基于自动驾驶道路场景的语义分割方法研究*
2024-01-03张佳琪惠永科
张佳琪,袁 骏,惠永科,胡 勇,张 睿
(1.太原科技大学 计算机科学与技术学院,山西 太原 030024;2.中国机械科学研究总院集团有限公司,北京 100044)
0 引言
自动驾驶领域中利用语义分割技术对路况进行分类有助于系统了解路况,进而做出更为精确的路径规划以及更为及时地规避障碍物,确保行车的安全,因此关于道路场景的分割对自动驾驶系统来说有着重要的现实意义。
现有的基于语义的图像分割方法已难以适用于多个目标的分割任务,而基于深度学习的方法为计算机视觉领域的研究带来了新的突破。与经典的体系结构相比,卷积神经网络(Convolutional Neural Networks,CNN)图像语义分割技术[1]能显示出更好的效率和准确性。陈先昌[2]和Farabet等[3]提出了一种使用从原始像素训练的多尺度卷积网络对密集特征向量进行提取,以图像中每个像素为中心,为多个大小的区域进行编码的方法;Long等[4]提出的全卷积神经网络(Fully Convolutional Networks,FCN)的流水线虽然扩展了卷积神经网络,并且可以预测任意尺寸的输入图像,但是FCN预测结果分辨率比较低;Ronneberger等[5]提出的UNet在上采样部分中具有大量特征通道,使得较高分辨率层能够接收到上下文信息,通过“U”字网络形状获得深度特征和浅层信息,达到了预测的目的。
随着大规模公共数据集和进化的高性能图形处理器(Graphic Process Unit,GPU)技术的发展,出现了一种高效的语义分割网络CPNet[6],能够捕捉到类与类之间的语义关系,进而提高了该网络对道路场景的理解分析能力。而基于像素的纵向位置且有选择性的突出信息属性的网络HANet[7]则可以更好地实现城市街道场景图像的语义分割。
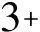
1 道路场景语义分割的优化算法设计
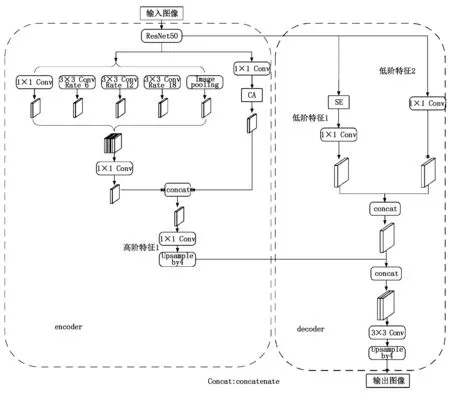
图1 改进后的DeepLab 网络结构
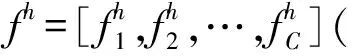
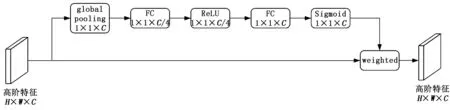
图2 通道注意力结构
FCA(vh,WC)=σ1{fc2{δ[fc1(vh,WC1)],WC2}}.
(1)
其中:FCA(vh,WC)为进行完激活函数后的输出;WC、WC1、WC2均为通道注意力模块中的参数;σ1为Sigmoid操作;fc1、fc2分别为第一个全连接层和第二个全连接层;δ为ReLU函数。
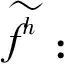
(2)
CA将对响应较高的通道给予较大的加权,为了进一步提高融合性能,将之前输入图像中的不同通道进行拼接融合,然后使用1×1卷积来进行维度的降低,与此同时使用CA注意力模块融合从主干网络提取出的特征图,并提取丰富的上下文信息,得到有效的高阶特征。
在解码器端输入图像并通过ResNet50模型的输入层后,首先将两个特征图同时提取出来作为解码器的特征输入信息,根据迁移残差连接的思想,将所提取出的两个特征图分为两条路径,一路经过注意力机制SE(Squeeze-and-Excitation)模块,在SE模块中对高阶特征进行处理,产生有效的特征图,从而提高分割结果,另一路不通过SE模块;接着再将两路提取出的低级特征分别经过1×1的卷积操作降维后再叠加,之后融合编码器中四倍上采样获取的高级特征,最后经过3×3的卷积和上采样的方法将其还原到与输入图像相同的分辨率,并对特征进行进一步的精细化,进而恢复空间信息。
本文采用了信息论中的重要函数——交叉熵损失函数,交叉熵损失函数计算公式定义为:
L=-yilog2pi-(1-yi)log2(1-pi).
