基于多元特征异构集成深度学习的图像识别模型及其应用
2024-01-08王子轩韩红桂
汤 健, 田 昊, 夏 恒, 王子轩, 徐 喆, 韩红桂
(1.北京工业大学信息学部, 北京 100124; 2.智慧环保北京实验室,北京 100124)
随着科技的发展和5G的迅速普及,智能手机的更迭速度不断加快[1]。据Strategy Analytics预测,2021年全球智能手机的出货量将同比反弹6.5%,总量达13.8亿部[2]。更换速度的加快是导致手机出货量不断提高的主要原因,这也导致个人闲置手机的累计量逐年增多。废旧手机作为一种典型的城市矿产资源[3],利用无人化、智能化的回收装备对其进行回收,能够节省大量人工成本和提升居民交投意愿[4]。废旧手机的外观大多具有唯一性,根据图像对其品牌等特征进行识别的方法具有成本低、实用性强等特点[1]。如何采用相关数据集构建分类模型对废旧手机进行智能化识别已成为当下提高智能化回收装备回收效率的研究重点[5]。
传统图像识别方法模型较为简单,无须基于大规模数据训练。文献[6]改进小波阈值去噪方法及Otsu阈值设置方法,提高传统Canny算子的边缘检测性能,实现了生产线手机膜的缺陷检测。文献[7]提出了基于形态学的红外图像边缘检测算法,改进了仅使用单一方向和固定方向权重的边缘检测算法,采用多方向结构元素提取图像边缘,通过自适应加权得到最终结果。上述传统图像算法虽然广泛应用于工业目标检测,但该类算法精度较低,难以应对回收装备所拍摄废旧手机图像训练样本稀缺场景。
目前,以卷积神经网络为基础的图像识别技术已在目标检测、人脸识别等领域广泛应用[8]。文献[9]将卷积注意力机制引入残差网络提出一种基于注意力特征融合的无人机多目标跟踪算法。文献[10]将方向梯度直方图(histogram of oriented gradient, HOG)特征和注意力模型作为孪生结构构建目标跟踪模型。文献[11]将自监督预训练和监督微调用于医疗图像分类,在图像标记稀缺的情况下提高了模型的分类精度。通常,以卷积神经网络和大型自监督模型构建的图像分类模型通常需要海量数据集进行预训练。