基于改进BERT的电力领域中文分词方法
2024-01-09夏飞陈帅琦华珉蒋碧鸿
夏飞,陈帅琦,华珉,蒋碧鸿
基于改进BERT的电力领域中文分词方法
夏飞1,陈帅琦1,华珉2*,蒋碧鸿3
(1.上海电力大学 自动化工程学院,上海 200090; 2.国网上海电力公司 电力科学研究院,上海 200437; 3.上海电力大学 图书馆 上海 200090)(∗通信作者电子邮箱hmhzgb@163.com)
针对电力领域中文文本包含大量专有词时分词效果不佳的问题,提出一种基于改进BERT (Bidirectional Encoder Representation from Transformers)的电力领域中文分词(CWS)方法。首先,构建分别涵盖通用、领域词的词典,并设计双词典匹配融合机制将词特征直接融入BERT模型,使模型更有效地利用外部知识;其次,通过引入DEEPNORM方法提高模型对于特征的提取能力,并使用贝叶斯信息准则(BIC)确定模型的最佳深度,使BERT模型稳定加深至40层;最后,采用ProbSparse自注意力机制层替换BERT模型中的经典自注意力机制层,并利用粒子群优化(PSO)算法确定采样因子的最优值,在降低模型复杂度的同时确保模型性能不变。在人工标注的电力领域专利文本数据集上进行了分词性能测试。实验结果表明,所提方法在该数据集分词任务中的F1值达到了92.87%,相较于隐马尔可夫模型(HMM)、多标准分词模型METASEG(pre-training model with META learning for Chinese word SEGmentation)与词典增强型BERT(LEBERT)模型分别提高了14.70、9.89与3.60个百分点,验证了所提方法有效提高了电力领域中文文本的分词质量。
中文分词;领域分词;改进BERT;电力文本;深度学习;自然语言处理
0 引言
电力领域的文本数据这类非结构化数据包含大量运行经验,对它进行分析可以为电力运行提供支持[1]。电力领域中文文本分词是自然语言处理技术范畴内中文分词(Chinese Word Segmentation, CWS)任务的一个分支,它的目的是将整段的电力领域文本正确拆分成词的集合,为后续电力文本挖掘、知识图谱构建等基于词级语料的电力领域自然语言处理任务提供基础数据[2-3],因此,电力文本分词的质量直接影响后续任务的质量。
CWS任务一直面临分词标准选择、分词歧义和未登录词(Out-Of-Vocabulary, OOV)识别的问题[4]。CWS通常被视为序列标注任务。在近20年的发展中,CWS经历了隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场(Conditional Random Field, CRF)等基于统计的方法[5-6],以及长短期记忆(Long Short-Term Memory, LSTM)网络、BERT(Bidirectional Encoder Representation from Transformers)等基于深度神经网络模型的方法[7-8],准确率逐步提升。目前,分词标准选择与分词歧义的问题随着更多标准的提出与深度神经网络模型的大规模应用得到有效缓解,未登录词成为影响分词准确性的最重要的因素[4]。
未登录词指的是分词任务中遇到但模型训练语料中没有涉及的词。在对未登录词的研究中发现,56%~72%的未登录词为专有词[9];因此,采用面向通用场景的语料库设计的分词手段应用于特定领域时通常效果较差。为此,研究者们开始探索针对领域文本分词任务的方法。
