基于加权特征融合的多尺度遥感影像分类
2023-12-18程寅翥刘松王楠师悦天张耿
程寅翥,刘松,王楠,师悦天,张耿
(1 中国科学院西安光学精密机械研究所 光谱成像技术重点实验室,西安 710119)
(2 中国科学院大学,北京 100049)
0 引言
遥感影像分类是遥感影像处理中的关键分支,为精细农业、矿物勘探、城市规划以及其它工农业应用提供了重要依据。近年来,光谱成像技术从多光谱技术发展到高光谱技术,丰富的谱段信息对遥感影像分类算法提出了更高的要求。
许多基于传统方法的高光谱影像分类算法,例如超像素方法[1]、扩展形态学特征方法[2]、基于组合核的空-谱联合分类算法[3]、基于支持向量机和图割的分类算法[4],在各个高光谱公开数据集上均取得了一定的效果。这些方法往往采用人工设计的某种特征提取方法,结合经典的分类器,如支持向量机[5]、逻辑回归[6]、随机森林[7]等进行分类。
近年来,受益于硬件条件的提升和算法的更新迭代,各类深度学习算法层出不穷,并被研究人员引入高光谱遥感影像分类领域。这类方法为端到端的分类,特征提取和分类器设计合二为一,且采用多层网络进行特征提取,在误差反向传播的过程中不断优化网络参数,从而能够提取图像块更为深层的信息,大幅改进了原有算法的性能。2014 年,CHEN Yushi 等[8]将GEOFFREY Hinton 等提出的深度学习概念引入高光谱影像分类,并验证了堆栈自编码器在遥感影像分类领域的有效性。后来,深度信念网络[9]、孪生神经网络[10]、长短时记忆网络[11]、胶囊网络[12]、门控循环单元[13]、Transformer[14]等神经网络结构被相继引入高光谱影像分类领域,并取得了优良的性能。卷积神经网络(Convolutional Neural Network,CNN)是一种用于图像处理的神经网络,其通过模拟人类视觉过程,提取感受野的特征,并通过共享权值减少参数量。在高光谱影像分类领域,CNN 能够天然地融合空间维度和光谱维度的特征,基于CNN 的高光谱影像分类算法因而在各个公开数据集上取得了比许多其他算法更好的效果。在此基础上,SHI Yuetian 等[15]提出了利用多角度平行特征编码的方式,通过增强局部空间特征的方式提高图像分类精度,并且该算法对图像旋转是鲁棒的。三维卷积神经网络(Three-dimensional Convolutional Neural Network,3D CNN)[16]是一种常用于高光谱影像处理的卷积神经网络结构,与常见的2D CNN 不同,3D CNN 的卷积核为一个立方体,能比2D CNN 更好地提取光谱维度的特征,从而在各个高光谱公开数据集上取得了比2D CNN 更为优秀的性能指标。
尽管3D CNN 方法在目前的高光谱影像分类领域取得了一定的效果,但是该方法仍然存在许多问题。传统的3D CNN 通常从单一的尺度提取图像块,往往会损失一定的局部信息;单纯通过增加模型的深度来提高参数量,往往会导致梯度消失等问题[17],且容易导致过拟合。据此,本文提出了一种多支路3D CNN,三条支路分别采用三种不同的3D CNN 结构设计,从不同的尺度上提取了图像块的特征,从而既能获取全局信息又能兼顾局部信息,同时增加了参数量,提升了模型拟合能力。