基于改进随机森林算法的薏苡仁产地溯源研究
2024-01-11赵汉卿王斌陈瑶唐章奉方鑫陈增萍杨健邓婷
赵汉卿,王斌,陈瑶,,唐章奉,方鑫,陈增萍,杨健,邓婷
1.中南林业科技大学 理学院/应用化学研究所,湖南 长沙 410004;2.湖南工业大学 生命科学与化学学院,湖南 株洲 412007;3.湖南大学 化学化工学院/化学生物传感与计量学国家重点实验室,湖南 长沙 410082;4.中国中医科学院道地药材国家重点实验室培育基地 国家中药资源中心,北京 100700
0 引言
薏苡仁为一年生草本植物薏苡的干燥成熟种仁[1],含有人体所必需的8种氨基酸和多种矿物质元素,且富含不饱和脂肪酸、多糖、维生素E等物质[2-3],有较高的药用价值,具有抗肿瘤[4-5]、消炎镇痛[4]、清热利湿、活血化瘀、调节血糖[6]、提高免疫力[7]等功效。薏苡仁产地范围较广,不同产地薏苡仁的品质有明显区别[8],因此开发可快速判别薏苡仁产地的检测技术具有重要意义。
目前,已有一些关于薏苡仁品质、种类和产地分类方面的研究报道。例如,X.Liu等[9]利用近红外光谱结合模式识别方法实现了不同种类薏苡仁的快速鉴别;刘星等[10]构建了基于薏苡仁中主要营养成分(粗脂肪、蛋白质、氨基酸、矿质元素)含量的判别模型,实现了不同产地大颗粒薏苡仁和小颗粒薏苡仁的准确区分;郑利等[11]通过薄层液相色谱法测定薏苡仁中甘油三油酸酯含量,以鉴别不同产地薏苡仁;W.W.Tang等[12]采用超高效液相色谱-四极杆飞行时间串联质谱和高效液相色谱-蒸发光散射检测技术检测薏苡仁在加工和储存过程中甘油三酯类成分含量的变化,以监控薏苡仁产品的品质。虽然上述方法可以对薏苡仁进行鉴别,但处理和检测过程较为复杂。
荧光光谱分析技术具有分析速度快、灵敏度高、选择性好等优点,应用于白术、天麻、葛根等产地溯源及掺假检测方面已有一定的研究成果[13-16]。S.Matthias等[17-18]尝试通过激发-发射矩阵(Excitation-Emission Matrix ,EEM)荧光光谱结合随机森林算法以实现薏苡仁产地的快速准确溯源分析。与偏最小二乘[19]等多元线性判别分析方法相比,随机森林算法对非线性数据拟合效果更好,且其预测结果的准确度高于多数基础模型算法预测结果。