情报学研究中的时间序列分析:任务、过程与问题
2023-12-21陈果王凯月
陈果 王凯月
1 引言
在时间维度上,对每一时刻数据的记录就是时间序列[1]。时间序列数据在生活中无处不在,对其开展研究具有十分广阔的应用前景。在传统计量经济学中,时间序列分析关注的是经济指标的日常变化,其中受关注较多的是周期性问题,如季节效应[2]。情报学定量研究中多关注文献数据、网络数据、政府数据等分析对象的变化[3],其变化趋势更接近阶段性。典型的如利用生命周期理论,划分文献主题、舆情话题在不同时期的变化阶段。除此以外,利用回归、拟合等方式对时间变化曲线进行数理统计和描述,也是情报学研究中时间序列分析的一个重要方面。
近年来,时间序列分析方法不断发展优化,在时间序列分类、预测、聚类、回归分析、异常检测等方面都得到了深入的应用[4]。然而,在情报学研究中,尽管大量研究引入了时间因素,但多是从划分时间段的视角来对所关注对象的变化状态进行描述性分析,或沿用基本的回归模型来拟合其整体变化趋势,而对情报研究对象时间序列模式的深入挖掘和分析依然较为缺乏[5]。当前,情报学研究的模型化、预测化发展趋势,迫切要求研究者更为深入地应用时间序列分析方法开展研究。因此,有必要对现阶段情报学中涉及时间序列分析的研究进行系统性的梳理。
鉴于此,本文采用文献调研的方式,梳理国内外情报学领域与时间序列分析相关的研究现状。首先,依据《中文核心期刊要目总览》和SSCI-INFORMATION SCIENCE&LI-BRARY SCIENCE-JOURNAL LIST[4]选定了情报学代表性期刊,如表1所示。其次,利用CNKI全文期刊数据库以及Web of Science数据库,以“时间序列”和“time series”为主题词分别筛选中英文代表性期刊中的相关文献,检索时间截至2023年4月30日。结果表明,情报学领域与时间序列相关的国内外研究论文分别有222篇和202篇。随后,在对这些论文进行初步定性分析的基础上,本文先按应用场景归纳其中的应用类论文,再按时间序列分析过程归纳相关论文在各环节上的典型处理方法。具体归纳时,对某些值得探索的问题,本文进一步追溯了上述论文的参考文献,最终选取了其中质量较高、具有代表性的82篇论文进行综述。基于此,本文最后探讨了情报学研究中时间序列分析存在的问题,以期为其深入发展和有效应用提供借鉴。

表1 中外情报学十种核心期刊中相关论文统计结果Table 1 Statistical Results of Related Papers in Ten Core Domestic and Foreign Journals of Information Science Research
2 情报学研究中时间序列分析的主要任务场景
在情报学研究中,时间序列分析主要是用作解决相关研究问题的方法手段。因此,有必要根据所解决问题的任务场景,来归纳时间序列分析方法在情报学研究中的应用。此外,时间序列分析的核心思想是“分析过去,预测未来”,故而各任务场景下的应用模式又可根据研究目标,划分为对历史规律的揭示和对未来趋势的预测。相应地,本节从任务场景和研究目标两个维度,对情报学研究中的几种时间序列研究任务进行归纳,如图1所示。

图1 情报学研究中时间序列分析的研究任务归纳Fig.1 Task Scenarios for Time Series Analysis in Information Science Research
2.1 学科主题演化
