分路段差异化收费条件下货车司机出行路径选择意愿模型
2024-01-02刘拥华段瑞坤段莉珍申科秦雅琴
刘拥华, 段瑞坤, 段莉珍,, 申科, 秦雅琴
(1.昆明理工大学交通工程学院, 昆明 650504; 2.云南省交通科学研究院, 昆明 650011)
近年来,受疫情和经济下滑的影响。一些原本在高速公路上通行的车辆(尤其是收费较高的货运车辆)为了降低出行成本,转而选择普通公路进行出行。不仅给普通公路造成交通拥堵,还造成普通公路管理维护压力过大,也导致了一些地区的高速公路资源存在严重浪费的现象[1]。面对如此困境,2016年由交通部提出的高速公路差异化收费政策将是解决此困境最有效的手段[2]。差异化收费主要是通过经济杠杆作用,调整货车司机的出行时间和路径选择。以起到改善路网流通质量、提高物流运输效率和降低物流运输成本的作用[3]。目前,常见的差异化收费方式主要有分路段、分时段、分方向、分支付方式和分车型等多种方式。
既有研究已对高速公路差异化收费政策下的合理收费费率和差异化收费政策下货车司机出行路径选择进行了探讨。Cheng等[4]研究了考虑交通流动态演化过程,提出了最小最大后悔模型来解决拥堵状态下不平衡交通流的动态费率。王林等[5]根据湖北省目前的分车型收费情况,提出了一种有效降低出行成本,同时确保高速公路运营企业能够获得一定利润的分路段分车型的差异化收费模式。Politis等[6]分析了高速公路与平行公路之间选择行为特征,从中发现出行时间会对货车司机的出行决策产生重大影响。孔德学等[7]将多项Logit模型、巢式Logit与潜在类别模型相结合,刻画出了出行方式之间的相关性与货车司机出行选择的偏好性。
既有研究多关注如何合理有效地确定差异化收费政策下高速公路的收费费率和差异化收费政策下货车从高速公路转向平行公路或者从平行公路转向高速公路的车辆比例。较少关注差异化收费政策对货车司机出行路径选择的影响程度。此外,现有的研究多是基于传统的统计模型分析差异化收费对货车司机路径选择行为的影响,其模型结果仅给出差异化收费变量与货车司机出行路径选择之间的统计显著性。无法量化各个属性变量对货车司机出行路径选择的影响程度[8-9]。因此,有必要构建目前正处于如火如荼的机器学习模型来量化捕捉差异化收费变量对货车司机出行路径选择的影响程度,从而为差异化收费政策的有效实施提供有效的理论依据[10]。
1 数据描述与指标选择
1.1 数据描述
对银昆高速(G85)昭通至水富段实行分路段差异化收费方式,其具体措施是在该路段原费率的基础上进行打折活动。为了确定分路段差异化收费条件下,货车司机出行路径选择的影响因素,对银昆高速(G85)昭通至水富段及麻水线与昭麻二级路等相关道路上展开问卷意向调查。在调查过程中发现银昆高速(G85)的平行路段麻水线与昭麻二级路在不同的地点道路条件存在较大的差异。为了得到更加真实反映差异化收费条件下,货车司机的出行意向选择。分别在昭通南站、靖安站、大关站、岔河站与庙口站展开问卷调查。本次调查分别在每个站点发放问卷132份,发放问卷合计660份,有效问卷636份,问卷有效率为96.36%[11-12]。有效问卷统计性描述如表1所示。

表1 问卷统计描述信息Table 1 Statistical description of questionnaire
1.2 指标选择
从货车驾驶员出行选择行为产生的内在动力和外生环境出发,车货属性特征和出行特征作为内在因素影响其出行选择行为,而分路段差异化收费政策则作为货车驾驶员出行选择行为的外部因素,因此将解释变量分为分路段差异化收费变量和非分路段差异化收费变量两类,共同纳入研究的范畴。其中,车货属性特征和出行特征指标依据现有的分路段差异化收费条件下货车出行行为研究选取[1,7,10],分路段差异化收费的描述指标则选取优惠折扣、收费费率、出行费用、出行距离和是否关注差异化收费政策这五项指标,其变量描述性统计结果如表2所示。
2 分路段差异化收费条件下货车司机出行路径选择的RF模型构建
2.1 模型选取
由于影响因素的单位和数量级等存在较大的差异,传统的统计模型很难估计出分路段差异化收费变量对被解释变量的影响程度[13]。现构建随机森林(random forest,RF)模型来分析分路段差异化收费对货车司机路径选择行为的影响程度。RF是在Bagging集成的基础上,进一步在决策树的训练过程中引入随机变量。RF模型在特征变量重要度选择方面具有高精度、高效率等特点[14]。以及能反向评估各个输入参数对目标值的相对重要性,对于各变量之间的多重共线性具有一定的包容性。同时,RF模型对噪声数据和不平衡数据具有很好的预测效果。十分符合本研究数据类型和模型构建的思想。

