基于改进SE-Net网络与多注意力的脑肿瘤分类方法
2024-01-06张晓倩金芊芊
张晓倩,罗 建,杨 梅,金芊芊,朱 熹
(西华师范大学 电子信息工程学院,四川 南充 637009)
脑肿瘤,也指颅内肿瘤,包括垂体瘤、脑膜瘤和胶质瘤,是常见且致命的肿瘤之一。如果能尽快确定脑肿瘤的类型,及时确定治疗方案,那么脑肿瘤患者的生存率将明显提高。通常,手工筛选肿瘤图像来预测脑肿瘤的类别非常耗时,而利用脑肿瘤辅助诊断系统,将深度学习与医学图像相结合,可以在一定程度上帮助医生解决这一问题。脑肿瘤辅助诊断系统是在大量脑肿瘤图像数据的基础上,结合以往的诊断结果、医生的个人经验以及患者的既往病史,帮助医生快速得出诊断结论。
近年来,卷积神经网络已经成为图像处理中最流行的方法。HE等[1]提出了一种残差学习框架来训练深度网络,并在ILSVRC2015图像分类任务中取得了最好的效果。它摒弃了以往简单叠加卷积层的方法,在网络上增加跳跃连接,并将浅层特征信息带到网络的深层,很大程度上解决了网络梯度消失或梯度爆炸的问题,但残差网络没有对关键信息进行聚焦。Abiwinanda等[2]提出了一种不同的CNN结构,通过在卷积层、最大池化层和flatten层的每一层后都添加全连接层,可对脑膜瘤、胶质瘤和垂体瘤实现准确分类,但是CNN结构对信息的提取有限,并且当网络层数太深时,采用反向传播调整内部参数会使靠近输入层的参数改动较慢。Kumar等[3]提出了一种将ResNet50与全局平均池化相结合的方式来解决在深度网络中存在的梯度消失和过拟合的问题,该方法的平均准确率高达97.48%,能对脑膜瘤、胶质瘤和垂体瘤进行高质量分类,虽然此方法利用全局平均池化避免过拟合,但是没有关注目标信息,存在一定的信息丢失情况。夏景明等[4]提出MDM-ResNet网络框架,利用双通道池化层、深度残差结构、多尺寸卷积核对脑膜瘤、胶质瘤和垂体瘤进行有效分类,但没有对有效信息给予关注,使得网络对信息学习的不够充分。
