基于组合注意力模型EAAT的云KPI数据预测方法
2023-12-16丁建立龚子恒
丁建立 龚子恒
云KPI数据;时序预测方法;经验小波变换;组合注意力模型;双向长短时记忆网络
0 引言
近十年来,基于预测和变换的时间序列的机器学习方法引起了科学界和工业界的广泛关注,其中广受关注的时间序列应用之一是云计算集群的KPI(Key Performance Indicator,KPI)指标的预测.云集群的KPI指标指云计算集群中一些关键的监控指标[1],比如承担云计算集群主要计算功能和业务供给的服务器、集群的CPU和内存资源,本质上属于时间序列数据.随着数据中心对云计算集群环境安全性的要求日益增加,对这些KPI数据的预测准确度的要求也随之提高,如何准确预测云计算集群中的KPI数据的动向和变化,从而提升云计算集群的高可用性,是云计算集群高效运维需面对的问题[2].云计算集群的KPI数据变化多样,特征各不相同,线性、平稳性以及周期性常常针对不同的数据集单独分析,但综合分析后的预测准确性并不理想[3].传统模型存在各种欠缺(表1),急需一种能提高预测准确性的通用型综合分析方法.

表1 传统模型优缺点对比
2013年,Gilles等[11]在降低高噪声电信号数据的复杂度时首次提出经验小波变换EWT(Empirical Wavelet Transform,EWT),将数据分解成各个内在模态函数IMFs(Intrinsic Mode Functions,IMFs),大大提高了数据处理能力.为提高云计算集群中CPU和内存使用率等关键时序数据的预测精度,本文基于经验小波变换进一步处理得到云KPI数据的低中高频IMFs,根据分解得到的低中高频IMFs特征,分别运用ARIMA[4]、Autoformer[9]、TPA-BiLSTM[10](Temporal Pattern Attention-Bidirectional Long Short-Term Memory)模型对不同IMFs进行预测,建立一种应用性更强、预测精度更高的时序数据预测算法EWT-ARIMA-Auto-TPA(EAAT)方法.本文创新点如下:
1)在EWT基础上提出3分类模型,使用EWT方法将原始序列数据分解为低中高频3类IMFs,根据3类IMFs不同的特点,选用最合适的预测模型进行预测.
2)将中高频IMFs分成中频和高频分开讨论:针对高频IMFs中噪声较多的问题,引入TPA模型,增强模型对特征的处理能力,并与BiLSTM相结合,在噪声较多的数据中也能有更好的结果;在中频IMFs中引入最新的基于深度分解架构和自相关机制的Autoformer模型进行分析.
3)将注意力机制模型Autoformer加入组合模型,规避了其在应对噪声较多、周期较差的数据集上的不利情况,将其长处应用于有一定周期和规律的中频IMFs中,进一步提高了预测精度.
本文内容总体安排如下:首先分析已有分类集成模型的优缺点,说明2分类组合模型的局限性,以及3分类等组合模型的必要性;然后提出基于EAAT方法的模型架构;最后在谷歌和亚马逊的4个数据集上验证了结果.无论数据是否具有周期性或者稳定性,EAAT比单个模型在效果上均有较大提升,比EWT-IF-LSTM模型在均方根误差上最大降低了11.26%,验证了EAAT效果确实好于传统的2分类模型,如EWT-ARIMA-LSTM、EWT-ARIMA-TPA.
1 组合注意力模型EAAT预测方法
1.1 EAAT的构建背景
预测建模技术已被广泛用于云计算集群KPI数据的预测之中,如自回归移动集成平均模型(ARIMA)[4]、循环神经网络(RNN)[12]、长短期记忆网络(LSTM)[5]等.文献[6-7]将Transformer类注意力模型引入时间序列预测;Zhou等[8]提出稀疏注意力机制Informer,在长时序数据预测中取得了较好的效果;Wu等[9]提出自相关机制Autoformer,结合数据分解机制,在周期性和趋势性较好的长时序数据预测上于2021年取得了最佳效果.但单个模型常常难以从非线性和非平稳数据中提取特征,很难适应复杂多变的时序数据,容易发生局部优化和过拟合等现象,其准确性往往得不到保证.因此,很多研究利用集成学习的方法对单个模型进行组合,从而提高对云计算集群KPI数据预测的准确率.Baig等[13]将工作负载分为线性和非线性两种类型,并应用ARIMA和RNN的组合模型进行分类预测;Bi等[14]专注于识别和预测云负载中的模式问题,提出一种基于资源使用情况的聚类方法来识别周期性任务和非周期性任务.但是上述工作只考虑数据的线性或者周期性,并没有进一步对数据分解和分析以挖掘更深层的特征,对于非线性、非平稳、噪声较高的数据,ARIMA和LSTM等2分类组合模型的准确率难以进一步提高.为了对数据进一步分解和研究,文献[15]提出EMD-CNN-BiLSTM的混合预测模型用于风力数据的预测,文献[16]提出EMD-ARIMA的混合预测模型用于水流数据的预测,文献[17]用EWT将数据分解为低频和中高频的IMFs,用LSTM或GRU模型对IMFs进行预测,并最终合成,从而提高了预测效果.上述模型使用EMD(Empirical Mode Decomposition,EMD)或EWT对数据分解,降低了数据复杂程度以提高效果,区分了低频和中高频IMFs,但没有用多种模型进行组合和尝试.同时,低中高频IMFs本身具有不同的特点,中频IMFs没有低频IMFs那么大的波动和趋势性,也没有高频IMFs中那么多噪声和不确定信息,可以单独对其进行预测.因此,用EWT进行数据分解,并运用多种模型分类处理低中高频IMFs的方法具有一定的可行性.本文用EWT对时间序列数据进行处理,分解为低中高频3类IMFs,然后用最合适的模型进行预测.低频IMFs噪声较小、波动较大、趋势较好,适宜用传统的ARIMA模型进行预测;中频IMFs可以看出原数据中短期的变化规律,有一定的周期性和规律性,适宜用针对周期规律的Autoformer进行提取和预测;高频IMFs有大量的噪声和随机性因素,适宜用TPA-BiLSTM进行处理和预测.
