一种基于RISC-V架构的高性能嵌入式处理器设计
2023-12-13刘向峰高诗昂邓庆绪
杜 岚,王 裕,刘向峰,高诗昂,邓庆绪
(东北大学 计算机科学与工程学院,沈阳 110004)
1 引 言
RISC-V是一个可扩展,模块化的开源精简指令集架构,它由伯克利大学于2014年提出,基于RISC-V架构,可以设计各种各样的处理器微架构,以部署在不同的应用场景,且无需支付任何授权费用[1].由于RISC-V架构的指令集极其精简,基础的RV32I指令集只有不到50条指令,这使得基于RISC-V架构的处理器核的面积较小,功耗较低,这些处理器核被大量应用于嵌入式MCU、硬盘控制器、AI数据处理器[2].目前,有很多高校、研究机构、企业加入到了RISC-V联盟的生态建设中,RISC-V基金会包含的组织已经超过了100家,RISC-V在嵌入式微控制器领域的软件生态已经相当完备,且正向个人电脑,服务器领域不断扩展,这对国内的半导体产业崛起是一个很好的机会[3-5].
目前,IoT和移动处理器领域,应用最为广泛的是基于ARM架构的处理器,在性能要求不高的领域,以Cortex-M系列的处理器核为主,在有一定性能要求的领域,以Cortex-A系列的处理器核为主.但ARM架构不是一个开源架构,如果使用这些处理器核,需要向ARM公司支付较高的授权费用,且这些处理器具有较差的灵活性[6-8].在RISC-V社区中,也存在着一些开源的处理器核.伯克利大学开发了基于RISC-V架构的Rocket-Chip[9]和BOOM[10]两个处理器核心,它们都是64位的RISC-V处理器,前者是一个5级顺序流水,后者是一个高性能超标量乱序处理器,它们分别同ARM的Cortex-A5和Cortex-A9相比,使用更小的芯片面积,拥有更低的功耗,更高的性能,但Rocket-Chip和BOOM使用的访存总线是由伯克利大学提出的Tilelink总线,其使用场景有限,不利于第三方进行SoC的集成.此外,工业界也发布了很多的开源的RISC-V处理器内核,例如,芯来科技的蜂鸟E200[11],阿里巴巴的玄铁C910[12].蜂鸟E200是一款性能较低的微控制器,可用于对性能要求不高的场景,玄铁C910是一款相对复杂的高性能嵌入式处理器,它可以运行Android操作系统.但对于一些不需要运行类似于Linux或者Android,且同时需要处理大量数据的场景,例如硬盘控制器或南桥逻辑控制器,E200和C910就不能有效支持,E200的性能较低,不适用于该场景,而C910包含了很多并不需要用到的功能,会造成芯片面积的浪费,徒增芯片成本.
针对现有的开源RISC-V处理器核的不足,本文设计了一种顺序取指,乱序执行的处理器微架构,代号为FRV232,它支持RISC-V的基本整数指令集,以及M扩展指令集.FRV232采用了指令的动态分支预测技术,指令乱序执行技术,有较强的性能,且占有较小的面积,可应用于对处理器性能要求较高,且无需运行类似于Linux或其它复杂操作系统的场景.
2 FRV232处理器核微架构设计
图1是FRV232的整体结构图,FRV232利用取指单元(Instruction Fetch Unit,IFU)每个时钟周期从存储器中取出一条指令,由译码单元(Instruction Decode Unit)对指令进行译码,获得译码信息,再将译码信息传递给发射队列(Issue Queue)和重定向队列(Reorder Queue),发射队列对译码信息进行判断,将其分发给不同的执行单元.执行单元执行完指令后,将指令运行结果写回到重定向队列中,重定向队列最后按照程序中原本指令的顺序将指令的执行结果提交到对应的目标存储单元中.
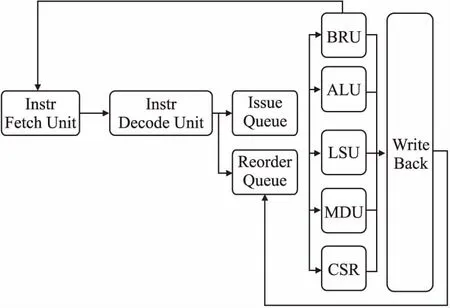
图1 FRV232整体架构图Fig.1 FRV232 entire architecture
发射队列在发射指令给执行单元时,采取的策略是乱序发射,即只要发射队列中的指令具备发射条件,就会被队列选中,发射到对应的执行单元中,无需等待该指令之前的指令是否完成,依靠指令的乱序执行,可以有效提升处理器的性能.同理,在访存单元(Load Store Unit,LSU)中也存在类似的情况,访存指令的执行时间可能很长,采取乱序访存技术可以让后续访存指令越过前面的访存指令乱序执行,以提高访存性能.FRV232采取的访存策略是Store指令会按顺序执行,两条Store指令之间的所有Load指令可以乱序执行,因为,Load指令不会改变存储器的状态.因此,FRV232的LSU中也设计Load队列和Store队列,用于提升处理器的访存性能.为了保证指令供应的稳定性,FRV232采用了动态分支预测技术,在取指阶段猜测指令的类型,预测下一条指令的取指地址,以防止取指单元运行的指令流被分支指令打断,尽可能地保证发射队列和执行部件中的运行的指令是正确指令流上的指令.FRV232采用了这些处理器优化策略,并结合RISC-V指令的精简性,以较低的芯片面积,实现了较高的性能.