针对领域文本的分词方法一般通过改进通用分词模型、结合领域词典、采用迁移学习等方式获得更好的领域分词性能。文献[10]中在双向长短期记忆(Bidirectional LSTM, Bi-LSTM)网络模型中添加了词典信息并取得了较好的效果,证明了在神经网络模型中添加词典对指导拆分领域专有词的有效性;文献[11]中在自适应HMM的基础上添加领域词典和互信息,构建了对石油领域文本的分词模型;文献[12]中设计了一种利用未标记和部分标记数据训练的Bi-LSTM网络分词模型,在跨领域CWS任务中取得了良好的效果;文献[13]中基于Bi-LSTM网络和迁移学习设计了领域自适应的分词方法;文献[14]中使用双向门控循环单元(Bidirectional Gated Recurrent Unit, Bi-GRU)代替多头注意力机制中的位置编码,设计了面向领域的分词模型;文献[15]中通过设计新词发现机制自动标注新领域语料,并用它训练门控卷积神经网络(Gated Convolutional Neural Network, GCNN)分词模型,在多个领域的测试中取得了较好的成绩。
目前,面向电力领域文本的自然语言处理技术研究中缺乏对电力领域中文文本分词任务的研究,现有研究大多使用基于规则或统计的方法实现分词。文献[16]中使用经过电力专业词典增强的HMM对电力设备缺陷记录进行分词以构建知识图谱;文献[17]中利用HMM与Viterbi算法辅以领域词典进行分词,再依据分词结果构建Bi-LSTM分类器,实现变压器故障文本句子分类;文献[18]中采用串频统计等方法实现分词,用于后续电力领域命名实体识别;文献[19]中设计了包含大量领域词汇的预设词库,通过正向逆向最大匹配的方法获取低粒度电力词汇。基于规则与统计的分词方法存在分词歧义、粒度混乱和对未登录词错误分词的问题,且对领域词典质量有较高要求,分词效果不理想,会对后续任务造成严重影响。在与分词任务同属序列标注任务的电力领域命名实体识别中,深度学习技术得到了广泛应用。文献[20]中使用经过电力领域语料预训练的电力BERT模型作为字嵌入的编码方式,之后通过Bi-LSTM网络与CRF输出序列标注;文献[21]中使用多个双向循环神经网络(Bidirectional Recurrent Neural Network, Bi-RNN)创建多个单一实体识别器,最后利用卷积神经网络(Convolutional Neural Network, CNN)分析结果,输出最终的电力实体信息。以上述文献为代表的电力领域命名实体识别工作虽然同为序列标注任务,但它们仅针对电力实体词汇的识别,应用在电力文本的整体分词任务时,效果较差,无法解决依赖词级语料的模型的语料问题;同时,BERT模型的特征提取能力与表示能力较强,但目前基于BERT的领域文本序列标注方法(包含分词与命名实体识别)大多仅作为动态字嵌入的获取方式,而将特征提取工作交予送入了字嵌入与词典等外部信息的后续模型(例如Bi-LSTM),这样的模型设计将外部知识表示与字嵌入获取过程隔离,没有充分利用外部知识以及BERT模型的特征提取能力与表示能力,提高了模型复杂度。
综上,目前面向电力领域的分词方法研究较少,分词手段性能落后,严重制约了模型性能。为了实现以高准确率切分电力领域文本词汇的目的,本文受词典增强型BERT (Lexicon Enhanced BERT, LEBERT)模型[22]的启发,以电力领域专利文本为实验对象进行了研究,提出了面向电力领域的CWS深度神经网络模型。
本文的主要工作内容如下:
1)构建了面向电力领域的领域词典,设计了包含领域词典与通用词典的双词典匹配融合机制,将外部知识信息直接集成到BERT内部,强化了语料特征并缓解了未登录词问题。
2)引入DEEPNORM方法[23],将BERT模型稳定加深至40层,避免了传统深层BERT模型面临的增量爆炸问题,提高了模型对特征的提取能力;结合贝叶斯信息准则(Bayesian Information Criterion, BIC)对模型性能、时间等因素综合评分,确定了模型最佳深度,防止模型过于复杂。