另外,为了缓解过拟合现象,引入了数据增强,并在训练阶段使用了丢弃法,本文引入了一种基于模拟退火算法的加权特征融合方法,提升了算法的性能。为了验证本文方法的有效性,分别在公开数据集Indian Pines,Pavia University,Salinas 等上采用10%的有标签数据进行训练,分别得到了98.60%、99.83%、99.97%的总体准确率,达到了目前的领先水平。进一步的实验结果表明,当有标签的数据比例从10%下降到2%时,本文方法相比对比方法的分类总体准确率更高。此外,还对本文方法进行了实用性验证,说明了本文方法具有一定的应用价值。
1 本文方法
如图1 所示,对于输入的高光谱数据立方体,本文首先采用主成分分析对数据进行降维,降维后光谱的维数选取为40。将数据立方体分解为许多19×19×40 的图像块,并以其中心像素的标签作为整个图像块的标签,之后采用旋转90°,180°,270°的方法进行数据增强。在特征提取阶段,采用了三支路并联的三维卷积神经网络,分别从2×2,4×4,6×6 三种空间尺度来提取特征。在训练阶段,采用Adam 优化器对三条支路的参数分别进行优化,并选用交叉熵损失函数。在测试阶段,对从三条支路上提取到的特征进行加权特征融合。在分类器方面,本文选择了逻辑回归分类器,这是一种经典而有效的分类器,对于中小规模的数据集具有不劣于全连接神经网络的效果[18]。

图1 针对高光谱遥感影像分类的多支路3D CNN 结构Fig.1 multi-branch 3D CNN framework for HSIC
1.1 预处理
可以将高光谱数据集描述为一个数据立方体X∈Rn1×n2×nbands。n1×n2为像素规模,代表空间信息。而nbands为波段数目,代表光谱信息。高光谱影像分类的要求是逐像素的分类,需要根据每个像素点的光谱信息以及上下文信息给出其类别。假设该数据集一共有nclasses类,则需要建立一个从高光谱数据立方体X∈Rn1×n2×nbands到集合Y={1,2,…,nclasses}n1×n2的映射。
对于预处理模块。HUGHES[19]现象指出,随着光谱波段范围增大和光谱分辨率的提高,分类准确率出现先上升后下降的现象。其出现的原因主要是:遥感影像各个谱段的相关性较高,因而有一定的冗余度,干扰了后续图像处理的过程。为此,研究人员提出了一系列的算法[20],如主成分分析、奇异值分解、线性判别分析、独立成分分析,以及各类波段选择方法等用于降低数据维度,缓解HUGHES 现象。根据MUHAMMAD A 等[21]的对比实验,在常见高光谱公开数据集下,对于多数分类算法,使用主成分分析算法进行降维的效果最好,故本文选取主成分分析作为降维算法。
将光谱数据中心化,并将其存放到一个m×n行,nbands列的矩阵A中[22]。协方差矩阵ATA的特征值分解为
式中,Λ对角线元素按照模的大小由大到小排列,取P的前若干列组成W,则主成分分析降维后的数据A′为
经由主成分分析,数据矩阵A被投影到AW,光谱由nbands维降到了40 维。
为了将数据立方体输入3D CNN 中,以每个像素为中心,取其周围19×19×40 的立方体为图像块(边缘部分不足的,使用零填充补齐),从而得到一系列3D 图像块,以这些3D 图像块中心像素的标签作为整个图像块的标签进行训练。
