基于双模编码器-解码器框架的联机手写数学公式识别
2024-01-08付鹏斌李树军杨惠荣
付鹏斌, 李树军, 杨惠荣
(北京工业大学信息学部, 北京 100124)
手写数学公式识别作为手写识别领域的一个重要分支,有很多应用场景,可分为联机和脱机2种识别模式。其中,联机模式是将数学公式以一维坐标点序列的形式作为输入,而脱机模式是将数学公式以二维静态图像的形式作为输入。目前,联机手写数学公式的识别主要分为传统识别方法和基于深度学习的识别方法。传统识别方法旨在基于文法规则将识别过程划分为字符分割、字符识别和结构分析3个阶段[1]。商俊蓓[2]采用隐性分割的方法,将时间点作为切分的依据,避免字符粘连导致的切分错误。克昊哲[3]通过构建全局解析树,实现数学公式的动态结构分析,可以根据结构分析阶段的错误对前2个阶段动态调整。郑恩东[4]通过构建笔画结构图的方式,克服一维序列对数学公式二维结构表达的限制。然而,这一类识别方法过度依赖人工预定义规则,对公式的复杂程度有较高的要求。Deng等[5]将深度学习引入该领域,实现了端到端的识别,并且证实基于编码器-解码器框架的神经网络模型在很大程度上优于传统的识别方法。Zhang等[6]设计了基于门控循环神经网络的编码器-解码器模型,引入注意力机制帮助模型在每次解码前聚焦于特征信息的有效解码区域,随后又设计了TAP(track,attend and parse)模型[7]和WAP(watch,attend and parse)模型[8],前者将注意力引导机制作为正则化项以提高注意力机制的精确性,后者采用卷积神经网络和注意力机制实现对数学公式图像的识别。Zhang等[9]设计了多尺度编码器,在一定程度上克服了字符尺寸相差较大而造成的信息丢失问题。这类方法或模型均是在单模下实现的,只能接受同一种形式的数据,即坐标点序列形式或图像形式,均无法充分利用输入数据的特征。因此,Wang等[10]设计了基于注意力机制的多模识别模型,这里的多模是指双模,即将联机识别模型和脱机识别模型结合。然而,因为没有对单模下的识别做任何改进,所以单模模型的缺点会保留至双模模型中。Wang等[11]设计了笔画约束注意力网络(stroke constrained attention network,SCAN)模型,将联机模式与脱机模式下的特征信息融合,但是其形状和信息密度不同,导致无法充分利用融合后的特征信息。
针对以上问题,本文设计了一种基于编码器-解码器框架的双模识别模型(dual online-offline model,DOOM)。该模型可同时接受坐标点序列和图像形式的输入数据,充分保留原数据的特征。除此之外,还提出了正弦编码,实现了联机模式下输入的数据增强,并设计了平滑注意力机制,实现了脱机模式下手写字符与相关特征信息的有效对齐。经实验验证,该模型可有效提升数学公式识别的准确率。
1 正弦编码
为了从输入序列中提取子序列的标志信息,本文提出了正弦编码,其可应用于输入为序列数据的场景。序列化的数据在深度学习领域较为常见,一个序列往往由若干长度不等的子序列组成,如一段文本包含多个长短不一的句子,此时该序列的完整信息是由多个片段化的子序列信息组成的。然而,当一个序列包含一个较短的子序列时,极有可能在数据处理过程中造成该子序列数据信息的丢失,严重影响数据信息的完整度,因此,如何防止序列中各个子序列信息的丢失至关重要。
