基于Sentinel-2影像的横山水库叶绿素a反演算法研究
2024-01-03李小勇范春波
李小勇,黄 鹏,孙 武,范春波,游 林
(1.武汉华夏理工学院 土木建设工程学院,湖北 武汉 430223;2.浙江时空智子大数据有限公司,浙江 宁波 315200;3.宁波市奉化区横山水库管理站,浙江 宁波 315511)
1 材料与方法
1.1 研究区域
宁波市横山水库是宁波、奉化城市供水的主要饮用水源地之一,是地方水资源时空分配调控的重要水利工程措施,承担供水、防洪、灌溉、发电、养殖等方面重要任务[1-2]。水库位于奉化江支流县江上,集雨面积 150.8 km2,正常性蓄水水位111.5 m,相应库容7.65×107m3。作为易受作物更替种植和城市扩张等人类活动干扰的水库,其水质常年在Ⅱ~Ⅲ类之间,但水体富营养化的几个重要指标逐年升高,尤其是在春季已爆发过轻微“水华”事件。
1.2 地面数据
自动站点监测数据来源于宁波市生态环境监测中心提供的2020—2022年每日8时、12时、16时3个时间点监测水库水质。月度常规取样化验数据由宁波原水集团有限公司提供,于水库坝前分别进行表层、供水层、底层水样采集,送往实验室测定水质参数。自动站点与月度常规取样都测定了包含水温、pH、溶解氧、浊度、电导率、高锰酸盐指数、氨氮、总磷、总氮、Chl-a等常规水质参数。自动站点与采样点位置如图1所示。
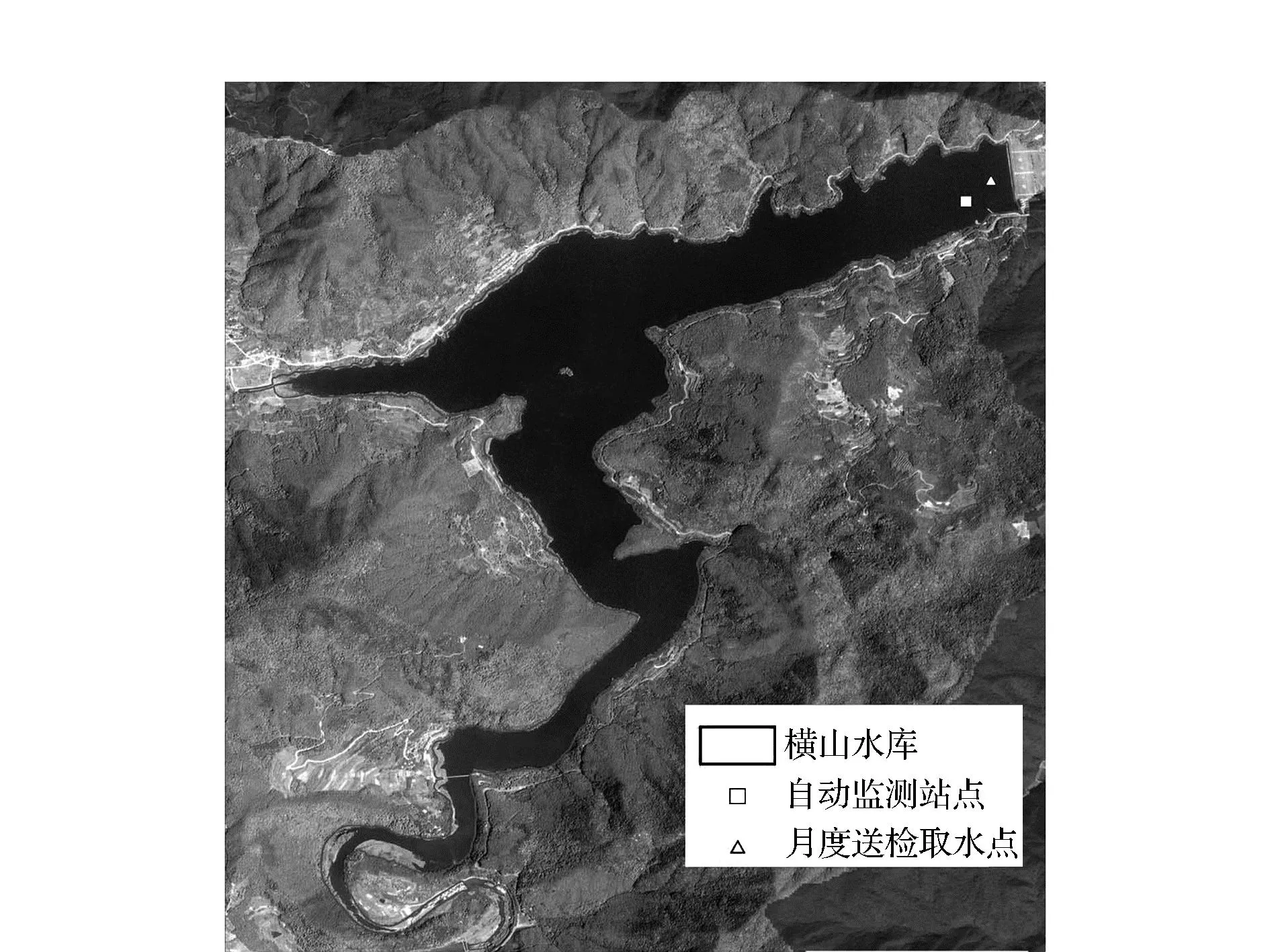
图1 自动站点与采样点示意图
