基于混合模型的电力用户信用评估研究
2023-12-13王岩陈孝文许家伟
王岩, 陈孝文, 许家伟
(海南电网有限责任公司信息通信分公司, 海南, 海口 570203)
0 引言
社会信用体系[1]已在各行各业全面展开,尤其是在金融、通信、电子商务等领域已有广泛的应用基础[2-4]。为此,可将信用评估体系引入电力系统,采用不同的信用评估模型,以在一定程度上遏制用户窃电、欠费等行为。目前,大量研究提出了许多不同的信用评估模型。根据模型类型不同,常用信用评估模型[5-6]主要分为两类:统计方法和人工智能方法。统计方法实现简单,可移植性强,然而计算精度有限。
为此,本文提出了一种基于混合模型的电力用户信用评估方案。首先,在低计算和操作成本下,使用改进的自适应弹性网络模型,可从诸多的电力信用数据中取得了一些关键特征,让分类结果变得更加准确。其次,基于自适应孤立森林方法构建噪声增强数据集,从而增强模型对噪声数据的鲁棒性,同时,该方法也可缓解模型过度拟合的问题。最终,我们决定使用双层集成模型来对ELM模型分类器进行改进,通过增加分类器之间的差异性让训练效果和性能等得以提升。
1 混合信用评估模型
1.1 特征选取
令电力用户历史信用评分数据表示为(xi,yi),i=1,2,…,N,xi是一个由xi1,xi2,…,xip组成的列表,用于描述电力客户的信息。yi为类别标签。因此,回归模型可构建如下:
(1)

(2)
由式(2)可以看出,较大的λ使βj中的一些系数缩减至零,即Lasso模型[7]将系数逐渐减小到零,而λ逐渐增大。此外,考虑到Lasso模型能够容纳任意数量的变量,因此可以同时进行系数的缩减和特征(变量)的选取。
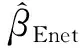
(3)
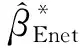
(4)
(5)
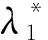
依照以上的计算结果,可挑选出更关键的特征。接下来,本文将这些重要特征组合出了一些特征向量,并输入到且电力用户信用评分模型中,以确保在成本不高的前提下,让分类结果变得更加准确。
1.2 噪声数据处理
