日志信息加权关联分析方法
2024-01-02李文钊董晓炜赵思亮
李文钊,董晓炜,王 新,赵思亮
(1.重庆市气象信息与技术保障中心,重庆 401147;2.重庆赛宝工业技术研究院有限公司,重庆 401331)
0 引言
气象信息中心在业务系统运维过程中经常需要通过大量的软硬件日志信息分析、判断和处理系统存在的不足、隐患和故障等,以期达到系统稳定运行的目的。然而,这些日志信息通常存在大量冗余,如a点和b点的告警是c告警点造成的;o点的故障可能造成p或q点同时告警等。简单系统的日志源较少,其关联关系很容易确定,但由于气象业务系统较大,其中包含路由器、防火墙、IDS/IPS、交换机、服务器和数据库等各种类型的设备,且规模涉及整个地区,因此确定其关联关系十分困难。运维工作需先于用户发现故障,降低故障发生率甚至杜绝业务中断,要求工作人员能够在大量的冗余信息中确定各告警点的关联关系,变被动的故障修复为主动的性能优化。快速精确地找到源故障点是对气象业务系统运维工作提出的全新要求。
系统故障往往不是独立产生的,而是与其他事件相关联。一般Apriori,FP-growth等典型数据关联规则算法在一定程度上能够解决日志信息冗余的问题。Apriori算法通过多次扫描事务集,利用候选频繁项集产生频繁项集;FP-growth算法利用FP-树构建频繁项集,不产生候选项集,可在一定程度上减少事务集扫描频次。Apriori算法扩展性较好,且易于实施分布式并行化,满足系统实时性要求。文章主要依据Apriori基本思想分析处理日志信息的关联规则[1]。然而,通过对日志信息的研究,发现每条日志在考察范围内的重要程度不同,如设备的电源故障比网络延迟故障重要得多,用传统的Apriori的相同支持度和置信度阈值来计算不同重要程度事件的关联规则显然不能真实地反映事物本质。因此文章提出一种引入日志信息权重的加权关联分析方法。
1 日志信息数据模型
各种设备的类型、应用软件或操作系统各不相同,其日志数据也不尽相同。对这样的异构数据进行关联分析,首先需要建立统一的基于Apriori算法的日志数据模型和确定权重,并且把一个时间段内出现的告警看作是同一告警事务来考察。日志数据结构如表1所示。

表1 日志数据结构
日志信息预处理过程如下:
1)数字或字母:根据日志信息定义确定编号、权重。
2)故障代码:根据日志故障代码定义确定编号、权重。
3)文本:根据文本语义,用正则表达式确定编号、权重。
2 日志信息权重的定义和赋值
Apriori算法是一种基于事务出现频次的关联规则算法,项目(单个日志告警点)的权重须用关于频次的量来表征[2]。文章定义:Wx是Px点的权重,Wx等于Px出现的频次,即每出现Px次加权相当于出现了一次Wx次告警点。Wx可赋值为正整数(1,2,3,…),显然传统Apriori算法的Wx都为1。
目前对日志信息权重的赋值还没有统一的标准。依然需要日志和对应故障现象的大数据作为依据,由运维人员根据经验主观赋值,文章旨在研究关联分析方法,建立算法框架,假定日志信息权重已经确定为常量。
3 支持度和置信度阈值的确定原则
支持度阈值和置信度阈值即最小支持度和最小置信度,是界定是否关联和是否能够接受该关联的重要指标,与日志信息权重一样,也是需要根据数据和场景(日志和对应故障现象)的接受程度来确定的常量[3]。两种参数阈值的设定,对算法解决问题的优劣影响很大。如果支持度和置信度阈值设置过高,一些隐含在数据中的非频繁特征项就会被忽略掉,难以发现足够有用的规则;如果支持度和置信度阈值设置过低,又可能产生过多无意义的规则。可以根据实际日志告警点的数量及其间可能存在的相关性,用比较明确的小样本数据,通过反推来试选支持度和置信度阈值。