由于深度网络容易出现信息丢失,因此可以利用残差结构给网络深层带来浅层特征来解决这一问题。针对上述情况,本文将从以下几个方面展开研究:(1)利用Swish激活函数同时代替批归一化和特征融合后的ReLU激活函数,与ReLU激活函数相比,Swish并没有屏蔽过多的特征,这可以使模型更好地学习有效特征,对脑肿瘤图像进行有效分类;(2)在第一层卷积、批归一化和Swish激活函数后插入ECA注意力,提取通道特征信息,弥补深层网络存在信息丢失的情况,能使得模型更好地学习到有效信息;(3)在第二层卷积、批归一化和Swish激活函数后插入BAM注意力,用Swish激活函数代替ReLU激活函数,在通道和空间上并发的提取特征信息,使特征信息得到充分利用;(4)SE注意力模块中加入全局最大池化,将全局平均池化和全局最大池化相结合,使提取的高维信息互补,更有利于特征提取。
本文基于改进的SE-Net网络,利用多注意力机制提取特征信息,在空间和通道上获取有效特征,在分类上取得了较好的效果。
1 方法描述
1.1 网络模型
SE-Net(Squeeze-and-Excitation Networks)是由自动驾驶公司Momenta的高级工程师胡杰提出的一种基于加权特征图思想的网络结构[5]。它可以在Inception结构或残差网络ResNet中嵌入SE注意力模块。SE注意力模块主要对特征通道间的相关性进行建模,促使网络能对有效特征聚焦,能更好的提取目标特征,以提高模型的表达能力。简而言之,是通过对重要特征信息进行强化来提升准确率。
本文基于SE-Net的思想,在残差网络ResNet中嵌入SE注意力模块。本文的网络模型如图1所示:首先,在批归一化后,用Swish激活函数代替ReLU激活函数。与ReLU激活函数相比,Swish并没有屏蔽过多的特征,这可以使模型更好地学习有效特征。其次,在特征融合后用Swish激活函数代替ReLU激活函数,Swish激活函数处处可导且连续光滑,与ReLU激活函数相比,可以显著提高模型的表达能力。此外,在全局最大池化后的第一个卷积层(包括卷积、批归一化和Swish激活函数)后,增加ECA注意力模块,将其在通道特征中聚焦,以最大限度地提取通道信息;然后,在第二层卷积层之后加入改进的BAM注意力机制,让其在空间和通道2个方向并发进行特征提取,使目标特征发挥极致作用。通过试验发现,通道特征更有利于信息提取,可以提高模型的准确率。因此,采用改进的SE注意机制可获取更多通道信息,提高模型的表达能力。