解决数据集中的噪声问题是对分类或回归准确度造成重要影响的一个巨大挑战[8]。一般而言,电力用户的信用数据可能会受到两种干扰的影响:类别噪声和属性噪声。前者指代数据被错误分类的情况,而属性噪声指代数据中有错误的属性数值。
考虑到在实际情况下,对比数据空间中密集区域的数据,在数据稀疏分布区域的数据点出现的可能性不是很高,所以可把其作为是异常值。为了对这些噪声数据进行检测,文章提出了一种自适应孤立森林噪声方法(AIFNM)。首先,此方法使用异常程度对离群值的分数进行计算,以便于对数据中的噪声进行检测。然后,把这些噪声数据逐步加入到训练集中,然后建立了一个适应噪声的自适应训练集。对比原始数据集,噪声自适应训练集中涵盖了相对较多的噪声数据。这样做不只是可以让模型对噪声数据的适应性变得更强,也在一定程度上减少过拟合现象。
AIFNM执行过程如图1所示。令训练集大小为算法应用于大小为N。首先,通过计算每个数据点的离群值得分来确定分离数据点。其次,找到有着较高异常值得分的数据点,然后创建出能适应噪声的训练样本,以便于让训练集的效果得以强化。

图1 AIFNM执行过程
1.3 极限学习机分类模型
极限学习机(ELM)模型,本质上就是一种单隐层前馈神经网络(SLFN)。对比其他模型,ELM模型的独特之处在于它使用随机选择的输入权重和隐含偏差,且避免了要进行调整的步骤[9]。同时,隐含层输出矩阵的穆尔-彭罗斯广义逆矩阵可用于分析和确定输出权重。ELM模型具有良好的泛化性能,可有效减少训练过程的迭代时间。
对于任意电力用户历史信用数据(xi,yi),输入向量xi=(xi1,xi2,…,xip)T∈Rp为具有p维特征的第i个样本,输出Y=[y1,y2,…,yN]。其中,输入神经元p个,用来对输入特征的数量进行描述。同时还有隐藏神经元L个、输出神经元C个,用来对输出类别的数量进行描述。同样地,存在一个称为权重矩阵K的输入矩阵。其中每个kj向量由p个输入神经元与第j个隐藏神经元的连接组成。以b=[b1,b2,…,bj,…,kL]来描述隐藏神经元的偏差,其中bj为第j个隐藏神经元的偏差,ELM的输出可在下式中来计算:
h(xi)=G(Kxi+b)
(6)
式中,G()为激活函数。令H为所有样本的输出,则H可计算如下:
(7)