然而,EEM荧光光谱数据的维数较高,在原始EEM荧光光谱数据基础上直接使用随机森林算法构建判别模型的计算成本较高,将数据降维方法(如主成分分析(PCA))[19-20]与随机森林算法结合可以减少非重要特征数量,从而提高随机森林判别模型的训练速度,且能在一定程度上避免过拟合情况的发生。鉴于不同产地薏苡仁中所含物质的组成和含量相近,其提取液的EEM荧光光谱数据相似程度较高,直接采用PCA进行无监督模式分类难以对薏苡仁进行准确的产地溯源分析,本文拟提出一种改进的随机森林算法,通过对EEM荧光光谱数据进行标准化和PCA降维处理,并利用网格筛选法找出最佳保留主成分数和模型超参数来获得最优薏苡仁产地判别模型,以期为薏苡仁产地的高效准确溯源提供一种可行的技术方案。
1 材料与方法
1.1 主要材料、试剂与仪器
主要材料:薏苡仁粉末,来自安徽、福建、河北、黑龙江、吉林、辽宁、内蒙古、山东、陕西9个产地,每个产地取30个样品,共270个样品。
主要试剂:超纯水,湖南大学实验室;无水乙醇(分析纯),国药集团化学试剂有限公司。
主要仪器:ZWM型超纯水仪,湖南中沃水务环保科技有限公司;F-7000型荧光光谱仪,日本日立公司;KM-500DE型超声波清洗仪,昆山美美超声责任有限公司;Super Mini Dancer桌面型迷你离心机,生工生物工程股份有限公司。
1.2 实验方法
1.2.1 薏苡仁样品预处理称取薏苡仁粉末样品各15 mg,分别溶于1 mL体积分数为70%的乙醇溶液中,超声处理30 min后,于5000 r/min条件下离心10 min,静置1 h,取150 μL上清液与1.35 mL 体积分数为70%的乙醇溶液混合后,检测其EEM荧光光谱。
1.2.2EEM荧光光谱检测使用荧光光谱仪测试薏苡仁样品的EEM荧光光谱数据,参数设置为:激发波长范围 200~450 nm,发射波长范围 250~750 nm,波长间隔 5 nm;激发和发射狭缝宽度5 nm;电压700 V;扫描速度30 000 nm/min。
