的分类损失函数,由softmax公式和交叉熵(cross-entropy)公式两个组合。假设有N个训练样本,归属于C个类别,其中每个样本ri被标记为类li。如式(3),假定最终全连接层的输出是fs(ri,c),交叉熵损失函数的计算公式如下:
其中,fs(ri,c)表示最后的全连接层在输入为ri下,第c类的输出,li为对应输入的类别标签。可以看到,这个计算公式旨在将相同类的数据“挤压”到特征空间的同一个角落,因此没有保留类内方差,而类内方差对于发现视觉和语义相似的实例至关重要。
度量学习则可以通过学习特征表示来解决这个问题,使得来自同一类的样本聚集在一起,来自不同类的样本则相互远离,即扩大类间距离和缩小类内距离。除了单独使用分类损失函数进行约束之外,相似性任务使用了Triplet Loss[25]与分类损失融合起来用于特征表示学习。在计算时,有3个样本表示为(ri,pi,ni),其中ri是来自特定类的参考样本,pi是来自同一类的样本,ni是来自不同类的样本。给定一个输入样本ri,Triplet Loss 驱动的网络可以生成一个特征向量ft(ri) ∈RD,其中超参数D是特征维度。理想情况下,对于每一个参考样本ri,期望它与不同类的任何ni的距离比同一类中的pi大一定的边距m>0,也就是说D(ri,pi)+m<D(ri,ni)。
式(4)是Triplet Loss 的计算方式。为了计算Triplet Loss,还将特征进行了L2 范数归一操作,其中D(.,.)是Triplet 网络中两个融合特征经过L2 范数归一化之后的平方欧几里德距离,m为最小边距。
损失函数是指导模型学习方向的准则,根据损失函数的求导方向可以做反向传播来修改模型参数。在多任务框架中,模态融合之后的特征表示会同时被输入到Softmax 分类网络和Triplet 相似性网络,Softmax 分类网络的输出fs(r)被转发到Softmax损失层以计算分类误差Losss(r,l),Triplet 相似性网络的输出ft(r)被转发到Triplet 损失层以计算分类误差Losst(r,p,n,m)。分类任务和相似性任务的输出可以看作两个独立的预测场景,在多任务融合阶段,如式(5),本文通过加权组合来整合这两种类型的损失。λ是两个任务的权重系数,取值范围在0~1之间。
2.2 实体纠错模型
