基于PSO-SVR模型的短期天然气负荷预测
2024-01-02杨奕刘金源陈天民魏王颖王寿喜
杨奕, 刘金源, 陈天民, 魏王颖, 王寿喜,*
(1.西安石油大学石油工程学院, 西安 716500; 2.西南石油大学石油与天然气工程学院, 成都 610000; 3.国家管网集团山东省分公司, 济南 250000)
中国宣布将增加自主减排贡献,力争于2023年前实现碳达峰[1],2060年前实现碳中和。鉴于超过85%的CO2排放量来自能源活动,碳中和战略将深刻改变中国能源的消费结构,必须加快向绿色低碳能源转型的步伐。天然气作为中国能源转型阶段的重要能源形式,近年来需求量逐年增长。但是天然气作为一次能源,并非取之不尽用之不竭,因此,天然气负荷的准确预测显得尤为重要。
天然气短期负荷预测[2]为多因素非线性回归问题,是燃气调度中心制定供气量及天然气报价的依据,对天然气系统[3]的日常运行、控制和供气计划有着非常重要的影响。准确的天然气负荷预测[4]可提高调度系统运行的可靠性、储气调峰的合理性、管网供气量的准确性,对城市供气的安全、稳定及经济性影响深远。
天然气负荷预测主要分为传统预测方法和人工智能预测方法两种。其中,传统的预测方法主要包括:灰色模型、时间序列算法等;人工智能预测方法[5]主要包括:支持向量机、粒子群算法、长短期记忆、遗传算法等。随着天然气负荷预测精度要求的不断提高,人工智能算法越来越受关注,但是单一的模型预测已经不能满足当下的精度需求,组合预测模型也逐渐成为潮流。文献[6]设计了一种改进传统时间序列算法的模型进行电力负荷预测;随着支持向量机的出现一定程度上解决了传统神经网络中容易陷入过拟合等问题[7],文献[8]对于短期负荷预测使用分布式支持向量回归(support vector regression,SVR),预测准确度有一定的提高。但是在现场应用中,发现预测结果的好坏与参数息息相关,随之出现的就是使用优化算法优化SVR重要参数。文献[9]使用最小二乘法对支持向量机进行改进,使计算复杂度降低,提升了预测精度和速度。可以发现支持向量机对提高预测精度存在优势,一般需与其他算法搭配,但是也会出现内存较大的问题[10]。文献[11]提出使用灰狼算法优化支持向量机,预测精度有所提高,但是经过灰狼优化得到的最优解接近于初始最优解,不是问题的真实最优解。而粒子群优化算法(particle swarm optimization,PSO)搜索精度高、收敛速度快的优点使其具有强大的参数寻优能力。
