基于机器学习的海上多层砂岩油藏精细注水开发实践
2023-12-15任燕龙刘英宪侯亚伟王刚安玉华
任燕龙, 刘英宪, 侯亚伟, 王刚, 安玉华
(中海石油(中国)有限公司天津分公司渤海石油研究院, 天津 300452)
对于多层合采的水驱砂岩油田,经过长期的注水开发之后往往会暴露出三大矛盾:层间干扰、层内水窜、平面水驱不均。主要有以下3个方面原因:一是开发初期,海上油田为充分利用井槽资源,油井多层合采,注水井笼统注水,层间注采矛盾突现。二是开发中期,经过注入水的长期冲刷,地层的局部孔隙结构发生变化,注入水极易沿着高渗透层突进,形成高渗条带,导致低效、无效水循环加剧,降低注水利用率。三是开发后期,为提高产油量,油田现场往往会对油井进行提频,注水井频繁酸化,从而加剧油、水井间注采不均衡的问题,严重制约着油田的高效注水开发。因此,开展水驱油藏精细注采研究对提高老油田采收率具有重要的工程意义[1]。
基于油田注采矛盾的改善需求,解决实际生产过程中层间、层内矛盾引起的无效注水问题,亟须厘清油、水井间小层的产、吸情况,而生产测井组合仪(PLT)测试可以最为直观地反映小层生产情况,但是受海上平台的环境限制,PLT测试成本高,持续获取也较为困难[2],因此,众多学者对于精细注采方面的研究尤为关注。贾晓飞等[3]从单层油藏出发并结合层间干扰定义,建立了多层合采砂岩油藏动态干扰数学模型,为定量评价层间干扰及优化分层调配提供了借鉴。姜立富等[4]通过油井生产数据参数相关性分析和产液规律数据挖掘,完成了油井产液能力影响因素分析及不同井区平面及纵向注水状况分析。周海燕等[5]综合研究了渗透率贡献率、含水率、劈分系数之间的关系,提出了不同渗透层的多层合采产量劈分模式,利用多项式回归计算,建立了不同渗透层综合考虑含水率、渗透率贡献率等参数的产液劈分数学模型。以上研究成果对油田分层调配工作具有重要的理论指导意义,但是大多是理论公式推导,具有较多的理想化假设,且未考虑已有的小层产、吸剖面测试资料。
目前,机器学习技术和智能优化算法经过多年的知识积累与技术积累,已逐渐成熟和完备。机器学习是指在一定的样本数据中学习数据之间的内在联系与特征,得到一般性的规律,并且可以应用到未知的数据上。智能优化算法是通过模拟生物种群的自然进化过程,并融合生物的固有特性与智能行为所设计的启发式寻优算法。当前这些算法在油田开发领域的应用愈发广泛,如预测油田产量[6-8]、含水上升模式分析[9]、岩性分类[10]、复杂储层流体性质测井识别[11]等,均表现效果良好,可以实现较为准确的预测。
因此,为实现精细注采的目标,现首先利用神经网络模型实现油藏动、静态参数与产、吸测试结果之间的非线性映射关系,但是机器学习模型单次只能学习一口井的产、吸规律,而生产测试结果是多口井不同层位的结构体数据,模型无法直接应用。为此,利用智能优化算法对神经网络模型的权重和阈值进行初始化与迭代优化,以期得到一个可以符合所有井产、吸规律的预测模型,从而推进精细注水,指导油田高效开发。