表2 变量描述表Table 2 Variable description table
2.2 模型原理
随机森林是由多棵决策树{h(X,θk),k=1,2,3,…}组成的集成算法,其中h()为联合熵;X、θk为随机变量,决定了训练集的随机抽取和候选分裂属性的随机选择。随机森林算法的具体过程如图1所示[14-15]。
(1)将原始数据集按照8∶2的比例划分成为训练数据集和测试数据集。

图1 随机森林构建过程Fig.1 Random forest construction process
(2)从划分好的训练数据集中随机选取N个训练数据集样本,得到一个自助训练集L[14]。
(3)用L作为训练数据,建立决策树T。然后针对每个分析节点,在M个特征属性中随机选取m个特征属性,作为候选分裂的属性。根据Gini指数,在m个特征或属性变量中选取一种加以拆分。然后重复以上步骤,直到树可以对所有测试数据作出正确划分[14]。
3 实证分析
以银昆高速(G85)昭通至水富段及麻水线与昭麻二级路问卷调查数据为基础进行实证分析。分路段差异化收费条件下,货车司机选择高速公路进行出行的意向在模型中体现为肯定类别的发生概率,当概率越接近1时,分路段差异化收费条件下,货车司机选择高速公路出行的意愿越强烈[15]。
3.1 模型超参数确定
模型超参数的选取会极大地影响模型的预测效果。在现有的研究中,模型超参数的选取主要依赖于经验[15-16],这可能会影响模型的整体效果。为了得到更加准确的预测结果,采用网格搜索法对所有超参数组合进行交叉验证,并以错误率为判断依据[17]。对RF模型的树的数量和最大特征值这两个超参数进行优化。调参过程如图2所示。从图2中可以看出最佳超参数取值为树的数量191、最大特征值2。
3.2 整体效应分析
本文讨论的对象为分路段差异化收费条件下货车司机出行路径选择意愿,为二分类变量,RF模型在python中的Scikit-learn库中求解。模型的整体结果如表3所示。

