融合流注意力机制的中文摘要生成方法
2023-12-13崔少国王奥迪
崔少国,王奥迪,杜 兴
(重庆师范大学 计算机与信息科学学院,重庆 401331)
1 引 言
随着互联网的发展,各类文本数量不断增加,使得读者难以快速获取文本中的主要内容.文本摘要技术能够从给定的源文内容中自动提取出简洁、流畅且保留源文的关键信息[1],读者通过阅读文本对应的摘要就可以快速了解源文内容,从而提高了读者的阅读效率.摘要生成技术已应用于各个领域,例如生成医疗报告和用户评论总结等领域[2].
目前,文本摘要生成主要分为抽取式摘要和生成式摘要.抽取式摘要是通过提取源文中的关键词或段落并对其进行简单组合从而生成源文摘要[3,4].生成式摘要是通过理解源文内容,用新的单词或句子表述源文内容,此方法允许生成摘要中包含新的词汇,生成摘要的内容更加灵活[5].抽取式摘要方法是简单的从源文中提取信息,然后对其进行简单拼接,不符合摘要的撰写习惯.因此,本文主要研究的是生成式文本摘要.
目前,基于深度学习方法中,编码器-解码器的序列架构与注意力机制相结合方法被广泛运用到摘要生成任务中[6],但序列架构模型在生成摘要过程中会出现未登录词的问题.因此,指针生成网络[7,8]通过使用指针机制有效缓解了生成摘要中未登录词问题,但在生成摘要的过程中存在全局语义信息缺失的问题,生成摘要的可读性有待提升.
在中文文本中,词汇是由汉字组合得到,常见汉字数量庞大,汉字间的组合方式不同所产生的词汇含义也不尽相同,从而导致文本的语义信息相对复杂.因此,在中文摘要生成任务中,仅通过指针生成网络和注意力机制相结合的方式生成摘要会存在全局语义信息缺失的现象.
针对上述问题,本文提出了一种融合流注意力机制的并行编码器模型(Flow-attention Parallel Encoder Model,FAPEM).首先,使用单颗粒处理方式对源文进行分词.然后,使用流注意力机制捕获源文的全局语义信息.其次,通过并行编码器对捕获的源文全局语义信息进行融合.最后,引入指针生成网络缓解生成摘要过程中未登录词问题.本文的主要贡献如下:
1)采用多头流注意力机制替代自注意力机制对源文从多个维度进行语义信息捕获,提高生成摘要的可读性.
2)采用并行编码器,将获取的源文全局语义信息进行融合,从而达到源文全局语义信息交互的作用,缓解全局语义信息缺失的问题.
3)在训练阶段,并行编码器和指针生成网络相结合,充分利用模型学习的语义信息,减少未登录词的出现,生成的摘要更加关注源文全局语义信息,提高了模型的泛化能力.
2 相关工作
2.1 序列到序列模型
近年来,基于序列到序列模型被运用到文本摘要任务中[9].Rush等人[10]首次将序列到序列模型用于摘要生成任务中,将卷积神经网络作为编码器,神经网络语言模型作为解码器,并在DUC2004和Gigaword数据集上取得良好效果.Chopra等人[11]在Rush等人[10]工作的基础上提出了一种条件递归神经网络模型,使用循环神经网络替代了卷积神经网络作为编码器,提升了生成摘要的质量.Hu等人[12]构建了一个大型中文短文本数据集,将循环神经网络运用在中文摘要生成任务中,为中文摘要生成任务提供了基线模型.吴等人[13]基于序列到序列模型,通过在编码器和解码器之间引入语义对齐网络,缓解了摘要生成中语义信息利用不充分的问题.
2.2 拷贝机制
摘要生成过程中会存在未登录词的问题.因此,Gu等人[14]提出了一种融合拷贝机制的CopyNet模型,使模型在生成摘要过程中具有拷贝源文词汇的能力,有效减少了未登录词的出现.但在生成摘要的过程中同时也会存在语义信息重复的问题.See等人[7]提出了指针生成网络模型,通过使用指针机制拷贝源文词汇有效缓解了摘要生成过程中未登录词问题,同时引入覆盖机制缓解生成摘要过程中语义信息重复问题.Wang等人[15]在混合指针网络的基础上引入外部概念信息集并提出了概念指针模型,通过使用概念集生成具有高级语义概念的摘要.
