基于窥孔结构LSTM 的电力系统跳闸故障诊断
2023-12-16张平王鹏展龚宁郑征高晶张晓东庄伟
张平 王鹏展 龚宁 郑征 高晶 张晓东 庄伟
跳闸;故障诊断;长短时记忆网络;窥孔结构;多源时序数据
0 引言
随着输电网络的扩展和负荷的增加,电力系统也会发生变化.电力系统高精度故障预测可以增加系统运行的可靠性和稳定性,并可以有效防范电力事故造成的巨大经济损失.故障预测是指通过分析和挖掘电力历史数据的隐藏信息,判断电力系统是否存在故障的一种技术.故障预测可以帮助决策者做出合理的决策以防止电气故障和减少不良影响,采取相关措施预防事故,并确保系统恢复.线路跳闸故障是电力系统中最常见的故障.近年来,很多研究者也证明:如果重合电闸不成功,将导致大规模停电,造成财产损失[1].因此,线路跳闸故障预测是非常有意义有价值的研究课题.
在以往的电力系统故障预测研究中,国内外学者提出了各种可用于电力故障预测的人工智能方法,比如专家系统[2]、贝叶斯网络[3]、粗糙集合[4]、佩特里(Petri)网[5]、神经网络[6]等.此外,研究人员还关注过去几年继电保护动作相关的研究和电气元件动作研究,并开发了新的分析模型[7],进一步提高了故障诊断结果的准确性.新的分析模型[7]基于改进的时间约束网络将系统故障事件推理和诊断定义为测试故障假设的优化问题.然而,这些流程在处理方面存在缺陷,如果继电器保护元件和电气故障组件存在冲突会有失效的风险.此外,基于保护的方法只能在故障出现之后提供支持,它不能预测输电和配电系统是否存在故障.实时的电气测量数据存在有关故障的隐藏信息.分析历史数据可以帮助预测电力系统是否会出现故障并帮助做出相应的决策以防止电力系统瘫痪.基于电气测量数据驱动方法的研究刚刚出现就快速成为一个有价值的研究主题.
近年来,许多研究提出基于人工智能的电力系统故障预测方法.例如:郑征等[8]提出一种基于多头注意力的卷积循环神经网络深度学习模型,该模型利用卷积和加权机制对电力属性和有功功率间的局部相关性进行建模;Ponraj等[9]提出一种基于多级遗传算法改进的优化神经网络预测方法;Eissa[10]提出对广域保护和控制系统瞬态不稳定性的在线预测神经网络方法;Li等[11]提出基于小波和人工神经网络的中压直流船舶电力系统的故障检测与分类;李嘉雨等[12]针对架空输电线路弧垂在计算过程中易受测量数据影响的问题,提出一种基于数据预处理的粒子群优化-反向传播(Particle Swarm Optimization-Back Propagation,PSO-BP)神经网络弧垂预测模型.然而,这些方法并没有考虑到电气数据是多源且时序的数据,而单一的将变量输入全连接网络强制拟合,导致大量的时序趋势信息被忽略,会影响方法的准确性.循环神经网络(Recurrent Neural Network,RNN)在时序建模任务如语音转换[13]、自然语言处理[14]等方面表现良好,在故障预测方面也表现出良好的准确性[15].然而,RNN存在梯度消失的问题,在长时序数据中历史计算节点对于先前计算节点的感知降低会导致最后的输出偏离目标值;并且,RNN作为一种循环递归网络,所需计算量由递归深度决定,导致计算量远大于估计值.因此研究如何缓解梯度消失问题,提出准确率较好的模型非常具有实际意义.长短时记忆网络(Long Short-Term Memory,LSTM)[16]作为一种改进的时序序列模型,与传统RNN相比,依靠遗忘门机制和输出门机制,仿照人脑记忆过程,对于长时间的特征融合任务具有良好的鲁棒性和收敛性.然而,基于LSTM的电力跳闸故障预测研究目前仍处于起步阶段.窥孔连接结构是一种LSTM变体结构,它通过增加遗忘门和输出门的栅极连接来增强单元间的状态通信强化网络长时间记忆能力.鉴于电力运行数据是一种连续的、多源的长时序数据,在时序上表现出较强的关联逻辑,因此,本文使用窥孔LSTM挖掘多源电气数据进行跳闸故障预测.
在故障预测过程中,故障分类是重要组成部分.支持向量机(Support Vector Machine,SVM)是一种由超平面定义的判别分类器.徐瑶等[17]指出基于SVM的故障分类方法是可行的,并且SVM分类方法具有良好的鲁棒性和泛化性.
在先前的研究中,刘冬兰等[18]将自动编码器应用于电力系统故障诊断的研究中,仿真结果验证了基于深度学习方法的故障预测的可行性.本文提出一种数据驱动的线路跳闸故障诊断方法.与传统方法相比,基于窥孔LSTM网络和SVM的模型结构捕捉多源时序数据的时间特征提高了整体性能.将该模型应用于电力系统中的多条线路时,可以检测出哪条线路出现故障.此外,本文方法可用于电网故障预测及故障预防工作,减少电力损失事故.本文的主要贡献概述如下:
1)通过实验和方案设计证明了窥孔LSTM+SVM进行电力系统故障预测的可行性.
2)选择多条输电支路的有功功率作为输入提取更加全面的时序信息,通过窥孔LSTM融合时序趋势信息提升性能.
3)使用SVM作为尾部分类器,仿真实验结果表明本文方法鲁棒性更佳.
4)本文方法是一种改进的实时故障预测方法.由于窥孔LSTM的计算复杂度低,本文方法可以适应实时性的要求.