LI Wei 等[23]的研究表明,将图像块绕着Z轴旋转90°、180°、270°,可以有效缓解高光谱影像分类过程中的过拟合现象。具体做法如图2 所示。
1.2 三支路3D CNN 结构
3D CNN 包含输入层、三维卷积层、激活函数、池化层、全连接层、输出层等。如图3 所示,三维卷积核与图像块进行点乘,并沿着三个互相正交的方向滑动,从而形成一幅三维特征图。一个卷积层包含多个三维卷积核,从而形成多幅三维特征图。这些特征图经由参数b进行偏置,再通过激活函数F实现非线性映射。若第l层共有dl幅特征图,且卷积核的长、宽、高分别为2δ+1,2γ+1,2ξ+1,则第i层的第j幅特征图中,经过偏置和激活函数后,其(x,y,z)处的值表示为
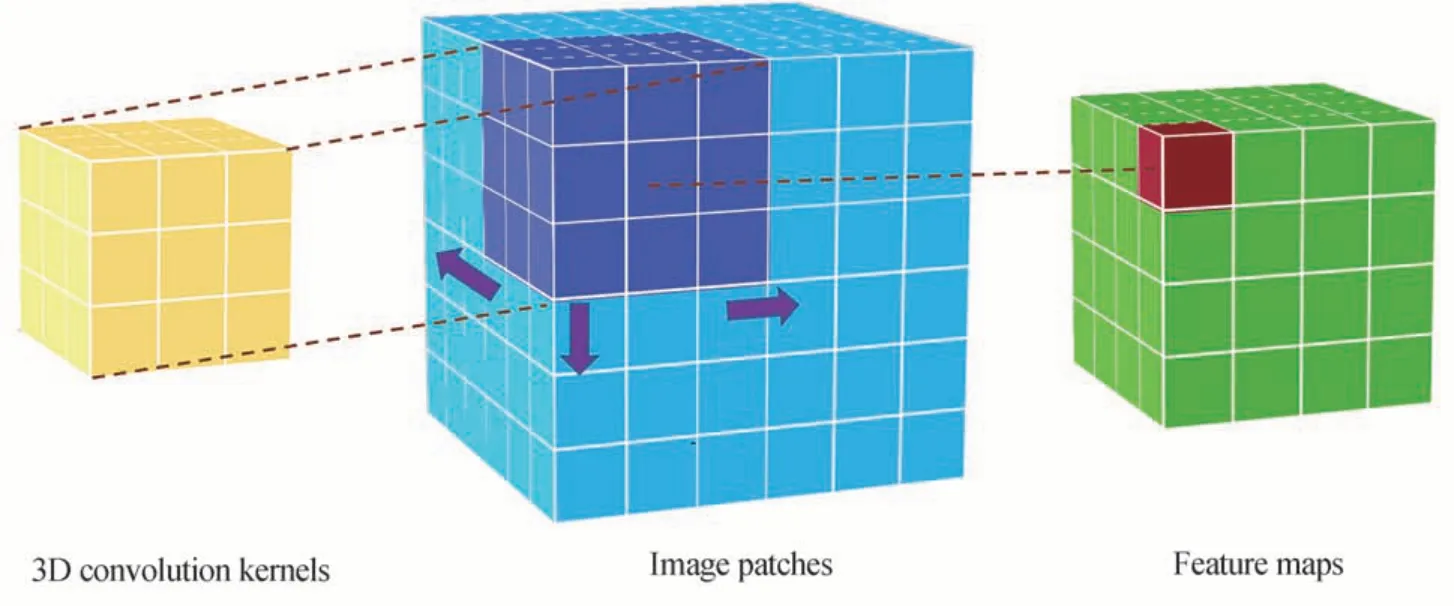
图3 3D 卷积层示意图Fig.3 Schematic diagram of 3D convolution layer
选取ReLU 函数为激活函数,可以减少计算量,并缓解梯度消失问题,该函数表达式为
池化层起到降采样的作用,本文方法选择最大池化层(Max pooling)。该层将输入特征图分为许多矩体,并取每个矩体内的最大值作为该区域的输出。从而降低了参数量,缓解了过拟合。全连接层是神经网络中起到分类器作用的层,该层的神经元密集连接。
在训练阶段,采用三条支路分开训练的方法,三条支路的网络结构图如图4 所示。
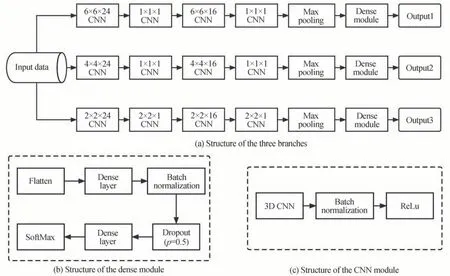
图4 训练阶段三条支路的网络结构图Fig.4 The network structure diagram of the three branches in the training phase
为了解决常规3D CNN 通常从一个尺度上提取特征,往往会丢失部分局部信息的问题,本文方法将数据输入三条3D CNN 支路中,分别从2×2,4×4,6×6 三种空间尺度来提取特征。在网络结构中用到了批量标准化[24](Batch Normalization,BN),以缓解梯度消失问题,加快网络收敛速度。在全连接层模块中使用了丢弃法[25](Dropout),将输入全连接层的数据的各个分量以0.5 的概率置为0,以缓解过拟合现象。
每批次数据的大小(Batchsize)为nbatch的情形下,若输入Batch normalization 层的数据为xi(i=1,2,…,nbatch),Batch normalization 单元的表达式为
经由上述变换,每批次内的数据均值变为0,方差变为1。再经由下列的变换,得到Batch normalizatiion层的输出(γ和β是可学习参数)
通过softmax 层产生输出,若输入softmax 层的数据为xt(t=1,2,…,nclass),其类别为c的概率为
采用交叉熵损失函数[26],该损失函数下网络收敛较快。交叉熵损失函数表达式如下(nbatch为该批次样本总数,nclass为类别数,Iic在样本i被预测正确时为1,否则为0)
采用Adam 优化器[27]进行优化,这是一种自适应学习率的优化器,是带动量的随机梯度下降算法和RMSProp 算法的结合。实验表明,该优化器在现有的多数数据集上可以使得网络收敛速度较快。