1.2.3 数据分析将270个薏苡仁样品按6∶2∶2的比例划分为训练集、验证集、测试集。使用训练集和验证集的EEM荧光光谱数据构建用于产地溯源的随机森林判别模型,用该判别模型对测试集样品的产地进行预测,流程图见图1。使用相同的数据集,利用通用算法(偏最小二乘法)构建判别模型,并对两种算法所构建模型的准确度进行对比分析。每个样品的EEM荧光光谱数据阵的大小为101×51,将其按行首尾相接展开成长度为5151的行矢量,则270个薏苡仁样品的荧光光谱数据为270×5151的矩阵。本文所用数据分析程序均采用Python语言进行编写。

图1 改进的随机森林算法流程图Fig.1 Flow chart of the modified random forest algorithm
2 结果与讨论
2.1 不同产地薏苡仁的EEM荧光光谱分析
图2为不同产地薏苡仁样品去除背景后的EEM荧光光谱图。由图2可知,薏苡仁样品的主要荧光信号均出现在激发波长为290~350 nm、发射波长为270~330 nm的区域内,但在荧光信号强度、最大荧光信号对应的激发波长和发射波长及光谱形状上均存在明显差异,这为利用EEM荧光光谱进行薏苡仁样品的产地溯源提供了数据基础。
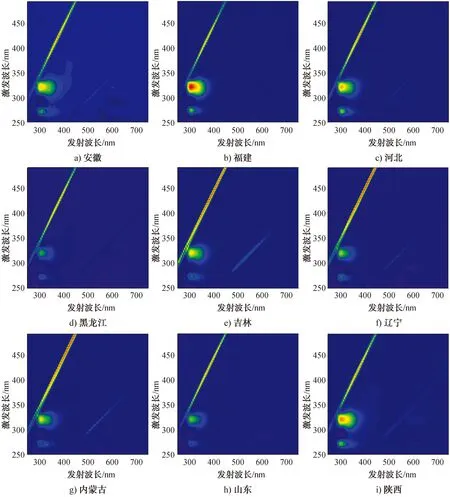
图2 不同产地薏苡仁样品去除背景后的EEM荧光光谱图Fig.2 Background-subtracted EEM fluorescence data of extracts of Coix seeds produced in different areas
2.2 基于EEM荧光光谱数据的薏苡仁产地鉴别分析
2.2.1 基于PCA降维的无监督模式分类图3为保留的PCA主成分数与累计方差贡献率之间的关系曲线。由图3可知,在保留PCA主成分数(PCs)少于12个时,累计方差贡献率随着保留PCs的增加而急剧升高;当保留PCs为12个左右时,累计方差贡献率提升速率趋于平缓;当保留PCs达到71个时,累计方差贡献率高于85%。

图3 保留的PCA主成分数与累计方差贡献率之间关系曲线Fig.3 Relationship curve between retained PCA principal component scores and cumulative variance contribution rate
