基于知识嵌入式预训练语言模型的文本分类方法研究
2024-01-04张渊,姚峰
张 渊,姚 峰
武汉工程大学计算机科学与工程学院,湖北 武汉 430205
在文本分类任务上,预训练的语言表示模型已经取得了很好的成绩,例如,基于变换器的双向编码器表征(bidirectional encoder representations from transformers,BERT)模型通过简单的微调就能在文本分类任务上取得很好的结果[1]。但是这些预训练模型并不能很好地将知识信息纳入到语言理解当中。为了解决这一问题,Zhang 等[2]提出了一种信息实体增强语言表示(enhanced language representation with informative entities,ERNIE)模型,该模型使用由TransE 算法[3]预训练得到的实体嵌入作为其输入,并利用知识图谱中丰富的语义信息来增强文本表示。
然而,TransE 算法存在多个实体会在嵌入空间中竞争一个点的缺点,因此在处理一对多或者多对多的情况时效果并不理想。针对这个缺点,可以使用Wang 等[4]提出的知识嵌入和预训练语言表示(knowledge embedding and pre-trained language representation,KEPLER)模型作为知识嵌入模型来获取实体嵌入,该模型通过对知识图谱中的知识信息进行提取和编码,将每个实体与对应的语料库中的描述相对应,为每个实体获得其对应的文本描述信息,可以生成有效的包含丰富文本信息的知识嵌入,能够更好地将事实知识整合到预训练语言模型中。
为了提高自然语言处理中各任务的效果,研究人员开始关注文本中的语义信息,文字和图像最大的不同之处在于,文字中包含了词与词之间的逻辑,包含了人的思想等重要信息,而图像并没有这些复杂的语境信息[5]。举例来讲,“2009 年,胡歌演唱了电视剧《仙剑奇侠传3》的主题曲《忘记时间》”这句简单的文本就可以提炼成如图1 所示的包含语义信息的示例图。如果想要提取图中实体包含的知识信息,就要知道不同实体代表的意义,如果不知道《忘记时间》和《仙剑奇侠传3》分别是歌曲和电视剧,很难识别胡歌在实体任务中的两种职业,即歌手和演员。由此可见,丰富的语义信息能够让模型更好地理解文本,从而有利于文本分类任务。
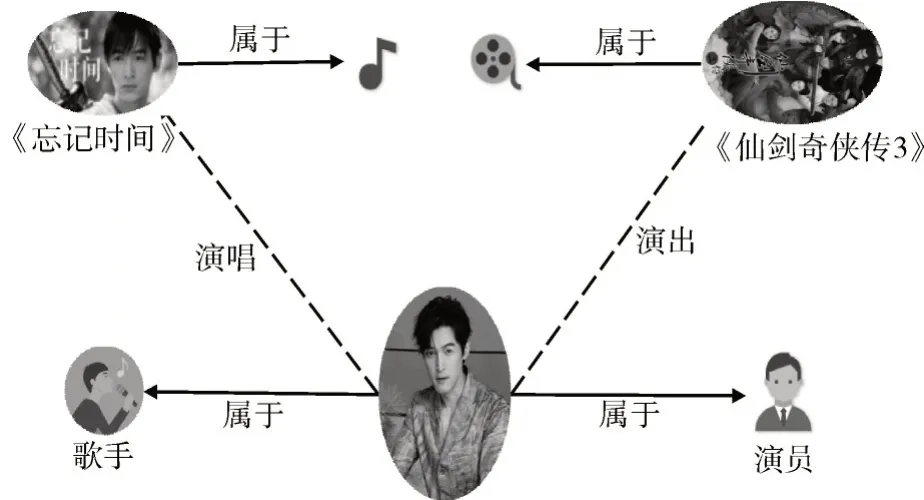
图1 包含语义信息的示例图Fig.1 Example of containing semantic information
早期获取文中的语义信息主要有2 种方法:基于特征和微调的方法。王珊珊等[6]提出一种基于特征的方法,通过训练神经网络从而得到词语的嵌入,将文本表示为低维的向量。但是基于特征的方法使用的是经过训练得到的词语嵌入,在具体的任务中使用已训练好的词向量作为词语的嵌入,不具普适性,只针对于具体任务才有好的效果,同时这种方法,在训练过程中捕获的句法和语义信息有限并且还会受到一词多义的影响。