图2 超参数调整过程Fig.2 Super parameter adjustment process

表3 模型整体结果Table 3 Overall results of the mode
从相对重要度的角度来看,优惠折扣是影响货车司机出行路径选择的重要因素,其贡献程度为38.56%,其次是出行费用和出行距离,其贡献程度分别为13.55%和10.06%,这表明大多数货车司机在出行路径选择时,首要考虑其经济性和时效性。出行时段和车货总重的相对重要度相近,在5%~7.1%之间,这表明出行时段和车货总重对货车司机出行路径的选择会产生较为重要的影响。其次是车辆类型(3.45%)、不走高速公路的原因(3.14%)、收费费率(2.89%)和是否关注差异化收费政策(2.85%)。
3.3 边际效应分析
通过调用RF模型中的部分函数依赖PDP (partial dependence plot)方法,来探讨解释变量与货车司机出行路径选择之间的关系。
3.3.1 出行费用
从图3可以看出,出行费用与货车司机出行路径选择之间存在着明显的阈值效应,当出行费用大于200元时,货车司机选择高速公路出行的概率明显降低;当出行费用在0~600元时,出行费用对货车司机出行路径选择影响较为明显,而当出行费用达到600元以上时,出行费用对货车司机出行路径选择影响不明显。
3.3.2 出行距离
从图4可以看出,出行距离与货车司机出行路径选择之间存在明显的阈值效应,当出行距离大于200 km时,货车司机选择高速公路出行的概率明显降低;当出行距离在0~160 km时,出行距离对货车司机出行路径选择影响较为明显,而当出行距离达到160 km以上时,出行距离对货车司机出行路径选择影响不明显。
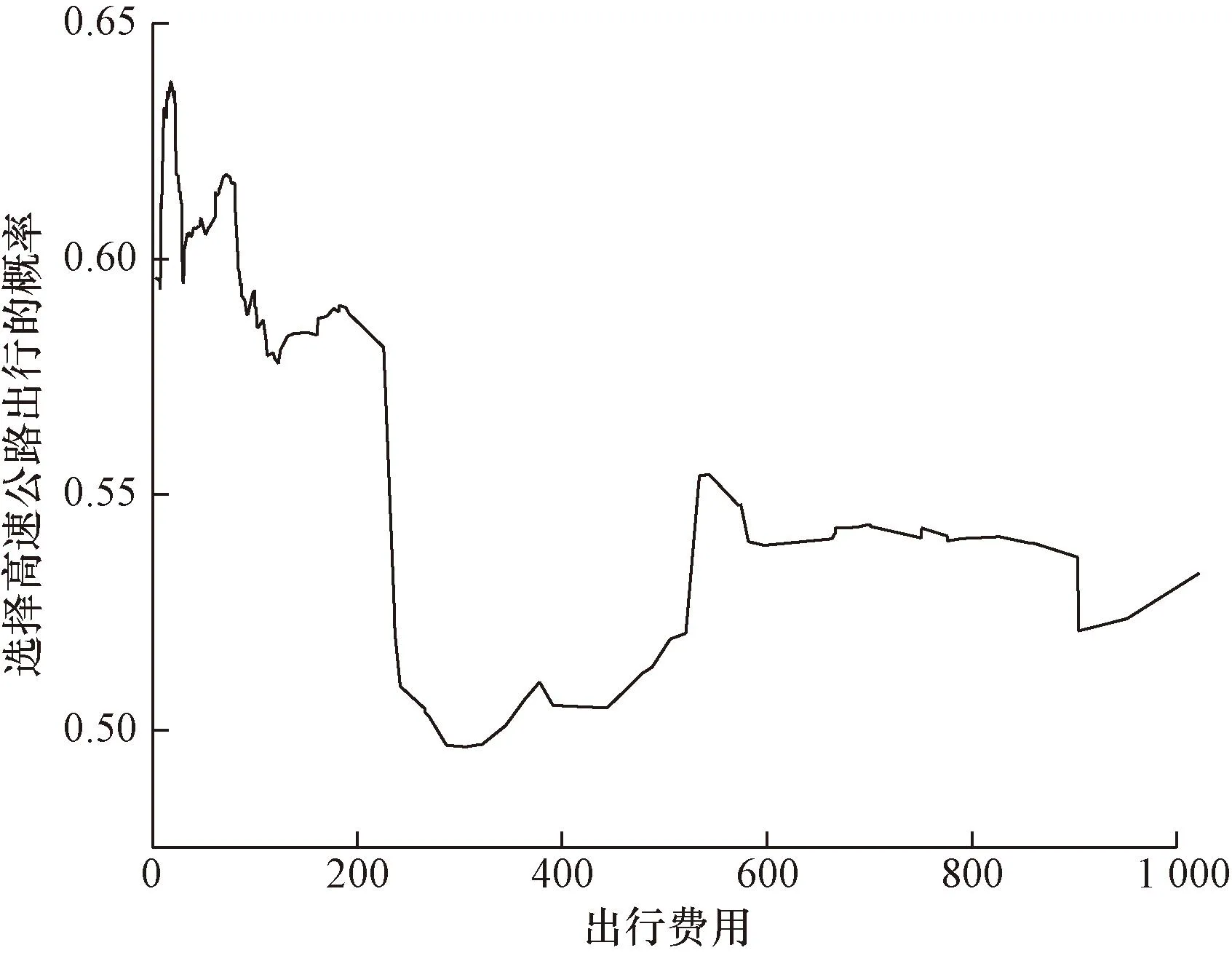
图3 出行费用与货车司机出行路径选择的关系Fig.3 The relationship between travel cost and truck driver’s travel route choice
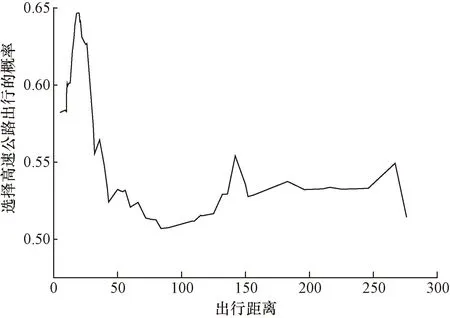
图4 出行距离与货车司机出行路径选择的关系Fig.4 The relationship between travel distance and truck driver’s travel route choice