2.3 注意力机制
注意力机制可以捕获源文的关键信息.因此被广泛运用到自然语言处理任务中[16].Vaswani等人[17]提出了一种Transformer模型,通过多头自注意力机制对源文的信息进行提取,但由于其具有二次复杂性导致模型难以处理长序列并扩展到大型模型中.Zhang等人[18]通过软注意力机制对源文的关键信息进行提取,但由于软注意力机制无法提取源文的语义和语法结构,生成的摘要会存在语义缺失问题.Qiu等人[19]通过将多头自注意力机制和软注意力机制相融合,增强了模型对特征信息的关注,提高了生成摘要的质量.曾等人[20]提出了一种基于层级注意力机制面向查询的新闻多文档抽取式摘要方法,进一步提升抽取式摘要的质量.Zaheer等人[21]通过使用稀疏矩阵使得模型具有较低复杂度,但在生成摘要的过程中依旧存在关键信息缺失问题.Zhen等人[22]通过重新改变输入文本的顺序位置,降低了模型的复杂度,但损失了模型的通用性.因此,Wu等人[23]通过从流动网络视角下将流量守恒引入到注意力机制中,进一步提出了流注意力机制,在保留多头注意力机制关注源文全局语义信息能力的同时,加快了模型训练的速度,降低了模型复杂度.
3 FAPEM模型
针对中文摘要生成过程中全局语义信息缺失问题,本文提出了融合流注意力机制的FAPEM模型,模型结构如图1所示.
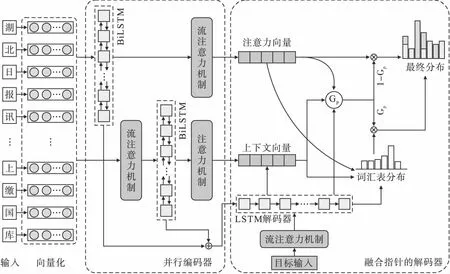
图1 FAPEM模型结构Fig.1 Structure of FAPEM Model
首先,模型采用单颗粒处理方式对输入的源文进行分词操作,对分词后的源文进行向量化得到词嵌入向量,然后通过并行编码器进行编码.在编码的过程中,一方面将词嵌入向量输入到双向长短期记忆网络(Bidirectional Long Short Term Memory,Bi-LSTM)中进行编码,然后对编码后的向量通过流注意力机制获取关键信息.另一方面,将词嵌入向量先通过多头流注意力机制获取源文的全局语义信息后再输入到Bi-LSTM进行编码.然后将两个编码器的结果进行融合,将融合后的结果输入到解码器中,使得模型更加关注源文的全局语义信息,最后在解码的过程中引入指针生成网络,减少未登录词的出现,使得解码器在生成摘要过程中更加符合源文的内容.
3.1 输入及向量化模块
本文对输入的源文采用单颗粒的分词方式.文本单颗粒处理主要是针对中文文本而提出的一种文本处理方式,将输入文本中的每一个字当作一个词进行处理,文本包含的一些特殊符号、英文单词等非文字部分原样分离,此操作可以有效减少未登录词的出现.在中文摘要生成任务中,假设给定一个输入文本序列为L=[l1,l2,…,li,…,ln],L表示经过单颗粒处理后长度为n的文本序列.然后将文本序列L通过Embedding操作[17]将其映射到低维稠密特征空间中,形成词嵌入向量C={c1,c2,…,ci,…,cn},其中ci表示第i个词的词嵌入向量.
3.2 流注意力模块
Wu等人[23]提出了一种不同于传统注意力机制的流注意力机制,其结构如图2所示.