在输入特征图后,模型将执行3个步骤。首先,通过步骤1对特征图进行数据预处理,包括卷积、批归一化、Swish激活函数和全局最大池化;然后,对处理后的图像分别进行保留操作和步骤2操作,包括4个子步骤,分别为卷积和批归一化以及Swish激活函数、ECA注意力模块、BAM注意力模型和SE注意力模块,将步骤2循环处理多次。若保留数据和输出数据的尺寸不相同,则对保留数据再添加一次卷积操作;若两者数据尺寸相同,则直接进行融合处理。最后通过步骤3进行全局平均池化和全连接层后输出。
1.2 Swish激活函数
深度网络中激活函数的选择对模型的性能有显著影响。校正线性单元(ReLU)是应用最广泛的激活函数,Swish激活函数在深度网络中往往表现优秀。Swish激活函数又称自门控激活函数,是谷歌在2017年提出的[6]。经验证,在同等情况下,Swish激活函数比ReLU激活函数更能提高模型的精准度。
Swish激活函数的表达式如式(1)所示:
Swish(X)=X·sigmoid(βX),
(1)
式中:β可以是常数也可以是通过训练得到的参数。当β→∞,Swish激活函数即为ReLU激活函数,当β=0时,Swish激活函数则变成线性函数。因此,Swish激活函数则可看作是两者之间的平滑激活函数[7]。当X>0时,不存在梯度消失的情况,当X<0时,神经元不会像ReLU激活函数那样死亡。同时与ReLU激活函数相比,Swish激活函数的导数不是一成不变的,而且Swish激活函数处处可导,连续光滑。
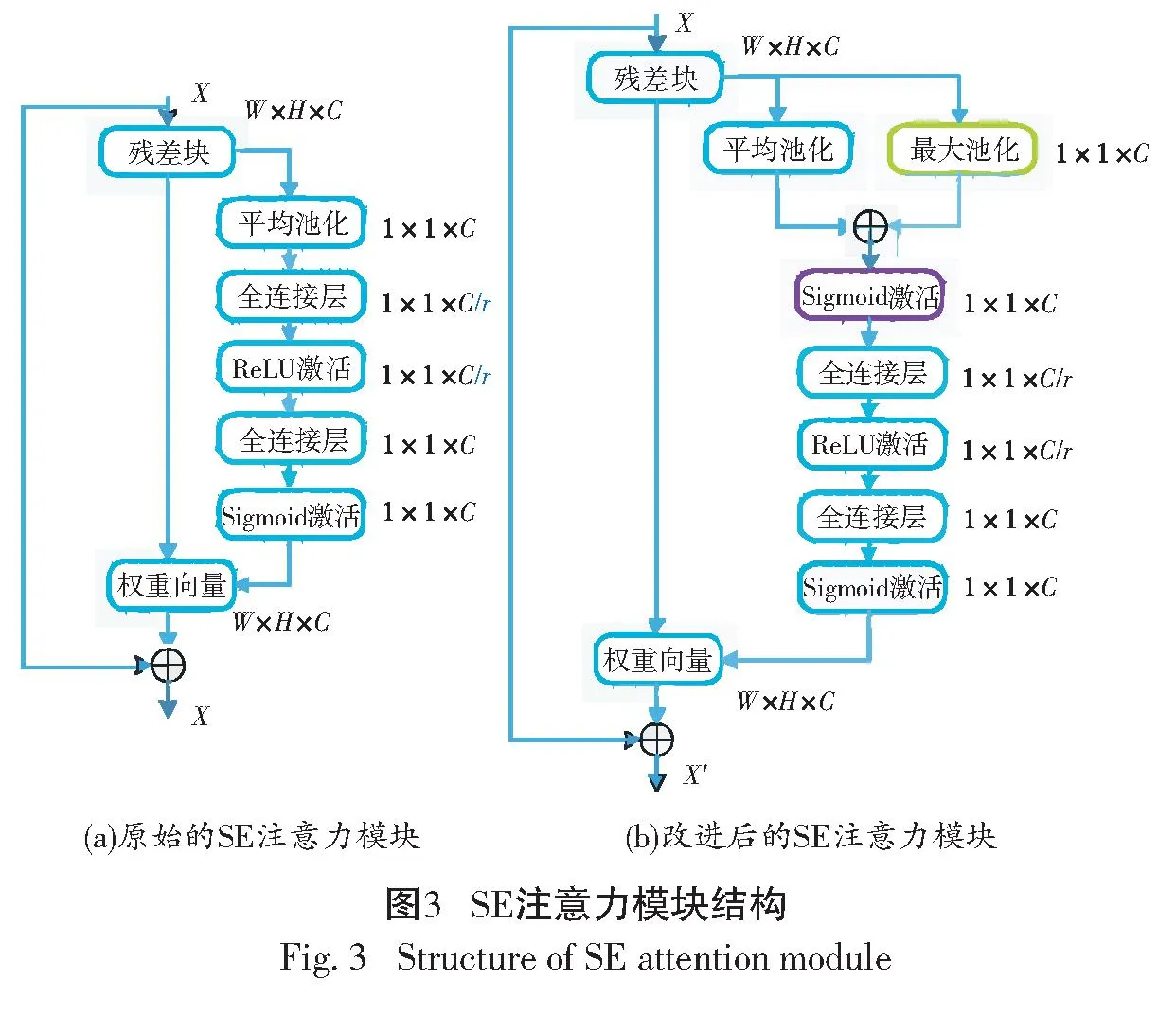
1.3 SE注意力模块
1.3.1 双通道池化层
平均池化更突出背景信息,用于将图片中激活的平均值作为最终输出。最大池化更突出纹理信息,用于将图片中激活的最大值作为最终输出[8]。本文在SE注意力模块中将平均池化与最大池化相结合,采用双通道池化层的方式,主要步骤如下:将X分别传入最大池化和平均池化两个路径后使用Add函数将两部分的结果合并,最后使用Sigmoid激活函数来捕捉非线性因素,然后输出X′进入下一步操作。双通道池化层结构如图2所示。

1.3.2 改进的SE注意力模块