1.2 基于经验小波变换EWT的云KPI提取和分析
云集群KPI数据如CPU和内存等,缺少周期性和规律性并存在大量噪声.为了准确地预测非平稳数据,必须首先对非平稳数据进行分解.在已有研究[6]中,经验模态分解(EMD)在处理非线性和非平稳时间序列方面得到了广泛的应用.但EMD等方法分解得到的分量过多且伴随模态混乱问题.与其他方法相比,EWT的主要优点是能够自适应地分割时序数据,傅里叶频谱将信号直接分解成频率分量,并在一段时间内以频域分布模式表示数据.EWT方法能通过序列分解方式,有效地获取云平台中各种类型的KPI时间序列的内在模态变量IMFs,因此具备了通用性和普适性.在应用预测模型之前,EWT通过分解和提取云服务机群KPI时序数据的信息来获得更高的预测精度.
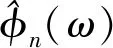
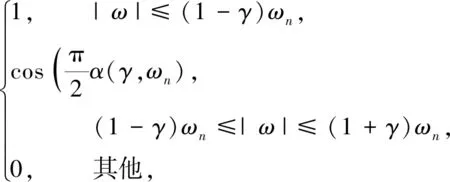
(1)
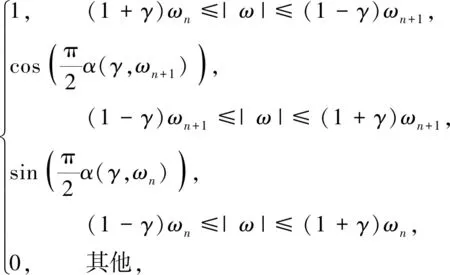
(2)
其中,函数α(γ,ωn)=β((1/2γωn)(|ω|-(1-γ)ωn)),函数β(x)一般需要符合以下条件:
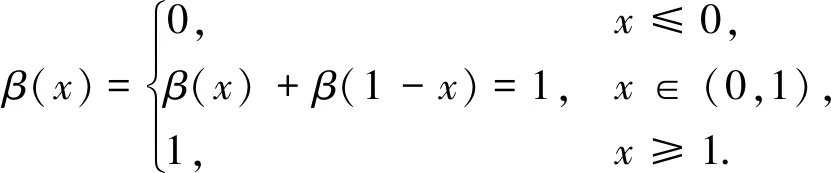
(3)
一般取β(x)=x4(35-84x+70x2-20x3).
式(1)、(2)中γ是为了确保2个连续的变换中不存在重叠的分量,取
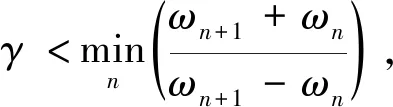
(4)
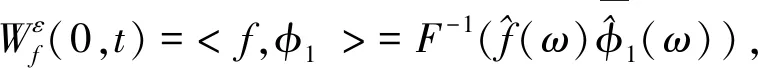
(5)
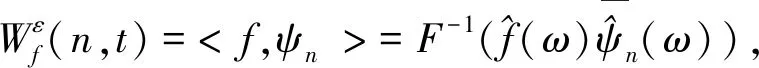
(6)


(7)

(8)
对处理后的信号进行重构得到逆经验小波变换IEWT的函数:

(9)
实验中对每个分量的预测结果记为低频预测结果f0′(t)和中高频分量fk′(t),最终预测结果为f′(t).如果IMF数量k取较大值时,几个中频信号会存在数据近乎相似、趋势相仿而信息较少的情况.本文实验中k取值为3,分解出的3个IMF分量f0(t)、f1(t)、f2(t)分别记为低频、中频、高频分量.
如图1中的Google集群2011数据集中某合成的时序数据(编号为mean CPU usage rate),通过对其进行EWT分解可以得到3个IMF分量,其中第1个分量IMF1反映原信号的低频部分,包含原信号的长期变化趋势等信息;第2个IMF2分量反映原信号的中频部分,可以看出原信号中短期的变化规律;噪声及某些突变部分在IMF3的高频分量中被体现出来.