3)为进一步降低模型规模,采用ProbSparse自注意力机制[24]层替换了BERT模型中的经典自注意力机制层,降低了模型的时间与空间复杂度;利用粒子群优化(Particle Swarm Optimization,PSO)确定采样因子的最优值,在降低模型复杂度的同时确保了模型性能不变。
1 融合领域词典与通用词典的CWS模型

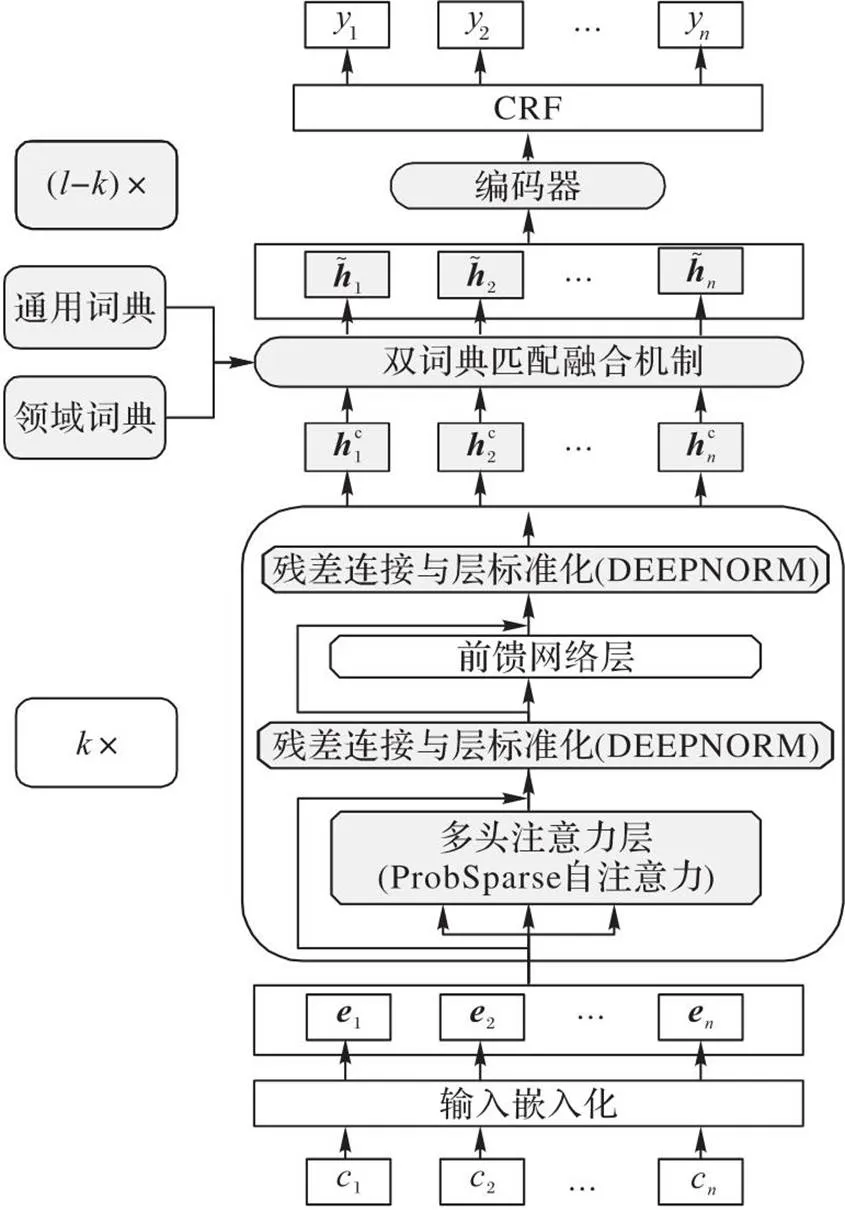
图1 融合领域词典与通用词典的CWS模型
1.1 双词典匹配融合机制
1.1.1词典建立与词特征提取
词典作为分词模型的重要组成部分,直接指导模型对于专有名词的拆分。本文的具体思路为通过通用、领域两个词典为模型添加外部知识,其中:通用词典有多个内容丰富的高质量开源词典,选择文献[25]中制作的词典与词嵌入,该词典具有完整的词汇文本部分与词嵌入部分,词语总数约为882万;对于领域词典,目前缺乏成熟统一的电力领域开源词典,需要构建,选择电力行业国标[26]、现有电力词汇书籍[27]等内容作为主体,用人工总结的最新电力热词作为填充构建电力领域词典,包含的词语总数约为15万,可以基本满足电力领域专有名词分词的需要。

1.1.2词特征的融入
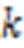
由于词嵌入的维度与模型字符特征的维度可能存在差异,为了使新加入的词嵌入能够与字符特征匹配,需要对词嵌入进行非线性变换,将它与字符特征统一维度:
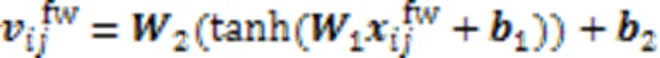
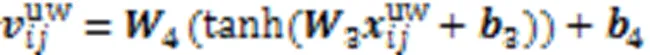
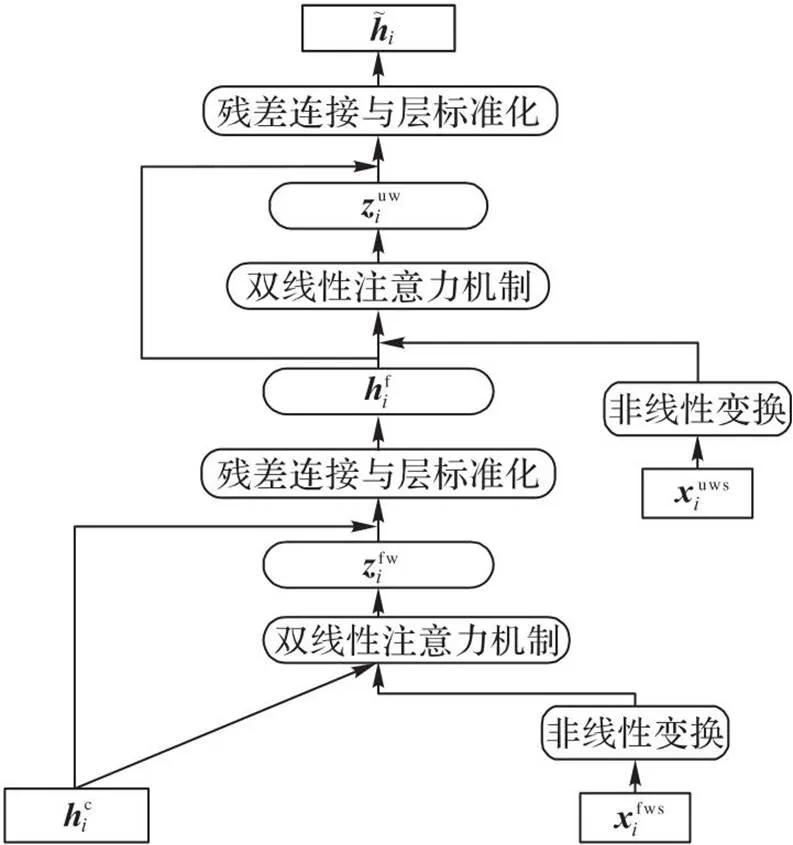
图3 双词典匹配融合机制的结构
由于同一个字符可能涉及多个匹配的词语,为防止引入歧义干扰,需要对结果进行选择。本文沿用双线性注意力机制实现词语挑选,基于字符特征获取各词嵌入的注意力得分,之后计算每个字符对应的领域词的加权和,即为领域词特征:
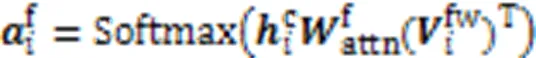
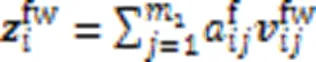
将获得的领域词特征与字符特征结合,并进行层标准化:
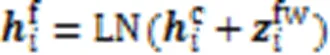
其中:LN代表LayerNorm,是用来进行层标准化的经典函数。
同理,使用添加了领域词特征的字符特征与通用词嵌入计算双线性注意力得分,构建通用词特征:
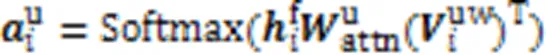
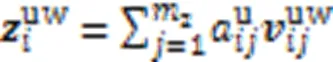
然后将获得的通用词特征与添加了领域词特征的字符特征融合,最后经过dropout与层标准化,完成词典信息的匹配添加。
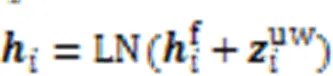
1.2 深层BERT
1.2.1DEEPNORM方法
双词典匹配融合机制将领域词典信息与通用词典信息融入BERT,给模型添加了更有效的外部知识,但也存在词特征被稀释的问题;另一方面,领域语料库的规模通常因为文本数量与标注成本问题而受到限制,因而需要提高模型对特征的提取能力。目前Transformer模型[28]正在向着大型化方向发展,对于基于Transformer的BERT模型,参数量意味着模型的宽度,而BERT编码器层数则代表模型的深度,更深的模型可以在较窄的情况下获得比宽而浅的模型更好的效果,因此,本文引入DEEPNORM方法[23]稳定地增加BERT模型的层数。DEEPNORM方法的公式为:
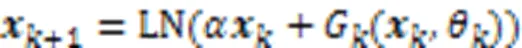



Tab.1 Values of and corresponding to SGD and Adam optimizers
