一种基于机器学习的电力能耗异常检测与预测的方法
2023-12-13杨婧宋强石云辉
杨婧, 宋强, 石云辉
(贵州电网有限责任公司, 贵州, 贵阳 550000)
0 引言
电力行业在我国的经济地位中处于重要地位,而长期存在的窃电现象对国家与电力公司的经济利益有着巨大的损害,很多非法用户更改电能表的线路和结构,更换电能计量表的零件,导致电表计量异常无法准确计数,以此减少电力计量表中电力的能耗数值。这样对电能表的改造是十分危险的,易引发电力安全事故,对周边其他居民用户的生命安全造成了巨大的威胁。因此,需要通过一定的方法检测电力能耗中的异常值,使非法窃电用户无法使用恶意手段窃取电力资源。
在现有的相关研究中,文献[1]在双向长短期记忆神经网络的配电网监督下,建立了基于时序的预测模型,得到了数序数据的双向特性,在配电网电压数据中提取预测值检测电压的异常数据,但该方法所得到的预测值普遍偏高,结果准确性较差。文献[2]检测了加时窗数据,探查电力能耗异常数据,提高检测结果的准确性,设计了新的电力数据检测方法,在不同的序列时窗中使用大数据分析技术,计算电力能耗数据运行的均值,将最大似然估计作为对异常情况的检测流程。文献[3]改进了传统的k-means算法,在初始聚类中心建立一个密集度较大的紧邻半径,并将中心的数据点全部结合在实际簇的节点中,通过更好的聚类效果检测电力能耗的异常数据,并对电力能耗进行预测。但这两种方法的电力能耗异常检测准确性较差。为提高电力异常数据检测结果以及预测结果的准确性,本文设计基于机器学习的检测与预测方法,以保证结果有效。
1 电力能耗数据清洗、转换与提取
1.1 数据清洗