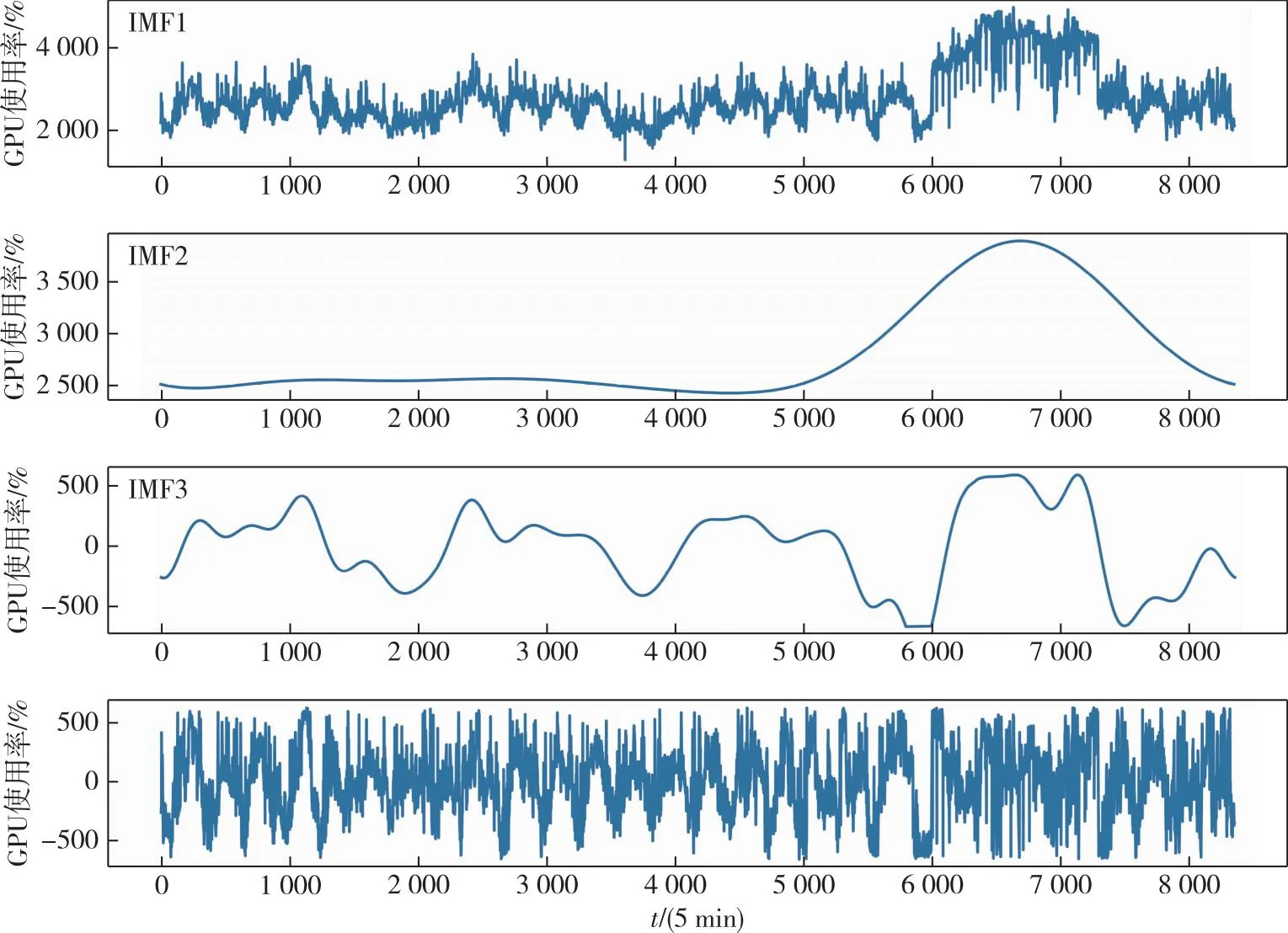
图1 谷歌某数据集进行EWT变换的结果Fig.1 Results of empirical wavelet transform for a data set in Google
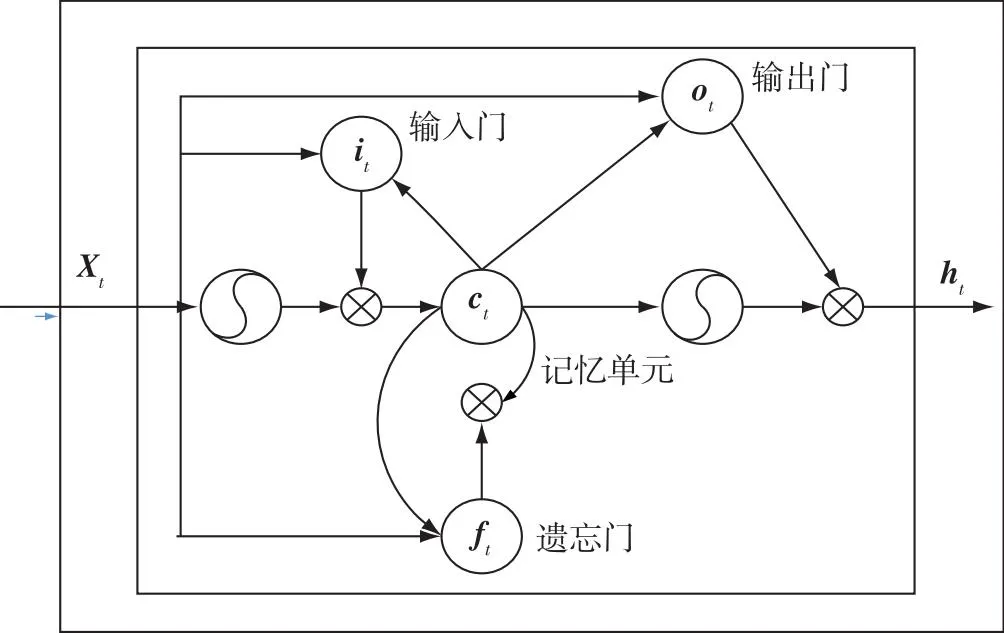
图2 LSTM原理Fig.2 Schematic diagram of LSTM
1.3 BiLSTM结合TPA模型的云KPI高频信息处理
长短时记忆LSTM(Long Short-Term Memory)网络是常用的改进的RNN网络[5],通过网络的记忆能力可将信息保存很长一段时间.LSTM在一个独立重复单元中存在4个运算单元.对于每一个输入的X,LSTM需要决定来自之前细胞状态的多少信息应该被移除.这一功能由Sigmoid函数实现,也被称为“遗忘门”,表示当前重复模块的细胞状态,作为输入传递给下一个重复模块.对于每个细胞状态,接受当前细胞,遗忘层输入一个介于0和1之间的值,表示将要从细胞状态中移除的信息量.LSTM网络决定需要包含在细胞状态中的新信息的数量.将Sigmoid层和tanh层相乘得到的值与遗忘层计算得到的细胞状态相加,最后每一个单元格都要输出一个值,通过使用另外一个Sigmoid层和tanh层得到.
LSTM的最终输出由输出门和单元状态决定:
ht=ottanh(ct),
(10)
其中,初始化时c0=0,且h0=0.LSTM的输入单元为Xt,输出单元为ht.
传统的LSTM有一个缺点,它只能学习时间序列数据的前一个上下文,不能学习同一序列数据的后向上下文信息,也不能编码从后向前的信息.而BiLSTM 通过将时间序列反向,由正反双向的LSTM组成,能够更有效地捕捉时间序列双向的变化.BiLSTM输出表达式为
ht=concat(htf,htb),
(11)
式中:ht表示BiLSTM 的隐藏状态向量;concat表示在输出维度进行拼接操作;htf,htb分别表示前向和后向LSTM的隐藏状态向量.