2.1 取指单元
图2描述了FRV232的取指单元的数据通路,它的取指电路被划分成3级流水线:
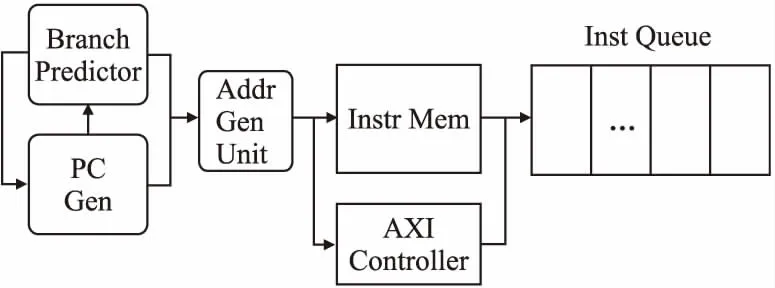
图2 FRV232取指单元Fig.2 FRV232 instruction fetch unit
1.指令地址生成单元,根据处理器的PC值(由PC Gen生成),分支预测器的预测结果,处理器的异常状态等信息,进行比对判断,生成访问指令存储器所需的地址.
2.IFU使用指令地址访问指令存储器或外部设备,获取指令内容.
3.IFU将获取到的指令,存放到指令队列(Instr Queue)中.
从FRV232整体结构上看,一条指令从取指到执行,需要经过很多模块的处理,而一条分支指令的执行是否成功,需要在执行阶段才能确定,如果此时发生分支跳转,那么该分支指令后续的指令,就不能执行,需要被处理器取消掉,发生流水线冲刷,这样会浪费大量的取指带宽.因此,FRV232使用了动态分支预测技术,实现了动态分支预测器,以减少流水线冲刷的次数,动态分支预测器可以记录历史分支指令的跳转状态和跳转目标,根据这些信息,对当前指令的跳转地址和跳转方向进行预测,并将预测信息传递给地址生成器.由于,各种指令运行的时间都不一样,有一些指令,例如访存指令,可能会运行较长时间,此时处理器的下游模块可能会发生阻塞,从而连带着IFU也发生阻塞,为了减轻指令阻塞带来的延迟,FRV232设计了一个Instr Queue,使得下游模块阻塞时,IFU不会立马阻塞,而可以继续运行一段时间.
2.1.1 分支指令方向预测
对于分支预测器,其预测的准确度是很重要的,这需要选取合适的分支预测算法,复杂的分支预测算法可能会带来较高的准确度,但同时也可能会造成较大的芯片面积开销,这对于一个嵌入式处理器核来说,是不可接受的,因此需要对预测算法的准确度和芯片面积进行权衡,目前广泛应用于动态分支预测技术的算法有Bimodal预测算法、Hybrid预测算法、两级自适应预测算法等[13,14],FRV232对这些算法的复杂度和准确度进行了折中,选择了两级自适应分支预测算法.
两级自适应预测算法的实现思路如图3所示,它需要硬件存储两个表格,一个是PHT(Pattern History Table),一个是BHT(Branch History Table),他们存储了分支指令的历史跳转情况.BHT中存储了指令地址对应的分支指令过去N次的跳转结果,PHT存储了对应分支指令不同跳转结果对应的跳转状态,跳转状态是一个两bit计数器.其中00、01、10、11分别代表强不跳转、弱不跳转、弱跳转、强跳转,如果结果索引为强不跳转或弱不跳转,那么分支预测器就预测的结果就是不跳转,否者,预测结果为跳转.IFU在取指时,会使用PC(Program Counter)值来查询PHT和BHT,来预测当前指令的跳转情况,由于PC值的位宽和系统位宽一致,为32位,但PHT和BHT不可能存储如此庞大的信息,因此,FRV232只是截取了部分PC值,并对其进行异或运算,以减轻不同分支指令在BHT和PHT中的冲突情况.当分支指令执行完毕时,相应的执行部件BRU会发出请求,更新PHT和BHT中的历史跳转信息.
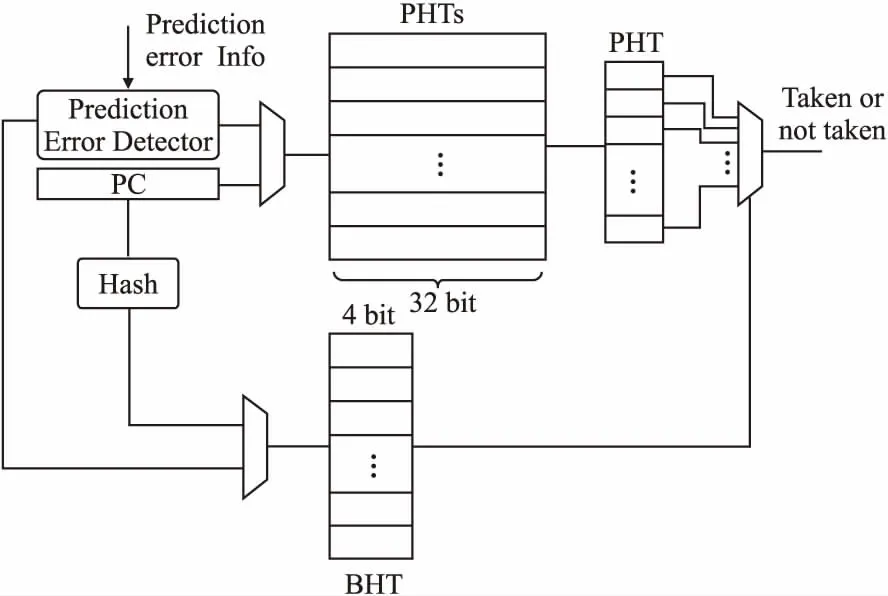
图3 两级自适应分支预测算法Fig.3 Two-stage adaptive branch prediction algorithm
2.1.2 分支指令跳转目标缓存
分支预测器不仅要给取指单元提供跳转信号,还需提供跳转的目标地址,因此,分支预测器内部也需要缓存跳转地址,该功能部件被称为BTB(Branch Target Buffer).与访存存储器类似,分支预测器使用PC值对BTB进行索引,获取访存地址.BTB不可能存储所有分支指令的目标地址,因为这样的代价太大,同时,为了节省空间,BTB中也只存储相对PC的偏移地址.RISC-V指令集有两种分支指令,一种是branch指令,用于if或while语句,一种是jump指令,用于函数调用和返回,后者是必然执行的分支,尤其是用于做函数返回的jump指令,FRV232利用了这一特性提高预测精度.