针对上述问题以及模型的优缺点,将PSO与SVR进行结合,针对SVR在进行参数选取过程中耗时较长,必须依赖人工经验的情况,PSO可以减少搜索时间,得到SVR重要参数的最优解,降低模型训练的时间,提高预测精度。
1 算法原理及核心公式
1.1 SVR算法
SVR[12]通过使用核函数将样本数据映射到高维空间的方式进行预测,从而解决小样本和局部极值问题。SVR的优点为:对异常值具有鲁棒性、决策模型更新简单、预测精度高;缺点为:参数选取较为困难,需要结合人工经验进行选取,在一定程度上比较耗费时间。
回归函数表示为
f(x)=ωφ(x)+b
(1)
式(1)中:ω为权重:b为偏差;φ(x)为低维空间变到高维空间的映射函数。
根据结构化风险最小化原则,式(1)可以转变为

(2)
约束条件为
(3)

式(3)为典型的二次规划问题,求解可得

(4)
(5)

对式(3)进行求解得到的参数ω和b,整理可得
(6)
式(3)中:K(xi,x)称为核函数。
目前,最常见的核函数是高斯径向基函数(标准差为σ),表达式为
(7)
SVR的流程图如图 1所示。

图1 SVR计算流程图Fig.1 SVR calculation flow chart
1.2 PSO算法
PSO是一种研究鸟类觅食行为的算法[13]。基本思想是通过鸟类种群中个体之间的互助合作和信息共享搜索最优解。它的优点为:高精度搜索、收敛速度快。粒子速度和位置更新公式为
(8)
式(8)中:Vi为第i个粒子的速度;ω为惯性权重;c1和c2为学习因子;rand表示0~1的随机数;pbi为第i个粒子搜索到的最优值;pi为第i个粒子的当前位置;gb为整个集群搜索到的最优值。
PSO算法对支持向量回归模型[14-15]中的参数c、参数ε和参数γ搜索最优的步骤如下。
(1)初始化:初始化粒子的位置和速度,设置基本参数的范围,规定惩罚因子参数c、不敏感系数参数ε和核函数参数γ的搜索范围为c∈(0,10)、参数ε∈(0,5)和参数γ∈(0,100),分别用参数c、ε和γ表示粒子位置。
(2)计算适应度:求解上述适应函数的适应度(fitness)的值,并对种群中的粒子位置以及速度进行更新。