实体纠错模型服务于第三级标签的识别任务,进一步对实体标签的识别结果做优化。标签预测模型根据概率选取最终分类结果。然而实体标签的粒度非常细,对于在视觉画风相似、场景人物相似的情况下往往会出现多个相似影视剧集难以区分的情况,导致出现错误识别的实体标签。以图5 场景为例,正确的标签是“延禧攻略”,而分类模型给出的结果排序是“陈情令、延禧攻略”。由于“陈情令”的预测分数大于“延禧攻略”,导致其作为概率最大的标签被输出。这种情况来自于两方面的原因:其一,这个样本的文本信息无法给出与“延禧攻略”剧集相关信息;其二,样本的图像在视觉画风、场景布局上与“陈情令”相似,导致难以区分。

图5 错误预测的一个实例Fig.5 Example of wrong labeling prediction
本文采用引入外部知识图片中的元数据(metadata)信息来解决上述问题。根据图像中出镜的人脸识别和现实生活中的人物关系知识图谱,可以获知视频中出现了演员“许凯”,结合该演员的出演历史可排除“陈情令”,从而得到正确标签。基于此,本文提出了优化视频标签分类的第二阶段模型,一种融合知识图谱的实体纠错方法。引入预先构建的知识图谱节点和节点关系作为对文本信息和视觉信息的补充,训练扩展注意力机制的先验知识模型,提高影视实体标签识别的准确性和覆盖率。
实体纠错任务可以形式化为:给定一批训练样本G={g1,g2,…,gn},其中g∈{n1,n2,…,N}。对于每一个输入g,随机将一部分节点信息掩蔽之后得到g∈{n1,[mask],n3,…,N},节点ni包括影视名称节点和演员节点以及一个特殊的MASK 节点。本文目标是训练一个重构缺失节点模型,预测其出现概率最大的节点ni∈g。在图神经网络中,图卷积层会计算当前节点与所有邻居的得分,加上注意力机制可以为其提供自适应加权方案,为不同节点分配不同权重,并且只需要计算邻居或者多阶范围内的邻居。基于图注意力网络思路,本文添加局部注意力头扩展Transformer模型,并采用BERT类似的掩蔽机制来预测最终标签结果,同时结合知识图谱的节点关系考虑节点预测的合理性。
实体纠错模型的总体架构如图6 所示。对于某个待定视频,将一定概率的候选名称看作影视节点,出镜人物识别出的演员看作演员节点,每个节点为一个token向量输入模型。训练模型时提取影视知识图谱中的剧集-演员两类实体,构建成一个二部图,将其邻接矩阵输入模型中。在预测阶段,例如输入“张若昀”“郭麒麟”“宋轶”3 个演员名字,就能得到与之相关性最高的影视剧名称是《庆余年》。
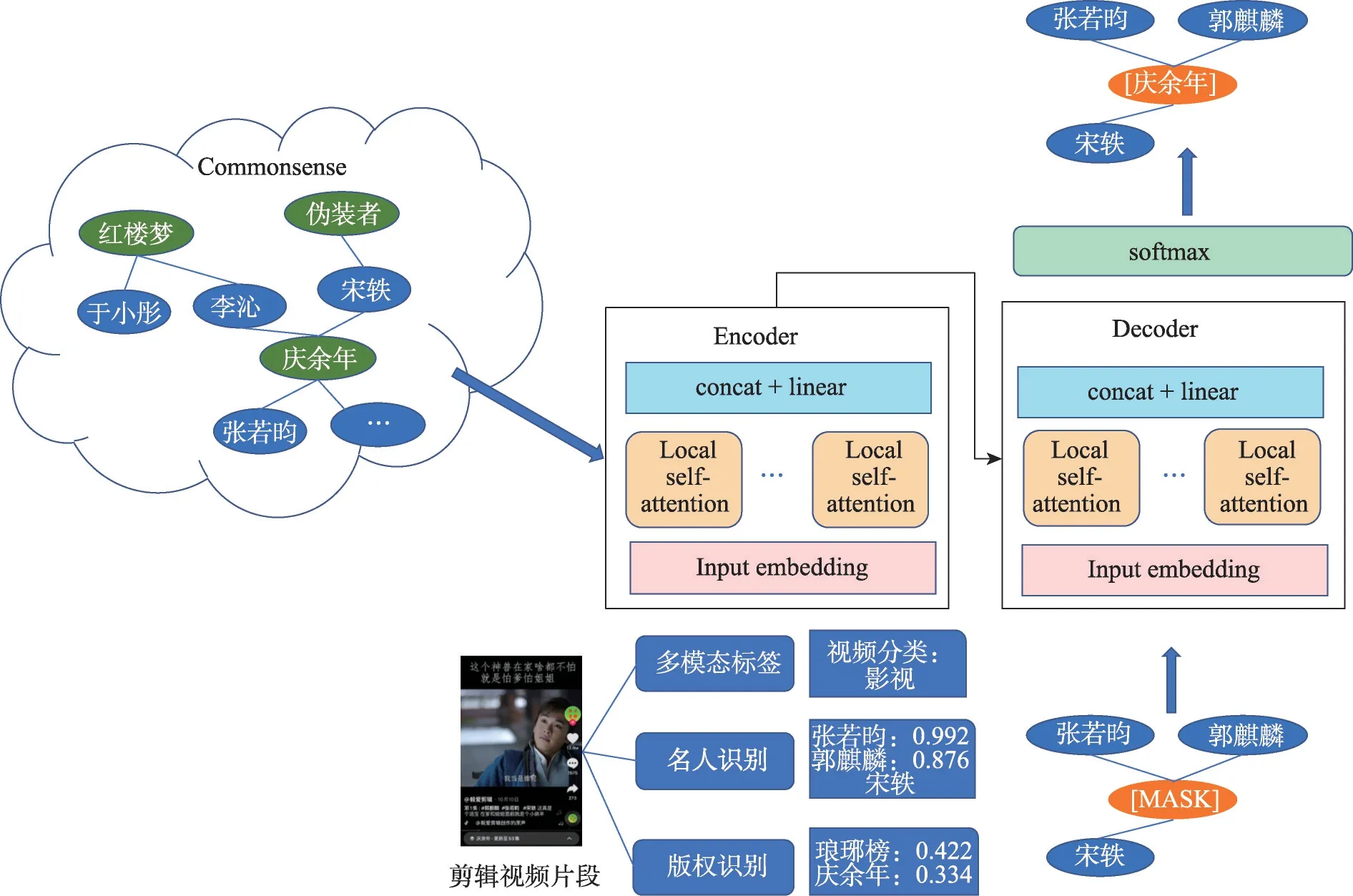
图6 实体纠错模型的体系结构图Fig.6 Structural diagram of entity error correction model