但是,本文所述废旧手机识别问题的数据集仅来源于回收装备样机实拍图片,废旧手机存在不同程度的磨损并且图片样本的数据量较少,难以构建行之有效的神经网络分类模型;并且,因考虑设备制造成本等因素导致拍摄图像清晰度较低,以及用户交投时的不规范操作等因素导致废旧手机图像存在完整度较差、部分区域具有镜像等问题。如何在样本量少且样本质量不高的前提下完成对手机品牌的分类已成为当前待解决的主要问题。
深度森林分类(deep forest classification,DFC)模型已被证实在小样本分类问题中具有良好表现[12-13],如:文献[14]将DFC模型应用于卫星姿态控制系统的执行机构与传感器故障诊断;文献[15]基于GrabCut预处理算法和DFC模型构建了衣物识别模型;文献[16]提出基于DFC的多级特征融合的合成孔径雷达(synthetic aperture radar, SAR)目标识别,表明该方法相比传统模型和深度神经网络模型具有更高的识别率。
基于上述研究现状,文献[4]提出“基于并行差分进化-梯度特征深度森林的废旧手机识别模型”,利用废旧手机背部图像构建手机品牌识别模型,准确率达到80.12%;但该识别方法仅考虑手机全局纹理特征,并未对字符等重要局部特征进行融合和识别处理,其精度仍有待进一步提升。显然,目前废旧手机识别存在的难点包括:如何借助其他领域知识解决训练样本稀少、如何同时融合局部字符特征和全局图像特征、如何融入专家知识以克服废旧手机磨损和交投不规范等因素造成的图片清晰度与完整度差、如何有效提取深度特征等问题。
综上,面向废旧手机识别,本文提出一种基于多元特征异构集成深度学习的图像识别模型。首先,利用字符级文本检测算法(character region awareness for text detection,CRAFT)提取手机背部字符区域;接着,使用ImageNet预训练的VGG19模型[17]对手机背部图像和其字符特征区域进行特征提取,使用高维卷积特征代替单一维度特征;基于局部字符特征构建光学字符识别(optical character recognition,OCR)模型,基于全局图像特征和局部字符特征构建改进DFC模型;最后,将不同模型分类结果线性拼接,通过Softmax函数得出最终分类结果。基于废旧手机回收装备实拍的图像数据集,验证了该算法在废旧手机识别中的有效性。
