复杂环境下小尺度烟火目标检测研究
2023-12-16温秀兰焦良葆李子康姚波唐国寅
温秀兰 焦良葆 李子康 姚波 唐国寅
烟火检测;改进YOLOv5;DIoU_Loss;优化加速
0 引言
火灾是威胁公共安全、危害人民生命财产的一种多发性灾害,能否快速有效地发现火情并及时预警,对维护日常生活生产秩序具有重大意义[1].在烟火的实际检测中,由于起火点目标小,火点颜色易与车灯、路灯等颜色背景相近的目标混淆,极易误检,并且易受外部光线变化的影响,使得复杂环境下烟火检测难度大大增加[2].目前市面上大多采用传感器进行烟火检测[3],这种检测方法存在设备昂贵、检测范围相对较窄、延时和误报等问题.为解决传感器检测存在的弊端,有学者提出基于传统图像处理的方法[4],主要是对烟火中易于辨识的颜色和边缘特征进行识别和检测,在一定程度上解决了不同光线下的干扰,但对于一些复杂环境背景中产生的烟火依然会受到较大的干扰,鲁棒性不强,不利于对火灾的实时检测.
随着深度学习的兴起,深度网络模型在视觉领域取得了突出进展,将深度网络模型应用于烟火检测成为近年来的研究热点[5-9].在烟火的实际场景中进行检测时,烟火目标易受光照条件干扰,火焰的颜色特征易与一些环境背景颜色混淆,而要做到及时有效的火情预警,就必须在刚起火时检测出起火点,但这种小尺度的起火点检测难度极大,传统的基于图像处理的目标检测算法无法解决上述难点.基于深度学习的目标检测算法具有强大的特征提取能力,在室外远程拍摄和航空遥感场景中的小目标检测得到较成功应用[10-11].
针对复杂环境下小尺度烟火目标检测难题,本文选择YOLOv5网络模型作为烟火目标检测与识别的基准网络,通过目标检测层设计、网络结构改进、目标框损失函数的选择等多种措施以解决小尺度烟火检测效率及准确率低等问题.
1 改进的YOLOv5模型
1.1 目标检测层的改进设计
在烟火检测任务中,要做到及时有效的火情预警,必须在刚起火时将起火点检测出来,然而现有的公开数据集都是以森林火灾为主,缺少小尺度的火焰数据,并且实际场景中的起火图像数据也很难收集.因此,本文首先采用一种复制增强的方法[12-14]人为构造场景数据,并对YOLOv5网络模型的预测端进行重新设计,以提高模型对小目标的检测精度.
原始的YOLOv5模型中,只有3个检测层,对应3组初始化的锚框值.为了更好地检测小目标物体,在原始模型的3个检测层上增加第4个检测层.因此需要多增加一层锚框(第4组锚框)参数,增加后的锚框参数如表1所示.
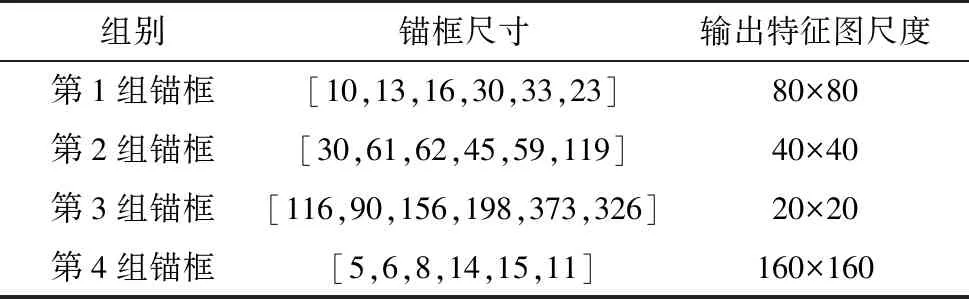
表1 锚框参数
当输入的图像尺寸为640×640时,网络的第1个输出层输出的特征图尺寸为(80×80),用以检测(8×8)以上的目标;网络的第2个输出层输出的特征图尺寸为(40×40),用以检测(16×16)以上的目标;网络的第3个输出层,输出的特征图尺寸为(20×20),用以检测(32×32)以上的目标.在增加了一个检测层之后,输出第4个尺度的特征图为(160×160),理论上可以检测到最小的目标为(4×4),提高了对小目标的检测精度.