为了解决上述问题,本文提出了正弦编码,对所有子序列中的每个元素通过正弦函数计算一个正弦标志,因此,每个子序列都有一个正弦标志序列,用来补充该子序列的数据信息。假设序列由各子序列组成,即


(1)
然后以同样的方式计算序列Q中所有元素的正弦标志,得到正弦标志序列
最终,编码后序列Z的公式为
Z=WQQ+WSS
(2)
式中:WQ为Q的权重;WS为S的权重。
从以上计算过程可以看出,正弦编码是从输入序列中提取每个子序列的正弦标志序列,并且将正弦标志序列同样作为模型的输入,因此,可在一定程度上保留子序列信息。
2 平滑注意力机制
为了对不同大小的目标区域进行更加精确的筛选,本文提出一种平滑注意力机制。注意力机制是一种类似人类视觉神经的算法,可通过自动学习权重的方式得到输入数据中的有效区域,常应用于基于编码器-解码器框架的模型。假设输入数据为特征图G,即
式中每个像素特征gkl∈RD,1≤k≤h,1≤l≤w,D为特征维度。在每次解码前,模型对特征图中的每个像素特征自动分配权重,权重越大,则表明其包含的有效信息越多,从而筛选出有效解码信息。这里,以在解码时刻计算像素特征gkl的权重为例,计算公式为
(3)
(4)
(5)
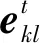
然而,以上这种计算方式经常会造成过解码和欠解码的问题,即每次筛选到的有效特征信息过多或不足。为了避免这种问题,Zhang等[7]提出了覆盖注意力机制,将之前所有解码时刻的注意力值的和F也作为计算当前时刻注意力因子的条件,即
(6)
则式(3)可改为
(7)

然而,当原输入图像中的有效信息区域的范围相差较大时,在固定大小的感受野下,覆盖注意力机制同样很难比较精确地筛选出有效的特征信息。例如,当输入为手写数学公式图像时,图像中不同手写符号的尺寸相差较大,注意力机制在捕捉尺寸较小的符号时,往往会得到一些无用的特征信息,而捕捉尺寸较大的手写符号时,却不能获取该符号的全部特征信息。为了改善这个问题,本文基于覆盖注意力机制提出了平滑注意力机制,通过引入平滑窗口,将窗口中所有像素特征的注意力因子作为计算当前像素特征权重的条件。这里,同样以在解码时刻t计算gkl的权重为例对平滑注意力机制的计算方式进行详细介绍。
(8)
(9)
式中:σ表示Sigmoid激活函数;T表示最大平滑范围;「⎤表示向上取整操作;Weh∈RD×1,Wew∈RD×1,同样为自动更新的模型参数。
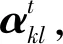
(10)
按照同样的方式对G中所有的像素特征权重化可得到Gt,公式为
(11)
3 模型设计
DOOM是通过编码器-解码器框架和注意力机制实现的。该模型主要包括联机编码器、脱机编码器和解码器3个部分,其中解码器又包含了覆盖注意力机制和平滑注意力机制,如图1所示。每次模型接收的坐标点序列和二维图像均来自同一手写数学公式。