图3(a)为原始的SE注意力模块[9],主要由压缩Squeeze和激励Excitation组成。改进后的SE注意力模块如图3(b)所示,主要步骤如下:首先是Squeeze操作,先将W×H×C的特征图通过双通道池化层,可得到1×1×C的全局信息描述符。再经过Excitation操作,由两次全连接层来预测通道间的重要性。先通过第一个全连接层来缩放,输入与输出分别为1×1×C和1×1×C/r,其中r为缩放参数;再通过第二个全连接来还原,输入与输出分别为1×1×C/r和1×1×C。之后利用Sigmoid输出特征图中各层权值的向量。最后是Scale操作,将输出的权值向量与特征图相乘,获得有权值信息的特征图。这一步骤聚焦有效特征,避免无效特征,更好地提取目标特征,在一定程度上提高模型的精准度。
1.4 ECA注意力模块
ECA注意力模型是Wang等[10]在2020年提出的一种高效的通道注意力,它主要是通过获取通道间的关系来提高目标特征的表达能力[11]。相对于传统的注意力方法,它可能解决降维对模型预测带来的副作用。本文采用ECA注意力模块增强卷积层后通道间的相关性,便于有效特征的提取。
图4是ECA注意力模块的结构,在同等条件下,特征图X先通过全局平均池化,再利用权重共享的一维卷积进行学习。在此期间将考虑通道间的相关性来获取跨通道交互,可以明显降低模型的复杂度。随后将通过Sigmoid激活函数。最后将激活函数输出的信息与特征图X相乘后输出X′。公式(2)是ECA自适应选择一维卷积核大小的方法,

(2)
式中:k代表一维卷积核大小,γ=2,b=1,C为通道数,通过此公式,可以确定局部跨通道交互的覆盖范围,即确定k的取值。
1.5 BAM注意力模块
BAM主要由通道和空间注意力模块组成,是2018年提出的注意力模块[12]。它可以与任何前馈卷积神经网络集成,提取有效特征信息。BAM注意力模块的结构如图5所示。特征图F的尺寸是C×H×W,依次表示为特征图的通道数、高度和宽度。经过BAM注意力模块后,输出特征图M(F),尺寸大小为C×H×W,最终输出的特征图F′为

F′=F⊗M(F),
(3)
式中:⊗指2个向量对应相乘,M(F)指通道与空间注意力模块融合后的特征图,M(F)为
M(F)=σ(MC(F)+MS(F)),
(4)
式中:σ表示Sigmoid激活函数,MC(F)表示通道注意力后的输出特征,MS(F)表示空间注意力后的输出特征[13]。为了更有效地提取特征,本文用Swish激活函数代替通道和空间注意力中的ReLU激活函数,在同等条件下可以提高模型的准确率。
