基于VMD-GRU 网络大型公共建筑冷负荷预测
2023-12-26于军琪解云飞赵安军王佳丽惠蕾蕾
于军琪,解云飞,赵安军,王佳丽,冉 彤,惠蕾蕾
(西安建筑科技大学 建筑设备科学与工程学院,西安 710055)
全球能源消耗量伴随经济发展迅速增长,其中建筑能耗占比高达40%[1]。大型公共建筑由于舒适度要求高、人流量大、空调系统运行时间长等特点,成为建筑能耗中的“巨无霸”,对其能耗进行准确可靠预测成为关注热点。
建筑能耗受多种因素影响,例如气候状况、室内条件和人员流动[2]。提高预测精度就需把握建筑冷负荷的变化规律:随机性、周期性、非线性和非平稳性。解决建筑能耗预测有许多优化模型,大体分为三类:物理学模型、数据驱动模型和混合模型[3]。基于物理模型(也称白盒模型)的常用模拟软件有EnergyPlus,eQuest和Ecotect。Foucquier 和Yildiz 等人[4]创建“热模型”进行校园能耗预测。使用物理学模型模拟建筑能耗模型(BEM)需要在利用物理方程式的基础上收集详细建筑信息,复杂度较高,不能广泛应用。虽然Fumo 应用“工程方法”实现了对物理模型校准[5],但随动性差,实时性不强;数据驱动模型(也被称为黑盒模型)根据历史数据进行统计分析和机器学习,具有较好学习能力和泛化能力而被广泛应用。钱志[6]使用改进型人工鱼群和SVR 混合模型对需求侧负荷进行预测,但当输入数据过多时,精度和收敛速度明显降低。李军在能耗预测时依靠经验获取SOM 神经网络的隐层节点数和训练次数[7]。混合模型(也称为灰盒模型)是物理模型和数据驱动模型相结合的方法[8-11]。多种组合的方法和单一的人工智能方法比较,组合后的方法性能优于单一的传统方法,适用于多种类型的建筑[12-13]。王林[14]使用FOA 优化ESN 算法建立电力需求与多种因素之间的非线性关系对工业用电量(IEC)进行预测,虽然FOA 算法可以对ESN 的4 个关键初始参数进行优化,但易陷入局部最优,并且它的搜索路径太粗糙。雷建文[15]提出灰色关联分析和蝙蝠优化神经网络的预测模型对短期负荷进行预测,但是灰色模型对非平稳变化序列难以辨识,预测值与实际值存在较大误差,成为提高预测模型精度的瓶颈。
有学者将经验模式分解( empirical mode decomposition,EMD) 应用于预测领域并取得初步成效[16],然而该技术却存在局限性,易出现模态混叠现象,造成失真,影响负荷预测精度。为避免发生模态混叠现象,降低原始负荷序列的复杂度和非线性。Dragomiretskiy 和Zosso[17]在2014 年提出非平稳信号自适应分解估计方法—变分模态分解(variational mode decomposition,VMD)。VMD 有较好的分解效果和鲁棒性,应用于风速预测领域。运用普通神经网络预测时,训练过程易陷入局部最优,发生过拟合使预测结果失真,难以挖掘冷负荷序列的长时序关系。循环神经网络可有效进行该方面预测,但是容易出现“梯度消失”现象。Zhao 等人[18]提出的GRU(gate recurrent unit)门控循环单元网络,通过引入门控单元解决梯度消失问题,更完整考虑时间序列中长短期依赖性关系,相较于LSTM 具有更快收敛速度,因此也逐渐应用到短期冷负荷预测领域。然而,当输入的时间序列较长时,LSTM、GRU 等RNN 系列网络处理高维信息难以有效提取数据间信息,影响模型准确率[19]。