为了更直观地显示不同产地薏苡仁样品之间的差异,取前两个PCs作不同产地样本两两之间的散点图(见图4)。由图4可知,PC1的方差贡献率为35.9%,PC2的方差贡献率为16.5%;安徽薏苡仁样品与河北、黑龙江、吉林、辽宁的薏苡仁样品之间,福建薏苡仁样品与河北、黑龙江、吉林、辽宁的薏苡仁样品之间,黑龙江薏苡仁样品与内蒙古、陕西的薏苡仁样品之间均有明确的分类边界,吉林薏苡仁样品与陕西薏苡仁样品之间,辽宁薏苡仁样品与陕西薏苡仁样品之间也有明确的分类边界,可以进行准确区分。但是部分产地(如安徽与内蒙古、吉林与辽宁、河北与黑龙江)薏苡仁样品之间重叠严重,难以区分。因此,基于PCA降维技术的无监督模式分类难以对薏苡仁进行准确产地溯源分析。
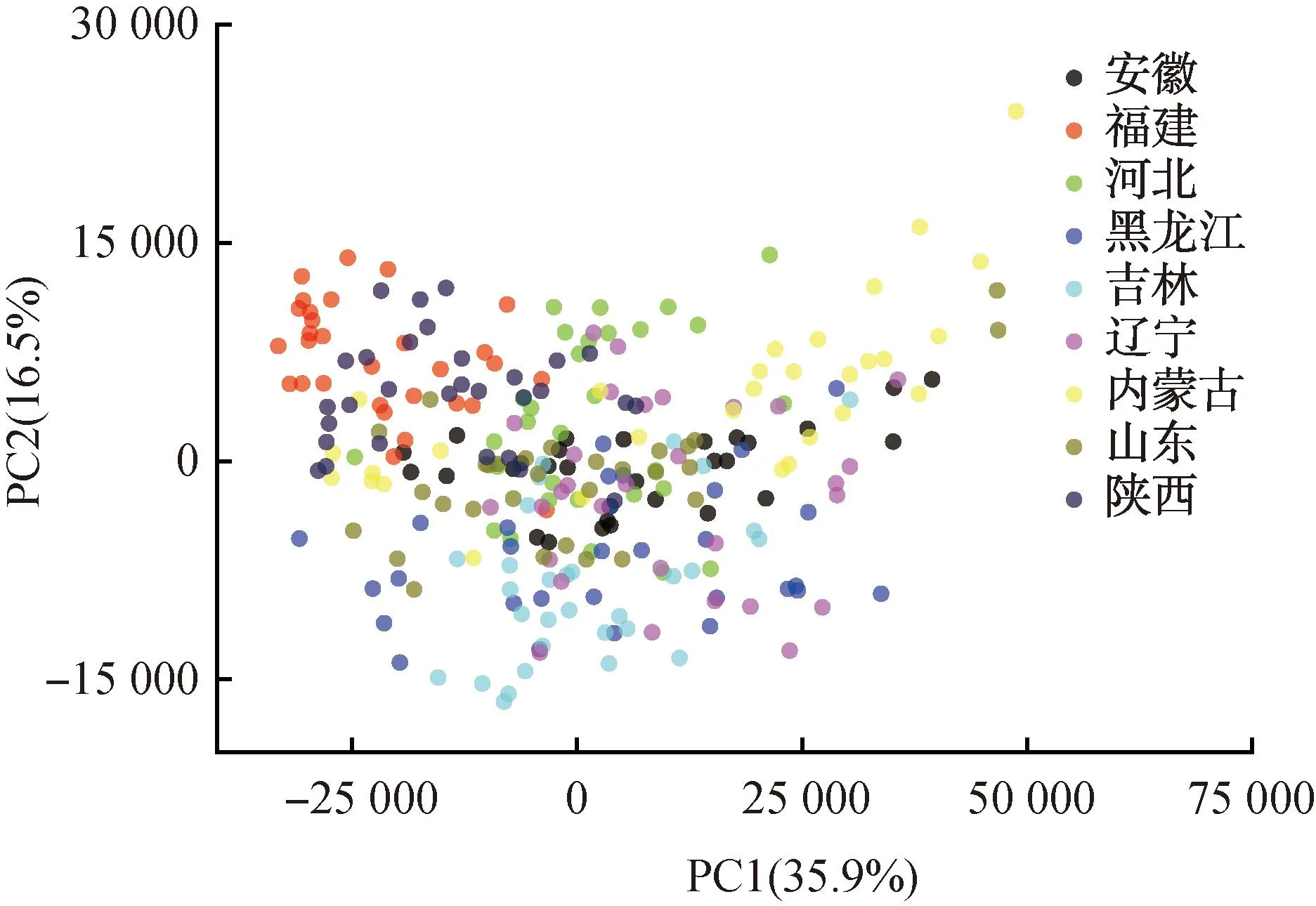
图4 取前两个PCs时不同产地样本之间的散点图Fig.4 Scatter plots of the first two principal components among samples of different origins
2.2.2 随机森林模型的构建和应用将270个薏苡仁样品通过分层抽样,以6∶2∶2的比例拆分为训练集、验证集和测试集,使用标准差标准化对相应EEM荧光光谱数据矩阵进行标准化处理后,进行PCA降维处理,将降维后的数据输入随机森林算法程序构建随机森林判别模型。通过网格筛选法优化PCA降维过程中保留PCs、决策树数量、决策树深度和叶节点最小样本数来获得最优随机森林判别模型。随机森林算法超参数的搜索范围为:决策树数量100~500棵(步长50);决策树最大深度1~6(步长1);叶节点最小样本数1~6(步长1)。
为使预测准确度与计算成本相对最优,PCA降维过程中所保留PCs的范围应控制在保留PCs与累计方差贡献率曲线的斜率突变点附近,故保留PCs的取值范围设定为5~25。在此PCs范围内构建随机森林判别模型,并确定在保留不同PCs时所对应的最佳决策树数量、决策树最大深度和叶节点最小样本数(见图5)及相应验证集和测试集的准确度(见图6)。
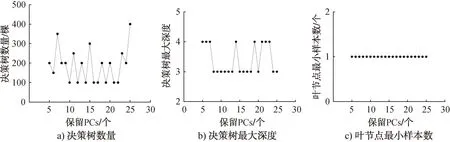