1 问题描述
线路跳闸是一种常见故障,可导致大规模停电.近年来,许多继电保护动作和电气元件动作被用于故障诊断.线路跳闸故障的最常见原因包括配电设备老化和绝缘体损坏、天气变化等.故障相关性表现为线路跳闸前配电线路电气数据发生故障时变化的情况.在发生故障时电气测量数据会根据一些规则进行变化,这些变量包括电流、电压、有功功率和用户在该过程中的无功功率.因此,必须挖掘故障记录和电气测量之间的相关性.假设P是故障预测的结果,P=1表示存在故障,P=0表示正常.本文提出的解决方案的流程如下:首先,采集输电过程中的电流电压和有无功电气数据并进行一定的特征归一化形成多源时序数据,其次,输入LSTM网络提取多源时序信息,最后,将提取的时序信息输入SVM做结果预测.
2 模型组件及其原理
2.1 循环神经网络
循环神经网络(RNN)是针对时序任务的一类人工神经网络,其中,人工神经单元之间的连接在同一层内形成有向循环.相比之下,传统的神经网络只有层之间的连接,层中的单元没有连接.同时,传统人工神经网络层序之间不传输时间信息,因此处理时间序列的性能可能很差.
RNN的简单结构如图1所示.其中,正向传播的计算过程如下:
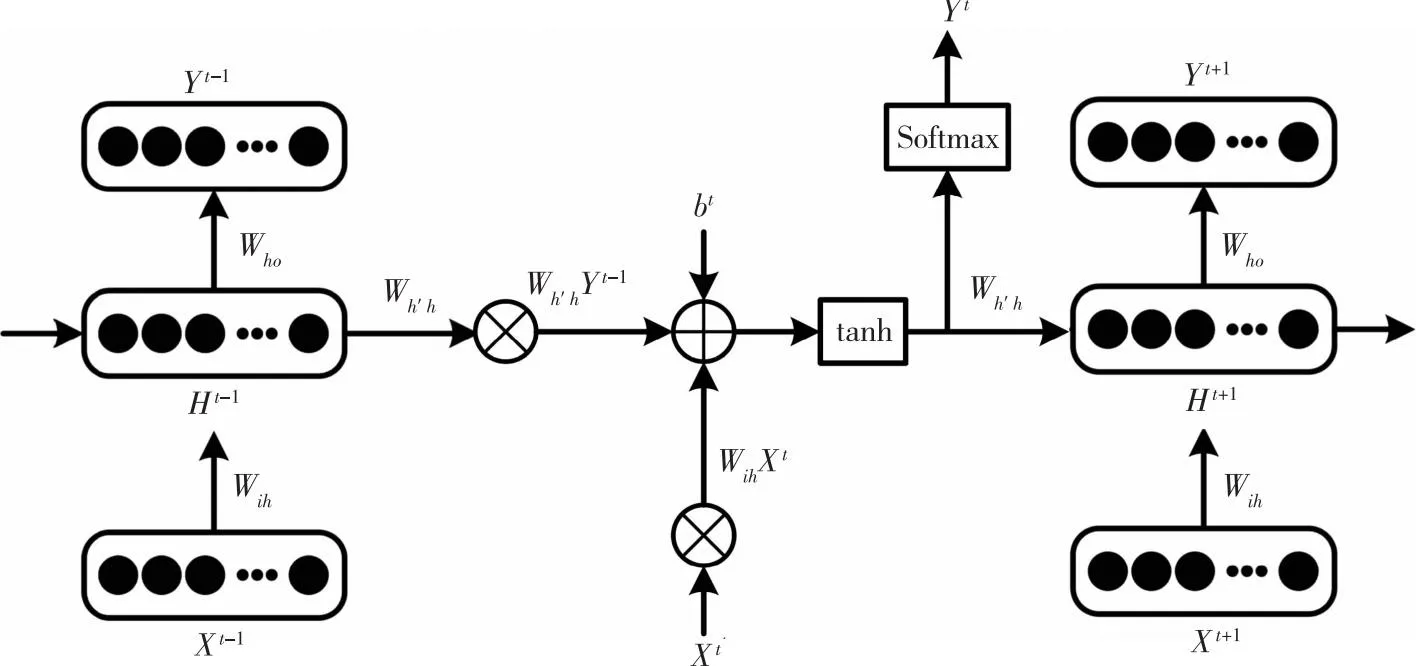
图1 一个简单的RNN结构(X是输入单元,H是隐藏单元,Y是输出单元,W是权重矩阵)Fig.1 A simple RNN structure (X,H,Y,and W represent input unit,hidden unit,output unit and weight matrix)
(1)
(2)
(3)
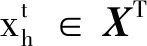
隐藏层神经网络单元不仅接收数据输入,还接收上一时间点隐藏层的输出构成有向图循环.因此,网络可以记住近期的趋势信息并将其应用于当前输出的计算.RNN全局架构近似有向时序图显示动态时序行为,并且在处理时间序列分析方面具有更好的性能.相应地,RNN需要通过单元之间梯度的反向传播来训练参数矩阵.RNN在电力系统跳闸诊断中具有广泛的应用.电力系统中可能存在诸如线路故障、设备损坏、负载异常等原因导致跳闸的情况,RNN可以通过学习历史数据,预测电力系统的运行状况,从而实现跳闸诊断.具体来说,RNN可以通过输入电力系统的历史数据(如电流、电压、功率等),进行学习和训练,并生成预测结果.这些预测结果可以用来识别异常情况,并在系统出现问题时及时采取措施,避免损失.然而,原始RNN容易受到梯度消失问题的影响.考虑到电力系统数据可能非常复杂,包含多种信号和噪声,原始RNN模型在学习复杂数据时会变得深入和复杂,后面的节点对前一时间步节点的感知降低,因此,原始RNN性能会随着时序增长而下降.