对于LSTM网络而言,每个时刻的输入都是当前时间所有行为组成的向量,使用BiLSTM的目的在于能够捕获不同序列方向的更多的特征信息.通过2个LSTM层以相反的方向处理数据,使得BiLSTM可以同时捕捉正向序列信息和反向序列信息.本文采用BiLSTM 结合TPA模型对云KPI数据的高频信息进行预测.
EWT分解得到的高频信号中有较多噪声以及与时间无关的干扰信息,需要一种在数据没有较好的周期性和趋势性时依然能获得较好效果的模型.
传统注意力模型如CNN+LSTM+Attention[18]等直接对原始数据的时间序列运用CNN完成特征提取,或者仅仅对单个序列的时序特性加以提取,常常无法兼顾不同序列之间各种错综复杂的关系.而在TPA-BiLSTM[17]中使用BiLSTM隐状态矩阵的行变量,则涵盖了在各个时间步各个时序下的复杂关系,比传统CNN-LSTM多用一层一维卷积层,从而对隐状态矩阵的行向量做特征提取,获得时序关系和各个变量间更深层的联系.在最后注意力加权的过程中,注意力向量是对每个有时间特征信号的时间模式矩阵的行向量加权和,使得TPA能从各个时间步中选取最关键的信息.在处理信噪比较高且时间步与不同序列间还存在着非平稳非线性的复杂关系的问题时,TPA比传统模型有更好的效果.TPA-BiLSTM的工作流程如图3所示.
对输入序列{Xt}用BiLSTM处理,所得向量ht-w-ht表示BiLSTM对不同时间步输入所得到的隐藏状态向量,w即为时序数据长度.定义隐状态矩阵H=(ht-w,ht-w+1,…,ht-1),其行向量代表每个变量所有时间步下的状况.图3中隐状态矩阵H的框表示不同的一维卷积核,利用一维卷积沿着H的m个特征卷积,提取可变时间模式矩阵HC:
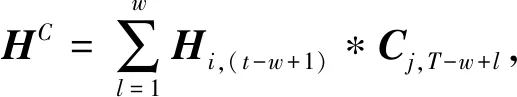
(12)
式中:Cj表示第j个长度为T的滤波器;T表示最大长度,w为其通常取值;*表示卷积运算.然后定义用注意力机制加权从而计算相关性:

(13)
(14)


(15)
式中,n表示输入变量x的特征数.
