基于改进YOLOv5s的轻量化车辆目标检测算法
2023-12-26舒腾辉
舒腾辉,丛 屾
(黑龙江大学 机电工程学院,哈尔滨 150080)
0 引 言
近年来,基于深度学习的人工智能技术取得了重大突破,深度学习在各领域都有着良好表现[1-2]。自动驾驶在智能交通领域变得越来越受到关注。在自动驾驶领域中,主要的检测对象是行驶在道路中的车辆,为了使自动驾驶在车辆目标检测任务中有些良好的表现,针对车辆的识别和归纳显得尤为重要[3]。
目前深度学习目标检测的方法主要分为one-stage、two-stage和anchor free的检测方法,针对two-stage检测算法中预设anchor情况,冗余框较多的问题,提出了anchor free,以达到实时高精度。而one-stage检测算法中的YOLO(You Only Look Once)[4-8]系列算法结合了anchor free,因此在车辆检测任务中,主要使用one-stage检测算法,相较于two-stage检测算法,检测速度更快,更适合对高速运行的车辆进行目标检测。其中,YOLOv1-v3主要的网络结构包括:负责特征提取的Backbone层、负责特征融合的Neck层,以及负责分类结果预测并输出的Head层。YOLOv3算法在Neck部分借鉴了特征金字塔的思想,引入了自底向上的FPN结构,在3个不同的尺寸上分别进行预测[9]。YOLOv4和YOLOv5算法在YOLOv3的基础上引入了自顶向下的PAN结构,即FPN+PAN相结合的形式,扩大了感受野,能够获得feature map的语义特征和位置信息。
在使用 YOLO 算法对车辆检测时,由于YOLO 模型的内存较大,对YOLO算法的轻量化是当前的研究方向。Howard A G等[10]提出了满足移动设备要求的高效模型MobileNets,采用深度可分离卷积构建轻量级网络,将卷积过程分解为深度卷积、逐点卷积两部分,实现通道内卷积和通道间卷积的分离,达到了减少模型参数量的目的;Liu W J等[11]利用深度可分离卷积设计了一种反残差模块,有效减少了模型计算量和存储量。霍爱清等[12]提出了改进的YOLOv3算法对车辆目标进行实时检测,其参数量比原有的减少了67%,提升了性能和效率。通过将深度可分离卷积引入YOLOv4-tiny的CSP架构。黄凯文等[13]成功地将网络的参数量降低了52%,从而显著改善了网络的反应能力。王银等[14]为了提升小目标车辆的检测性能,同样基于YOLOv4模型,在PAN结构中引入深度可分离卷积,同样也将参数量减少了42%,提升了网络响应速度。由此可见,轻量化网络结构MobileNet在减少模型参数有良好的表现,因此引入了MobileNet系列的v3版本,提出了一种将YOLOv5s算法与MobileNetv3-Large轻量级网络相结合的改进算法,提升其检测速度并降低网络的参数量。
1 轻量化网络MobileNet
Google从2017到2019年相继推出了轻量化网络MobileNet系列,MobileNetv1[10]提出了深度可分离卷积,MobileNetv2[15]在这基础上新增加了瓶颈残差模块,MobileNetv3[16]的网络架构将深度可分离卷积[17]和线性瓶颈技术有机地结合在一起,以提升其效率和可靠性,SE[18](Squeeze and Excitation)注意力模块以及h-swish函数的应用,提升了系统的运行效率。因此,本文采用MobileNetv3替换YOLOv5s的骨干网络,以此减少参数量。