4 加权关联规则算法
引入日志信息权重后,含有权重项目的事务的频次发生了变化,事务总量也随之变化。各项、项集的支持度以及关联规则的置信度也将发生改变。加权关联规则计算方法如下。
4.1 算法参数调整
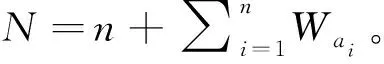
那么项集X的支持度数如式(1)所示:
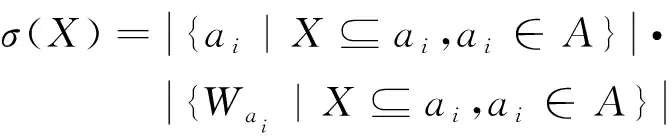
(1)
X→Y为关联规则(X∩Y=∅),则X→Y的支持度s(X→Y)=σ(X∪Y)/N;X→Y的置信度c(X→Y)=σ(X∪Y)/σ(X)。
4.2 算法描述
按照章节4.1加权调整参数后,使用统一的支持度阈值min_Sup和置信度阈值min_Conf进行处理。算法描述为:
挖掘频繁项集
C1=Generate_C1(A);
L1={c∈C1|C_Sup(c)>=min_Sup};
C2={{x,y}|x∈L1,y∈C1且σ(x)<σ(y)};
L2={c∈C2|C_Sup(c)≥min_Sup};
For(k=3;Lk-1≠∅;k++){
Ck={{X,y}|X∈Lk-1,y∈C1
且σ(X)<σ(y)};
Lk={c∈Ck|C_Sup(c)≥min_Sup};
};
L={Li|i=1,2,…,k}。
其中,Generate_C1(A)函数为扫描事务集合A获得一维候选项集;Ci为i维候选项集;Li为i维频繁项集(i为正整数);C_Sup(c)为候选项集c的支持度;σ()为项集数目。需要说明,这里的Generate_C1(A)函数对事务集合的扫描也必须做加权处理,即每条事务要扫描Wai次。
产生强关联规则
Support(X)=σ(X)/N;
Support(Y)=σ(Y)/N;
Confidence(X→Y)=Support(X∪Y)/Support(X);
Strongrules(X→Y)={X→Y|Confidence(X→Y)≥min_Conf};
其中,Confidence(X→Y)为X→Y的置信度;Strongrules(X→Y)为X→Y的强关联数据集合。
5 算法验证和结果分析
文章用5个点的日志信息,10条由zabbix采集的现场告警事务数据,通过改变相关参数来验证算法的适用性,已知关联关系的现场数据预处理后(平权)如表2所示。

表2 现场数据
由于项数及事务总量为已知,在具体程序设计时,可以使用支持度数阈值min_σ代替支持度阈值min_Sup,一方面可以提高程序运行效率,另一方面可以避免小样本因计算比值而丢失有效数据。
min_Conf均为0.70,分析min_σ为2和min_σ为4的IntelliJ IDEA环境下的程序运行结果可知,支持度数阈值提高以后,频繁项数明显减少;同时强关联(置信度≥0.70)项即符合关联规则的项也在减少。日志信息点p4做权重为3的加权处理以后p1;→p4;的置信度从0.7142提高到0.8823,并产生了关于p4的新的强关联项。这是符合Apriori算法基本原则的,也与日志信息的重要程度所产生的影响一致。
6 结束语
日志信息是气象信息系统运维中的重要依据,高效地利用日志信息需要以有效地挖掘各种日志信息之间的联系为前提。文章提出的增加正整数权重的日志信息关联规则分析处理方法是在成熟、传统的Apriori算法基础上通过调整有关参数实现的,因此不需要对Apriori做合理及可靠性论证。验证结果充分表明了该方法符合日志故障规律,可以有效地解决不同重要程度的日志信息关联问题。
