基于改进YOLO v5的矿山石块实例分割算法
2024-01-09曹士杰张竹林
曹士杰,张竹林
(山东交通学院 汽车工程学院,山东 济南 250023)
矿山工程建设面临复杂的地质与环境条件,存在较强的安全风险。以云计算、人工智能算法等共性支撑技术为基础的数字孪生技术的快速发展及应用,使数据的实时获取、瞬时传输、快速计算、智能决策等成为了现实,为实现安全、绿色、高效、智能发展与赋能零碳矿山的建设提供了有力的技术支撑[1]。作为液压挖掘机的一个重要作业工具,对于从事开矿、二次破碎等工作发挥着重要作用,而完成对破碎目标的准确识别是实现液压破碎锤挖掘机无人驾驶的关键一步。
由于矿山石块大多为开山作业形成,其结构特征通常较为复杂。而且矿山环境存在目标堆积、遮挡等问题,目标的漏检、误检很容易发生。研究人员提出了一系列目标检测改进的方法,杨丽荣等[2]结合混合注意力模块改进Mask RCNN的分割网络结构,减少卷积运算造成的矿石细节信息丢失问题,提高了分割精度。司晨冉等[3]提出了一种基于Mask R-CNN和分水岭算法的岩石颗粒图像分割方法,首先利用改进的CNN方法防止大块岩石出现过分割。汤文聪等[4]提出了一种基于FCM-WA联合算法的矿石图像分割方法,将模糊C均值聚类(FCM)算法与分水岭(WA)算法相结合,对FCM算法输出的矿石图像边缘粘连部分进行分割,获取最佳的分割图像。
以上方法虽然保障了检测精度,但检测速度有所牺牲,且计算量较大,操作较为复杂。本文通过采集到矿山石块相关图片信息,考虑图像处理方法的通用性,研究利用机器视觉技术识别石块的方法。为改善目标漏检、误检问题,并保证模型的检测精度与轻量化,提出了基于YOLO v5的实例分割模型。
1 改进的YOLO v5算法
YOLO v5的7.0版本提供了5种实例分割模型,综合考虑各模型的检测速度、模型大小及检测精度,本文选择YOLO v5l-seg作为进一步优化的模型。
1.1 SA注意力机制
注意力模块是网络设计的重要组成部分,为关注有用的特征信息,提升模型性能,可以引入ECA[5]、CBAM[6]、CA[7]等注意力模块。ECA注意力机制通过不降维的局部跨信道交互策略,使用了1-D卷积来生成通道间注意力机制,降低模型的复杂度,但其准确度无法保证;CBAM注意力机制主要聚焦于空间信息的聚合,但效果未达到最优。本文通过引入Shuffle-Attention(SA)[8-9]注意力机制提升模型效果。SA注意力模块结合了组卷积,空间注意力机制和通道注意力机制。不仅能取不同通道间的信息,还能降低计算量,有助于实现目标的精确定位和识别。SA注意力模块将输入序列打乱再重新排序,并计算每个位置的重要性,得到注意力权重,与传统的注意力机制相比,在计算效率提高的同时,提高模型的泛化能力,使模型在训练数据和测试数据上的表现更加一致。SA注意力模块如图1所示。

图1 SA注意力模块的整体结构
从图1给出的SA注意力模块整体结构示意可以看到,它首先采用Feature Grouping对输入尺寸为X∈RC×H×W的特征图X,沿着通道维度划分为g个组:X=[X1,…,XG],RC/G×H×W,特征X会被拆分成2个分支:Xk1,Xk2∈RC/2G×H×W,分别用于学习通道注意力特征和空间注意力特征。对每组特征通过SA Unit模块Concat的方式将组内信息进行融合,生成不同的重要性系数。SA内部绿色部分为通道注意力机制,采用GAP+Scale+Sigmoid的组合,该过程可以描述如下。
(1)
(2)
SA内部蓝色部分为空间注意力机制,采用Group Norm(GN)对Xk2进行处理得到空域层面的统计信息,然后采用Fc(·)进行增强,该过程可以描述如下。
(3)
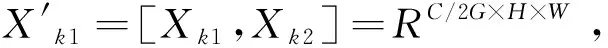
1.2 ASPP模块
图片中的相邻像素点一般都存在信息的冗余问题,传统的下采样虽可增加感受野,但会降低空间分辨率。为了获得更大的感受野,减少信息的冗余问题,实现矿山石块的精确分割,选择将主干网络中的SPPF模块替换为Atrous Spatial Pyramid Pooling(ASPP)[10]模块。
ASPP模块使用并行空洞卷积层进行采样,获得不同采样率的提取特征,处理后的分支特征融合后,最终结果在保证分辨率的同时可以获得更大的感受野和多尺度的物体信息。通过赋值不同的膨胀因子实现不同的感受野,进而获取多尺度信息,具体实现如图2所示。