学科主题演化是指用一系列技术方法,观测学科主题在时间维度上的变化与发展趋势[6]。学科主题演化是近年来情报学研究的重点,在分析学科领域热点主题演化趋势的基础上,研究者开始探索新兴主题预测以发现新的学科知识增长点。对学科主题演化的研究可以帮助研究人员确定科研主题,帮助研究资助机构选择有发展潜力的主题进行资助,还可以识别领域学术贡献突出的研究人员与研究机构。
当前的学科主题演化研究,主要是在对不同时间窗口下各研究主题进行匹配的基础上,通过文献数量、关键词频次等数值序列的变化以揭示相关主题在不同时间窗口的热度变化,进而描述重要主题的出现、融合、分裂、消失等演化状态。一般认为,主题相关发文量的变化可以体现主题的热度演变[7]。但该指标过于主观笼统,随着主题识别的技术手段的不断丰富,情报学研究开始以关键词或主题词等为主要研究对象[8]。例如,Yan等以图情领域的文献数据主题词为数据来源,结合层次化分析的方法揭示了主题的传播演化过程[9]。同时,也有学者将时间因素引入到主题模型中,提出了非马尔可夫连续时间模型TOT(Topics Over Time)[10]、先离散概率模型DTM(Dynamic Topic Model)等方法,进一步体现了主题的时序演变过程。此外,对于语义相似的时间序列曲线,也可以通过DTW(Dynamic Time Warping)算法对其聚合表示,以便于观测其组合变化趋势[11]。
情报学研究者十分关注前沿主题或新兴主题的预测,目前这类研究主要利用各种指标来度量主题在时间序列曲线上的变化,通过时间序列回归等模型来拟合曲线规律以预测其未来趋势。例如,岳丽欣等使用ARIMA模型(Autoregressive Integrated Moving Average model,差分整合移动平均自回归模型)预测了信息构建领域的主题演变趋势[5]。Liang等使用LSTM模型(Long Short Term Memory)预测了候选主题的未来受欢迎程度分数[12]。Lee等使用ATM模型(Associative Topic Model),根据主题过去的文本和数值特征来预测下一个时间数值[13]。目前,主题时间序列预测研究的观测对象大多是单变量数据,使用多元时间序列预测方法的研究较少。事实上,科学研究的主题是相互关联的,有必要充分考虑主题间的关联,来提高对特定主题未来变化的预测效果[14]。
2.2 网络舆情分析
监测舆情的变化动态并挖掘其话题演变规律是情报学研究者持续关注的焦点,其时间序列分析主要围绕舆情的话题或情感变化来探索演化规律或预测发展趋势[15]。
在舆情演化方面,研究者通常从舆情事件的时空关联、主题分布和传播特征等方面出发,将文本中提取的信息按照时间维度开展演化分析[16]。目前已有较多研究从定性的视角,将舆情演化按时间轴划分为若干个阶段[17]。例如,李纲等[18]根据Web2.0时代网络舆情的传播特征,将其过程划分潜伏、成长、蔓延、爆发、衰退和消亡等6个阶段。有学者运用定性、定量相结合的方式对舆情的演化规律进行研究[19],以避免定性分析的主观影响。例如,曹学艳等[20]利用基于最小二乘法的多项式拟合法,根据网络舆情的时间序列函数特征,将其演化模式分为突发型、连续型和复合型。