电力能耗数据的清洗在异常检测中是十分重要的步骤,有一些电力能耗数据由于各种原因存在较大的错误,如果不将其清理干净,会影响到后续数据异常检测结果的准确性。在清洗数据时,需要注意能耗数据中的错误、重复的数据以及逻辑不通顺的数据,将错误数据修正,将重复数据删除,统一数据的规格,修正数据中心错误的逻辑,并对数据进行压缩处理[4]。其中电力能耗数据通常是时间序列的排序方式,一旦被删除、修正、统一,就会导致数据节点出现向前或向后的位移,数据改动的越多,位移的幅度就越大。因此,若一个时间序列中需要被修正的数据超出20%,则直接删除该序列,以免因数据缺失过多导致数据准确性变差[5-6]。而需要被修正的数据少于20%时,则补全缺失值,通过补差均值、补差众数等方式,将一部分缺失的数据填充到时间序列中,此时的填充公式为
(1)
式(1)中,di表示被补充在该时间序列中的数据,da和db分别表示数据缺失部位的前端数据和后端数据,Nd表示用电数据中缺失段的时间序列[7]。补全缺失的数据后,该段时间序列的数据才可以被称为清洗结束。
1.2 数据转换
在提取电力能耗数据前,有很多数据的格式不统一,且其中一些数值较大的数据在属性方面极大地削弱了数值较小数据的影响,导致数据无法完成特征计算,因此需要将其标准化,按照一定的方式缩放[8-9]。经过一定的预处理后,数据的大小就会保持在一定的区间之内,通过计算二值化特征的方式,将数据转化成0与1的形式,以便之后的数据提取,此时可以通过式(2)计算被转换后的数据。
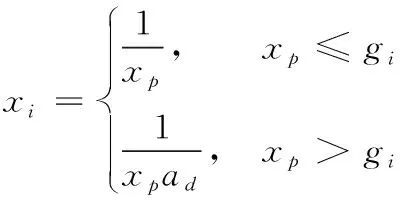
(2)