1 算法模型
为了保证回收装备在训练样本少且图像精度不高的前提下完成废旧手机品牌识别,提出了一种基于多元特征异构集成深度学习的图像识别方法,其结构如图1所示。
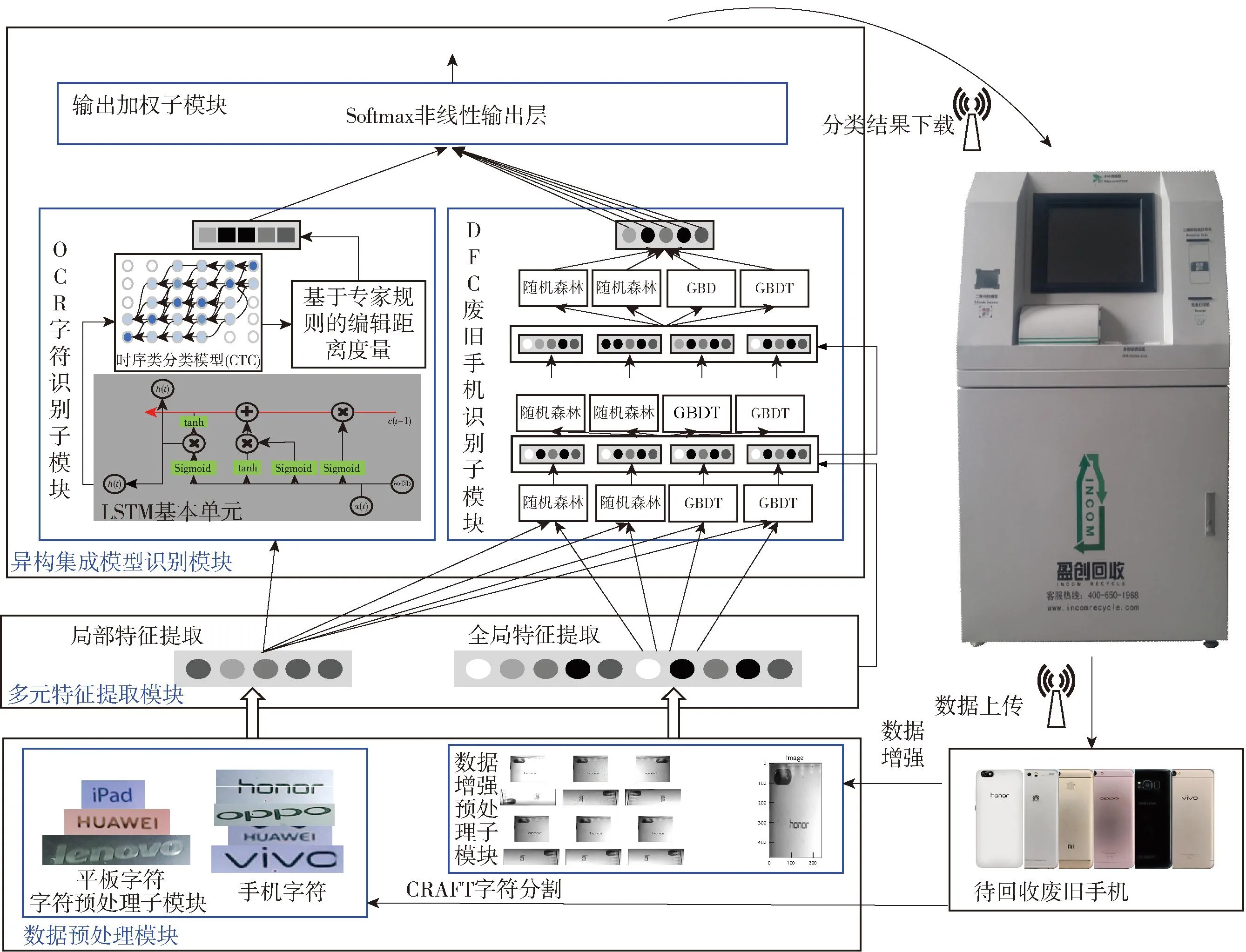
图1 基于多元特征异构集成深度学习的图像识别模型结构
不同模型的功能如下。
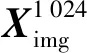
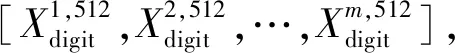
1.1 图像预处理模块
在废旧手机回收流程中,用户的不规范操作会导致采集图像不完整、手机表面反光、手机图像镜像等问题,这使得直接使用回收装备获取的图片构建的识别模型效果不佳。数据增强通过随机改变训练样本以降低识别模型对某些属性的依赖,进而提高模型的泛化能力,方法包括几何变换、颜色空间变换、内核过滤器、混合图像、随机擦除、基于生成对抗网络的增强和神经风格转移等[18]。由于几何变换可解决训练样本的位置偏差问题,而本文所述废旧手机在回收流程中会因用户摆放位置不同而使手机图像产生位置偏差。因此,本文所用数据增强以几何变换为主,包括旋转、翻折、镜像、平移和加入高斯噪声等。
此外,手机背部字符是识别其品牌的重要依据,但用户使用过程中会造成字符的磨损、遮挡等问题,仅将其背部字符作为分类依据会导致识别模型具有很大的局限性。因此笔者提取手机背部图像中的字符特征作为分类依据之一。采用CRAFT字符级图像定位算法确定手机字符位置并分割,将字符特征与整体图片线性拼接,作为后续模型的输入,进而解决难以依据手机图像构建分类模型、单字符特征构建模型的局限性。