通过自动站点监测数据与月度常规取样化验数据的相关性分析发现,站点监测数据与表层数据的相关系数都在0.79以上,鉴于Sentinel-2影像在10时左右过境拍摄,本文最终选取采用相关性较高的12时监测数据作为Chl-a浓度实测数据。
1.3 遥感影像数据
本文于Google Earth Engine(GEE)遥感信息管理与处理云平台上,获取Sentinel-2卫星(表1)地表反射率产品L2A级数据,其在L1C级数据的基础上,已经进行大气校正等处理。通过JavaScript API在线访问覆盖横山水库区域的遥感影像数据,选取受云雾影响较小,质量较好的影像共56景。
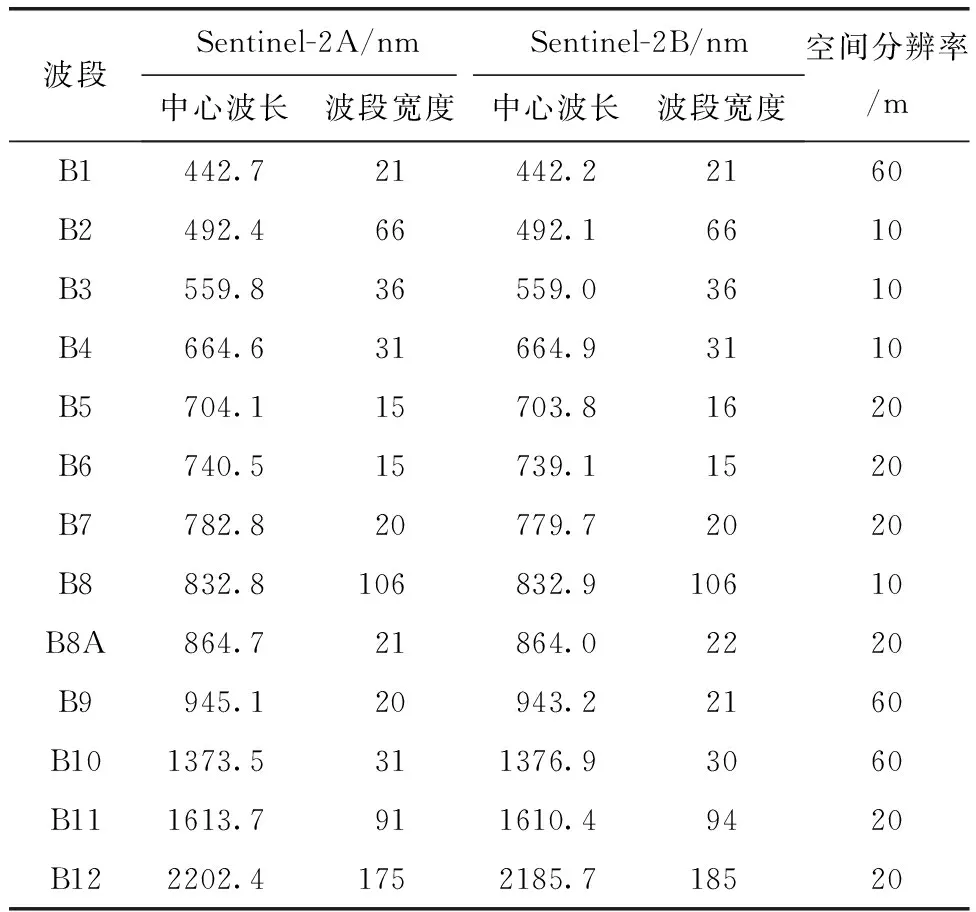
表1 Sentinel-2传感器波段信息
风速、降水、流速等环境因素会对自动站点监测的Chl-a浓度测量值有所影响,水面镜面反射以及大气影响使得遥感波段值不是真实的地面反射率值,因此,需剔除异常值,以减少因为站点监测数据与遥感影像数据不能完全匹配所产生的Chl-a浓度的估算误差。本文将监测站点Chl-a浓度值与遥感影像波段值绘制散点图,剔除偏离回归线的异常值之后的35对遥感数据与监测站点数据作为模型反演的训练数据。
1.4 方 法
1.4.1 Chl-a经验反演模型
归一化Chl-a指数模型(NDCI)是Sentinel-2的水色产品数据集的官方算法,相对于单波段、波段比值、三波段方法,估算精度更高、适用性更强[3]。该Chl-a反演模型使用一个新的高质量合成数据集(9836个样本),这些数据被分成7868个样本的训练数据集(80%)和1968个样本的测试数据集(20%),利用这些数据集建立一个估算Chl-a浓度值y的经验模型,如公式(1)所示。