本文改进了Transformer 的Encoder 部分。传统Transformer自注意力机制需要计算所有token的Query向量、Key向量和Value向量,相当于算得全局注意力分数;细粒度的实体标签纠错,本文更关注相邻节点的作用,只需计算具有出演或合作关系的明星与影视剧名两个实体间的注意力分数,无需对所有实体计算token,本文将Encoder中一部分注意力头替换成了局部注意力,基于知识图谱来修正计算视野,将非邻居节点间注意力强制为零。具体过程参见算法2。
算法2实体纠错模型
其中,Hl是第l层的注意力头集合,Wl和bl为该层训练权重和偏差,沿矩阵列进行concatenate操作。在实际训练过程中,本文将使用两种类型的注意力头,即全局注意力头和局部注意力头:
对于全局注意力头,每个节点可以通过全局注意力关注所有其他节点,与每一个节点都进行交互并计算注意力分数。全局注意力是典型的自注意力计算方式,每个注意力头具有独立的初始化参数和训练参数,但是计算过程是相同的:
其中,q(∙)、k(∙)、v(∙)分别表示节点表征X(l)经过3 个不同的参数矩阵映射之后的Query 向量、Key 向量和Value 向量。对于局部注意力头也是同样的思路,不同之处是查询向量只能与其直接邻居节点的关键向量进行交互并计算注意力分数:
其中,As是知识图谱的邻接矩阵,包含影视剧节点和演员节点,影视剧和演员之间有交互关系,在出演关系的影视剧-演员之间为1,其余地方为0。最后,本文使用交叉熵损失函数来训练网络计算所有类别的概率分布来预测输出节点类别,具有最高概率的类就是经过纠正之后的标签。
3 实验与分析
3.1 数据描述
当前有很多视频片段数据集,但是在影视剧领域还没有一个标注好的、可供训练的标准数据集。目前已有的一些视频标签的公开数据集,难以符合三级标签的影视剧视频的应用场景,这些数据标签都在相同层次上,譬如类型标签或题材标签,但缺乏更细粒度的实体标签,况且影视视频标签分类的关键特征跟画面内容、人物关系、场景美工、拍摄风格、台词字幕等因素都有关,本文也难以借用其他领域的通用视频标签数据集。此外由于视频数据源较难获取,在数据预处理时,需要同时完成抽帧和文本识别操作,本文考虑以(图片,文本)对的形式组织数据,用多张相似图片模拟视频连续抽帧结果。一个视频包括图像信息和文本信息,本文最终分别爬取了图片和对应的文本作为多模态信息。也就是说,利用搜索引擎构造了数据集。其中,文本和图片信息均来自百度图搜,例如输入query=“小敏家电视剧”,可以获取网站返回的若干张图片,选取自剧集截图且保留该图的标题文本描述。百度图搜返回的结果是经过排序筛选的,相关性较高,本文可以将此类(图片,文本)对作为训练数据。