研究表明,YOLO3[19-20]、Fast-RCNN[21]等目标检测算法在人脸检测、车牌检测等领域获得广泛应用,但该类算法检测的目标长宽比较为固定,且大多不会出现形变、磨损等问题。在手机回收问题中,摆放位置的差异会导致字符发生旋转和形变,同时废旧手机的部分字符存在磨损现象,因此直接标定字符所在位置进行训练的效果较差。此外,对手机图像数据集中单个字符进行人工标注的工作量难以估计,且已知目标检测数据集鲜有字符级别的标注。CRAFT算法本质是通过字符之间紧密程度预测文本所在区域。本文所用CRAFT模型的训练过程如图2所示。

图2 CRAFT定位裁剪模块结构
已标注数据集包含单个字符的高斯热度图,CRAFT算法对其进行有监督训练。对于手机背部图像数据集,首先,标记手机图像中的文本框区域,将其经过透视变换拉伸到比较正的文本框;接着,利用分水岭算法得到单个字符的位置框,生成对应的高斯热度图;最后,变换后重新贴回原图对应的标签图的相应位置。
分水岭算法的分割结果评分公式为
(1)
式中:l(w)表示手机图像文本框长度;lc(w)为分水岭算法分割字符串长度结果。
(2)
因此,分水岭算法分割得到字符串长度后,根据式(1)得到算法评价值,若该值与真实字符长度一致,则置信度Sc(p)=1。显然,评分越低说明分割结果可信度越差。
1.2 多元特征提取模块
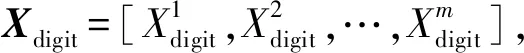
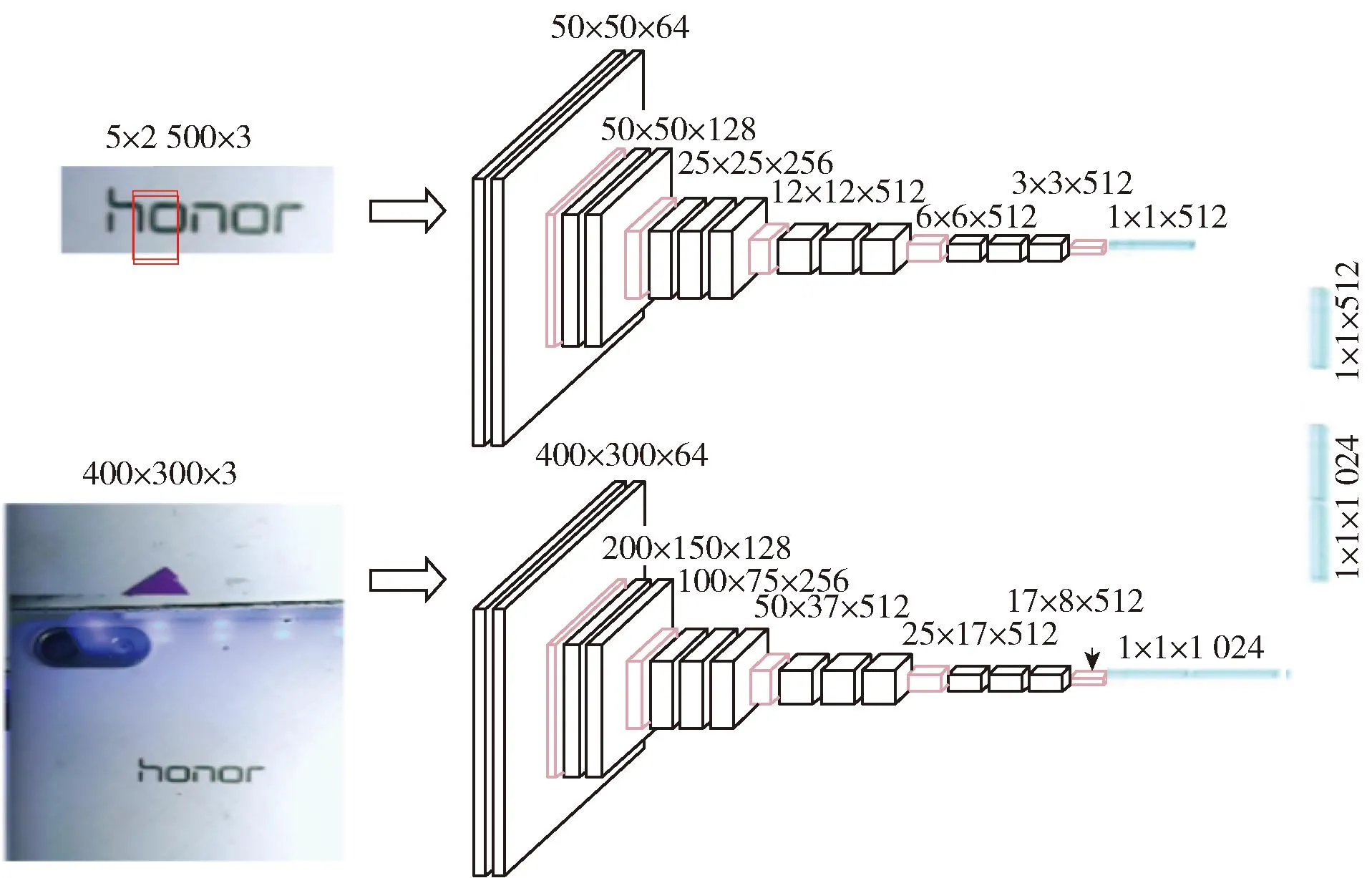
图3 多元特征提取模块结构
1.3 异构集成模型识别模块
仅由纹理特征、字符特征等单一特征构建手机识别模型,其精度难以达到实际应用需求。因此,本文采取集成学习理念[22],将不同角度的特征进行线性组合,构建异构集成多模型,以期通过具有多个不同机理的子模型的集成提高模型识别精度。针对前文所述废旧手机品牌分类问题,构建OCR子模型、DFC废旧手机识别子模型和输出加权子模型,具体如下所示。
1) OCR模型子模块


图4 OCR模型结构
该模块采用基于ImageNet预训练的VGG19模型作为基模型。首先,将VGG19模型中的卷积层和池化层参数固化,以充分利用迁移学习机制解决废旧手机训练样本缺失的问题;接着,针对不同图像特征构建不同大小的全连接层;最后,将不同图像的模型输出进行线性组合,作为后续分类模型的输入特征。多元特征提取后的特征维度由全连接层的维度决定。针对不同大小的手机图像Ximg和字符图像Xdigit,其特征提取过程为