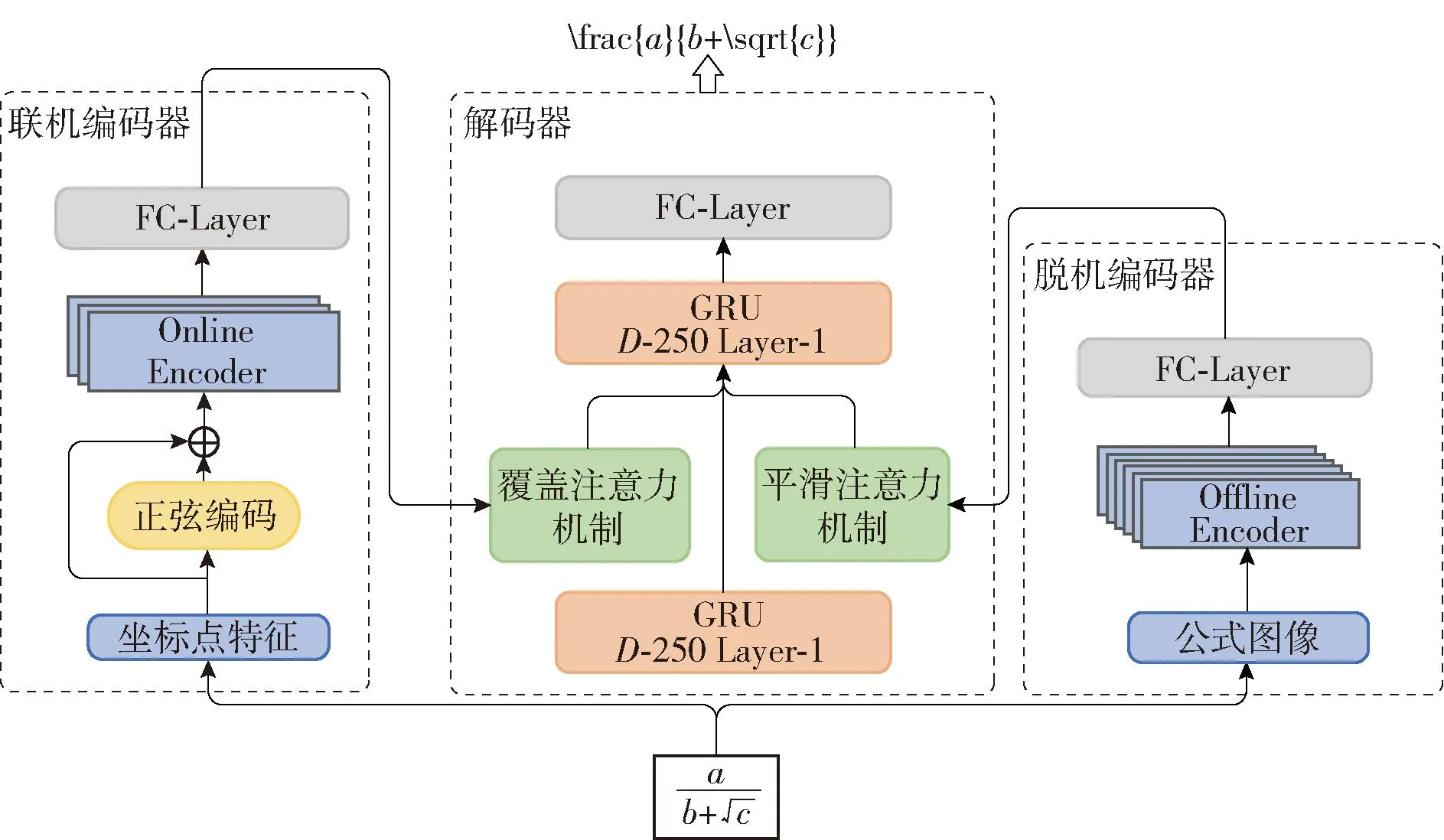
图1 DOOM结构
3.1 联机编码器
在联机模式下,每个手写数学公式的输入是一个坐标点序列,其包含了很多长度不等的子坐标点序列,每个子坐标点序列对应该数学公式的一个笔画的数据,这刚好符合正弦编码的应用场景。当手写数学公式包含较多笔画时,为了避免在识别过程中丢失较短笔画的信息,同时补充笔画之间的间隔信息,本文采用正弦编码对输入的坐标点序列进行编码。
假设联机模型的输入坐标点序列为P,其正弦标志序列为S。根据手写数学公式的特点,将编码后的序列Xon作为联机模式下的输入,其计算公式为
Xon=tanh(Win(WPP+WSS))
(12)
式中:tanh为激活函数;WP∈REin×E,WS∈R1×E,Win∈RE×E,皆为可训练的模型参数,其中,Ein表示每个坐标点的维度,E表示编码维度。以图2所示的手写数学公式“yt+1”为例,其包含了7个笔画,每个笔画的坐标点数量不同,均在公式右侧标明。从图中可看出,正弦编码可使每个笔画内的正弦标志序列按正弦规律变化,并且可以用热力图的方式可视化该公式正弦标志序列的变化规律,其中每个高亮区域对应一个笔画。每个笔画的正弦标志序列中的最小值为0,最大值为1,分别对应笔画的间隔位置和中心位置。笔画越短,则正弦标志变化越快;笔画越长,则正弦值变化越慢。因此,不仅能够根据该变化规律预测笔画的长度,而且能够在一定程度上补充笔画之间的间隔信息。
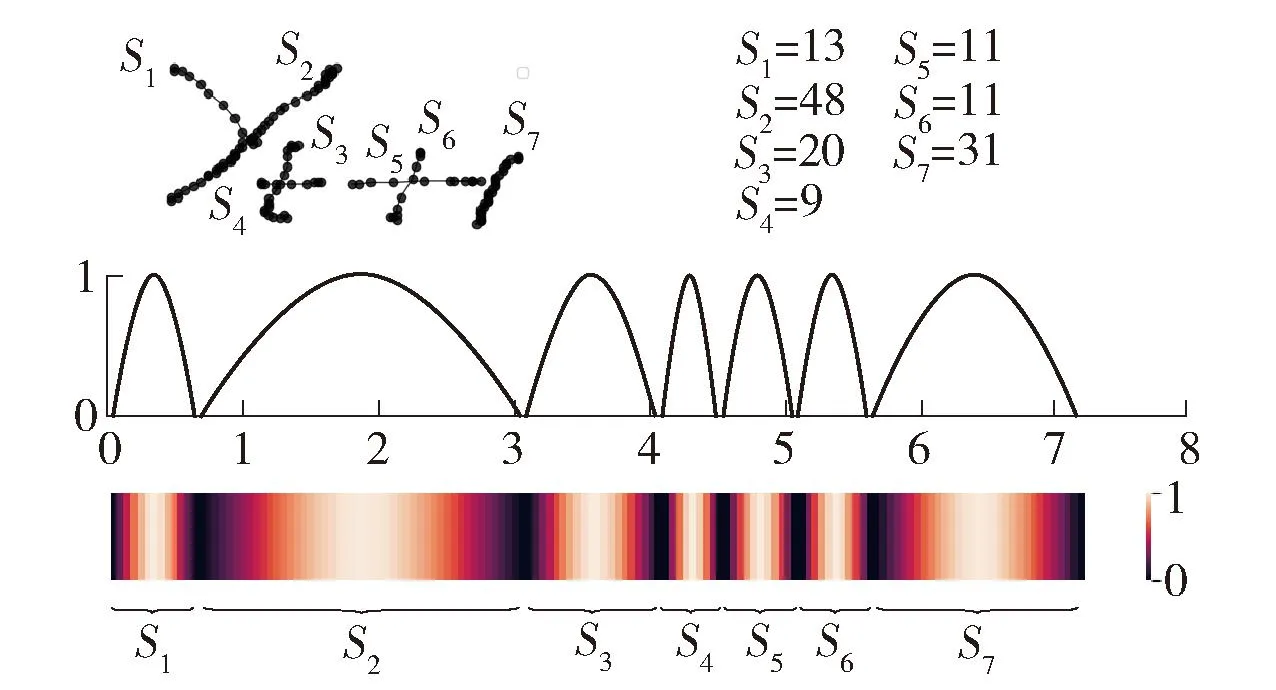
图2 正弦编码示例
联机编码模型由卷积神经网络(convolutional neural network,CNN)和门控循环单元(gate recurrent unit,GRU)神经网络两部分构成。其中CNN部分用于提取局部特征信息,如手写笔迹的拐点信息等,根据DenseNet-20[12]实现。该模型主要由5个DenseBlock构成,每个DenseBlock包含了3层网络,每层网络又包含了2层卷积层,增长因子K为24,如图3所示。DenseBlock之间的卷积层起到连接和压缩通道数的作用,压缩因子为0.5。在第3个和第5个DenseBlock后分别设置了一层平均池化层,最终可将输入序列的长度降为原来的1/4,起到汇聚特征信息的作用。GRU部分用来提取坐标点之间的关联性特征,采用2层双向门控循环单元(bi-direction gate recurrent unit,Bi-GRU)神经网络来实现,D为250,其输入是CNN部分的输出。
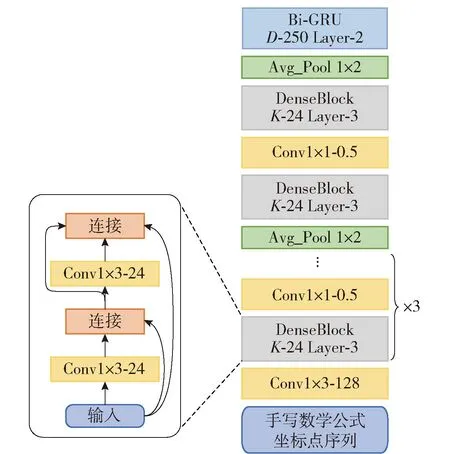
图3 联机编码器模型
假设输入序列Xon=[X1,X2,…,Xn],为了匹配模型的输入格式,首先将Xon转换成形状为[E,n,1]的张量。经过卷积后的输出是一个形状为[C,L,1]的张量,C表示最终输出的通道数,L表示输出的特征序列的长度,由于池化层的作用,L=N/4。然后,将该张量的形状转换为[L,C]并输入GRU模型中,最终得到联机特征信息Con=[C1,C2,…,CL],其包含了整个输入坐标点序列的特征信息。
