基于局部和全局特征的深度伪造检测方法
2023-12-20杨新露
杨新露,程 健,张 凯
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001; 2.安徽理工大学 人工智能学院,安徽 淮南 232001)
神经网络已经应用于计算机视觉的各个领域,深度伪造技术也迅速发展,其主要通过生成对抗网络[1]和自编码器[2]实现,旨在对图像或视频中的人脸进行替换、修改面部属性或表情以及合成不存在的人脸.现在的伪造模型可以生成高质量的虚假人脸,人眼无法直接辨别真假.此外,即使是非专业人士不了解生成原理也可以通过应用程序和开源工具生成高质量的虚假图像.虽然深度伪造可以应用于计算机生成图像、虚拟现实、增强现实、教育、艺术、动画和电影制作[3]等方面,但是伪造方法也可能应用于恶意的目的.这些伪造的图像或视频上传到互联网上传播虚假信息或者金融欺诈等,对个人和社会带来严重的危害[4].
为了解决这些威胁,深度伪造检测技术不断发展来确定数字媒体的可信度和真实性.早期的深度伪造检测算法主要基于手工制作的特征和可见的伪影进行判别,如头部姿势不一致、眨眼、面部伪影等.近几年开始使用卷积神经网络[5]检测虚假图像或视频.卷积神经网络能够学习局部区域的微小视觉伪影来区分图像真假,也取得了比较高的准确性[6].由于卷积神经网络的感受野受限,只能通过学习局部纹理来区分真假.然而局部纹理在数据集间不同导致一些检测方法在FaceForensics++[7]进行训练和测试时显示出优越的性能,在Celeb-DF[8]或其他数据集上进行测试时准确性大幅度下降.因此,深度伪造检测方法的泛化性需要进一步提高.
一些伪造图像通过局部特征检测时是正常的,但是从全局特征中可以检测到伪影,因此提出了基于局部和全局特征的深度伪造检测方法来提高泛化性.首先,通过多尺度Transformer模块从不同尺寸的图像块中提取全局特征.此外,使用滑动窗口对图像进行分块,保存图像块间的相邻信息,从而更好地提取图像全局信息.进一步,将EfficientNet网络作为骨干网络,通过注意力机制提取图像局部特征.然后将全局特征和局部特征结合学习伪造图像中的伪影,对深度伪造人脸进行分类.在FaceForensics++、Celeb-DF和DFDC[9]数据集上的实验结果表明,所提出的方法在不同数据集之间具有一定的泛化性.
1 相关工作
1.1 深度伪造生成
深度伪造主要是由生成对抗网络和自编码器等深度生成模型实现,对图像或视频中的人脸图像进行篡改,生成逼真的虚假人脸.生成对抗网络使用生成器和判别器两个网络生成虚假人脸,判别器判别接收到图像的真假,生成器生成逼真的虚假图像以欺骗判别器.生成对抗网络在深度伪造领域获得了可信和逼真的结果,如StarGAN[10]、DiscoGAN[11]和StyleGAN-v2[12]等.自编码器生成假脸的方法是使用编码器-解码器分解和重组两个不同的人脸图像,通过交换解码器对人脸图像进行篡改.现在深度伪造方法多种多样,需要具有泛化性的方法进行检测.
1.2 深度伪造检测
为了避免深度伪造带来的安全威胁,研究人员提出了多种深度伪造检测方法.早期的深度伪造检测算法主要基于手工制作的特征和可见的伪影进行判别,如头部姿势不一致、眨眼、面部伪影等.现有的大多数面部伪造方法会将更改后的面部混合到现有的背景图像中.因此,现在主要是使用深度神经网络通过检测视觉伪影或混合边界来判别真假.Li等人[13]使用面部X射线检测伪造边界来判别图像真假.Zhao等人[14]为了挖掘更多细微的伪影提出了多注意力机制进行深度伪造检测,并将深度伪造检测制定为细粒度分类问题.Qian等人[15]发现深度伪造图像或视频中的伪影会被压缩操作破坏,但是在频域中仍然可以检测到,提出了空频结合的深度伪造检测方法.Saikia等人[16]利用基于光流的特征提取方法来提取时间特征,通过分析视频帧内和帧间差异来准确识别真实性.虽然这些检测方法在同一数据集进行训练与测试时取得了较高的准确性,但是在其他数据集上进行测试时有效性降低,深度伪造检测方法的泛化性有待提高.