(3)
式中fVGG(·)表示VGG19模型输出过程。
利用软件中的灵敏度分析功能对理论塔数进行分析。初始条件为,原料进料位置:第5块,萃取剂进料位置:第3块,回流比:1,溶剂比:0.9,对塔板数进行灵敏度分析。
(4)
(5)
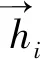
第i时刻的双向LSTM输出为
(6)
接着,采用CTC网络对双向LSTM网络输出[h1,h2,…,hx]中的重复识别字符进行去重,使其变为[y1,y2,…,yn]。由于双向LSTM的基本单元数多于手机字符数量n,导致字符重复划分,如“honor”会被分割为“hoonorr”。因此,需将“hoonorr”等多个子串映射为正确结果“honor”,表示为
(7)
CTC网络通过给定输入X的最大化后验概率P〈Y|X〉获得最终结果Y,表示为
(8)
式中π∈B-1(Y)表示所有可整合为Y的子串集合。
最后,加入基于专家经验的分类结果映射模块,主要是通过莱文斯坦距离构建分类结果距离度量准则,表示为
(9)
式中:pre表示电子产品背部字符识别模块结果;true表示标签集中标签;i和j分别表示pre第i个字符和true第j个字符。
通过上述准则表征预测识别结果与真值标签的相似度,根据相似度对识别结果进行映射,解决由于单一字符的错误识别导致整体识别结果与真实标签的差异问题,进而提高模型识别准确率。
2) DFC废旧手机识别模型子模块
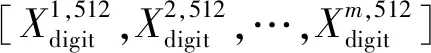
(10)
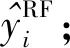
所提改进DFC模型的结构如图5所示。
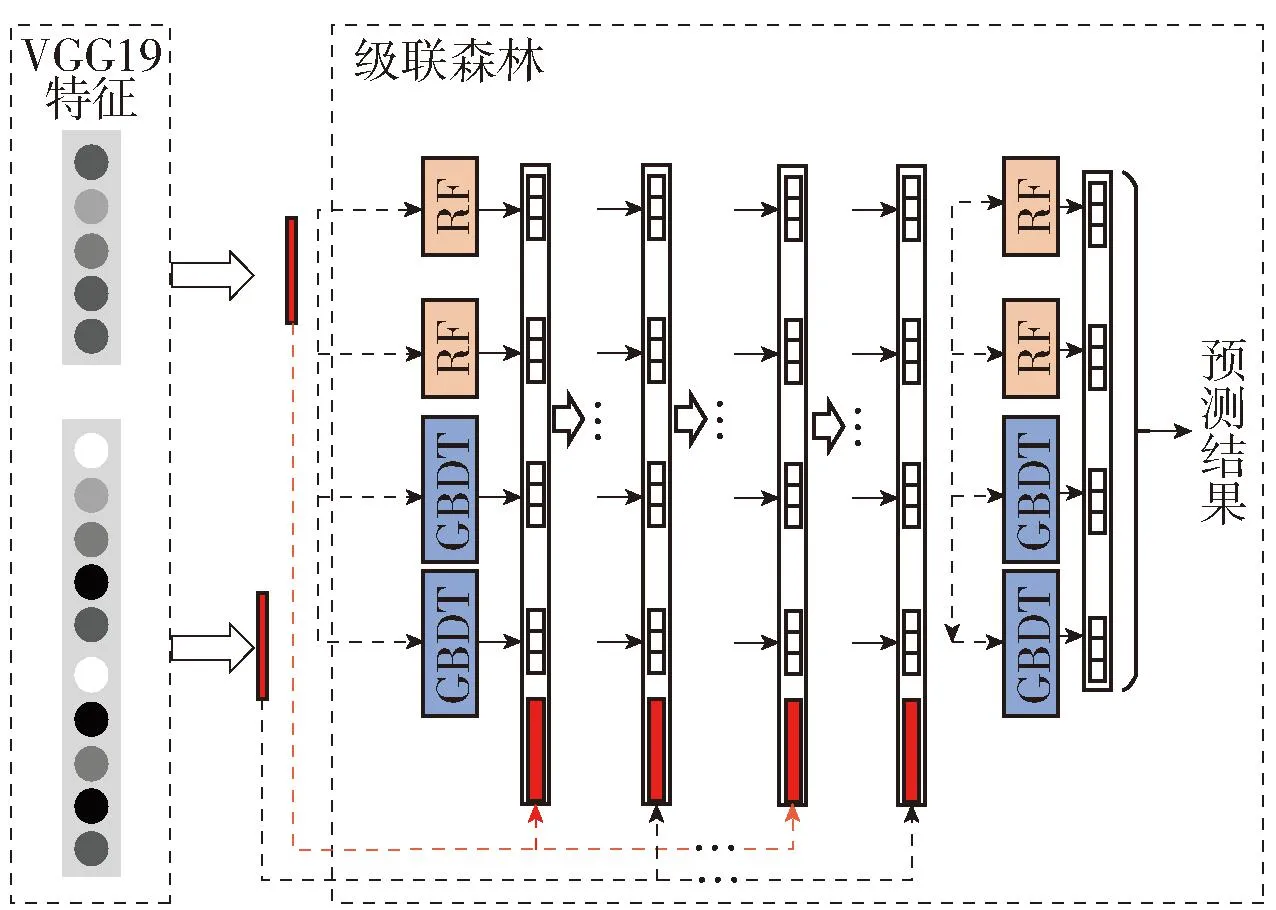
图5 改进DFC模型结构
3) 输出加权子模块
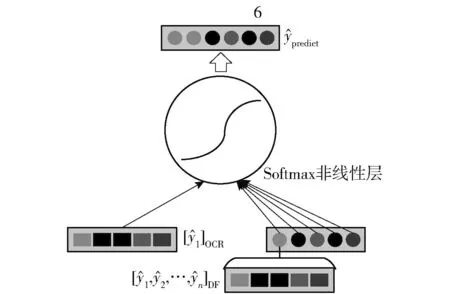
图6 输出加权子模块结构