2.2 窥孔变体长短时记忆网络
当循环神经网络单元搭建的模型结构变得深入且复杂时,后面的节点对于前面时间序列点的感知随着时序变长而降低,导致结果偏差.而LSTM使用遗忘门栅极结构将前一个时间步和隐藏状态有选择地延续到后续时间步单元的计算中,以此缓解长时序梯度消失的问题.窥孔连接变体长短时记忆神经网络(Peephole LSTM)是一种改进的长短时记忆神经网络,其结构如图2所示.窥孔LSTM网络本质上就是在LSTM的隐藏层中增加了遗忘门、输入门和输出门的三级栅极连接(如虚线所示).这些连接允许LSTM单元通过监视单元状态来决定门的开启程度,从而更好地控制信息流.具体来说,在计算输入门、遗忘门和输出门的时候不仅考虑输入和隐藏信息,还考虑上一时间单元格的状态信息.遗忘门根据当前时刻的输入、上一时刻的细胞状态以及上一时刻的输出进行选择性地丢弃或增加信息,同时更新当前时刻的细胞状态.输出门根据当前时刻的细胞状态、当前时刻的输入以及上一时刻的输出和细胞状态更新当前时刻的输出.至此,窥孔LSTM通过以上3个改进门控单元的相互作用和串联,反复迭代梯度回传更新得到神经网络权值.这种做法被认为可以提高LSTM的建模能力和泛化能力,特别是在长期依赖关系建模方面.
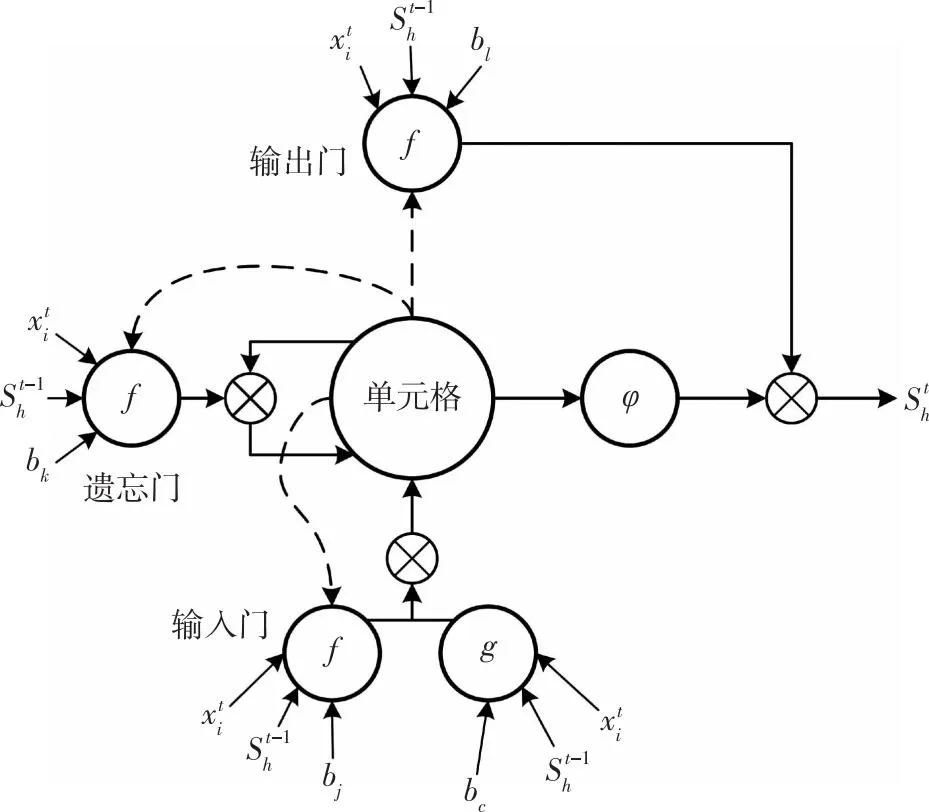
图2 带有单元格输入、输出和遗忘门的窥视孔LSTM块(其中所有边缘都具有固定的单位质量;虚线表示当前和上一个时间步之间的窥孔连接)Fig.2 A peephole LSTM block with cell input,output,and forgetting gates (where all edges have a fixed unit weight; the dashed lines represent the peephole connection between current and previous time steps)
考虑到电力系统中的时序数据通常包含很长的时间跨度和复杂的依赖关系,并且涉及到的传感器数据和监测数据非常多,同时这些数据存在着高度的不确定性和噪声干扰,将窥孔LSTM应用在电力系统跳闸诊断中,可以取得更好的预测成果.
1)窥孔LSTM 可以更好地捕捉电力系统序列数据的长期依赖关系,更好地预测未来的跳闸故障.
2)更少的训练时间和更好的泛化能力.窥孔LSTM 在训练时需要的迭代次数较少,因此,在训练时间上比传统的LSTM模型更加高效,同时,它也具有更好的泛化能力,可以更好地处理新的时序跳闸故障数据.
3)相比于传统的机器学习方法和传统的LSTM模型,窥孔LSTM具有更强的记忆和预测能力,可以更好地处理时间序列数据的非线性关系.
2.3 SVM分类器
窥孔LSTM能够处理序列数据并捕捉序列中的长期依赖关系,因此可以用于分析时间序列数据,如电力系统中的传感器测量数据.通过训练窥孔LSTM模型,可以预测未来的故障状态,并帮助监测员采取相应的措施.
然而,窥孔LSTM的预测结果并不总是准确的,因为它可能会受到许多因素的影响,如数据噪声、季节性因素和非线性关系等.这时,可以使用SVM来进一步筛选窥孔LSTM输出的预测结果.在故障预测的整个研究过程中,关于分类器的选择是重要组成部分.因此,本节将介绍本文使用的支持向量机(SVM)分类器的原理.
SVM是一种基于最大间隔原理的分类器,它可以将不同类别的数据分隔开,并对新的数据进行分类.分类模型从训练数据集中得出一些有效的映射函数,并在映射函数的帮助下预测新数据条目的类标签.属性或特征是在给定问题集中找到的一个参数,可以充分帮助构建准确的预测模型.跳闸故障预测任务被本文分解为二分类任务,而机器学习中的SVM在概念上契合本文目标任务,因此本文选择SVM作为分类器算法.SVM是一种用于分类和回归分析的监督学习模型,其基本原理是寻找距离最近训练样本最远的最优正负超平面,正负超平面之间的垂直距离称为空间余量,其值等于上述两个距离的总和.如果空间余量最大化,则决策超平面是最佳的.对于二维平面中的线性分离,分类函数可以呈现如下:
f(x)=wTx+b,
(4)
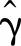
(5)

(6)
其中,yi=1或-1是样本标签,n是样本数量.针对数据线性不可分的情况,SVM设定铰链损失函数如下:
max(0,1-yi(wTx+b)).