ELM的输出可以通过以下计算获得,其中隐藏节点i的输出向量表示为第i列,输入xj的隐藏层输出向量表示为第j行:
(8)
式中,αi=[αi1,αi2,…,αiC]T为连接第i个隐藏节点与输出节点的权重向量。
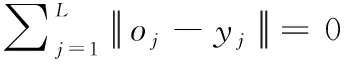
(9)
将式(9)转化为线性方程,则可得式(10):
Hα=Y
(10)
根据式(10),可以使用最小二乘法估计输出权重值,具体计算如下:
(11)
式中,H+为矩阵H的穆尔-彭罗斯广义逆矩阵。对于电力用户信用评分分类,ELM的输出计算如下:
(12)
1.4 集成模型
当对ELM模型输出的多组分类器进行组合优化时,当一个分类器明显表现和其他分类器有所不同的时候,传统的投票或堆叠方法有可能会对整个模型产生一些负面效应[10]。所以,在本节中,笔者提出了一种改进的双层集成模型,旨在对ELM模型分类器组合的效果作出改进,以便于对“坏值”分类器带来的不良影响作出改善。
根据图2,双层集成模型由2个组件而构成。第一层组件采用ELM模型作为分类器,其输出包括(Cf1、Cf2、…、CfM)作为分类结果。首先,训练3个分类器的时候,我们可以选择按照以下顺序使用投票或堆叠分类器的方法。这些训练过程是:
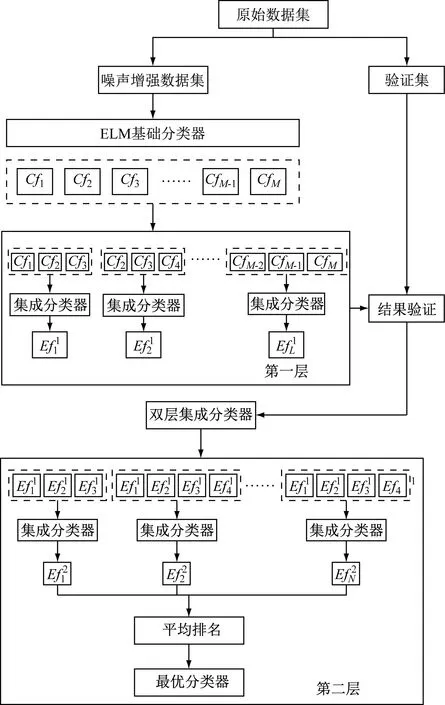
图2 双层集成模型结构图
(16)
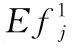
在第二层中,使用投票或堆叠分类器的方法进行训练。本文依次把4个第一层的集成分类器的输出结果输入到第二层,然后把其进行合并。具体而言,可以把合并后的结果当作其中的输入,用于完成一个新的集成分类器的训练如下:
(17)
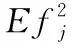
最后,本文对多个评估指标做出计算,得出每个分类器的平均排名,且在测试集上评估排名最高的集成模型,以保证分类效果最好。
2 仿真与分析
2.1 数据集
研究所用数据集为中国某电力公司提供的电网内部基础数据,包括不同公司的用电基本属性信息、用电业务行为信息、缴费方式信息、用电消费信息、用电可靠性信息、负荷特征信息、欠费信息、违章用电信息等共计13 472个样本数据。数据集中的公司包含外贸、制造业、电信、信息技术、能源、农业、房地产、制药等8类共计59个公司,每个公司包含15个特征属性。