本文最终收集的数据如表1所示,数据来自于豆瓣电影平台的标签体系,共包含24 000 图文对,分别归属于240 部影视剧集,每个影视剧集包含100 个(图片,文本)对。其中,视频真实标签的信息来自豆瓣,输入query=“小敏家”,本文可以从豆瓣爬取到该剧集的详细信息,包括一级标签“电视剧”、二级标签“剧情/家庭”、三级标签“小敏家”,甚至可以获得编剧、演员、上映日期等信息,便于以后构建影视领域的知识图谱。
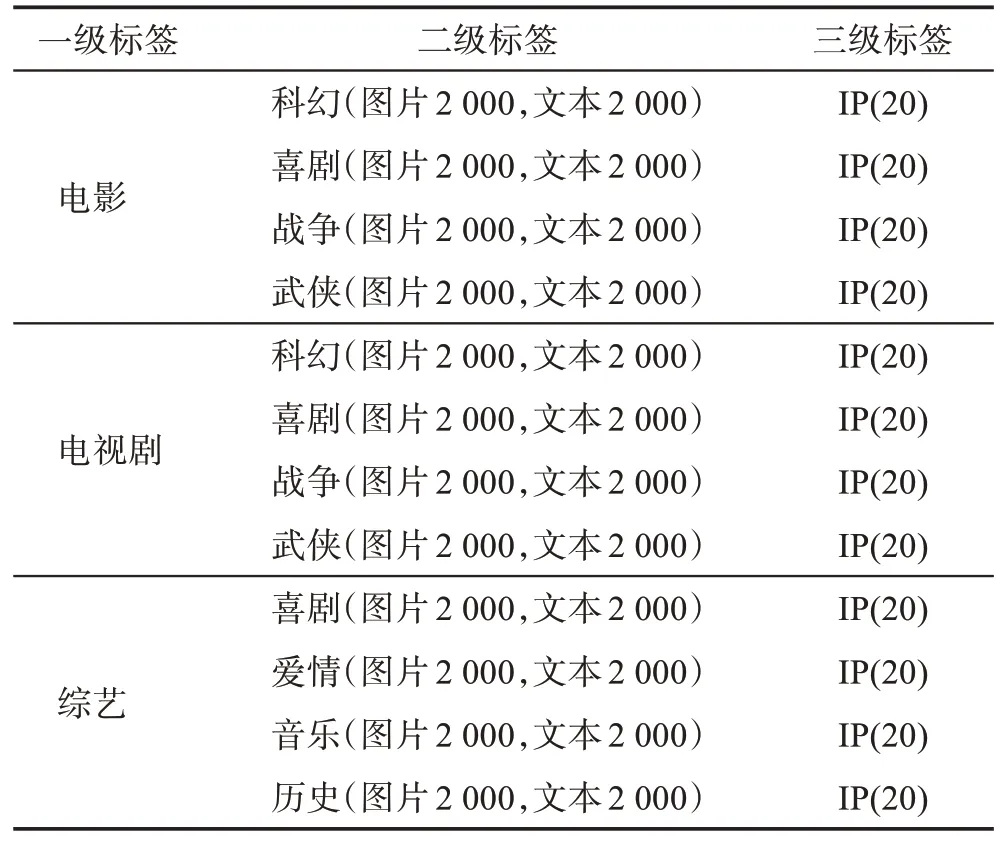
表1 数据集标签统计表Table 1 Statistics of dataset
3.2 实验设置
在评价指标方面,本文采用Top-N Acc、MacroP、MacroR和MacroF1作为评价指标,多分类问题中真实的样本标签有多类,学习器预测的类别也有多类,混淆矩阵在高维情况下难以直观表示分类效果。本文将多分类的评价拆分成若干个二分类的评价,计算每个二分类的F1-score 平均值作为MacroF1 评价指标。Top-N Acc是视频多分类的常用评价指标,计算公式如下:
其中,M是总样本数量,I(x)为指示函数,当x为真时,表达式为1,否则为0。在Top-N准确率指标中,N的取值一般在1 到10 之间,Top-1 的分类准确率是指,在预测结果得分中,排名第一的类别与实际标签一致的准确率;Top-5 的分类准确率是指,预测结果前五名的类别中,包含与实际标签一致的准确率。本文两个阶段的任务都是分类任务,均采用MacroF1指标和Top-N Acc指标。
在基准模型方面,本文使用了三种不同结构的CLIP 模型和两种消融模型,包括CLIP-RN50、CLIPRN101、CLIP-ViT 模型、只训练标签预测阶段的多任务分类模型以及本文提出的两阶段融合模型。其中,CLIP-RN50 使用ResNet-50 架构作为图像特征编码器,包含50 层卷积和全连接网络;CLIP-RN101 ResNet-101 架构作为图像特征编码器,包含101 层卷积和全连接网络;CLIP-ViT Vision Transformer 架构作为图像编码器,图像输入是将原始224×224像素图片分块展开成的序列。文本标签预测模型是实体纠错模型的前置模型,本文对比了两个阶段模型的输出结果,以验证实体纠错模型带来的效果差异。在标签预测模型的实验过程中,各个基线模型的参数设置都是一致的。批量大小设置为64,训练持续200个epoch。