式(2)中,xi表示经过数据转换的数据形式,通常为0或1,xp表示未经过转换的电力能耗数据,ad表示用电数据中的一个随机数,gi表示原始的用电量。通过式(2)转换用电数据,并将其进行类别特征编码,尤其是一些标签项,需要直接应用于机器学习算法中,成为有序且连续的数值。当统计不同时间序列中经过转换的数据格式时,可以通过式(3)判断是否转换完全。
(3)
式(3)中,fh表示电力能耗数据的转换标准差,mp表示用户使用电量的差值,xi表示为转换前的格式,Ri表示经过转换的数据数量[10]。若fh大于0,则表示转换成功,若fh小于0,则表示转换失败。
1.3 数据提取
通过统计性的特征指标计算用户用电量的平均值,以提取时间序列中的周期数据,此时计算平均值的公式为
(4)
式(4)中,meu表示某时间序列中周期型数据的平均值,xi表示第i个电力能耗数据,np表示所提取数据的总数量[11]。得到周期性数据的平均值后,需要计算用电量的极差,公式为
(5)
式(5)中,Ran表示某时间序列中用电能耗数据的极差,xmin与xmax分别表示电力数据的最小值与最大值。最后通过计算标准差的方式,获得新的提取序列:
(6)
式(6)中,sd表示经过数据提取形成的新的序列,Nm表示序列中被提取的用户总量。ETL是将业务系统的数据经过清洗、转换、提取之后加载到数据仓库的过程,目的是将分散、零乱、标准不统一的数据整合到一起。因此,通过以上清洗、转换以及提取后,将所得到的电力能耗数据存储到ETL数据仓库中,可用于后续的电力能耗异常检测与预测。
2 基于机器学习算法设计电力能耗异常检测与预测方法
2.1 电力能耗异常检测算法
使用机器学习的方法检测状态异常的区域,需要计算电网中电表的差值:
(7)
