融合图神经网络和稀疏自注意力的会话推荐分析
2024-01-09胡胜利
胡胜利,程 春
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
推荐系统[1]作为统筹互联网上众多数据的工具之一,在缓解信息过载、提升用户体验方面发挥着重要作用[2]。会话式序列推荐[3]是序列推荐研究的分支之一,它不依赖用户历史交互,可以在用户未注册或登录时仅提取一段时间内的用户行为信息,预测用户在当前会话中的下一个行为(如点击某个项目)。为实现更好的推荐效果,近年来国内外学者针对会话推荐做了很多研究工作。早期的马尔可夫链[4]模型将推荐生成处理成序列化问题,假设用户的下一个动作仅基于之前的动作。Hidasi等人基于循环神经网络(RNN)提出GRU4Rec[5]模型。模型利用门控循环单元(GRU)对序列信息进行建模。SR-GNN[6]第一次提出将会话信息映射为图结构,将序列问题转换成图的问题,通过GNN来学习项目的隐向量表示。GC-SAN[7]在SR-GNN的基础上将一个会话经过多个自注意力层,以捕获长期依赖关系。GCE-GNN[8]提出构建全局图和局部图来分别提取会话信息。由于传播的迭代有限,GNN在捕获相邻物品间的局部依赖时效果显著,但在捕获项目间的长距离依赖关系中效果并不明显[9]。有学者将在自然语言处理中表现优异的Transformer模型用于构建推荐系统,虽然其采用自注意力机制[10]捕获所有物品间的全局依赖,但它在捕获相邻物品间短距离的复杂依赖时效果不够明显。
鉴于以上问题,为了能够有效提取会话序列的全局和局部信息,本文提出一种融合图神经网络和稀疏自注意力的会话推荐模型(session-based recommendation fusing graph neural networks and sparse self-attention,SSA-GNN)。模型采用2种不同编码方式,全局信息提取采用稀疏自注意力网络,局部信息提取采用添加目标注意模块的图神经网络,最后将2个模块线性连接,完成推荐。
1 SSA-GNN模型设计
1.1 问题定义
1.2 模型结构

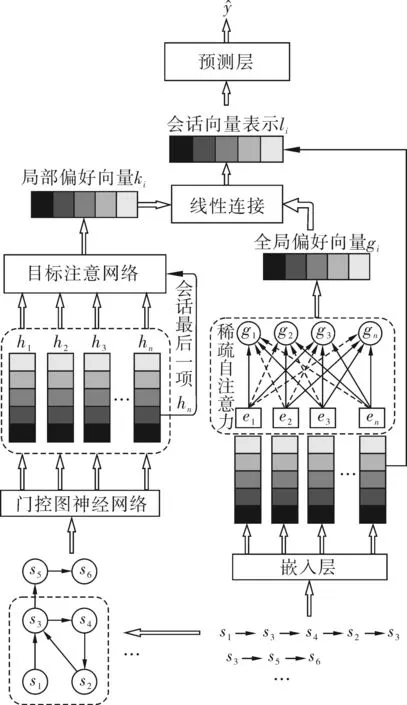
图1 SSA-GNN总体框架
1.2.1 嵌入层
嵌入层将输入的会话序列映射为低维稠密向量表示。将会话序列S=[s1,s2,...,sn]输入到嵌入层,通过填充0或利用最近交互保留的方式将其处理成长度为n的定长序列,得到对应的嵌入序列E=[e1,e2,...,en],其中ei∈Rd,d为嵌入的维度。
1.2.2 全局信息提取网络
自注意力机制可以不考虑项目与项目间的距离,减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性[11]。本文为区分会话中的无关信息,将注意力机制中的softmax转换函数替换为α-entmax[12]函数。α-entmax函数可以将与目标项毫不相关的项目权重置为0,减少了无关项目的干扰。α-entmax函数的公式如式(1)~(2)所示。
(1)
(2)
模型首先采用带稀疏转换的自注意力来捕获会话中项目对之间的依赖关系
(3)
式中:WQ、WK和WV∈Rd×d分别为查询、键、值参数矩阵;E为经过嵌入层得到的嵌入序列。为防止点积运算中内积太大,将查询向量和键向量的点积除以d/2,同时添加残差连接以减少在网络传播过程中的信息损失。采用一种自动学习α的方法,允许每个会话根据上下文自适应地选择参数,以确保学习到的项目嵌入包含尽可能少的无关信息。对于每个会话,模型学习自身α的方式如式(4)所示。
α=sigmoid(Wαei+bα)+1,
(4)
式中:Wα∈R1×d表示参数矩阵;bα∈Rd为偏置向量。
然后将上述F输入到添加残差连接的前馈神经网络中,使模型得到更好的非线性表示。最后,在模型中添加dropout机制以减轻过拟合。
G=max(0,FW1+b1)W2+b2+F.
(5)
式中:G=[g1,g2,...,gn]为会话中物品的全局隐向量;b1∈Rf、b2∈Rd为偏置向量,所有会话将共享相同的参数;W1∈Rd×f,W2∈Rf×d为参数矩阵;全局信息提取网络的输出用G表示。
1.2.3 局部信息提取网络
把每一个会话序列S=[s1,s2,...,sn]都表示成一个单独的有向图,再将所有节点si∈V映射到一个统一的嵌入空间,si∈Rd是经图神经网络后得到的d维特征向量,项目s的隐向量用hs∈Rd表示。对于图Gs的节点si,其更新规则如式(6)~(10)所示。
(6)
(7)
(8)
(9)
(10)
式中:t表示卷积层数,模型将会话建模成有向图;Ai∈R1×2n代表邻接矩阵的第i行对应于节点si;H∈Rd×2d代表可训练的权重;b∈Rd为偏置矩阵;σ(·)是sigmoid非线性激活函数;⊙代表点积运算。
模型采用局部目标注意模块,用于计算会话V中所有项目vi和每个目标项目st∈S之间的注意分数。首先,用权重矩阵W∈Rd×d参数化共享非线性变换应用于每个节点目标对。然后使用softmax函数标准化自注意分数,如式(11)所示。
(11)
最后,对于每个会话,用户对目标项st的兴趣由kt∈Rd表示,即
(12)
将最后一个项目作为短期偏好的局部嵌入能够有效提高推荐结果的准确性。hn∈Rd表示每个会话最后访问项目sn的嵌入向量表示。将目标嵌入和局部嵌入进行线性组和,为每个目标项目生成会话嵌入,如式(13)所示。
K=W2[kt;hn].
(13)
式中:W2∈Rd×2d是将两个向量投影到一个嵌入空间Rd中;K=[k1,k2,...,kn]表示局部隐向量的输出。
1.2.4 预测层
在预测层将序列中的第i个物品经过2个深度学习网络得到的局部隐向量ki和全局隐向量gi进行线性连接,如式(14)所示。
li=ωgi+(1-ω)ki,
(14)
式中:ω为线性连接的比例;L=[l1,l2,...,ln]为经过线性连接后的会话向量表示。