1.3 基于模拟退火算法的加权特征融合
在测试阶段,通过三条3D CNN 支路提取特征,并进行特征融合后,采用逻辑回归分类器进行分类。现有的特征融合方法通常将三条支路的特征直接拼接,而本文提出了一种加权的特征融合方法。本文特征融合的表达式为(⊗为克罗内克积;α1,α2,α3为加权系数;f1,f2,f3为三条支路的特征;f为融合后的特征)
式中,α1,α2,α3最优的取值可以采用模拟退火算法得到。模拟退火算法[28]是对固体退火过程的模拟,以α=(α1,α2,α3)取值为模拟退火算法的状态向量;将模拟退火算法的能量函数,即损失函数设为L(α)(本实验中以验证集准确率的负值为损失函数)。温度为T时,由状态(α1,α2,α3)转移到新状态(α'1,α'2,α'3)的概率由以下的Metropolis 准则求得
由马尔科夫链[29]相关理论,随着T→0,该随机过程在各温度下达到平衡状态后,L(α1,α2,α3)→Lmin,此时取到了最优的加权系数。具体而言,模拟退火算法由外循环和内循环组成,其算法过程描述为
输入:i(外循环当前轮次),j(内循环当前轮次),n1(外循环最大迭代次数),n2(内循环最大迭代次数),α(状态向量),new(α)(状态更新准则),L(α)(损失函数),T(i)(温度函数)。


1.4 逻辑回归分类器
采用逻辑回归算法对样本进行分类。该分类器通过逻辑斯蒂克函数刻画样本属于某一类的概率。假设共有nclass类样本,记为1,…,c,…,nclass。
设第c类样本数为nc,该类中各个样本的特征为fi(i=1,2…,nc),若样本fi的标签为c,则yi取1,否则yi取0。在上述符号规定下,逻辑回归分类器的似然函数为
通过最大似然估计,可以得到参数wc和bc。样本属于第c类的概率表示为
取概率最大的那一类作为分类结果即可。
2 实验与分析
2.1 数据集介绍
为了验证本文方法的有效性,在Indian Pines,Pavia University,Salinas 三个公开数据集上进行了实验,下面分别对这些数据集进行介绍:
1)Indian Pines:Indian Pines(IP)数据集是最早的高光谱影像分类测试数据。采用机载可见红外成像光谱仪(Airborne Visible Infrared Imaging Spectrometer,AVIRIS)收集数据,光谱仪波长范围为0.4~2.5 μm,以220 个连续波段对地物进行连续成像,其中20 个噪声严重的波段被剔除。该数据集包含16 种地物,像素规模为145×145,其中有标签的样本数目为10 249,具有典型的样例不均衡的特点,且由于空间分辨率较低,为20 m,有严重的混合像元现象,具有一定的难度。
2)Pavia University:Pavia University(UP)数据集是德国机载反射光学光谱成像系统(ROSIS-03)于2003 年在意大利帕维亚城市获取的高光谱数据的一部分。光谱成像仪在0.43~0.86 μm 波长范围内对115 个波段进行连续成像,其中12 个波段由于受噪声影像严重而被剔除,所得图像的空间分辨率为1.3 m,像素规模为610×340。该数据集共有9 类地物,其中有标签的样本数目为42 776。