3.2 脱机编码器
脱机编码器是由更深层的卷积神经网络模型DenseNet-99实现的,不同的是去掉了Transition后的平均池化层。模型主要由3个DenseBlock和2个Transition构成,如图4所示。每个DenseBlock包含23层网络,每层网络包含4层卷积层,增长因子K为24。在第1个DenseBlock前有一层卷积核为7×7的卷积层和一层最大池化层,卷积步长为2。每个Transition内部和后面均有一层卷积层,用来压缩和连接2个相邻DenseBlock的通道数。模型最后一层是全连接层,作用于通道维度上,用来控制输出特征维度的大小。
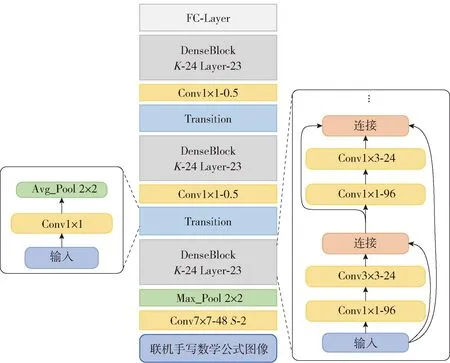
图4 脱机编码器模型
假设输入图像的高和宽分别为Himg和Wimg,在输入模型前需要将其转换成形状为[1,Himg,Wimg]的张量,1表示输入通道数。经过编码后的脱机特征信息Coff是一个形状为[D,H,W]的张量,其包含了整个输入图像的二维结构特征信息,D表示脱机特征维度,与联机特征维度大小相同,H和W分别表示输出特征图的高和宽。
3.3 解码器
解码器模型根据Con和Coff预测LaTeX序列,由2层GRU构成。为了在每次解码前使解码器聚焦于特征信息的有效解码区域,引入了注意力机制。在每次解码前,分别通过覆盖注意力机制和平滑注意力机制对Con和Coff筛选有效的解码信息,进而提升解码器的效果。解码器计算过程的公式为
t=GRU1(yt-1,ht-1)
(13)
(14)
(15)
(16)
式中:上标on和off分别表示联机模式和脱机模式;yt-1和ht-1分别表示t-1时刻的标签和隐藏状态;t表示t时刻的近似输出;Con和Coff分别表示联机特征信息和脱机特征信息;Fon、Foff分别表示联式、脱机模式下的注意力值矩阵;和分别表示在t解码时刻经过注意力机制筛选后的联机特征信息和脱机特征信息;Q是一层卷积核为1×7的卷积层;和分别为覆盖注意力机制和平滑注意力机制的实现函数;fcross表示一种交叉合并操作,可将和合并。式(16)是一层GRU,根据和t计算得到t时刻的隐藏状态ht。首先,在合并前要将转换成形状为[H×W,D]的序列形式;然后,利用卷积操作实现合并后的多模数据在数值上的充分融合。其中交叉合并是在Wang等[10]提出的多模融合方法的基础上进行改进的,能够保证多种模式的数据分布较均匀,其具体操作步骤如下。
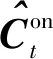
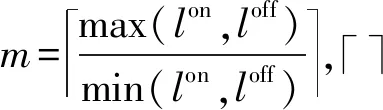
m=max(lon,loff)min(lon,loff),「⌉
步骤3计算间隔距离为向上取整操作。
步骤5返回融合后的结果。
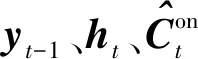
(17)
4 实验
4.1 数据集及数据预处理
4.1.1 数据集
