一种序决策信息系统中的快速属性约简算法
2023-12-15张义宗王诚彪
张义宗 ,王 磊,2 ,徐 阳 ,王诚彪
(1.南昌工程学院 信息工程学院,南昌 330099;2.江西省水信息协同感知与智能处理重点实验室,南昌 330099)
粗糙集理论是波兰数学家Z.Pawlak[1]于1982年提出的一种能够有效处理带有不确定性、模糊性、不精确性数据的数学工具。由于粗糙集理论解决实际问题的有效性,广大研究者已将粗糙集理论大量地应用于机器学习[2-3]、模式识别[4]、数据挖掘[5]与知识发现[6]等领域。而属性约简是粗糙集理论中的核心与热点研究问题之一,其旨在找出与决策信息系统分类能力一致的属性子集,从而达到决策信息系统属性降维的目的。
经典粗糙集理论是以等价关系对论域的划分形成的等价类为研究基础的,但该理论不适用于处理具有偏序关系的属性值的数据。为此,S.Greco等[7-8]基于优势关系对经典粗糙集方法进行了研究,提出了优势粗糙集方法(dominance rough set approach,简称为DRSA),并根据优势粗糙集方法近似集的运算对象是决策类的上(下)向联合集,给出了上(下)向联合集的上、下近似集的定义。此后,众多学者对优势粗糙集方法进行了一系列的研究和推广。张娇娇等[9]定义了两种新的优势关系,并结合毕达哥拉斯模糊加性算子提出了2种广义优势粗糙集模型;李艳等[10]对不协调目标信息系统的属性约简进行了深入研究,在优势关系上给出了浓缩布尔矩阵的概念,并将其用于计算属性约简;Li W.T.等[11]针对区间值序信息系统提出了一种基于优势关系的特征选择(属性约简)方法;Du W.S.等[12]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数提出了一种计算所有属性约简的方法;Yang X.B.等[13]将优势关系拓展到区间值决策系统上,提出了基于α-优势的粗糙集模型,并给出了上下近似的计算方法。针对多标准排序问题;M.Szelag等[14]基于可变一致性优势的粗糙集,提出了一种带有偏好信息的多准则排名方法;Zhang H.Y.等[15]将α-优势推广至集值信息系统中,结合合取和析取给出了2种新的优势关系,并基于此提出了集值决策表的特征选择(属性约简)方法。以上研究均是对优势粗糙集模型的扩展和推广,可用于解决不同类型数据集的属性约简问题。然而,在实际生活中,数据的属性约简结果需要实时快速地更新,因而基于优势关系的属性约简方法的效率需要进一步的研究。
本文以序决策信息系统为研究对象,首先将王磊等[16]的知识粒度的矩阵表示与计算方法运用到序决策信息系统中,同时引入优势关系矩阵的概念,在此基础上以知识粒度表征的属性重要度为启发信息进行属性约简;然后,探讨序决策信息系统中知识粒在属性数目变化条件下的粗化与细化过程,由此提出一种相对冗余属性的判定准则,并结合前向属性约简方法设计了一种快速属性约简算法;最后,通过在UCI数据集上进行属性约简算法的性能测试,结果证实了本文提出的属性约简算法的可行性和高效性。