注:代表BERT编码器的层数。
1.2.2基于BIC的BERT编码器层数确定方法
虽然BERT编码器的层数在一定范围内加深可以获得更好的效果,但超过该范围后模型的整体性能将下降。BIC是一种常用的判别准则,用于评价模型性能。本文采用经过改进的BIC对不同深度的模型进行评价,以确定模型中BERT编码器层数的最优值。最佳层数可以通过BIC评分结果得到。
本文所述BIC公式为:
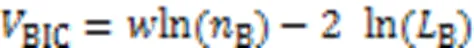
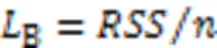
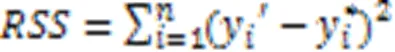
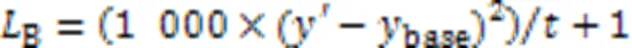
1.3 基于ProbSparse 自注意力机制的模型简化
1.3.1ProbSparse 自注意力机制
优化后的BERT模型提升了特征提取的能力,但也带来了时间复杂度与空间复杂度高的新问题。针对这一问题,本文引入ProbSparse自注意力机制[24]替换BERT编码器中原本的自注意力机制,在几乎不影响模型效果的前提下进一步减少参数量,提高训练速度。

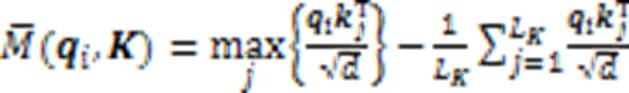
最终,ProbSparse自注意力机制的公式可以表示为:
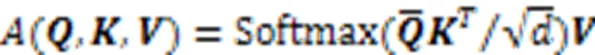
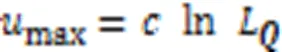
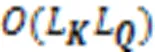
1.3.2基于PSO的采样因子确定方法
采样因子的选取对模型有直接影响:选取过大会削弱ProbSparse自注意力机制的模型简化效果;选取过小则会造成特征丢失,降低模型性能。针对这一问题,本文建立了最优化目标函数,利用PSO算法确定采样因子的最佳取值。
PSO算法粒子速度、位置的更新公式为:
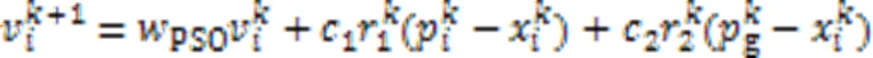
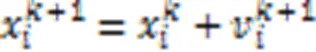
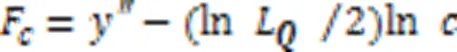
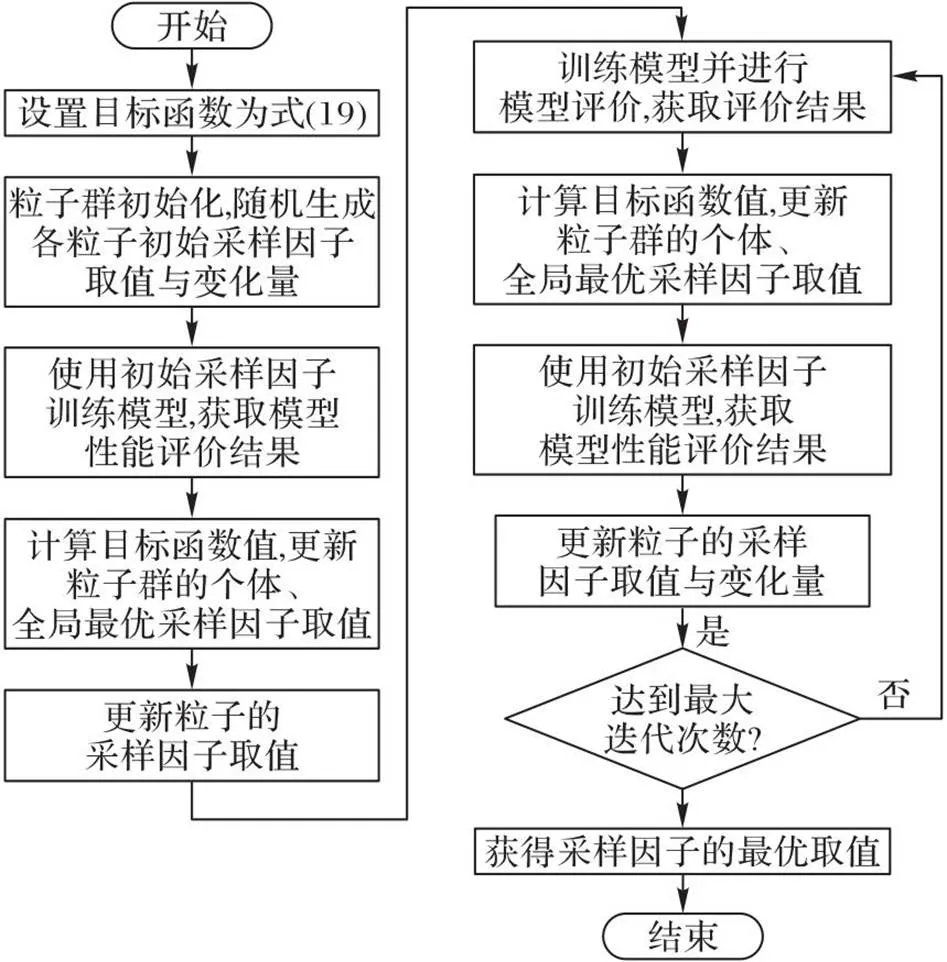
图4 PSO算法优化采样因子的流程
2 实验与结果分析
为了验证本文模型的效果,搭建了基于Python的实验环境,开展了大量实验。计算机操作系统为Windows 10,CPU为AMD Ryzen5 3600,内存32 GB,GPU为NVIDIA GEFORCE RTX 3090,显存容量24 GB。
在讨论模型的最优参数选择时,由于采样因子相较于BERT编码器层数对模型性能的影响更大,因此在设置模型超参数之后,先确定采样因子的最优值,再讨论BERT编码器层数的优选值。
2.1 语料构成与评价标准
为充分体现模型性能,选取电力专业词汇密集且涵盖广泛的电力领域专利文本进行人工标注制作语料库。由于领域文本仅能靠人工标注获取,规模较小,且具有一定程度上的局限性,因此将领域语料库与Bakeoff提供的微软亚洲研究院(MicroSoft Research Asia, MSRA)语料库、北京大学(PeKing University, PKU)语料库等标准语料库[29]的部分内容进行组合,使领域语料库与标准语料库的文本比例为1∶2。用于训练的语料库具体构成情况如表2所示。取领域语料库的10%用于后续测试。
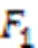
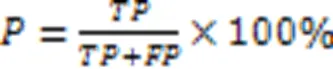
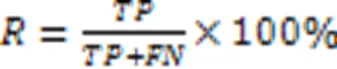
