基于BWOA-SVM的尾矿库风险评价
2024-01-08于雁武许开立
荀 曦 郑 欣 于雁武 许开立
(1.东北大学资源与土木工程学院,辽宁 沈阳 110819; 2.中北大学环境与安全工程学院,山西 太原 030051)
经过选矿厂选出有价值的精矿后剩余的废渣,称作尾矿[1],这些尾矿堆存起来形成了尾矿库。尾矿库是矿山企业最大的危险源[2],工业发展的同时,尾矿库数量日益增加,坝体也越来越高,严重威胁着企业和周围居民的生命财产安全;尾矿库同时也是最大的污染源,尾矿库溃坝后大量的尾矿流入河流,造成土壤和水等环境污染,治理费用高,生态恢复困难。尾矿库一旦发生溃坝将会造成难以逆转的生态破坏和无法估计的财产损失。2022年3月27日山西省吕梁市的山西道尔铝业有限公司一尾矿库发生溃坝事故,致7.5亩乔木林地掩埋,200余米季节性沟渠、乡村道路堵塞,相邻企业部分围墙冲毁。故需要对尾矿库进行定期风险评价,及时掌握尾矿库风险状态,才能采取应对措施。
随着信息时代的到来,人们开始借助于机器学习算法进行风险分级评价,机器学习中的分类算法,能学习已有数据分类规则对新输入的数据进行分类,得到了广泛使用。目前,很多专家学者利用机器学习算法进行尾矿库风险评价,并取得了一定成果[3-7]。基于机器学习的风险评价类文章中构建的尾矿库风险评价指标体系中的评价指标大多为可监测的指标,很少考虑非监测类的管理指标,由此评价得到的尾矿库风险等级极易与现实存在差异;为保障模型的精度,需要足量的数据对模型进行训练,尾矿库数据受到技术、成本等的限制,获取完整数据较为困难。
基于此,本研究从事故统计和管理方面对尾矿库综合分析,全面构建指标体系;针对尾矿库指标体系中的指标数据难获取、成本高的问题,本研究根据现有的尾矿库等级比例,采用加权RAND()函数生成随机数值作为尾矿库风险评估的训练数据库。对生成的样本数据采用博弈论法组合层次分析法(AHP)和熵值法确定评价指标权重,构建加权物元模型评估尾矿库风险等级。采用改进鲸鱼算法(BWOA)优化SVM对尾矿库风险等级进行预测。鲸鱼算法(WOA)提高模型分类准确性的同时改进SVM过拟合的问题。此时尾矿库风险评价模型已经构建完成,将实际尾矿库数据输入构建好的模型中,即可得到对应的风险等级,本文采用山西东沟尾矿库实际数据验证模型。研究流程图见图1。