式(7)中,ΔRt0表示t0时刻电网中电能总量与电表记录数据的差值,elvg和etlt0分别表示电力能耗的技术损失和异常损失,ei(t0)表示某用户在t0时刻的用电量[12-13]。通过式(7)计算某片区域内电网的独立状态,此时可以以此记录区域状态的转换序列,并将其作为阈值判断的准则。区域状态转换的规则如图1所示。
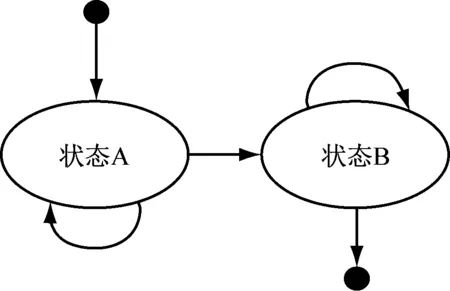
图1 区域状态转换规则
在图1中,状态A为正常状态,状态B为异常状态。在滑动窗口的集合中,将新的用电记录接收并更新,同时将新的元素添加到记录的状态机中,使之成为一个独立的个体区域[14]。此时即可计算序列中的能耗差值,将对应的阈值完全转化,变成电力能耗异常检测的个体,并得到检测结果。
2.2 电力能耗预测算法
同样使用机器学习方法,对电力能耗数据进行预测,可以使用如图2所示的算法结构。
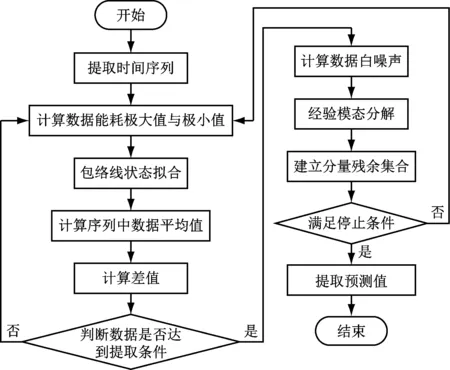
图2 算法流程
如图2所示,首先需要使用状态包络拟合以及平均值计算等方式提取状态数据,若数据达到提取条件,则可以继续计算白噪声。在分解模态经验时,需要首先计算残余分量fi(t):
(8)
式(8)中,pi(t)表示第i组噪声在经验分解过程中的分量集合,hi(t)表示同样时段内经平均处理后的残余集合[15]。分别使用以上方法,判断此时得到的数据是否能够满足终止条件,若满足条件,则需要提取电力能耗的预测值。
3 实验研究
3.1 实验环境设置与数据集训练