1.3 Transformer
Transformer[17]是基于多头注意力机制的模型,具有强大的上下文建模能力.Transformer在机器翻译、文本分类、问题回答等自然语言处理任务中表现了出色的性能,如BERT[18],BioBERT[19]和GPT-3[20]等.最近Transformer扩展到图像领域应用于计算机视觉任务,如目标检测[21]、图像分割[22]、图像分类[23]等.ViT(Vision Transformer)[24]将图像处理成16×16的图像块,然后形成图像片序列,直接输入到Transformer的编码器中进行图像分类.现在研究人员开始使用Transformer进行深度伪造检测.Khan等人[25]使用ViT进行深度伪造检测,他们提出了增量学习策略,在较小的数据量上对所提出的模型进行调整,获得更好的检测性能.Wodajo等人[26]提出了卷积ViT,使用卷积神经网络提取特征,并使用ViT对学习的特征进行分类,取得了较好的检测性能.
2 基于局部和全局特征的深度伪造检测方法
本文提出了基于局部和全局特征的深度伪造检测模型,整体框架如图1所示.本文首先使用RetinaFace[27]从视频中提取人脸,然后使用Transformer网络结构和注意力模块分别提取局部和全局特征,最后通过这些特征对人脸图像进行分类.
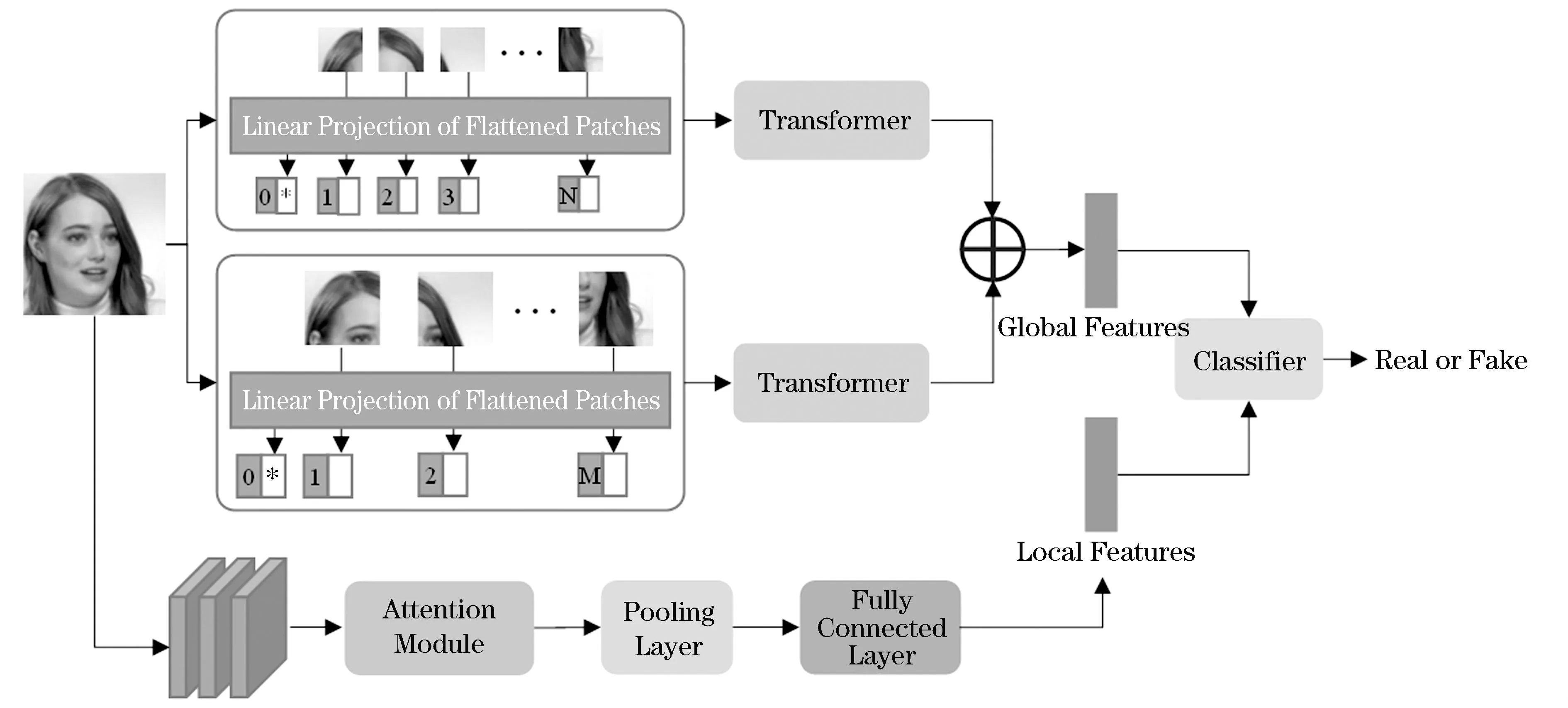
图1 基于局部和全局特征的深度伪造检测模型整体框架
2.1 提取视频帧和人脸