1 构建风险等级评价指标体系
尾矿库自身常见的危害类型有:洪水漫顶、坝体失稳、渗透破坏、结构破坏4种[8],同时尾矿库的安全性还受到管理因素的影响。通过尾矿库的事故统计和分析的结果,选取指标构建尾矿库风险评价指标体系,见图2。
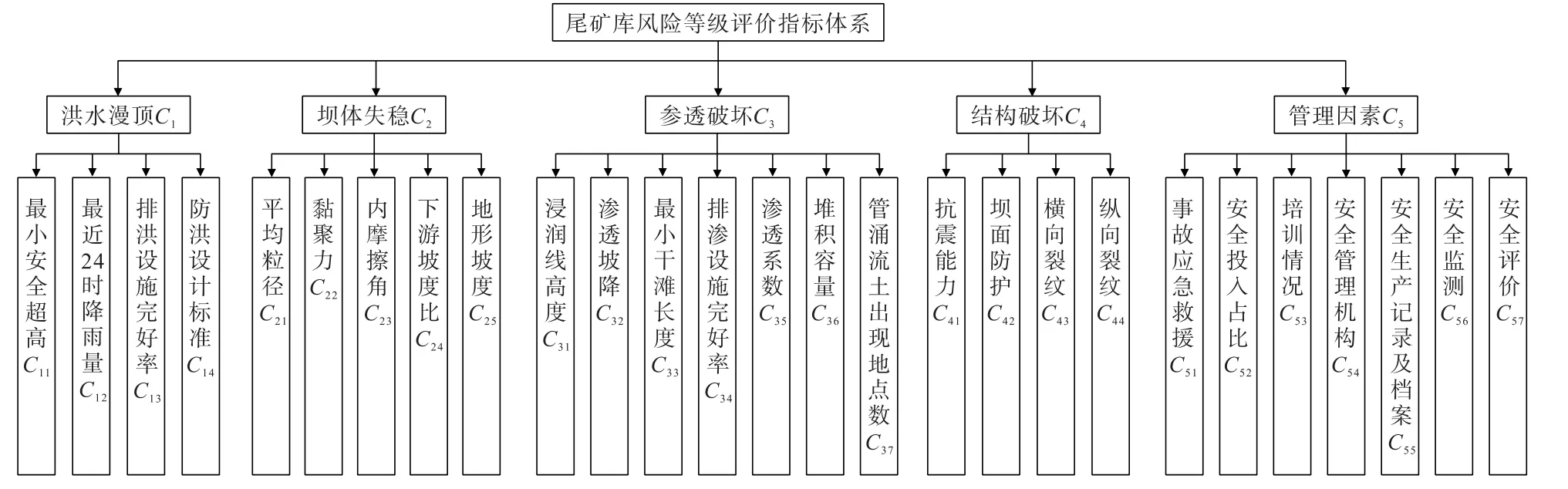
图2 尾矿库风险等级评价指标体系Fig.2 Risk level evaluation index system of tailings pond
尾矿库分为正常库、病库、险库、危库4个等级,因此将尾矿库风险评价指标也分成4个级别,并结合现有标准资料和尾矿库基础数据库,制定了尾矿库风险评价指标的分级标准,见表1。
2 确定指标权重
本研究以博弈论为基础,将层次分析法和熵值法相结合,从主、客观两个方面确定评价指标权重,既考虑了评价指标内部关系,又考虑了数据量本身对权重的影响。
2.1 层次分析法
层次分析法是由美国运筹学家T.L.Saaty教授于上世纪70年代初期提出的评价方法[9],其在赋权得到权重向量的时候,主观因素占比很大。
通过两两比较指标重要性,对重要程度按1~9赋值构建判断矩阵,计算判断矩阵特征向量、特征值,选取最大特征值,将对应特征向量归一化作为权重,最后进行一致性检验,一致性检验通过说明判断矩阵没有逻辑错误。
2.2 熵值法
在信息论中,熵是对不确定性或随机性的一种度量,不确定性越大,熵值就越大,数据越离散,则包含的信息就越大,在确定权重的时候往往就越小。
熵值法确定权重步骤[10]如下:
(1)应用最大最小标准化方法对数据进行标准化操作。
(2)确定各指标的信息熵:
式中,n为数据量;pij=若Pij=0则=0。
(3)确定权重:
式中,m为指标数量。
2.3 博弈论组合赋权
博弈论的基本思想是在不同方法的权重之间寻求一致或妥协[11],即将层次分析法确定的主观权重W1=(w11,w12,…w1j)和熵值法确定的客观权重W2=(w21,w22,…w2j)与组合权重之间的偏差和最小。其实现步骤如下:
(1)W1和W2确定的组合权重W线性表达式为
W=λ1W1+λ2W2.
(2)寻求最优的λ1、λ2,使得偏差最小,目标函数为
min(‖W-W1‖+‖W-W2‖) =
min(‖λ1W1+λ2W2-W1‖+
‖λ1W1+λ2W2-W2‖).