将vt与ht线性映射后相加获得最终预测值:
yt-1+Δ=Wh′h′t=Wh′(Whht+Wvvt),
(16)
式中:yt-1+Δ表示最终预测值;h′为用于生成最终值的中间变量;Δ表示任务预测的时间尺度;Wh′,Wh和Wv为对应变量的不同权重矩阵.
1.4 基于Autoformer分解架构的云KPI中频信息处理
Autoformer结合自相关机制和独特的时序分解机制[10],对传统注意力类模型在时序预测模型中进行了升级并取得2021年最好的效果.一方面,自相关机制计算原始序列和滑动各个步长后序列的自相关系数并做出选择,基于周期性找到子序列之间的相关性,从传统注意力的点到点的相关度上升到子序列和子序列的相关度,从而提高计算效率和信息利用率,且具有较低复杂度O(LlogL) 的输出.另一方面,Autoformer在编码器部分的主要目的是对复杂的周期项进行建模,通过多层的时序分解模块,基于滑动平均思想,不断从原始序列中提取周期项和趋势项,用于解码器预测未来的信息.编码器部分输入原始时间序列数据,解码器部分的输入包括趋势项和周期项两个部分.趋势项由两部分组成:一部分是通过原始数据经过时序分解出得到的趋势项,等同于用原始数据近期的趋势项作为解码器的初始化;另一部分是0填充的,即尚未得到的未来序列的趋势项.周期项的组成和趋势项类似.
Autoformer的解码器中对趋势项和周期项分别处理:针对周期项,通过自相关机制与序列的周期特性结合从而聚合有相似特征的子序列;针对趋势项,通过信息累积的方法逐步提取出趋势项信息.
图4为Autoformer模型工作流程.因为对时序数据周期和趋势的强行提取和加入,使得Autoformer在数据量大,且有季节性和周期性的长时序数据预测中效果较好,而在没有周期和规律的数据中效果较差.EWT分解得到的中频信号具有一定的周期性和规律性,因此,本文对中频部分采用Autoformer的序列分解架构进行预测.
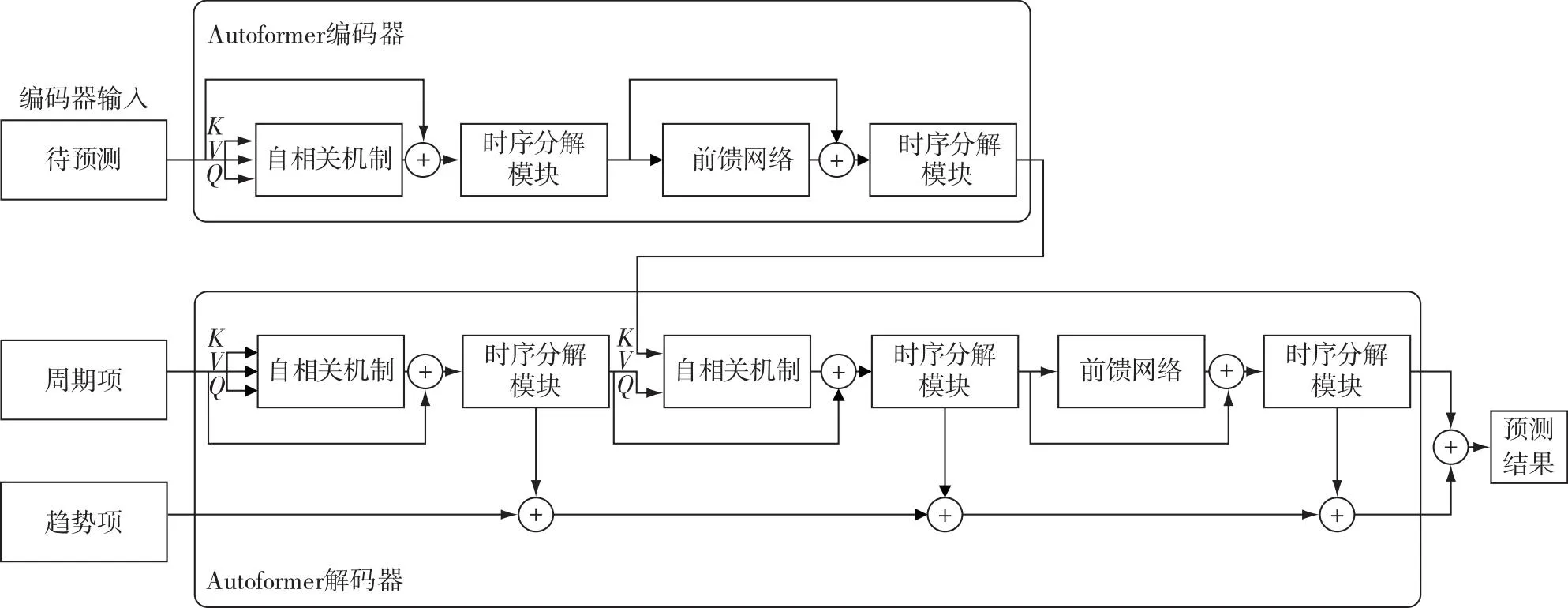
图4 Autoformer的流程和机制Fig.4 Processes and mechanism of Autoformer
1.5 EAAT总体预测流程
根据EWT与ARIMA、Autoformer、TPA-BiLSTM等模型各自的优势,将这3个预测模型相结合,以进一步提高数据集数据处理的准确性.该方法的具体操作如下:
第1步:输入云计算集群中某段待预测的KPI关键时序信息,对其进行EWT变换和分解,得到3个IMFs,分别涵盖了低中高频信息.噪声和随机信息主要集中在高频IMFs中,中频IMFs体现短期有周期和规律性的变化,低频IMFs反映原始数据的长期变化和主要趋势.
