改进CNN在TBM变速箱磨损状态识别中的应用
2023-12-13顾伟红毛梦薇
顾伟红, 毛梦薇
(兰州交通大学土木工程学院, 甘肃 兰州 730070)
0 引言
近年来,我国地下交通工程取得了巨大进展,全断面硬岩隧道掘进机(TBM)开挖工法由于其安全高效的优点得到了广泛应用。但是TBM的施工环境恶劣且复杂多变,在掘进过程中常受到频繁的冲击和振动,设备零部件难免会逐渐劣化,从而埋下安全隐患,同时TBM系统结构较为复杂,各部件之间相互关联,无论哪个部位出现问题都会对TBM的正常运行造成影响。变速箱作为TBM的核心部件之一,主要由齿轮、轴承、轴和箱体等部件组成,是复杂的行星齿轮结构,由于在运行过程中长期承受来自TBM和外界的强转矩作用,致使其故障率极高,而故障发生早期通常以磨损形式出现,大多数设备的失效也是由磨损引起的。因此,监控变速箱的磨损状态可以在故障发生早期做出判断,及时处理并制定维护保养策略,防止其带“病”作业而造成更大的损失,对维持TBM安全稳定运行具有重要意义。
目前已有很多国内外学者对TBM重要部件的状态监测进行了研究: Sutherland[1]通过比较计算电机处的电压与隧道中的测量电压,对TBM电机的性能做出诊断; Simoes等[2]运用模糊逻辑理论建立了TBM利用率预测模型; Alvarez等[3]阐述了依托神经模糊方法对TBM性能建模的研究结果; 左庆林[4]通过分析盾构关键设备的故障机制和状态检测方法,开放了故障诊断系统; Yagiz等[5]通过构建非线性多变量预测模型,对盾构性能做出评估; 陈文远等[6]通过融合盾构各监测技术,基于互联网开发了信息管理系统; 乔世范等[7]在推导出掘进参数与刀具磨损关系的基础上,提出了一种小波包分解掘进参数信号的盾构刀具磨损识别方法; 刘尧等[8]结合机器学习和盾构掘进参数,基于关联规则数据挖掘对刀盘的健康状态做出评估; 李宏波等[9]基于声发射和改进灰关联度分析的方法对TBM滚刀的磨损状态做出评估; 夏燕冰等[10]介绍了油液监测技术的原理和程序,并将其应用于TBM刀盘主轴承、主变速箱和主液压油箱。