1 基本知识
1.1 优势粗糙集方法的相关基础知识
定义1 决策信息系统S=(U,A=C∪D,V,f)。其中,U为非空有限对象集合,U={x1,x2,…,xm};A是一个有限非空属性集,C是条件属性集,D是决策属性集,并且C∩D=∅;对于∀a∈A,均存在a的一个属性值集Va,V=∪Va为属性集A的属性值集;f为信息系统的信息函数,其能给出属性集A在U上的属性值集。若属性值集V具有偏序关系,则称该系统为序决策信息系统。
例1 表1是一个序决策信息系统,其中对象集U={x1,x2,…,x5},条件属性集C={a1,a2,a3,a4},决策属性D={d}。

表1 一个序决策信息系统Table 1 A order decision information system
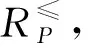
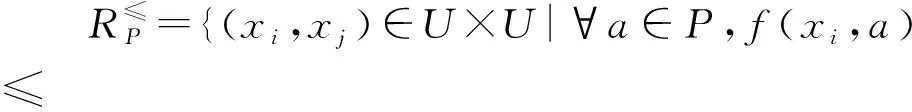
(1)

(2)
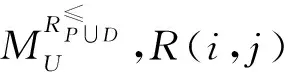
(3)
定义5 给定一个序决策信息系S=(U,A=C∪D,V,f),P⊆A,那么P的知识粒度记为GK(P),定义为:
(4)
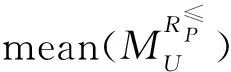
定义6S=(U,A=C∪D,V,f),P,Q⊆A,知识Q关于知识P在U上的相对知识粒度为GK(Q|P),可表示为:
(5)
定义7S=(U,A=C∪D,V,f),P⊆C,∀a∈C-P,那么属性a相对于属性集P的外部属性重要度可定义为:
(6)
同理,属性a相对于属性集P的内部属性重要度可定义为:
(7)
定义8S=(U,A=C∪D,V,f),R⊆C,R是条件属性集C相对于决策属性集D的一个属性约简,则R必须满足以下2个条件:
(1)GK(D|R)=GK(D|C)
(2)∀a∈R,使得GK(D|R-{a})≠GK(D|C)
1.2 优势粗糙集方法中的启发式属性约简算法
根据景运革等[17]给出的经典粗糙集中基于知识粒度的属性约简算法,将其引入到优势粗糙集方法中,优势粗糙集方法中以知识粒度表征的属性重要度为启发信息的属性约简算法如算法1所示。
算法1 优势关系下基于知识粒度的属性约简算法(Attribute reduction algorithm based on knowledge granularity under dominance relationship,ARKG-DR)
输入:序决策信息系统S=(U,A=C∪D,V,f)
输出:一个属性约简RED
步骤1:计算GK(D|C)。