第2步:对噪声较多的中高频IMFs使用iForest和线性插值等方法清除异常值,并对清除后的空缺部位进行数据填充,从而确保中高频IMFs的数据位数保持相对恒定.
第3步:对上面预处理后的低中高频IMFs分别采用ARIMA、Autoformer、TPA-BiLSTM模型进行模拟训练和检测.依据实际状态调节模拟中的各项参数,以获得最佳预期状态.
第4步:将各IMFs计算后的预测结果,经过对EWT的逆变换IEWT加以合并,最后得出该KPI时序的预测结果.
EAAT预测方法的整体框图如图5所示.
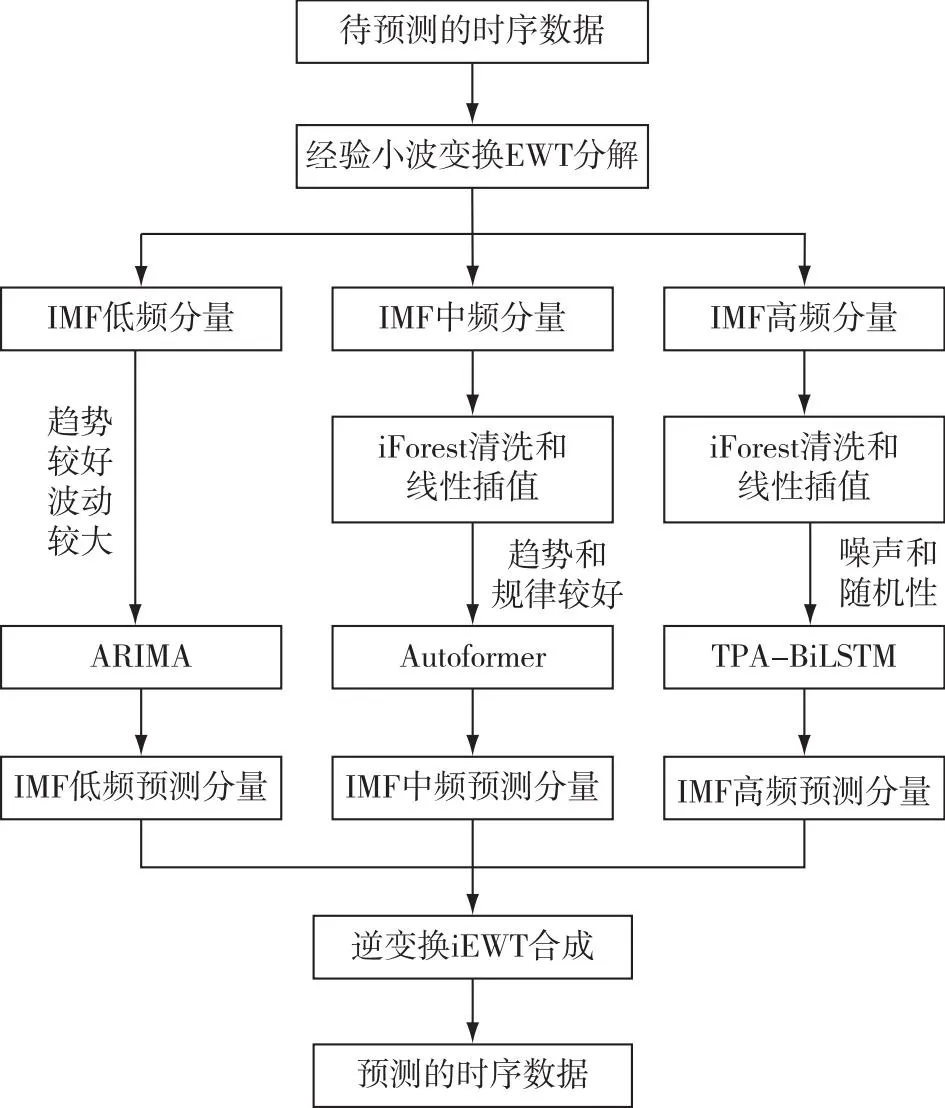
图5 基于EAAT的组合模型预测方法Fig.5 Combined model forecasting method of EAAT
2 实验与评价
2.1 数据集准备和参数设置
实验数据集选用谷歌和亚马逊两大云平台所监控采集的KPI时序数据集.