为了克服这一缺陷,叶水欢等[7]提出了一种序列级模型来捕获复杂单词特征即根据上下文来推断每个词对应的向量,但是其只能解决一部分的歧义性,同一个词有不同的上下文时,就会过度考虑上下文信息。与这种只使用经过训练后的语言表示作为特征嵌入的方式不同,基于微调的方法,会根据下游特定任务,在原来的模型上做出一些修改,使得最终的输出是当前任务需要的。例如,张民等[8]提出一种生成性预训练转换器来学习语言表征。杨兴锐等[9]提出了一种基于残差注意力BERT 词向量的文本分类模型,该模型在文本分类任务中取得了很大成功。虽然这些方法都取得了不错的成绩,但都没有考虑到利用知识信息。
所以,考虑到丰富的知识信息可以获得更好的语言理解,从而有益于文本分类任务,可以将外部知识纳入语言表示模型,同时为了顺利完成2 部分信息的融合,提出一种通过知识嵌入式预训练语言模型改进信息实体增强语言表示(ERNIEKEPLER)模型。而且为了更好的结合文本和知识特征,随机屏蔽输入文本中的一些命名实体,并从知识图谱中选择适当的实体来完成对齐是一种比较合适的解决办法。
1 模型结构
1.1 总体结构
综合考虑ERNIE 模型和KEPLER 模型的优点,构建了一种用于中文文本分类的ERNIEKEPLER 模 型,如 图2 所 示。ERNIE-KEPLER 模型的整体结构由3 个部分组成:①底层文本编码器,负责从输入令牌中捕获基本词汇和语法信息;②KEPLER 模型,负责提取知识图谱中包含的丰富的语义信息的实体;③上层知识编码器,负责将面向令牌的额外知识信息和文本信息进行结合。
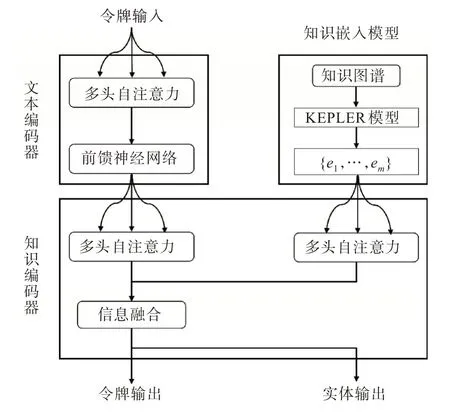
图2 ERNIE-KEPLER 模型结构图Fig.2 ERNIE-KEPLER model structure diagram
1.2 文本编码器
文本编码器对于给定的令牌序列,首先对每个令牌的令牌嵌入、分段嵌入、位置嵌入求和,用于计算其输入嵌入,然后计算词汇和句法特征{t1,…,tn},其中n为令牌序列的长度,tn表示第n个令牌。该部分的实现与BERT 模型相同,因此在后文不做过多介绍。
1.3 知识嵌入模型
通过KEPLER 模型获得的实体序列{e1,…,em}作为实体输入,其中m为实体序列的长度,em表示第m个实体。在KEPLER 模型中,使用实体对应的文本将实体编码为向量,而不是像传统知识嵌入模型那样为每一个实体、关系都分配一个d维向量。与此同时,使用实体描述作为嵌入的方法,并经过Transformer 架构[10]的编码器得到了序列每个位置的上下文表示,在保证简单有效的同时获得包含x个有效的头实体列表{H}和y个有效的尾实体列表{T},这些实体将组成实体列表{e1,…,em}以用作知识编码器中的实体嵌入。KEPLER 知识嵌入模型框架如图3 所示。
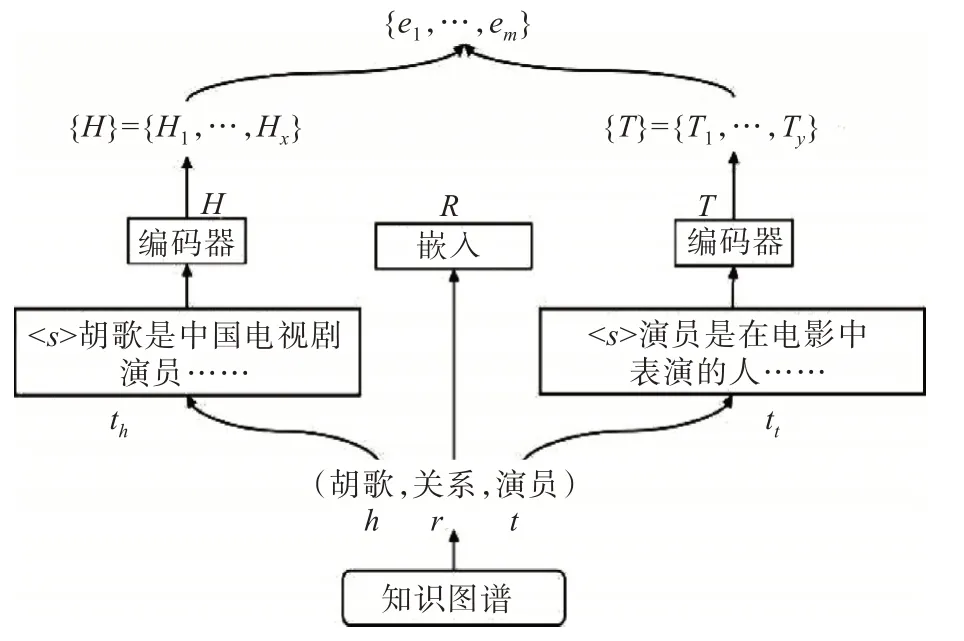
图3 KEPLER 模型框架Fig.3 KEPLER model framework