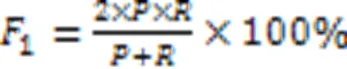
在分词规范方面,本文参照文献[30],对于规范未涉及的专业领域词汇,采用国标等文件中提供的标准作为分词规范。
表2训练语料库构成情况

Tab.2 Composition of training corpus
2.2 模型构建与超参数设置
本文模型基于BERT模型构建,其中,BERT模型的初始化采用huggingface[31]提供的中文BERT模型参数。通用词典采用文献[25]中制作的中文词典,领域词典使用Word2Vec方法训练词嵌入。经过测试,在可以取得最佳效果的BERT第1、2层编码器之间插入双词典匹配融合机制。采用{B,M,E,S}四词位进行序列标注,使用AdamW(Adam Weight decay)优化器和最小化负对数似然损失函数对神经网络进行训练。损失函数公式为:
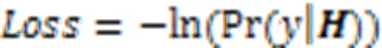
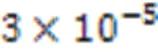
2.3 采样因子的确定实验
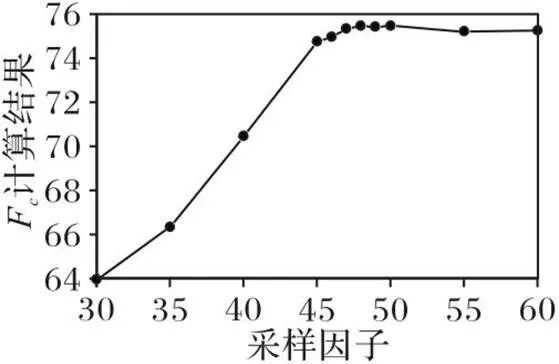
图5 不同采样因子的计算结果
2.4 BERT编码器层数的确定实验

表3模型性能与耗时的测试结果
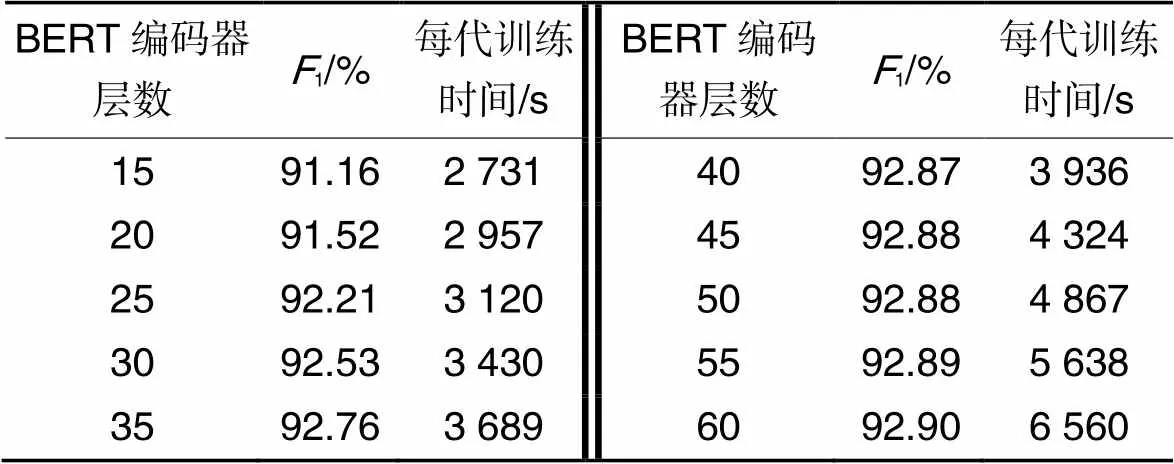
Tab.3 Test results of model performance and time consumption
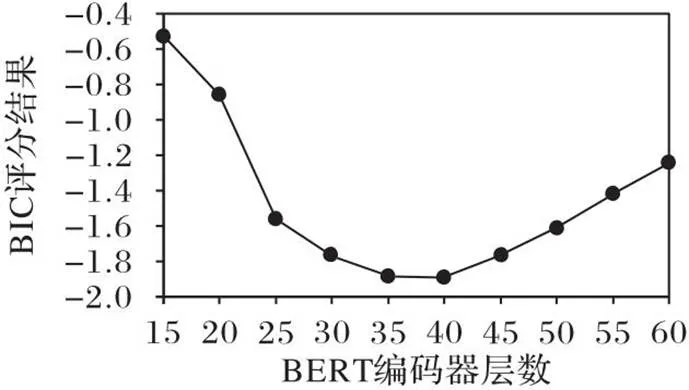
图6 不同BERT编码器层数的BIC评分结果
由表3、图6中的数据可知,当BERT编码器层数多于30时,模型1值的增长趋于平缓,在层数为35和40时,BIC评分结果达到最小。根据BIC的“吝啬原理”,结果最小的模型为最佳模型。当BERT编码器层数为40时,模型不仅取得了最佳的BIC评分结果,还具有更大的1值,因此本文最终选择BERT编码器层数为40。
2.5 分词结果及分析
在确定了模型的各项参数之后,对模型在电力领域专利文本语料上的分词性能进行了测试。由于近年来鲜有针对电力领域的CWS模型研究,为了验证本文模型的效果,选取了多个具有代表性的模型进行分词结果比较,这些模型包括:多标准分词模型METASEG(pre-training model with META learning for Chinese word SEGmentation)[33],电力领域自然语言处理研究常用分词模型HMM(添加电力领域词典辅助分词)[32],以解决分词问题为主的序列标注模型ZEN(a BERT-based Chinese(Z) text encoder Enhanced by N-gram representations)[34]和LEBERT[22]。评测结果如表4所示。
表4不同模型的分词评测结果 单位:%
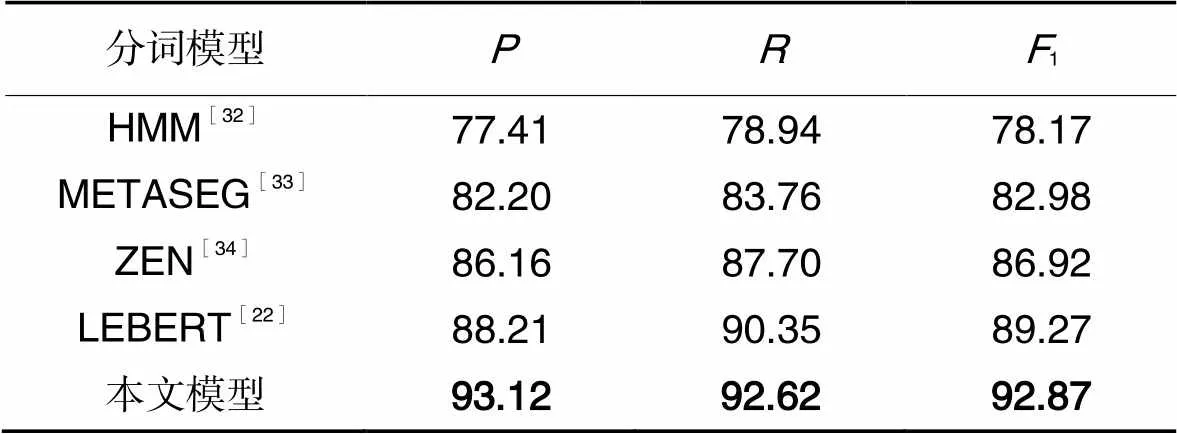
Tab.4 Test results of word segmentation by different models unit:%
通过对比可以发现,在针对电力领域具有代表性的专利文本语料分词任务中,本文模型与次优的LEBERT相比,1值提高了3.60个百分点,相较于HMM、METASEG也分别提高了14.70和9.89个百分点。这验证了本文模型在电力领域文本分词上的优势。
为了对比分词效果,在表5中列出了各模型对几个例句进行分词的结果比较。由表5可知,本文模型对于登录词的切分更准确,对于未登录词,本文依赖更深的BERT神经网络能够更好地将它们切分。例如对于短语“输电线路”“电磁屏蔽”“能源交互”,其他模型更倾向于将它们切分为更细的粒度。同样的,对于未登录词例如“纤维素基”“能量云”“风雨水能”等,其他模型更倾向于将它们切分成“纤维素/基”“能量/云”“风雨/水能”,本文模型则倾向于将它们作为一个整词进行切分。此类切分差异会对后续任务例如聚类、构建知识图谱等产生重要影响。