1 原理与方法
为充分利用油田测井解释成果和动态监测等实际数据,利用反向传播(back propagation,BP)神经网络较强的非线性映射能力[12-13]和量子进化算法强大的局部和全局寻优能力[14-15]剖析出动、静态数据资料中的内在规律和特征,将地层的孔隙度、渗透率、有效厚度、压力等指标与生产测井结果建立非线性映射模型。
1.1 BP神经网络
BP神经网络是1986年由Rinehart和McClelland为首的科学家小组提出,是目前应用最广泛的神经网络模型之一。BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程,如图1所示,BP神经网络模型拓扑结构包括输入层、隐藏层和输出层。

图1 BP神经网络拓扑结构图Fig.1 Topology diagram of BP neural network
BP神经网络的学习规则一般是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,采用量子进化算法进行优化调整,使网络的误差平方和最小。
1.2 量子进化算法
量子进化算法结合了量子计算和进化算法的优点,是一种非常优异的智能优化算法。进化算法具有鲁棒性强、全局搜索能力高的优点,但是进化算法的种群进化存在着概率算法的缺陷,导致其进化过程具有较大的随机性,而且收敛速度缓慢,容易导致未成熟收敛,而量子计算可以降低某些复杂度很高问题的解决难度,提高收敛速度。
另外,为了提高量子进化算法的全局搜索能力,避免其陷入局部最优解,还引入了量子交叉与量子变异的思想。量子进化算法能够保持种群多样性和避免选择压力,而且当前最优个体的信息能够很容易地用来引导变异,使得种群以大概率向着优良模式进化。量子进化算法主要包括以下4个操作步骤。
步骤1量子位编码。一个量子比特具有3种状态:“0”态、“1”态、叠加态。在量子进化算法中,使用一种特殊的基于量子比特的编码方式,即用一对复数定义一个量子比特位。一个具有k个量子比特位的系统可以描述为
(1)
式(1)中:i=1,2,…,k。
步骤2量子旋转门操作。将种群中所有个体与最优个体进行对比,计算出量子门的变换矩阵,使得生成种群的量子态染色体实现进化,从而使种群不断迭代进化。最常用的量子旋转门如下。
(2)
式(2)中:δ=s(α,β)为旋转方向;θ为旋转角,控制量子进化算法的收敛速度。
步骤3量子交叉。假设原始种群有n个个体,每个个体拥有k个基因,将其作为基因库。当生成第1个新个体时需要k个基因,其每一个基因都有n种取值方式,在对应的基因位置上随机选取,直至生成新个体。选取之后的基因便从基因库中剔除,防止重复使用。因此当生成第2个新个体时,其每一个基因都有n-1种取值方式,当生成第n个新个体时,其每一个基因都有1种取值方式。以此循环生成新个体,直至恢复到原来的种群规模。