(3)根据微积分原理,取得最小值的求导条件为
(4)对求得的系数λ1、λ2进行归一化处理。
(5)最优组合权重为
3 尾矿库风险等级综合评价
本文采用加权物元模型确定尾矿库对应的综合风险等级。
3.1 物元可拓模型、
物元可拓模型基于可拓学理论,将多指标决策问题转变为单指标决策,定量得出评价结果。前文中介绍的尾矿库风险评价指标记为评价因子cn(n=1,2,…,27),制定的尾矿库风险等级标准记为N,评价因子对应的数据记为xn(n=1,2,…,27)。物元可拓模型实现步骤[12]如下。
3.1.1 建立物元可拓模型指标
物元模型最重要的3个指标叫做经典域、节域和待评物元。
(1)经典域。经典域R0表示给定尾矿库风险评价等级Nj(j=1,2,3,4)时,xn对应于cn的取值范围:
式中,Nn表示尾矿库风险评价等级,m=1,2,3,4;cn表示评价指标;vij=(aij,bij)表示评价指标cn对应评价等级的取值区间,i、j=1,2,…,27。
(2)节域。对于4种尾矿库风险等级N,xn对应于cn的所有取值区间叫节域,尾矿库风险评价的节域Rp表示为
(3)待评物元。将待评尾矿库的R中N和xi分别用确定的等级和实际数据表示出来即得到尾矿库风险的待评物元,记作:
3.1.2 计算关联系数及关联度
待评物元Rk关于尾矿库风险等级Nm的综合关联度为
式中,是博弈论综合AHP和熵值法得出的权重(i=1,2,…,27);Kj(Nj)表示各评价指标关于等级j的关联度;Kj(vjk)表示各评价指标关于等级j的单指标关联度。
其中:
式中,b、a分别为评价指标区间的上下限。
3.2 尾矿库风险等级评价模型构建
依托matlab,编写尾矿库风险等级物元可拓评价模型代码,借助编程来快速实现尾矿库风险等级综合评价。
4 尾矿库风险等级预测
4.1 随机过采样
运用物元可拓模型得出的尾矿库等级比例存在严重不均衡的问题,直接送入分类模型中进行验证会出现总体分类准确率高但某类等级准确率严重偏低的问题,因此需要对分类结果进行均衡化处理后再送入分类模型中,本文使用随机过采样的方法进行处理,该算法将少数样本随机复制达到样本平衡[13]。
4.2 WOA算法
WOA算法是澳洲格里菲斯大学的教授Mitjalili等人通过观察澳洲座头鲸特殊的捕食活动于2016年提出的一种仿生启发式优化算法。相比于其他优化算法如PSO粒子群算法、GA遗传算法等,该算法具有计算步骤简单、原理简单、可调参数少的优点[14]。该算法实现步骤[15]如下:
(1)包围收缩。鲸鱼识别猎物位置并将其包围,数学模型为
式中,t为迭代次数;X*(t)为目前为止鲸鱼最有利位置;X(t)为当前鲸鱼位置;r1、r2取值范围为[0,1];a值从2到0线性递减。