图2 ASPP模块结构
ASPP模块由一个1×1的卷积(最左侧绿色)、池化金字塔和ASPP Pooling 3个部分组成。池化金字塔各层分别为卷积核大小为3×3的3个卷积层,每个卷积层的padding和dilation分别为6、12、18。空洞卷积[11]层通过控制padding以及dilation 2个参数控制膨胀率,获取不同尺度的感受野来实现多尺度的特征信息提取。ASPP Polling 部分首先是一个指定最后输出尺寸为1×1的自适应均值池化(AdaptiveAvgPool2d)层,通过将各通道的特征图分别压缩至1×1,从而提取各通道的特征,获取全局的特征。然后是一个1×1的卷积层,将获取的特征进一步提取并降维。通过Upsample利用传统插值方法进行上采样还原成原始输入大小,出层后对ASPP五层输出进行Concat融合,对叠加后的输出用1×1卷积层卷积操作降维至给定通道数,得到最终输出结果。Concat融合过程表述如式(4)所示。
n=k+(k-1)×(d-1),
(4)
式中:n为现在的卷积核大小;k为原卷积核大小;d为超参数;d-1的值为加入的空格数。令o为空洞卷积后的特征图大小,i为输入空洞卷积的大小,s为步长,则有
(5)
全局平均池化后上采样的输出等于每个空洞卷积的输出,可以实现在通道维度的Concat融合。
1.3 加权双向特征融合模块设计
YOLO v5的实例分割算法主干特征提取网络为CNN网络,颈部层采用PANet结构,由于存在冗余信息的融合,计算量过大,通过用改进后的加权双向特征金字塔[12]网络(BiFPN)替换原PAN结构,并将multi-head self-attention(BoT)[13]处理框架融合到网络颈部中,形成BIFPN+Transformer(BBIFPN)架构,充分发挥两者优点,提高对密集目标的检测效果。
BoT使用sgd+momentum构成的优化器进行训练,通过Batch Normalization模块完成归一化操作,并在FPN block模块中作用了3个非线性激活。改善基线的同时减少了参数量,从而实现了延迟最小化。图3(a)是传统的Transformer[14]模型,图3(b)是BoTNet模型,图3(c)是BoTblock模型。
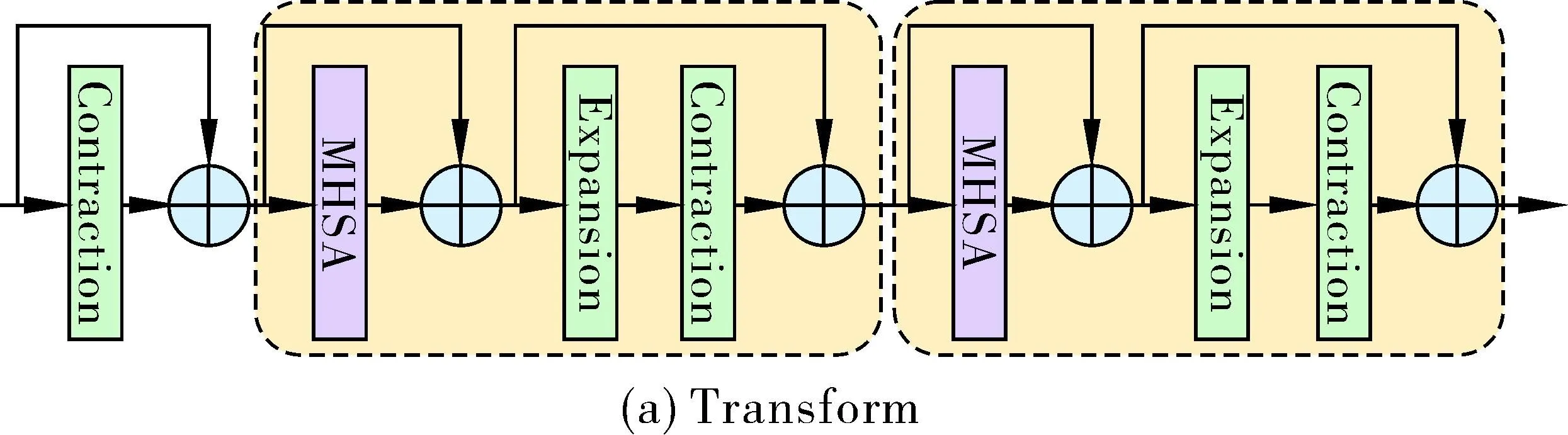