图5 保留不同PCs时所构建的随机森林模型的最优超参数Fig.5 The optimal hyperparameters of the random forest model constructed by retaining different PCs
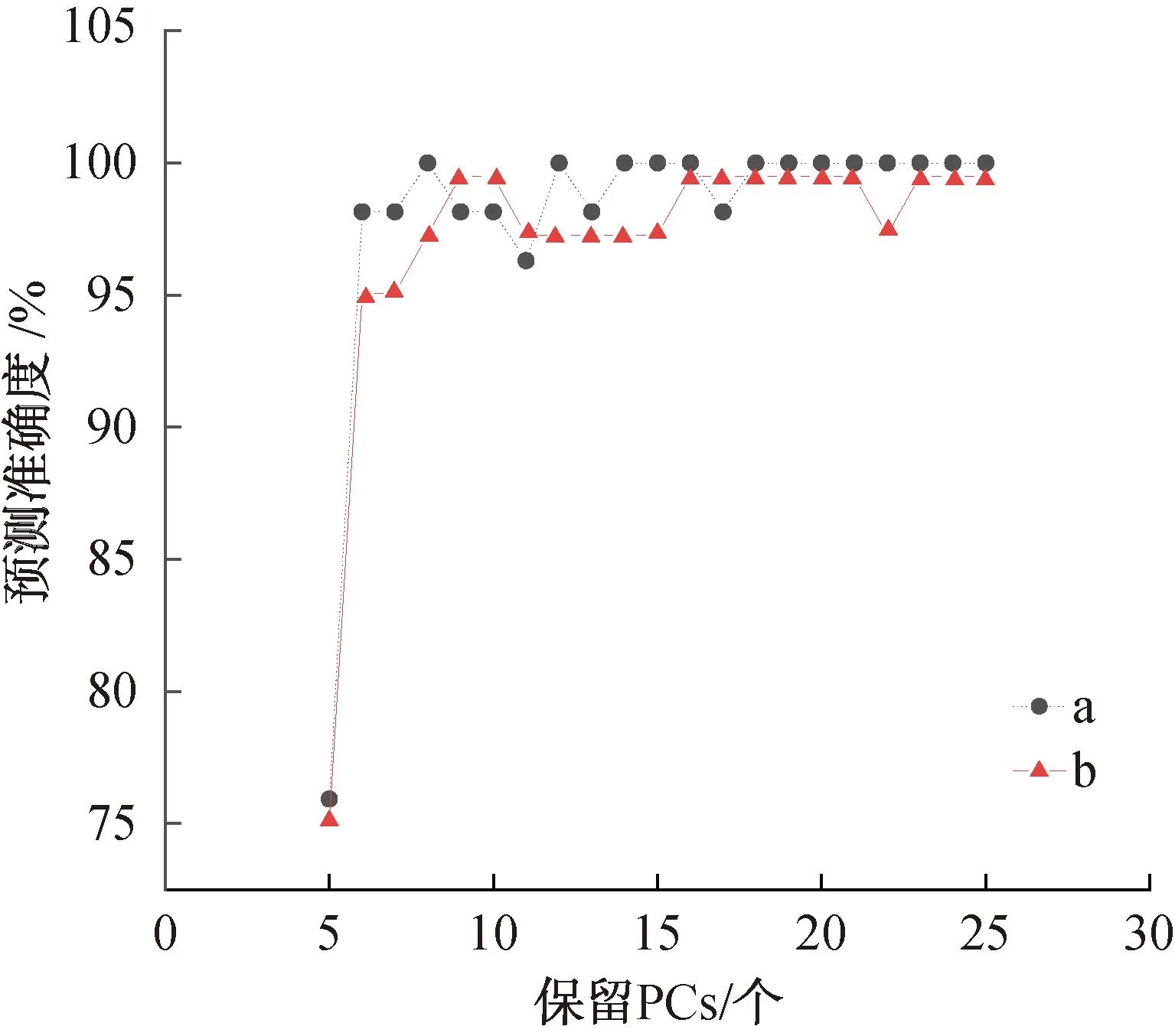
图6 保留不同PCs时所构建的随机森林判别模型对验证集和测试集的预测准确度Fig.6 The accuracy of prediction for the validation and test sets obtained by the random forest model constructed by retaining different PCs
确定最优PCs值的基本原则为:1)所构建的随机森林判别模型具有最佳的预测准确度;2)在保证预测准确度的前提下,随机森林判别模型的计算成本应最小,即决策树数量、决策树最大深度和叶节点最小样本数值越小越好。综合图4和图5,当保留PCs为16时,所构建的随机森林判别模型最优,对验证集和测试集的预测准确度均为100%,而此时决策树数量为100棵,决策树最大深度为3,叶子节点最小样本数为1个,均为最小值。表1为采用上述最优参数值构建的随机森林判别模型对不同产地验证集和测试集样品的混淆矩阵。由表1可知,随机森林判别模型对验证集和测试集中的108个样品均实现了正确的产地溯源,表明该模型结合EEM荧光光谱对薏苡仁样品的产地溯源具有较强的可行性。
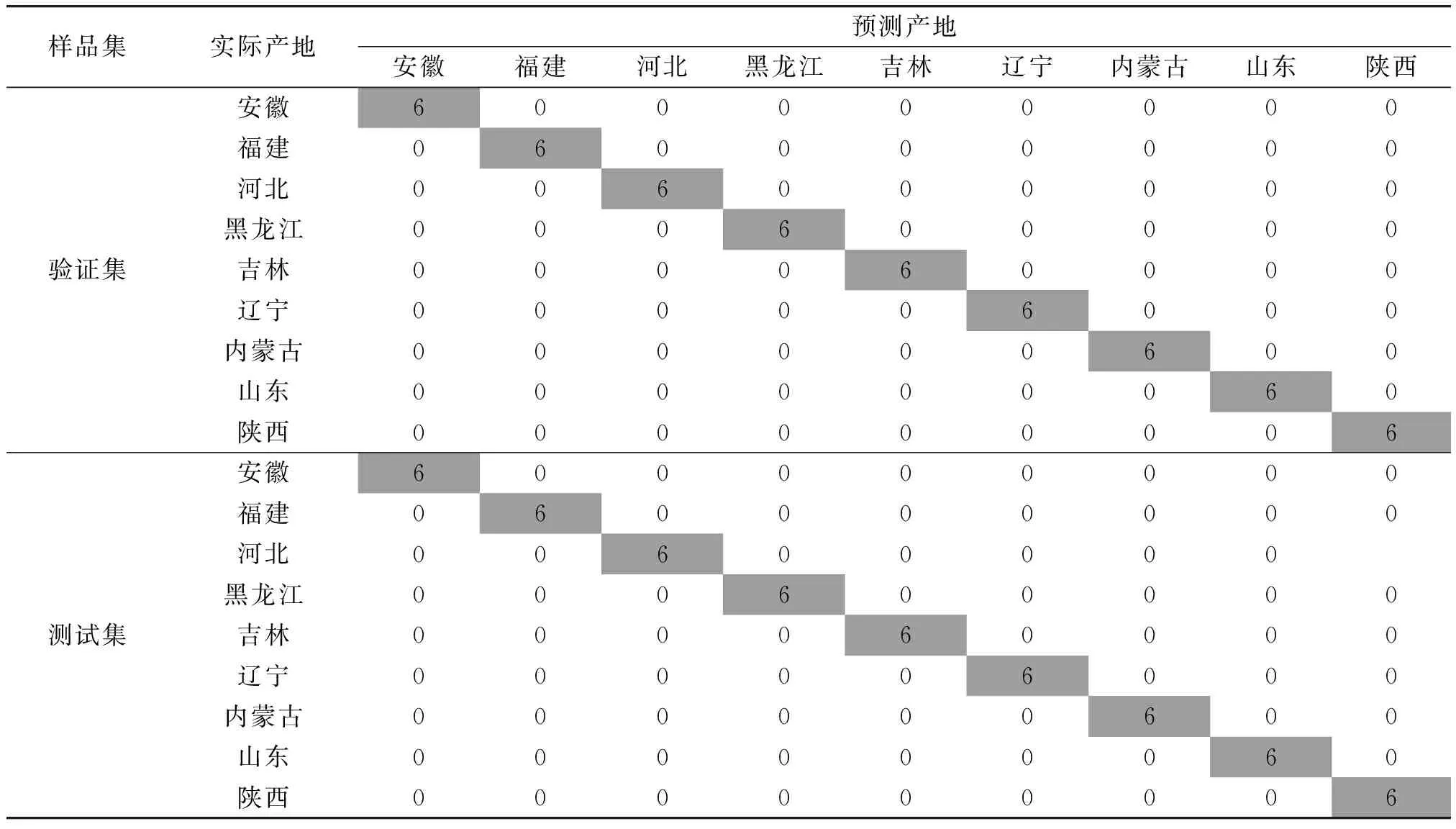
表1 最优随机森林判别模型对不同产地验证集和测试集样品的混淆矩阵Table 1 Confusion matrix of the optimal random forest discriminant model for the validation and test samples of different origins
2.2.3 改进随机森林算法中各模块的必要性考查与常用随机森林算法相比,本文采用的改进随机森林算法加入了标准差标准化和PCA降维两个模块。为考查这两个模块的必要性,将按以下4种策略构建的随机森林判别模型的预测能力、最优超参数和计算时间进行比较研究,结果见图7。