1.2 改进的YOLOv5网络结构
针对烟火检测任务中起火点目标小、易与环境背景相混淆,且存在光照变化、目标遮挡和目标尺度变化等问题,本文对YOLOv5的网络结构进行了改进,改进后YOLOv5(Improved-YOLOv5)网络结构如图1所示.骨干网络由1组Focus单元、4组CBL单元和3组C3T_X组成.C3T_X就是经典的CSP结构,由多个残差组件和卷积层张量拼接组成,其中,X代表的是使用残差组件的个数,这种C3结构是整个网络中特征提取的重要环节,它不仅增强了CNN的学习能力,还极大地降低了计算瓶颈和计算的成本,使得在轻量化的同时保持较高的准确性.在Neck端采用FPN+PAN的结构,该结构不仅加强了语义信息的传递,同时还加强了特征信息的定位,因采用了C3结构,进一步加强了网络特征融合的能力.因此,改进后的网络继续对第3层输出的(80×80)的特征图进行上采样等处理,得到尺寸为(160×160)的特征图,将此特征图与骨干网络中的第1层输出的特征图进行融合操作,进行特征信息的补偿,从而提高对小目标的检测精度.
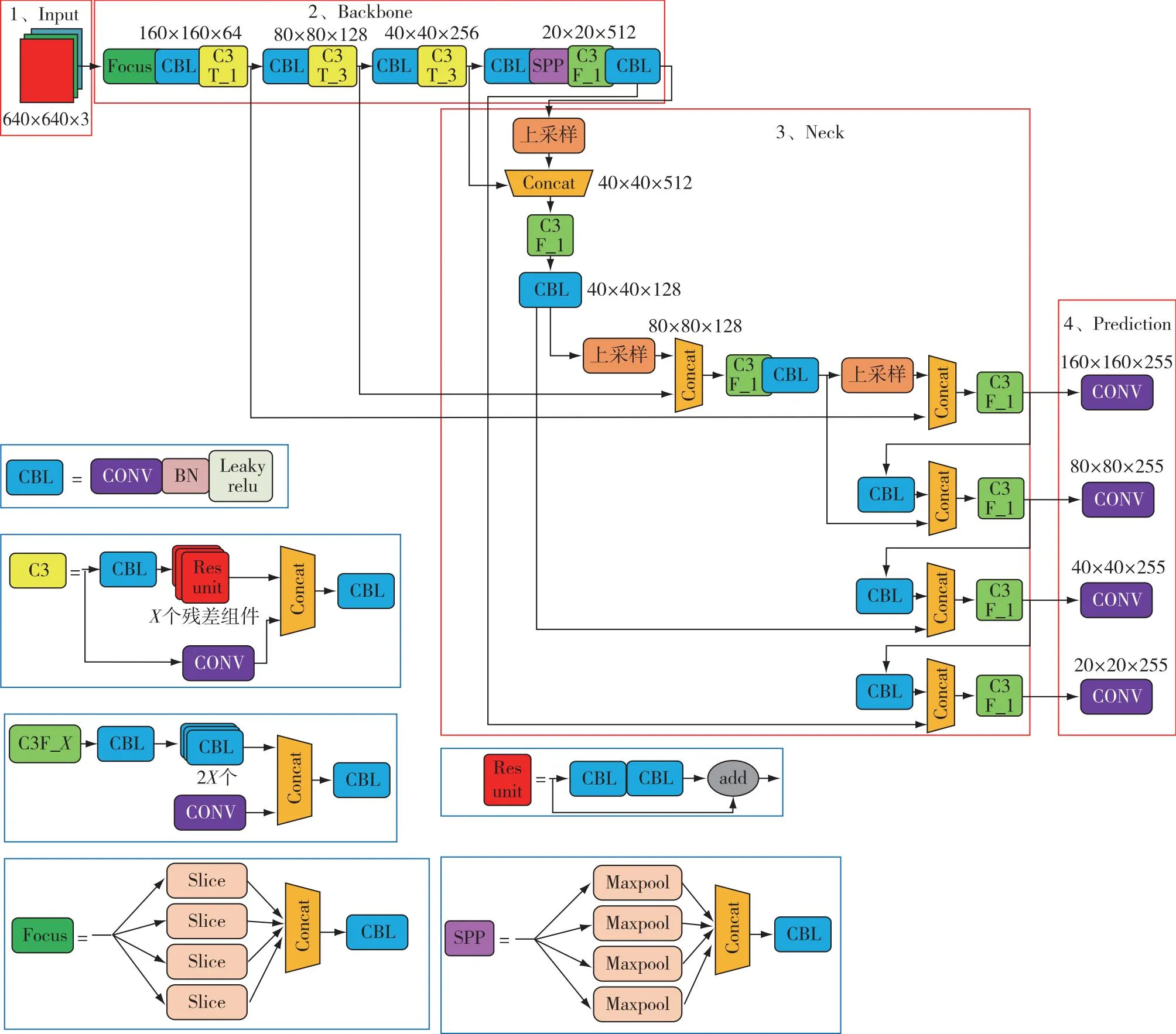
图1 改进后的网络结构Fig.1 Improved network structure
1.3 目标框损失函数的选择
模型的好坏通常采用损失函数来衡量,目标框损失函数用来评价模型的预测框与目标框之间的不一致程度.常见的损失函数有IoU_Loss,定义为
(1)
式(1)中,A,B分别代表预测框与目标框之间的交集与并集.
YOLOv5原网络中用GIoU_Loss计算目标框损失函数:
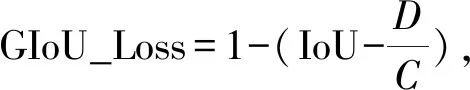
(2)
式(2)中,C为预测框与目标框的最小外接矩形,D为C与B之差.尽管GIoU_Loss解决了IoU_Loss存在的弊端,但当预测框小于目标框,位于目标框内多个不同位置时,因目标框与预测框差集相同,使得GIoU_Loss的值相同,无法区分相对应的位置关系.