(3)更新速度和位置:对步骤(2)计算的适应度值再次进行计算,以此来更新个体极值和群体极值。
(4)设置终止条件:将种群的最大迭代次数设置为100,对上步操作进行重复,直到满足终止条件时,循环结束。
PSO的计算过程见图 2[pbest(d)为个体搜寻到的最佳位置,gbest(d)为群体搜寻到的最佳位置,x(d)为个体当前位置,x(d-1)为个体上一步位置,Q为个体因惯性下次到达的位置,ω为惯性参数]。

图2 PSO计算过程Fig.2 Calculation process of PSO
1.3 误差评价指标
误差评价指标用来评价预测模型的性能好坏,选取平均绝对误差(mean absolute error, MAE)、均方误差(mean squared error, MSE)、均方根误差(root mean squared error, RMSE)和平均绝对百分误差[13](mean absolute percentage error, MAPE)作为预测模型的评价指标。MAE表示预测值与真实值之间的平均偏差程度,取值范围[0,+∞);MSE、RMSE表示预测值与真实值之间的偏离程度,取值为[0,+∞);MAPE既考虑预测值与真实值的偏离程度,又考虑偏离程度的占比,取值范围为0~100%;MAE、MSE、RMSE、MAPE的值越接近0代表模型的预测效果越好,各评价指标的表达式为
(9)
(10)
(11)
(12)

2 PSO优化SVR算法
SVR是支持向量机对回归问题的一种运用,一般情况下,SVR中的3个关键参数(C,ε,γ)往往需要根据人为经验确定,具有一定的盲目性,因此,使用PSO算法[16]对SVR算法中的3个参数进行寻优[17],组合新的天然气负荷预测模型(PSO-SVR),并将其用于天然气短期负荷中。在PSO-SVR预测模型中,首先对SVR算法中3个关键参数进行初始化,对参数的取值范围进行设置为:c∈(0,10)、ε∈(0,5)、γ∈(0,100),设置迭代次数为100,种群数量为30;然后粒子通过自身经验和最优个体的经验进行迭代调整;最后找到最优值和最优位置,绘制优化曲线。流程图如图3所示。
