基于改进Faster R-CNN的食品包装缺陷检测
2023-12-27夏军勇王康宇周宏娣
夏军勇 王康宇 周宏娣
(湖北工业大学机械工程学院,湖北 武汉 430068)
食品在生产过程中,外包装不可避免会出现部分缺陷[1],如撕裂、破损或破洞,这些缺陷会使包装丧失完整性,进而导致食品在运输和存储过程中被挤压、碰撞或摔落。传统的人工检测方法不仅效率低,还会出现漏检的情况[2]。近年来,深度学习在工业中的应用越来越广泛,陈雪纯等[3]提出了一种改进MobilenetV2的轻量化包装缺陷检测方法;李志诚等[4]基于改进的YOLOv3算法,提高了卷纸包装缺陷检测的准确率和速率;暴泰焚等[5]采用一种基于深度学习中语义分割任务的表面缺陷检测方法,实现了对纸质包装表面缺陷进行检测。目前,深度学习在缺陷检测方面应用较广,但也存在一些不足,如对包装盒缺陷进行分割检测的精度较低[5],无法满足工业使用要求;对中小目标检测效果较差[6],容易产生漏检等;一阶段目标检测模型[7]检测速度快,但检测精度受限;二阶段目标检测模型精度较一阶段目标检测模型高[8],但检测速度较慢。
为实现对纸质包装盒缺陷进行准确的识别与定位,研究拟在检测精度较高的二阶段目标检测模型Faster R-CNN[9]上进行改进,提出一种能够对纸质包装盒缺陷进行识别的模型。通过3个方面(ResNet50网络[10]融合特征金字塔结构、双线性插值法和聚类)的改进提高模型的检测准确性,以期对食品纸质包装缺陷的检测研究提供参考。
1 材料与方法
1.1 数据预处理
图片数据采集于某纸板生产厂,共包含1 000张包装盒缺陷图片,图片格式为jpg,大小包括1 080像素×1 440像素和1 440像素×1 080像素两种,比例约为1∶1,使用labelImg软件进行标注,标注的标签为VOC格式。将数据集中的图片按照8∶2的比例随机划分,得到800张用于网络模型训练的图片和200张用于模型效果验证的图片,训练集图片与验证集图片没有交集。由于数据集较小,为了得到更好的训练效果,采用随机水平翻转以及垂直翻转对训练集图片进行数据增强处理[11]。此外,为了增强模型的鲁棒性,对训练集图片随机添加高斯噪声[12]。经过数据增强后的训练集图片为4 000张,预处理后的图片如图1所示。

图1 预处理后图片
1.2 网络模型的改进
1.2.1 原始网络模型Faster R-CNN Fast R-CNN是二阶段目标检测模型中的经典,而Faster R-CNN是其改进版。Faster R-CNN模型分为4个主要部分:特征提取网络(卷积)、区域候选网络(region proposal network)、兴趣域池化层(RoI pooling)及分类与回归,其中RPN网络预先产生大量候选框,使得Faster R-CNN相比于SSD[13]、YOLOv3[14]和YOLOv4[15]等一阶目标检测算法能够实现更好的检测精度[16-17]。其工作原理:利用特征提取网络提取图像特征,将特征输入RPN网络,RPN网络根据预先设定的锚框尺度和比例,在特征图上生成一系列的建议框,经过NMS极大值抑制后获取最终建议区域。将建议区域与图像特征融合后输入到RoI pooling对建议区域进行池化,以便将尺寸不固定的特征图转变为固定的尺寸[18],用于后续的全连接层进行目标分类和边界框回归。Faster R-CNN模型结构如图2所示。
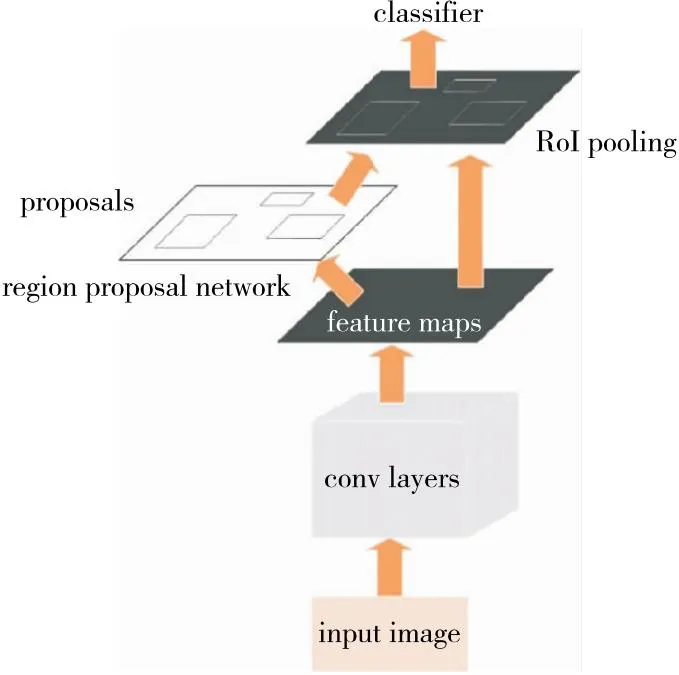
图2 Faster R-CNN模型结构
1.2.2 改进Faster R-CNN后的模型 图像特征图层次越浅,细节信息越丰富,语义信息越弱;图像特征图层次越深,细节信息越少,语义信息越强。为了更好地提取包装盒缺陷的特征,提高模型的泛化能力,选择使用更加深层次的特征提取网络,但是深层次的网络可能会造成梯度消失或梯度爆炸,并且产生网络退化。在ResNet50网络中,引入BN层(batch normalization)解决梯度消失或梯度爆炸的问题,并且引入残差(residual)解决网络退化的问题。故采用层次较深且性能较好的ResNet50替换Faster R-CNN中的特征提取网络,ResNet50网络结构如图3所示。
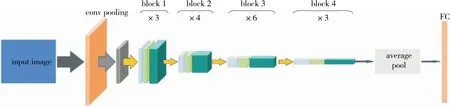
图3 ResNet50网络结构
数据集中部分缺陷尺度较小,采用深层次的特征提取网络可能会造成信息丢失,影响模型的精度,FPN(feature pyramid networks)网络中采用自下而上和自上而下的结构对图片特征进行处理[19],使得包含小目标特征的尺度较大的特征层参与后续的预测与回归,提高模型的精度,FPN网络结构如图4所示。为了进一步提高模型的性能,引入FPN结构,将ResNet50与FPN进行融合,在提取更强语义信息的同时减少信息的丢失,图5为融合后的网络结构。