通过对上述文献的学习发现,国外对于TBM状态监测的研究集中于掘进机运行性能评价、模型适用性等方面,国外公司主要通过在关键设备上装置各种传感器,通过传感器参数的变化来发现故障; 国内对于TBM状态监测的研究大多为介绍各种监测技术在施工中的应用,以及开发相关信息管理系统。实际施工中会采用各种监测技术对TBM零部件的运行状态进行监测,并记录相关数据,但缺乏对记录数据的分析。振动和油液监测是机械故障诊断的常用方法,但振动监测多用于识别表面损伤类故障,对早期磨损故障敏感性较差,而油液监测对磨损故障更为敏感,识别率更高。光谱分析是油液监测的一种方法,它可以检测出润滑油中元素的种类和质量分数,从而判断机械设备的磨损状态,施工中常用三线值法对油液光谱数据进行分析(三线值法是对历次变速箱油样光谱分析数据进行线性分析,确定3条控制线,根据数据曲线的走势判断变速箱当前的磨损状态),但这种方法需要结合历次数据进行分析,存在数据量大、计算困难的问题,并且该方法对工程经验的依赖性较强,需要人为选择所用历次数据的组数,不同选择确定的3条线也不同,大大增加了人为因素对结果的影响,可能会存在误诊和漏诊的情况,给正常施工带来损失。
近年来,深度学习在学术界引发了研究热潮,相较于浅层网络,深层网络可以自适应地提取数据中的深层特征。其中,卷积神经网络(CNN)是一种经典的深度学习网络模型,由于其稀疏连接和权值共享的特点,在提取数据特征时具有很大优势[11]。并且也有学者将卷积神经网络应用于解决小样本问题,如钟建华等[12]基于小样本数据,使用一维卷积神经网络对齿轮箱进行故障诊断; 林年添等[13]使用卷积神经网络深度学习方法,用于在小样本条件下智能提取、分类并识别地震油气特征。基于此,本文提出使用改进的卷积神经网络对TBM变速箱进行磨损状态识别(wear state recognition based on improved convolution neural network,WSRCNN),并结合工程实际数据验证模型识别性能,通过模型对比分析证明本研究所提出方法的有效性,以期为实际施工中TBM变速箱的安全稳定运行提供可靠保障。
1 卷积神经网络结构
卷积神经网络是一种深度前馈神经网络,本质是多层感知机,包括前向提取拓扑和后向传播优化2部分,最早是在1998年针对手写数字分类问题提出的,在处理图像问题时具有很大优势[14-15]。因此,最初的卷积神经网络只能解决二维图像问题。后来由于输入数据的类型不同,专家学者对网络模型结构做了改动,可用于处理一维数据、图像和视频,虽然应用的领域不同,但结构和原理相同。
1.1 卷积层
卷积层的作用是提取数据特征,其中最重要的就是卷积核。卷积结构中一般包括多个卷积核,在训练前预设好卷积核的步长和边长,通过多次迭代不断更新各自的权值。使用卷积核在输入特征上按步长移动做卷积运算,遍历后输出提取到的特征图[16-17]。具体的卷积运算公式为:
(1)
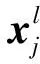
1.2 激活函数
激活函数用于对卷积运算的结果做非线性处理,可以帮助模型学习数据中复杂的模式。本文选用ReLU函数,因为其运算量低,且比sigmoid函数和tanh函数更能加快梯度下降和网络模型训练的速度[18],具体的计算公式为:
yl=f(xl)=max{0,xl}。
(2)
式中:xl为卷积运算后得到的特征图;yl为xl经ReLU函数激活后得到的输出值。
1.3 池化层
池化层的作用是通过压缩卷积层的输出提取关键特征,从而简化模型结构,避免过拟合现象的发生。最大池化和平均池化是最常用的2种池化方式,最大池化是将计算区域中的最大值作为池化后的值,平均池化是将计算区域中的平均值作为池化后的值,本文选用最大池化方式[19-20]。最大池化和平均池化的计算公式分别如式(3)和式(4)所示。
(3)
(4)
1.4 全连接层和输出层
卷积层和池化层交替后进入全连接层,其作用是将提取到的多维特征展开平铺为一维向量,并进一步提取特征后传给输出层,输出层使用Softmax分类器完成分类任务。计算公式分别如式(5)和式(6)所示。
(5)
(6)
2 变速箱磨损识别机制
变速箱是TBM主驱动中负责变速以及传递力和力矩的重要部件,且在运行过程中易发生磨损,而油液检测对磨损类故障的识别率较高[21]。因此,本文使用油液检测对变速箱的磨损状态做出判断。
2.1 磨损的定义
磨损是指机械设备运行时,相互接触的零部件发生相对运动,接触表面在交变接触应变力的作用下产生零件表面材料损失。当变速箱处于超载荷工作时,因加工装配不当、人为操作不当等原因造成的杂质异物侵入都会导致磨损,产生的磨损产物也会参与磨损; 当磨损发展至严重状态时,会使得变速箱故障失效停止工作。
2.2 油液检测
根据磨损的定义可知,磨损会造成零件表面损失,产生的磨损产物都会随机器运转进入到油液中,因此对油液的检测可以获得许多关于设备磨损的信息。
油液检测包括润滑油分析和磨损颗粒分析2部分[22]。其中,润滑油分析是指分析油液的理化性能指标,用于判断对象的润滑状态; 磨损颗粒分析是指分析油液中磨粒大小、形状、质量分数等参数,用于判断对象的磨损状态,包括铁谱分析和光谱分析。分析润滑油中的磨粒可以在不拆机的情况下对TBM变速箱磨损状态做出判断,本文使用光谱分析的结果作为磨损识别依据。