首先,通过针对这些数据集进行数据清洗和预处理,我们成功排除了样本中有错误数据(缺失值超过80%)的样本。因此,最终的数据集包括了9843个正常用电样本和623个异常用电样本。其次,通过使用自适应弹性网络回归模型,我们可确定出在众多特征中有着很重要的特征。同时,将这些重要特征组成特征向量并带入电力用户信用评分模型,从而保证低计算和操作成本前提下,获取更为精确的分类结果。经过特征提取后,数据集维度空间为8,其中包含4个连续属性(用电消费信息、负荷特征信息、欠费信息、违章用电信息),4个离散属性(电基本属性信息、用电业务行为信息、缴费方式信息、用电可靠性信息)。可以看出,该数据集具有多维度、样本不均衡(异常用电与正常用电比例约为1∶15.8)等特点。
此外,为保护用电客户的隐私信息,将数据集中所有包含公司属性相关的名称去除。进一步,将数据集按8∶1∶1划分为训练集、测试集和验证集。
2.2 实验过程
首先,借助基于孤立森林的噪声自适应模型,可以创建一个训练集,其中包含了被用来处理噪声数据的样本,可以提高模型对这些数据的适应能力,从而在一定程度上把过拟合能力有所减少。其次,为了应对数据不均衡问题,本文提出了一种解决方案。首先,本文运用了ELM分类器针对这些数据开展分类,且确定了其中最佳的分类器数量。接着,本文通过一些训练集针对上述分类器来完成相关的训练。为了提升实验结果的稳定性,并减少偶然性的影响,本文重复了每组实验30次,且计算了这些实验结果的平均值,以便于对模型的性能进行评估。
实验时选取准确率、Brier分数和曲线下面积(AUC)作为指标验证不同算法性能。同时,我们在这里选择了决策树(DT)、动态贝叶斯网络(DBN)和极限学习机(ELM)等模型,以及对比了混合模型。
2.3 性能与分析
2.3.1 特征提取对比分析
依照表1的数据,应用自适应弹性网络(AEN)特征提取方法,各个模型中的诸多性能得以改善。提取特征以后,DT模型的准确率直接提高了0.004,SVM模型提高了0.006,RF模型提高了0.013,DBN模型提高了0.006,ELM模型提高了0.003。因此,应用AEN对分类器的分类结果有很大的帮助。根据相关的分析结果来看,AEN能有效消除冗余和不相关的变量,让模型训练的效率有所提升,而且对训练结果作出改善。