在深度伪造过程中主要是对人脸的面部区域进行篡改,背景区域一般保持不变.去除背景噪声后基于人脸区域训练模型,可以降低计算复杂度,提高模型的性能.因此本文从输入的视频中随机提取人脸图像,然后采用RetinaFace[27]进行人脸检测,根据五个标记点定位人脸面部矩形.对于图像中有多张人脸的情况,将检测到的人脸矩形的中心点与掩码的中心点进行比较,以确定检测到的人脸位置.本文将面部矩形放大1.2倍后裁剪每个帧上的面部区域,大小调整为224×224,并使用计算出的标记进行人脸对齐.
2.2 Transformer提取全局特征
在使用Transformer模型分析图像时,需要把输入图像I分成较小的图像块IP,然后组成序列.为了保存和学习局部区域的相邻信息,使用滑动窗口的方式对图像进行分割,将重叠的图像块作为输入.具体来说,将分辨率为H×W的输入图像分成大小为P×P的图像块,通道数不变,都为C.滑动窗口的步幅为S,每个相邻的图像块共享一个大小为P×(P-S)的相邻区域.因此,可以将输入的图像分成N个图像块:
(1)
将获得的图像块展平并投影到潜在的D维线性空间,先添加上图像的编码特征,然后添加可学习的位置编码保留每个图像块的位置信息,如式(2)所示:
(2)
其中:E∈P2×(C·D)是图像块编码,Epos∈(N+1)×D表示位置编码.
Transformer模型主要包括多头注意力模块和多层感知机模块,具体结构如图2所示.多头注意力模块可以更好地学习全局特征,对输入X执行三个可学习的线性投影WQ、WK和WV,通过式(3)生成Q(Query)、K(Key)和V(Value):
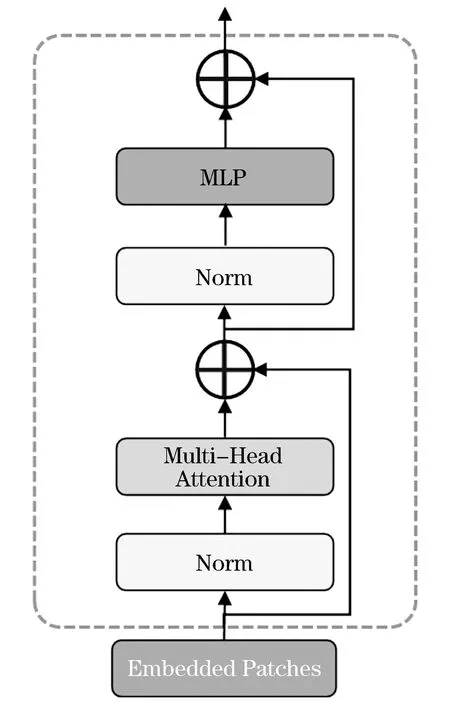
图2 Transformer结构图
Q=XWQ,K=XWK,V=XWV
(3)
然后矩阵Q、K和V通过式(4)进行自注意力计算.