图4 FPN (feature pyramid networks)网络结构
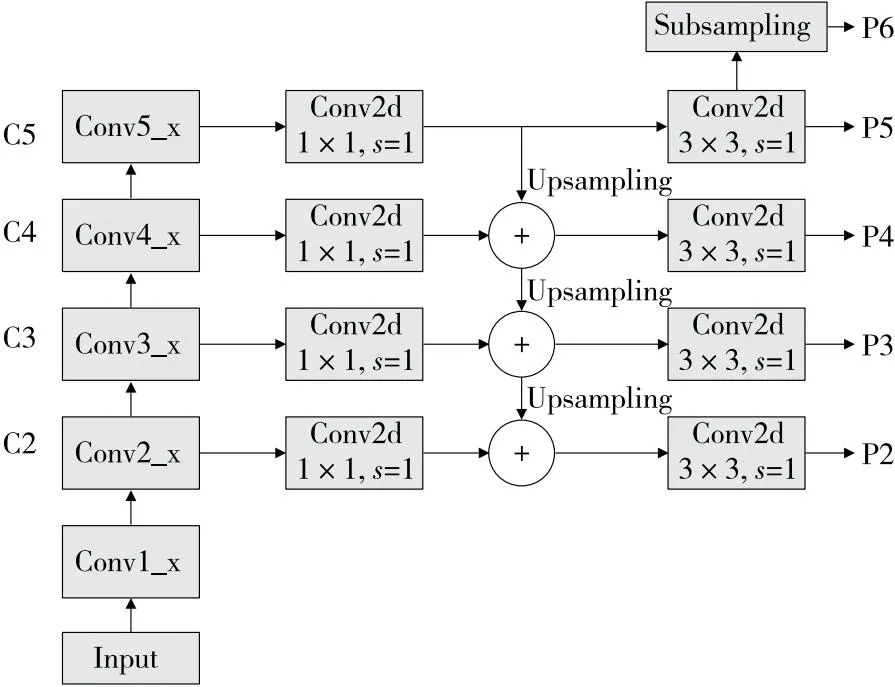
图5 ResNet50+FPN网络结构
使用ResNet50+FPN网络进行特征提取时,特征图尺寸对比原图缩小32倍, RoI pooling经过两次浮点数取整量化,会造成后续回归精确度下降。为了解决这一问题,Mask R-CNN中使用了RoI Align[20](图6),通过双线性插值法,保留浮点数,避免取整对精度带来的不良影响。在模型中引入RoI Align结构,避免其精度下降。

