基于特征点匹配的视觉识别方法
2024-01-10林远长
罗 胜 张 彬 胡 严 林远长*
(1 重庆工程学院,重庆,400056;2 中国科学院重庆绿色智能技术研究院,重庆, 400714;3 中科时永(苏州)科技有限公司,江苏苏州,215104;4人工智能与服务机器人控制技术重庆市重点实验室,重庆,400714)
0 引言
随着机器视觉的不断应用,3C 产品制造过程中对视觉识别的速度、精准度的要求也越来越高。为了满足3C产品的制造要求,即在安装过程中更加快速识别电阻、电容等器件,需要对视觉识别的方法进行改进,以提高工作效率。
HSU 等人[1]开发了一套机器视觉系统,该系统可以在不同光照环境下使用六自由度机械臂来实现对物体的自动分类。ENGEL 等人[2]提出了一种实时视觉测距方法,采用单目摄像机对运动物体进行跟踪,通过密集图像对目标进行定位对齐,提供增强现实的参考依据。HAJILOO 等人[3]为六自由度单目机器人设计了视觉伺服系统控制器。TAHERIMAKHSOUSI 等人[4]制造了一种便于大面积钙钛矿光电优化的机器视觉工具。唐旭等人[5]开发了Kinect 视觉系统,该系统安装在双臂机器人上对目标物体进行图像预处理和分拣。韩博等人[6]开发了一套立体视觉系统,采用双目摄像机,利用改进的Otsu 算法分割工件,通过分类识别算法实现了工件的三维定位,最终提高了工件的识别率。张文卓等人[7]采用灰色狼优化算法优化的模糊C 均值算法和改进的卷积神经网络结合状态转移算法(STA)识别柑桔表面缺陷。
视觉识别算法发展至今种类繁多,本文提出一种基于特征点匹配的视觉识别方法,该方法利用机器视觉的目标识别检测法,对视觉识别所需时间进行研究,经YOLOv5 算法、图像处理和手眼标定处理,通过分析该方法四种不同结构对处理速度和精准度的对比验证,选择合适的结构与权重文件,快速检测产品安装所需3C 产品,并实现目标定位,提高了生产效率。
1 系统硬件设计
图1 所示为视觉系统总体组成图。搭建视觉平台的主要部件有:工业相机、工业镜头、工控机(电脑)、协作机器人。
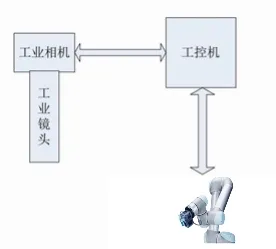
图1 视觉系统总体组成图
视觉平台的主要功能是图像采集和处理、坐标转换、数据传送给机器人引导抓取,硬件设备经选型后进行组装搭建调试。
2 软件算法研究
2.1 Halcon 软件的视觉标定