对于关系三元组(头实体,关系,尾实体),KEPLER模型通过公式(1)将实体描述作为嵌入,公式(1)表示如下:
其中th、tt是头实体h和尾实体t的描述,并使用字节对编码的标记方式[11]将其转化为标记序列,开头有一个特殊标记<s>,通过该标记,可以知晓标记后的句子就是对该实体的表示,同时将表示函数表示为E<s>(·)。Tr是关系嵌入,r表示头实体和尾实体之间的关系类型,H、T、R分别是h、t、r的嵌入。同时使用范文韬[12]提出的损失作为知识嵌入目标,采用负采样进行有效优化。
1.4 知识编码器
知识编码器的输入包括文本的特征向量和信息实体两部分。在文本编码器计算完特征向量后,ERNIE-KEPLER 模型采用知识编码器将知识信息注入语言表示。通过KEPLER 模型获得的实体序列{e1,…,em}表示实体嵌入,然后将令牌序列{t1, …,tn}和实体序列输送到知识编码器,用于合并异构信息并计算最终输出嵌入,该过程可以表示为:
其中K代表知识编码器,K(·)表示异构信息融合函数,令牌序列{t1,…,tn}和实体序列{e1,…,em}作为该函数的两个输入。{t0,1,…,t0,n},{e0,1,…,e0,m}是经训练后最终的输出,将用于文本分类任务中,{t0,n}和{e0,m}表示最后一层的第n个令牌输出和第m个实体输出,知识编码器第i层的信息融合过程如图4 所示。

图4 第i层信息融合流程图Fig.4 Flowchart for the i-th level information fusion
知识编码器由堆叠的聚合器组成,这些聚合器用于编码令牌和实体并融合它们的异构特征。从图4 可知,在第i个聚合器中,输入令牌嵌入和实体嵌入,分别输送到2 个多头自注意网络[13]中,最后得到第i层的令牌输出和实体输出,编码过程如式(3)所示。
其中M(·)表示多头自注意网络函数,{t(i -1),1,…,t(i -1),n}和{e(i -1),1,…,e(i -1),m}分别表示第i-1 层的输入令牌嵌入和实体嵌入,{Ti,1,…,Ti,n} 和{Ei,1,…,Ei,m}表示第i层的令牌和实体输出。然后,第i个聚合器对令牌和实体进行相互集成,并计算每个令牌和实体的输出嵌入。对于令牌和其对应的实体,信息合并过程如下:
其中hj是融合令牌和实体的内部隐藏状态。σ(·)是非线性激活函数,一般是高斯误差线性单元函数[14]。Ti,j和Ei,k分别表示第i层信息融合后的令牌和实体的输出嵌入,j和k分别表示两者的长度,Wi,t和Wi,e分别为对应于2 个输入项Ti,j和Ei,k的权重参数,用来调节输入对节点的贡献程度。bi为常数,表示偏置项,不依赖于输入。偏置项用于调整节点的激活阈值,从而影响节点的激活程度。
对于没有对应实体的令牌,信息融合层只计算输出不进行集成,如式(5)所示。
简单来说,第i层的聚合器操作如下,