图4描述了BTB的微架构,BTB采用两路组相连结构存储跳转目标地址,每一路存储器使用一片SRAM实现.BTB使用PC的一部分地址进行索引,用剩下的高位地址判断对应单元存储的目标地址和该PC值是否匹配,同时查询两路BTB存储器,从存储器获取跳转目标信息,再根据跳转信息,判定当前地址是否有效,将地址信息传递取指单元.除了目标地址,存储单元中还存储了PC高位地址的Hash值、指令的类型以及用于标识当前单元存储的地址是否有效的标记位.存储PC高位地址的Hash值可以有效地节省芯片的面积,FRV232采取的策略是对高位PC先进行Hash,再进行存储.此外,由于函数返回的地址具有一定的特殊性,它的存储位置固定,且一定会跳转,因此,FRV232专门设计了RAS(Return Address Stack)模块存储函数调用返回地址,当BTB中对应单元存储的指令类型是函数返回指令时,BTB提供给取指单元的地址就从RAS中获取.
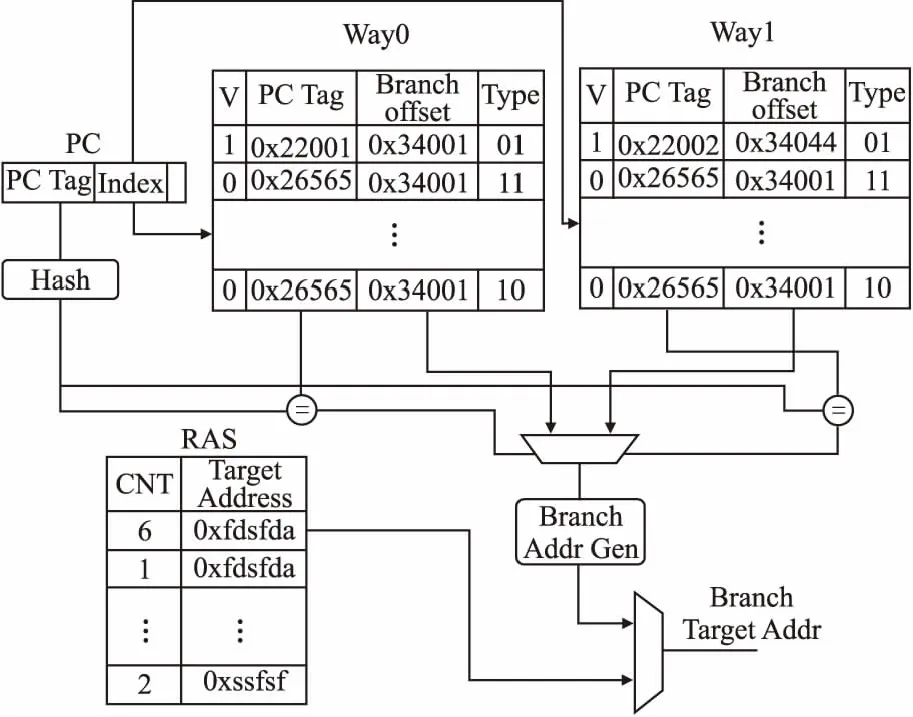
图4 BTB微架构Fig.4 BTB micro-architecture
递归函数会多次调用同一个位置的jump指令,也会多次从同一个地址调用相同的返回指令,在RAS中存储过多相同的返回指令是不合适的,FRV232对这一特性进行了优化,在RAS中添加计数器,在PC值相同位置有函数调用指令时,将对应的返回指令的计数器的值做加一操作,函数返回时做减一操作,直到对应地址所有返回指令执行完成.
2.2 译码单元
译码单元不断地从指令队列中读取指令,将指令转化为对相应执行单元的控制信息码,并把这些控制信息码传递给发射队列.此外,由于每一条指令都有自身的操作数,它们可能保存在寄存器中,也有可能作为立即数保存在指令中,因此译码单元需要根据当前处理器的情况,从不同的操作数源获取操作数,并将它们传递给发射队列.RISC-V的基础指令极其精简,只有算术、访存、分支3类指令,FRV232在这3类指令的基础上又实现了RISC-V的M扩展,即乘法指令和除法指令扩展.在译码阶段,译码单元会将普通算术指令翻译成对ALU(算术逻辑单元)的控制信息,将乘法除法指令翻译成对MDU(Mul Div Unit)的控制信息,将访存指令翻译成对LSU的控制信息,将分支指令翻译成对BRU(Branch Unit)的控制信息.