通道注意力模块的主要步骤如下:首先对特征图进行全局平均池化,再通过MLP方法获得通道间的相关性,最后通过全连接层输出特征图。
空间注意力模块的主要步骤如下:首先将特征图进行卷积,卷积核大小为1×1,然后分别进行空洞卷积(卷积核大小为3×3)和普通卷积(卷积核大小为1×1),最后输出特征图。
通过式(3)和(4)输出最后的注意力特征图,对重要的特征信息分配更多的注意力,提高模型的精确率。
2 试 验
2.1 数据集
本文所使用的数据集来自于Kaggle的公开脑肿瘤数据集[14],通常用于分类。此数据集包含4类肿瘤图像:胶质瘤、脑膜瘤、垂体瘤和无肿瘤。数据集一共有来自7 678张脑图像,其中胶质瘤1 796例,脑膜瘤1 784例,垂体瘤1 936例以及正常脑图像2 162例。在本次肿瘤分类任务中,由于数据集图像统一并且分布均衡,对训练数据集进行随机裁剪图像大小为224、随机水平翻转以及归一化操作;对于验证和测试数据集,将原图片中短边尺寸统一缩放到256、裁剪图像大小为224和归一化操作。将数据集划分为训练集(5 712张)、验证集(655张)、测试集(1 311张)。在训练集中包含胶质瘤1 321例、脑膜瘤1 339例、垂体瘤1 457例以及无肿瘤1 595例;在验证集中包含胶质瘤175例、脑膜瘤139例、垂体瘤179例以及无肿瘤162例;在测试集中包含胶质瘤300例、脑膜瘤306例、垂体瘤300例以及无肿瘤405例。
2.2 试验参数
本文试验的硬件环境:CPU为Intel(R) Xeon(R) Gold 6148 CPU @ 2.40 GHz,1个CPU,内存为100 G,GPU为Tesla V100,显卡16 G。软件环境:python 3.7,PaddlePaddle 2.2.2深度学习框架。
在训练模型的过程中,学习率采用Piecewise策略,初始学习率设置为0.1,最终学习率为0.01,迭代批量设置为64,训练次数Iteration为4 500。用Momentum优化器进行优化,动量设置为0.9。
2.3 评估指标