Halcon 软件是一种功能强大的机器视觉图像处理工具,具有多种优点,使其在该领域中发挥着重要的作用。Halcon 拥有众多封装完善的算子;多种编程语言可直接访问函数库;调用方便快捷,且不限制拍摄设备;集成多种内部接口,完成编程后可转化为所需语言代码;人性化的交互式程序设计界面,使其成为一个可广泛应用于各种图像处理任务的可靠工具。
2.1.1 相机标定
相机标定是确定相机成像几何模型的参数,即确定空间物体表面点与图像点的关系,求解该参数的过程称为相机标定。本文采用蜂窝式标定板对相机进行标定,先创建所用标定板的描述文件,在Halcon 中使用算子create_caltab 生成标定板的(.cpd)文件,并设置标定板相关数据。蜂窝标定板如图2 所示。

图2 HG-90 蜂窝标定板
利用Halcon 相机标定助手,导入标定板描述文件,修改摄相机参数,如单个像元的高、宽和焦距等等。利用标定助手实时获取标定板的图像9-16 张,选择其中的一张图片用做参考位姿,最后对相机进行标定。标定结果如图3 所示。
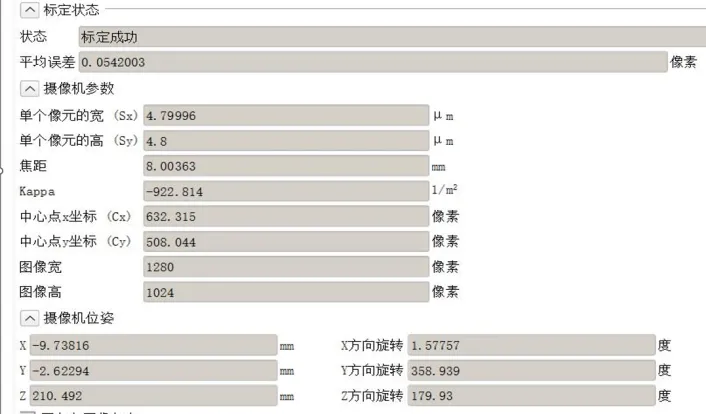
图3 相机标定结果(相机内外参)
标定结果展现出了像素的平均误差,平均误差越小,说明标定的结果越准确,从图像可以看出,标定数据包括单个像元的高和宽、焦距、中心点的坐标等等,这些参数代表的是相机的内参,而相机的位姿代表的则是相机的外参。对相机的内外参进行保存,或将其转化为代码,方便后续直接调用。
2.1.2 手眼标定
本文采用九点标定法进行手眼标定。在该标定方法中,机械手所处的空间坐标系与相机生成的像素坐标系之间存在一种转化关系。九点标定法可以确定空间坐标系与像素坐标系之间的转化关系,从而实现空间坐标与像素坐标之间的相互转换。
九点标定顾名思义,需要使用九个点进行标定,既需要在图像中获取其像素坐标,也需要在空间坐标系中确定其空间坐标,再通过仿射变换矩阵计算出转换关系。
完成手眼标定后,用affine_trans_point_2d 算子对二维点进行仿射变换,将该算法处理对象的像素坐标转换成世界坐标。
2.2 Python 语言的算法研究
Python 是一种简单易学、语法简单、文档齐全、自由开源的编程语言,可以自由复制Python 软件、阅读源代码、修改源代码并在新软件中使用。Python 语言可以不考虑程序所用内存的底层细节,可在Linux、Windows、Amiga、AROS、VMS、Acom RISC OS 等多个平台使用。