因此,本文选择DIoU_Loss作为目标框损失函数:
(3)
式(3)中,R1代表最小外接矩形C的对角线距离,R2代表目标框与预测框2个中心点之间的欧式距离.DIoU_Loss同时考虑了重叠面积和中心点的距离,因此,当目标框处于预测框内部时,通过直接度量2个框的距离,不仅使得模型训练时网络收敛快,而且当目标在被遮挡的场景中也可以将预测框快速回归出来.
2 实验及结果分析
2.1 实验数据集
数据集的丰富与否极大地影响着深度学习模型的训练效果.目前网络上还没有公开的火灾数据集,能用于研究的烟火数据图像更是匮乏,因此,通过视频抽帧、Baidu、Github以及数据复制增强等方法,建立自制的烟火数据集FDD,并用于烟火目标的检测与识别.该自制数据集包含不同场景下的烟火图像共10 668张,FDD的部分图像样本如图2所示.

图2 FDD数据集部分图像样本示例Fig.2 Example of some image samples from the FDD dataset
2.2 评价指标
在目标检测领域常用准确率(Precision)和召回率(Recall)来评价一个算法的优劣.为了更好地评价模型的准确性[15-17],通常在评价算法性能优劣时还会引入平均准确率(Average Precision,AP)和平均准确率均值(Mean Average Precision,mAP)2个指标[18].本文将采用Precision、Recall、AP和mAP作为模型的训练评估指标,并且利用每秒帧数(Frame Per Second,FPS)来衡量模型的检测速度.
由于原网络YOLOv5在COCO数据集上训练好的权重yolov5m.pt已经具备良好的特征信息的提取能力,利于做迁移学习,所以将该训练权重文件用于Improved-YOLOv5训练.训练的数据集采用自制的FDD数据集.对训练好的模型进行参数的微调,训练完成后烟雾和火焰的准确率结果如图3所示.在置信度为0.6的情况下,火焰的准确率为91.4%,烟雾的准确率为89.1%.