y=17.441e4.7038NDCI
(1)
1.4.2 BP神经网络
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,主要包含输入层、隐含层、输出层3个部分,是广泛应用的神经网络模型之一。其训练过程分为信号的前向传播与误差的反向传播两个阶段。通过不断的信号前向传播和误差反向传播,各层权值会不断进行调整,直到训练结束。
1.4.3 随机森林
随机森林(RF)算法是一种集成模型,其核心思想是采用集成学习三大分支中Bagging、Boosting 和 Stacking中最具有代表性的Bagging集成学习技术。随机森林在保留决策树处理多特征数据类型特点的同时,由于采取有放回的抽样,解决了决策树容易产生的缺陷——过度拟合,另外其预测结果是参考多个决策树得到的结果,降低了异常值带来的影响。随机森林在非线性特征模拟等方面都有很好的表现,其所构建的Chl-a浓度遥感反演模型也更具有泛化性。
1.4.4 精度评价体系
各反演模型的精度通过3个指标进行评估,即均方根误差(RMSE)、平均绝对误差(MAE)和决定系数(R2),如公式(2)~公式(4)所示。
(2)
(3)
(4)
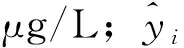
2 结果与讨论
2.1 波段选择
随着叶绿素含量增加,水体反射光谱在蓝光和红光波段构成较强的吸收谷,在绿光波段出现反射率峰值,含量越高,峰值越高。通常影响因子与水质参数之间的关系不能利用单波段很好反应,采用 SPSS计算不同的波段组合与Chl-a浓度的皮尔逊相关系数,获取相关性强、干扰小的敏感波段。本文利用35个自动监测站点实测的Chl-a浓度数据与遥感影像反射率数据,分别在单波段、单波段比值、双波段比值、三波段、四波段以及NDCI中选择相关系数最大的作为变量因子,各波段与Chl-a浓度值的相关性如表2所示。最终选取B8、B5/B4、(B5-B4)/(B5+B4)作为机器学习模型构建的输入层。
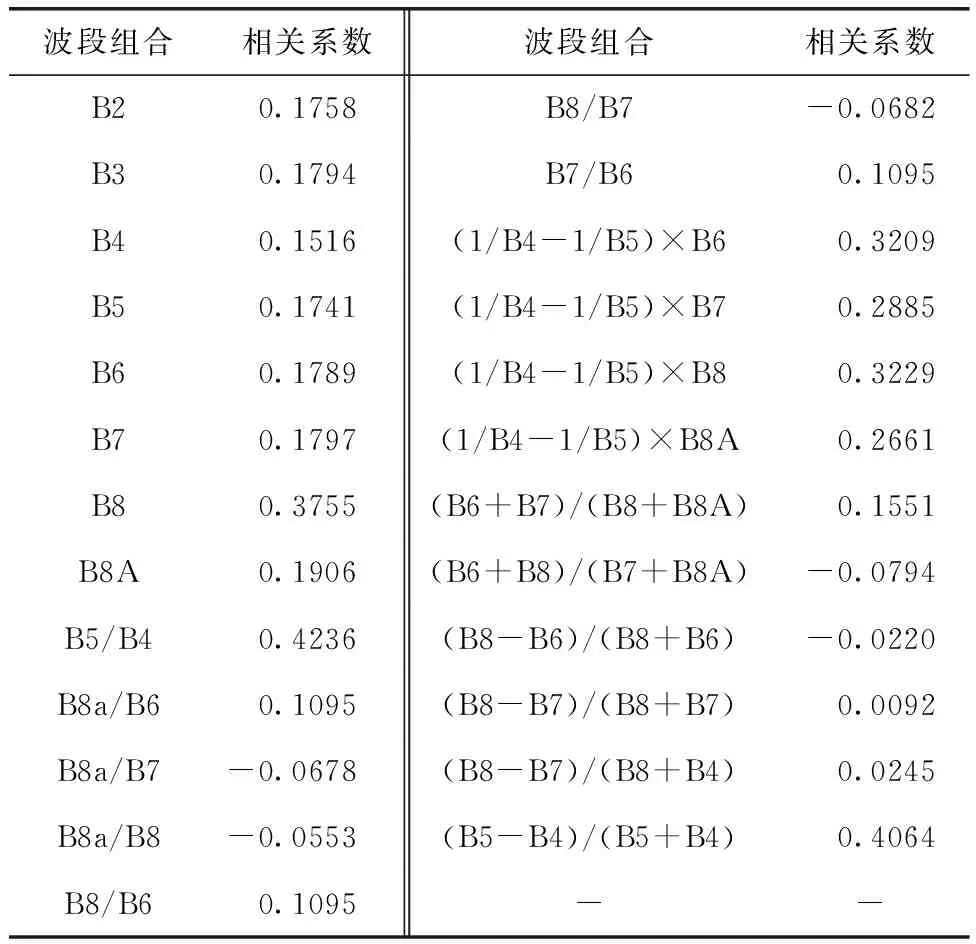
表2 各波组合与Chl-a浓度的相关系数
2.2 模型构建与验证
本文将样本数据划分为训练集以及测试集,并按照8∶2的比例随机进行划分,其中训练集28个,测试集7个。然后基于Scikit-learn机器学习库,根据上述筛选的重要特征变量,作为机器学习的输入因子,与之相对应的自动站点监测Chl-a浓度作为输出数据,分别构建BP神经网络与随机森林模型。
本文分别选择不同的决策树大小、决策树的深度对随机森林进行反复训练,经调试,模型参数确定为n_estimators=20,max_depth=5时,训练集RMSE为2.094、MAE为1.631、R2为0.876,此时的模型训练效果最佳。BP神经网络采用relu作为激活函数,学习速率为0.01,通过多次实验确定隐含层节点数为10时,模型精度最高,训练集RMSE为2.766、MAE为2.298、R2为0.785。利用经验模型直接对训练集进行预测,RMSE为 2.7063、MAE为 2.6197、R2为0.7544。三种模型的拟合曲线如图2(a)~图2(c)所示。