(7)
因此,最后的损失函数可以呈现为
max(0,1-yi(wTx+b))+λ‖w‖2.
(8)
由于SVM分类器的优化策略是寻求不同类别间的最大间隔,因此损失函数为最大化损失函数.对于如何解决线性不可分割性的问题,SVM可以使用核技巧和非线性映射算法来将低维输入空间转换为高维特征空间,使得它们线性可分离.
一般来说,SVM是一种具有坚实理论基础的新型学习方法,与普通分类器相比,它具有良好的鲁棒性,样本较少,在非线性问题中具有泛化性能.原因是SVM的优化目标是结构风险最小化,而不是经验风险最小化.SVM不仅确保了样本的分类精度,而且减少了学习模型的维数.简而言之,它有助于防止过拟合问题.此外,计算复杂性取决于支持向量的数量而不是样本空间的维数,这在某种意义上避免了维数灾难.
通过将LSTM和SVM结合起来,可以提高跳闸故障的诊断准确率.LSTM可以从复杂的时间序列数据中提取特征,并进行预测;SVM可以根据这些特征对预测结果进行分类,并且能够处理高维数据,从而提高分类精度.
3 基于窥孔LSTM 和 SVM的故障预测方法
本节将详细阐述基于窥孔LSTM和SVM的电力系统线路跳闸故障预测方法.首先描述数据集的来源和特点;然后针对过拟合问题提出解决方法;最后阐述线路跳闸故障预测的建模方法.
3.1 数据集简介
真实的历史数据来自电气测量数据、设备台账、设备健康记录、天气和拓扑结构历史信息.这些数据由国家电网的供电管理部门提供(数据可向本文通信作者获取).由于在配电线路电阻的渐变过程中,用户的电流、电压、有功功率、无功功率等电气量与故障密切相关,因此,本文着重研究故障与电气量之间的相关性.本文选择的输入包含电流、电压和有功功率,去除了无功功率和相位角等冗余变量,采样了500个数据样本点(采样周期为15 min).电流的正常样本和故障样本如图3所示,它们之间的区别不能简单地从数字上来确定.电压和有功功率在表现故障情况下是类似的,因此需要通过LSTM网络挖掘隐藏的特征来进行故障预测.采样样本是具有时间信息的时间序列数据,将其转换为不同维度的时间序列LSTM网络输入,将在仿真实验中具体讨论.
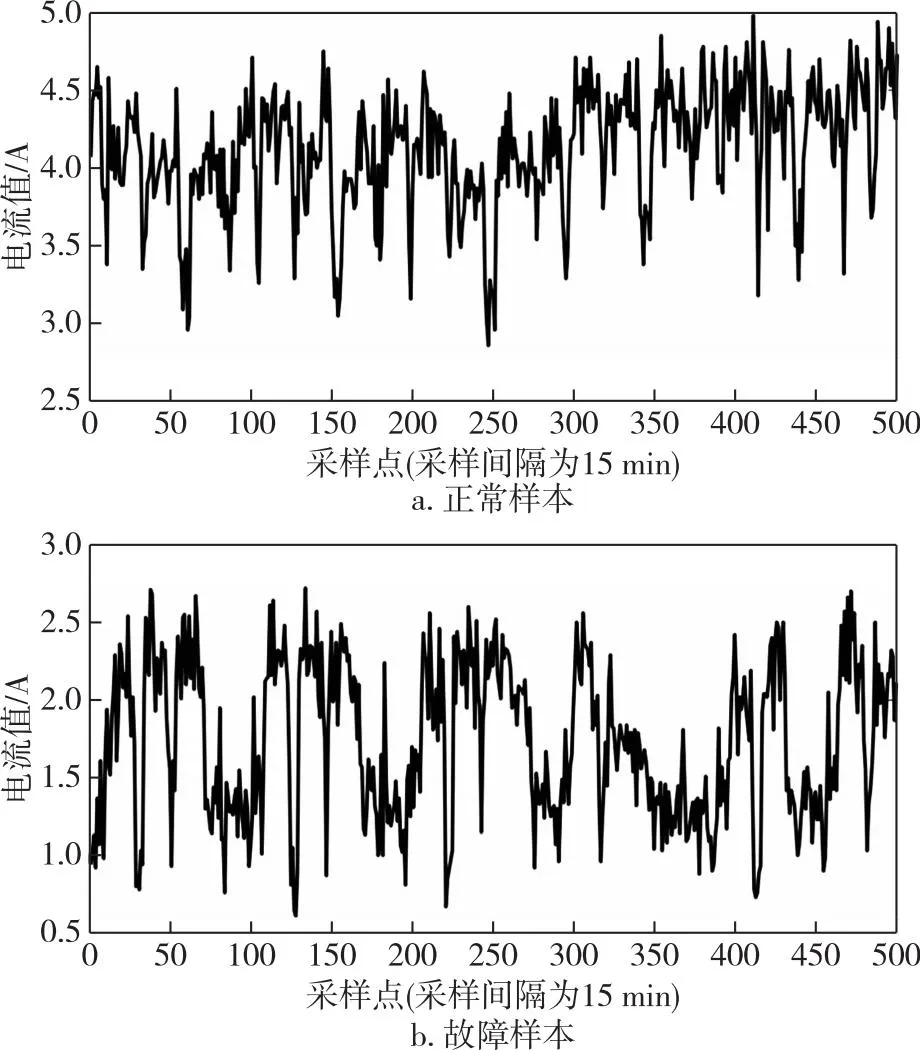
图3 某地变电站正常与异常情况下500个采样点电流值样本曲线Fig.3 Current value sample curves of 500 sampling points under normal or abnormal conditions in a substation,including (a) normal samples and (b) fault samples
3.2 数据预处理过程
数据预处理是数据挖掘任务的一项基础性工作.