网络舆情传播规律的研究通常依托于其关注热度、网民情感态度、热点主题等的变化。具体研究开展中,舆情热度常用百度指数、微博转发数、评论数[21]等数据来表征。例如,徐敏捷等利用微博热议数来表征“东方之星”沉船事件的舆情热度变化趋势[22],赵磊等以百度指数构建舆情热度时间序列[23],孙永历等综合用户关注度、参与度和话题回复数三个指标来计算舆情热度的熵值[24]。舆情情感态度可用情感分析方法对舆情话题进行情感计算,再按时间序列形成舆情情感的走势。例如,崔彦琛等[25]构建了微博突发事件“杭州保姆纵火案”的专属情感词典,利用ARIMA模型分析了该事件的事态演进。舆情热点主题的变化可通过对带有时间戳的社交媒体语料进行主题分析得到。例如,张帅等统计了不同时间段各类主题出现的频次,并划分了其时间序列阶段[26]。
目前针对舆情数据的预测主要有三种思路:一是根据相似话题的时间序列规律来预测新事件的发展走向。例如,聂恩伦等[27]通过相似历史话题点击数的时间序列来预测新话题的热度。二是更为常见的利用时间序列分析模型来预测舆情数据,如移动平均法[28]、马尔科夫链[21]、ARIMA/ARIMAX预测模型[29]等。三是依托时间序列聚类方法,即将形状变化相似的时间序列聚集在一起,再预测其热度趋势。例如,高烨等[11]利用时间序列降维算法将舆情热度的时间序列曲线聚成三类变化模式,再通过DTW距离方法来预测网络舆情事件热度的高峰期时间区。需要注意的是,不同舆情事件的传播规律、持续时间不尽相同,舆情数据预测的精度又严重依赖于其算法和参数,因此如何提高时序预测方法在应用中的适用性是一个亟需解决的问题。
2.3 技术趋势分析
专利蕴含技术概念、主题和研发活动等显性技术信息和隐性知识[30],是技术趋势分析和预测的常用数据源。专利情报研究者常使用生长曲线(如S曲线[31])表示技术的演化过程,并使用时间序列分析方法发现技术发展趋势的轨迹和模式。
技术演化是指技术领域内部的技术活动、子技术或技术主题随着时间推移的发展、继承和变化的过程。在专利分析中,可使用文献计量方法来识别技术演化的基本特征数据,如特定技术的专利申请数量、引文数、专利分类号等。曾闻等分析了人工智能技术的专利申请数量、国别等专利信息随时间的变化[32]。Wang等[33]利用国际专利分类(IPCs)来追踪技术领域和演进路径中的技术变化。Liu等[34]使用三个S曲线模型拟合日本双足机器人行走技术的专利时间序列曲线,以揭示其演化趋势。
预测技术变化的方向和速度也是时间序列分析在情报学研究中的典型应用之一,常用的方法包括文献计量分析、趋势外推法、动态线性模型等。专利数量、发表数量或引用数量等指标可以用来衡量和解释技术进步。例如,You等基于专利和专利子类之间的两级知识转移网络,利用巴斯扩散模型和ARIMA两种典型时间序列模型比较并预测了技术的发展趋势[35]。为了更有效地拟合专利数据的时间序列曲线,机器学习方法越来越多地运用于技术趋势预测。专利数据通常是短时间序列,Xin等[36]利用参数量更少的卷积神经网络CNN模型捕捉时间序列模式以预测技术趋势。需要指出的是,在技术趋势预测中,现有技术方法容易忽视技术创新的随机性,高估了现有技术主题的持续发展能力,低估了新技术的出现速度[37]。
2.4 学术影响力评价
引文是评价学术影响力的一个重要依据,典型的相关指标有期刊影响因子、H指数等。进一步关注引文相关指标在时间维度的动态分布规律,可揭示其被引模式、预测其未来影响力增长的可能性,从而更有效地评价相关对象的学术影响力。
目前,研究者基于文献被引频次的时间序列数据,对文献被引的生命周期规律进行了总结。A.Avramescu[38]发现引文时间曲线的变化规律有5种类型:变化规律相近的3种经典曲线、“天才型”曲线以及“昙花一现”型曲线。在此基础上,H.P.Van Dalen和K.Henkens[39]提出了“被遗忘”的论文以及“睡美人”论文。此后很多研究者基于引文时序曲线的特征来识别“睡美人”文献,例如Ke等[40]通过测量论文的“美丽系数”来识别“睡美人”文献的被引曲线。为了更好的理解引文模式的作用机制,Hu等[41]引入格兰杰因果推理来研究下载和引用之间的方向性。