图6 RoI Align
Faster R-CNN中的锚框尺度与数据集不同,原始锚框比例为0.5,1.0,2.0,但数据集中标注框的尺度不一定与原始锚框相同,不合适的锚框尺度可能需要更多的训练迭代才能收敛,这样会增加训练时间和计算成本,而且锚框的尺度设置可能会影响模型对目标的敏感性,如果锚框的尺度过大或过小,可能会导致目标的漏检或误检。为了得到更加接近真实标注框的锚框尺度,选择使用K-means++对数据集中的标注框进行聚类,聚类后结果如图7所示,得到3个聚类中心(552,1 113)、(352,337)、(1 126,426),故将锚框比例由原始的0.5,1.0,2.0修改为0.49,1.0,2.6。

图7 K-means++聚类结果
改进后的网络模型如图8所示。

图8 改进后的网络模型
1.2.3 损失函数 在模型训练过程中损失函数用来对模型进行评估和对参数进行优化,Faster R-CNN网络结构中包含分类损失和回归损失,损失函数公式定义为:
(1)
式中:
pi——第i个锚框预测为真实标签的概率;

ti——第i个锚框的边界框回归参数;

Nc——分类样本数;
Nr——回归样本数;
Lc——分类层损失;
Lr——回归层损失;
λ——权重系数。
分类损失公式定义为:
(2)
回归损失公式定义为:
(3)

(4)
1.3 试验方法及模型评估方法
1.3.1 试验模型对比 为验证网络模型的有效性,将其与不同的目标检测网络进行对比。选取一阶段目标检测模型中的YOLOv3和YOLOv4作为对比对象,YOLOv3由于其速度快,适合在实时检测场景中使用,检测精度较高,对小目标也具有一定的检测能力,但是在复杂场景中检测精度可能会降低;YOLOv4在YOLOv3的基础上进行了改进,在复杂场景中的表现优于YOLOv3。研究所选二阶段目标检测模型Faster R-CNN在检测精度上有优势,但是检测速度较一阶段目标检测模型慢,对比使用VGG16和ResNet50作为特征提取网络的Faster R-CNN模型,由于ResNet50网络层次较深,所以提取深层次特征信息能力较强,但检测速度稍慢;在ResNet50网络中融入特征金字塔网络可以进一步提升其提取特征的能力,防止小目标特征信息丢失,提高模型的检测精度;使用K-means++对模型候选框尺度进行优化后,可以使建议框的尺度更加接近真实的区域,减少训练时间,并提高检测精度。
1.3.2 试验方法及参数设置 对不同网络模型使用相同训练集与测试集,对比在测试集上的表现。所有模型训练环境为Linux系统,训练框架为Pytorch,版本为1.11.0,CUDA版本为11.4。所有试验模型均使用迁移学习的方法进行训练,训练时batch size设为4,训练30个epoch,初始学习率设置为0.01,对学习率使用SGD优化器进行优化(每经过3个epoch学习率衰减为原来的0.33倍),其中动量(momentum)设置为0.9, 权重衰退(weight_decay)参数设置为0.000 1。经过多次试验后发现,Faster R-CNN系列模型RPN中进行NMS处理时使用的IoU(预测框与真实框重叠部分占两者集合区域的比例)阈值设置为0.7时能取得较好的效果。试验模型见表1。

表1 试验模型
1.3.3 模型评估方法 目标检测算法的检测结果共4类:TP(正样本预测为正)、TN(负样本预测为负)、FP(负样本预测为正)、FN(正样本预测为负)。为对比所提算法模型与其他算法模型的性能,采用精确率P(precision)、分类召回率R(recall)、平均精度AP(average precision)对模型性能进行评估[21]。
精确率计算公式如式(5),用于评估模型检测缺陷的准确性。
(5)
式中:
P——精确率,%。
召回率计算公式如式(6),用于评估模型找到缺陷正样本的能力。
(6)
式中:
R——精确率,%。
平均精度计算:
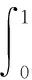
(7)
式中:
AP——平均精度,%;
P——准确率,%;
R——召回率,%。
2 结果与分析
2.1 检测精度对比
如表2所示,一阶段网络模型YOLOv3和YOLOv4在IoU为0.5时的AP值明显低于二阶段网络模型Faster R-CNN。分别使用VGG16和ResNet50作为Faster R-CNN特征提取网络时,AP值无明显差别,但是使用ResNet50融合特征金字塔作为特征提取网络时,精度和召回率有明显的提升。进一步使用RoI Align后,IoU为0.5时的AP值对比只使用ResNet50作为特征提取网络的模型提升了3.3个百分点,而IoU为0.75时的AP值提升了16.9个百分点,IoU为0.5/0.95(预测框与真实框重叠部分占两者集合区域的比例从0.5以0.05的增量到0.95)的召回率提升了6.8个百分点。使用K-means++对锚框尺度进行修改后IoU为0.5和IoU为0.5/0.95时的AP值进一步提高了0.5个百分点,IoU为0.5/0.95的召回率提高了0.4个百分点,但是在IoU为0.75时的AP值反而下降了1.5个百分点。由结果分析可知,二阶段检测模型在检测精度上的表现更加出色,明显高于一阶段检测模型;使用ResNet50+FPN作为特征提取网络时模型精度和召回率均有明显提升,证明特征金字塔网络对小目标检测的有效性。