对于RISCV指令集,不同指令的执行时间是不一样的,例如一条普通的算术指令在ALU中只需要一个时钟周期就可以完成,而一条乘法指令在MDU需要3个时钟周期才能完成,一条访问外设的访存指令可能需要上百甚至上千个时钟周期才能完成.在顺序执行的流水线中,后续指令必须等待前一条指令执行完成才可以继续执行,而FRV232采用了乱序执行的技术,可以在执行一条需要超长执行时间指令之后的指令,提前执行后续指令.为了提前执行指令,需要暂存提前指令的运行结果,并在最后顺序提交指令的执行结果,不同乱序处理器缓存指令执行结果的位置有所不同,BOOM使用了寄存器堆栈保存,FRV232使用的是重定向队列(Reorder Queue)保存.因此,在译码阶段,译码单元会为每一条拥有目标寄存器的指令分配一个重定向队列编号,并在读取操作数时,判断操作数的读取来源,从相应的读取源读取需要使用的操作数,这一过程是FRV232的寄存器重命名.
图5是FRV232寄存器重命名模块的微架构图,寄存器重命名模块中维护了一张寄存器重命名表,重命名表中存储了RISC-V架构中32个通用寄存器在执行指令时的状态,以及在执行时各个寄存器对应的重定向队列编号.在寄存器重命名时,译码单元先从指令中获取对应的寄存器编号,再查询该寄存器最新的值目前存放的位置,并从相应的模块读取对应的操作数并发送给发射队列.寄存器最新的值对应的来源有3个,一个是寄存器堆栈,一个是重定向队列,还有可能来自执行单元.
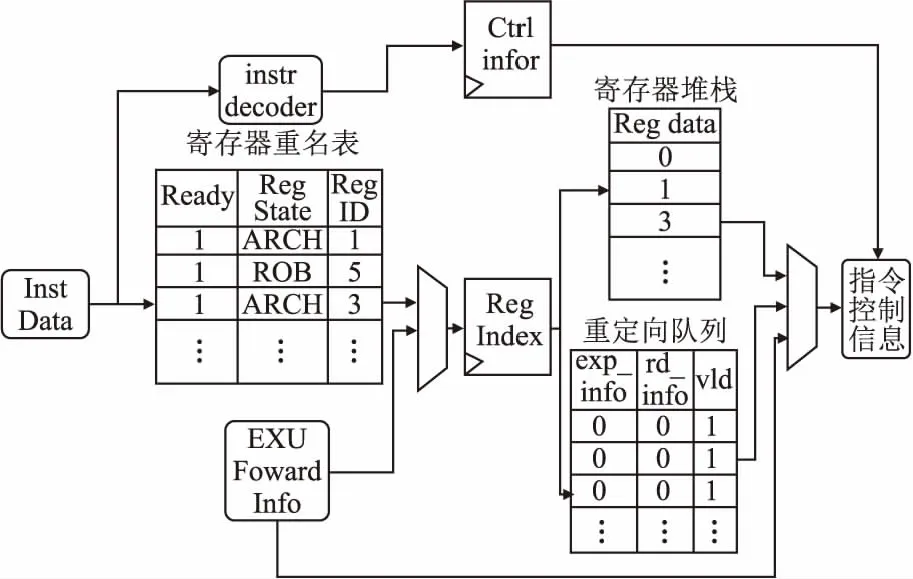
图5 寄存器重命名模块微架构Fig.5 Register rename module micro-architecture
在程序执行时,一条指令在进入发射队列前就完成了寄存器重命名,此时指令的运算结果并未写入重定向队列中,因此,在重命名阶段后续的指令有可能读取不到操作数具体的数值,也有可能在读取数值时,相关执行单元正好完成运算.为了让一条指令尽早执行,FRV232将执行单元的运算结果也前递到了寄存器重命名阶段,在这一阶段,操作数也有可能从后续的执行部件直接获取.此外,各个执行部件在完成相关指令的运行时,会修改寄存器重命名表的内容,并将运算结果写入到重定向队列中;重定向队列在指令提交时,也会修改寄存器重命名表的中对应指令的映射关系.
2.3 发射队列
发射队列接收了译码单元发送的执行单元控制信息以及相关的操作数信息,并根据这些信息进行调度,把这它们发射给不同的执行单元.在发射队列中,存放了针对ALU、BRU、LSU、MDU、CSR的控制信息,不同的指令可以控制不同的执行单元,控制信息发射的时机由发射队列中的调度器决定.为了尽可能地提升处理器的性能,FRV232的指令发射策略为:
1.普通算术指令和分支指令,只要指令所需的操作数已经准备好,就将该指令发射出去.
2.存储器写指令(Store指令)按指令写入发射队列的顺序发射.
3.夹在两条Store指令之间的存储器读指令(Load指令)的发射顺序与普通算术指令一致.
4.多条操作数都已经准备好的指令按指令进入发射队列的顺序进行发射.
为了实现发射队列中的指令,按指令进入发射队列时的顺序发送,FRV232采用了一种功耗较低的设计方案,即在发射队列的每个存储单元中存储年龄信息,在指令发射调度器中根据指令的年龄和准备状况等信息进行仲裁,而没有采用移动队列中存储单元在队列的位置的方式来实现这一功能.发射队列中的部分指令可能依赖该指令之前指令的计算结果,这些指令就不能被发射出去,当被依赖指令在执行单元中计算完成后会将计算结果传递回发射队列,用于唤醒相关指令.此外,FRV232在发射一条指令时,依赖该指令的后续指令也会被唤醒,虽然此时相关操作数并未准备好,但后续指令在发射到对应执行单元时,所需操作数就已经计算完成,对应的执行单元直接将计算结果传递给该指令的执行单元,这样可以提升处理器的性能,让具有相关性的指令执行的更快.