由于不同类型的数据具有不同的维度,为了减少数量级和量纲不同的影响,提高模型的收敛速度,需要对供电局提供的数据进行标准化预处理,处理公式如下:
(9)
式中:x为原始数据;yp是处理后的结果;ymax和ymin分别是处理后结果的最大值和最小值;xmax和xmin分别是未处理数据的最大值和最小值.在本文的仿真实验中,ymax和ymin分别被设置为1和0,这样处理后的数据可以被约束在[0,1]区间内,这是一个非负数.预处理后,在不改变数据内部变化的情况下,将数据变换到同一层次.
3.3 过拟合问题
由于样本在变量复杂度上相较于图像问题更为简单,过拟合是故障预测中的关键问题.在电力系统稳定运行过程中,故障很少发生,故障样本数量较少.因此,训练很容易陷入过拟合问题.在网络训练过程中,当迭代次数增加时,网络对训练集的拟合可能较好,在训练集中损失较小,但对验证集的拟合较差.Dropout和批量归一化是解决此类过拟合问题的有效方法.本节对过拟合问题的解决方案进行讨论.
1)Dropout
基本的Dropout方法是在网络正向传播过程中,神经元会存在P的概率停止工作,如图4所示.

图4 单层Dropout的示意图(P是神经元出现Dropout的概率)Fig.4 Schematic of single-layer Dropout(P is the probability of neurons experiencing Dropout)
Dropout随机令神经元不起作用,可以有效避免在某些固定组合中性能更好的情况.与此同时,网络可以学习一些共同的知识以获得更好的泛化性能.此外,对存在Dropout的网络进行训练可以看作是训练多个子网络,输出是所有子网络的平均值.每次迭代得到的子网络基本不重复.因此,它可以避免训练网络过度拟合训练集,并加快收敛速度.
2)批归一化
批归一化是指在每个批次的训练过程中,将中间层的权重数据进行归一化.归一化层输出的均值和标准差分别为0和1.批归一化的本质是研究数据的分布特征.一旦训练集的分布与测试集的分布不同,网络的泛化能力就会大大降低.此外,如果每批训练数据的分布不同,网络必须学会适应每次迭代的不同分布,这将降低训练网络的速度和网络的性能.因此,使用批归一化可以提高泛化性能,加快收敛速度.
3.4 故障预测建模
线路跳闸故障预测主要任务是检测电力系统运行过程中是否发生故障.本文提出模型的总体结构如图5所示.根据故障记录,将样本标记为正常或故障.在线路跳闸故障前或正常运行期间,采样500个节点的电流、电压和有功功率;然后,将3×500维向量转化为窥孔LSTM网络的多个带有时间步的输入向量,先经过神经网络层(NN)完成一次特征嵌入,目的是对输入特征的稀疏向量进行压缩;接着,通过3个窥孔LSTM网络捕获时间特征,在获得输出单元的最后一个进行串联,以便在融合层中进行合并.为了保留关于每个测量的信息,融合的形式被设置为串联.在3个窥孔LSTM神经网络之后增加Dropout层和批归一化层.模型的结构和参数根据多次试验设计和调整,以获得满意的结果,这将在下节显示.此外,如果电力系统中记录的故障有其他类型的关联数据,则可以使用本文所提出的窥孔LSTM扩展子网络,利用更多的信息进行故障预测.
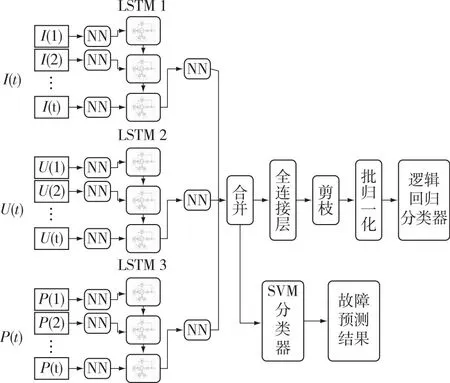
图5 基于数据的线路跳闸故障预测模型示意Fig.5 Schematic of a data-based line tripping fault prediction model
4 仿真结果
本节讨论仿真条件和实际实验结果,验证所提方法的性能.
4.1 实验条件与评估方法
采用南方电网某变电站的数据,硬件方面使用两张3070Ti作为训练GPU.在Pytorch环境下训练40轮;使用Sigmoid函数而非深度学习常用的Relu函数作为激活函数,因为经过实验发现,当网络较浅时无需担心网络过深而导致的梯度消失问题,而Sigmoid函数的非线性拟合能力要强于Relu;使用目前最热门的Adam算法作为优化函数,设置初始学习率为0.002,并为其设置每隔10代0.9的学习率衰减;使用预测值和真实值的准确率(Accuracy)作为比较指标.
除此之外,在评估训练完成的网络的性能时,测试是很重要的一步.K折交叉验证(K-CV )是评估训练完成的网络的经典方法.在K折交叉验证中,原始样本被随机平均划分为K个子样本.每个子样本为测试集,其余K-1个子样本为训练集.用子样本重复实验K次.K个模型的平均性能被认为是最终性能.这种方法的优点是,所有的观察都用于训练和测试,从而避免过拟合和欠拟合,以获得有说服力的结果.
一般来说,K是5.本文模拟的训练样本和测试样本数量如表1所示.故障诊断的性能可以通过正确诊断样本与所有测试样本的比值即准确率来观察.如果在多个epoch中精度没有提高,则停止训练.最佳精度的epoch作为实验结果.重复实验的平均准确率记为最终结果.