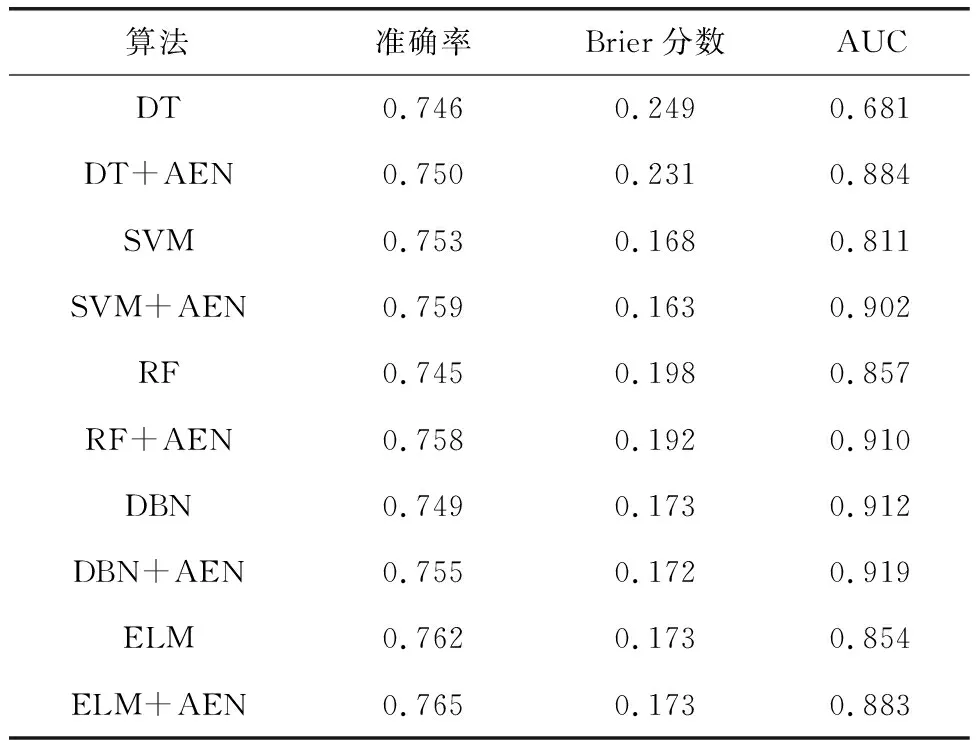
表1 特征提取前后不同模型性能
2.3.2 噪声数据对比分析
在使用自适应孤立森林噪声方法(AIFNM)之前和之后,不同模型性能的统计结果如表2所示。由表2可知,经自适应噪声增强后,除RF模型准确率降低0.013之外,其余DT、SVM、DBN和ELM模型准确率分别提升0.003、0.002、0.002和0.007。因为数据集严重不平衡,导致随机森林在提取有效信息和识别正样本方面的表现相对较弱,模型性能没有明显的改善。所以,可以得出结论AIFNM方法有助于提高分类模型的性能并减少其随机性。
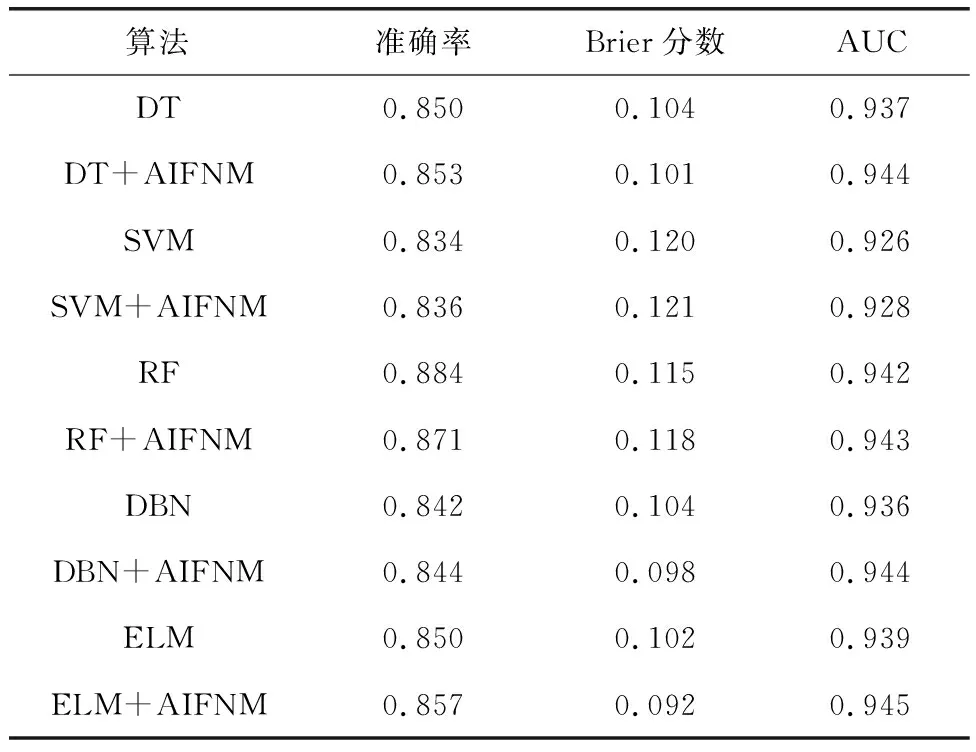
表2 噪声数据处理前后不同模型性能
2.3.3 最终性能
表3是所提方法应用特征提取、噪声增强数据集后,在集成模型中最终的训练结果。其中平均排名为第二层输出的所有分类器进行平均排名统计后的结果(30次实验中将第二层输出分类器平均排名按从小至大统计)。可以看出,对比表1和表2中的基础分类器,双层集成分类器表现出明显的优势,其性能指标相对而言较为突出。最佳分类器的准确率大约可以达到88.1%。此外,模型的平均排名越高,性能越优,集成分类器的泛化性和鲁棒性越好。
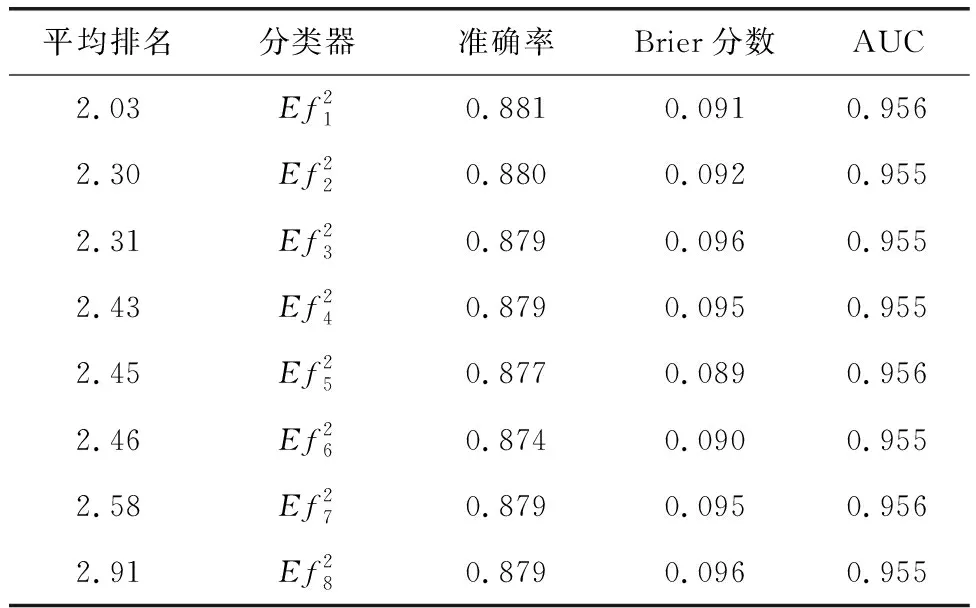
表3 所提模型最终性能
3 总结
本文基于电网内部基础数据提出了基于混合模型的电力用户信用评估模型。首先,基于改进的自适应弹性网络模型从大量电力信用数据中提取重要特征。其次,基于自适应孤立森林方法构建噪声增强数据集,从而增强模型对噪声数据的鲁棒性。为了解决“不良”分类器对ELM模型分类器而带来的不利影响,本文最终采用了双层集成模型。通过该研究,提出了一种新的方法来对电网电力营销风险进行分析,以改善电力风险管理和对营销服务情况作出改善。
今后的研究,将会主要关注保护电力用户隐私和增强配电网网络安全,以进一步提升配电网数据的安全性和服务管理能力。