2.3 光谱分析
2.3.1 光谱分析原理
光谱分析技术主要有红外光谱和发射光谱2种,其中发射光谱分析常被用于机械设备的状态监测。光谱分析能快速准确地检测到油液中21种金属、非金属元素质量分数。根据变速箱的材料化学成分,本文选取了Fe、Al、Cr、Ni、Si、Cu、Ti、Zn、Ba 9种元素,以变速箱润滑油光谱分析结果中这9种元素的质量分数为指标,识别出变速箱的磨损状态。
2.3.2 光谱三线值法
实际TBM施工过程中会定期采集油样做光谱检测,通常采用三线值法对检测结果进行分析。三线指的是正常线、警告线和危险线3条控制线,由于油液中的磨粒元素质量分数随机械设备运行而不断增加,因此3条控制线也以一定的斜率呈现: 正常线V1=0.8(P+2S),警告线V2=P+2S,危险线V3=P+3S,其中,P为基准值,P=a+bx;S为标准差。基线通过线性回归法对样本点进行拟合确定,计算公式如式(7)—(9)所示。
(7)
(8)
(9)
式(7)—(9)中: (Xi,Yi)为设备测得的元素质量分数值经过变换得到的回归系数;a、b为最小二乘法求得的拟合系数。
建立的控制线如图1所示。
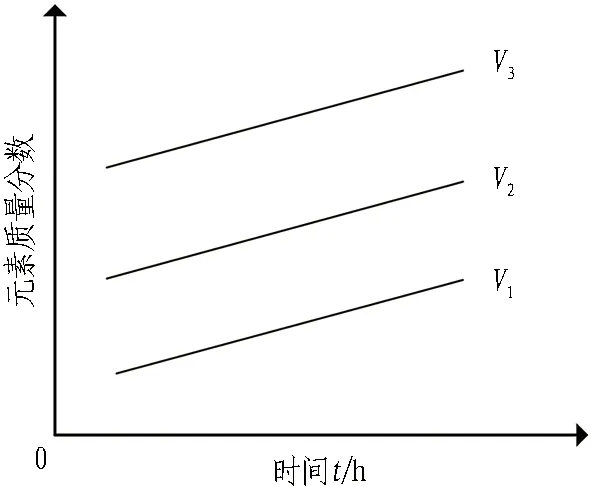
图1 光谱分析三线值法
使用光谱三线值法的判别标准如下:
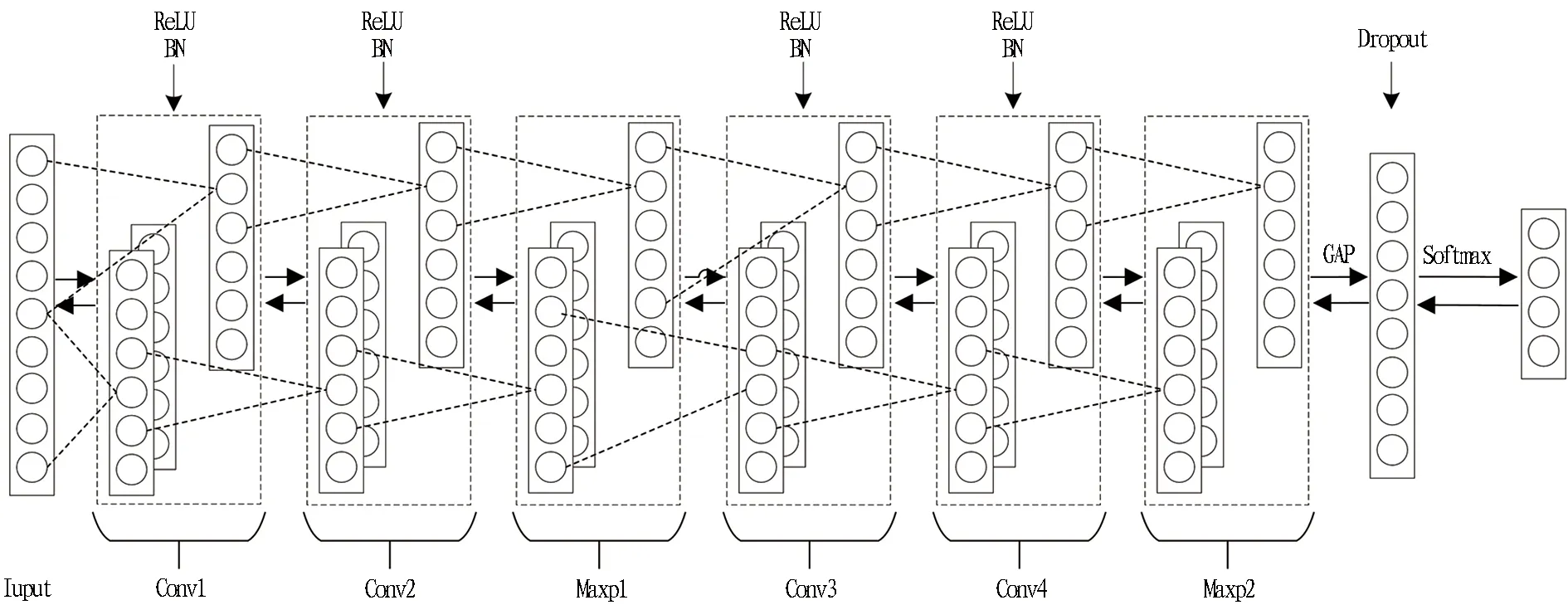
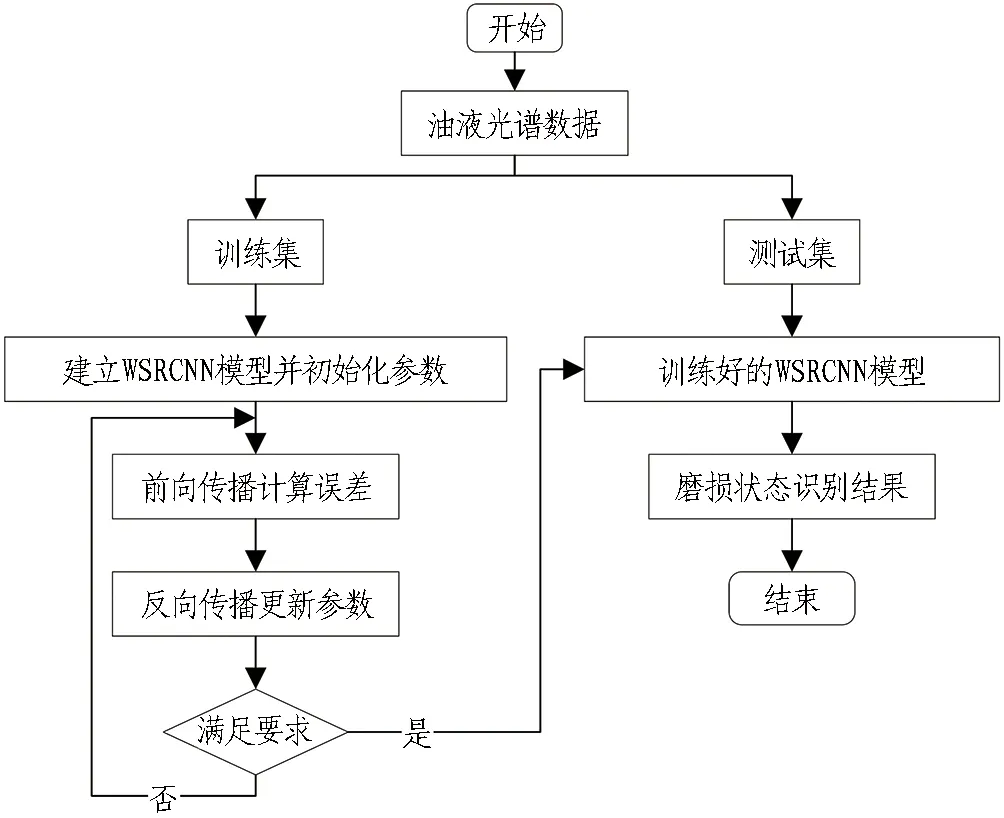
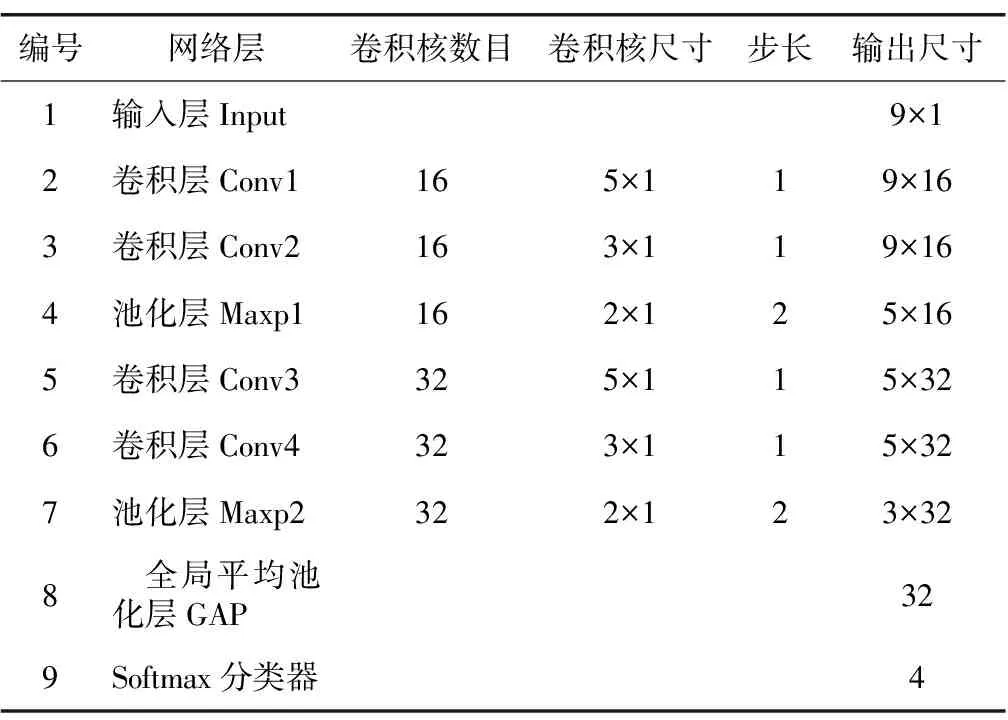
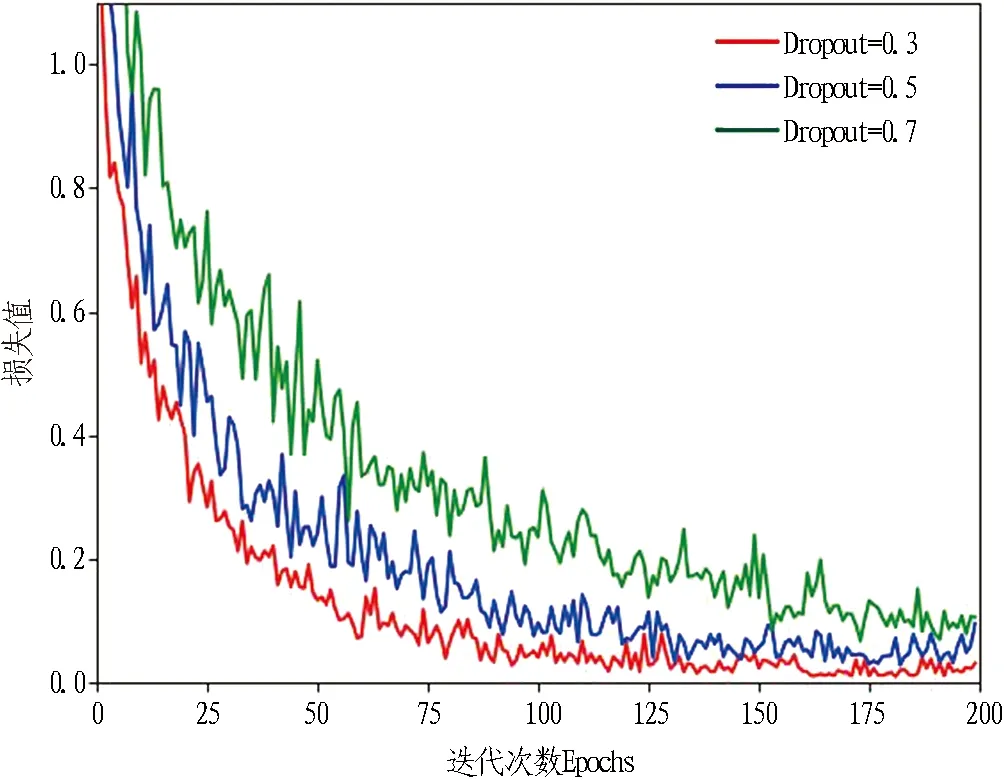
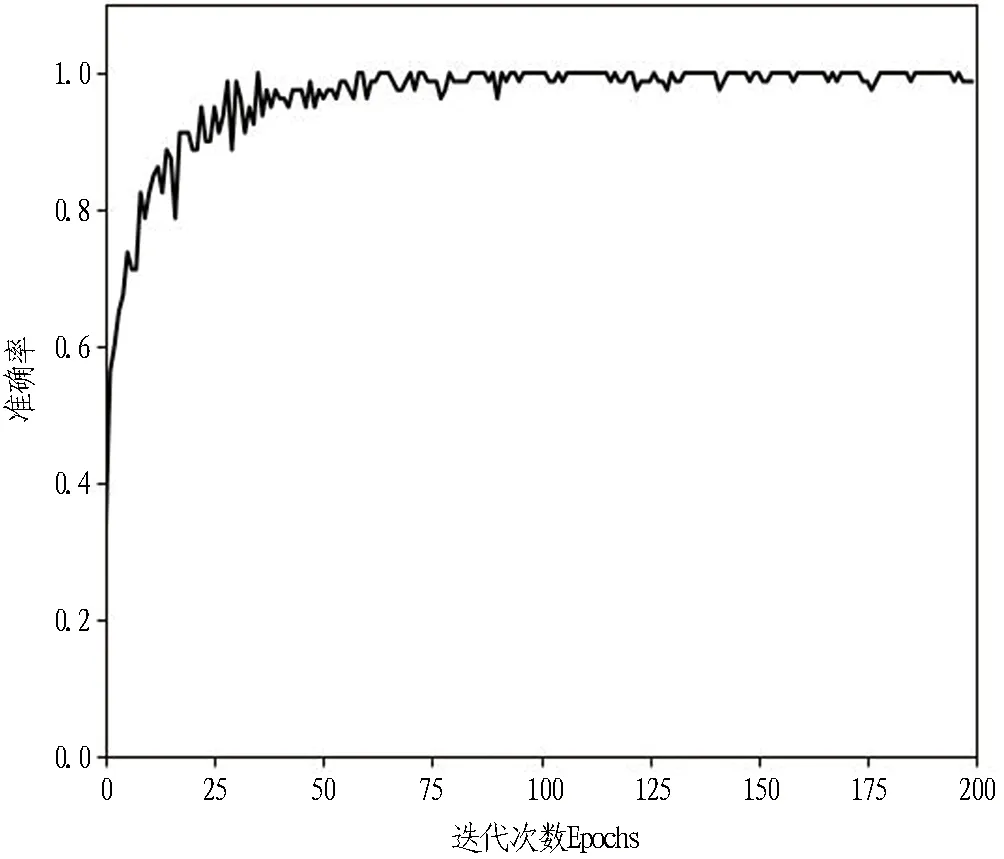
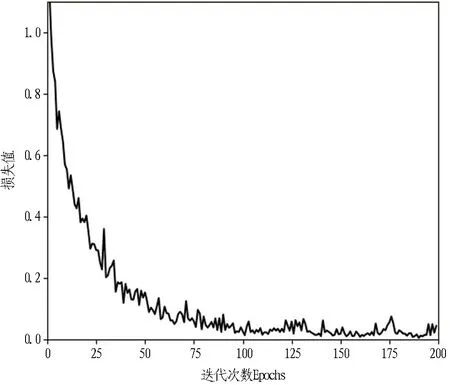
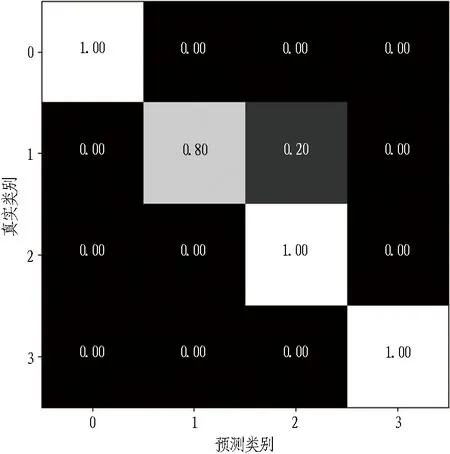
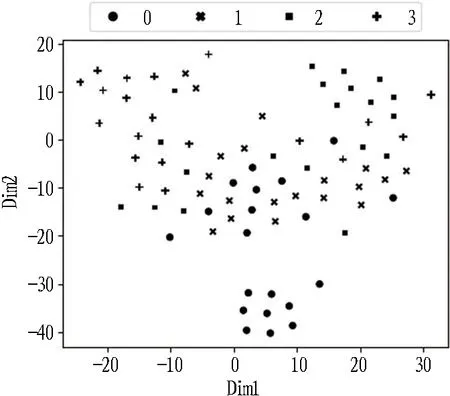
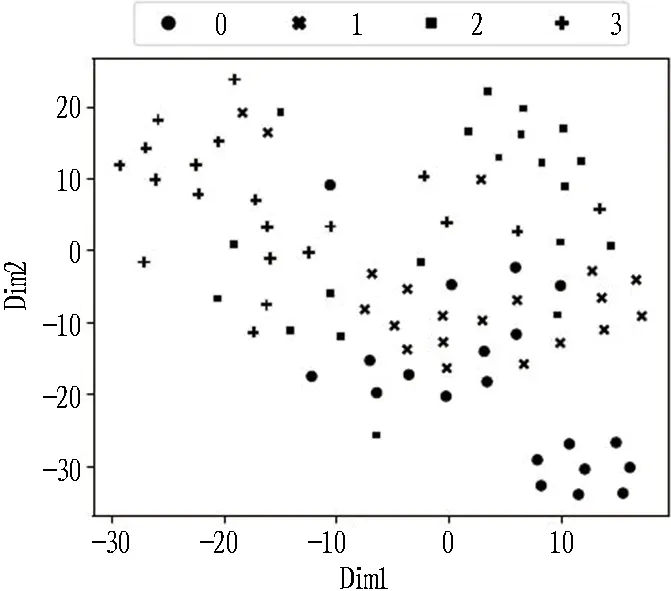
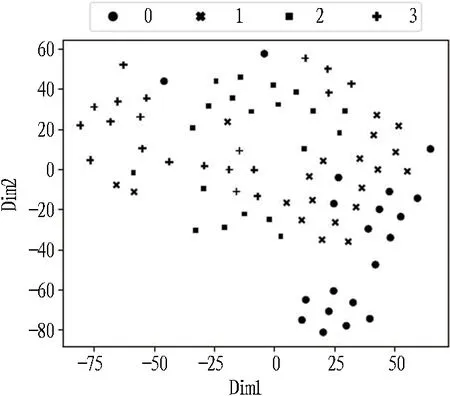
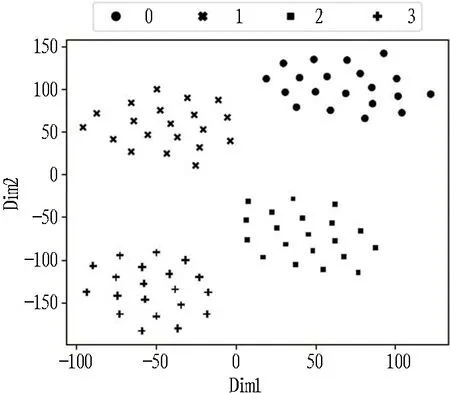