3.3.3 优惠折扣
从图5可以看出,优惠折扣与货车司机出行路径选择之间存在明显的阈值效应,当优惠折扣为5~6折,货车司机选择高速公路进行出行的概率高达89.3%和81.6%,而当优惠折扣为8折和9折时,货车司机选择高速公路出行的概率仅为35.5%和22.6%。该分析结果与整体效应分析的结果相一致,优惠折扣对货车司机出行路径选择会产生较大。
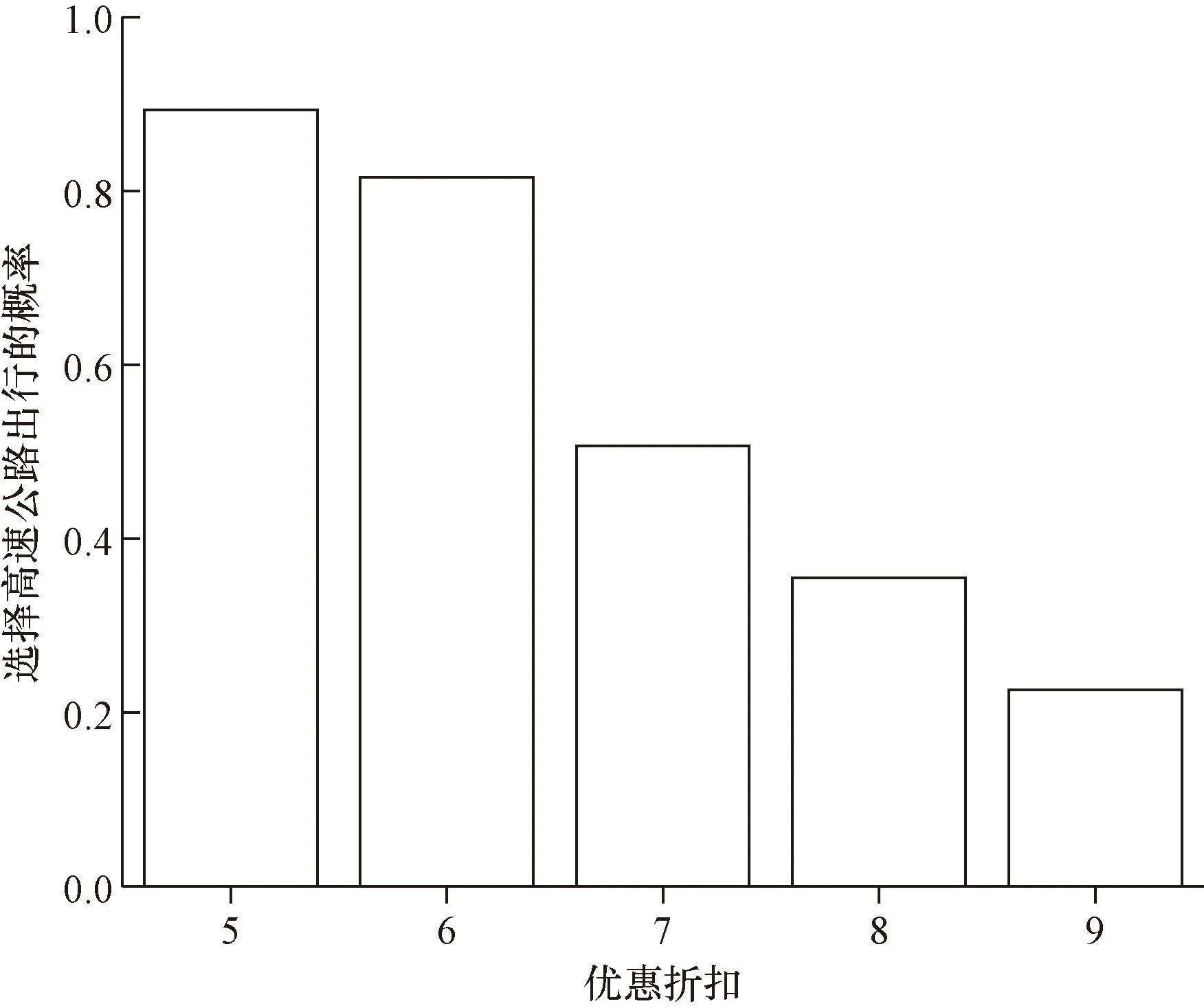
图5 优惠折扣与货车司机出行路径选择的关系Fig.5 The relationship between preferential discount and travel route choice of truck drivers
3.4 模型比较
为得到最准确预测货车司机出行路径选择的方法,选择目前最为常用的随机森林法(RF)、迭代算法(AdaBoost)、梯度提升迭代决策树(gradient boosting decision tree,GBDT)和传统Logit模型,通过使用相同的训练数据集和测试数据集来训练这些模型并评估其性能。
AdaBoost在处理分类问题时,首先会给不同的样本附上一个不同的权重,被分错样本的权重在Boosting过程中会被放大,因此新得到的模型会更加关注这些被分错的样本。而被分正确的样本的权重在Boosting过程中会变小。接下来AdaBoost算法会将新得到的权重输入新的模型中进行训练,从而得到基模型。最后AdaBoost将这些基模型组合起来,并根据错误率赋予不同的权重集合成新模型[18]。
GBDT算法与AdaBoost算法不同,GBDT算法会在加权的基础上定义一个损失函数,并对损失和机器学习所得到的函数进行求导,新生成的模型都是沿着基模型负梯度方向进行优化,直到找到最优的模型。
NL模型是一种统计回归分析模型,它会给出每个选项的选择概率,作为所有选项的效用函数。本文中采用最大似然法来对模型进行估计。
为了更加科学地进行模型性能比较,使用精确率(precision)、召回率(recall)和AUC(area under curve)值对模型的性能进行比较。基于混淆矩阵计算这3个性能度量指标[19]。
(1)混淆矩阵。混淆矩阵是机器学习模型的原始基础之一,也是推导后续一系列评估指标的基础。其具体的混淆矩阵如表4所示[18]。