在本文所述识别模型中,假定废旧手机标签为n个,则OCR结果为[1]OCR,DFC识别结果为[1,2,…,n]DF,线性拼接后可获得n+1维结果向量将其输入目前广泛用于深度网络监督学习分类器的归一化指数函数Softmax,后者表示为
(11)
式中:K表示原始向量维度;e表示自然对数。该函数将任意实数的K维向量z压缩为向量σ(z),并使得每个元素σ(z)j范围都在(0,1)内。
2 仿真实验
2.1 实验数据描述
为验证本文所述算法的有效性,选用废旧手机回收装备实拍图作为数据集进行仿真测试。废旧手机回收装备的应用场景如图7所示。数据集共123张图像,包含8个类别的废旧手机品牌,分别是华为手机(HUAWEI)、荣耀(HONOR)、小米(MI)、中兴(ZTE)、OPPO、VIVO、苹果(iPhone),其他品牌(Others)。

图7 废旧手机回收装备应用场景
实验阶段将样本按8∶2的比例随机划分训练集和测试集,在训练过程中通过十折交叉验证的方法进一步划分为训练子集和验证子集。
本文所述识别模型基于python3.7及TensorFlow-GPU-2.3.0框架构建,其训练和测试硬件环境如下:系统为Ubuntu20.04LTS,内存为 64 GB,GPU为GeForce RTX20280,CPU为Intel Xeon CPU-1650。
2.2 实验结果及分析
首先,构建分类模型前采用数据增强手段对训练集和测试集样本进行扩充。以HONOR手机背部图像为例,将手机背部图像进行旋转、翻折、加噪声等操作,将1张手机背部图像样本扩充至12张。样本扩充示意图如图8所示。
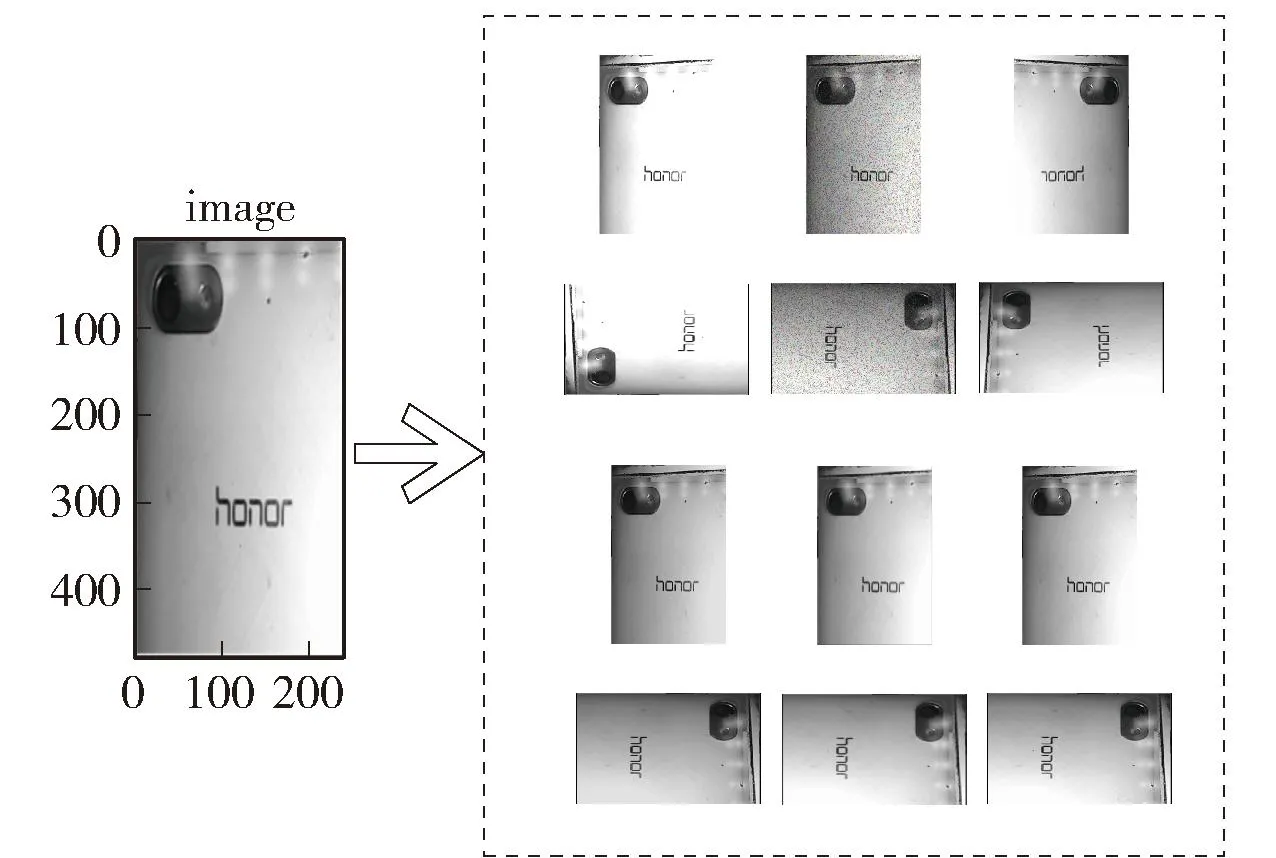
图8 数据增强效果
接着,采用CRAFT字符分割算法对待回收废旧手机图像进行分割,获得对应手机字符数据集,图像预处理结果如图9所示。

图9 图像预处理结果
2.3 多元特征提取结果
多元特征提取采用基于1 400万张图片2万类ImageNet数据集的VGG19预训练模型fVGG(·)。根据输入图像的不同,在VGG模型中加入不同大小的全连接层,其中针对400×300的全局手机图像加入1 024维全连接层,针对50×50的局部字符图像加入512维全连接层。