(2)螺旋更新。座头鲸根据猎物位置螺旋式更新位置,数学表达式为
式中,b为决定螺旋形状的常数;l∈[-1,1]。
(3)随机搜索。当|A|>1时,鲸鱼根据同类位置随机搜索,表达式为
式中,Xrand(t)为随机选取的同类位置。
4.3 BWOA算法
WOA算法同PSO粒子群优化算法、GA遗传算法一样具有局部收敛、收敛速度慢等缺点[16],因此本研究采用混沌映射初始化种群和自适应调整搜索策略的方法对其进行优化,将优化后的算法记为BWOA算法。
(1)混沌初始化策略。传统算法使用随机方法初始化种群,不同映射方法使得种群空间分布不同,将直接影响算法性能。混沌映射具有遍历性、周期性和初值敏感性等特点[17],作为随机数生成器对优化算法进行改进,在随机数生成方面具有很好的结果。本研究采用Chebyshev映射初始化种群,其迭代公式如下:
xk+1=cos(acos-1(xk)),
式中,a为Chebyshev的分形参数,a∈[0,5]。
(2)自适应调整搜索策略。为防止算法出现局部最优的问题,在搜索阶段,根据概率阈值Q调整变量值[18],数学表达式为
式中,t表示迭代次数;tmax为最大迭代次数。任取q∈[0,1],当q<Q时,随机变量Xj按上式更新,否则采用螺旋式更新。随着不断迭代更新,Q值减小,迭代次数自适应调整搜索策略,实现全局优化,表达式为
Xj=Xjmin+r(Xjmax-Xjmin),
式中,r∈[0,1];Xjmin、Xjmax分别为变量Xj的最小值和最大值。
4.4 SVM算法
SVM模型是一种基于统计学习理论的机器学习算法,在处理小样本、高维度的数据上有着独特优势。实现步骤[19]为:
(1)将原始数据通过核函数映射到高维空间,本研究采用rbf核函数,数学表达式为
(2)在高维空间构造最优分类超平面,通过对惩罚因子C和核参数λ寻优,使得分类间隔最大,分类效果最好,SVM目标函数和约束条件为
式中,i=1,2,…,l;w为权重向量;ξi为松弛变量;xi为训练集样本;yi为分类标签;w(xi)为核函数。
4.5 矿库风险等级预测模型构建
尾矿库风险等级预测模型BWOA-SVM算法主要步骤如下:
(1)利用随机过采样算法对物元可拓模型得出的尾矿库综合等级进行均衡化处理。
(2)初始化BWOA算法参数,迭代得出最优的惩罚因子C和核参数σ。
(3)将得出的最优参数和均衡化处理后的归一化数据送入SVM尾矿库分类模型中进行训练。
(4)给出算法模型准确率、召回率、F1(F1分数)、AUC(ROC曲线下面积)等性能参数。
5 实例验证
5.1 模型训练数据来源