步骤4量子变异。量子变异可以避免量子进化算法未成熟收敛,并且提高局部寻优能力。具体的方法如下:首先按照给定的概率P1判断某一个体是否发生变异,在变异个体中按照给定的概率P2选取一个或多个变异基因;对发生变异的基因执行量子非门操作,使其倾向于坍塌到“1”态转变为倾向于坍塌到“0”态,或者相反。量子交叉与量子变异如图2所示。

图2 量子交叉与变异示意图Fig.2 Schematic diagram of quantum crossing and mutation
1.3 算法融合
利用量子进化算法对BP神经网络的权重与阈值进行优化与更新,之所以将这两种算法相结合主要有以下两方面原因。
(1)若利用BP神经网络本身自带的梯度下降法更新模型参数,则无法同时学习多口油、水井的产、吸剖面规律,因此通过编程构建多层循环,使得BP神经网络模型学习得到所有井的综合规律。
(2)从数学角度看,BP神经网络解决的是一个复杂非线性化问题,网络的权重与阈值是通过沿局部改善的方向逐渐进行调整的,这样会使算法陷入局部最优值,而非全局最优值,从而导致网络训练的精度不够。因此可以利用量子进化算法强大的全局寻优能力避免神经网络陷入局部最优值。
首先对神经网络节点的权重与阈值进行初始化,然后进入第1层循环,判断误差是否满足精度。若是,则保留全局最优参数,结束程序,若否,则进入第2层循环,判断是否遍历所有种群个体。若是,则对当代的种群方案进行量子进化操作,并进行优化和更新,并进入下一代操作,若否,则利用每一个个体对BP神经网络的权重和阈值进行更新,并进入第3层循环。之后利用最新的模型遍历全部油、水井,得到个体方案的适应度。通过层层迭代,在每代较优方案群的基础上逐步优化,最终得到最优个体,结束程序。如图3所示。
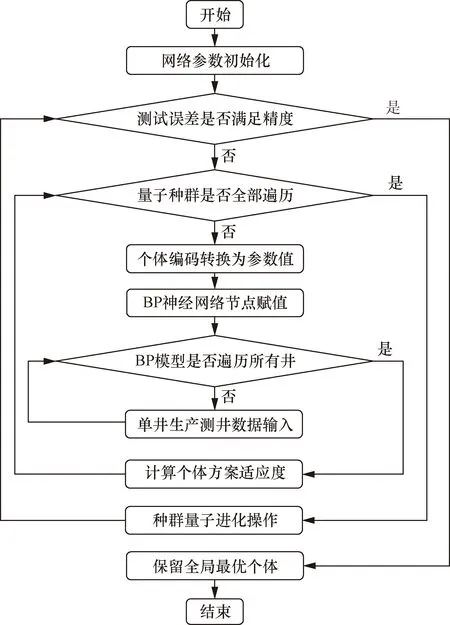
图3 神经网络参数优化与更新流程图Fig.3 Flow chart of neural network parameter optimization and update
2 学习样本库建立
在利用神经网络模型进行训练和预测的过程中,数据样本集的质量优劣直接影响着模型的训练质量和预测准确率。因此,在构造数据样本集的时候,首先要做好原始数据的清洗和标注;然后要对原始参数进行特征构造,使得输入到神经网络中的特征包含更多的有效信息,从而提高模型的预测效果;最后建立信息完备的学习样本库。
2.1 原始参数收集与选取
数据集成是指对来源不同的数据进行整理,将数据进行汇总、转换、提炼,最终得到一个简洁完备的数据库,有利于提高数据挖掘的效率。数据处理主要是对数据进行信息筛选、信息转换、矩阵合成等操作,技术含量不高,但是极其耗费时间,是进一步处理数据的重要基础。
小层产液比例或吸水比例主要与两方面参数相关:一方面选取小层固有的地质属性,包括小层完井垂厚h、有效孔隙度Ф、渗透率k、有效含油饱和度So、干黏土含量Cd、湿黏土含量Cw、地层静压P;另一方面选取油、水井动态参数,包括油井泵入口压力Pp、水井注入压力Pi,与地层静压相减后可以得到生产压差和注入压差,共计73口油井和84口水井,如表1所示。