为了保证结果对比的公平性,实验采用CROHME[13]比赛提供的官方数据集。训练集为CROHME2014提供的训练集,模型的验证分别采用CROHME2014和CROHME2016提供的验证集。实验数据集如表1所示。每个公式的标签均是一个LaTeX格式的序列,因此,标签符号不仅包含了101种手写字符,还包含了一些表示二维结构关系的虚拟符号, 如“^”“_”“{”等,共包含111种标签字符。这里111种标签字符已经包含了用于标志输出序列结束的特殊符号。
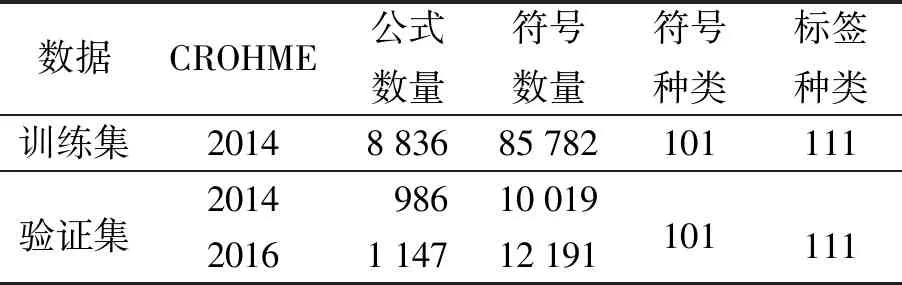
表1 实验数据集
4.1.2 数据预处理
在输入模型前数据集需要经过数据预处理操作,其目的是要将手写数学公式的原数据转化为一维坐标点序列和二维静态图像2种形式,进而提高数据的表示能力。数据集中每个公式的原数据是一个坐标点序列
[(x1,y1,s1),(x2,y2,s2),…,(xn,yn,sn)]
式中xi、yi和si(1≤i≤n)分别表示第i个坐标点的横坐标值、纵坐标值和该坐标点所属笔画的序号,坐标点的顺序对应手写的笔迹顺序。每个人的手写风格和录入设备规格不同,导致同一公式的录入数据有很大差别,增大了识别难度。为了解决该问题,对联机模式和脱机模式分别设计了不同的预处理方式。
对于联机模式,首先根据文献[14]对原坐标点序列去重和归一化,然后为了增强每个坐标点与其前后坐标点的关联性,基于文献[7] 将每个坐标点表示为一个10维的特征向量
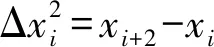
对于脱机模式而言,首先将原坐标点序列进行二维映射,然后经过双线性插值、平滑处理和膨胀处理,最后经过转换得到二维静态图像。
4.2 模型评估指标
模型的输出是LaTeX序列,其包含了手写实体符号和表示二维结构关系的虚拟符号,因此,采用公式识别准确率RE和结构识别准确率RS作为模型的评估指标。具体的计算方式为
(18)
(19)
式中:N表示公式总数;NE表示完全识别正确的公式数量;NS表示所有虚拟符号识别正确的公式数量。RE和RS的值越大,表示模型的识别效果越好。
4.3 实验参数设置
实验分为训练和测试两部分,其中训练的任务根据输入数据更新模型参数,使预测LaTeX序列的概率最大。为了降低过拟合,目标函数采用引入了标签平滑的交叉熵损失函数,公式为
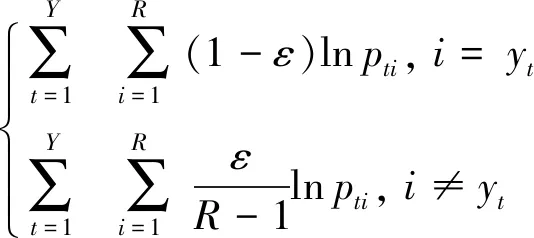
(20)
式中:ε为0.1,表示平滑因子;R为111,表示标签字符的种类;pti为t时刻第i个字符的预测概率;yt为t时刻的真实标签;Y表示LaTeX序列的长度。实验采用AdaDelta[15]作为优化算法,参数rho为0.95,eps为10-6,weight_decay为10-4。根据实验环境,将训练批次设置为32,学习率设置为10-3,最大迭代次数为500,并且采用早停法根据单字符错误率[16]判断训练过程是否提前结束。实验相关的可调整参数主要有点特征维度Ein、编码维度E、特征维度D、注意力维度A和平滑注意力机制的最大平滑范围T。