图3 BoT模块
本文特征融合结构改进点如下:
(1) 融合Bottleneck Transformers处理框架。在实例分割任务中纳入自注意力,用全局自注意力替换空间卷积,减少参数,从而使延迟最小化,更有利于实现密集预测任务。
(2) 删除冗余节点。特征融合后的节点,对于特征网络的贡献相对更大,因此保留网络中进行特征融合的节点,删除单独输出的节点,有效减少模型计算量。对相同尺度的输入节点与输出节点之间添加跳跃连接,如图6中间虚线所示,在不增加太多计算成本的同时,融合了更多的特征。
(3) 加权特征融合。引入可学习的权重,使网络更关注关键特征学习。通过Fast normalized fusion集成双向跨尺度连接和快速归一化融合。具体计算过程可以表示为
(6)
式中:Ii表示输入特征图;wi为权重系数,使用Relu激活函数保证该值始终大于0;ε为学习率,值为10-4。
以level4的融合特征为例,计算过程如式(7)~(8)。
(7)
(8)


图4 特征融合模型
1.4 网络轻量化
在引入BBIFPN架构后,检测精度有了很好的改善,为了进一步减少计算量,提高推理检测速度,降低模型体积,采用轻量化模块优化网络。YOLO v5特征提取网络原始C3结构,参数量与模型过于庞大,容易产生检测速度、响应速度慢,内存不足的情况。本文通过引入Ghost[15]网络,减少特征图中的冗余来实现高效的神经网络。
Ghost模块由3步操作完成,假设原始卷积操作中特征图输入数据为h×w×c,卷积核维度为n,尺寸为k×k,卷积后输出的本征图(intrinsic)数据为h′×w′×m。
(1)对于输出通道较少的特征图使用m组k×k的Kernel与input进行原始卷积。
(2)其他的ghost特征图通过廉价操作生成,即将本征图的每个通道单独进行线性变换产生。
(3)将前两步得到的特征intrinsic和ghost进行identity连接得到最终结果。
假设在Ghost模块的线性操作中有m个恒等映射和n-m个线性运算,且每个线性运算的平均核大小等于d×d,则用Ghost模块替换普通卷积的理论加速比(speed up ratio)为
(9)
理论压缩比(compression ratio)为
(10)
由此可知,通过使用Ghost模块,理论上可以获得s倍的加速比和压缩比,有效减少模型的体积,提高模型的运算速度。本文构建了Ghostconv、GhostBottleNeck和GhostC3模块,如图5所示。

图5 Ghost系列模型
1.5 Rock-YOLO v5模型整体结构
Rock-YOLO v5模型从以下4个方面对模型进行了优化:
(1)融合Shuffle-Attention(SA)注意力机制。
(2)优化主干网络,将SPPF模块替换为ASPP模块。
(3)设计BBIFPN框架优化路径聚合网络(Path Aggregation Network,PAN)。
(4)网络轻量化。
最终建立的模型结构如图6所示。