使用自适应矩估计Adam 优化器,初始学习率为0.001,动量为0.9,每2 000 个样本做一次学习率衰减,衰减系数为0.1。在实体纠错模型的实验过程中,批量大小设置为64,训练持续40 个epoch。其中,两个阶段的模型的可学习参数通过均值为0、方差为0.02 的正态分布进行初始化。所有的模型超参数通过在验证集上进行网格调参获得,每10个epoch会保存一次在验证数据集上具有最佳性能的模型,根据损失来进行替换每次保存的最优模型,然后用于测试分类任务中的性能。针对第三级标签识别结果的优化,本文将图片-文本对数据集的标签结果和影视知识图谱融合输入到实体纠错模型中进行细粒度标签纠错任务。实体纠错模型是基于Transformer框架的,整个Transformer模型包含6层Encoder,每一层含有8 个注意力头,其中每个节点都有300 维表示。在训练时,本文随机屏蔽了30%的节点。
在实验过程方面,本文先将构建的图片-文本对数据集输入到多任务标签预测模型中进行多级标签识别。标签预测模型是基于对比自监督CLIP 模型的,其中图像编码器使用的是ResNet-50 主干网络,文本编码器使用的是文本Transformer 主干网络。特征融合阶段使用的是一个基于注意力机制的Encoder模块,多任务架构将分类损失函数和相似性损失函数进行权重相加。
3.3 实验结果与分析
本文分别在类型、题材、实体三种不同粒度级别标签上进行测试。其中,类型标签包含三类,即电影、电视剧、综艺;题材标签分为八类,包含科幻、喜剧、战争、农村、武侠、爱情、音乐、历史等;三级标签是最细粒度的实体标签,每一个影视剧属于一类,总共有228 类。对于各层级标签各种模型的分类性能比较结果如表2所示,从中可以发现三个方面的主要结论:首先,在小规模影视数据集上各种CLIP模型分类效果差异不大。基于同样的输入图片大小进行预训练,相比ResNet 系列模型的卷积层堆叠,视觉Transformer 模型将图片按位置切分并拼接成序列。在本文数据集上,CLIP-RN50、CLIP-RN101、CLIP-ViT 3个不同架构在类型标签Top-1 中三者精确度分别是78.3%、78.9%、78.8%,MacroF1 分别是76.8%、78.0%、77.8%;在题材标签Top-1中三者精确度分别是62.6%、63.1%、62.8%,MacroF1 分别是50.7%、53.9%、52.0%;在最细粒度的实体标签Top-1 中三者精确度分别是33.2%、33.4%、33.9%,MacroF1 分别是31.2%、31.4%、31.9%,显然性能差异不显著。其次,本文提出的多任务学习框架可以显著提升分类性能。