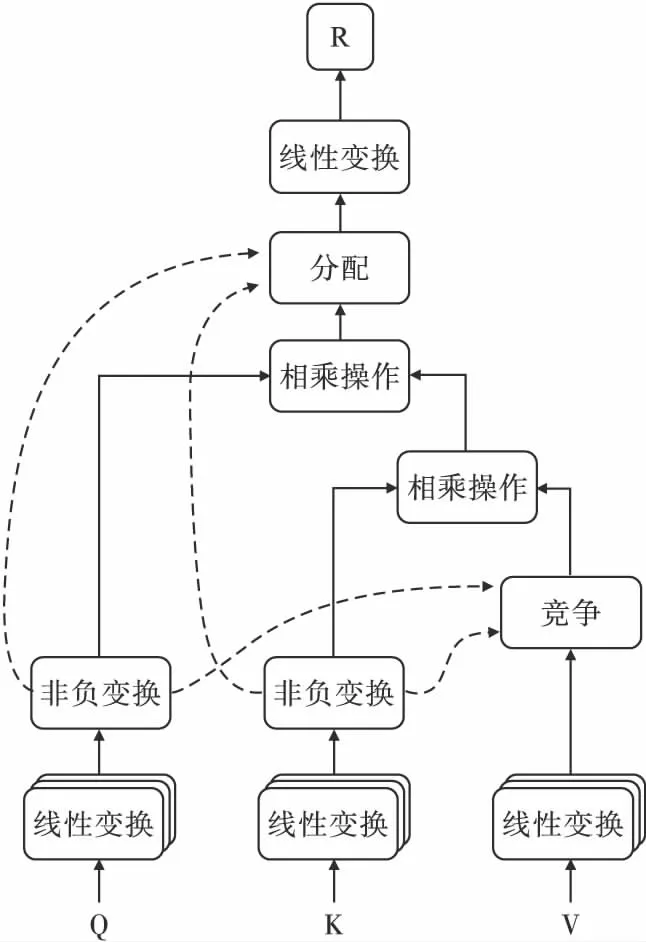
图2 流注意力机制结构Fig.2 Structure of flow-attention mechanism
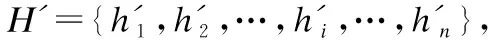
Q=HWq
(1)
K=HWk
(2)
V=HWv
(3)
通过将流量守恒引入到注意力机制中,根据查询Q和关键字K,然后对其进行标准化,此操作保证了流量守恒,计算过程如式(4)和式(5)所示:
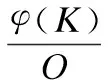
(4)
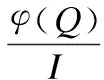
(5)
通过标准化实现了源的流出守恒与汇的流入守恒,由此可以得到引入竞争之后的源的流出量I′和汇的流入量O′,计算过程如式(6)和式(7)所示:
(6)
(7)
其中,I′表示源流出信息量一定的情况下,汇得到的信息量,O′表示汇流入信息量一定的情况下,源提供的信息量.
如图2所示,流注意力机制中主要包含竞争、聚合、分配3个部分,计算过程如式(8)~式(10)所示:
竞争:V′=softmax(O′)⊙V
(8)
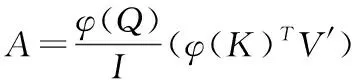
(9)
分配:R=sigmoid(I′)⊙A
(10)
其中,R表示使用流注意力机制之后词汇之间的注意力机制得分,⊙表示对应元素相乘操作.
3.3 并行编码器
单个流注意力机制可以提取到局部依赖关系,学习到文本中重要信息,而多头流注意力机制是由多个流注意力机制组成,通过联合不同位置处理不同子空间下的信息,由此获取文本全局语义信息.模型在训练过程中,编码器获取的语义信息越多,解码过程中产生的摘要可读性就越高.因此,FAPEM模型将多头流注意力机制融合到并行编码器模型中,通过在不同维度上提取源文全局语义信息和语法结构,然后将获取的信息进行融合,使得模型能够关注到更加丰富的全局语义信息.
并行编码是对输入的文本向量进行不同的编码操作.一方面,FAPEM模型对输入的文本直接通过Bi-LSTM进行编码得到隐藏层H={h1,h2,…,hi,…,hn}.
其中,Bi-LSTM是由一个前向和后向的长短期记忆网络[24](Long Short Term Memory,LSTM)叠加而成的,在时间序列上能够同时利用前向信息和后向信息,通过依靠前一时刻时序信息来预测的下一刻输出,模型能够获得源文的上下文序列信息,计算过程如式(11)~式(13)所示:
(11)
(12)
(13)
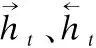
为了得到编码后的关键语义信息,将得到的H通过流注意力机制进行关注,对得到的流注意力机制结果进行合并,形成最终的注意力权重向量Y′,计算过程如式(14)和式(15)所示:
Y=(R1,…,Rn)
(14)
(15)
其中,Rn表示第n个流注意力机制的结果.

P=Concat(H,H′)
(16)
3.4 融合指针的解码器
在解码过程中,将编码阶段得到的向量P输入到单向LSTM解码器中进行解码,在解码的过程中得到解码器隐藏层S={s1,s2,…,st,…,sn}.
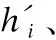
(17)
(18)
(19)
其中,mt表示当前时刻的上下文向量,W1、W2、ba表示可学习参数.
由于词汇表所包含词汇数量的有限性,模型需要从源文中拷贝词汇用来扩充词汇表中词汇数量.因此,需要一个指针概率Gp∈[0,1]用来控制生成摘要过程中词汇是复制源文还是从词汇中生成,为使指针更加关注文本关键信息,将编码得到的语义信息融合到指针生成网络中.计算过程如式(20)所示:
Gp=σ(Wgmt+WyY′+Wsst+Wxdt+bg)
(20)
其中,Wg、Wy、Ws、Wx、bg表示可学习参数,dt表示t时刻解码器的输入,σ表示sigmoid激活函数.