2.4 执行单元
如图1所示,发射队列会将指令对应控制信息发射给各个执行单元,每个执行单元可以执行一类指令.ALU可以执行RISC-V中除乘法和除法以外的所有算术逻辑指令,例如加法指令、移位指令、比较指令;BRU可以执行分支指令,并在执行时,判断分支预测的正确性,将执行结果反馈给分支预测器;MDU可以执行乘法指令和除法指令;CSR模块中包含了处理器中的所有状态寄存器,RISC-V中有特定的读写指令对其进行读写;LSU是系统的访存单元,可以对存储器和外部设备进行访问.
2.4.1 旁路网络
为了保证指令执行的连续性,即两个有相关性的指令可以流水化执行,FRV232在各个执行单元之间设计了一套旁路网络,在各个执行单元计算完成之时,将计算结果直接传递给自身的输入和其他执行单元,让下一条与之有相关性的指令可以在下一个时钟周期直接执行,而无需等待计算结果写入发射队列.
图6描述了ALU在旁路网络中与其他模块的连接关系,ALU两个操作数的来源有ALU自身、LSU、BRU、MDU,旁路网络会根据发射队列传递的操作数据选择方式,选择正确的数据来源.在旁路网络中,FRV232没有将CSR的读取结果传递过来,主要原因是,CSR指令是一种特殊指令,它会影响后续指令的执行状态,直接引入结果,需要将系统寄存器的很多状态也接入流水线,这样会大大增加系统复杂度,增加芯片面积和功耗.ALU在计算单元完成计算时,会将计算结果传递给一个寄存器,再由寄存器传递给其他执行单元,以及译码单元和发射队列,该寄存器的目的是漫长的组合逻辑链,防止组合逻辑过长,降低整个系统的主频.其他执行单元中操作数的数据通路也与ALU中的通路一致,都需要经过旁路数据选择器的判定.
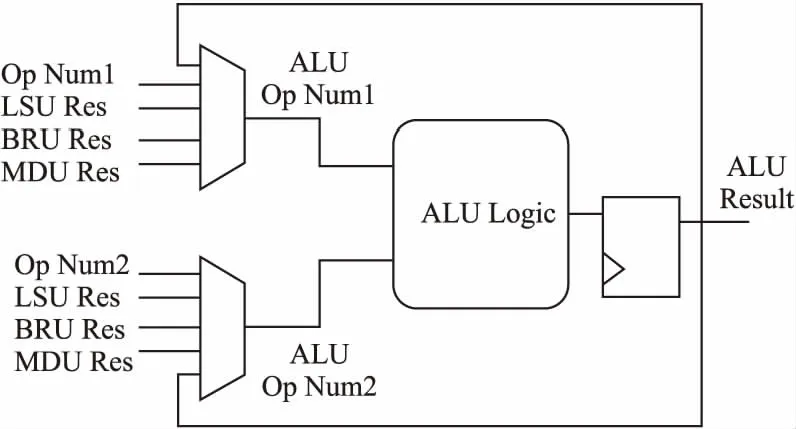
图6 ALU中的旁路网络Fig.6 Bypass network in ALU
2.4.2 访存单元
图7是访存单元的数据通路,访存单元从发射队列获取访存指令,将访存指令存入对应的访存队列,再将访存队列中的访存请求发送出去,对存储器或外部设备进行读写.由于外部存储器和外设的访问速度远小于处理器核的运行速度,这会阻塞后续访存指令的访问,为了减轻阻塞的负面影响,FRV232设计了Load队列和Store队列,用于存放这些访存请求,以实现访存指令的乱序执行.访存顺序可以有多种实现方案,FRV232在复杂度和性能之间进行了折中,选择了Store指令访问,Store指令之间的Load指令访问这一策略,这造成了Load指令和Store指令的执行逻辑具有很强的差异性.因此,访存单元将Load请求和Store请求分别存放在Load队列和Store队列中,并在两个队列中记录了各个访存请求的年龄信息.在Load队列中,只要队列中的存储单元中的访存请求处于就绪状态,且该请求的年龄信息比Store队列队头请求的年龄信息大,Load队列就会把该请求发送给对应的存储控制器或外设控制器;在Store队列中,只有Store队列的头部请求处于就绪状态,Store队列才会把这个请求发送出去.