其中A(·)表示聚合器函数,{t(i -1),1,…,t(i -1),n}和{e(i -1),1,…,e(i -1),m}分别表示第i-1 层的输入令牌嵌入和实体嵌入,把这2个嵌入作为聚合器函数的输入,在经过最后一层的聚合器计算以后,得到令牌输出嵌入{ti,1,…,ti,n}和实体输出嵌入{ei,1,…,ei,m},这2个输出嵌入将用作知识编码器的最终输出嵌入。
2 实验部分
2.1 数 据
本实验的文本分类任务属于主题分类,所选数据集为清华大学自然语言处理组开源的THUCNews 新闻文本分类数据集(2.04 G),同时为体现各个模型的分类效果,选用SogouNews 新闻数据集进行对比试验。首先在THUCNews 数据集中筛选10 个分类的数据,每个分类6 000 条数据,总共63 500 条新闻数据,其中训练集每个分类5 120 条数据,测试集每个分类1 230 条数据,SogouNews 数据集也是选取相同的10 个分类,但是由于该数据集文本较短,收录的新闻数据在时间范围上也比THUCNews 数据集偏短,覆盖面比较狭小,所以选取的数据量相对较少一些。
2.2 设 置
在进行实验过程中,参考了亢文倩[15]用到的方法,设置以下参数对模型进行预训练,文本编码器层的数量N=6,知识编码器层的数量M=6,令牌嵌入和实体嵌入的隐藏维度分别为768 和100,聚合器中的自注意头的数量分别为12 和4,注意力层丢失概率设置为0.1,学习率为5×10-5,学习周期数为2 或者3。
2.3 结果分析
2.3.1 不同模型的分类效果对比 在THUCNews数据集和SogouNews 数据集上对不同模型的准确率、召回率进行对比,验证不同模型的分类效果,结果如表1 所示,P、R、F1分别代表精确率、召回率、精确率和召回率的调和平均数。

表1 不同数据集上各模型的结果Tab.1 Results of each model on different datasets %
从 表1 可 以 看 出,BERT、ERNIE 和ERNIEKEPLER 模型的召回率在2 种数据集上都要远高于文本循环神经网络(text recurrent neural network,TextRNN)模型,说明预训练的语言模型更适合对较长的文本进行处理。前者充分发挥了预训练的优势并利用了预处理的数据,以更好地完成信息提取和信息融合。从表1 也可以看出ERNIE-KEPLER 模型的召回率在2 种数据集上分别达到89.18%和90.36%,接近90%,与召回率为85.65%、87.35% 的BERT 和87.45%、88.61% 的ERNIE模型相比,提高了近2%,说明ERNIE-KEPLER模型的适用性较强,在不同的数据集上都有较好表现,由此可见ERNIE-KEPLER 模型的分类效果优于文中应用于分类任务中的其他模型。
2.3.2 不同数据集上模型分类效果的对比 为了验证不同数据集对实验结果也有一定影响,实验人员同时记录了4 种模型在THUCNews 和SogouNews 数据集上的实验结果并统计了模型在文本分类任务的准确率指标。实验结果表明,不同的数据集也会造成实验结果的差异。对比实验结果如图5 所示,且4 种模型在数据质量比较高的THUCNews 数据集上表现出来的准确率比SogouNews 数据集都要高,这表明包含的语义信息越丰富,覆盖面越广泛的数据集,模型在该数据集上表现出的效果越突出。