图6 Rock_YOLO v5模型结构
2 试验结果分析
2.1 数据集及试验环境介绍
本文所有试验均在Windows10系统上进行,CPU为Intel(R) Core(TM) i7-10700,GPU为NVIDIA GeForce RTX 3070,显存为8 GB,采用的深度学习框架为Pytorch1.7.1,参数环境CUDA版本为11.0,编译语言为Python-3.9.13,训练批尺寸(batch_size)设置为4;迭代次数(epoch)为100;输入图片大小为640×640。试验所使用的数据集为实地采集的石块数据集,共有4 556张高清图片。石块数据集按照7∶1∶2的比例随机划分训练集、测试集、验证集3个部分,分别为训练集3 188张,测试集456张,验证集912张。
2.2 结果分析
为验证引入注意力机制、ASPP模块、Ghost模块和BBIFPN架构后对实例分割任务产生的影响,本文通过消融试验进行测试,评估指标包括参数量(params)、计算量(FLOPs)、mAP50等。mAP50为IOU>5时的mAP。
对于三类损失曲线:定位损失(box_loss)、分割损失(seg_loss)、置信度损失(obj_loss),改进模型收敛速度更快,训练损失图像如图7所示。为验证不同注意力机制对模型性能提升的影响,进行对照试验,对比加入不同注意力机制后对网络性能的提升效果,结果如表1所示。

表1 注意力机制性能对照
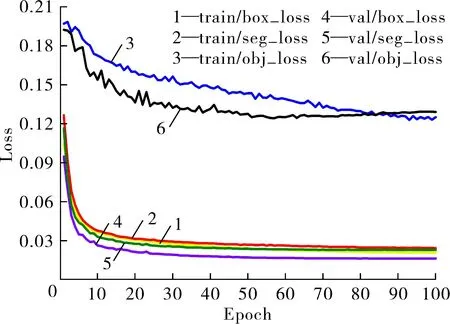
图7 训练损失图像
由试验结果可知,各注意力机制均对分割精度有提升效果,添加SA和CA注意力机制后,准确率提升最高,达到86.4%,但SA注意力机制的计算量与参数更少,因此选择SA注意力机制对模型进行优化。
进行消融试验验证改进前后相同条件下对算法性能的影响,结果如表2所示。

表2 消融试验
改进后的模型获得了mAP的提升,虽然FPS值有所下降,但还是可以满足无人驾驶破碎锤视觉实时性的要求。引入SA模块后,mAP提升了1.4%;引入ASPP模块时,mAP提升了2.8%;引入BBIFPN架构时,mAP提升了2.2%,证明本文提出的特征融合结构对于实例分割任务有正面作用,通过引入Ghost模块极大的减少了网络复杂度。使用GhostConv系列模块替换掉原始模块后,参数量减少了42.4%,保障了模型的轻量化。
设置对照试验,验证对于密集目标实例分割任务的效果。图8为YOLO v5原始模型与改进后模型对于密集目标任务的检测对比图,由图8可知,引入空洞卷积、SA注意力机制和加权跨层特征融合模块后,对目标关注度提升更大,对位置信息的捕捉更为精确,从而提高模型精度。当石块分布为密集时,原算法出现了漏检的情况,一些石块没有被分割出来,而Rock_YOLO v5模型检测结果有不错的提高,漏检的情况有所改善,验证了改进算法具有更高的检测精度。

图8 密集目标检测对比效果
3 结语
本文建立了Rock_YOLO v5实例分割模型,结合通道注意力机制与空间注意力机制,对原始算法进行改进,并在矿山石块数据集上进行了试验验证。针对密集目标实例分割任务的漏检、误检问题,通过引入SA注意力机制、ASPP模块和改进的BBIFPN模块对实例分割网络进行优化。SA注意力机制和ASPP模块使网络更有利于关注位置信息和获取感受野,更有利于网络对密集目标物的定位和识别,改进后的BBIFPN模块通过多尺度特征信息和融合,使模型提取到更丰富的特征,有效提高了模型的准确率。引入Ghost模块后,减轻了模型的计算量和参数,降低了显存和要求。试验结果表明,相比YOLO v5l-seg,本文提出的改进算法具有更好的准确性和实时性,可以完成无人驾驶破碎锤识别目标石块的任务。本文改进后的模型在解决行业难题,特别是处理遮挡和密集问题方面具有参考价值。但是也存在训练和推理时间增加的问题,可以从边缘平滑和分割体验优化方面,进一步提升Rock_YOLO v5模型的性能,更有效地分配和利用资源。