并将关键参数的最优值以及相关的影响因素和天然气的负荷值导入SVR算法中进行训练,得到天然气负荷的预测结果。使用MAE、MSE、RMSE、MAPE指标对各模型的性能进行评价,从而得到最优预测模型,该算法即为PSO-SVR算法
3 实例应用
天然气作为实现“双碳”目标[18]中的重要能源,将得到进一步发展。但是,也存在一些问题,当天气突然变冷的时候,城市就会因为大量采暖处于用气高峰,从而出现“供不应求”的现象,便会出现诸如近年发生的北方“气荒”。为减少此现象的出现,考虑供气和用气两个方面,更加准确的预测可以给天然气公司的供气量提供参考,也可以为政府的储气调峰提供参考。
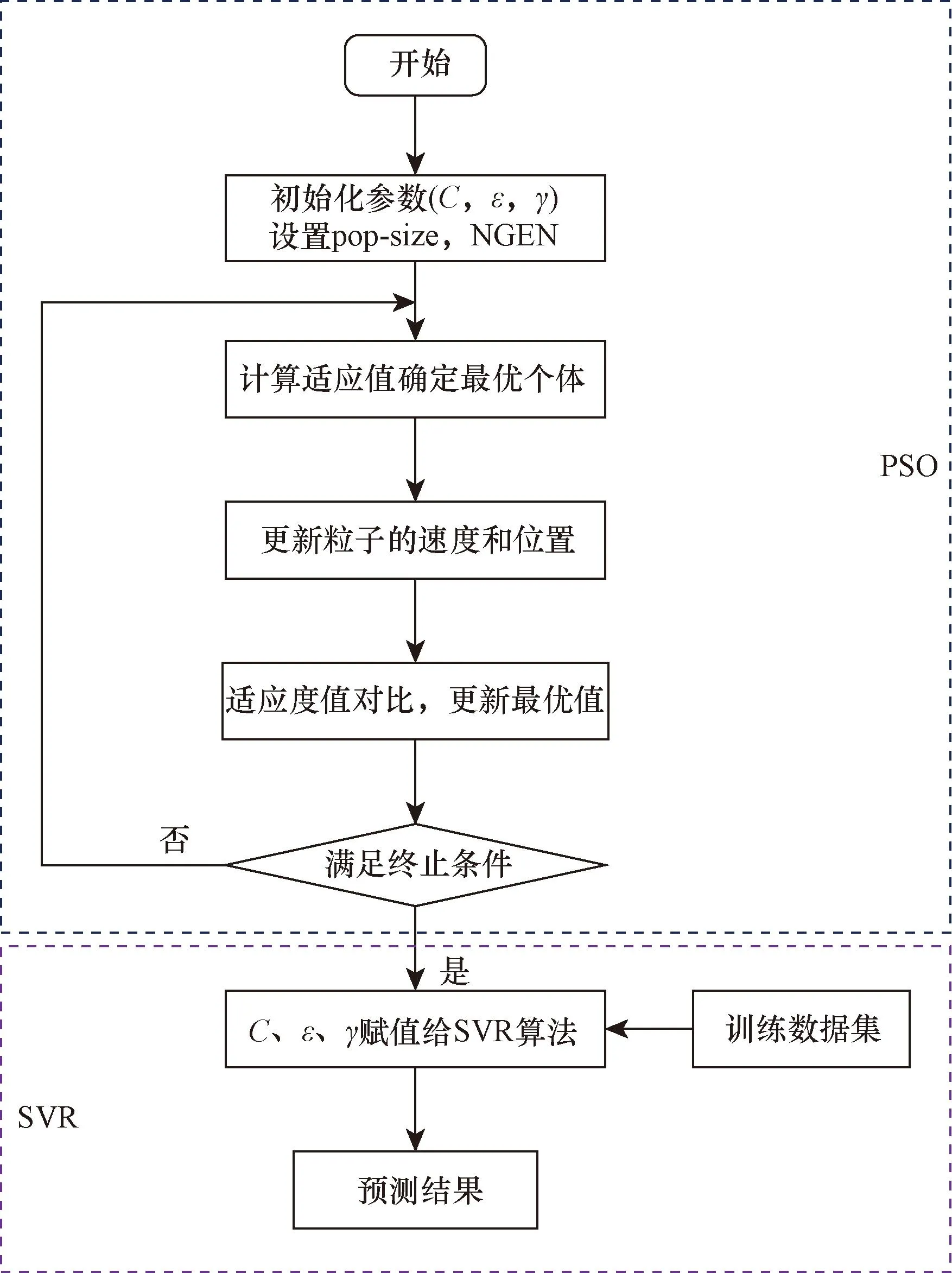
pop-size为种群数量;NGEN为迭代次数图3 PSO-SVR组合模型对天然气负荷预测流程Fig.3 Natural gas load forecasting process with PSO-SVR combination model
3.1 负荷数据分析
所用的数据为国家管网集团榆济管道有限责任公司2016年5月30日—2021年10月6日共5年的天然气日负荷数据,共计1 956组。天气情况数据来自于气象局网站。以2016年5月30日—2020年11月11日为训练集,预测2020年11月12日—2020年2月29日的负荷值。使用Python计算机语言的Pycharm和anaconda环境进行编程。考虑到影响负荷的因素分别为:最低温度、最高温度、天气情况、风力大小。为了使数据的量级得到统一,对数据进行归一化处理[19],对于数据集中的异常值,使用平均值代替的方法进行处理。为了避免出现实验的不确定性,进行8次重复实验,取平均值为预测结果。
3.2 特征选择
Relief算法作为特征选择算法的一种,早期针对于分类问题由Kira所提出。该算法作为特征权重算法,权重较大的特征被保留,而较小的特征将会被剔除。Relief算法对于不同的样本区分能力不同,该算法借助其特有的能力来进行特征权重的估计,算法步骤如下。
(1)从训练集中随机选取一个样本xn(1≤n≤N)并记录。
(2)在同类中找到命名为NearHit的最近样本H,在不同类中找到命名为NearMiss的最近样本M。
(3)然后更新权重ω:在某特征上,R到NearHit的距离小于R到NearMiss的距离,说明可以进行类别区分,故提高权重值;反之亦然。将上述更新过程重复多次,最后得出平均权重。权重大小与变量影响成正比。表达式为