(4)
其中:dK是K中每个输入向量的维度.
每一层的输出可以表示为:
(5)
ViT中使用固定大小的图像块,只能在小部分区域提取特征.为了更好地从全局中提取信息,提出了多尺度Transformer模块,有利于提取更细微的面部细节.所提出的多尺度Transformer框架由两个分支组成,包括小图像块分支和大图像块分支.这两个分支的主要区别是图像块的大小以及如何从这些图像块编码和位置编码中构建序列块编码.小图像块分支从较小尺寸的图像块中提取信息,大图像块分支从较大的图像块中提取更多的全局信息.最后将提取的两部分特征进行互补对伪造人脸分类.
2.3 EfficientNet提取局部特征
由于真实和虚假人脸图像之间的差异也存在于局部区域中,在提取全局特征的同时也需要注意局部特征.本文提出了基于注意力机制定位图像的伪造区域来获取局部伪造特征,然后使用区域独立性损失函数[14],允许多个注意力图聚焦在人脸的不同区域.
给定输出图像I,主干网络用f表示,从第t层提取的特征图用ft(I)表示,大小为Ct×Ht×Wt,其中:H、W和C分别表示特征图的高度、宽度和通道数.然后将主干网络特定层生成的特征图ft(I)输入到轻量级注意力模块.该模块由一个3×3卷积层、一个1×1卷积层、两个批归一化层和两个ReLU激活函数组成,具体模块如图3所示.注意力模块生成大小为Ht×Wt的多个注意力图,对应于特定的判别区域.

图3 注意力模块
由于不同的注意力图倾向于集中在图像中的相同区域,影响网络捕获更多的伪造痕迹.本文将Zhao等人[14]提出的区域独立性损失与交叉熵损失结合,将注意力映射到不同的伪造区域.最终的目标函数见式(6):
L=λ1*LBC+λ2*LRIL
(6)
其中:λ1和λ2是这两个损失函数的平衡权重,在实验中设置为λ1=λ2=1.
3 实验部分
3.1 数据集和评估指标
本文使用三个公开的人脸伪造数据集进行实验,即FaceForensics++(FF++)[7]、Celeb-DF[8]和DFDC[9].FF++是Deepfake检测领域最流行的数据集之一.FF++包含1 000个原始视频和4 000个伪造视频.原始视频是Rössler等人从YouTube收集,伪造视频是由Deepfakes、FaceSwap、Face2Face和NeuralTextures这四种伪造方法生成.网络上大多数视频经过压缩,为了模拟真实的伪造视频,使用不同压缩级别的H.264编码器进行压缩,生成高质量(C23)和低质量(C40)视频.Celeb-DF数据集包括590个不同年龄、种族和性别的受试者的原始视频,5 639个Deepfakes伪造视频,总帧数超过230万.该数据集是一个高质量伪造视频数据集,对大多数现有检测方法具有一定的挑战性.DFDC数据集是由Facebook主办的Deepfake检测挑战赛构建的大规模Deepfake数据集.该数据集包含3 426名付费演员的10万个视频,使用多种Deepfake和基于GAN的多种面部操作方法合成.
为了评估本文方法的有效性,采用准确率(ACC,Accuracy)和ROC曲线面积(AUC,Area Under the receiver operating characteristic Curve)进行评估.ACC计算公式如下:
(7)
其中:TP(True Positive)表示真脸预测为真,TN(True Negative)表示假脸预测为假,FP(False Positive)表示假脸预测为真,FN(False Negative)表示真脸预测为假.ROC曲线的横坐标为TPR(真正例率),纵坐标为FPR(假正例率),从而获得AUC值.AUC常用于图像和视频领域的分类任务,可以更直观地反应分类模型的优劣程度.ACC和AUC越大表明分类器的性能越好.