2.2.1 算法原理
YOLOv5 算法的结构大致分为Input(输入端)、Backbone(骨干网络)、Neck(特征融合部分)和Prediction(预测头部)等四个部分。
Input 具有数据增强功能,同时也可以进行自适应锚框计算,以实现图像的缩放。Mosaic 数据的增强包括随机缩放、随机裁剪和随机排列等操作,以提高图像质量。为了避免传统方法中的过拟合问题,本文引入了一种新的图像匹配算法,用于实现特征提取,以增强对小物体的检测效果。自适应锚框计算指的是根据不同数据集的锚框初始长度,通过网络层输出预测框,并将预测框与真实框进行比较,计算二者之间的差异,并进行反向更新,迭代网络参数。然而,一般的目标检测算法要求输入检测图像的长度和宽度相等,并将输入图像统一缩小到标准尺寸,然后由检测网络进行处理。
在Backbone 中,存在两种结构,即Focus 和CSP,Focus 结构是YOLOv5 中的轻量级特征提取器,旨在保持较低计算成本的同时提取有效的特征,而CSP 结构是一种更复杂和强大的特征提取器。Focus 结构实现了切片操作,可以将部分处理过的图像切成N×N×M 特征。图4展示了Focus 结构的切片结构图。在YOLOv4 算法中,主干网络仅使用CSP 结构。而在YOLOv5 中,引入了两个CSP 结构,一个用于主干网络,另一个用于Neck 部分。

图4 Focus 结构切片操作图
Neck 网络主要采用特征金字塔网络(Feature Pyramid Network, FPN)和路径聚合网络(Path Aggregation Network, PAN)的结构,以增强网络特征融合能力。这种结构能够有效地将不同层级的特征进行融合。Prediction部分包含两种函数,一种是Bounding box 损失函数,另一种是非极大值抑制(Non-Maximum Suppression,NMS)。在目标检测的后期阶段,为了筛选出多个目标框,使用NMS 操作对结果进行改进。
YOLO 系列的算法包含四种网络结构(s、m、l、x),这些结构通过控制网络的深度和宽度来发挥作用,s(small)模型相对较小,具有较低的参数数量和计算复杂度;m(medium)模型具有中等的模型规模,介于小型和大型之间;l(large)模型比中等规模的模型更大,通常包含更多的参数和更多的层次;x(extra large)模型是最大的,通常具有最多的参数和最大的深度,因此是最复杂的模型。不同结构的网络具有不同数量的卷积核,这不仅会影响CSP 等结构的性能,还会影响各个普通卷积层。随着卷积核数量的增多和特征图宽度的增大,网络的特征学习能力得到了增强。