(15)
(16)
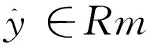
为训练模型,将损失函数定义为真值与预测值之间的交叉熵,如式(17)所示。
(17)
式中:有效物品的独热编码用y表示,算法优化的损失函数采用时间反向传播(BPTT)算法。
2 试验结果与分析
2.1 数据集
SSA-GNN模型使用Yoochoose1/64[13]数据集和Diginetica[14]数据集进行评估。为过滤噪声数据和使试验数据具有可比性,先预处理掉数据集中出现次数少于5的项目,再屏蔽掉2个数据集中长度少于2的所有会话。Yoochoose1/64将上周的会话数据作为测试集,Diginetica将上周的会话数据和最后一天的数据作为测试集,2个数据集中剩下的部分分别作为训练集。通过对会话序列S=[s1,s2,...,sn]分割预处理,生成序列和相应的标签,即([s1],s2),([s1,s2],s3),...,([s1,s2,...,sn-1],sn)用于数据集的训练和测试。表1为2个数据集的统计数据。

表1 试验数据集统计
2.2 评价指标
Precision@20(P@20)和MRR@20是基于会话推荐的2种常用评估指标,前者评估未排名列表中正确推荐项目的比例,后者进一步考虑正确推荐项目在排名列表中的位置。
2.3 试验设置
模型在所有试验中将隐藏维度设置为d=100。Adam优化器的初始学习率设置为0.001,每3个训练周期后衰减0.1。2个数据集的批处理大小都设置为100,L2正则化设为10-5。
2.4 消融试验
为进一步研究全局偏好和局部偏好对会话推荐的影响,本文设计了SSA-GNN的2种变种模型来分别分析对模型性能的影响,如图2所示。其中, SSA-GNN-L表示仅使用目标感知注意的图神经网络局部网络模型, SSA-GNN-G表示仅使用稀疏自注意力的全局网络模型。

(a) 不同网络对P@20的影响
图2的试验结果直观的展示了使用不同网络对推荐结果的影响。以Diginetica为例,SSA-GNN在Diginetica数据集上的P@20比SSA-GNN-L提高1.25%,比SSA-GNN-G提高1.37%;MRR@20比SSA-GNN-L提高0.78%,比SSA-GNN-G提高3.47%。依据试验结果分析,SSA-GNN试验数据相较于SSA-GNN-G有较大提升,SSA-GNN-L比SSA-GNN-G效果更好。因为Diginetica数据集包含大量重复点击行为且行为相关性较强,在处理短距离复杂依赖时自注意力机制的效果没有图神经网络好,且SSA-GNN-L中还添加了目标注意模块,能捕获更深层次的项目间关系。此外,可以看到SSA-GNN模型比任意一个单个模型的推荐效果都要好。
图3的试验结果展示了全局网络中使用稀疏自注意力与只使用普通自注意力之间的结果对比。与普通自注意力相比,使用稀疏自注意力的全局网络在Diginetica数据集上的P@20指标提高0.16%,MRR@20提高0.75%,在Yoochoose1/64数据集上也有所提升。这是因为稀疏自注意力可以在全局信息上进一步减小无关项的比重,进一步印证了稀疏自注意力方法在全局信息提取中的有效性。