笔者结合VMD 与GRU 优势,提出VMD-GRU 冷负荷预测模型,有效解决特征信息的提取,用于大型公共建筑冷负荷预测,并展开以下研究:
1)构建VMD-GRU 冷负荷预测模型,使用VMD 将原始数据序列分解为独立固有模式函数,用GRU 对每个分量进行预测,将分量预测结果相加得出冷负荷预测值。
2)以西安某大型公共建筑相关数据为例进行实例分析,对模型的输入变量进行相关性分析,选取对冷负荷影响较大的输入变量。
3)采用VMD-GRU 模型进行冷负荷预测,与其他预测模型进行比较,验证模型的有效性。
1 VMD-GRU 能耗预测模型的构建
VMD 模型依据序列数据的特点逐级进行平稳处理,GRU 网络具有较强的非线性拟合能力, VMD-GRU模型处理冷负荷的非线性拟合及预测,降低复杂度的同时提升模型预测精度。
1.1 VMD 分解
变分模态分解是一种新型非平稳信号自适应分解估计方法,目的是将原始复杂信号分解为K个调幅调频子信号。将大型公建冷负荷相关变量X=[X1,X2,…,Xm] 进行Pearson 相关性分析,选取相关性高的数据重组为新的相关性序列Y=[U1,U2,…,Un,O]。利用VMD 进行分解及平稳化处理,分解为表示原始数据特征的多个分量。VMD 分解的具体步骤如下
步骤一:初始化各模态、中心频率和算子。
步骤二:根据式(1)和(2),更新参数uk和ω
其中:f(t)为原始信号;uk是信号f(t)的第k个分量分别代表f(ω)、ui(ω)、λ(ω)和un+1k的傅里叶变换;n代表迭代次数。
步骤三:根据式(3)更新参数λ,
步骤四:对于给定的判别精度e>0,若则停止迭代,否则返回步骤二。
1.2 门控循环单元网络
GRU 网络是长短期记忆网络(long short-term memory,LSTM)的一种变体。通过使用“门”结构,极大避免梯度消失现象。GRU 网络包括更新门、重置门和输出门3 个部分。它将LSTM 网络中的遗忘门和输入门合并成zt,原有重置门rt, LSTM 门控网络的优点更新细胞状态和隐藏状态。
Step1:更新门rt和重置门zt。
更新门zt是过去时刻特征信息对现在特征信息的影响程度,阈值越大说明前时刻特征信息对现在影响越大,如式(4)。重置门rt是过去时刻状态特征信息被丢弃的程度,阈值越小说明对过去信息丢弃越多,有助于学习序列中短期的时序特征,见式(5)。其中ht-1表示前一时刻的隐藏状态,σ表示sigmoid 激活函数,W为输入的权重向量。
Step2:候选隐藏状态
Step3:隐藏状态
ht为当前隐藏状态,取决于ht-1和͂t。如果zt趋近于0,表示上一时刻信息被遗忘; 如果zt趋近于1,表示当前输入信息被遗忘,见式(7)。