表1 模拟实验样本
4.2 基于窥孔LSTM网络的故障预测
本节讨论基于窥孔LSTM网络的故障预测实验,其模型如图5所示,去掉了SVM.通过多次实验,窥孔LSTM网络的参数设置如表2所示,为了获得更好的性能,在实际情况中应该进行调整.epoch数设置为40,因为根据反复实验,精度在epoch达到40后趋于稳定.选择“RMSprop算法”优化器是因为它在递归神经网络中具有更好的性能.基于5-CV,窥孔LSTM融合网络的故障预测结果如图6所示.最终结果是5个训练好的模型的平均准确率为87.44%.一个训练周期内故障预测的损失和准确率分别如图7和图8所示.准确率随着训练增加而增加,而损失则减少.反复实验可以保证网络的稳定性.结果表明,窥孔LSTM网络可以挖掘线路跳闸故障与量测数据之间的时序信息.
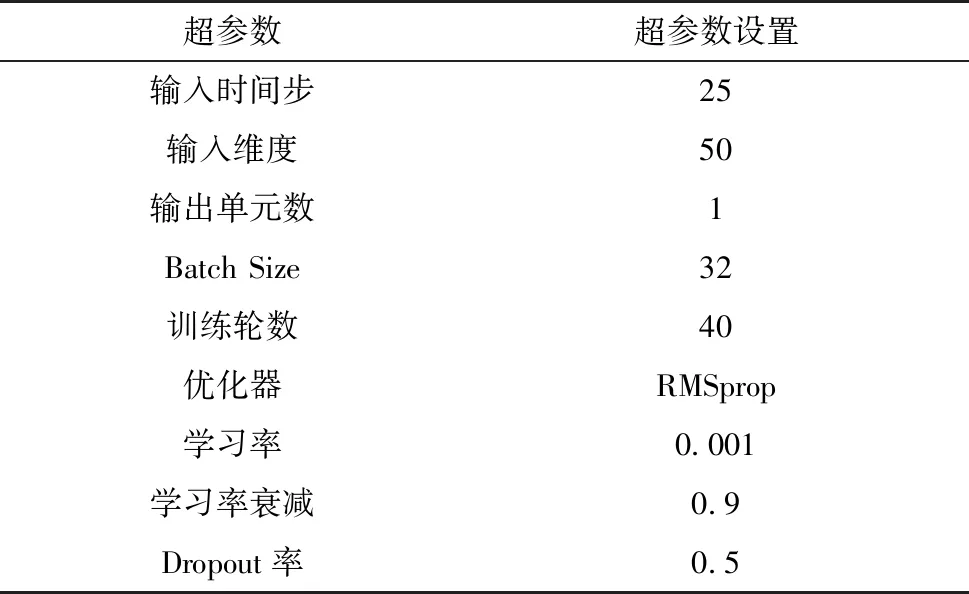
表2 实验设置的超参数

图6 基于5-CV的窥孔LSTM融合网络的故障预测准确率Fig.6 Fault prediction accuracies of peephole LSTM fusion network based on 5-CV
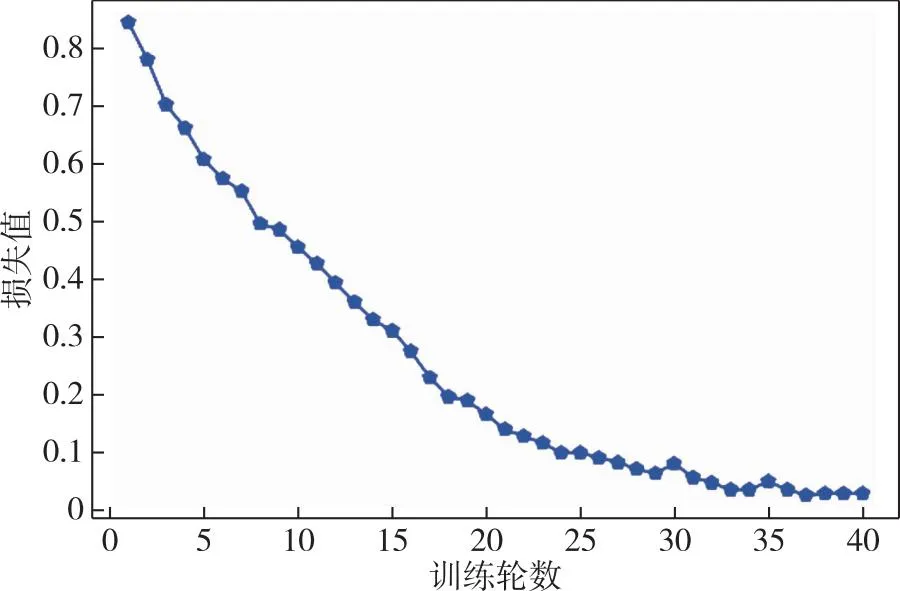
图7 通过40个epoch训练得到故障预测中的损失Fig.7 Loss in fault prediction obtained from 40 epoch trainings
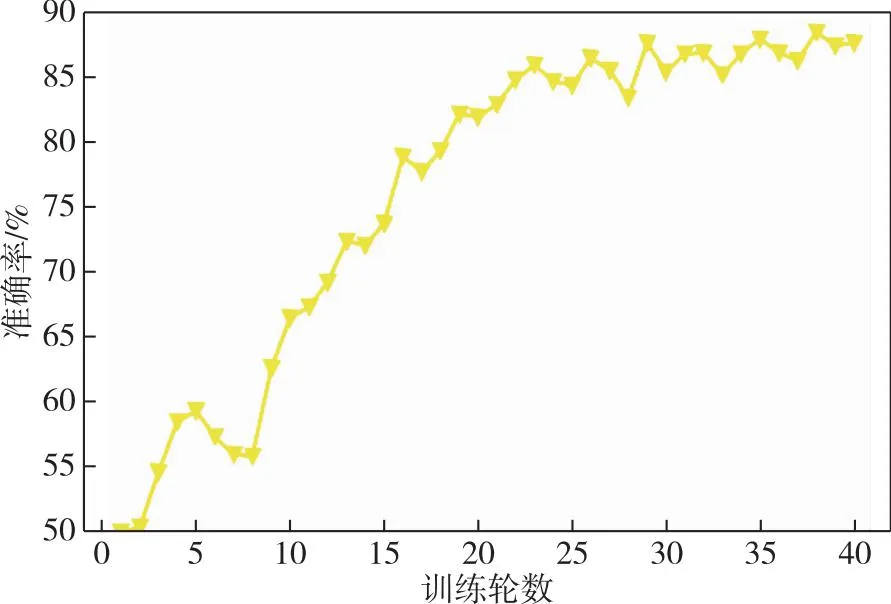
图8 通过40个epoch训练得到故障预测的准确率Fig.8 Accuracy of fault prediction obtained from 40 epoch trainings
4.3 针对故障预测的模型性能改进方法
由于窥孔LSTM网络需要提取时间特征,因此输入时间步长和维度是重要的影响因素.几种代表性输入时间步长和维度的实验结果如图9所示,其中,T为时间步长,D为输入向量的维度.当输入时间步长达到50以上时,收敛速度太慢,对显示结果没有意义.可以得出结论,T=25、D=20的输入维度更好.原因如下:如果时间步长较长,则不可避免地会在漫长的过程中丢失已学习的特性;如果时间步长较短,输入向量的维数较高,则会丢失时间信息.因此,输入时间步长和维度设置为T=25、D=20是合适的.过拟合是基于数据的故障预测中的一个难题.网络中引入了Dropout层和批归一化层以避免过拟合.使用表2中设置的参数进行实验,以证明过拟合得到有效缓解.使用Dropout和批量归一化的改进结果如图10所示.通过逐层的Dropout和批归一化,性能得到了明显的提升.由于网络需要训练的层数和参数较多,在训练初期收敛速度较低且不稳定,但在后半部分,精度有所提高.一般来说,带有Dropout和批归一化的网络表现更好,并且具有更快的收敛速度.