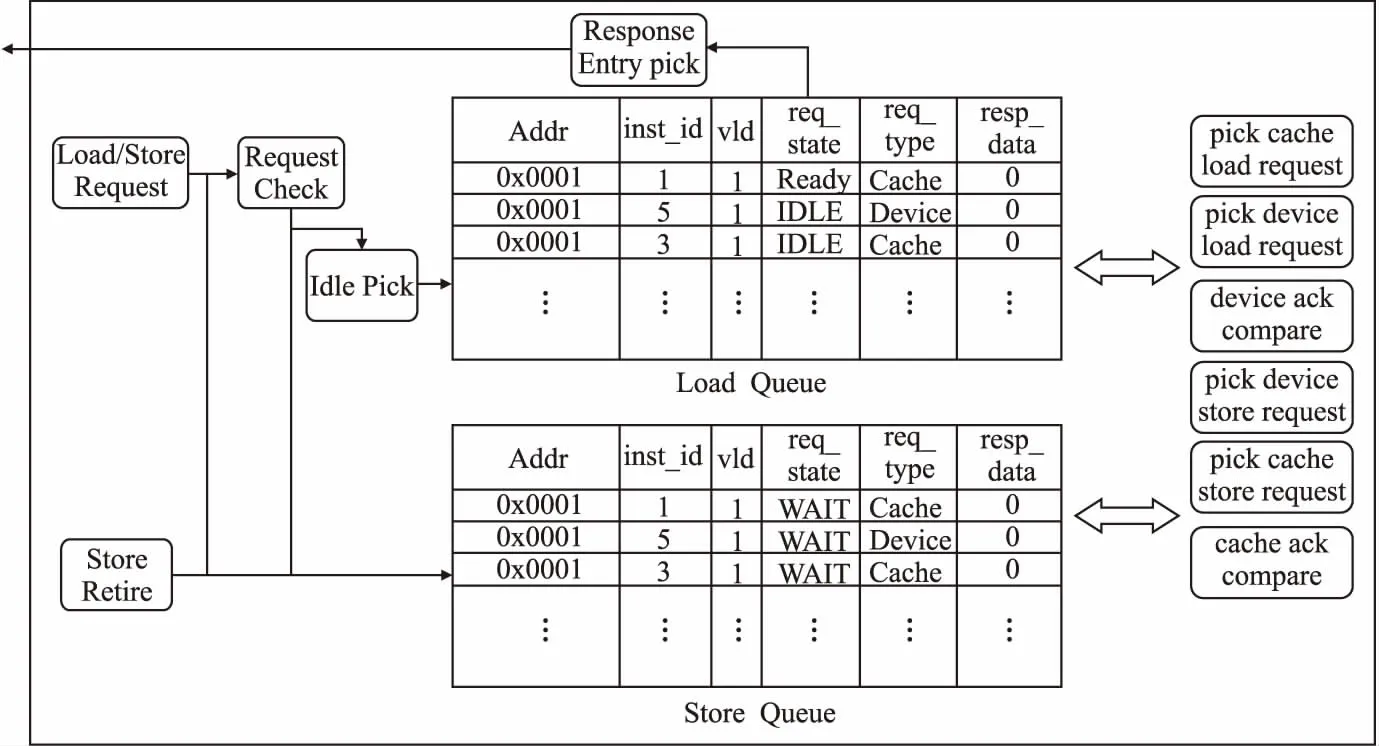
图7 访存单元数据通路Fig.7 Load store unit datapath
FRV232在访存队列中的每一个访存请求单元中存储了该请求的执行状态,图8是Load请求执行时的状态转移图,Store指令的执行过程也与该图类似,所有指令都可以并行且流水化地执行.Load指令在进入Load队列时,默认的执行状态是LOAD WAIT状态,在该状态下,它会被队列发送给Cache并同时将该请求的状态变成LOAD ACCESSED.如果Cache命中,该请求状态就会变成LOAD READY状态,处于该状态的请求会被访存单元清空并把访存结果发送给处理器核的下游模块;如果Cache未命中,访存请求就会变成LOAD CACHE MISS状态,访存队列会将该请求发送给内存控制器,让内存控制器读取数据,在发出内存读取命令后,该请求的执行状态转变为LOAD DDR ACCESSED,当内存放回数据成功时,该请求再转变为数据就绪状态.对于Store指令,由于FRV232是一个乱序处理器,Store指令之间的指令可能会发生异常,如果直接执行Store指令,会出现不可逆的错误,因此,对于Store指令,访存单元需要等该指令之前的所有指令执行完毕,才会开始发送Store请求给存储单元.
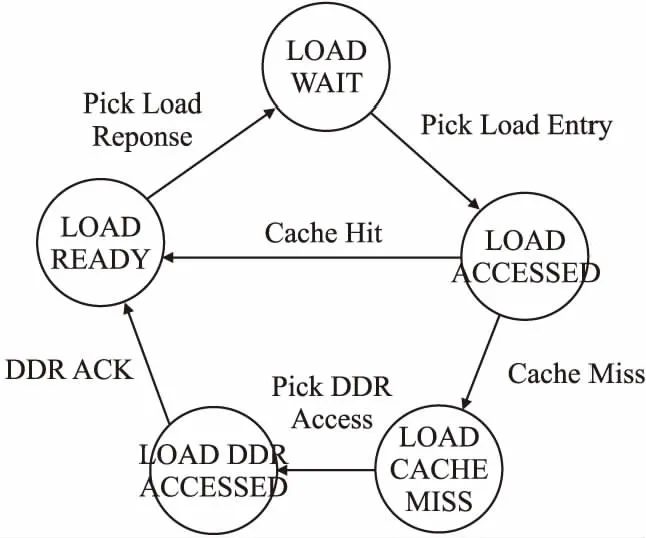
图8 Load指令状态转移图Fig.8 Load instruction state transition diagram
Load请求和Store请求访问的存储空间可能存在相关性,为了提高访存效率,FRV232暴露了Store请求的地址和数据,Load请求在进入Load队列时,会检查Store队列中的请求和自身是否有相关性,如果存在多个Store请求有相关性,就将离Load请求最近的Store结果直接作为Load请求的结果保存在Load队列中.实现这一功能对Store队列的结构设计有特殊的要求,它需要Store请求的存储顺序在Store队列中必须是固定的,图9是FRV232的Store队列的数据通路.Store队列中的每一个请求单元在头部请求发送出去后,都会向头部存储单元方向移动一次,这样可以让所有请求在队列中按进入队列的顺序进行存储.由于Store队列不可能一直处于满队列状态,因此,Store请求在进入队列时,需要存放到队列中最靠近队列队头的一个存储单元中.