MobileNet系列算法通过改变传统的卷积模型为深度可分离卷积模型,使其能够更有效地处理复杂的问题,从而降低计算量和参数量,并且加快运行速度。深度可分离卷积由深度卷积和1×1的逐点卷积两部分组成。通过使用滤波器和线性组合技术,可大幅度降低参数的复杂度,节省计算成本。
MobileNetv3网络结构是该系列中最先进的算法,特点是模型尺寸小、参数量少,且精确度较高,能够满足多种复杂的分类、检测、图像分割等需求,并能够在多种计算能力水平上得到良好的运行效果。作为基础模块的Bneck结构,采用1×1的卷积技术,可有效地提高维度,从而更好地利用高维空间中获取的特征信息来进行深入研究;采用深度可分离卷积技术,并将SE模块融入其中,以实现对各种通道的权重的有效调节,提高系统的性能和效率;采用1×1的卷积算法,可有效地减少维度,而当步长设定为1时,可对输出和输入进行残差处理。Bneck结构见图1。
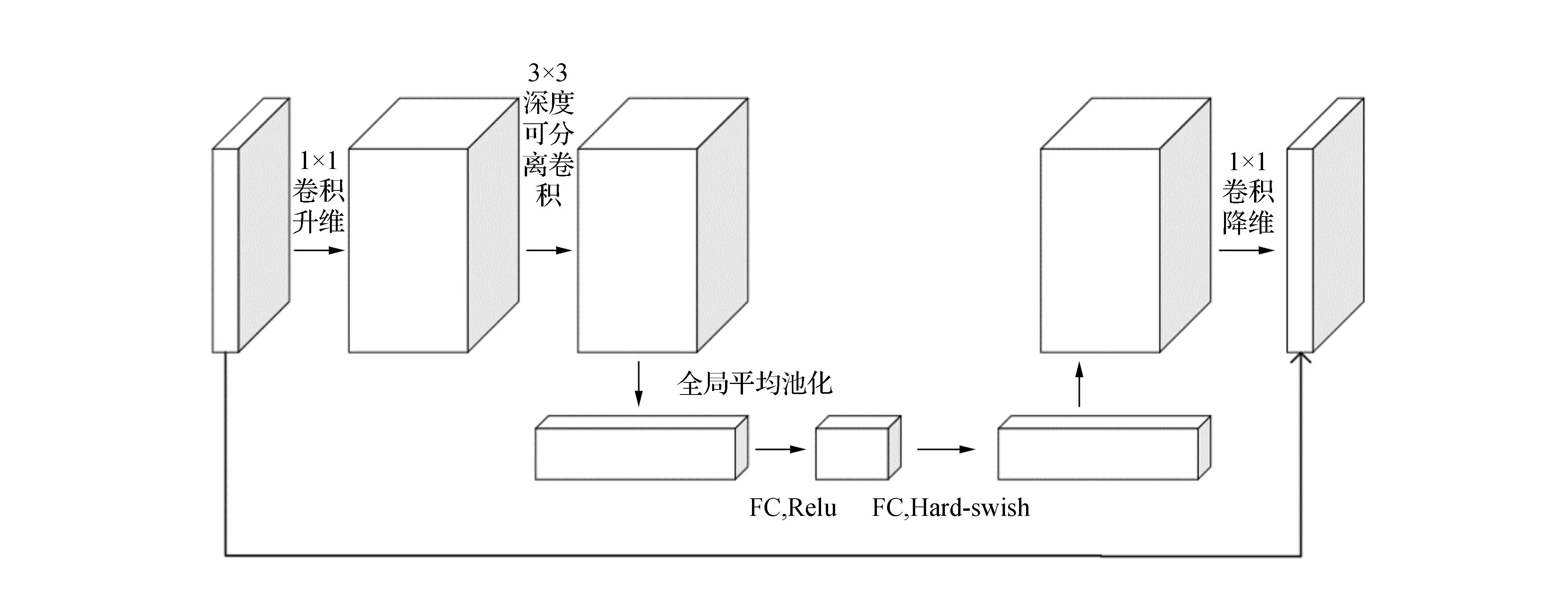
图1 MobileNetv3的Bneck结构Fig.1 Bneck structure of MobileNetv3
2 改进的YOLOv5s车辆检测算法
YOLOv5s[6]基于回归的One-Stage目标检测算法。采用MobileNetv3-Large网络取代YOLOv5s网络中的骨干网络CSPDarkNet53,以改善模型的性能,而其余部分则与原有模型保持一致,其结构见图2。

图2 YOLOv5s-M3网络结构Fig.2 Network structure of YOLOv5s-M3
由图2可见,YOLOv5s-M3在经过MobileNetv3之后,获得的特征矩阵96×13×13先是通过1×1卷积,得到48×13×13的特征矩阵,再输入到空间金字塔层(Spatial Pooling Layer,SPP)模块,通过在3个并列的最大池化处中进行下采样,由于每个步长均为1,因此得到的结果为48×13×13;然后,将结果与输入该模块的特征矩阵在深度上相加,得到182×13×13的特征矩阵;最后,使用96×96的卷积核进行卷积,使特征矩阵恢复为96×13×13。在颈部使用空间金字塔结构,特征金字塔[19](Feature Pyramid Network,FPN)自上向下传达强语义(High-Level)特征,路径聚合网络[20](Path Aggregation Network,PAN)则自下向上传达强位移(Low-Level)特征,两者联合,提高了特征信息提取能力。
YOLOv5s中含有3种损失函数,分别影响分类(cls_loss)、定位(box_loss)、置信度(obj_loss)。其中分类和置信度的损失函数采用的是BCE Blur With Logits Loss,为一种二元交叉熵损失函数;定位的损失函数采用的是CIOU[21]。
(1)
(2)
(3)
(4)
式中:b和bgt分别为预测框和真实框的中心点;ρ为计算两个中心点之间的欧氏距离;c为用来描述一个可容纳真实框和预测框的最小闭合区域,用来描述两个框之间的距离。v为衡量真实框和预测框相对比例的一致性;α为权重系数,不仅包含了面积交并比IOU,还包含了更多的考虑因素,这些因素构成了αv。
CIOU可准确地反映出物体的长宽比,但精确性取决于物体的位置和置信度,因此,如果忽略了这些因素,可能导致检测出现偏差。因此,采用EIOU[22]损失函数,EIOU是在CIOU基础上的改进,增加了长度与宽度的损失,以弥补CIOU的不足。表达式为
(5)
3 实验分析
3.1 实验数据集