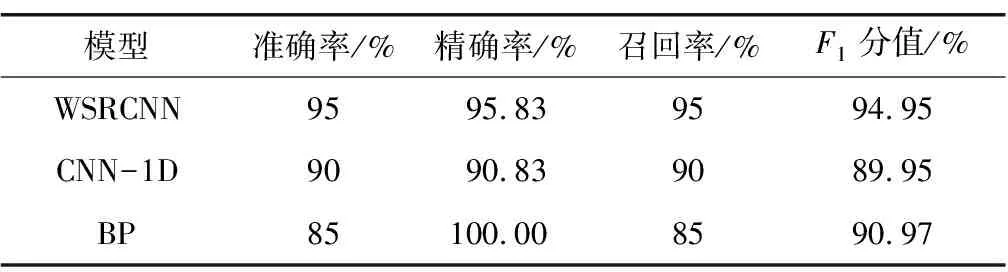
1)当本次检测的特征参量P 2)当V1 3)当V2 4)当P>V3时,说明设备磨损已属于危险范围,此时油液中磨粒的质量分数很大,设备磨损严重将导致故障失效无法运转。 使用三线值法可以对变速箱的磨损状态做出判断,但使用这种方法主要结合历次所有光谱分析数据,所需的数据和计算量比较大,而且一定程度上会受到人为因素的影响。因此,本文选用可以自适应提取数据特征的卷积神经网络,该方法可以更加准确地对TBM变速箱磨损状态做出识别。根据元素质量分数的大小,将TBM变速箱的磨损状态分为正常、轻度磨损、异常磨损和严重磨损。 本文以变速箱油液光谱分析的9种元素的质量分数值作为模型输入,因此选用一维卷积神经网络,并通过对传统网络模型作出调整,提出了基于改进卷积神经网络的TBM变速箱磨损状态识别模型(WSRCNN),最终构建的模型如图2所示。其中包含4个卷积层(Conv)、2个池化层(Maxp)和1个全局平均池化层(GAP)。通过卷积层和池化层交替提取光谱数据特征,使用全局平均池化层对输入的多维特征进行整合,并结合Dropout正则化随机丢弃神经元,最后通过Softmax分类器输出磨损状态类别。 WSRCNN模型对传统的卷积神经网络做的改进为: 使用2个卷积层叠加代替传统模型中的1个卷积层,可以更深层地提取数据特征; 并且使用2个不同尺寸的卷积核,可以学习不同级别的数据特征。 为优化模型性能,避免过拟合现象的发生,使用全局平均池化层代替全连接层,并引入Dropout正则化和批量归一化,减少模型参数。 图2 改进CNN模型结构 使用WSRCNN模型识别TBM变速箱磨损状态的流程包括4个部分: 数据准备、模型搭建、模型训练、模型预测。具体步骤如下: 1)将采集到的TBM变速箱油液光谱数据划分为训练集和测试集,并进行归一化处理。 2)构建WSRCNN模型并初始化相关参数。 3)将训练样本数据批量输入到构建好的WSRCNN模型中,逐层向前传播提取数据特征,使用Softmax分类器输出磨损状态类别,并计算目标输出与实际输出的偏差。 4)误差反向传播,更新模型参数。 5)重复步骤3)、4),不断调整模型参数,当误差收敛至满足要求或达到最大迭代次数时,即完成模型的训练。 6)将测试集数据输入训练好的WSRCNN模型,进行TBM变速箱磨损状态识别。 具体的识别流程如图3所示。 图3 磨损状态识别流程图 为验证模型识别性能,就要引入一些评价指标进行衡量。