3)Salinas:Salinas(SV)数据集由AVRIS 成像光谱仪采集,其拍摄地点是加州Salinas Valley。这个数据集的空间分辨率是3.7 m,像素规模为512×217,共有224 个波段,剔除部分噪声波段后剩余了204 个波段。该数据集共有16 类地物,其中有标签的样本数目为54 129。
表1 展示了上述数据集各类样本的数目。
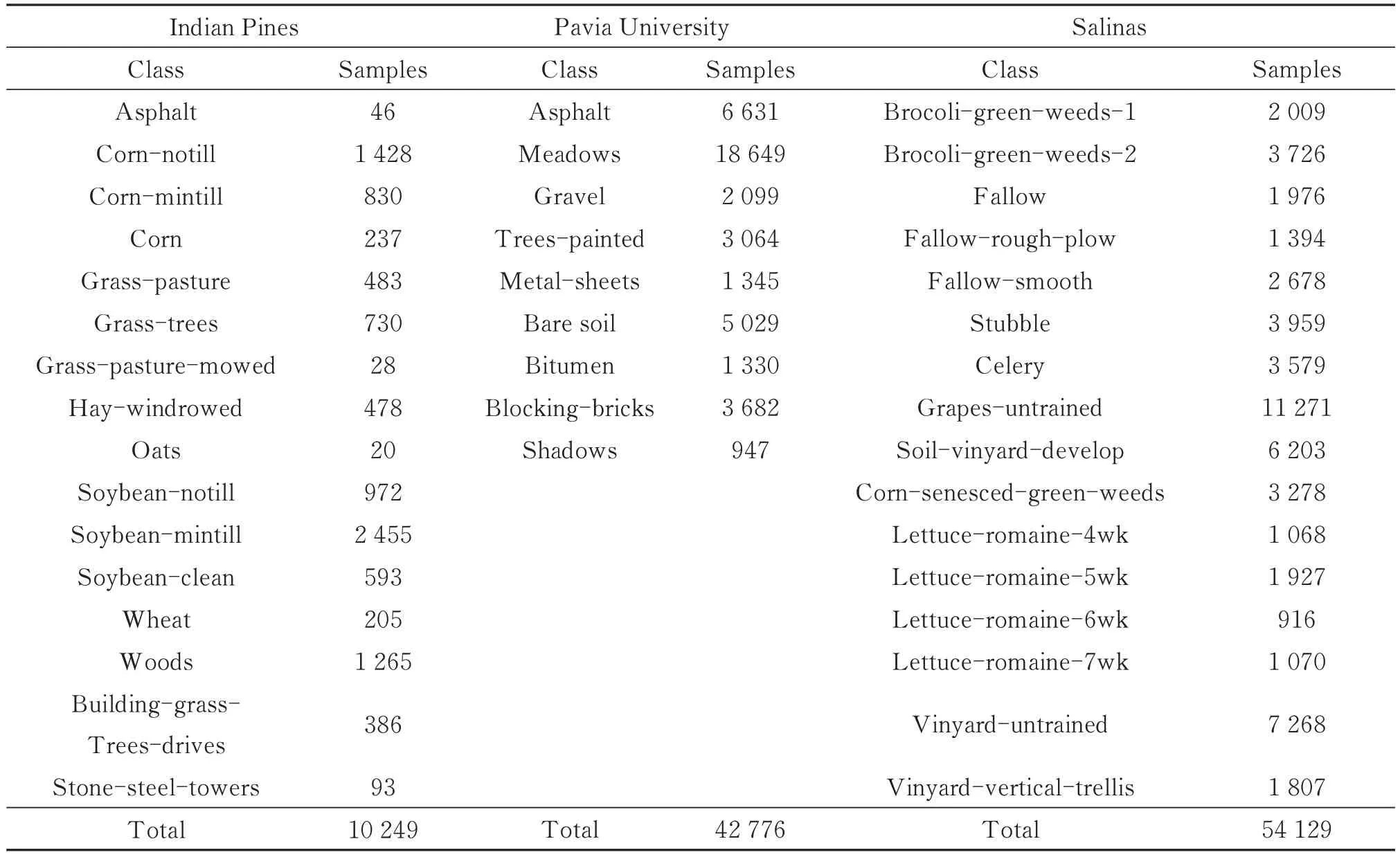
表1 高光谱遥感数据集样本分布Table 1 Sample distribution of hyperspectral remote sensing dataset
2.2 实验环境与参数设置
实验硬件条件为:处理器为AMD Ryzen 9 5900HX;内存为DDR4 3 200 MHz 16 GB×2;显卡为NVIDIA GeForce RTX 3080,显存为16 G。软件环境为windows11 下的python 3.8+tensorflow 2.3.0+numpy 1.23.5。
在参数设置方面,采用Adam 优化器的默认参数进行训练;BatchSize 设置为100;最大训练轮数设置为150,以使得模型收敛;每训练三轮进行一次验证,仅仅保存损失最小的模型;Dropout 的概率设置为0.5,以缓解过拟合。训练集、验证集、测试集分别随机取总样本量的9%,1%和90%(部分算法不需要验证集,则将训练集和验证集合二为一)。
2.3 性能指标
本实验采用的性能指标有总体准确率(Overall Accuracy,OA),平均准确率(Average Accuracy,AA),Kappa 系数。下列各式中,c为类别数,Ni为第i类样本的数目,mij表示第j类样本被分为i类的数量,mij各元素组成了一个混淆矩阵。
1) OA 为正确分类的样本数与总样本数N的比值,表示为
2) AA 为各类分类准确率的平均值
3) Kappa 系数是基于混淆矩阵的精确度度量,其公式为
2.4 分类结果
实验对比了本文方法与支持向量机(Support Vector Machine,SVM)、长短时记忆网络(Long Short-Term Memory,LSTM)、门控循环单元(Gated Recurrent Unit,GRU)、深度语义卷积神经网络(Going Deeper With Contextual CNN,CDCNN)、双支路双注意力机制网络(Double-Branch Dual-Attention Mechanism-Network,DBDA)、双支路多注意力机制网络(Double-Branch Multi-Attention Mechanism Network,DBMA)等方法。这些对比算法均在文献中被证明在高光谱遥感影像分类任务中有效,采用文献中的默认参数将这些方法与本文方法进行对比实验,证明本文方法的有效性。