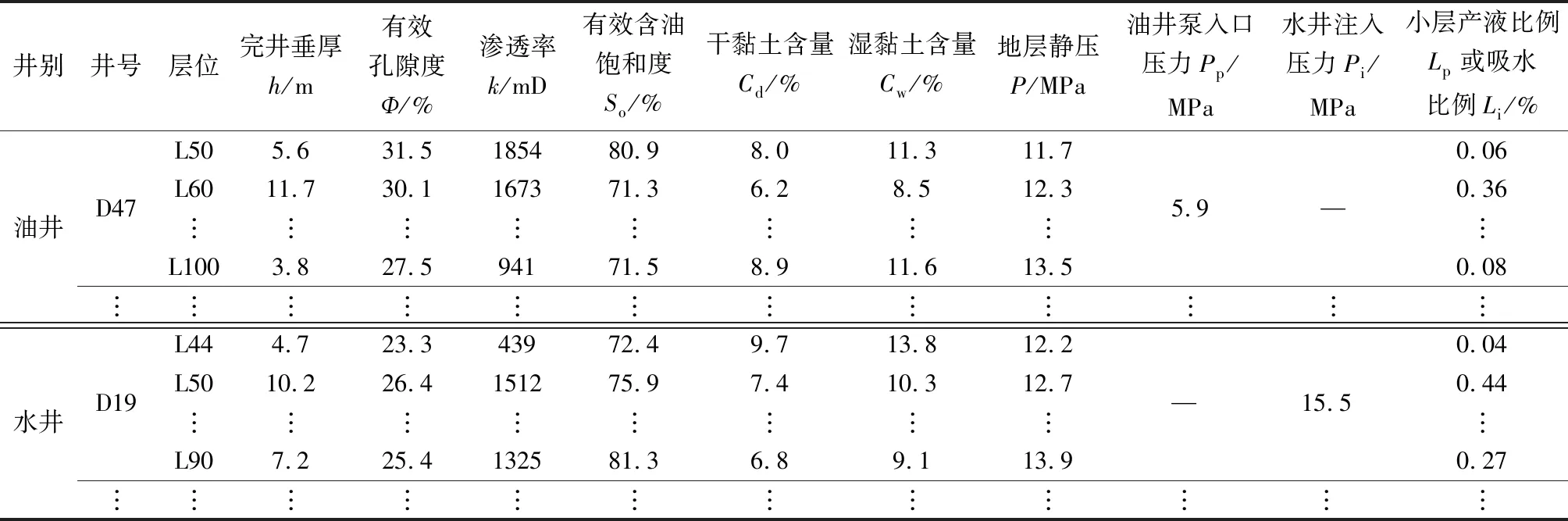
表1 参数选取表Table 1 Parameter selection table
2.2 特征构建
小层生产测井一般是按照防砂段进行计量的,但是一个防砂段通常包含多个小层,为建立上述参数和产液比例、吸水比例之间的非线性函数关系,因此将小层的地质属性按照厚度加权平均,从而得到整个防砂段的综合地质属性。以小层渗透率k计算为例进行说明,假设该防砂段有m个小层,函数关系式为
(3)
结合油藏工程理论,受达西公式启发,构建3个参数,包括kh、P-Pp、Pi-P;考虑到产、吸剖面受层间非均质性差异的影响较大,构建2个参数,包括k/km、Ф/Фm。最后得到11个与产、吸剖面相关的特征参数,如表2所示。

表2 参数构建表Table 2 Parameter construction table
2.3 关联度分析
为确保所构造的特征参数可以真实反映小层产、吸剖面的变化规律,因此需要对其进行关联度分析。首先,不同的特征参数通常具有不同的量纲,且有较大的数量级差异,如果直接用未标准化的数据进行神经网络的训练与预测,会导致预测结果过度依靠某一特征,使得预测精度较差。因此需要对特征参数进行标准差标准化处理,计算公式为
(4)
采用相关系数r分别计算出油井和水井的特征参数与产、吸剖面之间的平均相关性,如图4所示。
由图4分析可知,产能系数kh与产、吸剖面的相关性最高。干黏土含量Cd和湿黏土含量Cw与产、吸剖面的相关性较低,且为负相关,可对这两个参数进行删除,其余参数与产、吸剖面的相关性良好。上述特征参数与油井小层产液比例Lp的相关程度整体优于与水井小层吸水比例Li的相关程度,但整体而言所建立的特征参数与产吸、剖面的相关性较为良好。这主要是因为油井的产液大小与众多因素相关,生产情况十分复杂,而水井的生产制度比较简单。
最后,对油田内157口油、水井构建学习样本, 包括小层的8个特征参数和对应的小层产、吸剖面测试数据,为后续建立预测模型奠定坚实的数据基础。
3 小层产、吸剖面预测模型建立
基于所建立的学习样本库,利用BP神经网络模型和量子进化算法挖掘出特征参数与小层产液比例、小层吸水比例之间的内在规律,并建立相应的预测模型。
3.1 模型训练

图5 融合模型拟合误差迭代变化图Fig.5 Iterative variation diagram of fusion model fitting error
由图5分析可知,通过量子进化算法不断迭代,小层产、吸剖面预测模型的拟合误差在逐渐降低,最终所得模型对油井平均训练误差为1.29%,对水井平均训练误差为1.28%,训练结果十分精准;初始拟合误差下降较快,随着逐渐迭代,拟合误差趋于平缓或无变化,说明量子进化算法对模型参数的优化效果良好。