表2 缺陷AP和召回率
2.2 训练损失结果对比
图9为模型G与模型F训练时损失结果对比,可以看出,在同样的学习率下,初始训练时模型G损失低于模型F,证明使用K-means++对数据集进行聚类后得到的锚框尺度与真实标注框更加接近,对加快网络训练起到了积极的作用。
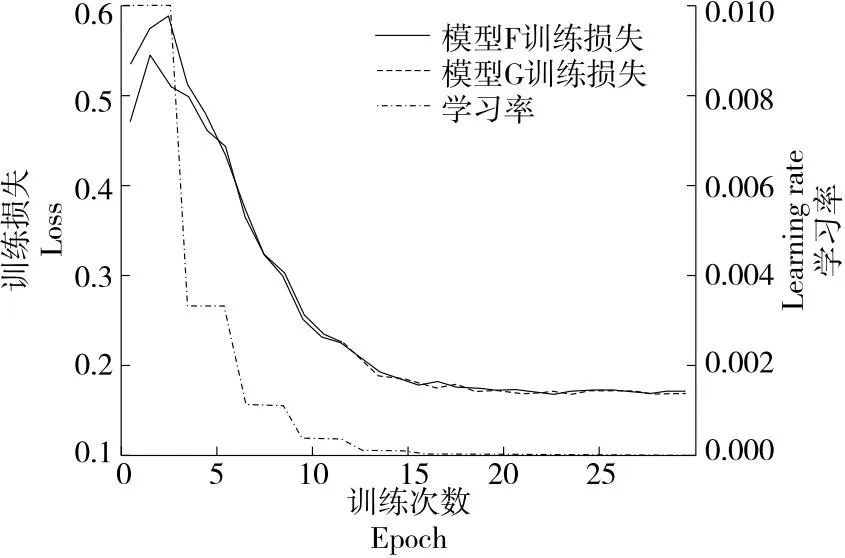
图9 训练损失结果
2.3 检测速度对比
如表3所示,模型G检测速度为8.65帧/s,由于Faster R-CNN检测模型在进行目标预测时需要经历区分前景与背景和提取对应特征图上特征这两个阶段,而YOLO系列模型只需要一次性产生预测结果,所以YOLO系列的检测速度明显比Faster R-CNN系列模型高。

表3 检测速度对比
2.4 模型预测结果
利用训练好的网络模型对缺陷图片进行预测,预测结果包含预测框和置信度,分别表现模型的回归准确性和分类准确性。模型A和模型B预测结果见图10。

图10 模型A和B预测结果
使用VGG16和使用Resnet50作为Faster R-CNN模型的特征提取网络时,相比较于YOLOv3和YOLOv4,漏检情况有很大的提升,每个缺陷的置信度比较接近,均能够准确识别出缺陷。但是定位不够准确,某些框图尺度过大,与实际缺陷位置差别较大。模型C和模型D预测结果见图11。

图11 模型C和D预测结果
使用特征金字塔结构后,缺陷检测的定位准确率对比模型D有所提升,证明特征金字塔结构能够提升网络对包装盒缺陷的检测能力。模型E预测结果见图12。

图12 模型E预测结果
对比模型F和模型G的预测结果可以看出,是否使用K-means++在检测精度上无明显的差别,但是使用K-means++的模型G在某些缺陷上生成的标注框比模型F更加接近真实缺陷范围,由此可见,对数据集进行聚类对提升模型的回归精度有一定的帮助。模型F和模型G的预测结果见图13。

图13 模型F和G预测结果
3 结论
使用改进的Faster R-CNN网络模型对包装盒缺陷进行检测,改进后的模型在验证集上的平均准确率达到了93.9%,检测速度达到了8.65帧/s,满足工业使用的需求。使用特征金字塔网络后的模型在精度和召回率上都有明显的提升,证明特征金字塔网络在小目标检测中的有效性,对数据集使用聚类之后,模型的训练速度以及回归精度都有所提升。虽然研究使用的模型在精度上的表现比较出色,但是在检测速度上还有提升的空间,一阶段目标检测模型的速度基本能够满足实时检测的需求,但是精度不高。因此,下一步需要研究的是如何在保证检测精度的同时提升检测速度。