对比方法分别为:1) SVM[30]:基于最大分类间隔的分类器;原文作者在经典SVM 的框架下优化了其核函数,并在算法中引入了光谱角以提升分类性能;2) LSTM[31]:通过输入门、遗忘门和输出门控制网络信息流动的一种循环神经网络,其输出由当前输入和历史输入所决定,相比于传统的循环神经网络,LSTM 能够有效地解决长时间序列中的梯度消失和梯度爆炸等问题,由于引入了遗忘门,其能够忽视历史输入中的次要信息,从而获得比传统的循环神经网络更为优良的性能;3) GRU[31]:通过更新门和重置门控制网络信息流动的一种循环神经网络,其中,更新门有利于捕捉时间序列里的长期依赖关系,而重置门有利于捕捉时间序列里的短期依赖关系;4) CDCNN[32]:一种包含多尺度滤波和残差单元的 2D CNN 网络,能利用相邻像素的局部空间光谱关系很好提取各个像素的上下文信息,原文作者引入了多尺度空间滤波器组提取空间特征,与光谱特征进行联合推理,实现空谱联合分类;5) DBDA[33]:双分支的3D CNN 网络,原文作者引入了自己设计的注意力机制,且采用了Mish 激活函数代替常用的ReLu 激活函数;6) DBMA[34]:双分支的3D CNN网络,两条支路分别注重提取空间特征和光谱特征,从而缓解两方面特征的相互干扰,且仿照稠密连接网络引入了三维稠密连接模块,并引入了空间注意力机制和通道注意力机制。
实验在IP、UP、SV 三个公开数据集上进行,分类结果由表2~表4,图5~图7 所示。
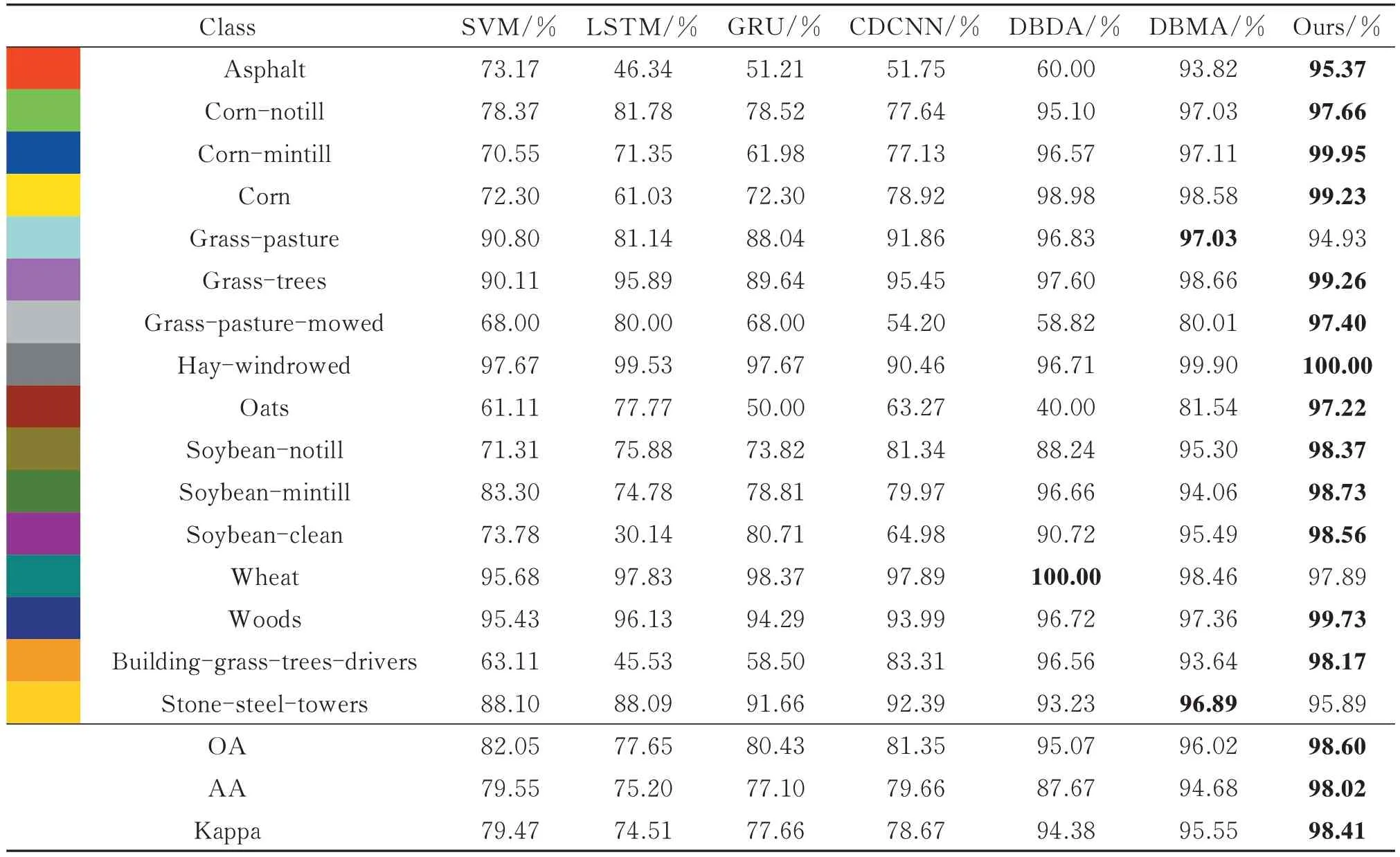
表2 IP 数据集使用10%有标签样本的分类结果表Table 2 Classification results for the IP dataset using 10% of the available labeled data

图5 使用IP 数据集10%有标签样本的分类结果Fig.5 Classification results for the IP dataset using 10% of the available labeled data
1) Indian Pines 数据集
随机选取Indian Pines 数据集中922 个样本作为训练集,103 个样本作为验证集,9 224 个样本作为测试集,并进行五次重复实验,得到的分类结果如表2 和图5 所示,每类最好的分类结果加粗。从图5 可以看出,SVM、GRU、LSTM、CDCNN 这些方法的分类结果中有较多噪声,分类性能不佳;各类基于3D CNN 的方法,如DBDA 和DBMA 等可以很好地融合空间信息和光谱信息,取得了更好的分类性能。相比于对比方法,本文方法的分类结果图与真值图最为为接近。本文提出的方法引入了旋转数据增强,并从多尺度上提取了特征,能更准确地对高光谱影像进行分类。从表2 可以看出,本文方法对于IP 数据集16 个类别中的13 个类别,均取得了最高的准确率,对于Hay-windrowed 类别取得了100%的准确率。本文方法的OA,AA,Kappa 等性能指标均优于其他对比方法。相比于次优的DBMA 方法,本文方法的OA,AA,Kappa 指标分别提升了2.69%、3.53%、2.99%。
2) Pavia University 数据集