图像分类的常用评价指标包括准确率、精确率、召回率和F1值,准确率指所有样本中被模型预测为正确的比例;精确率则是指正确被模型预测为正的,占模型全部预测为正的比例;召回率可以理解为正确被模型预测为正的,占样本中所有实际为正的比例;F1值被定义为精确率和召回率的调和平均数。F1值受精确率和召回率的影响,精确率越高,召回率越高,F1值越高。公式如下:

(5)
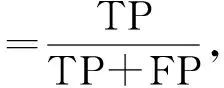
(6)

(7)
(8)
式中:TP指预测为正确(实际为正确)的正样本个数,FP指预测为正确(实际是错误)的负样本个数,FN指预测为错误(实际是正确)的正样本个数,TN指预测为错误(实际是错误)的负样本个数。本文使用宏平均计算准确率、精确率、召回率和F1值。
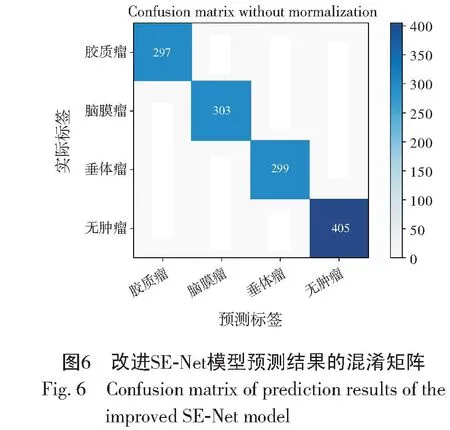
模型训练完成后,使用测试数据集对本文中改进的SE-Net模型进行评估,生成的混淆矩阵如图6所示。改进的SE-Net模型在脑肿瘤图像的分类任务中具有较好的准确率,出现错误分类的个体较少,能对脑肿瘤进行精准分类。模型的错误分类图像如图7所示,(a1)—(d1)是模型预测结果,(a2)—(d2)是图像的真实标签。可以看出(a2)垂体瘤图像诊断为脑膜瘤,存在的问题可能是病灶区域较小,模型对于较小的肿瘤敏感度较低;(b2)脑膜瘤图像诊断为胶质瘤,存在的问题可能是大多数胶质瘤生长于在脑内,即不靠近颅底,脑膜瘤是个相对规则和规整的球形形态,常常位于颅板内侧颅底,但在这张图像中,肿瘤区域位于脑内但真实标签是脑膜瘤,属于特殊情况,模型对于这一类特殊情况还不具备分辨能力。(c2)和(d2),都是将胶质瘤图像诊断为脑膜瘤,通过图像可以看出肿瘤区域较小且脑膜瘤和胶质瘤有一定的相似性,所以模型出现了判断错误。
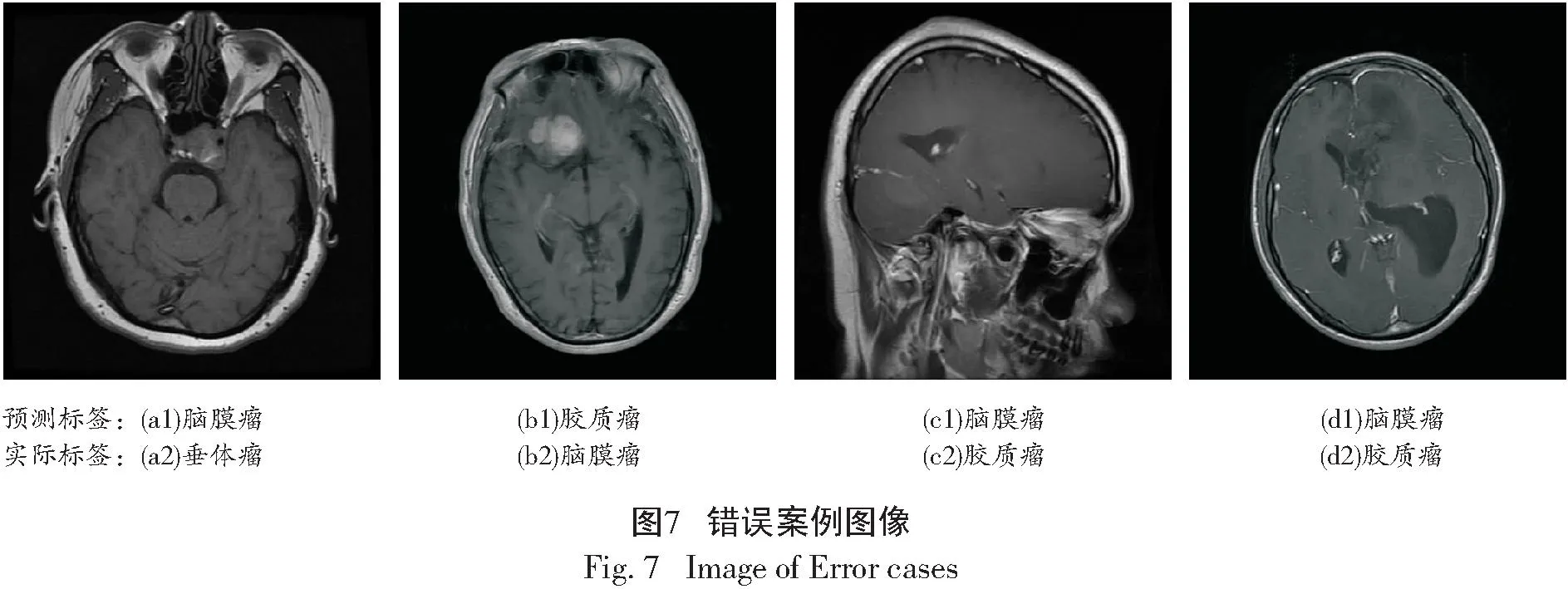
通过对错误分类的个体图像分析,可以得出由于肿瘤区域较小且胶质瘤和脑膜瘤有一定的相似性,模型对于两者的区分出现少部分的错误,但对于诊断为脑肿瘤这一结果是没有问题的,对于具体的肿瘤类型还需借助肿瘤专家的帮助,但总体来说改进的模型对脑肿瘤可以实现精准分类,能大大缩短诊断时间,证明了模型的有效性。
2.4 网络整体性能