为验证本文方法的有效性,将其与双向长短期记忆神经网络算法、大数据分析方法、改进k-means方法进行比较。使用某居民区的用电记录作为本实验的数据集,列举智能电表所采集的实测数据,每3天计算一个相邻点,将所有用电记录分为10 000份,其中包含10%(即1000份)窃电样本,另外90%(即9000份)为正常用电记录。对10 000份样本进行分层采样,60%作为训练集,20%作为验证集,剩余的20%作为测试集。比较实验数据集中的数据,为消除数据集中的错误样本,使用归一化的方法,其计算公式为
(9)
式(9)中,fi表示将任意一个数据集中的数据归一化后所得数据,hi表示未归一化的数据,hmin和hmax分别表示样本数据集中的最小值和最大值。经过规划化后得到居民区用电能耗图,该居民区在1月(冬季)、4月(春季)、7月(夏季)、10月(秋季)的用电能耗,如图3所示。
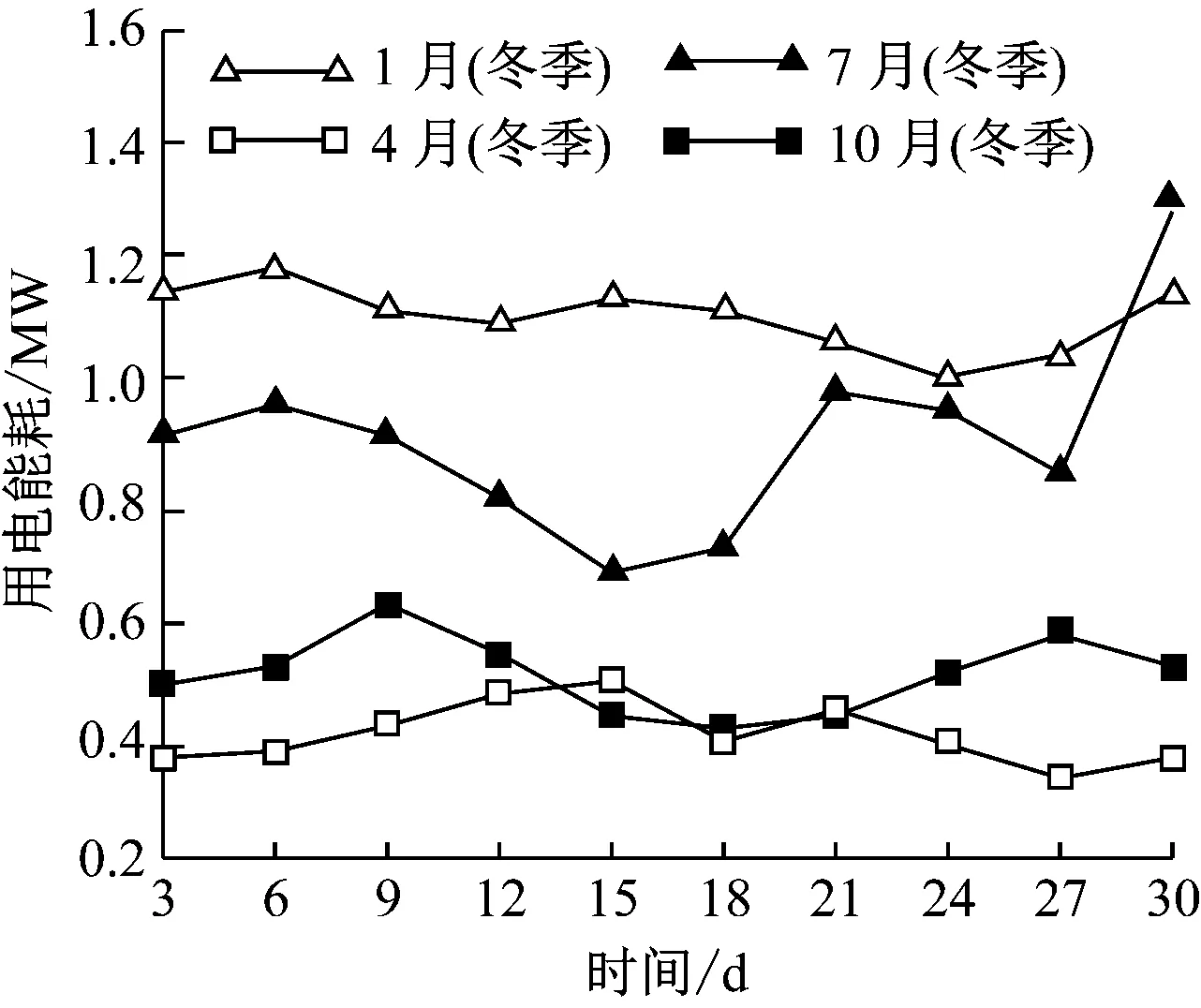
图3 居民区用电能耗
由图3可知,冬季与夏季所需要的能耗相对较高,春季与秋季的用电能耗相对较低。
3.2 电力能耗异常检测方法测试
比较4种电力能耗异常检测方法,使用工作特征曲线(ROC曲线)作为异常检测结果的评价指标,将ROC曲线下的面积量化,得到计算公式:
(10)
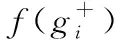
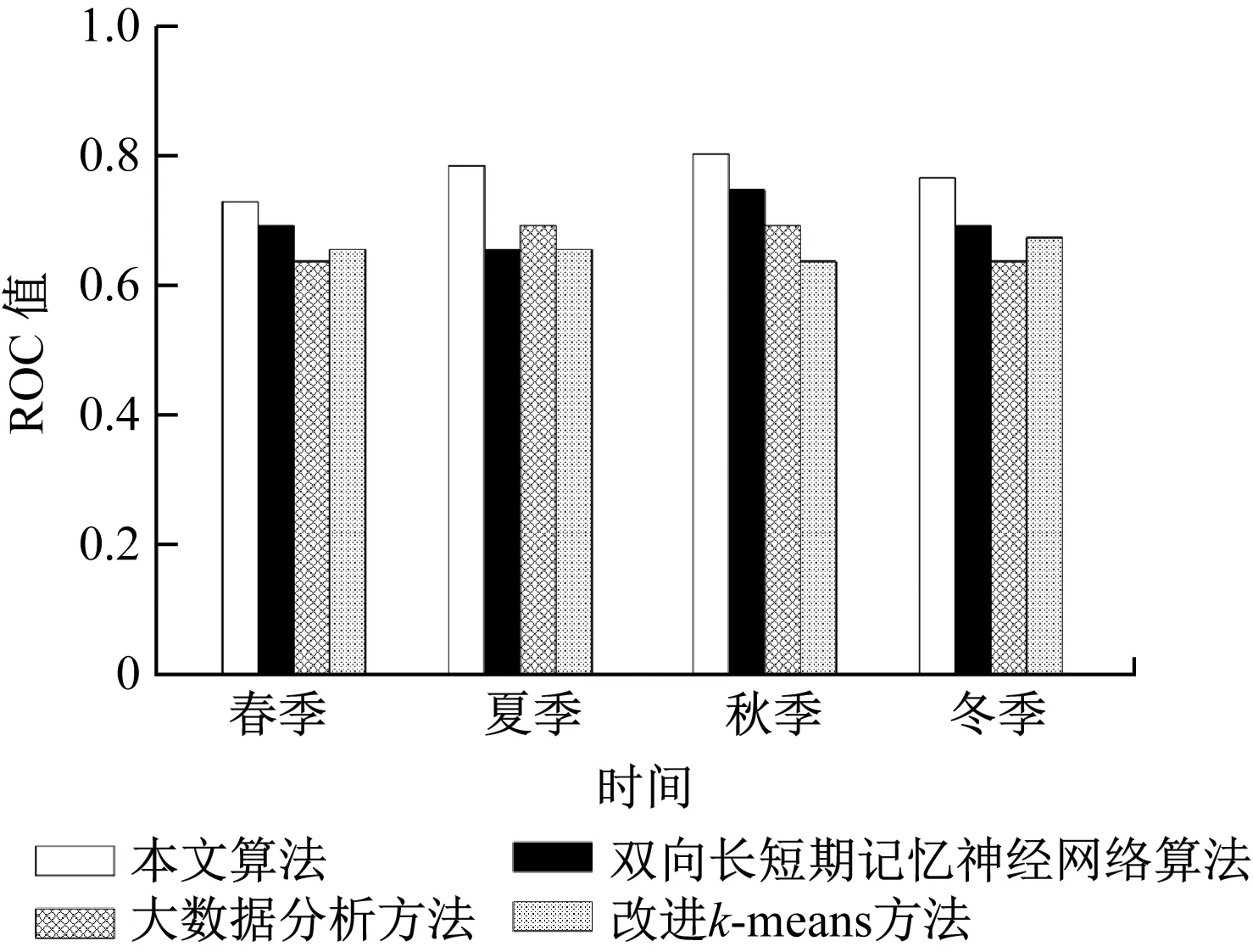
图4 电力能耗异常值检测方法比较
如图4所示,4种电力在春季的ROC值分别为0.74、0.70、0.64、0.66,其中本文算法的结果最接近1.0,表明本文方法检测结果最好。在夏季、秋季与冬季的电力能耗异常值检测中,本文算法的ROC值仍然大于其他3种方法。通过以上数据可知,本文设计的机器学习方法较其他几种方法的检测效果更好。
3.3 电力能耗预测