实验数据集的选择:UA-DETRAC[23]数据集是取景于北京和天津的道路过街天桥。其中训练集约82 085张图片,测试集约56 167张图片,该数据集可用于多目标检测和多目标跟踪算法开发。实验所选取其中6 000张图片组成一个新的数据集UA-DETRAC-P,并将其按照6∶2∶2的比例将其划分为训练集、验证集和测试集。
3.2 实验环境与参数
实验在Windows 10系统中进行,选用型号为NIVIDA GeForce RTX3060的图形处理器(Graphics Processing Unit,GPU),加速环境为 CUDA 11.3,CUDNN8.2.1。在模型实验参数的中,设置迭代次数为200次,学习率为0.001,batch size为4。
3.3 评价指标
在实验过程中与不同算法的性能进行比较,主要评价指标是从平均精准率均值(Mean Average Precision,mAP)和检测速度(Frames Per Second,FPS)进行对比。在目标检测过程中,T和F表示分类是否正确,P和N分别表示正样本和负样本,TP(True Positives)表示正样本被正确识别,TN(True Negatives)表示负样本被正确识别,FP(False Positives)表示误测的负样本,FN(False Negatives)表示漏测的正样本。AP(Average Precision)为平均精度,即PR曲线上各精度值的平均值,表达式为
(6)
对于每个类别,按照上述方法计算AP值,并取所有待映射类别AP值的平均值:
(7)
精确率和召准率分别为
(8)
(9)
3.4 结果与分析
通过采用UA-DETRAC-P数据集对模型进行训练,并且针对改进步骤进行消融实验,通过对比参数量、mAP值和FPS来证实算法改进的有效性。通过采用优化骨干网络、调整损失函数以及将两种技术有机地结合,并对其采用消融实验进行验证分析,结果见表1。

表1 不同改进方法对算法性能的提升
由表1可见,针对骨干网络进行MobileNetv3的轻量化优化,模型的检测速度从30帧/s提升到了33帧/s,对损失函数的优化之后,mAP值从83.27%提升到了83.35%,且检测速度从30帧/s提升到了33帧/s,将两种优化结合在一起后的YOLOv5s-M3相较于YOLOv5s,其检测速度从30帧/s提升到了37帧/s,且参数量从7.33 M减少到了6.41 M,实验证明本文的改进方法有一定的提升效果,检测可视化结果见图3。

图3 YOLOv5s-M3检测结果图Fig.3 Detection result graph of YOLOv5s-M3
将YOLOv5-M3算法与其他轻量化算法进行比较,结果见表2。
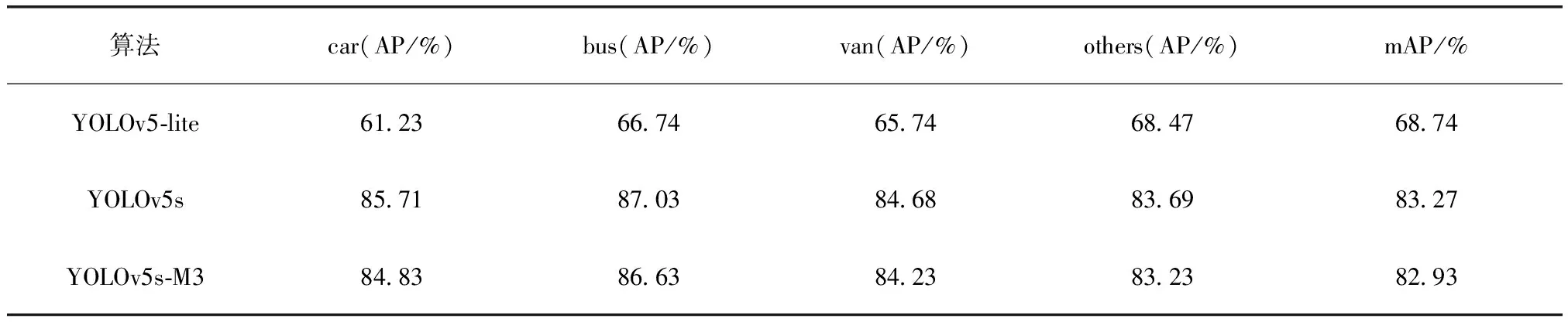
表2 不同算法的AP、mAP对比
由表1和表2可见,提出的YOLOv5-M3算法相较于YOLOv5s算法来说,mAP值虽然有0.34%的降低,但是参数量减少了0.92 M,检测速度增加了7帧/s。并且YOLOv5-M3算法相比于轻量化算法YOLOv5-lite在测试集中的训练结果来说,提出的改进方法有着较好的检测精度。
4 结 论
针对车辆检测算法对于小目标检测较困难的问题,基于YOLOv5算法,通过使用MobileNetv3网络结构替换原有的骨干网络结构,使用EIOU函数改善损失函数,降低模型的复杂度,减少模型的参数量,提升模型的检测速度,并经过实验验证,优化后的YOLOv5s-M3算法的mAP值较其他轻量化算法更加出色,并且具备更强的鲁棒性。