可以看到,将相似性任务加入到多任务训练框架后,模型对于3个级别标签的识别准确性上都有提升。其中在类型标签上多任务框架的Top-1识别精确度从78.3%提升到81.2%,MacroF1从76.8%提升到79.7%;在题材标签上Top-1 识别精确度从62.6%提升到64.7%,MacroF1 从50.7%提升到53.5%;新模型在第三级实体标签识别性能上提升最明显,Top-1 精确度从33.2%提升到38.7%,MacroF1 从31.2%提升到34.8%。本文所提出的新模型之所以能取得性能上的显著提升,是相似性任务训练模型学习到了样本之间特征表达的差异,而传统分类任务较少考虑样本差异化特性。实验结果也验证了本文提出的多任务框架对于细粒度标签识别的有效性。最后,本文提出的实体纠错模型可以在标签预测模型基础上进一步提升对实体标签的分类性能。实体标签是最细粒度的内容标签,这里的实体纠错模型实际视作针对于困难样本改进多任务框架标签预测模型的一个优化算法。从表2中可以看出,引入知识图谱中的演员节点和出演关系之后,第三级实体标签识别的Top-1 精确度从38.7%提升到45.6%,而且Top-3精确度也从52.5%提升到了58.3%,实验结果表明在影视图文数据集中引入实体纠错模型可以有效提升粒度较细的标签的分类效果。
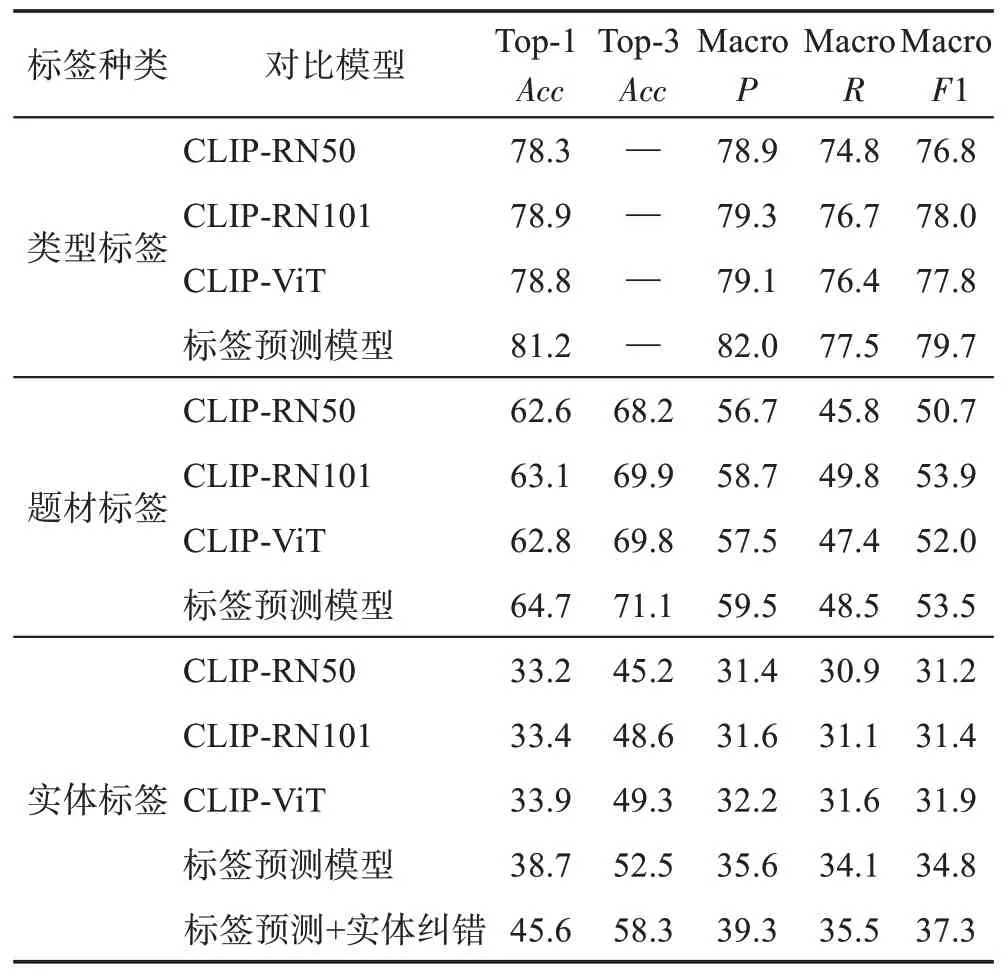
表2 在各类标签上模型分类性能对比Table 2 Comparison of model classification performance on various types of labels 单位:%
3.4 参数影响分析
针对多任务框架中分类任务和相似性任务权重系数λ,本文执行了参数敏感性分析的多重对比实验以确定其最优取值。λ的取值范围是[0,1.0],λ越小时,多目标学习网络模型更关注分类损失的优化;反之,λ越大时,模型更关注度量损失的优化。通过将λ从0 变化到1.0,可以探究分类任务和相似性任务对特征学习的作用。在实验过程中,从模型中分别提取分类网络和相似性网络的倒数第二层特征,将分类特征和相似性网络特征拼接起来,通过相应的平均特征方差进行归一化后得到每个样本的128 维特征。根据第三级实体标签的预测结果,计算所有样本输出特征在特征空间下的类内距离和类间距离值。