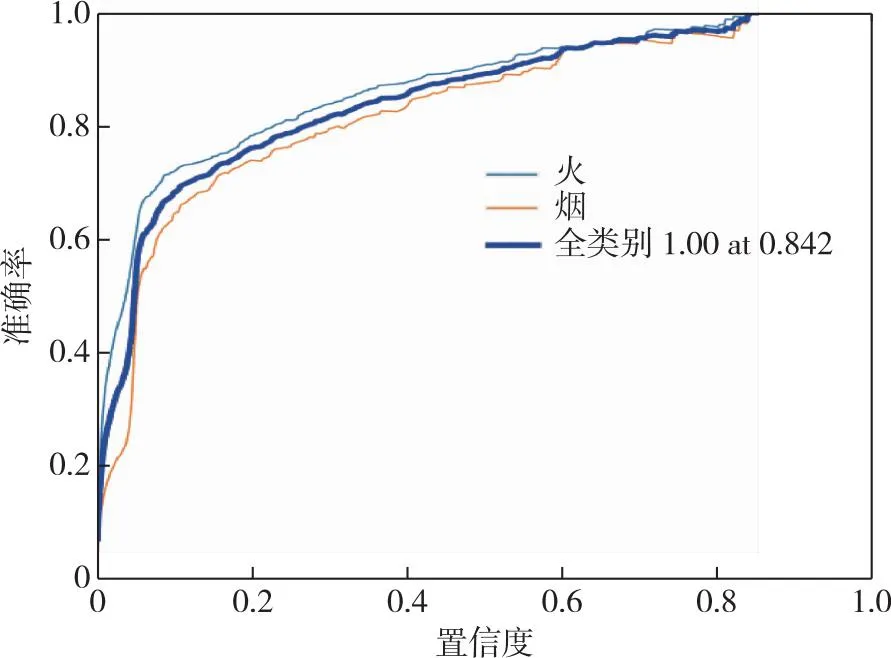
图3 准确率Fig.3 Precision
为了更好地评价模型的准确性,在评价算法性能优劣时还会引入mAP指标.mAP@0.5是指IoU为0.5时烟雾和火焰2个类别的平均AP.召回率和准确率的计算结果如图4所示,火焰的AP为94%,烟雾的AP为87.6%,mAP可根据曲线下方的面积大小来计算.

图4 平均准确率均值Fig.4 Mean average precision
2.3 与已有算法的对比实验
在网络模型训练过程中,可以通过Loss曲线观察网络训练的状态.为了验证替换后预测框损失函数DIoU_Loss是否可以提高网络的收敛速度,在同一个数据集上分别对改进前后损失函数的网络进行200个epoch数量的训练,其Loss曲线如图5a所示,红色曲线和蓝色曲线分别表示原YOLOv5网络损失曲线和替换损失函数后的网络曲线,而绿色曲线代表使用经典的YOLOv4算法在该数据集下的训练情况.由图5a可见,因DIoU_Loss考虑了目标框的中心点能够更快地将目标回归出来,模型的收敛速度也快于原网络,说明将GIoU_Loss替换成DIoU_Loss后提高了网络的收敛能力,损失函数值明显小于原YOLOv5和YOLOv4算法结果,表明改进后的网络模型训练结果更佳,可以作为一个合适的网络模型进行后续的实际部署.