图9 不同输入时间步长和维度的对比结果Fig.9 Comparison of different input time steps and dimensions
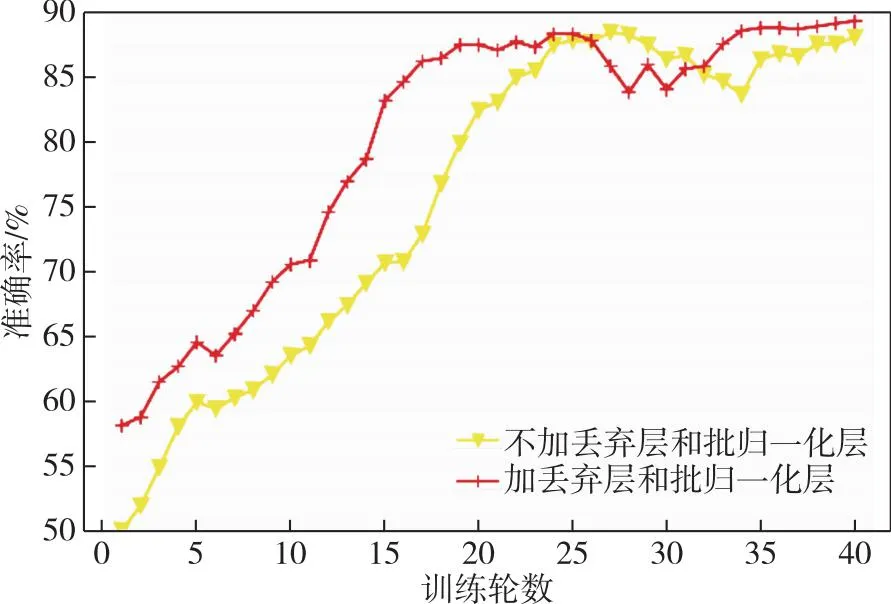
图10 使用Dropout和批归一化改进训练的准确率Fig.10 Accuracy curve for trainings improved by Dropout and batch normalization
电力系统运行过程中存在着大量的量测数据.时间特征从用户的电流、电压和有功功率数据中捕获.针对多源输入和单输入进行了对比实验,结果如图11所示,从图11可以清楚地得出改进的结论.它可以解释如下:当故障即将发生时,电力设备的逐步状态转换反映在包括电流、电压和有功功率在内的所有测量数据中,更清晰的特征被挖掘出来,信息也更充分.因此,多LSTM网络表现出更好的性能.在使用窥孔LSTM网络和SVM进行基于数据的故障预测的类似实验中,这种改进被证明是有效的.窥孔LSTM网络的性能更好,可以更好地捕获特征,从而更有利于使用SVM分类器进行分类.基于改进影响因子的窥孔LSTM网络在10次重复实验中的准确率在85.1%~89.7%之间,平均准确率为87.5%.这是可以接受的,但仍需改进.

图11 多源信息和单个输入在训练过程中的准确率Fig.11 Accuracy curves of multisource information and single input during training process
4.4 改进方法在故障预测上的效果
为了提高故障预测的准确性,提出基于窥孔LSTM网络和SVM的数据型线路跳闸故障预测方法.将训练好的融合时序特征放入SVM分类器进行故障预测,模型结构如图5所示.在10次重复实验中的准确率在97.5%~97.8%之间,平均准确率为97.7%,与仅基于窥孔LSTM网络的方法相比提高了约10 个百分点.这种改进依赖于SVM,它对样本具有良好的鲁棒性,对非线性问题具有良好的泛化性能.SVM基本不涉及大数的概率测度和规律,其优化目标是结构风险最小化,缓解了过拟合问题.它既能保证样本的分类精度,又能降低学习模型的维数.这些优点使其适用于电力系统中基于数据的故障预测.
实验采用表1相同的样本数据应用于其他数据挖掘方法.本文所提方法与基于数据的挖掘方法的对比结果如图12所示,其中涉及正常和故障测试集的准确率.可以看出,在正常和故障情况下都有明显的改善.