本文模型在训练时,损失函数值的变化如图8所示:当迭代次数增大,网络的损失值慢慢减小,在迭代次数接近4 500次左右,网络的损失值开始收敛,并且趋于稳定。由于保存loss值时,每隔10次迭代保存1次损失值,即一共有450次迭代数据。

2.5 消融试验
为了验证改进的模块对网络模型的有效性,进行了消融试验。所有试验在相同的环境下进行,消融试验结果如表1 所示。首先在SE-Net的基础上,在特征融合和批规范化后使用Swish激活函数替换原有的ReLU激活函数,在深层网络中,效果优于ReLU激活函数的同时也不会出现神经元死亡的情况,使得模型能更好地学习;随后在SE注意力模块中添加全局最大池化来突出目标特征,通过全局平均池化和全局最大池化相结合的方式,使提取的高维信息互补,更有利于通道特征信息的提取。为了进一步的提取更多地特征信息,加入ECA和BAM注意力模块,在通道和空间两个方面都再一次进行目标特征提取,使得目标信息能充分利用,最终能准确地对肿瘤实现分类。
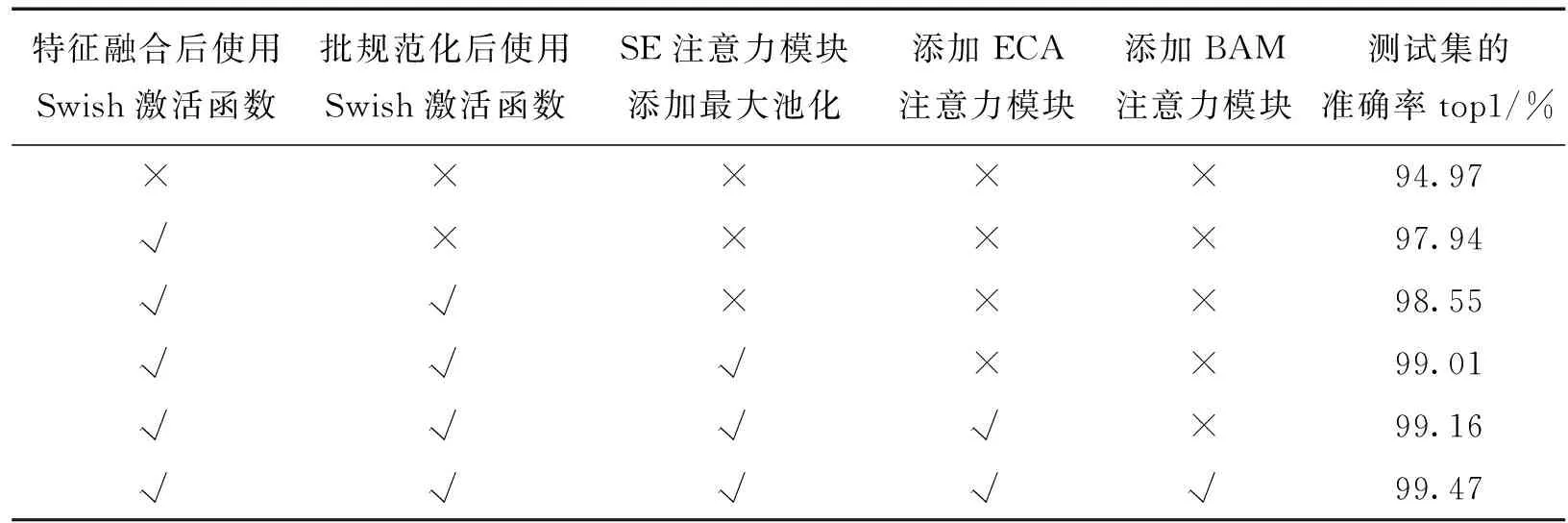
表1 SE-ResNet-50消融试验对比结果Table 1 Comparison results of ablation experiments for SE-ResNet-50
在消融试验中,验证了更改激活函数,添加最大池化、ECA和BAM注意力模块的性能。其中影响最大的是在特征融合后使用Swish激活函数,在深度网络中其表现良好,优于ReLU激活函数,对模型的准确率有一定的提高。
表1消融试验对比结果可见,改进后的模型的准确率可达到99.47%,在同时更换Swish激活函数、添加最大池化、ECA注意力以及BAM注意力后,对表1中测试集的准确率top1值进行比较,最终结果较原模型增加了4.50%,充分验证了改进后模型的可行性。
2.6 与其他方法对比
为了验证本文改进的SE-Net模型的有效性,将其与目前先进的算法进行对比。由于大多数的分类模型是基于ResNet和DenseNet改进的,所以本文将ResNet和DenseNet优秀的变体进行对比,试验对比结果如表2:在同等试验环境下,采用Kaggle的公开数据集进行训练与测试,在准确率、精确率、召回率和F1值中都取得了最优的结果。由此可见,本文提出的改进SE-Net模型在脑肿瘤分类中表现优秀,能大幅度的提升模型的性能。