步骤2:初始化RED←∅,RED_Pool←C。
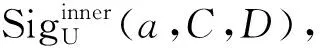
步骤4:计算GK(D|RED),如果GK(D|C)= GK(D|RED),则转至步骤9,否则转至步骤5。
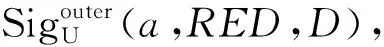
步骤6:计算更新后的GK(D|RED),若GK(D|C)=GK(D|RED),则转至步骤5,否则转至步骤7。
步骤7:B←RED。
步骤8:对于∀a∈B,如果GK(D|C)=GK(D|B-{a}),则RED←RED-{a}。
步骤9:输出属性约简结果RED。
例2续例1,表1是一个序决策信息系统,运用算法1对其进行属性约简的过程如下:
步骤6—步骤9 计算更新后的GK(D|RED)≠GK(D|C),则执行步骤5,RED={a1,a2,a3,a4}, GK(D|RED)=GK(D|C),则执行步骤8,对于∀a∈RED,计算GK(D|RED-{a}),得出RED去除a4时,GK(D|RED-{a4})=GK(D|C),输出属性约简结果RED={a1,a2,a3}。
然而,在处理无核或少核数据集的属性约简问题时,算法1中求核的步骤3和步骤4极大地降低了数据集的属性约简效率。此外,在步骤5中若存在多个属性外部属性重要度相同的情况下如何去除相对冗余属性的同时并正确选取到约简集属性是值得研究的问题,其将会通过减少去冗余属性的过程(步骤7、步骤8)和缩小待约简属性集来降低算法的时间复杂度。针对这些问题,本文研究了相对冗余属性的判定定理和提高约简结果有效性的策略并结合前向属性约简方法设计了一种快速启发式属性约简算法。
2 优势粗糙集方法中的快速启发式属性约简算法
为了提高无核或少核数据集属性约简的运算效率和约简结果的有效性,本小节通过分析序决策信息系统中知识粒在属性数目变化条件下的粗化与细化过程,由此得出加速属性约简的相对冗余属性判定定理,并结合前向属性约简方法[18]设计了基于知识粒度的一种快速属性约简算法。
2.1 快速属性约简的相关性质与定理
性质1S=(U,A=C∪D,V,f),P={P1,P2,…,Pn}为条件属性子集簇,并且P满足P1⊆P2…Pn,那么任意对象xi∈U在不同属性子集P1,P2,…,Pn下的优势类满足[xi]P1⊇[xi]P2⊇…⊇[xi]Pn。
由性质1可知在属性约简过程中随着属性约简集中元素数目的增加,优势类的个数并不会发生变化,而每个优势类中的元素会逐渐减少。条件属性集将论域U覆盖为|U|个不同的优势类,而每个优势类均是一个优势知识粒。参照文献[16],有论域U在条件属性子集簇P1,P2,…,Pn下的所有优势类构成的优势知识粒层次结构图,如图1所示。