其中:Ein根据数据预处理设定为10;D和A的取值参考了文献[6] 的参数设定,最终将D设置为250,A设置为500。本研究对新参数E和T进行了参数分析实验,并最终将E设置为200,T设置为4。参数分析实验分别将E设置为50、100、150、200、250、300和350,T设置为2、3、4、5和6,并观察实验结果。图5(a)为E和T的取值与公式识别准确率之间的关系。从图中可以得出,公式识别准确率受E和T的影响较大且会随着E的增大而增大。当E取值为200及以上时,公式识别准确率的增长开始趋于平缓。相较于取其他数值时,T取4可使识别的准确率达到较高水平。图5(b)展示了E和T与单个公式识别耗时之间的关系。从图中可以看出,当E取值为250及以上时,识别耗时明显增长且整体受T的影响较小。为了使公式识别准确率尽可能高的同时保证识别性能,综合考虑将E设置为200,将T设置为4。
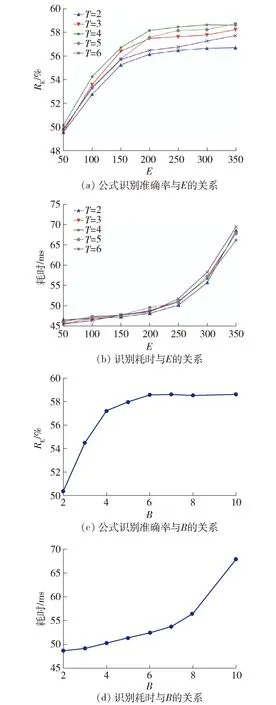
图5 参数E、T和B对识别的准确率和识别耗时的影响
在测试阶段,为了使预测LaTeX序列的概率最大,引入了束搜索策略,束宽为B。B的取值对公式识别准确率和识别耗时的影响都比较大,因此,这里同样对B的取值进行了参数分析实验。图5(c)展示了B与公式识别准确率之间的关系,公式识别准确率会随着B的增大而增大,当B取值为4及以上时,公式识别准确率的增长开始趋于平缓。图5(d)展示了B与识别耗时之间的关系。从图中可以得出,识别耗时会随着B的增大而快速增长,当B取值为5及以上时,识别耗时的增长更加明显。同样,为了在公式识别准确率较高的前提下,尽可能降低单个公式识别耗时,综合考虑将B设置为5。
4.4 实验结果与分析
为了验证本文提出的正弦编码、平滑注意力机制及融合了这2种方法的DOOM的优越性,本文分别对正弦编码、平滑注意力机制及DOOM的效果进行实验。
4.4.1 正弦编码效果实验
本文提出正弦编码的目的是通过丰富笔画级别的表示信息,尽可能避免笔画信息丢失,尤其是在有不同笔画粘连和笔画数量较多且长度相差较大的情况下。本文对文献[7] 中的TAP模型进行复现并作为对比模型,在TAP的基础上应用正弦编码得到模型TAP+SINS。加入正弦编码后在CROHME2014和CROHME2016验证集上,公式识别准确率分别提升3.89%和3.31%,结构识别准确率分别提升2.49%和3.12%,如表2所示。实验结果表明加入正弦编码序列能够有效丰富每个笔画的特征信息,进而提高不同笔画之间的区分度,增强输入数据的表示能力,在一定程度上提高了联机模式下的公式识别准确率和结构识别准确率。
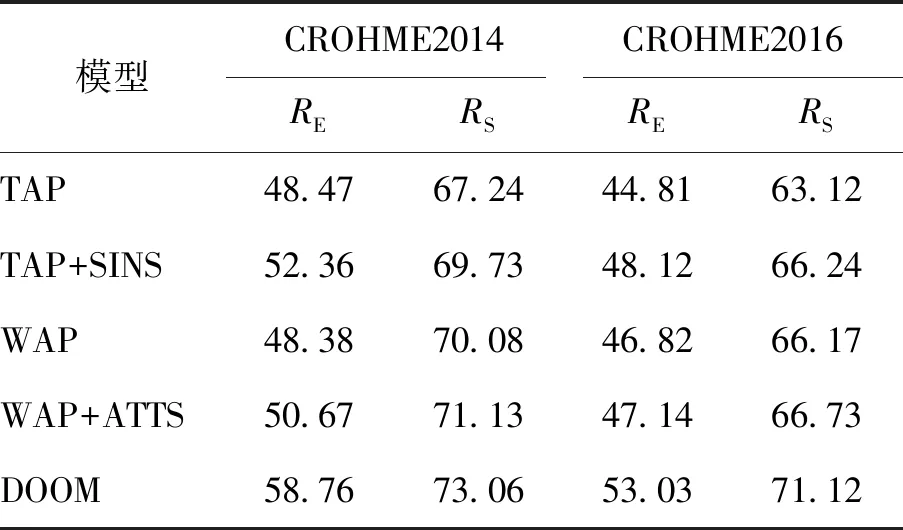
表2 实验结果对比
本文通过2个实例对应用正弦编码前后的识别结果进行了分析,表3分别展示了原手写公式图像、应用正弦编码前的识别结果(识别结果1)和应用正弦编码后的识别结果(识别结果2)。
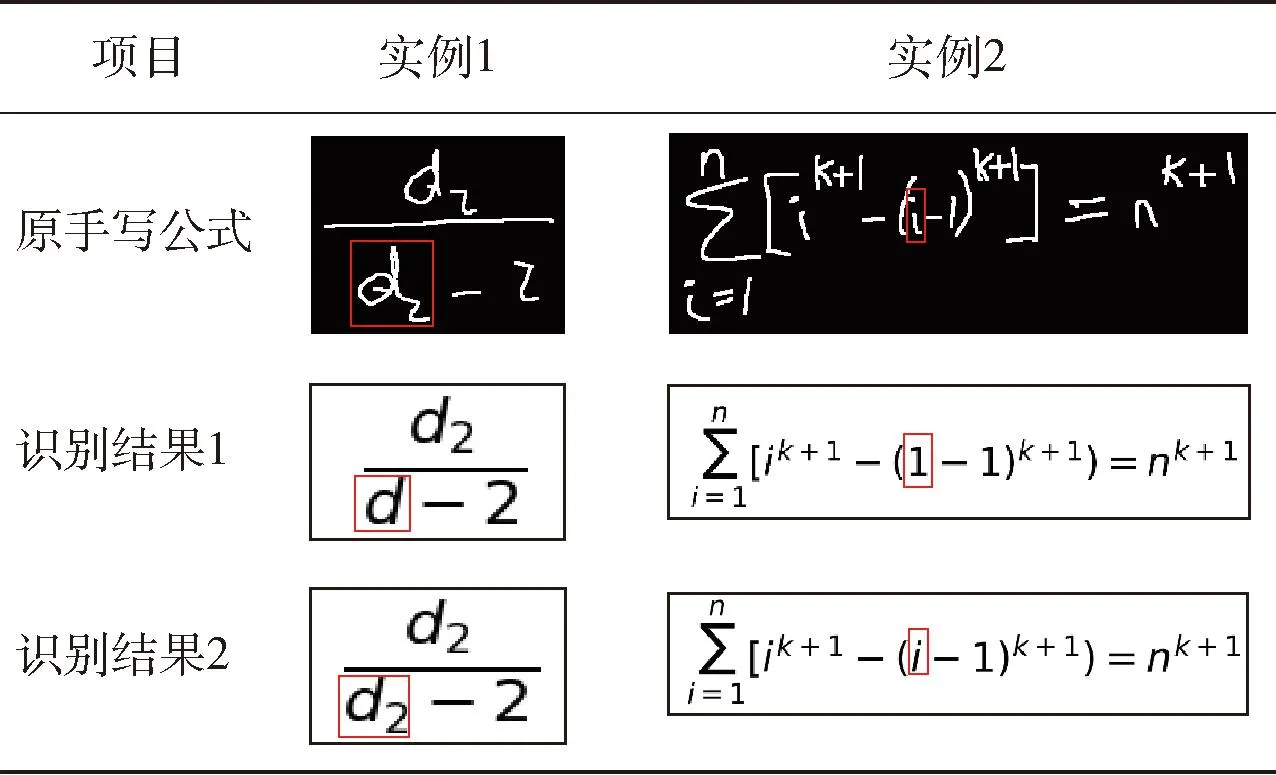
表3 应用正弦编码前后识别结果对比