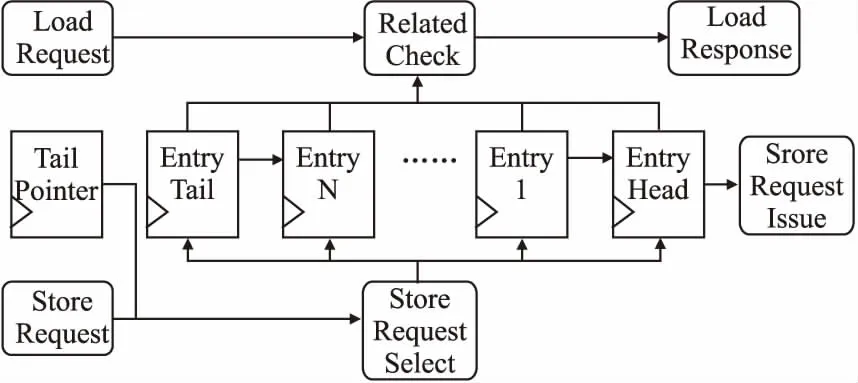
图9 Store请求队列数据通路Fig.9 Store request queue datapath
FRV232对外访问存储器和外部设备的协议采用的是AXI协议,它是ARM公司提出的一种访存协议,具有较高的访存性能,支持这一协议可以有效保障FRV232的访存带宽,当发生Cache缺失时,FRV的访存控制器会利用AXI总线从内存中读取数据,当访存请求访问的地址从属于外设地址时,访存单元会利用AXI总线,将请求发送给对应的外设控制器.AXI总线一共有5个数据传输通道,读写通道是相互分离的,可以做到读写同时进行,同时,它也具有突发传输机制,可以一次传输较多数据,也因此AXI总线被广泛应用于高性能嵌入式处理器.
3 FRV232功能验证模型
在现代处理器的设计流程中,处理器的功能验证是必不可少的,这需要有一个软件模型提供处理器运行正确时的运行结果,因此,在开发FRV232处理器硬件之前,需要先开发针对该处理器的软件功能验证模型.在RISC-V社区中,已经开源了针对RISC-V指令的功能模型Spike[15],它可以输出RISC-V程序的正确运行结果,但Spike支持的外设很固定,不利于第三方扩展指令,为了更好地满足处理器核的开发需求,本文开发了新的模拟器FRVEMU,并且FRVEMU运行基础指令的结果会与Spike进行对比,以此来保证FRVEMU的正确性.在开发处理器的过程中,运行在处理器上的应用软件也可以提前开发,并部署在FRVEMU上,验证相关软件的正确性,在完成处理器开发后,可以直接将相关应用软件运行在FRV232上,无需做任何修改.通过软件模拟的方式,不仅可以验证处理器的正确性,还可以大大地提高系统硬件和软件的开发效率.
RISC-V架构中一共有32个通用寄存器和按需支持的系统寄存器,这些通用寄存器、系统寄存器以及内存中的值,代表了处理器当前的运行状态信息,可以使用验证模型生成每一条指令执行后处理器的状态信息,然后在验证时,用电路模型去比对验证模型.由于内存信息包含的范围太大,而通用寄存器和系统寄存器已经代表了处理器当前运行的状态,因此,FRV232的验证模型主要生成通用寄存器和系统寄存器的数据.此外,为了提高验证效率,FRV232验证模型还提供了写指令的操作状态,它可以在处理器发出存储器写操作时,对其进行验证.
图10是FRV232功能验证的流程图,从FRV232复位开始,处理器核心每执行完一条指令,验证框架就会先检测处理器核的通用寄存器和系统寄存器是否发生变化,再检测处理器是否发送访存的写请求,如果发生变化,就将处理器核的变化信息和验证模型的正确输出做比对,如果处理器核心的变化结果和验证模型的结果不一致,就说明处理器核的电路设计存在错误.FRV232的验证环境以Modelsim为基本工具,利用验证模型提供的正确运行结果,System Verilog为基本的验证编程语音,实现了图5所示的验证流程.当所有指令运行完毕时,就说明当前的测试用例已经通过,在功能验证阶段,FRV232通过了riscv-test中全部的指令测试用例,以及移植到FRV232上的性能测试用例Dhrystone,通过RISC-V的基础功能用例,一些相对复杂的性能用例,以及访问外设的用例的验证,FRV232功能的正确性得到了有效的保障.