表4 混淆矩阵Table 4 Confusion matrix
(2)精确率。根据混淆矩阵,很容易计算出精确率。计算公式为

(1)
(3)召回率。根据混淆矩阵,计算公式为

(2)
(4)AUC指标。在坐标轴中绘制的ROC(receiver operating characteristic)曲线依赖FPR、TPR这两个指标,其计算公式为

(3)
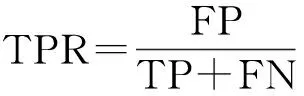
(4)
将FPR值作为横坐标,TPR值作为纵坐标,可得到一个二维坐标系。将机器学习模型得到的FPR值与TPR值映射到这个二维坐标系中,用一条曲线将其连接起来便得到了ROC曲线,而AUC值则是ROC曲线与横坐标围成的面积[19]。
图6所示为RF模型、AdaBoost模型、GBDT模型和传统Logit模型的性能对比结果图,可以观察到RF模型的精确率(precision)、召回率(recall)、AUC值高于AdaBoost模型、GBDT模型和传统Logit模型。

图6 模型性能对比结果图Fig.6 Comparison results of model performance
因此,本文构建的分路段差异化收费条件下货车出行路径选择的RF模型具有较高的可靠性。
4 结论
(1)以银昆高速(G85)昭通至水富段及麻水线与昭麻二级路问卷调查数据为基础,对分路段差异化收费条件下,货车司机出行路径选择进行建模,模型整体结果表明,所构建的RF模型具有较高的预测精度,同时非线性模型也能够很好的捕捉分路段差异化收费条件下,货车司机选择高速公路出行的变化趋势。
(2)相对重要度方面,优惠折扣是影响货车司机出行路径选择最重要的因素(38.56%),其次是出行费用(13.55%),出行距离(10.06%)以及出行时段(7.08%)对货车司机出行路径选择的影响也较为显著。
(3)边际效应分析表明,当出行费用大于200元时,货车司机选择高速公路进行出行的概率将明显降低;当出行距离在0~160 km时,货车司机选择高速公路进行出行的概率波动较大;当优惠折扣大于7折,货车司机选择高速公路进行出行的概率将明显提升。
(4)模型性能对比结果表明。本文所构建的分路段差异化收费条件下货车司机出行路径选择的RF模型的分类准确率优于AdaBoost模型、GBDT模型和传统Logit模型。