Step4:输出
过去的冷负荷状态会对当前状态产生长期影响,GRU 通过控制与更新门限层控制模型的记忆能力,在不断迭代中,对历史数据的特征信息进行记忆与更新,历史数据会被赋予不同的权重值,已经训练的模型会对接下来的数据进行预测。

图1 预测模型结构Fig. 1 Forecast model structure
un1,un2,…,unk分别是系统n个不同输入变量的观测值,o'k是模型输出的观测值,GRU 神经网络的输入向量。将历史数据依次通过多层GRU 全连接层,并在接下来通过完全连接层合并特征,生成预测当前时刻后m个采样周期的输出。将GRU 神经网络的预测值与真实值之间的平均平方差定义为损失函数,随时间反向传播。
1.3 相关性分析
选用Pearson 分析法对冷负荷和输入变量间的相关性进行分析。公式为
式中:rxy为2 个变量的相关系数;xi、yi分别为2 个变量的第i个数据点;、分别为2 个变量的均值;n为该变量中数据个数。
1.4 VMD-GRU 预测模型
VMD-GRU 模型的构建分为4 部分:VMD 分解、分解分量重构、GRU 网络训练及最终预测结果输出。使用VMD 对冷负荷序列和变量进行相关性分析,舍弃相关性低的变量,对相关性高的变量和冷负荷序列进行VMD 分解,将分解后的分量进行重组。选取所有相关性高的变量第一个分量作为输入,冷负荷分解后的第一分量作为输出,在GRU 网络中对预测模型进行训练,依次类推,对第二分量、第三分量等分别进行训练。对冷负荷预测数据相关性高的变量进行VMD 分解,输入GRU 网络中进行预测,得到冷负荷的预测分量o'(n),将分量预测值叠加得到预测值并输出结果,见式(10)。
2 案例分析
2.1 项目介绍
实验数据来源于某大型公共建筑,建筑物高40.6 m,总建筑面积258×104m2,商业面积20×104m2,建筑空调面积18.76×104m2。首先对输入变量进行相关性分析,选取出对负荷影响较大的输入变量。

图2 方法流程图Fig. 2 Flow chart of the method
2.2 相关性分析
大型公共建筑冷负荷预测训练样本的输入层节点考虑到太阳辐射、室外温度导致建筑冷负荷存在滞后,预测模型中加了(T-1)h 时刻室外空气温度[20],加入(T-1)h 时刻冷负荷以及(T-2)h 时刻冷负荷作为模型输入变量。
实验以6 月、7 月60 天中前50 天每天14 h 运行数据做为训练数据,采用7 月份的25、26、27、28 数据作为验证分析数据,使用Pearson 相关性分析法对其相关性进行分析。
如图3 为变量之间的相关性热点图。冷负荷与1 h 前的太阳辐射强度相关性R为0.470 93,冷负荷与相对湿度相关性R为-0.21487,大多数公共建筑墙体表面会采用隔热材料维持室内在一定时间的热湿环境,在短周期内外界环境的太阳辐射对于墙体温度变化效果不明显,墙体温度变化对室内温度影响较小,因此选择舍弃;冷负荷与室外风速的相关性R为-0.05391,相关性较低,这是由于大多数建筑室内本身处于相对密闭的空间,与外界空气流动时间较短,热交换较少,室外风速对于冷负荷的影响较小,在进行冷负荷预测时选择舍弃[21-23]。最终选取的输入变量为X1、X2、X3、X4和X5;输出变量为O,具体变量选取见表1。