为说明字符特征在废旧手机分类问题中的重要性,抽取VGG19模型中的某层输出进行可视化。全局手机图像和局部字符图像的VGG19特征提取图如图10和11所示。如图所示,进行VGG19特征提取后,字符纹理信息能够有效保留。
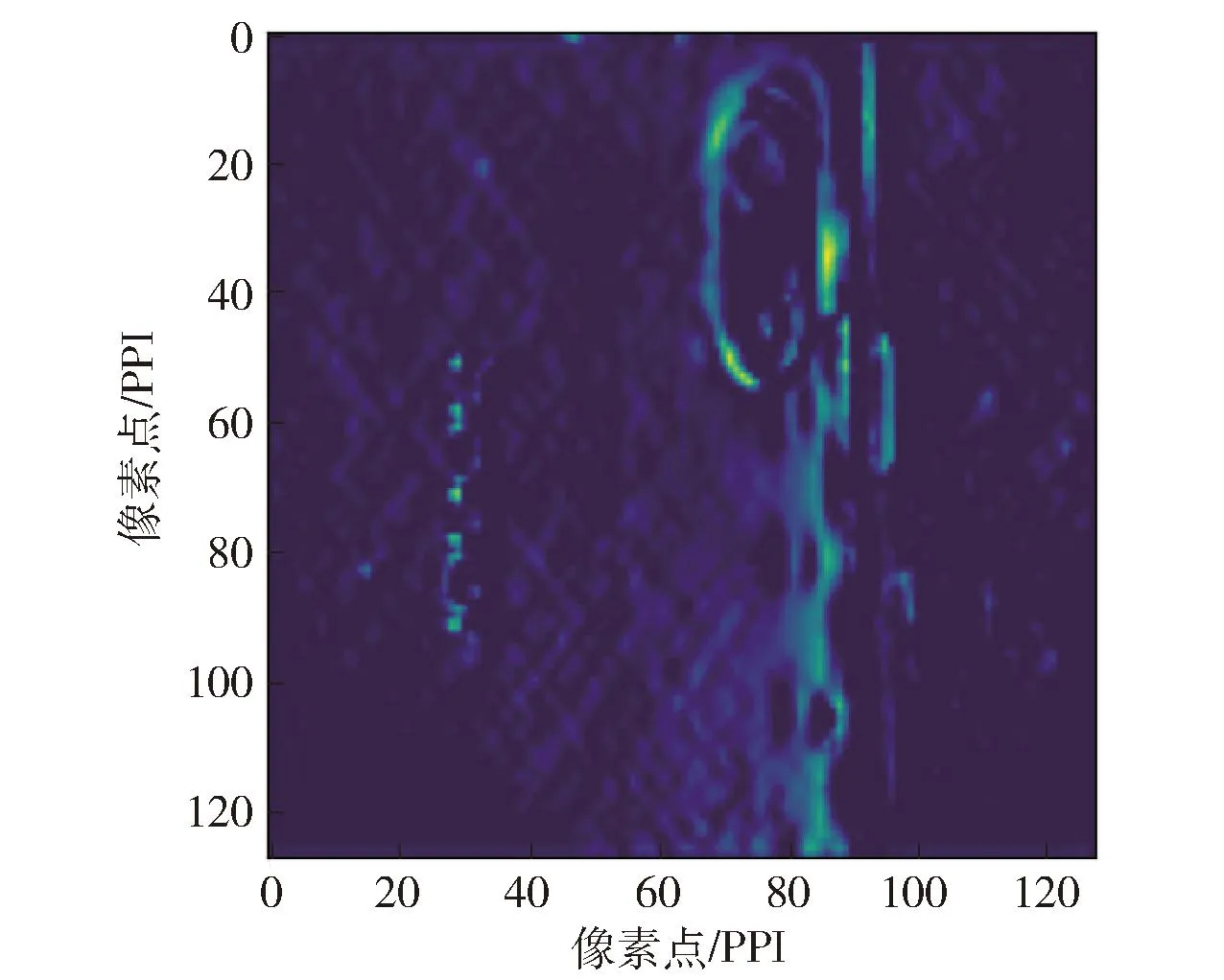
图10 VGG19提取的全局图像特征
图11 VGG19提取的局部特征
2.4 异构集成模型识别结果
本文的OCR模块利用EasyOCR中英文字符预训练模型[23],包括128个LSTM基本单元,即k=128。DFC废旧手机识别模型使用RF和GBDT作为每层模型的基分类器,均采用250棵决策树,后者选用L1+L2正则化优化损失函数。
使用图像预处理后的字符图片构建的OCR模型分类混淆矩阵如图12所示,使用废旧手机图像和字符图片构建的DFC废旧手机识别模型分类混淆矩阵如图13所示。

图12 OCR模型混淆矩阵

图13 DFC废旧手机识别模型混淆矩阵
通过输出加权子模块对上述2个子模型的结果进行集成,进而得到多元特征异构集成深度学习的识别模型混淆矩阵,其分类精度可达90.17%,如图14所示。

图14 多元特征异构集成深度学习模型混淆矩阵
2.5 对比实验
为验证本文所述方法有效性,将所提方法与当前主流小样本分类模型进行比较,其中:微调(fine-tuning)法用ImageNet作为原始数据集训练VGG19和ResNet50[24],将卷积层权重参数固定,采用本文所述废旧手机图像训练最后的全连接层参数;元学习法中采用基于度量准则的Siamese network[25],采用网络爬虫获取手机背部图像训练一个VGG19网络,再通过废旧手机图像训练另一个VGG19网络,利用欧氏距离计算相同类别高清样本与实拍样本在对应模型中的高维特征相似度,具体结果如表1所示。此外,本文分别构建了单一特征+深度森林、VGG特征+深度森林、VGG特征+OCR模型的分类模型,精度如表2所示。由结果可知,本文所提方法具有最佳性能。

表1 不同方法的对比结果

表2 废旧手机识别模型精度对比结果
3 参数分析