(a) 稀疏自注意力对P@20的影响
2.5 对比模型比较
为更直观的评估该方法的整体性能,将SSA-GNN模型与以下5种具有代表性的基线算法进行综合比较。
(1) POP将训练集中频率最高的N个项目作为推荐。
(2) FPMC[4]结合了矩阵分解和一阶马尔可夫链,以捕获序列效果和用户偏好。
(3) GRU4Rec[5]是基于RNN的模型,使用门控循环单元(GRU)对用户序列进行建模。
(4) SR-GNN[6]将序列化问题转换成有向图结构,通过图神经网络获得项目嵌入,由注意力网络捕获短期兴趣。
(5) GC-SAN[7]分别用自注意力网络和图神经网络捕获全局和局部信息,最后在预测层将二者进行线性连接。
为使试验结果更加客观,本文模型与基线模型在相同的公开数据集上进行比较,并以P@20和MRR@20作为评价指标,试验结果如表2所示。
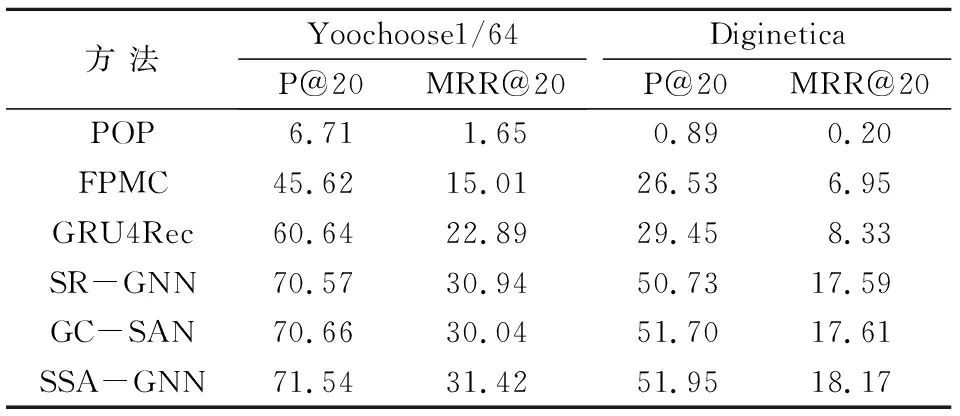
表2 试验结果对比
从表2的试验结果可以看出,传统方法在P@20和MRR@20评价指标上的整体效果不如深度神经网络。POP只推荐top-k个常见项目,主要强调高共现项目。FPMC利用一阶马尔可夫链和矩阵分解在上述评价指标下得到了比POP略好的结果。深度神经网络GRU4Rec能够更好的捕获项目间的复杂转换,以非线性的方式对用户和物品进行建模,还可以在模型训练过程中采用正则化、dropout等技术防止过拟合。
在上述基线方法中,基于GNN方法的模型在上述评价指标上的表现优于其他模型。SR-GNN将会话信息建模为图结构化数据,保留物品之间复杂的关系结构。GC-SAN的查询向量所使用的节点隐向量首先经过GNN网络,使得与目标项目相关的非邻节点的信息被弱化,无法准确捕获全局信息。
相较于上述评分指标最好的基线模型GC-SAN,SSA-GNN在Yoochoose1/64数据集上的P@20提高1.25%,MRR@20提高4.59%;在Diginetica数据集上的P@20指标提高0.48%,MRR@20提高3.18%。可以看出,SSA-GNN在推荐能力上均有所提升,在MRR@20上的提升效果更加明显。表明使用稀疏自注意力网络捕获全局信息,可以有效缓解无关项的干扰,并解决图神经网络在长距离信息表示中项目间依赖过于复杂的问题;在局部信息提取中加入目标注意模块,可以更深层次的捕获项目间的复杂依赖关系。试验结果进一步说明了SSA-GNN模型的有效性。
3 结语
本文提出了一种融合图神经网络和稀疏自注意力的会话推荐模型(SSA-GNN),模型采用2种不同的深度学习网络对序列信息进行建模,不仅通过稀疏自注意力忽略距离因素的特性对全局信息进行提取,还将可以建模项目之间复杂关系的图结构用在提取当前会话信息上。为进一步提升推荐能力,本文还将目标注意模块添加到图神经网络中。试验结果表明,本文提出的模型在评价指标P@20和MRR@20上的推荐效果明显高于上述基线方法。本文虽对物品的全局和局部信息进行充分提取,但未对物品中包含的细粒度信息如时间、分类等信息进行充分挖掘,后续可以将提取细粒度信息作为模型的补充,进一步研究物品内部细粒度信息对推荐结果的影响。