(3)
其中:yi为输出的真实值,yi=0或yi=1;pi为样本的预测概率。
2 实验验证与结果分析
2.1 数据集
本文采用Cityscapes这一大型的数据集来对实例语义标签[11]进行训练和测试。Cityscapes是从50个城市中春、夏、秋季的街头采集到的各式各样的三维图像,其中5 000张图像是具有高品质的像素级注释,而另外20 000张图像则进行了粗略的注释,这样就可以更好地使用这些标注过的数据。
2.2 实验平台
本实验是在Windows10操作系统下使用Pycharm平台以及Python3.9语言开发的,CPU为Intel(R)Core(TM)i9-10900K CPU @ 3.70 GHz;GPU采用NVIDIA RTX 3090。
2.3 实验评价指标
本实验使用的评价指标为平均交并比(Mean Intersection over Union,MIoU)和总体精度(Over Accuracy,OA)。MIoU计算公式为:
(4)
其中:n为标签标记的类别数;n+1为包含空类或者背景的总类别数;pii为模型预测与实际均为i类的像素个数;pij为预测为j类但实际为i类的像素个数;pji为预测为i类但实际为j类的像素个数。
MIoU的取值范围为[0,1],1表示准确的预测,0表示完全错误的预测,MIoU值越高表示模型性能越好。
2.4 改进模型消融实验
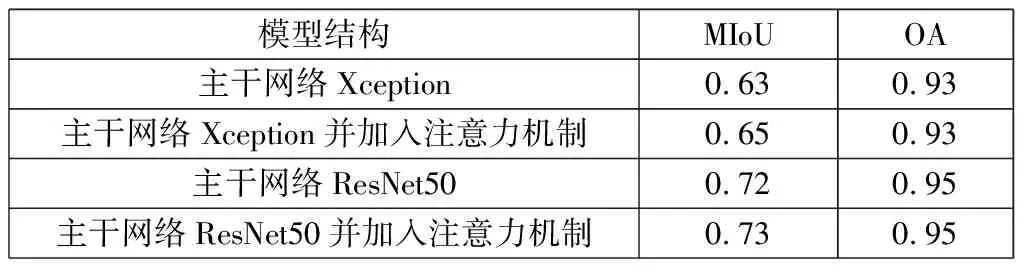
表1 不同模型结构的消融实验结果
2.5 性能对比实验
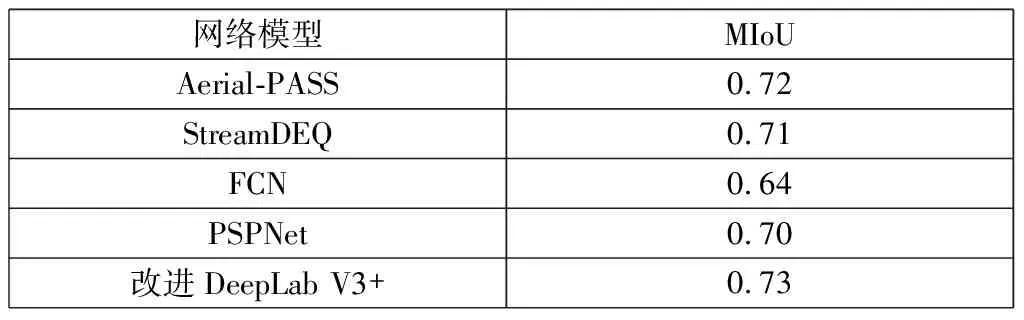
表2 不同网络模型Cityscapes数据集分割效果对比

图3 原始模型分割结果和改进后DeepLab 模型分割结果对比