实例1展示了有笔画粘连时的识别结果,粘连部分已在原手写公式图像中通过红色矩形框圈出,可以看到字符“d”和“2”粘连在了一起。在应用正弦编码前,模型将其认为是同一个笔画,从而将其误识别为“d”。在应用正弦编码后,模型能够将粘连后的字符“d”和“2”分开识别,表明正弦编码能够补充笔画的间隔信息,在一定程度上解决了笔画粘连问题。
实例2展示了当公式包含较多笔画且笔画长度相差较大时的识别结果,从手写公式图像中可以看到,其不仅包含了较长的笔画,如求和符号“∑”,还包含了较短的笔画,如在原手写图像中通过红色矩形框圈出的字符“i”的“.”,由于该笔画包含了非常少的坐标点,在识别过程中极有可能发生信息丢失的问题。在应用正弦编码前,丢失字符“i”中“.”的信息导致将其误识别为“1”,如识别结果1所示。在应用正弦编码后,能够有效保留了“i”中“.”的特征信息,并将其正确识别为“i”,表明应用正弦编码能够补充各个笔画的特征信息,进而在一定程度上避免了较短笔画的特征信息发生丢失。
4.4.2 平滑注意力机制效果实验
本文提出平滑注意力机制的目的是更加精确地筛选尺寸相差较大的符号的特征信息。本文基于平滑注意力机制得到模型WAP+ATTS。相比于复现后的WAP模型,WAP+ATTS模型在CROHME2014和CROHME2016验证集上,可将公式识别准确率分别提升2.29%和0.32%,将结构识别准确率分别提升1.05%和0.56%,如表2所示。以上实验结果表明,平滑注意力机制能够在一定程度上提升脱机模式下的公式识别准确率和结构识别准确率。
为了能更直观地感受应用平滑注意力机制后模型对有效特征信息捕捉能力的提升,分别对覆盖注意力机制和平滑注意力机制的结果进行了可视化,效果对比如图6所示。图6以公式“g(b)-g(a)=b-a”为例,将右侧字符对应的有效手写区域以红色表示。从图中可以看出,相比于覆盖注意力机制,平滑注意力机制捕捉到的与右侧符号有关的手写区域更加精确。例如,在捕捉符号“b”的手写区域时,覆盖注意力机制却捕捉到了属于左右括号的一些手写区域,而平滑注意力机制可以精确捕捉只属于“b”的手写区域,表明平滑注意力机制可以对特征信息中的特征元素实现更细粒度的计算和筛选。除此之外,对于尺寸相差较大的符号,如“-”和“g”,覆盖注意力机制在对“-”捕捉特征信息时,会捕捉到其他的无用信息,而对于“g”的信息捕捉时,却并不能捕捉到其全部的特征信息。相比之下,平滑注意力机制对“-”和“g”的特征信息捕捉效果较好,表明平滑注意力机制可以有效提升对不同大小的手写符号特征信息的筛选效果。

图6 覆盖注意力机制与平滑注意力机制效果对比
4.4.3 DOOM识别效果实验
首先,通过识别准确率指标衡量DOOM的效果。相比于TAP+SINS模型,DOOM在CROHME2014和CROHME2016验证集上可将公式识别准确率分别提升6.40%和4.91%,将结构识别准确率分别提升3.33%和4.88%,相比于WAP+ATTS模型,DOOM在CROHME2014和CROHME2016验证集上可将公式识别准确率分别提升8.09%和5.89%,将结构识别准确率分别提升2.93%和4.39%,如表2所示。实验结果表明,相比于单模识别模型,DOOM能够在一定程度上提高手写符号和结构关系分类的准确率。