学术影响力预测主要对论文、学者、机构等对象的未来学术影响力指标进行预测,以期识别潜力学者、学科、期刊等。Bai等人[42]利用时间序列回归模型预测了论文的未来被引频次。Du等改进了LSTM模型以拟合论文被引频次的分布和演变趋势[43]。Xie等对机构发文数量的时间序列进行回归分析以预测其未来影响力[44]。尽管研究者已设计各种指标来量化评估学术影响力,并基于利用时间序列方法对这些指标进行预测,但人们对学术影响力是如何产生和演变的仍知之甚少[45]。因此,融合复杂网络分析和时间序列分析方法,对引文网络的拓扑结构及其演化机制进行研究,也是目前学术影响力预测研究的一个重要方向[46]。
3 情报学研究中的时间序列分析过程
在情报学研究中,可用于时间序列分析的数据指标种类繁多,相应的分析方法尚未形成固定的过程环节。为此,本文按照时间序列分析方法的基本过程,依次从观测数据选取、时间序列切片方式、时间序列形态规律挖掘、预测与评价四个环节,对情报学中的时间序列分析研究进行梳理,具体流程如图2所示。

图2 时间序列分析研究流程图Fig.2 Flow Chart of Time Series Analysis Study in Information Science
3.1 时间序列观测数据选取
时间序列分析的第一个步骤就是选取和处理观测数据。情报学通常根据研究目标来选定构成时间序列的定量指标,例如文本的主题指标[47,49]、科学计量学相关指标等。总体而言,这些观测指标可分为单一性指标和综合性指标两种。单一性指标是从单一维度对数据进行描述,例如用论文数、引文数、关键词频次等指标描述研究主题的热度;综合性指标是综合多方面因素构造数据指标,例如h指数、p指数等综合论文的被引量和发文量来度量论文的影响力。表2列举了不同情报分析任务中典型的时间序列观测指标。
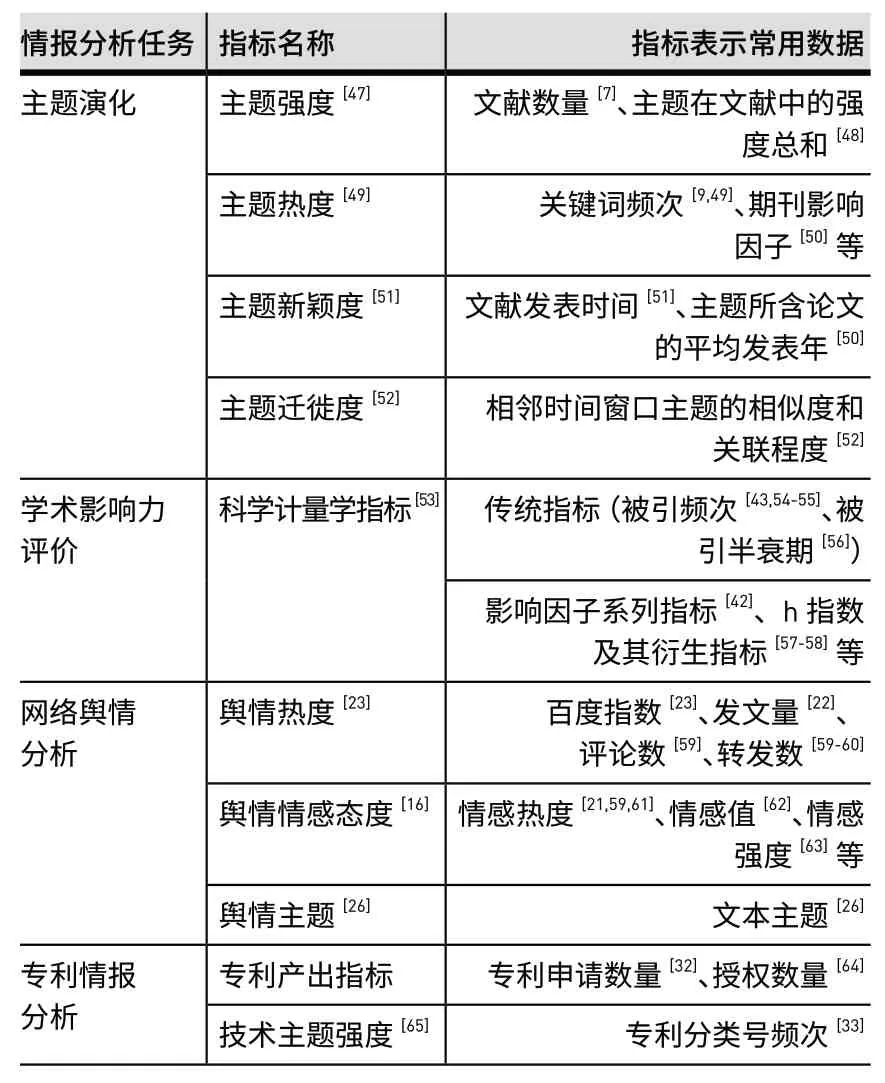
表2 情报学研究中典型时间序列观测指标Table 2 Observation Indicators of Typical Time Series in Information Science Studies
3.2 时间序列切片方式
获得时间序列基础数据后,需要对其进行切片,即明确时间序列数据单元对应的时间窗口大小。切片方式有离散时间窗口和交叉时间窗口两种,离散窗口是选取不重叠的独立时间单元来对数据进行分段,目前这种切片方式比较普遍。交叉时间窗口切片中的时间序列单元则与前一单元有部分时间重叠。
离散时间窗口往往按自然时间粒度划分,如年、月、日。与计量经济中常用的以日为单元不同,情报学研究的时间窗口粒度相对较大,例如对词语、引文分析往往是以年为单元。在对主题、舆情的分析中,时间窗口往往是多个自然时间粒度的组合。主题分析以若干年为一观测阶段,舆情分析则以若干天为一观测阶段。在实际分析中,为了便于归纳主题或舆情变化的整体趋势,比较不同阶段的特点,研究者往往采用等长[66]或不等长的方式对“年”或“天”的时间序列进行划分,通常分割为3-5段。等长[66]的划分方法操作简单,但是在整个时间序列中,有规律的时间序列模式长度不定,因此等长划分方式不利于后续的规律发现。为了降低等长划分方式的主观性影响,有学者根据时间序列曲线的阶段性规律来划分时间片段,典型的是结合生命周期理论或者根据曲线拐点来切分时间序列窗口。朱光等[67]基于文献增长理论,将文献数量时间序列划分为初步探索期(2005-2007年)、稳定发展期(2008-2017年)和快速增长期(2018-2020年)3个不等长区间。