随机选取Pavia University 数据集中3 850 个样本作为训练集,428 个样本作为验证集,38 498 个样本作为测试集,并进行五次重复实验,得到的分类结果如表3 和图6 所示,其中每类最好的分类结果加粗。从图6可以看出,相比于对比方法,本文方法的分类结果图与真值图最为为接近。从表3 中可以看出,本文方法对于UP 数据集9 个类别中的5 个类别取得了最高的准确率,对于Meadows 类别和Bare Soil 类别取得了100%的准确率。本文方法的OA、AA、Kappa 等性能指标均优于其他对比方法。相比于次优的DBMA 方法,本文的方法的OA、AA、Kappa 指标分别提升了0.30%、0.29%、0.40%。
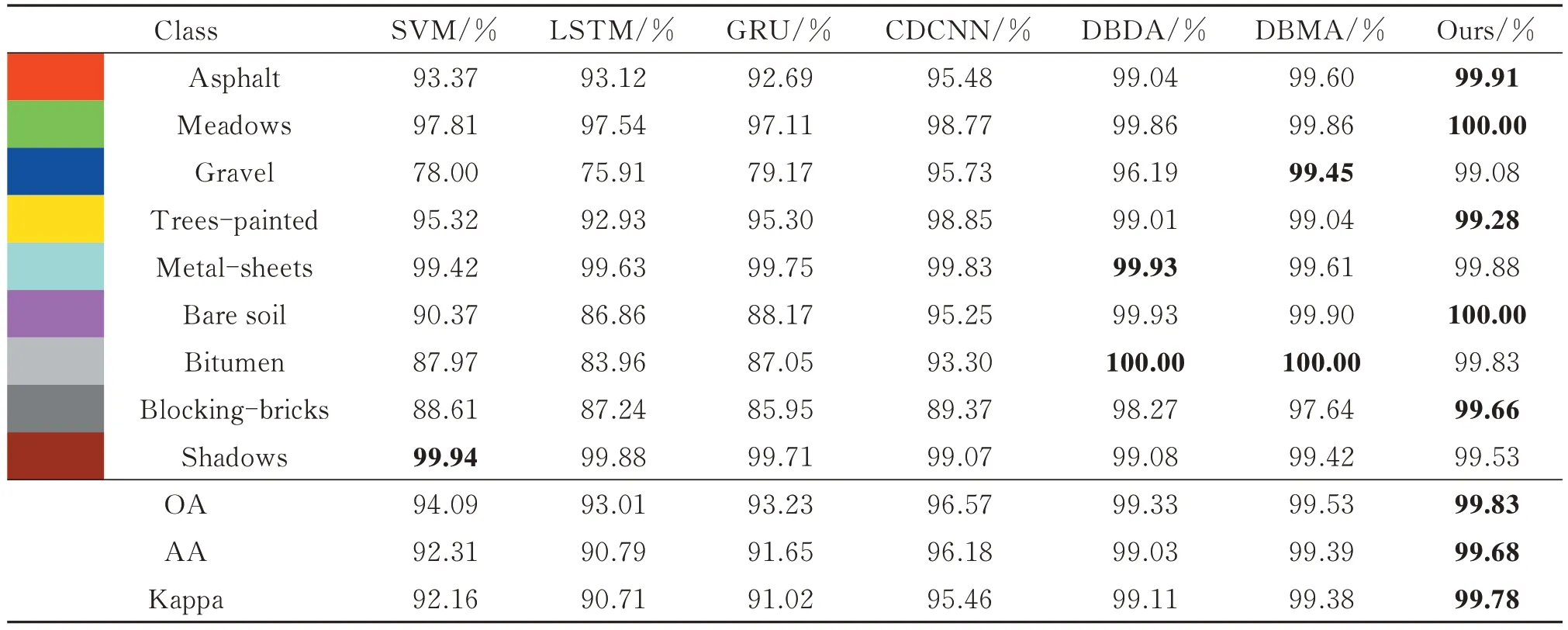
表3 UP 数据集使用10%有标签样本的分类结果表Table 3 Classification results for the UP dataset using 10% of the available labeled data

图6 使用UP 数据集10%有标签样本的分类结果Fig.6 Classification results for the UP dataset using 10% of the available labeled data
3) Salinas 数据集
随机选取Salinas 数据集中4 872 个样本作为训练集,541 个样本作为验证集,48 416 个样本作为测试集,并进行五次重复实验,得到的分类结果如表4 和图7 所示,其中每类最好的分类结果加粗。从图7 可以看出,相比于对比方法,本文方法的分类结果图与真值图最为为接近。从表4 中可以看出,本文方法对于SV 数据集16 个类别中的15 个类别,均取得了最高的准确率,对于其中8 个类别取得了100%的准确率。本文方法的OA、AA、Kappa 等性能指标均优于其他对比方法。相比于次优的DBMA 方法,本文方法的OA、AA、Kappa 指标分别提升了1.09%、0.79%、1.20%。

表4 SV 数据集使用10%有标签样本的分类结果表Table 4 Classification results for the SV dataset using 10% of the available labeled data

图7 使用SV 数据集10%有标签样本的分类结果Fig.7 Classification results for the SV dataset using 10% of the available labeled data
4) 训练时有标签样本占比与总体准确率的关系
为了进一步探究有标签样本占比与总体准确率的关系,并验证本文方法各个模块的有效性,在Indian Pines、Pavia University、Salina 数据集上进行了一系列消融实验。消融后方法分别为:多支路无数据增强3D CNN、单支路有数据增强 3D CNN、单支路无数据增强 3D CNN。IP 数据集上的分类结果如图8(a)所示,UP 数据集上的分类结果如图8(b)所示,SV 数据集上的分类结果如图8(c)所示。横轴表示训练时用到的有标签样本的比例,纵轴表示测试集上的总体准确率(OA)。
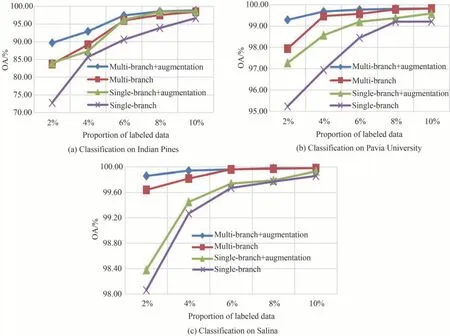