谷歌集群数据集2011(https://github.com/google/cluster-data)从2011年5月1日19时开始记录29 d的CPU资源利用率和每个任务在大约12 500 台计算机上的内存使用情况.取其中task usage数据集,分别提取mean CPU usage和 assigned memory usage这两个KPI指标构成新的数据集,按5 min间隔进行采样,按照任务开始时间进行聚合,数据体现一个数据中心一段时间内总体CPU和内存使用率的变换情况,分别记为第1组和第2组数据集.
亚马逊KPI监控数据集(https://github.com/numenta/NAB/tree/master/data/realAWSCloudwatch)来自于美国AWS的云监控CloudWatch所采集的云服务器的基础资源指标数据,共计17种不同类别KPI的监控数据,涵盖了云服务器的CPU使用率、磁盘I/O以及弹性负载均衡(ELB)的请求数等关键监控指标.为了和文献[15]进行对比,本文选用KPI编号为ec2_cpu_utilization_53ea38和ec2_cpu_utilization_5f5533的监控CPU利用率的数据集,分别记为第3组和第4组数据集.
对上述4组实验数据集进行切割,其中前80%作为训练集,后20%作为测试集.数据集长度代表有多少个时刻的数据,CPU和内存的使用率数据都是百分比数据,切割后的数据集长度如表2所示.
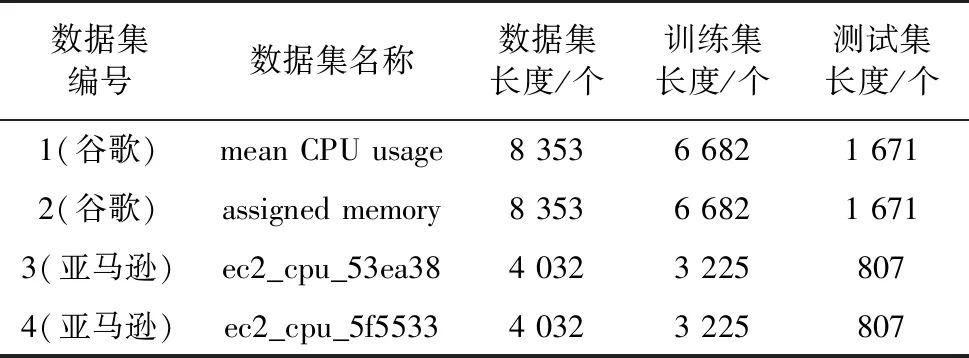
表2 实验用数据集信息
EAAT模型选择Adam作为优化器,ReLU函数作为各个神经网络的激活函数,学习率设置为0.001,滑动窗口长度为5.经过多次实验和调整后,ARIMA选择五阶差分回归,TPA-BiLSTM神经网络层设置32个隐层节点,Autoformer和TPA-BiLSTM选择batch_size为32,输入长度为80个历史数据,输出长度为20个数据,即每次用前80个时刻的数据对后20个时刻的数据进行预测,然后对每个重复预测的时刻取平均值作为预测结果.
2.2 评价指标
本文使用以下3个模型预测量化指标:均方根误差(RMSE)、平均绝对误差(MAE)以及平均绝对百分比误差(MAPE)评估算法性能:
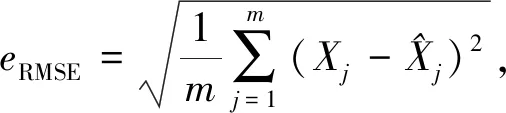
(17)
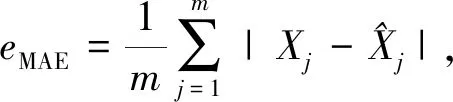
(18)
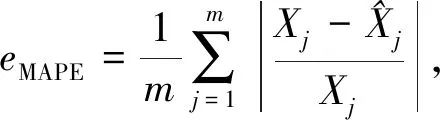
(19)
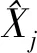
2.3 实验结果与分析
对4个数据集进行ADF校验,一般当p值大于0.05时,可以认为序列是不平稳的.实际校验数值如表3所示.数据集1、4不太平稳,数据集2、3相对平稳;低频IMFs中多数都不平稳,但具有较好的趋势性,在中高频IMFs中数据基本都是平稳的.