尾矿库评价指标一般大都选取浸润线、坝体位移、干滩长度等监测指标,极少考虑管理因素,尾矿库风险评价指标体系不全面。采用机器学习方法对尾矿库进行风险评价需要足量的数据去训练模型,而且监测数据存在获取成本较高和测量设备测量局限等问题。总体来说,尾矿库数据获取困难、不全面、数据后续处理复杂,因此借助随机数据生成模拟法可以解决该类问题。随机函数RAND()采用线性同余法生成伪随机数,数据获取容易,数据量可人为选定,因此我们借助RAND()函数生成伪随机数替代实测数据验证模型效果。
根据划定的取值范围,采用随机模拟技术生成数据[20],本研究将数据量设定为300条。
据不完全统计,2008年我国12 655座尾矿库中,正常库7 745座,病库3 032座,险库1 265座,危库613座[21],即Ⅰ级库占比61.2%,Ⅱ级库占比24%,Ⅲ级库占比10%,Ⅳ级库占比4.8%。利用随机模拟法生成尾矿库风险评价数据时按照上述比例采用加权RAND()生成模拟数据用于模型训练。
设第j个评价指标的第k个风险等级的取值下限和上限分别为ajk和bjk,保留m位小数,则数据样本的随机模拟公式为
式中,j取值范围为[1,27];k取值范围为[1,4];i表示数据容量,i取值范围为[1,300]。
选取的评价指标中有些属于定性指标,无法使用随机模拟技术生成具体的数据,因此要将选取的定性指标转化为定量指标。Ⅰ级取值区间为[7.5,10],Ⅱ级为[5,7.5],Ⅲ级为[2.5,5],Ⅳ级为 [0,2.5]。则定性指标的随机模拟公式为
5.2 模型训练结果
根据构建的指标体系,首先采用RAND()函数生成300条伪随机数据,运用博弈论将层次分析法和熵值法组合得到指标权重,见表2。将生成的数据进行加权后利用构建的物元可拓模型得出风险等级,将风险等级和生成的伪随机数据组合输入BWOA-SVM模型中,利用BWOA算法得出C最优值为12.220 9,σ最优值为0.157 6,将最优取值输入SVM中得出算法各评价指标的取值,与C、σ取默认值时的SVM算法分类性能进行比较,结果见表3。通过比较,BWOA优化的SVM算法在所有指标上效果均优于SVM算法,预测结果准确率提升了44.9%。同时计算出2种模型分别在尾矿库4个等级上分类的准确率和ROC曲线,见图3、图4和图5,可以得出BWOA-SVM算法在每个等级上分类的效果同样也优于SVM算法。
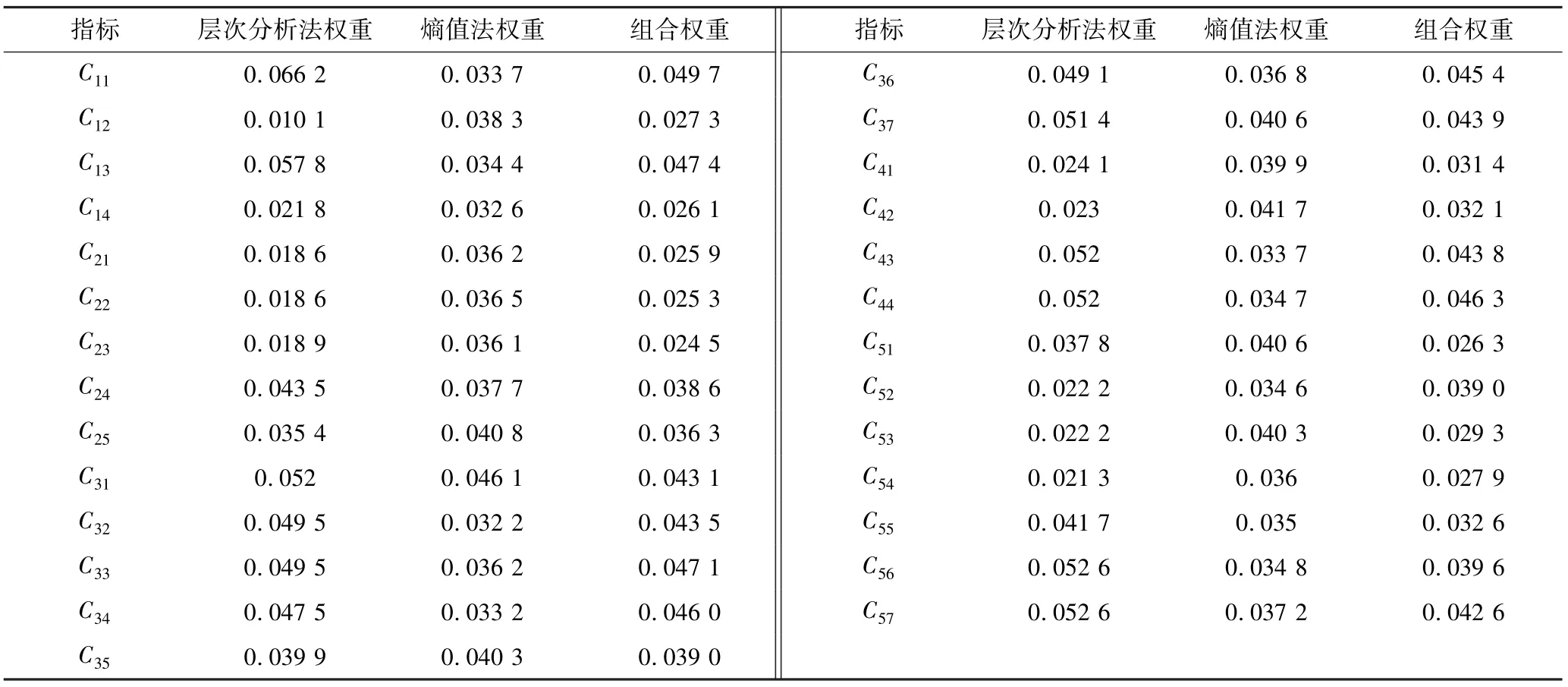
表2 尾矿库指标权重Table 2 Weights of tailings pond index
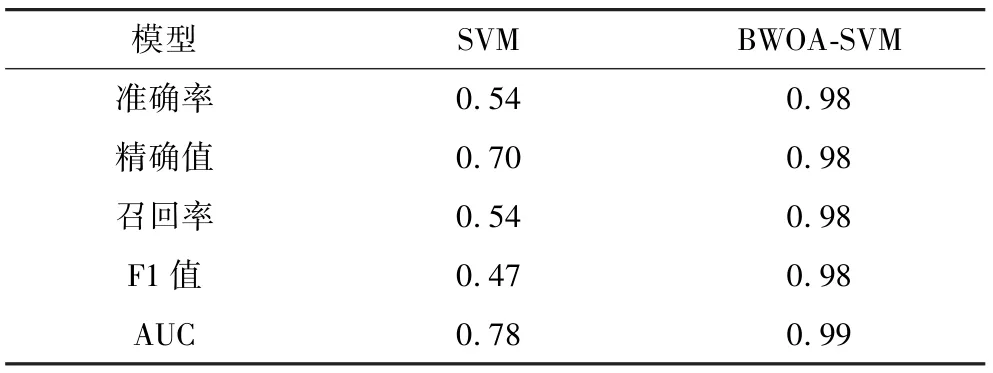
表3 算法评价指标Table 3 Algorithm performance index