使用交叉窗口的时间序列的优点,是可以利用相邻时间窗口的重叠更好地捕捉数据背后事物演变的连续性,以避免连续过程被独立切片操作打散。具体操作上,有的学者主观地选择时间窗口的重合区间,例如Henry Small[68]直接将数据集切分为三个重叠时间窗,分别为1996-2001年,1997-2002年和1998-2003年。也有学者利用滑动窗口的方法,按指定长度的时间窗口持续向后平移构成时间片,以比较各窗口内的统计指标。例如,Lu等[69]通过滑动窗口和切片相结合的方式,设计了一个步长固定为3的滑动窗口来预测关键词的增长频次。
3.3 时间序列形态规律挖掘
时间序列分析的最终目标是从原始或转换后的时间序列数据中发现蕴含的规律。本节主要讨论利用生命周期理论或时序聚类方法对时间序列模式进行分析的相关研究。除此以外,有大量关于时间序列曲线拟合的情报学研究,因其主要目标是开展预测,故而归入3.4节讨论。
时间序列形态规律的一个重要方面是其表征事物的演化过程规律,即其典型阶段与各阶段延续方式。情报学研究中对时序演化规律的分析通常依托生命周期理论,即将研究对象(如研究主题、技术发展)的全时序过程划分为因果关联、前后相继的各个阶段,典型的生命周期状态可分为新生、成长、成熟、收缩和消亡五个阶段。例如,在学科主题演化分析中,Wu等[70]根据生命周期理论将主题划分为萌芽期、缓慢增长期以及快速增长期。在网络舆情演化分析中,马晓悦等[71]将突发公共卫生事件社交媒体信息的生命周期划分为潜伏期、爆发期、衰退期、稳定期。在专利演化分析中,Cong等[72]将产品的技术发展周期划分为婴儿期、成长期、成熟期、衰退期。马建红等人[73]发现产品技术主题的语义信息会随着其生命周期的发展而逐渐丰富,词汇从独立转向组合演变从而形成主题的分化和融合。
此外,还可以通过对演化趋势相似的时间序列进行聚类,根据其共性变化特征来识别时间序列的不同模式。常用的聚类依据是通过基于距离表示的时间序列相似度。在主题演化方面,李海林等[74]利用DTW算法计算了研究主题流行度时间序列的相似度,再用AP聚类算法聚合具有相似发展趋势的主题簇。在引文分析方面,黄思雨等[75]对期刊篇均引用值时间序列进行聚类,根据其变化趋势探索参考文献与引证文献两种来源期刊间隐含的相关关系。
3.4 时间序列的预测与评价
时间序列的预测需要将时间序列划分为两个序列,一个用于构建拟合模型,一个用于测试拟合模型的质量。然后根据数据特征选择预测模型用于预测,再评估模型的准确性。
时序预测的方法分为统计学的方法和机器学习的方法。统计回归方法包括线性回归、ARIMA、VAR(Vector Autoregressive)多元时间序列等模型。例如,陈娟等采用ARIMA模型拟合了能够代表用户价值的人均满意程度演变曲线[76],S Bjork等通过创新扩散的Bass模型分析了诺贝尔经济学奖获得者的引用轨迹[55]。Xie等运用VAR多元时间序列模型预测了来年预计录用的会议论文数量[44]。机器学习方法强调在特征辅助下对时间序列进行预测,包括BP神经网络模型、LSTM模型等方法。例如,Zhang等[77]通过LSTM模型预测了未来COVID-19病例数量。研究表明,用于时间序列预测的机器学习算法的效果经常优于统计模型[78]。