基于参数λ的多重对比实验结果,如图7 所示。在λ=0时,相似性任务不起作用,此时只有分类任务生效,不同类别间样本之间距离达到最大,可以较好区分不同的影视剧集;但是这时类内的距离也较大,表明同类样本之间存在较大的差异,各个样本的特征在特征空间分布较分散。随着λ增加,相似性任务逐渐主导多任务网络的训练过程。从图7 中可以看到,不同类别样本之间距离稍有下降,但变动不大;类内的距离随着训练过程稳定地逐渐减小,说明相似性任务的损失函数优化使得同类别样本之间逐渐减少差异。最终当λ=1.0 时,只剩下了相似性任务,不同类别样本之间的距离和同类别的样本之间的差异都很小。这时没有分类任务优化的引领,无法形成多样化的特征,类与类之间的差异低,在特征空间里各类难以区分,分类性能显著下降。综合来看,在λ=0.4时,模型在第三级实体标签的分类精度最高。
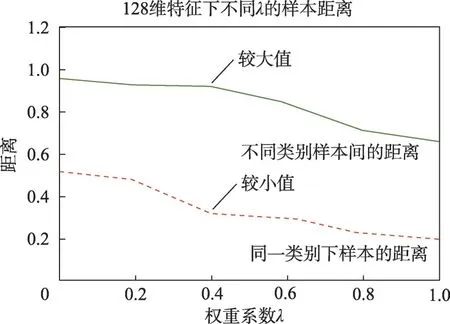
图7 不同权重系数时类内和类间距离Fig.7 Intra-class and inter-class distances at different weighting factors
实验结果表明,单独的分类任务或者单独的相似性任务都不是学习特征的最佳方案,有效的特征来自于两者的适当结合。分类任务没有考虑到样本差异化的重要性,而相似性任务则为样本之间的特征表达学习到了差异,这也说明了本文提出的多任务框架对于细粒度标签的识别的有效性,通过同时使用两个任务来学习样本特征是有效的。
3.5 相似性任务验证
本文进一步验证多任务分类网络中引入相似性任务的有效性。相似性任务也是一种监督学习,用在分类任务中研究的是如何通过基于距离度量(如欧式距离、余弦距离等)的损失函数学到更好的特征表示[26]。相似性任务对数据标注质量要求较高,分类训练时将所有非标签类别当作负样本,在模型参数优化过程中,同一类样本之间的距离需要比不同类样本之间的距离更小。基于距离度量的损失函数在人脸识别、图像检索等领域被广泛使用,代表方法除了Triplet Loss之外还有Sphereface[27]、Arcface[28]等。
通过对比相似性任务中使用不同损失函数约束模型的分类效果,本文验证相似目标学习的有效性。在所有200 个epoch 的训练过程中,每一个消融实验都是保存最优的模型之后比较性能。其中基线是只使用了分类任务的交叉熵损失函数,相当于单任务框架;其他任务框架均在λ=0.4 下进行,实验结果如表3所示。

表3 在各类标签上不同损失函数分类性能比较Table 3 Comparison of classification performance of different loss functions on various types of labels 单位:%