图1 优势关系下优势知识粒的层次结构图Fig.1 Hierarchy diagram of dominant knowledge granules under dominant relationship
定义9S=(U,A=C∪D,V,f),Rn是S的一个属性约简,∀a∈C-Rn,则称a为条件属性集C关于决策属性集D的相对冗余属性。

向属性约简Rn中添加相对冗余属性a并不会影响其对论域U覆盖的优势类,也就是说每个优势知识粒都不会发生变化,证明从略。
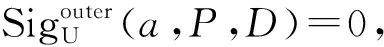
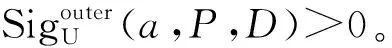
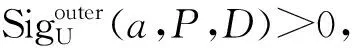
定理2表明,在后述快速约简算法的每轮迭代中删除相对冗余属性,不仅不会影响属性约简的计算,还可通过缩小待约简属性集提高属性约简的计算效率。此外,为了提高后述快速约简算法的属性约简结果的有效性,当一轮迭代中最大外部属性重要度属性有多个时,选取与属性约简子集合并后知识粒度最小的一个属性,这是因为此属性相对于属性约简子集更能区分论域从而更重要。
2.2 结合前向属性约简方法的快速属性约简算法
算法2 优势关系下基于知识粒度的快速属性约简算法(Fast attribute reduction algorithm based on knowledge granularity under dominance relationship,FARKG-DR)
输入:序决策信息系统S=(U,A=C∪D,V,f)。
输出:属性约简RED。
步骤1:计算GK(D|C);
步骤2:iter←1,Citer←C,RED←{};
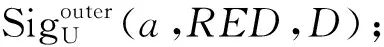
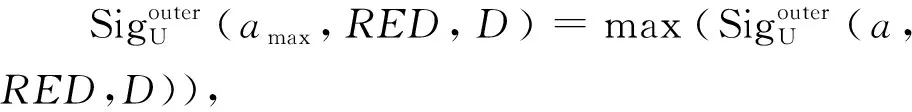
步骤6:iter←iter+1,Citer←Citer-1-RED_non;
步骤7:计算GK(D|RED),如果GK(D|C)=GK(D|RED),则转至步骤8,否则转至步骤3;
步骤8:输出属性约简结果RED。
在算法2中,不需先计算出核属性集,而是在待属性约简集中通过多次迭代去除相对冗余属性并选取出属性约简集,对于无核或少核数据集会大幅度提高属性约简的计算效率。
例3 续例1,现用算法2对其进行属性约简,共有3次迭代,具体过程如下:
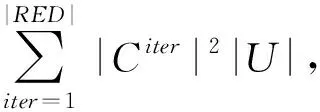
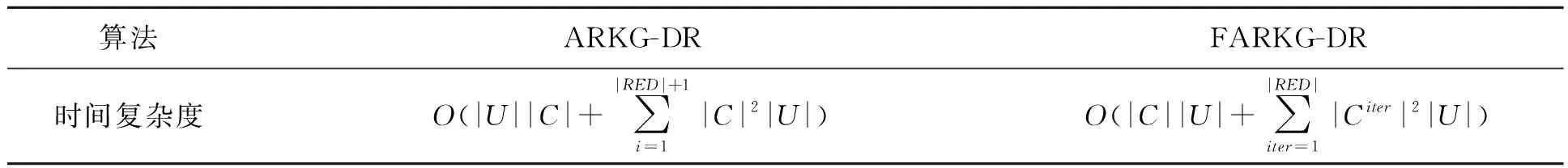
表2 两种算法的时间复杂度比较Table 1 Time complexity comparison of two algorithms
3 实验与结果分析