表5不同模型分词结果示例
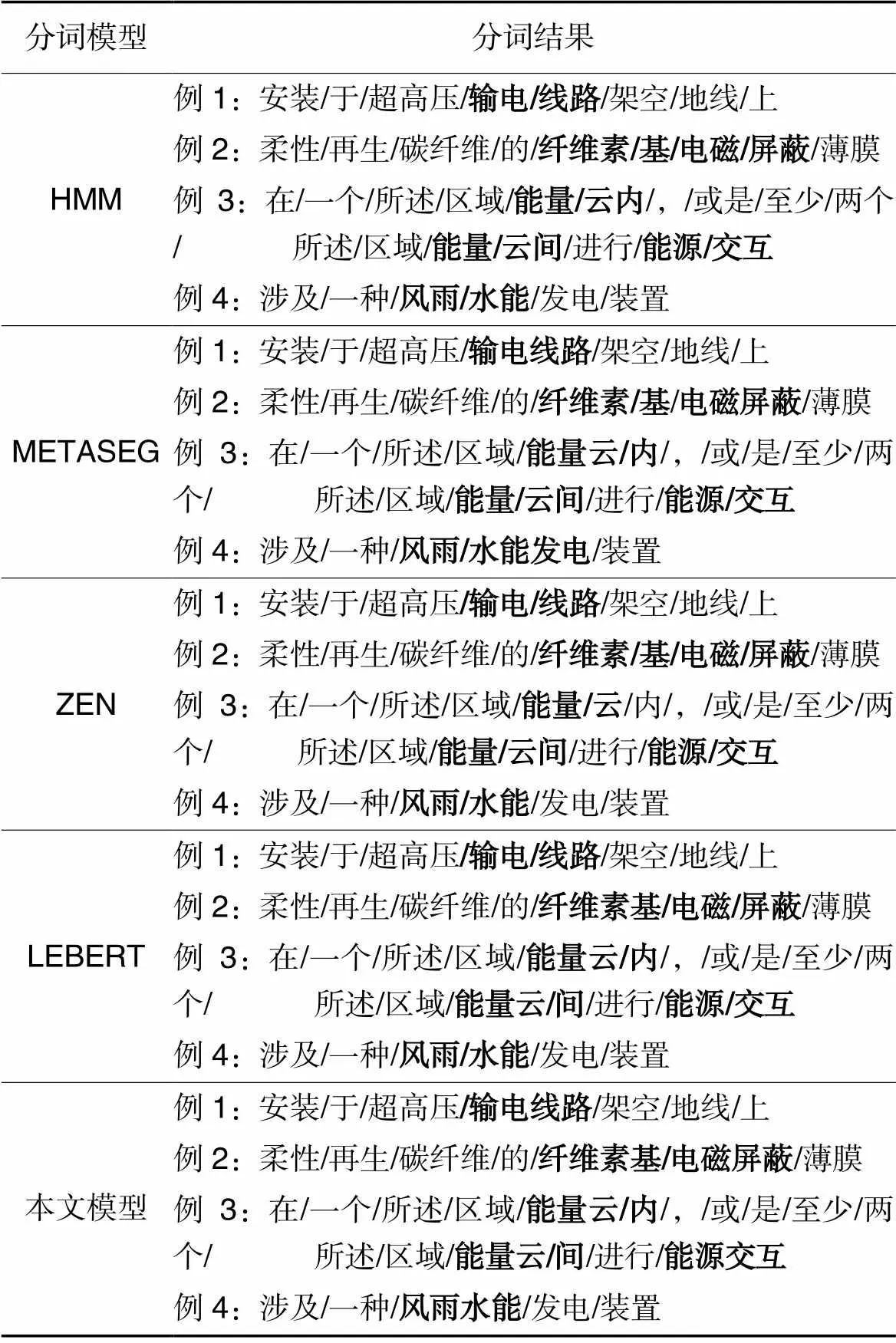
Tab.5 Examples of word segmentation results by different models
注:加粗字为不同模型的具体分词差异示例。
除了分词准确性,还对ProbSparse自注意力机制(此处用PSAttn表示)加入前后模型(非PSAttn模型和PSAttn模型)的训练速度和显存占用进行了测试,以评测模型在降低算法复杂度方面的作用。测试时,设置显存上限为16 GB,batch_size从1开始增加至显存允许的最高值。为衡量不同batch_size下的模型精度,同时测试了不同batch_size下模型的1值,具体结果如表6所示。从结果看,ProbSparse自注意力机制的引入使得模型训练时间与显存占用大幅减少,降低了对硬件的要求;同时,通过对比采用ProbSparse自注意力机制模型(PSAttn模型)与未采用模型(非PSAttn模型)的1值可以发现,ProbSparse自注意力机制的引入并未对模型性能造成影响。由此可知,在保证分词准确性以外,本文模型由于引入了ProbSparse自注意力机制,可以降低模型的时间复杂度和空间复杂度。时间复杂度的降低直接缩减了模型训练所需时间;空间复杂度的降低允许模型以更大的batch_size或者在显存容量更低的硬件条件下进行训练。
表6训练速度及显存占用的测试结果
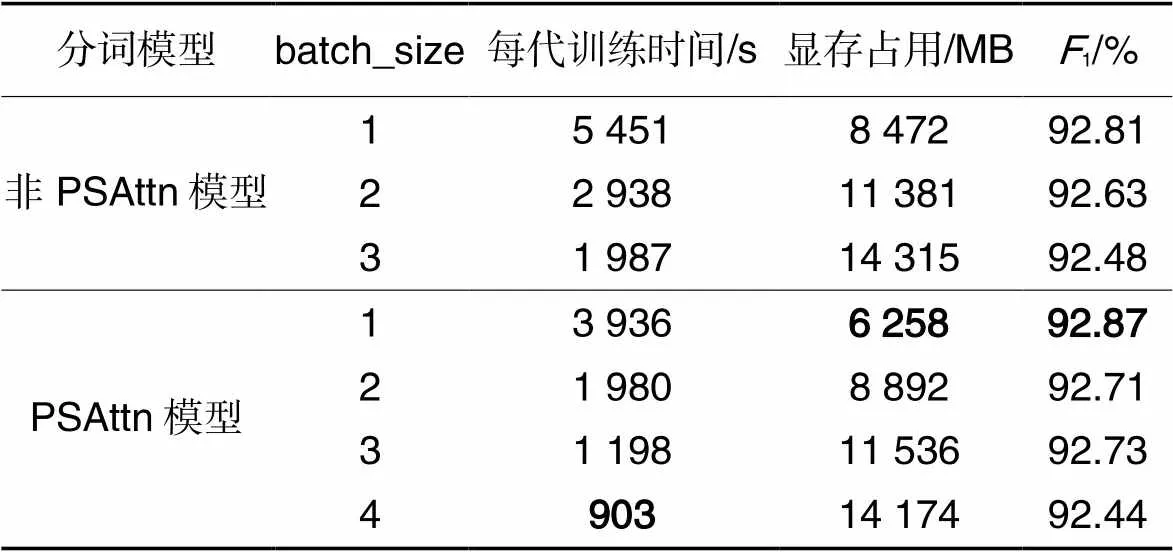
Tab.6 Test results of training speed and memory consumption
综上所述,在电力领域文本的分词任务中,本文提出的模型具有更好的性能,可以更准确地切分词语。
3 结语
本文针对电力领域分词任务进行了研究,并对目前存在的不足进行了改进。具体地,首先构建了面向电力领域的领域词典,并设计了用于更好地向BERT注入词典信息的双词典匹配融合机制;其次引入了DEEPNORM方法稳定增加BERT模型深度,提高了模型的特征提取能力,并使用BIC确定了BERT编码器的最佳层数,防止模型过于复杂;最后采用ProbSparse自注意力机制降低了深度BERT模型的时间与空间复杂度,并利用PSO算法确定了最优采样因子,确保了在降低复杂度的同时不改变模型性能。本文将标准语料与人工标注的电力领域专利文本相融合,制作了语料库,并以此为依托设计了对比实验,1值达到了92.87%,体现出了本文模型对电力领域中文文本内的词汇尤其是专业词汇的拆分效果,在电力文本信息挖掘、知识图谱构建等电力领域自然语言处理任务中具有良好的应用前景。
在测试中,具有更深BERT编码器层数的模型展现出了获得更好效果的趋势,但为了降低模型复杂度,本文未将DEEPNORM方法的潜力充分发挥。因此,如何在控制模型体积的前提下进一步加深模型将是我们未来的研究方向。
[1] 李刚,李银强,王洪涛,等.电力设备健康管理知识图谱:基本概念、关键技术及研究进展[J].电力系统自动化,2022,46(3):1-13.(LI G, LI Y Q, WANG H T, et al. Knowledge graph of power equipment health management: basic concepts, key technologies and research progress [J]. Automation of Electric Power Systems, 2022, 46(3): 1-13.)