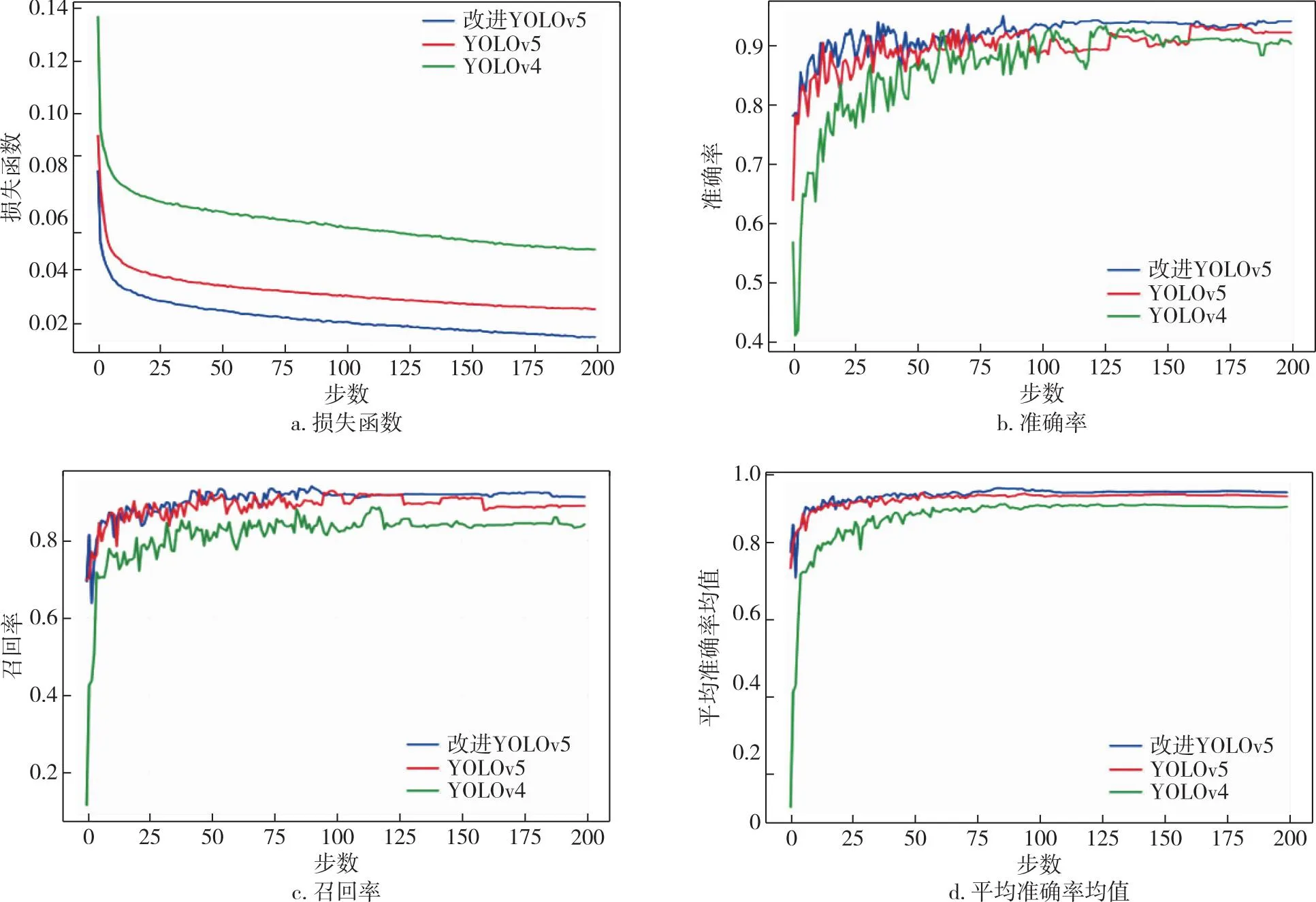
图5 不同算法评价指标变化曲线对比Fig.5 Comparison chart of evalution index changs curves of different algorithms
同时从准确率(Precision)、召回率(Recall)及mAP指标对改进前后网络整体的性能进行评价,结果如图5b—d所示.可见:相比于原YOLOv5网络,改进后的网络模型平均准确率均值mAP从83.5%上升到90.8%,提升了7.3个百分点,但由于增加了检测层导致推理速度从60.32 FPS下降到58.94 FPS;与YOLOv4相比,改进后YOLOv5网络的mAP提升了14.6个百分点.
改进前后网络模型在自制的视频序列上烟火目标检测的定性对比实验结果如图6a—f所示.
对比图6a和6b可以发现,原YOLOv5对于存在遮挡的目标图像检测存在漏检现象,而改进后的YOLOv5在目标被部分遮挡的情况下依然可以精准地检测出目标,说明改进后的YOLOv5在替换损失函数后,可以保持对图像特征提取的能力.对比图6c和6d,原YOLOv5对于小目标的检测效果较差,不能够将30×30像素点以下的小目标检测出来,而改进后的YOLOv5依旧能很好地检测出小尺寸的着火点,说明改进后的YOLOv5在增加检测层之后,网络对图像特征信息的提取能力进一步加强,使得漏检问题得到有效的改善.对比图6e和6f,原YOLOv5在特征信息相似的物体上存在误检的情况,而改进后的YOLOv5有效避免了误检,说明复制粘贴的数据增强方式利于网络对特征的提取和分析,减少误检率,提高了模型的泛化能力[19-20].