2.2.2 YOLOv5 算法重要代码的作用
YOLOv5 算法中包含大量的代码,每个代码片段都具有不同的功能。图5 展示了YOLOv5 算法训练数据集yaml 文件中非常关键的代码段。以下对其中的几行代码进行解释:第13 行的代码用于准确读取训练数据集中的图片;第14 行的代码则是用于提前打好标签的相关图片数据;第17 行的代码表示数据集中所包含的目标类别数量;第20 行的代码用于给三种测量物体打上标签。这些代码段是训练数据集中的重要参数设置。

图5 LJ.yaml 文件代码
在训练数据集的过程中,需要从四个网络构建的配置文件中选择一个。这四个文件具有不同的检测速度和精确度。本文选用.s 文件,尽管它的精确度较低,但它具有最快的检测速度。图6展示了所选文件中的部分代码。其中,第2 行的代码用于设置目标的种类数量,即在图像打标签时需要进行分类的类别数量,需要将该数字修改为相应的值。第3 和第4 行的代码是宽度和长度的缩放比例系数,这些系数在每个文件中都是预先计算好的,无需更改。

图6 YOLOv5s_LJ 相关代码
在准备好前期工作后,可以使用train.py 文件中的代码对数据集进行训练。图7 展示了训练数据集时的重要设置部分代码。以下是对其中几行代码的修改说明:第461 行的代码用于初始化权重文件的路径地址,将下载的权重文件的路径复制到代码中。第465 行的代码用于读取模型的yaml 文件。第469 行的代码用于设置数据集yaml 文件的路径地址。第474 行的代码可以设置训练的轮数。第477 行的代码可以调整批次文件的输入数量。第483 行的代码用于设置最大的工作核心数。这两行代码对电脑的配置要求较高,电脑配置较低可以减小这两个参数值,配置较高,可增大这两个参数值,参数的增大会加快训练图片数据集的速度。
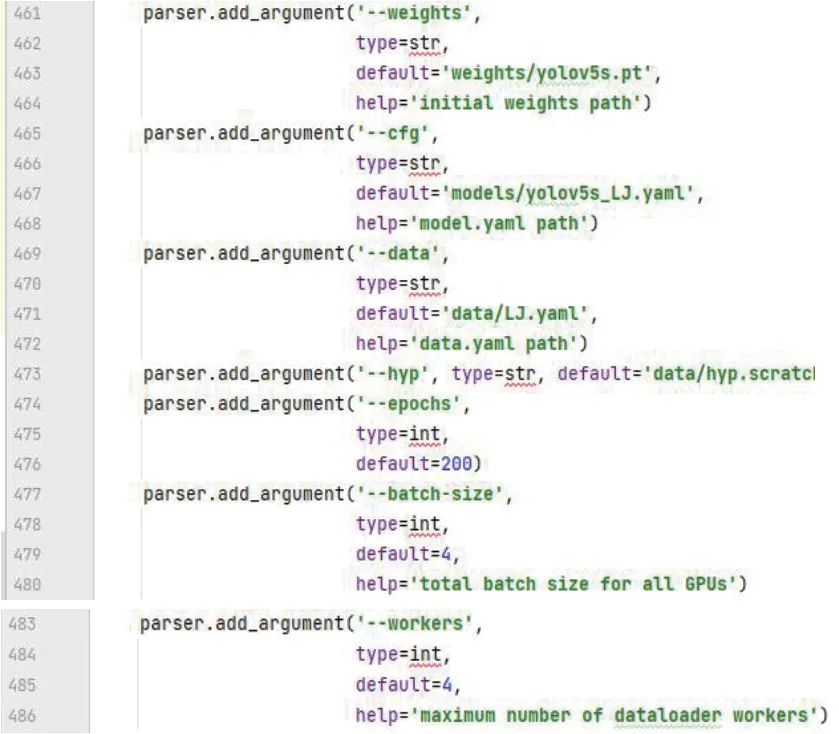
图7 训练数据集的主函数部分代码