图7 基于4种策略构建的随机森林判别模型的预测能力、最优超参数和计算时间Fig.7 The predictive ability, optimal hyperparameters and computation time of the random forest classification model constructed based on four different strategies
策略1(未加入标准差标准化和PCA降维模块):基于该策略构建的随机森林判别模型的最佳模型参数为决策树数量200棵、决策树最大深度3、叶子节点最小样本数1个。模型构建所需计算时间为199.93 s。该模型对验证集和测试集样本的预测准确度分别为100%和94.4%。测试集中有2个内蒙古薏苡仁样品被误判为山东样品,1个山东薏苡仁样品被误判为黑龙江样品。
策略2(仅加入标准差标准化模块):基于该策略构建的随机森林判别模型的最佳模型参数为决策树数量200棵、决策树最大深度3、叶子节点最小样本数1个。模型构建所需计算时间为174.74 s。该模型对验证集和测试集样本的预测准确度分别为100%和94.4%。测试集中有2个陕西薏苡仁样品被误判为山东样品,1个山东薏苡仁样品被误判为黑龙江样品。
策略3(仅加入PCA降维模块):基于该策略构建的随机森林判别模型的最佳模型参数为决策树数量300棵、决策树最大深度6、叶节点最小样本数1个。模型构建所需计算时间为84.59 s。该模型对验证集和测试集样本的预测准确度分别为94.4%和100%。验证集中有2个河北薏苡仁样品被误判为辽宁样品,1个安徽薏苡仁样品被误判为陕西样品。
策略4(加入标准差标准化和PCA降维模块):基于该策略构建的随机森林判别模型的最佳模型参数为决策树数量100棵、决策树最大深度3、叶节点最小样本数1个。模型构建所需计算时间为81.23 s。该模型对验证集和测试集样本的预测准确度均为100%。