[2] 冯斌,张又文,唐昕,等.基于BiLSTM-Attention神经网络的电力设备缺陷文本挖掘[J].中国电机工程学报,2020,40(S1):1-10.(FENG B, ZHANG Y W, TANG X, et al. Power equipment defect record text mining based on BiLSTM-attention neural network [J]. Proceedings of the CSEE, 2020, 40(S1): 1-10.)
[3] 许尧,马欢,许旵鹏,等.智能变电站继电保护智能运维系统自动配置技术研究[J].电力系统保护与控制,2022,50(11):160-168.(XU Y, MA H, XU C P, et al. Self-configuration technology of an intelligent operation and maintenance system of intelligent substation relay protection [J]. Power System Protection and Control, 2022, 50(11): 160-168.)
[4] 唐琳,郭崇慧,陈静锋.中文分词技术研究综述[J].数据分析与知识发现,2020,4(Z1):1-17.(TANG L, GUO C H, CHEN J F. Review of Chinese word segmentation studies [J]. Data Analysis and Knowledge Discovery, 2020, 4(Z1): 1-17.)
[5] 钱智勇,周建忠,童国平,等.基于HMM的楚辞自动分词标注研究[J].图书情报工作,2014, 58(4): 105-110.(QIAN Z Y, ZHOU J Z, TONG G P, et al. Research on automatic word segmentation and pos tagging forbased on HMM [J]. Library and Information Service, 2014, 58(4): 105-110.)
[6] 朱艳辉,刘璟,徐叶强,等.基于条件随机场的中文领域分词研究[J].计算机工程与应用,2016,52(15):97-100.(ZHU Y H, LIU J, XU Y Q, et al. Chinese word segmentation research based on conditional random field [J]. Computer Engineering and Applications, 2016, 52(15): 97-100.)
[7] CHEN X, QIU X, ZHU C, et al. Long short-term memory neural networks for Chinese word segmentation [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1197-1206.
[8] DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186.
[9] SHEIKH I, ILLINA I, FOHR D, et al. OOV proper name retrieval using topic and lexical context models [C]// Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2015: 5291-5295.
[10] ZHANG Q, LIU X, FU J. Neural networks incorporating dictionaries for Chinese word segmentation [C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 5682-5689.
[11] 宫法明,朱朋海.基于自适应隐马尔可夫模型的石油领域文档分词[J].计算机科学,2018,45(6A):97-100.(GONG F M, ZHU P H. Word segmentation based on adaptive hidden Markov model in oilfield [J]. Computer Science, 2018, 45(6A): 97-100.)
[12] ZHAO L J, ZHANG Q, WANG P, et al. Neural networks incorporating unlabeled and partially-labeled data for cross-domain Chinese word segmentation [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 4602-4608.
[13] 成于思,施云涛.基于深度学习和迁移学习的领域自适应中文分词[J].中文信息学报,2019,33(9):9-16,23.(CHENG Y S, SHI Y T. Domain adaption of Chinese word segmentation based on deep learning and transfer learning [J]. Journal of Chinese Information Processing, 2019, 33(9): 9-16,23.)
[14] 崔志远,赵尔平,雒伟群,等.面向专业领域的多头注意力中文分词模型——以西藏畜牧业为例[J].中文信息学报,2021,35(7):72-80.(CUI Z Y, ZHAO E P, LUO W Q, et al. Multi-head attention for domain specific Chinese word segmentation model — a case study on Tibet’s animal husbandry [J]. Journal of Chinese Information Processing, 2021, 35(7): 72-80.)
[15] 张军,赖志鹏,李学,等.基于新词发现的跨领域中文分词方法[J].电子与信息学报,2022,44(9):3241-3248.(ZHANG J, LAI Z P, LI X, et al. Cross-domain Chinese word segmentation based on new word discovery [J]. Journal of Electronics & Information Technology, 2022, 44(9): 3241-3248.)
[16] 刘梓权,王慧芳.基于知识图谱技术的电力设备缺陷记录检索方法[J].电力系统自动化,2018,42(14):158-164.(LIU Z Q, WANG H F. Retrieval method for defect records of power equipment based on knowledge graph technology [J]. Automation of Electric Power Systems, 2018, 42(14): 158-164.)
[17] 杜修明,秦佳峰,郭诗瑶,等.电力设备典型故障案例的文本挖掘[J].高电压技术,2018,44(4):1078-1084.(DU X M,QIN J F, GUO S Y, et al. Text mining of typical defects in power equipment [J]. High Voltage Engineering, 2018, 44(4): 1078-1084.)
[18] 刘荫,张凯,王惠剑,等.面向电力低资源领域的无监督命名实体识别方法[J].中文信息学报,2022,36(6):69-79.(LIU Y, ZHANG K, WANG H J, et al. Unsupervised low-resource name entities recognition in electric power domain [J]. Journal of Chinese Information Processing, 2022, 36(6): 69-79.)
