基于用户行为分析的APP 用户知识图谱构建
2024-01-04周金泽
周金泽
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
0 引 言
智能手机和移动互联网的普及促进了APP 的蓬勃发展,APP已经成为人们生活不可或缺的一部分。然而,APP 市场竞争激烈,为了在激烈的市场中获得成功,开发者需要深入了解用户需求,优化APP 功能和用户体验。在这个背景下,APP用户知识图谱[1-2]应运而生。通过APP用户知识图谱有望帮助开发者更好地理解用户需求,提高APP的品质和用户满意度。本文旨在介绍这种方法的实现原理和应用效果,并探究其未来发展的潜力和前景。
1 相关工作
目前,已经有很多学者对知识图谱构建方法提出自己的构建算法。文献[3]在2018 年提出了一种名为“Event-Centric Temporal Knowledge Graph(EventKG)”的多语言时序知识图谱,该图谱以事件为中心。文献[4]提出了一种金融事件知识的语义表示方法,该方法可自动处理和分析金融事件的意义,以协助决策。
然而,这些研究在知识图谱构建的过程中并没有充分挖掘数据可用性与细化实体行为。因此,本文提出一种基于用户行为分析的APP 用户知识图谱构建方法,为APP 开发提供更加全面和有效的支持和保障。
2 基于用户行为分析的APP 用户关系构建
本文提出了一种基于用户行为分析[5-6]的用户构建方法。为了构建APP 用户知识图谱,首先要进行APP 用户行为分析;接着,根据APP 用户分析结果进行用户关系抽取;最后,根据用户关系属性抽取结果构建APP 用户知识图谱。整体算法的流程框图如图1 所示。
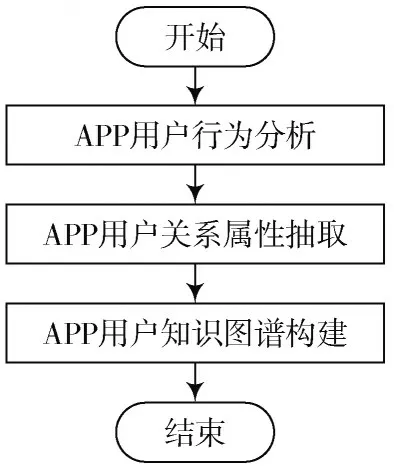
图1 整体流程框图
2.1 APP 用户行为分析
APP 用户行为[7-8]指的是用户在使用特定应用程序时所展现出来的行为或活动,这些行为可以被记录在APP 的日志中,并为APP 开发者或运营者提供有用的数据和见解。然而,本文提到的APP 用户行为并不涉及软件的用户操作[9],而是APP 用户在应用市场网站发生的各项行为。
定义1:APP 用户行为。本文提出的APP 用户行为指的是APP 用户在软件应用市场的用户行为,常见的APP 用户在软件应用市场的行为有:评论、点赞、推荐、下载等。
评论是用户最直观的一种行为表现,但本文还可以从用户评论内容、点赞、评价次数和下载的软件种类等数据中抽取更深层的、粒度更细的用户行为。通过分析大量评论数据,本文定义了四种细化的APP用户行为。
定义2:用户评价前后逻辑一致性。用户针对一款软件随着时间推移会进行多次的评价。对于一些APP用户,因为其没有实际使用过软件,所以不能真实地给出软件使用反馈,其评论内容就可能会出现前后矛盾的情况。