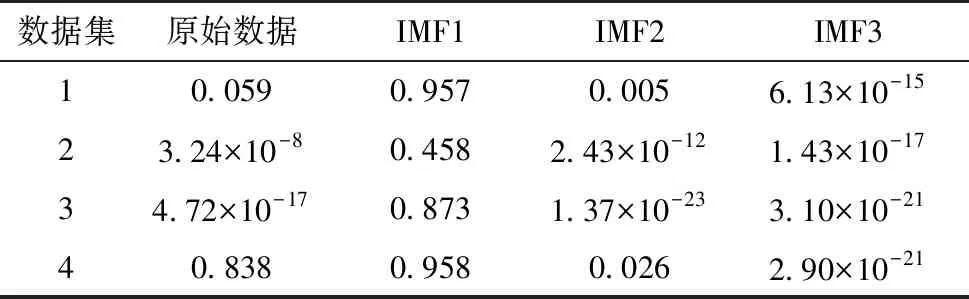
表3 数据集ADF检测的p值
将本文模型和传统的单一预测模型LSTM、TPA-LSTM、Autoformer以及EWT-LSTM、EWT-ARIMA-LSTM、EWT-ARIMA-TPA作为实验的对比对象,其中EWT-ARIMA-LSTM和EWT-ARIMA-TPA指中低频IMFs上使用ARIMA模型、高频IMFs分别使用LSTM或TPA的模型.测试集上的各模型预测结果如图6和图7所示,评价指标结果如表4—7所示,最优结果以加粗说明.

图6 两个谷歌数据集的测试集上的预测结果Fig.6 Prediction results on the test set of two Google datasets

图7 两个亚马逊数据集的测试集上的预测结果Fig.7 Predicted results on test set of two Amazon datasets
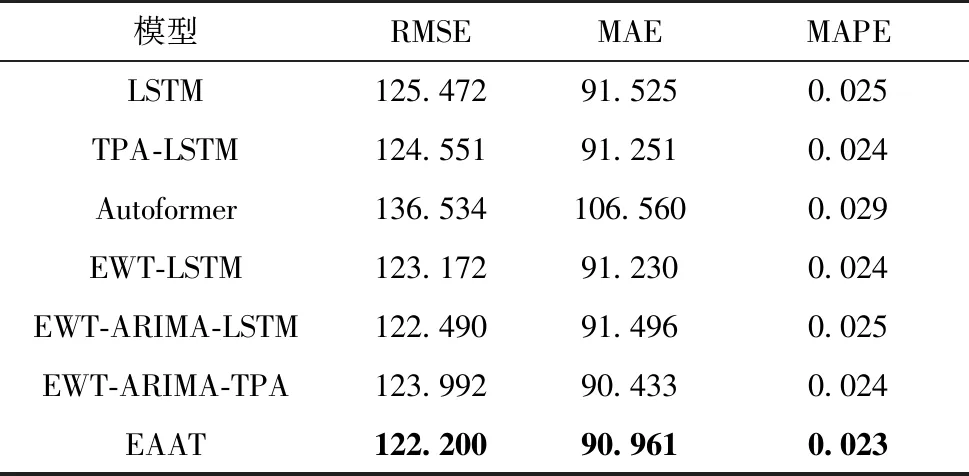
表5 各模型在数据集2上的效果
2.3.1 谷歌数据集的预测结果
处理后的谷歌两个数据集包含一个集群中所有机器的CPU和内存使用率的变化情况.由图6所示可知,在谷歌数据集的测试集上,EAAT方法整体拟合程度和稳定程度都略优于其他组合模型,远胜于单一的非组合模型.
两个谷歌数据集聚合了一个集群中所有机器的信息,数据更不平稳,整体误差较大.由表4、5可知:在3个评价指标上,EAAT方法都优于EWT-LSTM模型;对比EWT-ARIMA-TPA模型,EAAT方法在两个数据集上RMSE和MAPE指标中效果更优.
2.3.2 亚马逊数据集的预测结果
处理后的亚马逊两个数据集包含一个集群中所有机器的CPU和内存使用率的变化情况.由图7所示可知:在相对平稳的数据集3(53ea38)中,EAAT方法在稳定性和趋势性把握上相对最好;在数据集4(5f5533)中,因为该数据集的特殊情况,测试集数据比起训练集中的数据有一段陡升,所以实际值远远高于预测值,所有模型的误差都相对较大,此时EAAT依旧能在整体上优于其他模型,并在3个评价指标上取得了最好的结果(表6、7).
表6 各模型在数据集3上的效果

表7 各模型在数据集4上的效果
由实验结果可见:EAAT方法在4个特征各不相同的数据集中,RMSE和MAPE指标均表现最佳,MAE指标也表现较好;在相对不平缓、误差较大的数据集1和4中,EAAT方法效果提升更加明显.因此,EAAT方法可以有效提高对时间序列的预测的准确率,且具有广泛的适用性.
3 结束语
本文通过EWT将到云KPI数据分解成低中高频3类IMFs,分别运用ARIMA、Autoformer、TPA-BiLSTM模型对低中高频IMFs进行预测,再经过逆变换IEWT加以合并,最后得出该KPI时序的预测结果,即EAAT预测方法.本文运用EAAT预测方法对从谷歌和亚马逊服务器资源负载数据提取出的CPU负载时间序列数据进行了预测,结果表明,与单一ARIMA、Autoformer和TPA-LSTM模型预测相比,EAAT在3个评价指标上均有显著提升,预测效果更佳,在同一数据集中,比EWT-IF-LSTM模型性能更优,验证了EAAT方法的先进性.