综上可知,基于策略4所构建的最优随机森林判别模型的决策树数量为100棵,明显小于其他3种策略所构建模型的数量,且其所需计算时间最短,预测准确度最高。因此,本研究采用的标准差标准化和PCA降维这两个模块均对随机森林判别模型的性能起到了正面作用。
2.2.4 改进随机森林算法与偏最小二乘法构建模型准确度对比使用相同的训练集、验证集和测试集,利用偏最小二乘法构建和测试PLS-DA模型,PLS-DA模型潜变量数(13)由十折交叉验证法确定,其验证集和测试集准确度均为96%。表2为利用偏最小二乘法构建的PLS-DA模型对不同产地验证集和测试集样本的混淆矩阵。由表2可知,在验证集中,有1个河北薏苡仁样品被误判为吉林样品,1个山东薏苡仁样品被误判为内蒙古样品;在测试集中,有1个河北薏苡仁样品被误判为吉林样品,1个内蒙古薏苡仁样品被误判为河北样品。由此可知,利用偏最小二乘法构建的PLS-DA模型虽然可以对不同产地薏苡仁实现有效识别,但其准确度低于改进随机森林算法构建的模型。

表2 利用偏最小二乘法构建的PLS-DA模型对不同产地验证集和测试集样本的混淆矩阵Table 2 Confusion matrix of the PLS-DA model constructed using the partial least squares method for the validation and test samples of different origins
3 结论
本文设计了一种基于EEM荧光光谱与改进的随机森林算法的薏苡仁产地鉴别方法。该方法首先采用标准差标准化对EEM荧光光谱数据进行标准化处理,然后进行PCA降维处理,由筛选出的主成分构成随机森林算法的特征集,最终通过网格筛选法优化PCA降维过程中保留PCs、决策树数量、决策树最大深度和叶节点最小样本数来获得最优随机森林判别模型。结果表明:改进的随机森林判别模型(加入标准差标准化和PCA降维模块)最佳参数为决策树数量100棵,决策树最大深度3,叶节点最小样本数1个;该模型构建所需计算时间仅为81.23 s,对验证集和测试集的预测准确度均为100%,优于偏最小二乘法构建的PLS-DA模型(96%),可以实现对不同产地薏苡仁样品进行准确的溯源分析。本研究为规范薏苡仁产地来源及从源头控制薏苡仁品质提供了一种操作简单、准确度高的技术方案。