定义3:用户评价时间重合度。用户对软件会有多次的评价,一些用户往往通过程序进行集中的评论发表,相反,一些用户发表评论的时间就比较分散。
定义4:用户评价软件次数。针对APP 用户会出现对软件进行多次评价的情况,用户评价软件次数能很好地反映用户活跃度。
定义5:用户好评占比。用户针对每一款软件会给出自己的好评或者差评,所以,用户好评占比也能很好地体现用户之间的差异性。
2.2 APP 用户关系属性抽取
本文定义了4 种APP 用户行为,并用一个三元组来描述:例如(用户1,评价4 次,软件1)、(用户2,100%好评,软件2)、(用户2,前后评价不一致,软件2)。本文将用户行为映射为用户与软件之间的关系,并且用户与用户、软件与软件也可以通过某种关系属性相互关联。综上所述,本文定义了用户与用户、用户与软件、软件与软件之间的关系属性。
定义6:用户与软件关系属性。用户与软件之间的关系属性包括用户实体、软件实体和关系属性。其中,关系属性包括四种类型:首先,通过统计用户对软件的评论时间段的重合度来量化用户与软件之间的关系属性;其次,通过计算用户对软件的好评占总评价的比例来获得另一条关系属性;接着,考虑用户多条评论的观点倾向是否一致,若存在明显态度转变,则将其表示为{用户,评价前后逻辑一致性(一致/不一致),软件};最后,通过统计用户对软件的评价次数来得到另一条关系属性。
定义7:用户与用户关系属性。用户与用户的关系属性包含三个部分:用户实体1、用户实体2、关系属性。其中,关系属性为用户实体1 与用户实体2 的用户名的相似度,用三元组可以表示为(用户1,用户名相似,用户2)。
定义8:软件与软件关系属性。软件与软件的关系属性包含三个部分:软件实体1、软件实体2、关系属性。其中,关系属性为软件实体1 与软件实体2 之间是否为同一个类别的软件,用三元组可以表示为{软件1,(同类/不同类)软件,软件2}。
结合上述的用户与软件、用户与用户、软件与软件的关系属性定义,就可以对实体间关系属性进行抽取,如表1 所示。

表1 实体关系属性定义
基于上述关系属性的定义,对用户与用户、用户与软件、软件与软件之间的关系抽取提出下列关系属性抽取算法。
2.2.1 用户-软件(评价前后逻辑一致性)
在用户-软件关系中,评价的前后逻辑一致性对于构建用户关系至关重要。首先,可以计算一个用户表达的多个评价观点的情感倾向[10-11],并将所有情感倾向值放入一个集合中,如公式(1)所示:
式中ci代表每个观点的情感倾向值。随后,可以使用公式(2)计算该用户所有情感倾向值的平均值。