预测结果的评价至关重要,因为不同的模型尽管可能具有相似的特征,但会产生截然不同的预测值。一般而言,预测的精度越高,表明模型的效果越好。研究时可以通过比较不同的模型拟合效果来选择最优方案。例如,许海云等[79]使用ARIMA、LSTM以及Prophet三种模型进行趋势预测,通过计算RMSE(Root Mean Square Error)、MAE(Mean Absolute Error)、R2Score值衡量了观测值与真实值之间的误差,最终发现Prophet模型的预测精度最高。
4 情报学研究中时间序列分析的问题
本文梳理了情报学研究中有关时间序列分析的任务场景和处理流程,尽管当前研究已取得了一定进展,但仍面临诸多问题。
4.1 对时间序列模式的挖掘研究不足
当前情报学研究中的时间序列分析多侧重计量指标的趋势分析,较少利用时间序列模式识别和特征挖掘来揭示研究对象的发展过程、规律、动因及态势等。情报分析与预测一直是情报学研究中的核心工作,可相关研究中的预测方法与工具较少。相关研究或是识别学科在上升、平稳或下降等方向的趋势[7],或是回归拟合未来某一时间段里的预测值[80],对学科发展过程和动态变化规律的研究还不足,并没有进一步归纳总结学科兴起、衰退等状态转移的共性规律和基本模式。时间序列分析研究中引入数理模型并非刻意抬高或复杂化研究问题,而是为了避免人工解读的主观性影响,提升情报分析的科学性和精确性[5]。因此,在未来情报学研究中,应提高对时间序列数理模型、特征变换与分解、相似性度量、分类聚类等方面的重视,运用定量方法以更客观地解决时间序列分析问题,以将相关研究推进到更深入的规律总结、模式发现层面。
4.2 缺乏针对短时间序列分析的研究优化
情报学研究中,时间序列分析对象以短序列为主,原因是数据的时序记录点相对较少,各时序点数据的特征维度也低。例如,在论文[49]、专利[33]数据中,往往按照年为时间粒度提取文献的关键词、摘要或者引文等信息,而在观测舆情事件时,则以若干天为一观察阶段。如赵磊等[23]以14天为一滚动周期,将舆情数据分为21组。现有的时间序列分析方法和理论大多侧重于长时间序列分析,不能很好地适应短时间序列数据分析。例如,ARIMA模型想要取得较好的预测效果,通常需要至少50个观测值。如果数据量少或数据不完整,短时间序列分析的结果也不可靠。如何优化这些原本应用于长时间序列分析的挖掘方法,以处理科技情报分析普遍存在的短时间序列,是未来需要重点关注的问题。目前,已有学者提出了一些短时间序列分析方法。例如,Martin等[81]提出基于分数布朗运动的赫斯特指数估计方法,适用于长度大于10且满足分段独立性的短时间序列。在未来的研究中,应多关注短时间序列分析和挖掘方法,例如利用分组时间序列[82]解决单条序列数据较短而分组数较多的问题。
4.3 对研究结果的评估较为欠缺
情报学研究中时间序列分析还存在结果评估不足的问题。很多研究仅仅通过时间序列模型拟合曲线,而没有进一步评估拟合预测结果的准确性,这在一定程度上无法确保结果的可靠性。实际上,在情报学诸多研究场景中,时间序列分析是最有条件开展量化评估的。针对不同的时间序列模型,在进行曲线拟合及趋势预测时,可以通过均方根误差、平均绝对值误差[79]等指标来计算观测值与真实值之间的差距,评价趋势预测结果的好坏。因此,如何借助情报学研究的预测性导向,形成一套可用的时间序列分析结果评估方法,仍有待于进一步研究。
作者贡献说明
陈果:提出论文思路,设计框架,修改定稿;
王凯月:文献调研,初稿撰写。