数据集训练完成后,使用detect.py 文件中的代码对图片进行检测。图8 展示了detect.py 文件中主函数部分的代码。以下是对其中几行代码的修改说明:第151 行的代码表示权重文件的路径地址,该权重文件是训练数据集后得出的最佳权重文件。第156 行的代码用于读取待检测的图片或视频的路径地址,将路径地址设置为0可进行实时检测。

图8 图像检测的主函数部分代码
3 实验验证与结果分析
本文以电阻、电容、电感等3C 零件为实验对象,图像采集后用Halcon 的标定结果(相机的内外参数)对图像进行矫正,通过YOLOv5 算法进行目标检测和识别。在使用算法之前,必须对训练图片进行标注打标签,并将其转换为适当的格式,以此创建训练集和验证集。此外,还需下载相应的预训练权重,以便开始训练自己的模型。图像处理后,需要计算物体在图像中像素坐标,并转换为机器人所能识别的三维空间坐标。为此,采用九点标定法进行手眼标定,结合相机的标定结果,将物体所在位置的像素坐标转换为世界坐标。随后将这些坐标数据发送给机器人,引导机器人进行抓取操作。最后,使用PyCharm 集成所有程序,实现整体的功能。
在YOLOv5 算法中有s、m、l、x 等四个不同结构,结构不同,其检测速度与检测精度也不相同,实验结果如表1 所列:
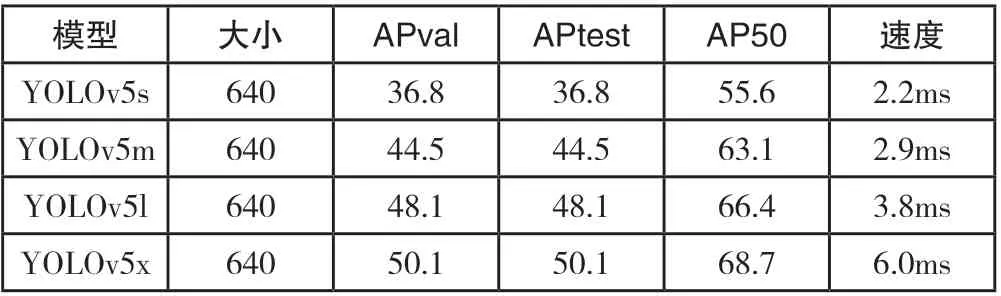
表1 YOLOv5 算法四种结构对比图
其中,AP 为平均精确率,APtest、AP50 和APval 是三种不同类别的平均精确率,在同一个处理器(GPU)处理下,输入大小一样的图片,通过平均精确率和不同类别的平均精确率,我们可以评估算法在不同结构下的检测性能。根据数据分析,四种结构的检测精度均满足要求,YOLOv5x 在APval、APtest 和AP50 最高,这表明YOLOv5x 在检测精度方面表现较好。YOLOv5s 在速度方面是最快的,仅需2.2ms,而YOLOv5x 则需要6.0ms,识别时间花费最多,速度最慢,且达不到检测速度要求。
因此,本文选择YOLOv5s 作为本项目的权重文件,YOLOv5s 在处理速度上表现非常出色,与较高的检测精度之间取得了良好的平衡。
图像识别检测的精准度还与训练数据集的轮数有关,下面是训练数据集轮数为200 轮的相关照片,图9 是训练完成后得到的真实值的结果图。图中16 个正方形表格中,FN 是将要识别的物体错认为是背景,FP 是代表背景可能会误识别成需要识别的物体,正方形中的数字是百分比分数。其余正方形是需要识别的物体在其他训练集中训练得到的分数,用不同的图片训练出的分数也不一样。