[19] 刘文松,胡竹青,张锦辉,等.基于文本特征增强的电力命名实体识别[J].电力系统自动化,2022,46(21):134-142.(LIU W S, HU Z Q, ZHANG J H, et al. Named entity recognition for electric power industry based on enhanced text features [J]. Automation of Electric Power Systems, 2022, 46(21): 134-142.)
[20] 蒋晨,王渊,胡俊华,等.基于深度学习的电力实体信息识别方法[J].电网技术,2021,45(6):2141-2149.(JIANG C, WANG Y, HU J H, et al. Power entity information recognition based on deep learning [J]. Power System Technology, 2021, 45(6): 2141-2149.)
[21] 田嘉鹏,宋辉,陈立帆,等.面向知识图谱构建的设备故障文本实体识别方法[J].电网技术,2022,46(10):3913-3922.(TIAN J P, SONG H, CHEN L F, et al. Entity recognition approach of equipment failure text for knowledge graph construction [J]. Power System Technology, 2022, 46(10): 3913-3922.)
[22] LIU W, FU X, ZHANG Y, et al. Lexicon enhanced Chinese sequence labeling using BERT adapter [C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: Association for Computational Linguistics, 2021: 5847-5858.
[23] WANG H, MA S, DONG L, et al. DeepNet: scaling Transformers to 1,000 layers [EB/OL]. (2022-03-01)[2022-03-23]. https://arxiv.org/pdf/2203.00555.pdf.
[24] ZHOU H, ZHANG S, PENG J, et al. Informer: beyond efficient Transformer for long sequence time-series forecasting [C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 11106-11115.
[25] SONG Y, SHI S, LI J, et al. Directional skip-gram: explicitly distinguishing left and right context for word embeddings [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2018: 175-180.
[26] 国家发展和改革委员会. 电力行业词汇:DL/T 1033—2006 [S].北京:中国电力出版社,2007:1-20.(National Development and Reform Commission. Electric power standard thesaurus: DL/T 1033—2006[S]. Beijing: China Electric Power Press, 2007:1-20.)
[27] 杨善让,赵晓彤,杨绍胤.英汉电力技术词典[M].2版.北京:中国电力出版社,2014:1-1469.(YANG S R, ZHAO X T, YANG S Y. An English-Chinese Dictionary of Electric Power Technology [M]. 2nd edtion. Beijing: China Electric Power Press, 2014: 1-1469.)
[28] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010.
[29] EMERSON T. The second international Chinese word segmentation bakeoff[C]// Proceedings of the 4th SIGHAN Workshop on Chinese Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2005:123-133.
[30] 俞士汶,段慧明,朱学锋,等.北京大学现代汉语语料库基本加工规范[J].中文信息学报,2002,16(5):49-64.(YU S W, DUAN H M, ZHU X F, et al. The basic processing of contemporary Chinese corpus at Peking University SPECIFICATION [J]. Journal of Chinese Information Processing, 2002, 16(5): 49-64.)
[31] HUGGINGFACE. Transformers [CP/OL]. [2021-12-11]. https://github.com/huggingface/transformers.
[32] 蒋卫丽,陈振华,邵党国,等.基于领域词典的动态规划分词算法[J].南京理工大学学报,2019,43(1):63-71.(JIANG W L, CHEN Z H, SHAO D G, et al. Dynamic programming word segmentation algorithm based on domain dictionaries [J]. Journal of Nanjing University of Science and Technology, 2019, 43(1): 63-71.)
[33] KE Z, SHI L, SUN S T, et al. Pre-training with meta learning for Chinese word segmentation [C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2021: 5514-5523.
[34] DIAO S, BAI J, SONG Y, et al. ZEN: pre-training Chinese text encoder enhanced by n-gram representations [C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 4729-4740.
Chinese word segmentation method in electric power domain based on improved BERT
XIA Fei1, CHEN Shuaiqi1, HUA Min2*, JIANG Bihong3
(1,,200090,;2,,200437,;3,,200090,)
To solve the problem of poor performance in segmenting a large number of proprietary words in Chinese text in electric power domain, an improved Chinese Word Segmentation (CWS) method in electric power domain based on improved BERT (Bidirectional Encoder Representations from Transformer) was proposed. Firstly, two lexicons were built covering general words and domain words respectively, and a dual-lexicon matching and integration mechanism was designed to directly integrate the word features into BERT model, enabling more effective utilization of external knowledge by the model. Then, DEEPNORM method was introduced to improve the model’s ability to extract features, and the optimal depth of the model was determined by Bayesian Information Criterion (BIC), which made BERT model stable up to 40 layers. Finally, the classical self-attention layer in BERT model was replaced by the ProbSparse self-attention layer, and the best value of sampling factor was determined by using Particle Swarm Optimization (PSO) algorithm to reduce the model complexity while ensuring the model performance. The test of word segmentation was carried out on a hand-labeled patent text dataset in electric power domain. Experimental results show that the proposed method achieves the F1 score of 92.87%, which is 14.70, 9.89 and 3.60 percentage points higher than those of the methods to be compared such as Hidden Markov Model (HMM), multi-standard word segmentation model METASEG(pre-training model with META learning for Chinese word SEGmentation)and Lexicon Enhanced BERT (LEBERT) model, verifying that the proposed method effectively improves the quality of Chinese text word segmentation in electric power domain.
Chinese Word Segmentation (CWS); domain word segmentation; improved BERT (Bidirectional Encoder Representations from Transformer); electric power text; deep learning; natural language processing
This work is partially supported by State Grid Science and Technology Project (52094020001A).
XIA Fei, born in 1978, Ph. D., associate professor. His research interests include power data analysis, power image processing.
CHEN Shuaiqi, born in 1997, M. S. candidate. His research interests include natural language processing.
HUA Min, born in 1987, M. S., engineer. His research interests include scientific and technological information, data management and applications, digital transformation of energy.
JIANG Bihong, born in 1981, M. S., librarian. His research interests include natural language processing, machine learning.
TP391.1
A
1001-9081(2023)12-3711-08
10.11772/j.issn.1001-9081.2022121897
2022⁃12⁃26;
2023⁃02⁃26;
2023⁃03⁃02。
国家电网科技项目(52094020001A)。
夏飞(1978—),男,江西南昌人,副教授,博士,CCF高级会员,主要研究方向:电力数据分析、电力图像处理;陈帅琦(1997—),男,山东泰安人,硕士研究生,主要研究方向:自然语言处理;华珉(1987—),男,上海人,工程师,硕士,主要研究方向:科技情报、数据管理与应用、能源数字化转型;蒋碧鸿(1981—),男,广西博白人,馆员,硕士,主要研究方向:自然语言处理、机器学习。