基于上述两个算法公式计算出来的Consistency 计算多个情感倾向值的标准差,当标准差小于等于时,将其量化为1(表示用户前后观点一致);当标准差大于时,将其量化为0(表示用户前后观点不一致),具体的抽取算法如算法1所示。
算法1:评价前后逻辑一致性关系抽取

上述算法通过情感分析[12-13]对用户评价观点进行量化。
2.2.2 用户-用户(用户名相似度)
在比较用户名之间的相似度时,简单的语义相似度并不能满足需求。因此,本文将用户名划分为三个类别进行比较,分别是中文名、英文名和无关字符。本文使用余弦相似度来衡量两个用户名之间的相似度。对于两个向量VA 和VB,余弦相似度可以使用式(3)来计算。
式中:“·”表示两个向量的点积;“‖ ⋅‖”表示向量的欧几里德范数。更高的余弦相似度值表示两个向量之间具有更高的相似度,该值的范围在-1~1 之间。为了统一量化区间,通过线性变换公式(4)将区间[-1, 1]映射到[0, 1]。
式中:Mapped 表示变换后的区间;Oringal 表示变换前的区间。通过对每个类别的相似度进行比较,本文能够更准确地判断用户名之间的相似程度。抽取算法如算法2 所示。
算法2:用户名相似度关系抽取

2.2.3 用户-软件(评价时间重合度)
一些APP 用户往往会选择在相对集中的时间段内进行评价,以增加其评论的影响力。相反,一些用户的评价时间分布较为分散。评价时间重合度的计算方法如公式(5)所示:
式中:min(ti2)代表所有评价时间间隔的最小结束时间;max(ti1)代表所有评价时间间隔的最大开始时间;和分别代表所有评价时间间隔的开始时间和结束时间的总和。
具体的抽取算法如算法3 所示。
中国科学院院士贾承造认为,推动我国天然气高质量发展首先需要加快天然气产供储销体系建设,以保证天然气安全平稳供应,满足人民日益增长的用气需求。
算法3:评价时间重合度关系抽取

2.2.4 其他关系属性
首先,针对用户与软件之间的好评占比这一关系属性,通过计算好评次数占总点评次数的占比,可以由公式(6)得到:
式中:P表示好评占比;Pi表示第i条评论的好评或者差评情况(好评为1,差评为0);n表示评论总数。
接着,软件与软件之间的软件间类别是否相似可以由计算语义相似度得到。
最后,用户与软件之间的用户评价软件次数通过统计累加得到。
2.3 APP 用户知识图谱构建
定义9:APP 用户知识图谱。APP 用户知识图谱是一种特殊类型的用户关系图,用于表示一个APP 软件应用市场中用户与用户、用户与软件、软件与软件之间的关系。由用户节点、软件节点和关系属性组成。用户节点表示APP 应用市场中的注册用户,每个用户节点包括用户IP、用户名两种信息。软件节点表示APP 软件本身,用APP 的名称来表示,每个软件节点包括软件名称与软件类别两种信息。关系属性包括用户与用户、用户与软件、软件与软件之间的关系属性类型和权重。