3.2 模型测试
将不同的训练集和测试集组合输入到模型中,所得油井产液剖面预测模型的平均测试误差为6.60%,水井吸水剖面预测模型的平均测试误差为4.36%。以油井E4、J1和水井V1、K3为例查看模型的测试效果,如图6和表3所示。

表3 kh值占比与融合模型测试误差对比表Table 3 kh value ratio and fusion model test error comparison table
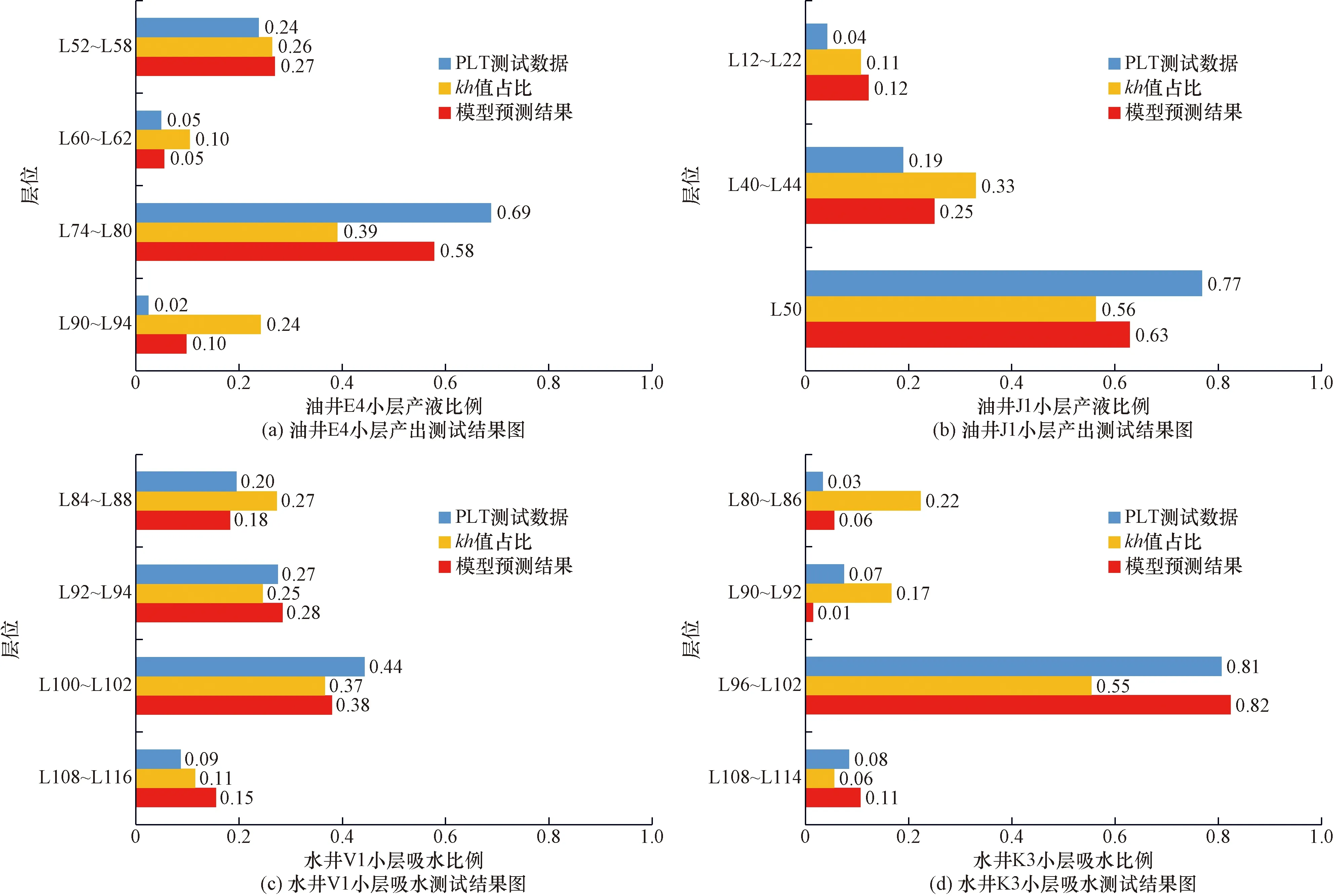
图6 融合模型拟合误差迭代变化图Fig.6 Iterative variation diagram of fusion model fitting error
由图6和表3分析可知,模型预测与kh值占比相比,模型预测结果更加接近小层产出测试数据,误差有了大幅度降低,且误差大小满足油田现场需求。因此可应用该模型对无小层产出测试数据的油、水井进行产、吸剖面预测,并基于该预测结果进一步推动分层调配、调剖调驱等精细注水工作,改善多层砂岩油藏水驱开发效果。
4 实例应用
目标油田P位于渤海中南部海域,以浅水辫状河三角洲沉积为主,小层数目多且单层厚度薄。目前该油田处于高含水期,含水率为89.6%,采出程度为17.9%,含水上升率为2.7%。针对该油田平面产液结构不均、纵向层位水窜问题,利用所建立的小层产、吸剖面预测模型开展分层调配研究,实现井区流场重建,控制含水上升。
4.1 油、水井产、吸剖面预测
以D1井组为例说明研究成果,如图7所示。
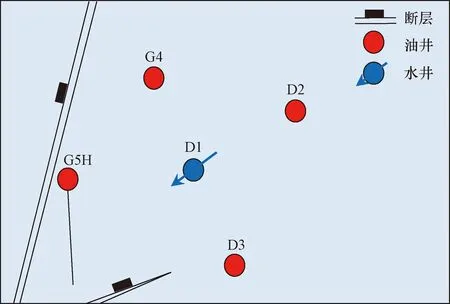
图7 D1井组井位示意图Fig.7 Well location diagram of D1 well group
该井组平面上连通关系差异大,产液不均,纵向上小层多,层间干扰严重。现有井网为1注4采,其中,水井D1注水层位为L40~L100,油井G4、D2、D3为定向井,油井G5H为L50的水平井。该井组的油井含水率均在92%以上,亟须通过分层调配及其他工艺措施来共同提高注入水利用率。
首先利用所建立的小层产、吸剖面预测模型预测出D1井吸水剖面,计算出调配前各小层的实际注入量,并与设计配注量进行对比,如图8所示,D1井的L50~L54、L80~L82小层的实际注入量远远低于配注量。经综合分析认为,主要是由于该油田储层疏松,存在微粒运移现象,导致部分小层的近井地带储层堵塞。因此设计对该井进行分层调配作业,经调配后水井D1井各个小层的实际注入量和配注量基本匹配。
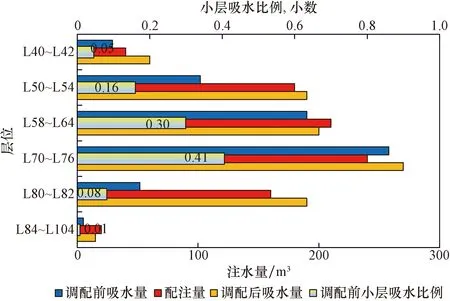
图8 D1井小层吸水比例预测图Fig.8 Prediction diagram of water absorption ratio of small layer in well D1