本文所述异构集成深度学习识别方法中的2个子模型的超参数决定了模型精度。对OCR模型中LSTM单元数进行超参数实验,结果如图15所示。
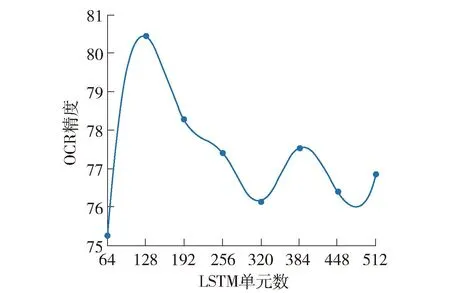
图15 LSTM单元数与OCR精度关系
如图15所示,OCR模型精度受LSTM单元数影响:LSTM单元数增多后,模型精度在训练集表现为持续提高,但在测试集表现为略有降低。综合考虑后,将LSTM单元数设为128较为合理。
在DFC模型中,对森林算法种类及其含有的决策树数量2个超参数进行实验分析。其中,森林算法类别在完全随机森林(CRF)、普通随机森林(RF)和GBDT这3类中任选2类。以VGG19输出为DFC输入进行的分组实验结果如表3所示。

表3 不同森林算法的DFC模型精度对比
为简化模型需调整的参数量,本文在不同种类的森林算法中采用相同数量的决策树。针对本文所采用的RF+GBDT模型,决策树数量对识别精度的影响见图16。如图所示,综合模型精度和复杂度考虑,决策树数量设为250较为合理。
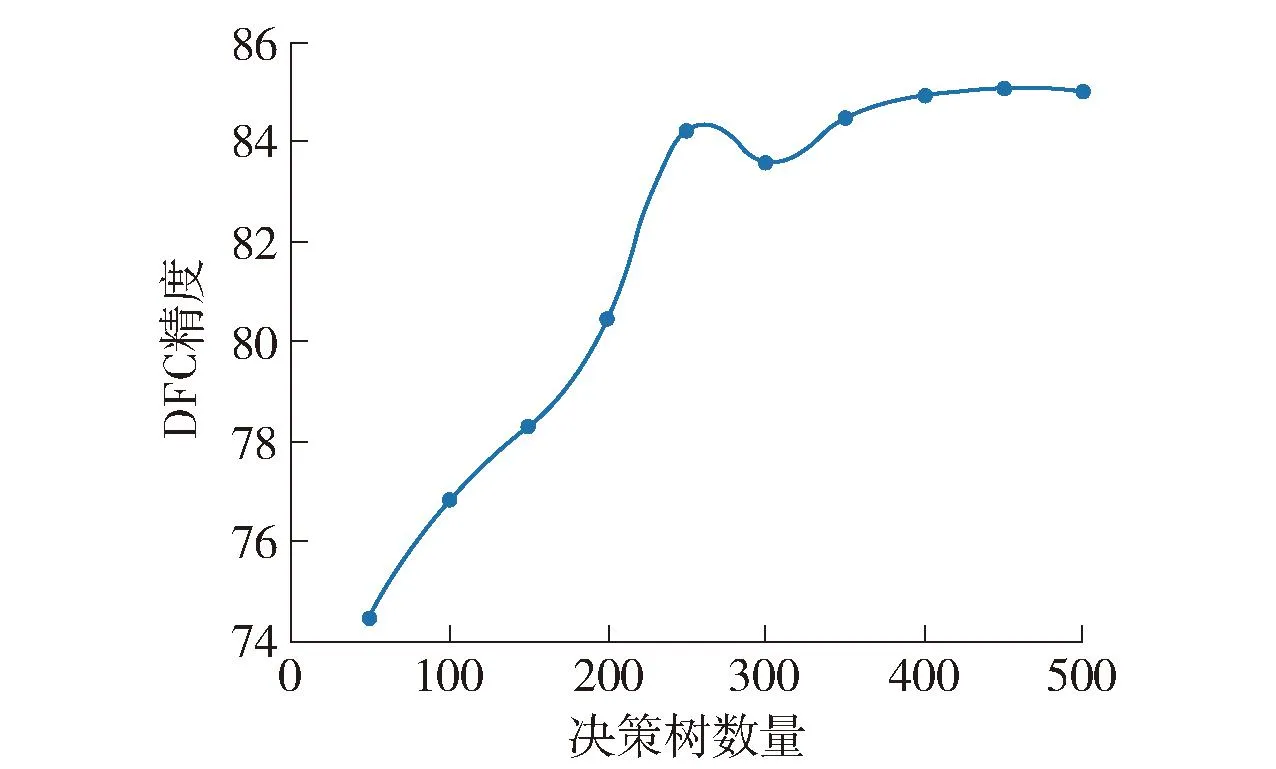
图16 决策树数量与DFC精度关系
4 结论
本文所提基于多元特征异构集成深度学习的图像识别方法能够很好地改善废旧手机回收装备拍摄手机图片样本少、图像质量不高导致的识别精度低的问题,创新性体现在:
1) 使用ImageNet预训练的VGG19网络对废旧手机图像进行全局和局部特征提取。随着卷积层的深入,单个特征的感受野不断增大,其表征能力不断增强,更优于单一视角的特征提取方法。相比仅采用对纹理敏感的HOG特征所构建的DFC模型,使用VGG19构建的模型精度明显提高。
2) 采用异构集成深度学习方法构建废旧手机分类模型,基于同一数据集对不同任务构建分类模型,最后通过非线性函数对多个模型输出进行加权得到最终分类结果,所提异构集成模型相比单OCR和单DFC识别模型的精度明显提高。
仿真实验结果表明,在样本数量相同的前提下,所提方法具有较高的识别率,但特征提取模块的计算代价较高,下一步研究将通过继续优化网络结构以提高特征提取模型与所识别对象的关联度,以期进一步提高精度。