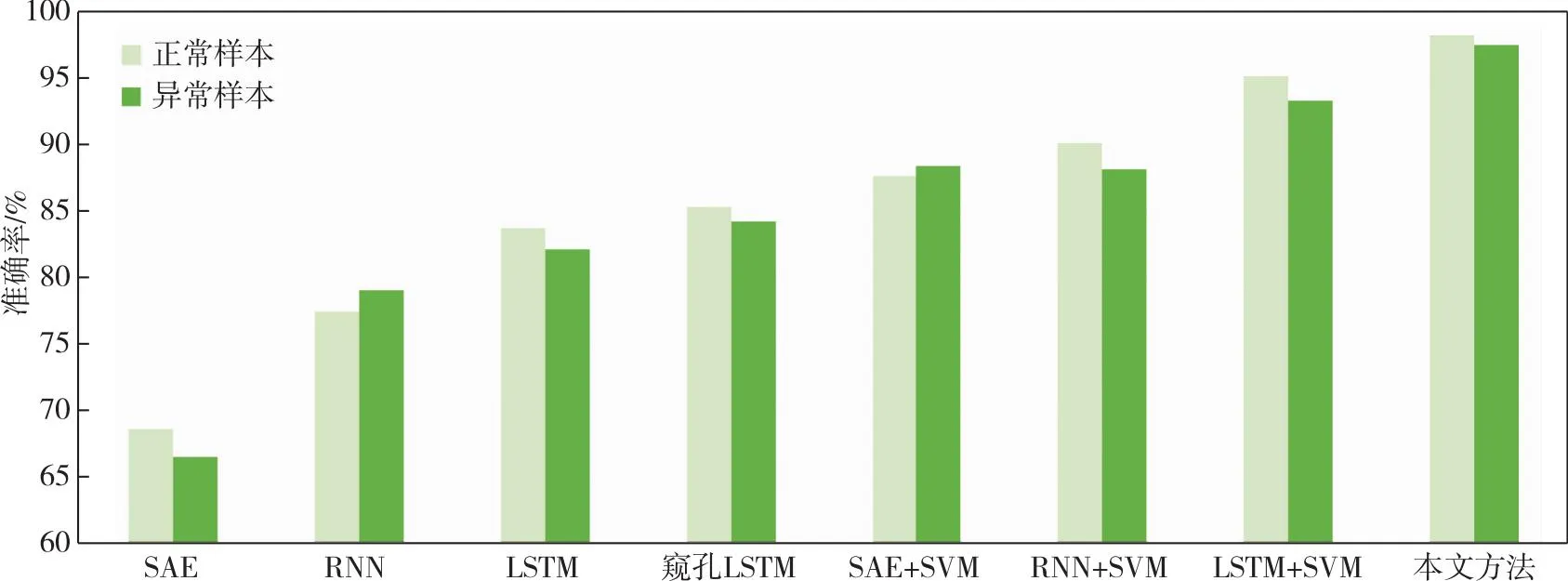
图12 以基于数据的线路跳闸故障预测为例,本文模型与基于数据的挖掘模型的准确率对比Fig.12 Comparison of accuracy between the proposed model and data-based mining models in line trip fault prediction
最终结果如表3所示,可以看出,本文所提出的方法比其他方法,如堆叠自编码器(SAE)、RNN,以及传统的LSTM性能更好.

表3 本文模型与基于数据的挖掘模型的准确率对比
一般而言,LSTM网络在长时序场景下具备比RNN更优秀的上下文语义挖掘能力,而考虑到电力系统故障发生时的负荷变化具有较强的时序逻辑关系,LSTM中引入窥孔的三级栅极链接使得模型在挖掘故障发生时的特征变化更具灵敏度.此外,由于电力系统的特征量较少,神经网络的深度和复杂度也相对较低,可以使用较为复杂的窥孔LSTM取代传统LSTM,牺牲部分时间复杂度以换取更高精度的故障诊断.由于SVM在分类任务中良好的鲁棒性和泛化性能,在主干网络外层包装一层SVM更符合故障诊断的需求,极大地提高了实验的准确率.它可以从多源测量数据中挖掘故障特征,实现高精度的故障预测.与基于继电保护动作和电气元件动作的方法相比,本文提出的基于数据的方法可以根据第一手信息预测电力系统是否会发生故障.因此,本文提出的基于窥孔LSTM网络和SVM的电力系统线路跳闸故障预测方法,对于提高电力系统的可靠性和稳定性具有积极意义.
4.5 具体实践应用
本文方法在上节的重复数据实验中被证明是有效的.当所提出的网络根据实际情况建立并使用历史数据进行训练时,它可以在线进行故障预测.参数不断更新,以适应新的在线运行状态.在实际应用场合中,LSTM网络根据2019—2021年的历史数据进行了训练,并使用2022年上半年国网某变电站的实际故障记录进行测试.各月准确率稳定在95%以上.研究结果在实际故障预测中具有重要意义.实验的训练和测试时间在英伟达3090GPU上表现为分钟级别,即单机仅需几分钟即可训练出一个故障诊断的模型,几秒钟即可完成故障诊断.用所提出的方法可以实现实际的故障预测.
5 结论
为了提高电力系统运行的可靠性和稳定性,本文提出了一种基于数据驱动并以SVM和LSTM作为主干网络的线路跳闸故障预测方法.首先,在线路跳闸故障前或正常运行期间,记录了500个电流、电压和有功功率采样点.样本被重塑为时间步长25、输入向量20的维度,作为LSTM网络的输入.同时,对样品进行0~1标准化处理至同一水平,将多源数据放入LSTM网络中进行训练和融合,并通过3个LSTM网络挖掘时间特征.为了解决电力系统故障预测的过拟合问题,在网络中加入Dropout层和批归一化层,将融合后的特征输入SVM分类器,得到更准确的预测结果.
此外,所提出的网络可以扩展LSTM子网络,以获得更多的信息,用于电力系统的故障预测.相应的实验结果证明了使用多个源的融合,以及逐层的Dropout和批归一化可以提高准确率,线路跳闸故障预测准确率可达97%左右.最后,对所提出的方法进行了实例应用,效果显著.