通过将APP 用户行为映射为用户关系属性,从而构建APP 用户关系图将多个用户关联起来。APP 用户知识图谱可以挖掘用户之间的共性和差异,为开发人员提供良好的用户反馈。
3 实验与分析
根据本文提出的APP 用户知识图谱构建方法,随机选择106 604 条APP 用户数据作为实验数据进行实体关系属性抽取。抽取的结果如表2~表5 所示。

表2 用户节点抽取结果
表2 展示了抽取出的部分用户节点信息,通过三个字段进行定位,分别是Id、Name、Label。
表3 展示了用户与软件之间的部分关系属性,通过StartId、Name、EndId、Type 字段定位APP 用户知识图谱中的一条边。
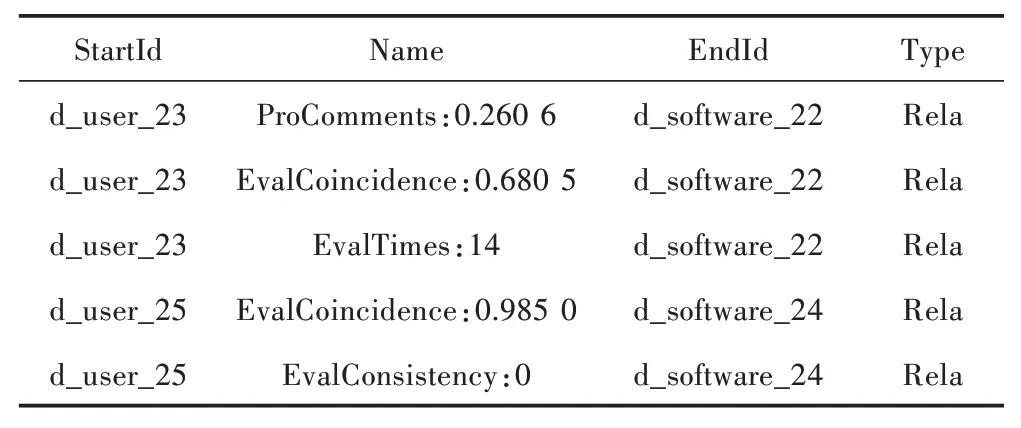
表3 用户与软件关系抽取结果
在表3 中,抽取了用户与软件之间的四种关系属性,分别是:评价前后逻辑一致性(EvalConsistency)、评价时间重合度(EvalCoincidence)、用户评价软件次数(EvalTimes)和好评占比(ProComments)。表4 展示了软件与软件之间的相似度关系属性,通过StartId、Name、EndId、Type 字段定位APP 用户知识图谱中的一条边。
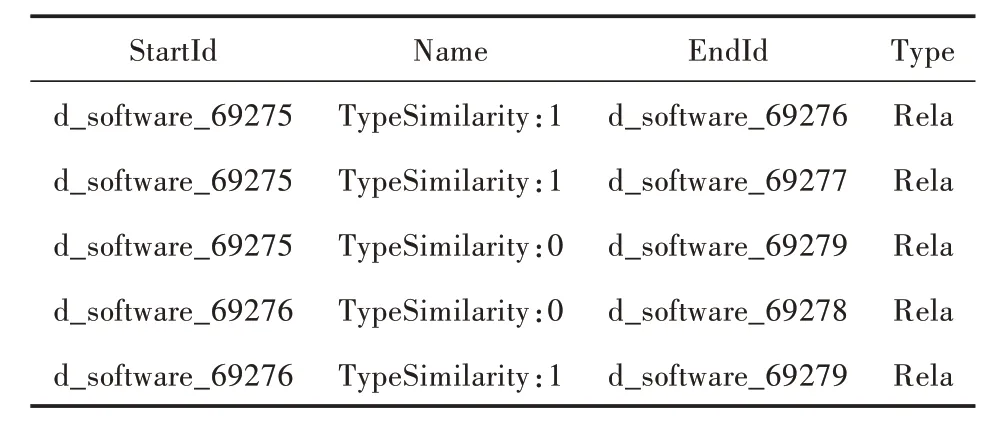
表4 软件与软件关系抽取结果
表5 展示了用户与用户之间的关系属性,通过StartId、Name、EndId、Type 定位APP 用户知识图谱中的一条边。
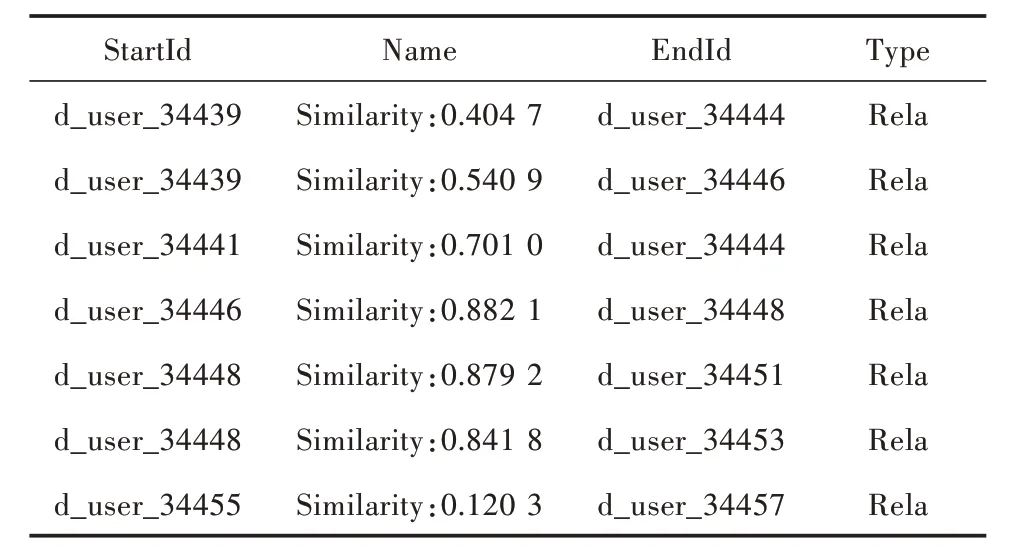
表5 用户与用户关系抽取结果
由表5 中可以发现,用户与用户之间的关系属性为用户名相似度(Similarity)。结合上述抽取结果可知,通过StartId 定位知识图谱的头节点,通过EndId 定位尾节点,通过Type 以及Name 定位边属性关系。
本文使用了106 604 条APP 用户数据构建APP 用户知识图谱,并将数据存储到了非关系型数据库Neo4j[14]中。本文共抽取出95 067 个节点(用户节点+软件节点)和456 965 条边关系属性,图2 对该APP 用户知识图谱进行了局部展示。
图2 APP 用户知识图谱
4 结 语
综上所述,本文提出了一种基于用户行为分析的APP 用户知识图谱构建方法,通过对用户行为的细化和关系属性的抽取,成功构建了一个信息更为丰富的APP用户知识图谱。这种方法有望帮助开发者更好地理解用户需求,优化APP 功能和体验,提高用户满意度。未来,将继续深入探究该方法的潜力和适用性,并进一步完善和优化APP 用户知识图谱的构建算法,为APP 开发和用户体验提供更加有力的支持和保障。