为了证实算法2的有效性及属性约简结果的准确性,从UCI机器学习数据(https://archive.ics.uci.edu/ml/datasets.php)中选取了6个数据集进行算法的性能测试。实验前对原始数据进行了预处理以得到具有偏序关系的数据集并将原始数据集的分类(决策)属性值赋予具体的数值。各UCI数据集信息的具体描述如表3所示。
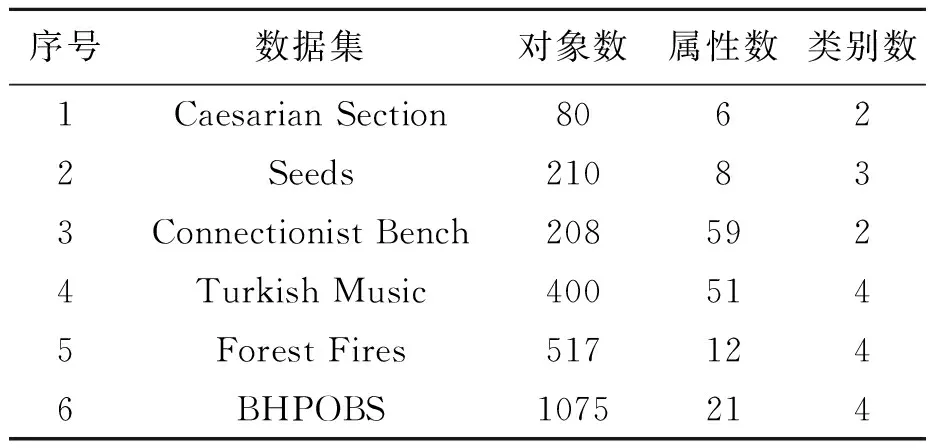
表3 UCI数据集Table 3 UCI data sets
本文所有算法的性能测试实验均在PC机上进行。实验的硬件、软件环境为:Intel® CoreTMi5-6300HQ CPU @ 2.30 GHz处理器,12 GB内存,操作系统为Window10(64位);实验算法均在Pycharm软件平台编程实现。
实验分为3个部分,第一部分实验是算法FARKG-DR、算法ARKG-DR和基于优势条件熵的启发式属性约简算法CHAR-DCE[19]对各数据集进行属性约简后的运行时间与属性约简结果的比较。此外,属性约简的运行时间是十次运行时间的均值;第二部分实验是将各数据集分为十等分,将第一份数据作为基础数据集,每次添加一份数据直至对整个数据集进行属性约简,然后比较分析FARKG-DR、ARKG-DR和CHAR-DCE算法按此过程对数据集进行属性约简的运行时间;第三部分实验是在Weka机器学习软件上测试各算法在6个数据集上属性约简的分类准确度。
从表3可知,实验选取了6个不同规模的数据集。规模最大的数据集是BHPOBS数据集,具有1 075个对象、21维属性,规模最小的属性集是Caesarian Section数据集,仅有80个对象、6维属性;属性维数最多的是Connectionist Bench数据集,具有59维属性,属性维数最少的是Caesarian Section数据集,具有6维属性。
表4给出了算法FARKG-DR、ARKG-DR和CHAR-DCE在各数据集上的计算属性约简的运行时间和属性约简结果。可以看出,FARKG-DR和ARKG-DR算法的属性约简结果长度非常接近,而CHAR-DCE算法在Turkish Music、Forest Fires和Connectionist Bench数据集上的属性约简结果长度比其他两算法略差。同时,FARKG-DR算法处理大部分数据集的运行效率优于CHAR-DCE和ARKG-DR算法,而在处理Seeds数据集时,FARKG-DR算法的效率低于ARKG-DR算法,这是因为Seeds数据集的核属性相对多,FARKG-DR算法需要多次迭代计算属性约简从而降低了运行效率。
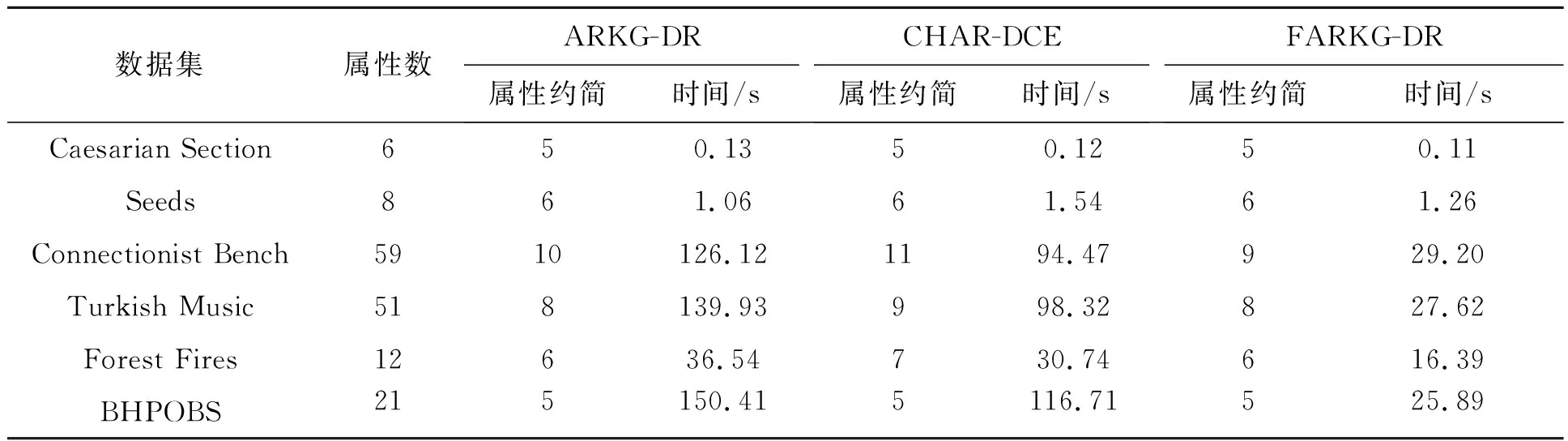
表4 三种算法的属性约简结果及其运行时间比较Table 4 Comparison of attribute reduction results and running time of three algorithms