表1 选取的变量Tab.1 Selected Variables

图3 变量间相关性热点图Fig. 3 Hot spot map of Inter-variable correlation
2.3 VMD 冷负荷序列分解
经过相关性分析后,提取5 个相关性较高的变量反映原始数据的主特征,进行VMD 分解。参数设置,确定模态数量,按照实验选择模态数量对冷负荷序列进行VMD 分解,获取VMD 结果。
参数设置为:惩罚参数α=1 000;初始中心频率ω=0;收敛判据r=10-6。在分解时出现相近模态时容易出现混叠现象。模态函数个数经过反复实验得出表2,看出在模态分量个数为6 时,中心频率2 288 Hz 和2 336 Hz 相距较近,出现模态混叠[24]。为了分解原始冷负荷序列,且不出现模态混叠,模态个数选为5 较适宜。5 条分量依次为u1,u2,…,u5,且各u分量按照中心频率从低到高依次排列。每条u分量反映出不同信息,u1是频率最低的一条分量,含有原始序列的趋势信息,u5是频率最高分量,包含着原始序列的震荡信息。
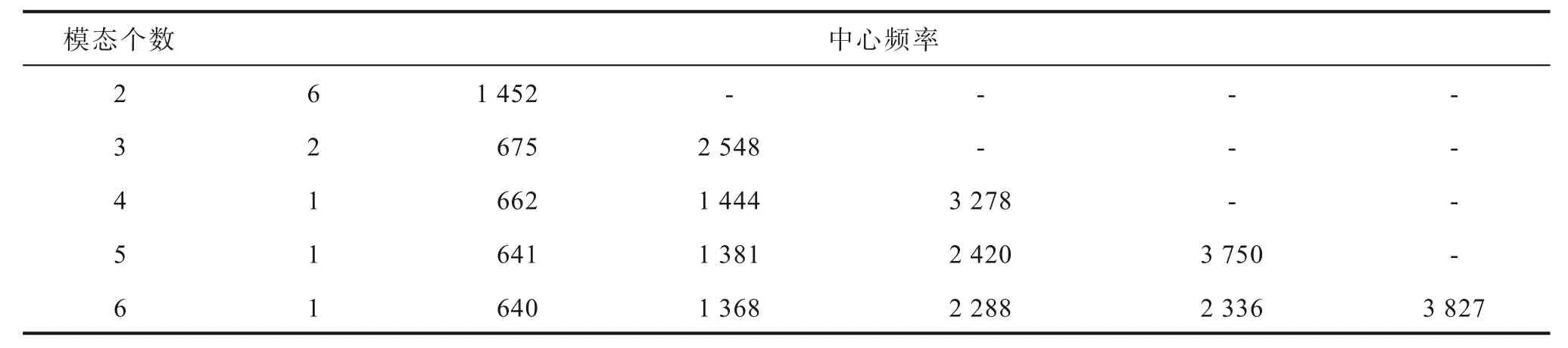
表2 不同K 值对应的中心频率Tab.2 Center frequency corresponding to different K
对冷负荷序列进行VMD 分解,分解结果如图4 所示。模态函数u1表示趋势分量,平均振幅较大,变化平缓,规律性最易掌握,反映检测样本中冷负荷的大体变化趋势。模态函数u2、u3表示细节分量,规律性较好,周期性明显,表明建筑冷负荷具有较强周期特性,规律性较强,波动平缓。模态函数u4和u5平均振幅最小,波动较大,规律性较差,受建筑人员活动影响较强,具有随机性。

图4 冷负荷VMD 分解图Fig. 4 The decomposed results of cooling load by VMD
3 实验与分析
基于VMD-GRU 的大型公共建筑冷负荷预测,是将VMD 分解的每一个分量分别采用GRU 网络进行预测,最终获得所有冷负荷预测分量相加求和,得到冷负荷预测结果。为验证所提出模型的有效性,采用研究模型分别与BP、GRU、EMD-BP、VMD-BP、EMD-GRU 模型进行实验对比分析。经过实验参数调试比较,GRU 网络设置2 个隐含层为最佳,激活函数为sigmoid,学习率为0.05,迭代次数为1 500,时间步的长度为28,最终设置GRU 网络为5-3-7-1。