对于多分类模型的评价指标通常有4种。 3.3.1 准确率 准确率是指被正确分类的样本数(ncorrect)与总样本数(ntotal)的比值。计算公式为: (10) 3.3.2 精确率 精确率是指分类正确的正样本个数(TP)占分类器判定为正样本的样本个数(TP+FP)的比例。计算公式为: (11) 3.3.3 召回率 召回率是指分类正确的正样本个数(TP)占真正的正样本个数(TP+FN)的比例。计算公式为: (12) 3.3.4F1分值 F1分值是指精确率和召回率的调和平均值。计算公式为: (13) 本文获取的TBM变速箱油液光谱数据主要来自于引汉济渭工程秦岭输水隧洞。秦岭输水隧洞的主要任务是将从汉江流域调出的水自流至渭河流域关中地区,全长81.79 km,隧洞主要采用TBM工法,开挖断面为圆形。 4.2.1 数据采集 本文使用工程实际采集的TBM变速箱油液的光谱分析数据为依据识别变速箱的磨损状态,但现场TBM变速箱润滑油的取样送检间隔通常为1次/月,因此样本量较少。TBM变速箱的磨损状态分为正常、轻度磨损、异常磨损和严重磨损4种,采集到4种磨损状态的油液光谱数据共100组,按类别对各组数据贴标签,具体的类别标签信息和样本分布如表1所示,并按8∶2的比例将数据集划分为训练集和测试集。 4.2.2 数据预处理 TBM变速箱油液光谱数据的各元素质量分数值变化量较大,还有可能存在奇异数据,这会使得模型计算的复杂程度较高且训练时间长。为了提高模型识别性能,先对奇异数据进行剔除,然后对样本数据进行归一化处理后再输入模型,使得数据处于0~1范围。对数据进行预处理后,可以减少梯度下降求最优解的时间,提高模型识别的准确度。具体的归一化公式为: (14) 式中:Xn为归一化处理后的数据值;Xmax和Xmin分别为某一指标样本数据中的最大值和最小值;X为原始数据值。 卷积神经网络模型中有许多参数,参数的选取对模型识别准确率有很大影响。因此,在构建WSRCNN模型过程中,需要对一些影响模型性能的参数进行选取。通过多次对比试验,最终构建的WSRCNN模型参数如表2所示。变速箱的磨损状态是根据选取的9种元素的光谱数据判断的,因此,输入层尺寸为9×1,2层卷积层的卷积核尺寸为5×1和3×1。Softmax分类器的神经元数即为变速箱的磨损状态类别数,设置为4。模型中采用交叉熵损失函数计算目标输出与实际输出之间的误差,优化器选用Adam调整模型参数,批处理量为20,学习率设置为0.001,最大迭代次数为200。