图3 BWOA-SVM与SVM算法预测正确个数和准确率比较图Fig.3 Comparison of the correct number and accuracy of BWOA-SVM and SVM algorithms

图4 SVM算法ROC曲线Fig.4 ROC curves of SVM algorithm

图5 BWOA-SVM算法ROC曲线Fig.5 ROC curves of BWOA-SVM algorithm
5.3 实例验证
山西宏伟矿业有限公司泽水沟东沟尾矿库位于灵丘县城北15 km处,以东沟尾矿库为例验证所提方法的可行性。该尾矿库安全超高约0.943 m,24小时降雨量小于50 mm,排洪设施未出现裂缝和磨损,防洪标准500 a一遇,平均粒径0.074 mm达到85%,下游坡比为1∶3,地形坡度16°,浸润线在0.85~6.8 m,渗透坡降介于0.1~0.138 m,干滩长度约100 m,排渗设施完好,堆积密度1.4 t/m3,抗震能力7级,坝体未发现裂缝、变形,全员配备较简单的个人防护装备,有应急预案,应急准备、应急保障基本满足尾矿库重大险情保障,安全投入资金有限,培训率100%,技术考核达标率>80%,建立了较为健全的安全管理机构,各级岗位责任较明确,制度和规程健全,安全记录资料较齐全,有隐蔽性工程档案、安全检查档案和隐患排查治理档案,有监测设施,但不全面,缺少水位监测设施,每3年开展一次安全评价工作[22]。将这些数据代入训练好的BWOA-SVM模型中,输出该尾矿库等级为Ⅱ级(病库),该尾矿库属于带病运行的尾矿库,与实际情况相符。
6 结 论
(1)本文建立的风险评价指标体系既考虑了浸润线、坝体位移、干滩长度等监测指标,又考虑了非监测类的管理类指标,同时给出了各指标风险分级评价的标准。
(2)采用机器学习方法需要大量数据构建模型,以随机模拟法生成数值用于模型训练解决了尾矿库评价数据难以获取、样本量少的问题。
(3)采用博弈论法将层次分析法和熵值法结合起来确定指标权重,既考虑了评价指标间关系对权重的影响也考虑了数据量本身的影响,使权重确定更加科学合理。
(4)以我国尾矿库中正常库、病库、险库、危库实际比例为依据,采用加权RAND()函数生成数据,比按照均分的方式生成的实验数据更加贴近实际和准确。
(5)采用物元可拓模型确定风险等级,利用BWOA算法优化SVM对风险等级进行预测,克服了传统SVM预测精度低、容易过拟合的问题,预测准确率、精确值、召回率、F1、AUC分别为0.98、0.98、0.98、0.98、0.99,总体的准确率提升了44.9%,4个等级上的分类效果同时优于SVM算法,模型可以应用到尾矿库风险评价中,为企业和安监部门监管提供科学依据。