由于很多输入向量与预测结果相关性差、信息冗余度高等原因,导致多数预测模型在预测精度上未达到理想预测效果[25]。首先对输入向量进行相关性分析,在众多输入向量中剔除冷负荷预测影响较小的向量,将剩余关键因素作为模型预测输入向量。由表3 中相关性前后的实验数据分析可知,将输入向量由8 个降到5个,精度提高,说明被剔除的3 个输入向量降低了模型预测精度,属于冗余信息。

表3 不同模型预测效率对比Tab. 3 Comparison of prediction efficiency of different models
图5 中u(1-5)为子序列预测结果,5 个分量序列进行累加可得到VMD-GRU 模型冷负荷预测序列,并且和原始冷负荷序列进行对比。由图5 分析可知,冷负荷预测分量累加之后获得VMD-GRU 模型的预测结果非常接近于冷负荷原始值。接下来对提出的VMD-GRU 预测模型和另外几个模型进行对比分析。

图5 冷负荷预测结果Fig. 5 Prediction results of cooling load
图6 展示6 种模型的预测结果,通过比较分析可知,单一BP、GRU 预测模型预测结果不稳定,偏差较大。EMD-BP、VMD-BP 和EMD-GRU 预测模型虽然预测结果偏差有所降低,但是与VMD-GRU 预测模型相比,预测精度不够好。采用VMD-GRU 预测模型的预测精度高于其它5 种模型,该模型得出的预测值与真实值更接近。

图6 6 种模型的预测结果对比Fig. 6 Comparison of prediction results of six models
图7 可见6 种预测模型误差对比,将6 种模型的预测误差序列采用Kolmogorov-Smirnow 检验[26],测试结果表明4 个序列均服从正态分布。BP 和GRU 在高误差区出现的次数较多,误差分布较分散。通过EMD 和VMD 分解后,预测值误差较小。VMD 分解后的预测值误差比EMD 更小,优化效果明显。VMD-GRU 预测模型的相对误差远小于其他预测模型。
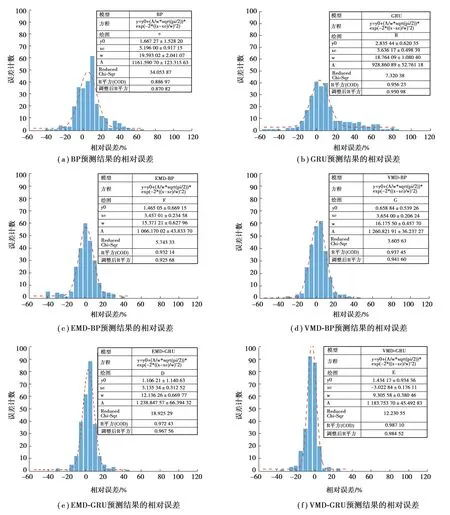
图7 6 种模型的预测相对误差的对比Fig. 7 Comparison of prediction relative errors of the six models
传统BP 神经网络单独使用预测效果不能很好挖掘时间序列中的长时序关系。GRU 引入门控单元可很好挖掘其中的长短期时序关系[27]。VMD 通过迭代搜寻变分模型最优解确定模态函数序列分量,具有较强长时序趋势特征[28],将VMD 与GRU 结合可较好挖掘冷负荷序列中的长时序关系特征,有利于提高预测精度。通过图7 和表4 分析可知,在实验中BP 预测性能较优于GRU,但在实际预测中往往需要考虑到冷负荷序列中的长时序关系, BP 神经网络在预测中不能够充分利用数据本身存在的长时序关系。VMD 与GRU 结合可以更加有效,助于提高模型预测精度, BP 与VMD 和EMD 等分解算法结合时不能有效利用长时序关系特征,不利于提高模型预测精度。
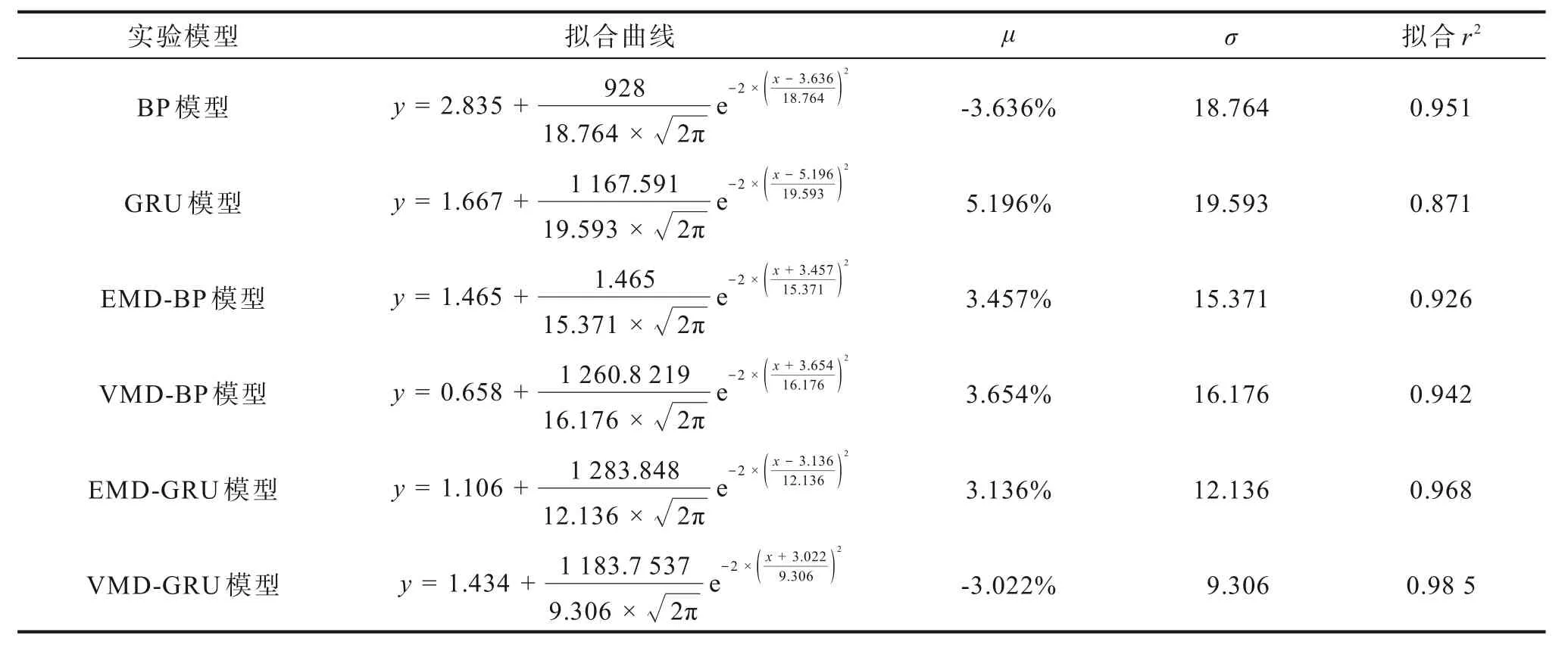