然后,将DOOM与相关领域内的其他模型进行对比,实验结果如表4所示。UPV[13]和Wiris[17]分别在CROHME2014比赛和CROHME2016比赛中取得了最高的识别准确率(在使用CROHME提供的官方数据集作为训练集的模型范围内)。WYGIWYS[18]和PAL[19]同样也在CROHME2014提供的数据集上取得了较高的识别准确率。E-MAN[10]和MMSCAN-E[11]分别是2019年和2021年在该领域提出的多模识别模型。相比于E-MAN模型,DOOM可在CROHME2014和CROHME2016验证集上将公式识别准确率分别提升4.71%和4.47%,将结构识别准确率分别提升0.95%和3.73%;相比于MMSCAN-E模型,DOOM可在CROHME2014和CROHME2016验证集将公式识别准确率分别提升1.56%和1.06%。以上实验结果表明,本文提出的DOOM能够更有效地实现多种模式数据的融合,丰富了特征信息,进而在一定程度上提升了公式识别准确率和结构识别准确率。

表4 与相关领域内其他模型对比结果
本文提出双模模型的目的是通过丰富特征信息,进而提升每个字符的区分度。因此,本文选择了一些相似字符,对不同模式下的特征向量进行降维,进而对相似字符可视化。图7(a)(b)(c)分别为基于脱机模式、联机模式和双模模式特征向量的相似字符的可视化效果。从图7(a)中可以看出,脱机模式下的相似字符在二维空间中分界并不明显,尤其对于字符“b”和“6”。从图7(b)中可以看出,相比于脱机模式,根据联机模式特征信息可以更好地区分相似字符,尤其是对于手写笔迹顺序不同的字符,如“a”和“α”。然而,对于外形和笔迹均相同的字符,如“q”和“9”,分类界限仍然很模糊。图7(c)展示了基于双模模式特征信息的分类效果,这类特征信息不仅包含了手写字符的二维结构特征信息,而且保留了手写笔迹的顺序特征信息。从图中可以看出,相比于单一的联机模式或脱机模式,基于双模模式特征信息对相似字符的区分度明显提高,不仅可以对像“a”和“α”这种外形相似但笔迹顺序不同的字符进行分类,而且在一定程度上提升了对外形和笔迹顺序都相同的字符的分类效果。
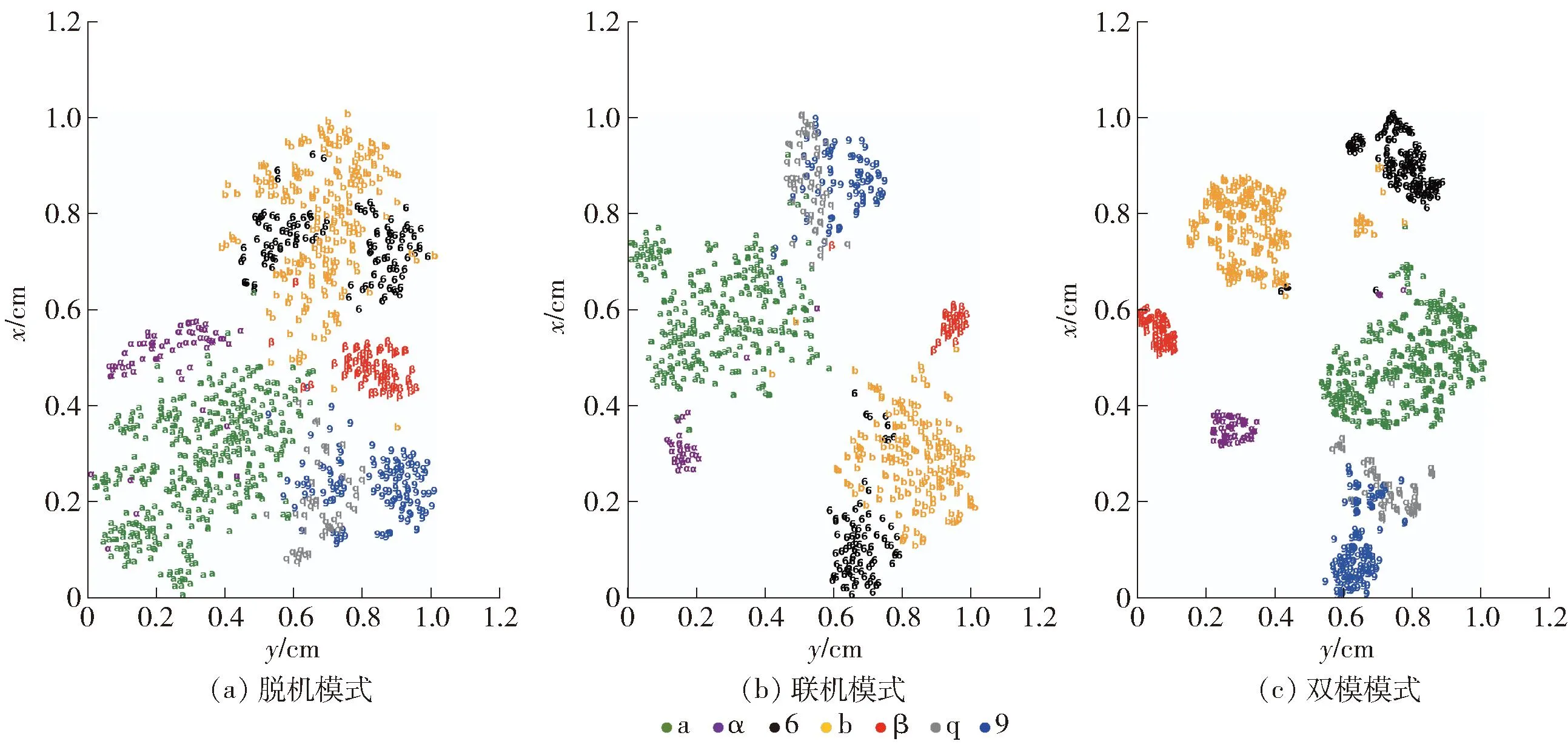
图7 基于不同模式特征向量的相似字符分类效果对比
5 结论
1) 为了解决单模识别模型只接受一种形式的数据导致输入数据特征的丰富度较低以及数据信息在识别过程中衰减、手写符号大小差异影响识别效果等问题,本文设计了双模识别模型,并提出了正弦编码和平滑注意力机制,分别针对联机模式部分和脱机模式部分进行增强。
2) 实验结果表明,正弦编码通过对输入坐标点序列进行编码,可有效补充笔画级别的表示信息,在一定程度上避免了该类信息在识别过程中丢失。平滑注意力机制在一定程度上克服了手写符号大小差异带来的影响,能够在特征信息中有效筛选到与解码字符相关的部分特征信息,从而提升了识别效果。相比于单模识别模型,双模识别模型能够更加有效地丰富手写字符的特征信息,提高手写字符的区分度。