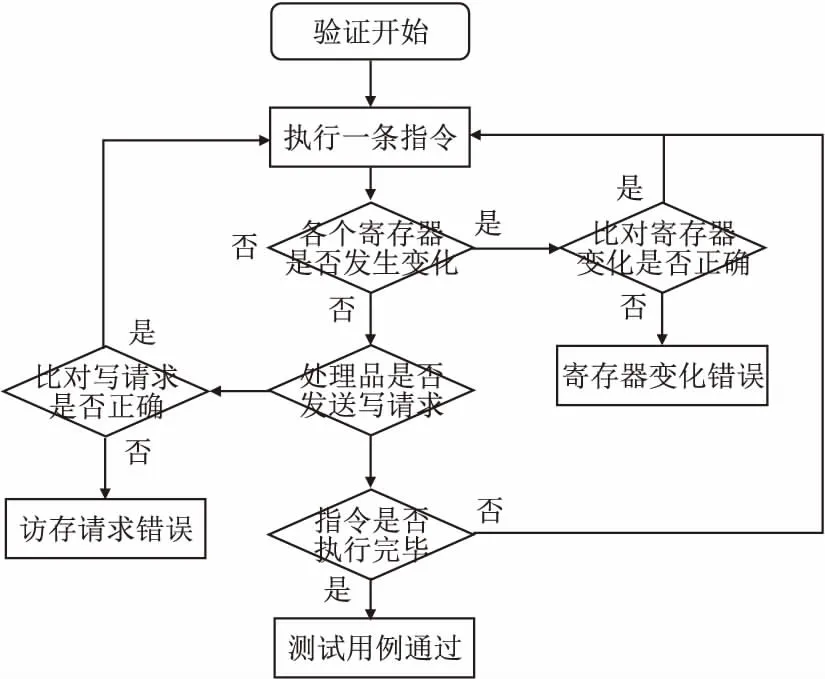
图10 FRV232功能验证流程图Fig.10 FRV232 function verification flow chart
4 FPGA原型验证与性能分析
在使用Modelsim进行功能验证后,还需要利用FPGA进一步验证,在FGPA上得到功能验证用例的正确结果,及时发现处理器中的隐藏的错误,初步得到FRV232所需的芯片面积、功耗,并在FPGA上运行性能用例,得到FRV232的性能数据.本文利用的FPGA平台是Xilinx的NEXYS 4 DDR,FPGA芯片的型号是xc7a100tcsg324-1,利用的EDA工具也是由Xilinx提供的Vivado,在利用FPGA进行原型验证时,需要先将处理器中使用到的SRAM替换成FPGA中的BRAM资源,并搭建一个简易的SoC系统,提供基本的外部设备,让FRV232可以正确地在FPGA上运行起来.此外,为了保证原型系统在FPGA上部署的正确性,需要先在vivado平台上做行为级仿真,对已有的验证代码进行了简易的移植.
在经过行为仿真后,利用EDA工具对SOC进行综合,布线并生成用于下载进FPGA芯片的比特文件,在综合后,可以得到FRV232的面积信息,它在NEXYS 4 DDR上的面积报告如表1所示.在时钟为100MHz时序约束下,Vivado对其进行了时序分析,其结果是WNS(Worst Negative Slack)的值为0.01ns,该值为正,表明本设计能在时钟频率为100MHz的约束下稳定运行.
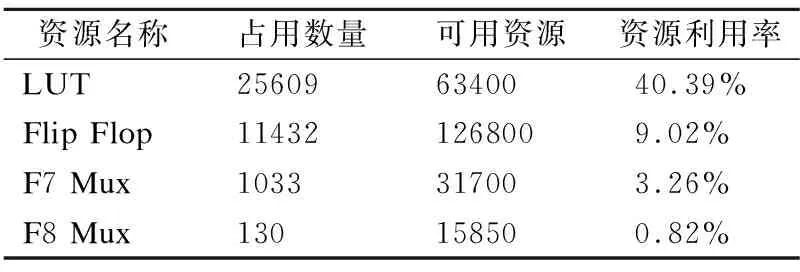
表1 FRV232面积开销Table 1 FRV232 area cost
最后,将性能用例Dhrystone导入到指令存储器中,并随着综合的比特文件一起下载到FPGA上运行,Dhrystone对FRV232的性能测试结果为1.73DMIPS/MHz,其验证结果和功能验证的结果一致.VexRiscv[16]也是一款支持了RV32IM指令集的开源RISC-V处理器核,它是一个实现了五级流水的标量顺序执行的处理器,和FRV232具有一定的相似性,它的性能数据和FRV232的比对结果如表2所示,其中也同时放置了嵌入式处理器核E201的Dhrystone性能跑分结果.从性能数据来看,同等编译优化情况下,FRV232优于一般的顺序处理器核,能处理对性能有所需求的场景.
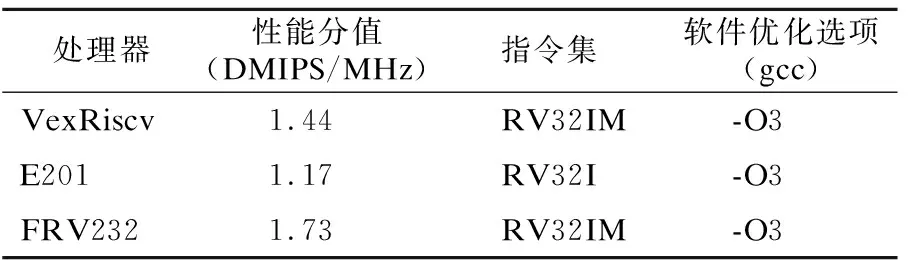
表2 FRV232和其他开源RISCV处理器的性能比较Table 2 Performance comparison between FRV232 and other open source RISCV processors
5 结 语
本文设计了一个基于RISC-V指令集架构的处理器核FRV232,介绍了FRV232的微架构,论述了其功能验证模型,并提供了它的面积和性能数据.FRV232在芯片的面积、功耗和性能之间进行了折中,利用寄存器重命名和乱序执行技术有效地提高了性能,并结合RISC-V精简指令的优势,以较小的面积实现了较高的性能,它强于RISC-V社区中单发射的顺序处理器,可以被应用于硬盘控制器,南桥系统控制器,以及其他对性能和面积都有一定要求的场景.