表4 6 种相对误差预测模型拟合曲线比较Tab. 4 Comparison of six relative error prediction model fitting curves
在正态分布中μ值决定了曲线位置,|μ|越接近0,说明位置越靠近0,即大多数的预测相对误差值接近于0,模型预测效果越好。σ决定了曲线的尖峭程度,σ越小图形越尖峭,说明在该误差范围内的包含数值越多。通过对6 个模型的相对误差分布图形对比可知,VMD-GRU 模型|μ| = 3.022%,最接近于0,并且σ最小,说明该预测模型的相对误差在0 附近数量值最大,模型最精确。
图8 对比GRU 预测模型和EMD-GRU 预测模型,VMD-GRU 模型更加逼近真实值。表5 中对6 个模型进行比较,VMD-GRU 模型线性回归拟合曲线拟合度最高,达到了0.992,残差和较小达到1.045。通过分析其截距和斜率可知,VMD-GRU 模型预测值和真实值的拟合曲线更加接近直线y=x,说明预测效果最好,且该模型的截距标准误差最小,说明其截距误差范围最小,预测值更加接近真实值。

表5 6 种预测模型回归拟合曲线参数比较Table 5 Comparison of six prediction model regression fitting curve parameters
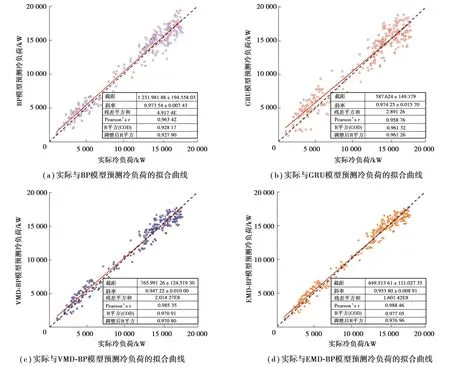
图8 实际冷负荷与模型预测冷负荷的回归拟合曲线Fig. 8 Cooling load regression fitting curve between actual value and model prediction value
4 结论
针对大型公共建筑冷负荷预测,提出VMD-GRU 预测模型,对输入输出数据间的相关性进行分析,利用VMD 算法对冷负荷序列进行初步分解,利用GRU 网络对分解序列分别进行预测,得出以下结论:
1)该大型公共建筑的T时刻输出冷负荷与T时刻室外温度、T-1 时刻室外温度、T时刻太阳辐射量、T-1 时刻冷负荷、T-2 时刻冷负荷这5 个输入量相关性较高。对变量进行相关性分析,避免人工经验选取输入变量的不足,缩短预测时间。
2)以MAE、MAPE 和r作为3 种预测模型评价标准,实验结果表明,BP、GRU、EMD-BP、VMD-BP、EMDGRU 和VMD-GRU 模型的MAE 分别为1 924.206、1 813.956、1 157.865、1 126.459、1082.47 和495.532;MAPE分别为0.181 6、0.171 8、0.102 5、0.122 5、0.092 7 和0.041 9;r分别为0.515 64、0.525 22、0.803 61、0.793 24、0.781 76 和0.954 9。
3) 冷负荷时间序列往往是非平稳、非线性。VMD- GRU 模型更容易掌握建筑冷负荷时间序列的特征,实现原始序列平稳化,提高建筑冷负荷预测的精度,更适合工程实际应用。