图2是在各数据集逐渐增加数据的条件下各算法处理数据集的运行时间图。图中横轴表示数据量的大小,为整个数据集的占比,纵轴表示算法的运行时间。可以看出,当数据集无核或者核属性过少、相对冗余属性过多时,FARKG-DR算法的运行效率明显优于ARKG-DR和CHAR-DCE算法,例如数据集Connectionist Bench、Turkish Music、Forest Fires和BHPOBS。由于BHPOBS数据集无核,Connectionist Bench、Turkish Music和Forest type数据集的核属性过少,FARKG-DR算法不需要计算核属性,只需少次迭代计算出属性重要度最大的属性加入属性约简结果并删除相对冗余属性,这极大地缩短了属性约简的时间,而ARKG-DR和CHAR-DCE算法需要计算核属性集和删除属性约简集冗余属性,从而较大的降低时算法的运行效率。
为了验证3种算法处理各数据集得出的属性约简结果的准确性,本文使用Weka机器学习软件上自带的贝叶斯分类器进行测试并使用十折交叉验证的方式计算FARKG-DR、ARKG-DR和CHAR-DCE算法得到的属性约简结果的分类准确度,结果如表5所示。可以看出,FARKG-DR算法在大多数数据集上的分类准确度要比ARKG-DR、CHAR-DCE算法更加优越,而在Seeds数据集上略逊于ARKG-DR算法,由此可以说明,FARKG-DR算法计算属性约简是有效且准确的。
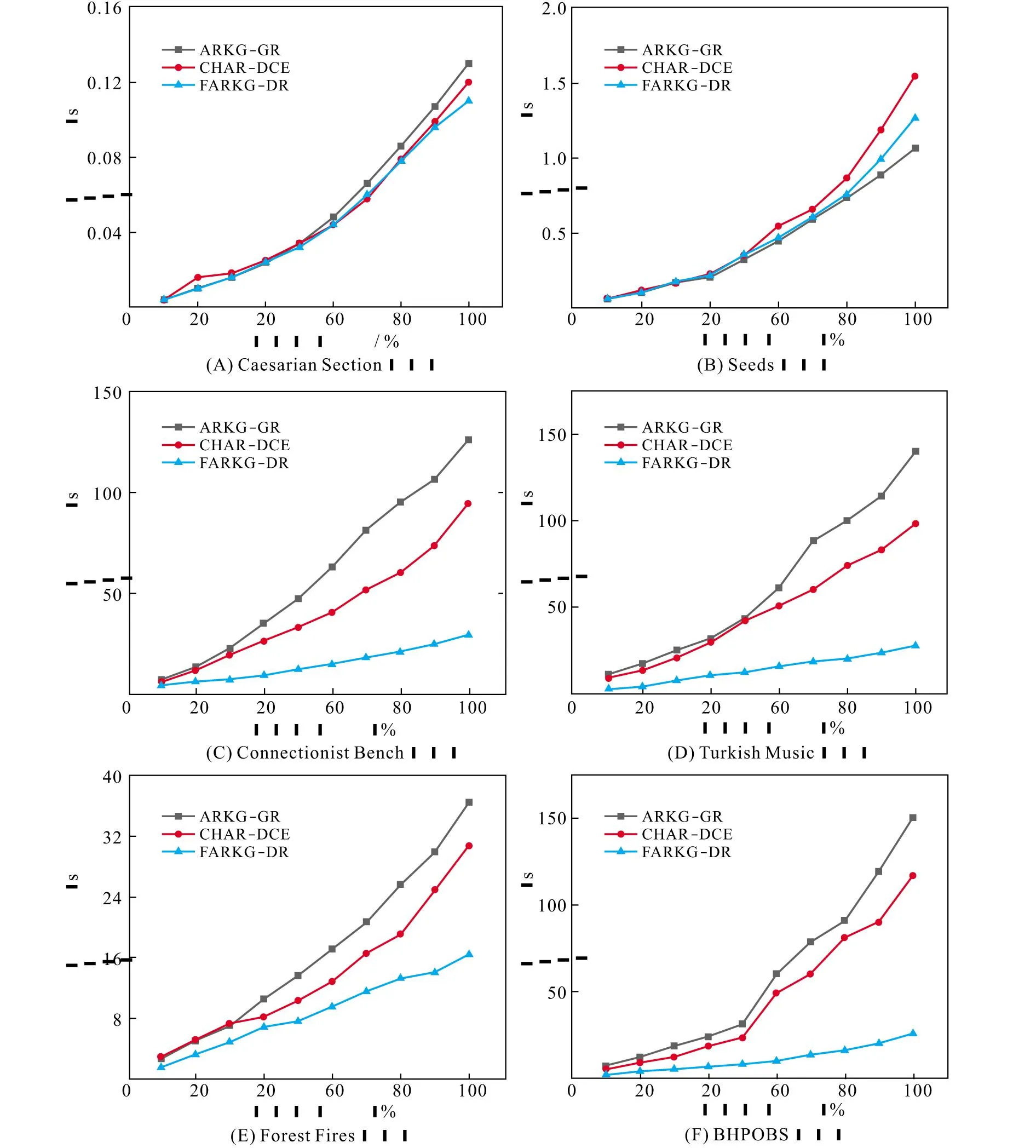
图2 三种算法运行时间的比较Fig.2 Comparison of running time of three algorithms
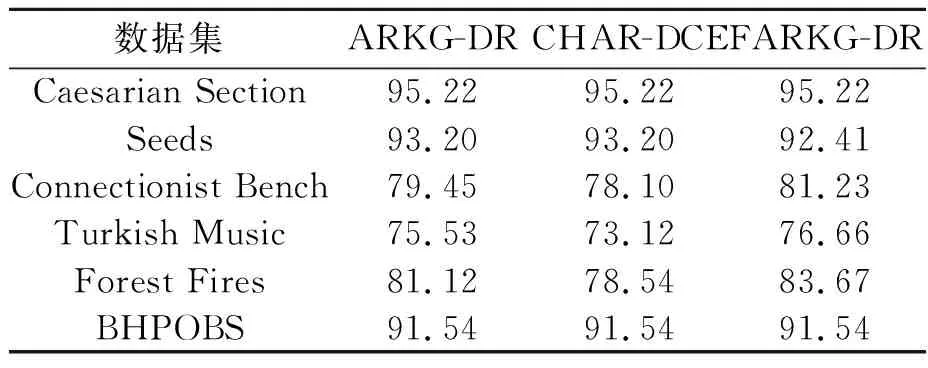
表5 三种算法分类准确度的比较(单位:%)Table 5 Comparison of classification accuracy of three algorithms (unit:%)
4 结 语
本文以知识粒度度量序决策信息系统中的属性重要度,在此基础上结合前向属性约简方法提出了一种快速属性约简算法。此算法不需先计算出核属性集,而是在待属性约简集中通过多次迭代去除相对冗余属性并选取出属性约简集,这极大提高了无核或少核序决策信息系统的属性约简效率。为了验证算法的有效性和高效性,本文选定6个UCI数据集进行实验,实验结果表明:本算法的属性约简效率优于经典属性约简算法,尤其是在处理无核或者少核数据集的属性约简效率远高于经典属性约简方法。考虑到现实生活中数据都是动态变化的,本文所提算法无法高效地进行属性约简,未来研究工作的重点是在序决策信息系统中有属性多个增加或者删除的情况下,设计以知识粒度表征属性重要度的快速增量式属性约简方法。