(13)
(14)
式中:diff(x1,j,x2,j)为x1和x2样本于第j维存在的差异度;m代表样本抽取次数;k代表样本最邻近个数。
经Relief算法特征选择得到特征权重结果如表1所示。

表1 特征选择权重Table 1 Feature selection weights
3.3 预测与结果评估
通过上述的数据归一化操作之后,对数据预处理完成之后,将处理后的数据导入到支持向量回归模型中进行训练,将训练好的数据用来预测,得到预测数据,将预测数据与真实数据进行对比,得到相关的评价指标[20],从而进行误差分析。通过将线性核函数和RBF核函数进行对比发现,RBF核函数的精度较高,因此本文中使用的核函数为RBF,惩罚系数C的取值范围为[0,10],损失函数ε的取值范围为[0,0.1],γ的取值范围为[0,100]。两种不同的核函数进行预测得到的精度如表 1所示。
将RBF核函数里面的参数及取值范围输入PSO模型中进行最优化搜索,将搜索到的参数最优值传进SVR模型中,从而得到预测结果和评价指标,图4所示为PSO优化曲线。

表2 线性核和RBF对比Table 2 Linear kernel versus RBF
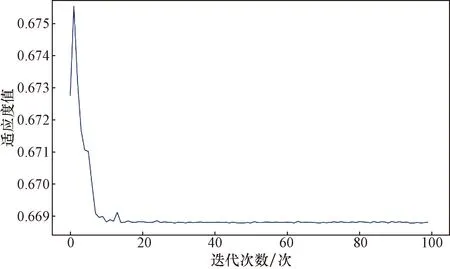
图4 PSO优化曲线Fig.4 PSO optimization curve
3.4 模型结果对比
本文采用自回归移动平均模型[21-22](auto regressive integrated moving average,ARIMA)、长短期记忆算法[23](long short time memory,LSTM)、SVR[24]、PSO-SVR四种算法在训练集和测试集比例为0.7的数据集上进行训练得到预测结果,再将其结果进行对比,预测结果对比图如图 5所示。
由图5发现,ARIMA的预测结果与真实值之间的偏差最大,2020年2月29日—2020年10月9日和2021年4月9日—2021年10月6日的预测值偏离真实值0.5;LSTM、SVR两个算法的预测结果比较接近;PSO-SVR组合模型预测结果与真实值之间的差距小于ARIMA、LSTM、SVR三种单一模型,经比较发现,组合模型的预测效果最好。