损失值使用交叉熵损失函数进行计算,计算公式为: (15) 式中:L为损失值;M为类别数;p(xi)为样本的真实类别;q(xi)为预测为该类别的概率。 表2 WSRCNN模型结构参数 Dorpout层的参数通过对比试验选取,分别将模型的Dropout率设为0.3、0.5和0.7,得到的模型损失曲线如图4所示。由图可知,当Dropout率为0.3时,模型收敛速度更快也更稳定,因此选择Dropout率为0.3。 图4 不同Dropout率的损失对比 4.4.1 准确率与损失曲线 将训练集数据归一化处理后批量输入到初始化参数的WSRCNN模型中,对模型进行200次迭代,得到的准确率和损失值变化如图5所示。从图中可以看出,模型在迭代75次后,准确率和损失值逐渐趋于稳定,并且在迭代100次后,准确率已经稳定于0.9以上,多次达到100%,并且模型的损失值也稳定于0.1以下。 (a) 准确率曲线 (b) 损失曲线 4.4.2 混淆矩阵 为了更直观地观察模型的识别效果,将测试集的数据输入到已经训练好的模型中进行磨损状态识别,把模型识别的结果与实际磨损状态的标签进行混淆矩阵的绘制,得到的混淆矩阵如图6所示。混淆矩阵是一种展示模型性能的可视化方法,其原理是将模型识别结果以矩阵形式表示出来,行表示模型预测类别,列表示真实类别,左上角到右下角对角线的值为分类正确的比例,其他位置为分类错误的比例。 图6 混淆矩阵 因此,本文提出使用改进卷积神经网络模型对TBM变速箱磨损状态识别的效果较好。 4.4.3 特征可视化分析 为验证本文模型提取数据特征的优势,使用t分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法对本文模型的卷积层、全局平均池化层和输出层学习到的特征进行分析和可视化[23],可视化结果如图7所示,为WSRCNN模型各层提取到的特征分布状态。从图中可以看出,经过卷积层和池化层的交替,不同类别的特征呈现分离趋势,同一类别的特征逐渐靠拢,在经过第4层卷积操作后,类别相同的特征都集中在一起,类别不同的特征基本可以区分开。在全局平均池化层和输出层,各类别的特征已完全分离开,同一类别的所有特征也聚集在一起完成分类。 (a) 卷积层1 (b) 卷积层2 (c) 卷积层3 (d) 卷积层4 (e) 全局平均池化层 (f) 输出层 为验证WSRCNN模型的有效性,将其与传统的一维卷积神经网络(CNN-1D)和BP神经网络模型进行对比。