3 模型加速及实时检测
为了满足实际场景中的烟火检测需求,需要对训练好的模型进行优化加速后部署到嵌入式设备中.TensorRT是一个高性能的深度学习推断的优化器和运行的引擎,其核心是一个C++库,可以促进对NVIDIA图形处理单元(GPU)的高性能推理,旨在与TensorFlow、Pytorch、MXNet等训练框架以互补的方式工作[20].
3.1 TensorRT的推理实验
由于RTX 3080服务器目前还不支持FP16的低精度推理,因此,在Pytorch框架和TensorRT框架下对改进的YOLOv5模型和YOLOv5基准模型进行FP32的高精度推理对比实验,其对比结果如表2所示.

表2 不同框架下的推理速度对比
如表2所示,在输入尺寸相同的情况下,同一种模型在不同的框架下的推理时间有所差异,TensorRT框架下的推理速度高于Pytorch框架下的推理速度.虽然TensorRT采用了算子融合的优化方式,一些网络结构层进行了合并,减少了大量的参数,模型的推理速度也有所提升,但在推理时依旧采用FP32高精度推理方式,导致TensorRT的推理性能没有完全释放[21].
而Jetson TX2平台既支持FP32的高精度推理也支持FP16的低精度推理,因此,在Jetson TX2上进行TensorRT加速推理实验时,分别采用FP16的低精度和FP32的高精度对改进的YOLOv5模型进行推理对比试验,结果如表3所示.

表3 TensorRT框架下FP16和FP32的推理速度对比
如表3所示:当输入图片尺寸为(416×416)时,改进的YOLOv5模型在FP16下的推理速度为58 FPS,相比于FP32高精度推理提升了47.7%;当输入图片尺寸为(640×640)时,改进的YOLOv5模型在FP16下的推理速度为28 FPS,相比于FP32高精度推理提升了33.3%.可以发现,虽然RTX 3080服务器的算力远强于Jetson TX2,但是当网络的输入尺寸为416×416时,在Jetson TX2开发板上执行FP16低精度的TensorRT加速推理时,其推理速度和RTX 3080服务器上执行FP32高精度的推理速度相当,这主要得益于TensorRT中的算子融合以及FP16低精度转化.因此,改进后的YOLOv5模型在Jetson TX2开发板上能够保持较高的推理速度,满足实时性的要求.
3.2 实际场景测试
将改进后的YOLOv5模型部署到Jetson TX2开发板上,同时进行TensorRT的加速推理,然后选择自制的一段烟火视频作为测试的视频序列,测试时常约为20 min,最终的测试结果如图7所示.

图7 自制视频序列测试结果Fig.7 Test results on self-made video sequence
图7中3张结果图均为测试视频序列中的随机截取,图中左上角显示的是进行TensorRT加速推理时的实时FPS.可以发现,在输入图像尺寸为416×416时,在Jetson TX2开发板上进行TensorRT加速推理的烟火目标检测方法能够满足实时性的要求,其平均的帧率可以达到60 FPS.通过自制的烟火视频序列的测试实验,验证了本文所提方法的有效性.
4 结论
针对小尺度烟火目标检测效率及准确率低的问题,提出一种改进的YOLOv5烟火检测方法.首先在YOLOv5原始的3个检测层上增加第4个检测层,加强对小尺寸目标的检测;然后将原网络中用于计算目标框损失函数的GIOU_Loss改成DIOU_Loss,使得目标在被遮挡的场景中也可以快速回归出预测框.对于实际场景数据少、误检率高的情况,采用一种复制粘贴的数据增强方式,在丰富场景数据的同时,大大减少了误检率,从而得到更适用于烟火检测的模型.最后对改进后的模型进行优化加速部署,通过对实际场景进行测试,结果表明改进后的YOLOv5模型不仅具有较高的准确率而且能够满足实时性要求,易于在实际场景中推广应用.