表3 呈现了相似性任务使用三种不同度量损失函数的各种层级标签分类效果。从中可以看出,加入了Triplet Loss、Sphereface、Arcface 等相似性任务的度量损失函数作为优化方向的模型,分类准确率均优于基线。在类型标签上Top-1 精确度分别提升了3.70%、1.79%和1.53%;在题材标签上Top-1 精确度也分别提升了3.35%、3.99%和3.99%;关键是在第三级实体标签上Top-1 精确度分别提升了16.57%、18.07%和18.98%,说明引入相似性任务的效益,也表明多任务学习网络的鲁棒性。更值得关注的是,添加相似性任务对于细粒度标签的识别具有更优的提升效果。相似性损失函数的原理是对多分类交叉熵损失函数进行修改,通过增加一个差值(Margin)提高分类模型训练的难度,使得所学特征更加紧密。在第一级类型标签和第二级题材标签中,以Triplet Loss为例,相似性任务的Top-1 精确度相比基线模型分别提升了3.70%和3.35%,相似性任务的MacroF1 值相比于基线模型分别提升了3.78%和5.52%;而三级标签中Top-1 精确度提升了16.57%,MacroF1 提升了11.54%,提升幅度是最大的。实验结果表明,对于识别力度越细的标签类别,度量损失函数提升的效果越好。
4 结束语
融合知识图谱的影视视频标签分类方法尝试解决视频标签不同细粒度层级分类的问题,基于碎片化信息生成清晰、合理的层级标签对于视频运营网站十分关键,该类方法具有较强的现实应用价值。视频标签分类算法在经历了较长时间的图像时序和音频的研究之后,当前的研究越来越多地将文本作为一种监督信息融合到分类模型中。基于影视类短视频数据,本文提出了一个融合知识图谱的影视视频标签分类模型。首先,整合半结构化数据建立影视知识图谱,为细粒度的标签识别提供数据支撑;其次,在大规模预训练模型上训练多个分类任务为数据集生成标签集合;最后,利用影视知识图谱中节点和节点关系,将分类结果修正为更合理的标签。
本文采集豆瓣的半结构化数据构建了影视知识图谱并对影视视频标签分类模型进行了实证研究。视频标签分类的实验结果表明:首先,基于多任务网络结构,在训练分类任务时加入相似性损失函数对模型进行共同约束优化了特征表达,在类型、题材、实体标签的Top-1 分类准确率分别提升了3.70%、3.35%和16.57%;其次,本文针对前置模型的困难样本提出的全局-局部注意力机制模型,在引入了知识图谱信息之后,实体标签的Top-1 分类准确率从38.7%提升到了45.6%;最后,当计算多任务网络的损失值时,权重系数λ设置为0.4,模型的层级标签识别效果最优。