其中CNN-1D模型包括2个卷积层、2个池化层、1个全连接层,2层卷积层的卷积核数目分别为16和32,卷积核尺寸为5×1,全连接层神经元个数为16,其余参数设置与本文一致。BP神经网络的3层神经元数分别设置为9、13、4,输入层和隐藏层分别使用tanh函数和sigmoid函数激活。模型识别结果对比如表3所示。 表3 模型识别结果对比 由表3可知,只有BP神经网络的精确率是高于WSRCNN模型的,是因为BP神经网络有3个样本没有判断出类别,其余分类器输出的均为正确分类的,因此精确率显示为100%; 而WSRCNN模型的其余指标均高于传统卷积神经网络CNN-1D模型和BP神经网络,证明改进后的卷积神经网络更适合进行磨损状态的识别,BP神经网络属于浅层模型,特征学习能力有限,因此其识别性能也较本文方法存在一定差距。 1)本文提出了一种基于改进卷积神经网络的TBM变速箱磨损状态识别方法。该方法以TBM变速箱的油液光谱分析结果作为模型输入,通过建立光谱数据与磨损状态标签的非线性映射关系,可以在不拆机的情况下及时识别出变速箱的磨损状态,避免发生更大故障,相较于传统的三线值法计算简便且准确。 2)通过对传统卷积神经网络模型做出改进,建立WSRCNN模型,使用2层卷积层堆叠代替传统的1层卷积层,可以深度提取数据特征,并使用2个不同尺寸的卷积核提取不同层级的特征;为避免过拟合,使用全局平均池化层代替全连接层,并引入Dropout正则化,降低了模型的参数量和计算量。 3)将基于改进卷积神经网络建立的TBM变速箱磨损状态识别模型应用于工程实例中,并与传统的CNN-1D模型和BP神经网络模型进行对比,试验结果表明,使用改进的卷积神经网络能够准确识别出TBM变速箱的磨损状态,且本文模型的识别性能更优,验证了所提方法的有效性。 4)本文使用光谱分析数据对变速箱的磨损状态进行识别,但数据需要对油液进行光谱分析后才能得到,具有一定的滞后性,之后进一步的研究可以使用TBM运行时变速箱的监测数据对其运行状态进行判断,更具有实时性。3 WSRCNN方法
3.1 WSRCNN模型建立
3.2 状态识别流程
3.3 模型评价指标
4 实例验证
4.1 工程概况
4.2 数据准备
4.3 模型参数设置
4.4 模型训练与测试
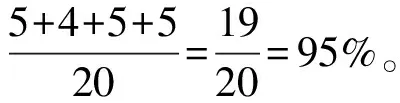


4.5 模型对比
5 结论与讨论