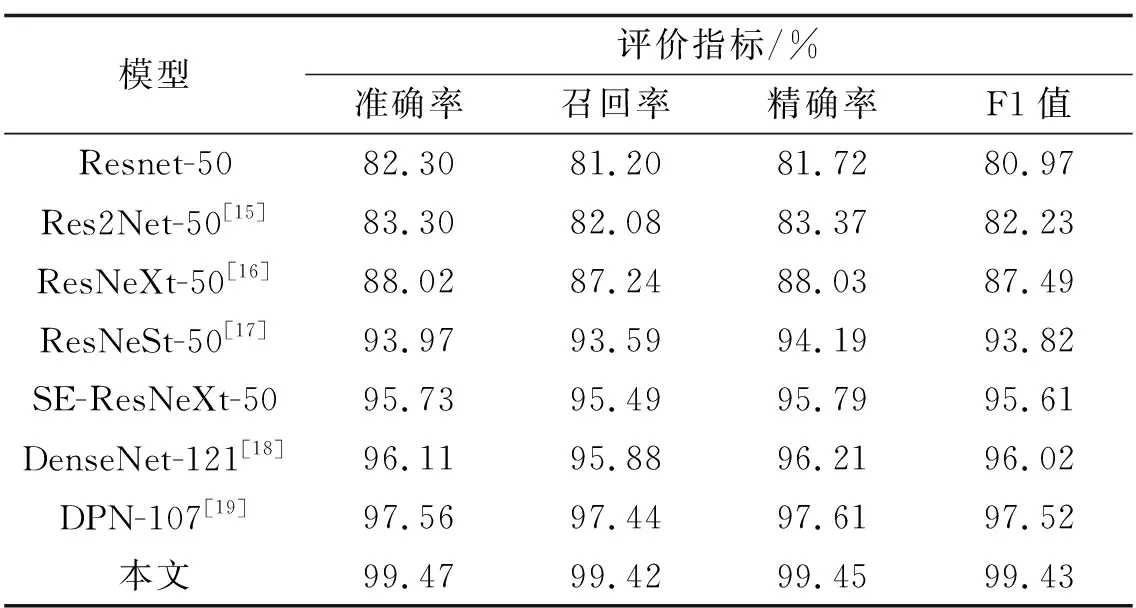
表2 模型对比结果Table 2 Comparison results of models
2.7 可视化分析
为了更好地对模型的注意力模块进行解释,本文使用梯度加权类激活映射(Gradient-Weighted Class Activation Mapping,Grad-CAM)方法[20]生成了热图,用于可视化分析模型在判别脑肿瘤类别时所依据的病灶区域。如图9所示,本文分别将4个类别的脑肿瘤图像进行可视化分析,从左到右图像的类别分别为垂体瘤、脑膜瘤、胶质瘤以及无肿瘤。从上到下4组图像中,第一组图像是原始图像,第二组到第四组图像都是热图,暖色部位表示模型对该位置的关注度,关注度越高,模型学习到的特征越丰富。其中第二组图像是原始图像使用基础模型SE-ResNet-50生成的热图;第三组图像是在基础模型的基础上将ReLU激活函数更换为Swish激活函数、在SE注意力模块中添加最大池化以及添加ECA注意力模块后生成的热图;第四组图像是在第三组的基础上添加BAM注意力模型后生成的热图。
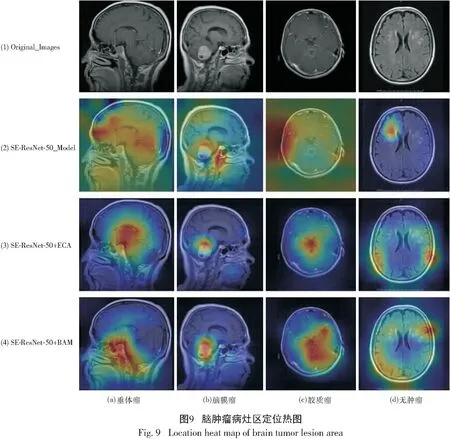
通过可视化结果,可以看到使用基础模型对4个类别的图像进行可视化时,模型对疾病位置和面积关注度准确度不高,如第二组图像SE-ResNet-50所示;当第二组模型的基础上添加ECA注意力,可以从图中看到模型更加聚焦病灶范围,这也使得模型避免学习病灶区周围无用特征,如第三组图像SE-ResNet-50+ECA所示;最后在第三组模型的基础上添加BAM注意力,从通道和空间两个部分捕捉特征信息,使得模型对病灶区域定位更加准确,如第四组图像SE-ResNet-50+BAM所示。通过可视化分析模型,也充分解释了模型中添加注意力模型的可行性,对模型的准确率的提高有着不可或缺的作用。
3 结 论
利用深度学习与医学图像相结合的方法来辅助临床医师减少脑肿瘤患者的死亡率有着至关重要的作用。本文基于多注意力提出一种改进的SE-Net网络﹐能够大幅度提高模型的准确率,高质量的对脑肿瘤实现分类。通过对1 311例数据进行测试,并和先进的ResNet变体进行试验对比﹐表明了提出的方法能够准确对肿瘤的类别分类﹐是省时和准确高的辅助诊断工具。