2.3.3 不同模型损失函数对比 在实验的过程中对比发现,在THUCNews 数据集上训练的过程中,ERNIE-KEPLER 模型的收敛速度比TextRNN 和ERNIE 模型都要快,稳定后的损失值也比其他2种模型更低。3 种模型的损失曲线如图6 所示。
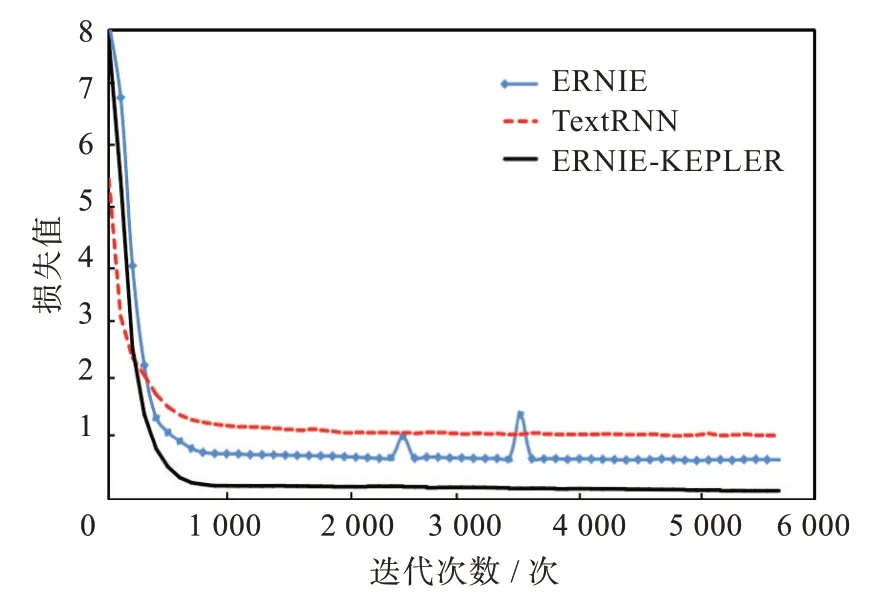
图6 损失值收敛示意图Fig.6 Convergence diagram of loss values
当迭代次数为0 时,即模型刚开始训练时,实验结果如图6 所示,TexRNN 模型的损失值明显低于其他2 种模型的损失值,这是因为训练过程中,TextRNN 模型一次性输入给模型进行更新的样本数目为16,使得在模型开始训练时,会有16 个训练样本同时使用神经网络,而其他2 种模型样本数目为32,使得模型对数据的训练结果存在较大误差,造成较大的损失,也导致TextRNN 模型刚开始的损失值明显低于其他2 种模型。
同时,在ERNIE 模型的训练过程中,出现了损失值先增大后减小的问题,而在ERNIE-KEPLER模型中并未出现。这是由于数据处理方式的不同,导致部分数据保留的有用的信息较少,使得ERNIE 模型获得的知识信息与实际信息存在误差;另一方面虽然有的数据包含的有效信息较少,但是ERNIE-KEPLER 模型使用了知识嵌入模型对知识信息进行提取,能够为实体进行信息扩展,使实体包含更丰富的语义信息,ERNIE 模型虽然也使用了知识嵌入,但是相对本次实验中提出的方法,其获得的实体嵌入没有包含更多的语义信息。所以也说明ERNIE-KEPLER 预训练语言模型凭借其优秀的学习能力更容易通过调整参数来使模型有更优秀的表现,即ERNIE-KEPLER 模型比其他模型具有更高的训练效率。
综合试验结果表明,经KEPLER 模型优化后的ERNIE 模型,更好地融合了知识图谱中的实体信息,从而使预训练语言模型比普通的网络模型在文本分类任务中有更好的结果,证明了本次研究的方法的可行性,能够有效提高文本分类的准确率。
3 结 论
为了利用知识嵌入模型将知识图谱中的知识信息融合到语言模型中,通过将实体和实体描述相对应,使实体包含更多的文本信息,从而使训练好的模型能更好地理解文本,增强语言表示。同时,为了更好地融合文本和知识图谱中的信息,使用了知识编码器和去噪实体自动编码器。实验结果表明,本次研究的方法具有良好的性能,ERNIEKEPLER 模型比BERT 和ERNIE 模型具有更好的数据学习能力。未来的研究方向,可以按照本文的思路,引入知识库等其他结构化的外部知识,优化预训练语言模型,而且本文提出的模型在实验过程中参数过多,训练时间较慢,如何提高模型的效率,加快模型的训练速度也是可以研究的方向;还可以考虑基于特征的预训练模型与知识信息的融合,从而探索在文本分类任务中更加有效的方法。