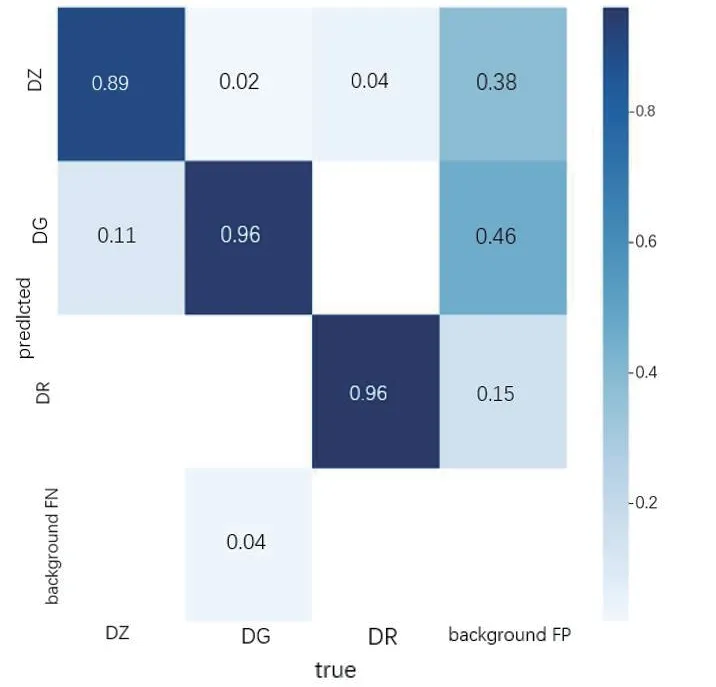
图9 真实值结果图
图10 是真实值的曲线图,F1 是精确率(模型识别出的样本数占所有样本数的比例)和召回率(模型识别出的样本数占真实样本数的比例)的调和平均数,横轴为置信度阈值,置信度阈值的设定影响检测结果的精确度和召回率。数据集训练完成后结果的曲线图如图11 所示。

图10 真实值曲线图
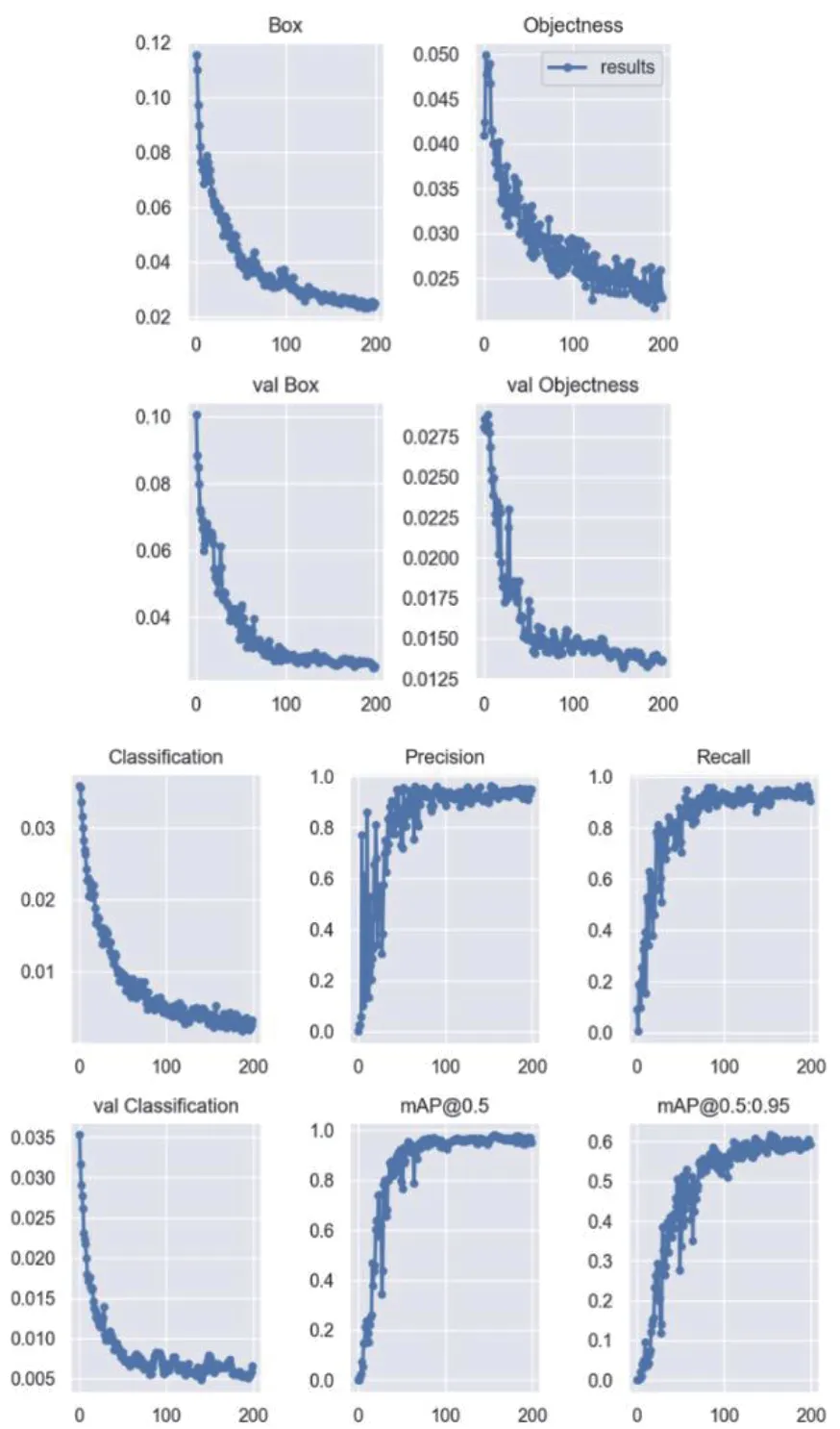
图11 结果曲线图
图11 中,横轴为做训练集图片的张数;Box:YOLOV5使用GIOUloss 作为bounding box 的损失。Box 推测为GIoU损失函数均值越小,方框越准;Objectness:推测为目标检测loss 均值,越小目标检测越准;Classification:推测为分类loss 均值,越小分类越准;Precision:精度(找对的正类/所有找到的正类);Recall:真实为positive 的准确率,即正样本有多少被找出来了(召回了多少);val BOX:验证集bounding box 损失;val Objectness:验证集目标检测loss 均值;val classification:验证集分类loss 均值;mAP@0.5:表示阈值大于0.5 的平均mAP;mAP@0.5:0.95(mAP@[0.5:0.95]):表示在不同IoU 阈值(从0.5 到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
训练得到的真实值高,各种曲线稳定,此数据集对物体进行检测,得出的精准度较高,识别检测结果如图12 所示。

图12 识别检测结果图
使用训练后的数据集对物体进行检测,检测结果表明,识别图片最快的时间为0.02s,得出结果并保存图片的时间为0.06s,对3C 零件的识别检测有着不错的表现。
4 结束语
本文针对3C 产品制造过程中的检测和识别要求,提出一种基于特征点匹配的视觉识别方法,利用YOLOv5软件算法搭配硬件系统,可以快速检测产品安装所需3C产品,提高生产效率。经实验表明,识别检测物体所需要的时间最快为0.02s,识别物体并输出结果图片的最快时间约为0.06s。通过实验验证了该方法对3C 产品的检测有着良好的效果。