然后利用所建立的小层产、吸剖面预测模型预测出G4井产液剖面,如图9所示,产、吸剖面预测模型与常规kh劈分法具有一定的差异性。经分析认为,主要是由于注入水冲刷与微粒运移会使得储层孔渗结构发生变化。对于kh值占比较小的层位,注入水流量较小,储层改造作用小,所以两种方法的小层产液比例预测基本一致;对于kh值占比较大的层位,生产初期注入水流量较大,随着长期生产,部分层位由于储层微粒运移导致堵塞,部分层位形成水窜通道。

图9 G4井小层产液比例预测图Fig.9 Prediction diagram of liquid production ratio of small layer in well G4
由分析可知,该油井L70油组的产液量较高,结合水井D1井L70油组的注水量也较高,且监测装置显示该井的井底流压较高,说明G4井与注水井D1在L70油组存在窜流通道,导致L70油组的注入水主要由G4井产出,从而降低了D1井在L70油组与D2、D3井的驱油效率,使得井组整体含水率较高,因此设计对G4井L70油组进行堵水作业。另外,该井L62小层的产液量较低,因此设计对G4井L62小层进行酸化解堵作业。
另外,同样对D2、D3井的产液剖面进行预测,预测方式与G4井相同,因此不再进行赘述。经分析发现D2井在L50油组存在窜流通道,设计对该井进行堵水作业;D3井的产液剖面较为均衡,但是该井整体产液量不高,主要是由于钻井过程中的储层污染问题,设计对其进行酸化解堵作业。
4.2 结果分析与讨论
通过油、水井多种措施综合实施,井组的治理效果如图10所示,水井D1井分层调配之后,周边油井均有动态响应,含水下降明显,产油提高显著,其中G4井日增油39 m3/d,含水率下降6%;D2井日增油20 m3/d,含水率下降5%;D3井日增油4 m3/d,含水率下降6%,最终实现井组整体日增油63 m3/d,综合含水率下降约6%。井组综合治理之后,井组注、采关系得到明显改善,解决了纵向产、吸不均衡的问题。
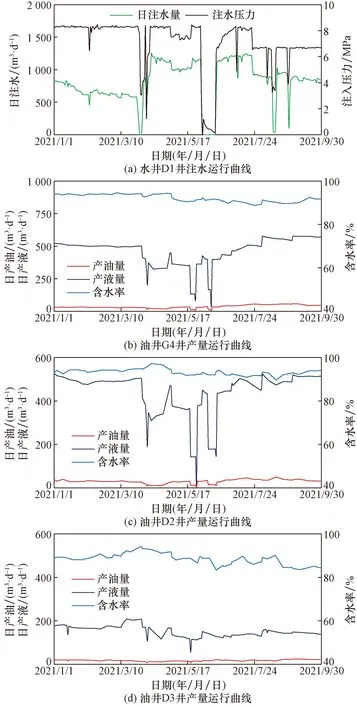
图10 井组综合治理效果图Fig.10 Comprehensive treatment effect picture of well group
5 结论
基于油田丰富的数据资料,利用智能优化算法和机器学习算法深度挖掘内部规律,并应用于实际油田,主要得到以下结论。
(1)提出了BP神经网络和量子进化算法深度融合的小层产、吸剖面预测模型,实现了神经网络权重和阈值的自动更新,克服了传统神经网络无法同时学习多口油、水井样本特征的难点。
(2)所建立的油、水井产、吸剖面预测模型的训练和测试结果较为准确,平均训练误差分别为1.29%和1.28%,平均测试误差为6.60%和4.36%,可快速、准确预测小层产、吸剖面。
(3)实例应用表明,D1井组整体开发效果得到明显改善,说明该研究成果可为油田分层调配等调整措施提供技术支持,对推进油藏精细注水具有一定的指导意义。