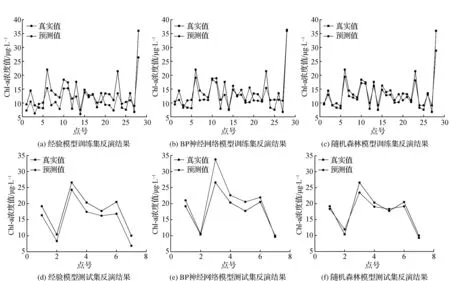
图2 Chl-a遥感反演曲线拟合
为评价模型的普适性,将三种模型对划分好的测试集分别反演Chl-a浓度,对反演结果进行模型验证以及精度评价。从表3可以看出,随机森林模型在测试集上,均方根误差和平均绝对误差都较低,决定系数R2大于另外两种,精度更高。图2(d)~图2(f)为各模型在测试集上预测值与真实值的拟合曲线,经验模型的预测值曲线虽然与真实值的曲线大致保持一致,但整体比真实值低得多;BP神经网络模型预测值曲线同样与真实值的曲线大致保持一致,但结果整体偏高,还出现高出真实值许多的异常情况;而随机森林模型除了测试集的预测值曲线与真实值的曲线大致保持一致之外,其在训练集上预测值曲线也大致保持一致,能够较好地分布在真实值附近。因此后续基于Sentinel-2影像反演横山水库Chl-a浓度将采用随机森林模型。
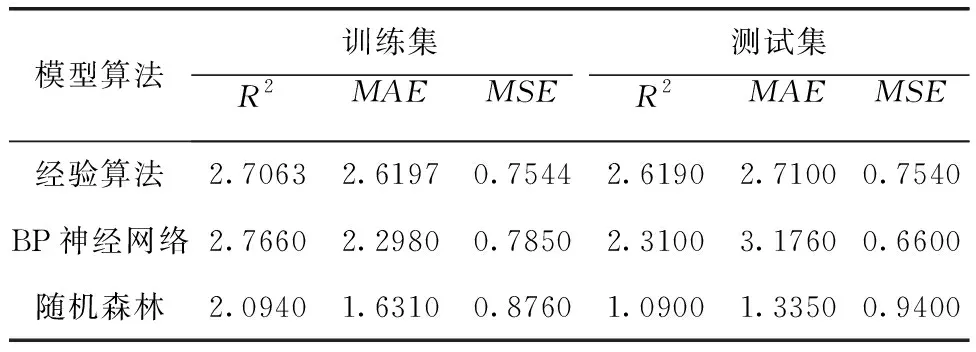
表3 不同模型预测Chl-a浓度的精度情况
2.3 叶绿素a浓度空间分布
为只对横山水库库面进行Chl-a浓度反演,计算Sentinel-2的归一化差分水体指数(NDWI),通过大津阈值法获取水库与陆地的分割阈值,掩膜出横山水库库面水域。