3.2 实验设置
本文提出的模型使用Pytorch深度学习框架实现.为了加快训练速度并取得更好的分类效果,加载在ImageNet数据集[28]上的预训练模型.在训练时使用Adam优化器,学习率为0.001,批量大小为8,epoch设置为50.
3.3 实验结果
3.3.1 数据集内评估
本文在FaceForensics++数据集不同质量的视频上进行训练与测试,并与其他检测方法进行比较,实验结果如表1所示.在人脸的局部和全局提取特征使得本文方法在低质量的视频上ACC达到了90.8%,AUC达到了93.67%,与其他方法相比取得了较好的结果.

表1 FaceForensics++数据集内对高质量和低质量视频的评估结果
3.3.2 跨数据集泛化性评估
现在的检测方法在训练集上取得了较好的检测性能,但是在其他数据集上测试时性能严重下降.为了评估本文方法在不同数据集之间的泛化性,在FaceForensics++数据集上进行训练,然后在Celeb-DF和DFDC数据集上进行测试,实验的AUC结果见表2.本文方法在Celeb-DF数据集上测试的AUC结果达到77.3%,在DFDC数据集上达到73.32%,在这两个数据集上的性能都优异于其他检测方法.通过与现有的方法比较,证明了本文方法能够捕获更多的伪造伪影,具有良好的跨数据集泛化能力.

表2 在Celeb-DF和DFDC数据集上的泛化结果(AUC(%))
3.3.3 不同伪造方法泛化性评估
本文进一步在FaceForensics++数据集的不同伪造方法生成的假视频中评估泛化性,在FaceForensics++数据集的3种伪造方法生成的数据集上进行训练并在剩余的伪造方法上进行测试.实验结果如表3所示,本文方法在4中伪造类型上测试的AUC值都达到了90%以上.本文使用Transformer提取全局特征并使用EfficientNet提取局部特征,更全面的捕捉各种伪造痕迹,因此本文方法可以很好地扩展到以前未见的深度伪造类型.

表3 FaceForensics++数据集上不同伪造方法之间的泛化效果(AUC(%))
3.4 消融研究
本文方法主要是通过Transformer提取全局特征和注意力网络提取局部特征后对图像进行分类.为了评估全局特征与局部特征结合的有效性,本节在FaceForensics++数据集上进行消融研究.实验结果如表4所示,本文方法与仅使用全局特征相比ACC提高了5.57%,AUC提高了4.52%.实验结果表明将全局特征与局部特征结合能够提高检测性能.
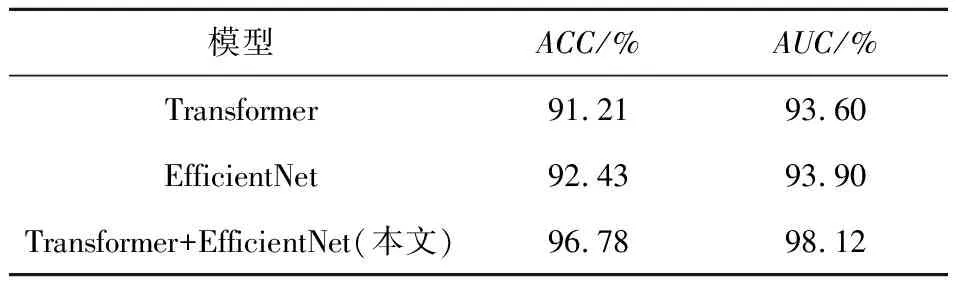
表4 在FaceForensics++数据集上的消融实验结果
4 结 语
针对目前深度伪造检测方法泛化性较差问题,本文提出了基于图像局部和全局特征进行分类的方法.通过多尺度Transformer模块从不同尺寸的图像块中提取特征,并保存图像块间的相邻信息,更全面的提取全局特征.使用EfficientNet网络作为骨干网络,并通过注意力机制提取图像局部特征.实验结果表明本文方法能够比现有检测方法捕获更多的伪影,在不同数据集和伪造方法之间表现出更好的泛化性.