为测试机器学习方法在电力预测中的有效性与优越性,选取某居民区的用电记录作为实验的数据集,采用滑动窗口提取与分解数据,并区分低频的趋势分量。将时间展开的数量设置为50,输出向量神经元数量设置为80,分别设置3个网络层,每一批次的预测样本数量为50,学习率为0.01,算法运行后,得到如图5所示的居民区电力能耗预测结果。
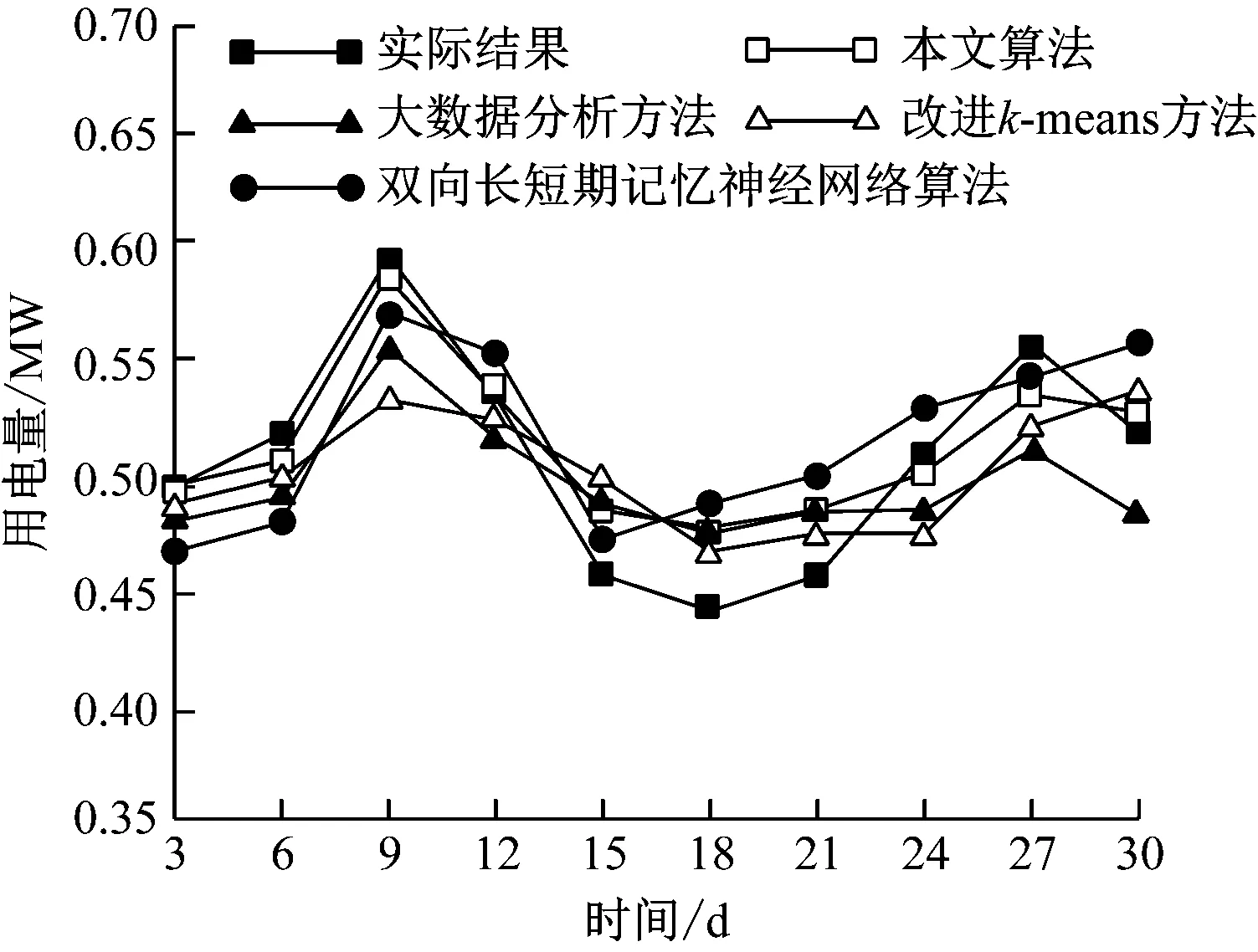
图5 居民区电力能耗预测
由图5可知,4种预测方法对电力的预测结果与实际数据存在一定的差距,使用RMSE以及MAE计算预测值与实际值之间的误差,计算公式为
(11)
(12)
式(11)、式(12)中,RMSEi与MAEi分别表示第i种预测方法与实际数据之间的误差指标,其数值越小表明误差值越小,ni表示电力数据的样本数量,gk与hk分别表示第k个测试样本的实际值与预测值。基于式(11)、式(12),计算4种算法的预测误差,如表1所示。

表1 不同算法预测误差
由表1可知,无论是RMSE的误差指标,还是MAE误差,本文算法所得数值均为4种算法的最小值,可见该方法在预测电力能耗时所得误差最小。
4 总结
本文基于机器学习设计了一种电力能耗异常检测以及预测的方法,将最初始的数据经过数据清洗、转换,并以时间序列提取有用数据,以此减少电力能耗异常检测以及预测的误差,然后设计相应的检测和预测算法。在实验中,本文方法的ROC值以及RMSE与MAE误差指标均小于其他算法,可见该方法优于其他方法。但是,在进行电力能耗异常检测以及预测时,没有考虑预测时间的问题,致使预测效率较低,为此在接下来的研究中将改进本文算法,缩短运算时间,旨在提升电力能耗异常检测以及预测效率。