计算库面区域内的B8、B5/B4、(B5-B4)/(B5+B4)等波段组合值,并作为随机森林模型的输入因子,对横山水库2020年4月20日及2022年10月22日两期遥感影像进行Chl-a浓度反演。如图3所示,其中标注的点位为相同日期自动站点监测的Chl-a浓度。2022年10月22日Chl-a浓度预测值为13.8936 μg/L,真实值为12.771 μg/L;2020年4月20日Chl-a浓度预测值为24.3188 μg/L,真实值为26.587 μg/L。由反演结果可以看出,2020年4月20日的Chl-a浓度整体普遍高于2022年10月22日,与横山水库易在春季发生水华时间点匹配,且该水库在2020年春季发生过轻微水华事件,说明随机森林反演模型对于横山水库的水质监测能够提供一定参考。
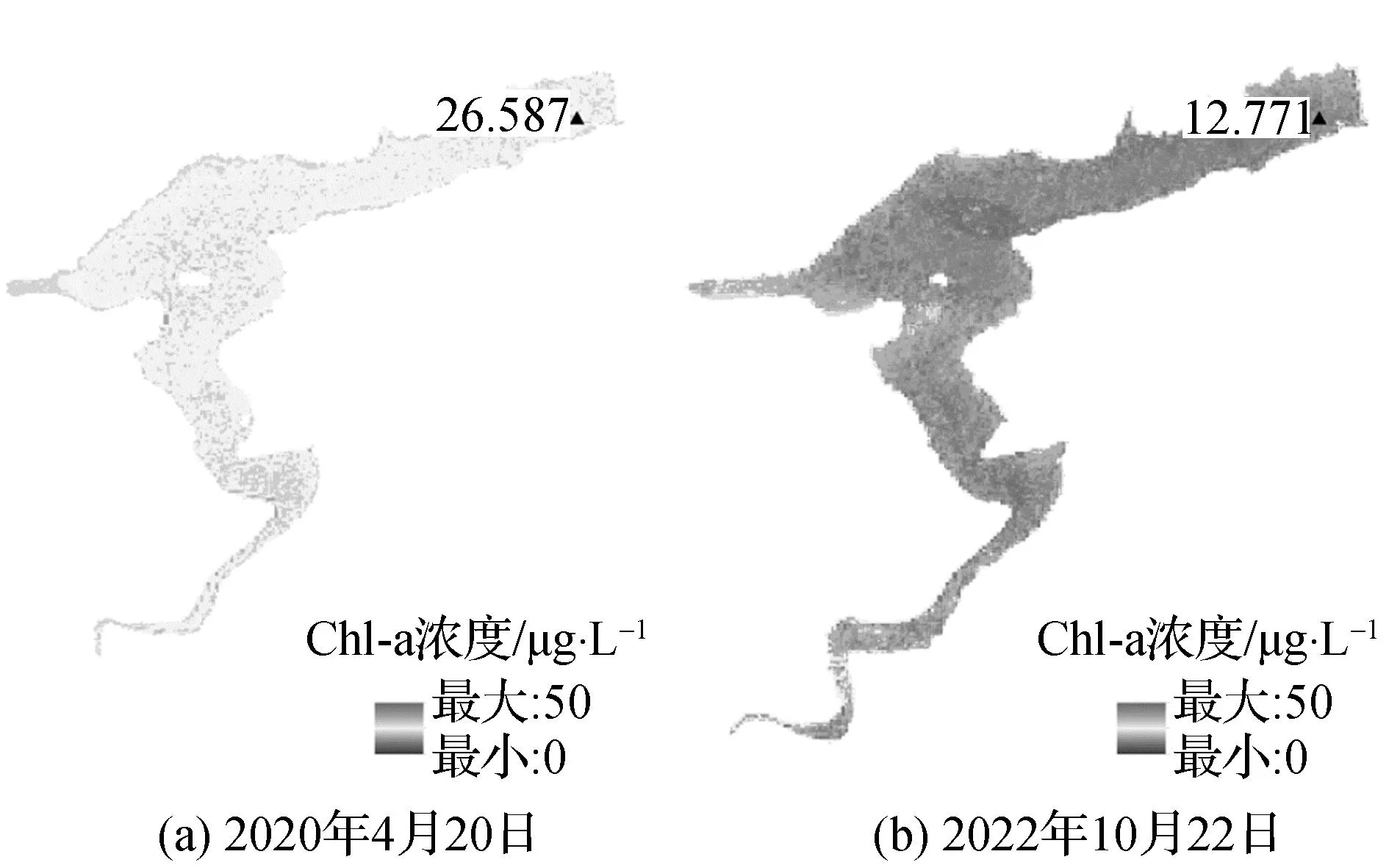
图3 横山水库Chl-a浓度空间分布
3 结 论
(1)对比Sentinel-2不同波段组合与Chl-a浓度的相关性发现,B8、B5/B4、(B5-B4)/(B5+B4)相关系数最大。
(2)使用相同数据集构建3 种不同的Chl-a浓度反演模型,对比发现随机森林模型的MAE、MSE和R2均最小,比经验模型和BP神经网络构建的反演模型精度更高。因此,利用本文构建的随机森林模型更适用于Sentinel-2数据在横山水库的Chl-a浓度反演。
(3)通过Sentinel-2影像监测发现,横山水库2020年4月20日Chl-a浓度比2022年10月22日整体较高,与横山水库易在春季发生水华时间点匹配,为水库的水华和富营养化监测提供了参考。