图8 训练时有标签样本比例与分类结果的关系Fig.8 The relationship between the proportion of the available labeled data and classification results
从图8 可以看出,对于IP、UP、SV 三个数据集,本文提出的方法与消融后方法相比,在训练时采用的有标签样本比例逐渐减少的情形下仍具有更高的总体准确率。即使只采用2%的有标签样本进行训练,本文方法在这三个数据集上仍能获得较好的分类结果,而消融后的方法受样本量减少的影响更大。该实验说明了无论是数据增强,还是多支路结构,均能有效提升3D CNN 对于遥感影像分类问题的准确率。且当两者共同运用时,分类准确率会有进一步地提升。
5) 小样本情形下的对比实验
为了进一步验证本文方法相比于对比方法在小样本情形下的优势,将本文方法与前文实验中较优的DBDA、DBMA 方法进行进一步对比。采用2%的有标签数据对IP、UP、SV 三个数据集进行分类,其分类结果如表5 所示。

表5 采用2%有标签样本训练时各算法的分类总体准确率Table 5 The overall classification accuracy of each algorithm when using 2% labeled samples for training
从表5 可以看出,在小样本情形下,本文方法比对比方法分类准确率明显更高。这验证了本文方法在小样本情形下,相比于对比方法的优势。
6) 实用性验证
为了验证本文方法的实用性,采用本文方法对无人机机载高光谱相机采集的数据进行了分类。该高光谱相机光谱范围为400~1 000 nm,波段数为176,空间分辨率为0.05 m。成像区域为我国山东烟台沿海区域,共有5 类地物。应用本文方法,采用1%的有标签样本进行训练,得到了99.64%的总体准确率。该数据集伪彩色图如图9(a)所示,真值图如图9(b)所示,分类结果如图9(c)所示。从图中可以看出,本文方法的分类结果与真值图较为接近,分类错误较少。该实验表明,本文方法具有一定的应用价值。

图9 机载高光谱数据集伪彩色图及其分类结果Fig.9 Airborne hyperspectral dataset and its classification result map
3 结论
针对普通的3D CNN 从一个尺度上提取特征,会丢失部分细节信息,且对于小样本任务表现一般的问题,本文提出了一种三支路的3D CNN,从不同尺度上提取特征后进行加权特征融合,从而获取了更为全面的特征;并引入旋转数据增强技术,从而改善了小样本情形下的分类性能。实验结果表明,从多个尺度上对高光谱数据进行特征提取,可以获得更为丰富的空间信息,提升遥感影像分类的性能指标。采用合适的数据增强技术,也可以提升遥感影像分类的性能指标。本文方法与各类对比方法相比,在各类数据集,各种训练样本比例的情形下均有优势,说明了模型具有较强泛化能力,且能很好地适应小样本情形下的高光谱影像分类问题。
由于本文采用了多个3D CNN 支路,导致训练时间和测试时间偏长,今后可以考虑采用各类并行计算方法以缩短训练时间;采用各类模型压缩方法如知识蒸馏、剪枝以缩短测试时间。此外,可以考虑在本文方法中引入一些卷积神经网络的最新成果如可变型卷积、Transformer 等,进一步提高分类准确率。