对于预测模型性能的分析,不仅包含定性分析,还应包含定量分析,经计算得到图 5中四种不同的预测模型相应的MAE、MSE、RMSE、MAPE值(表 3)。
不同算法预测结果对比如图 6所示。

表3 负荷预测误差对比Table 3 Load forecasting error comparison
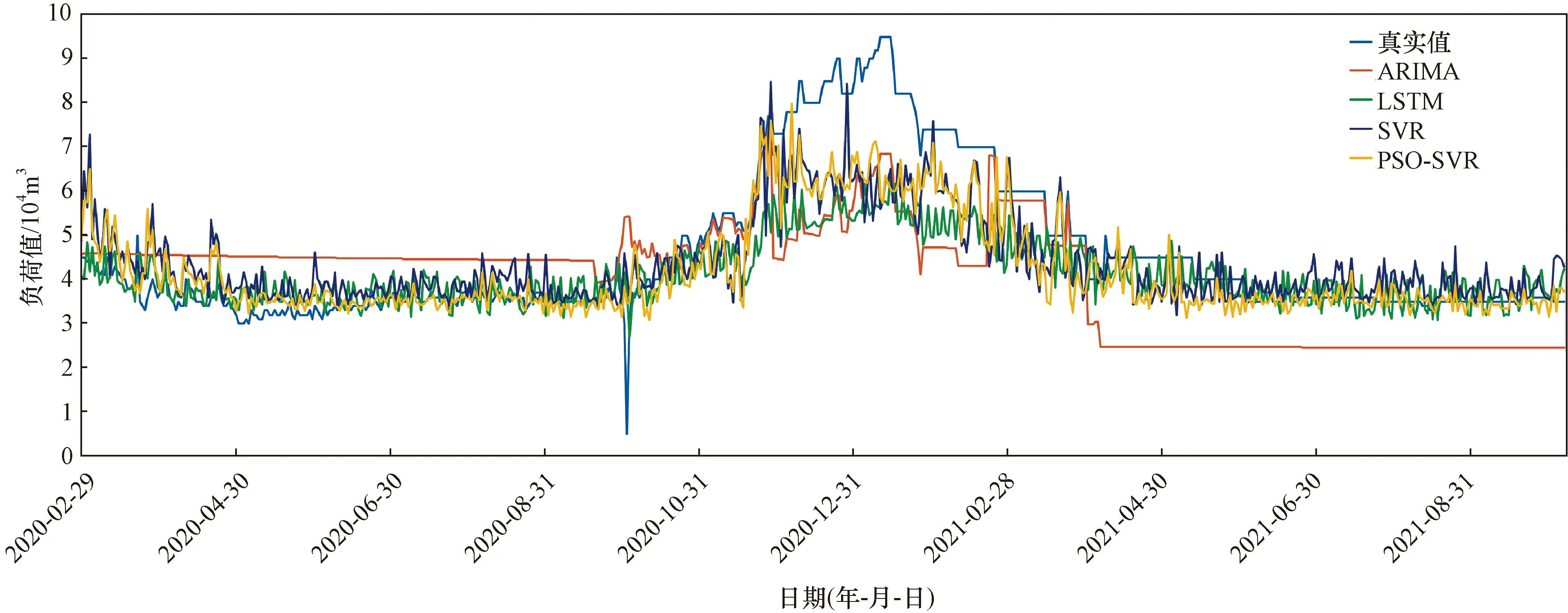
图5 不同模型预测结果对比图Fig.5 Comparison of forecasting results of different models
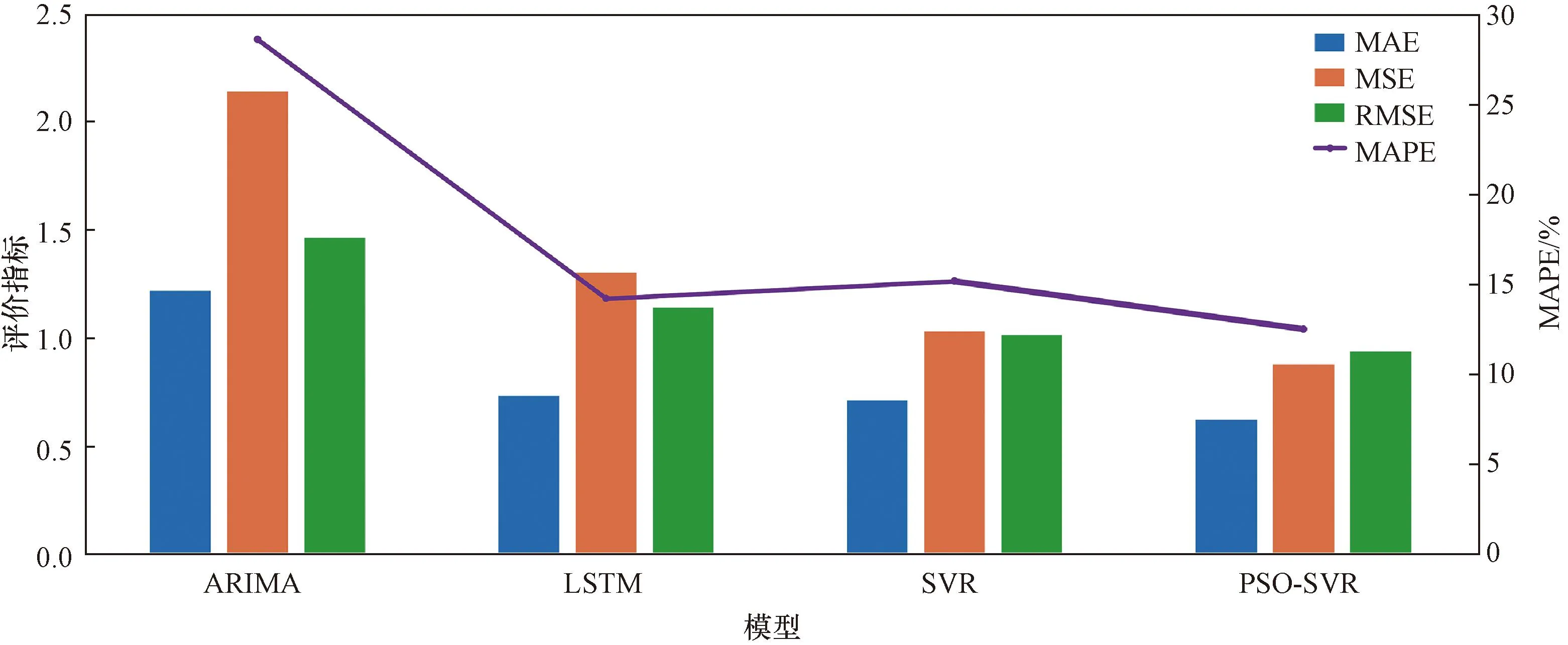
图6 评价指标对比Fig.6 Comparison of evaluation indicators
由图 6和表 3可以看出,PSO-SVR模型的预测精度相对于ARIMA、LSTM、SVR模型有了提高,其MAE分别减小了0.597、0.113、0.088;MSE分别减小了1.263、0.426、0.154;RMSE分别减小了0.527、0.205、0.079;MAPE分别减小了16.032%、1.661%、2.623%。因此,使用PSO-SVR模型可得到更好的预测结果。
4 结论
对于影响天然气负荷的因素进行特征选择,可以克服冗余因素对负荷预测精度及速度的影响;在此数据基础上,改变SVR预测模型中关键参数选取较为困难的情况,提出PSO优化算法搜寻最优关键参数的PSO-SVR组合算法,克服了关键参数选取困难且容易陷入局部最优的问题,将负荷数据和影响因素代入PSO-SVR中进行训练并预测,将得到的结果与SVR算法、LSTM算法、ARIMA算法进行对比,得到如下结论:
(1)经过PSO优化算法迭代寻找SVR算法关键参数的最优值,解决了传统SVR算法选择关键参数时的盲目性与局限性。
(2)本文提出的PSO-SVR组合模型,具有较强的全局搜索能力,预测结果的MAPE评价指标为12.49%,模型具有良好的可行性和有效性。
(3)将PSO-SVR组合算法应用于国家管网榆济分公司门站,预测得到的结果相较于传统单一SVR模型、LSTM模型和ARIMA模型的预测精度有了较大的提高,解决了单一模型参数寻优困难且耗时长的问题。