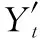
(21)
(22)
通过得到的向量Kt,可以计算当前词汇的概率分布Pvocab,计算过程如式(23)所示:
Pvocab=softmax(U3(U4[Kt,st]+b3)+b4)
(23)
其中,U3、U4、b3、b4均为可学习参数.
将计算得到的指针概率Gp作为一个控制开关,用于控制生成词汇过程中是从词汇表中生成,还是从词汇的概率分布Pvocab中生成,通过指针控制词汇的来源形成词汇的联合分布概率,计算过程如式(24)所示:
(24)
本文所提模型使用的损失函数是负对数似然函数,在训练过程中通过最小化t时刻目标字w′的负对数似然函数实现训练目标,则整个文本序列的损失函数计算过程如式(25)所示:
(25)
4 实验与分析
4.1 实验环境及参数
实验使用的环境是Window10操作系统,GPU为NVIDIA GeFore RTX3060Ti,深度学习框架为PyTorch,使用的优化器为Adam[25],Beam Search[26]搜索束,具体的实验参数如表1所示.
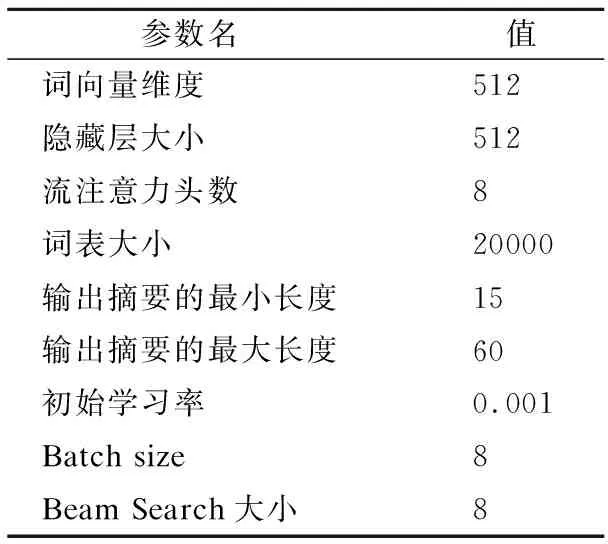
表1 实验数据表实验参数Table 1 Experimental parameters
4.2 实验数据集及预处理
本文使用数据集为公开的中文文本数据集,分别是CLTS和NLPCC两个数据集.其中,CLTS 数据集是在2020年由Liu等人[27]提供,文本数据主要来源于中国新闻网站.本文首先过滤掉文本字数小于等于摘要字数的数据,得到一个包含145461条摘要和内容对应的数据,然后随机划分原始数据集,将数据集分为训练集(87000条数据)、验证集(30000条数据)和测试集(28461条数据).NLPCC(Natural Language Processing and Chinese Computing)数据集是2017年由中国计算机学会主办的比赛数据集,包含52000条摘要与内容相对应的数据,数据集分为训练集(40000条数据),验证集(6000条数据)和测试集(6000条数据).
4.3 评价指标
ROUGE是Lin等人[28]提出被广泛运用到机器翻译、自动文本摘要、问答生成等相关领域的评价指标.其中,ROUGE-N表示的是生成的摘要和对比摘要之间N元重复率计算分数,ROUGE-L用于计算生成的摘要和真实摘要之间的最长公共子序列.本文使用的是ROUGE中的ROUGE-1,ROUGE-2和ROUGE-L 3个评价指标评估模型性能,可以直观、简洁的反映生成摘要的效果.
4.4 对比模型
为验证模型的有效性,本文选取了多个模型与本文提出的模型进行比较.
RNN-context[12]:采用GRU作为编码器同时引入注意力机制,在中文短文本LCSTS数据集上进行的实验,通过解码器生成中文摘要.
Lead-baseline[29]:通过选择源文中的前三句作为源文的摘要.
CopyNet[14]:提出了一种融合拷贝机制的CopyNet模型,使得模型生成摘要过程中具有拷贝源文词汇的能力.
Pointer-generator(PG)[7]:提出了一种指针生成网络模型,保留了模型生成摘要的能力,同时通过指针机制控制模型拷贝源文中的内容,有效缓解了模型生成摘要过程中未登录词的出现.
Pointer-generator-coverage(PG-cov)[7]:在指针生成网络模型的基础上添加了覆盖机制,有效缓解了生成摘要过程中词汇重复的问题.
Tri-PCN[8]:提出了一种融合指针网络的文本摘要生成模型,使用transformer提取多层次的文本特征,同时引入指针网络复制源文内容.
4.5 模型的性能对比
为验证FAPEM模型的有效性,本节通过将CLTS和NLPCC两个数据集上的结果与其他模型进行对比,实验结果如表2所示.
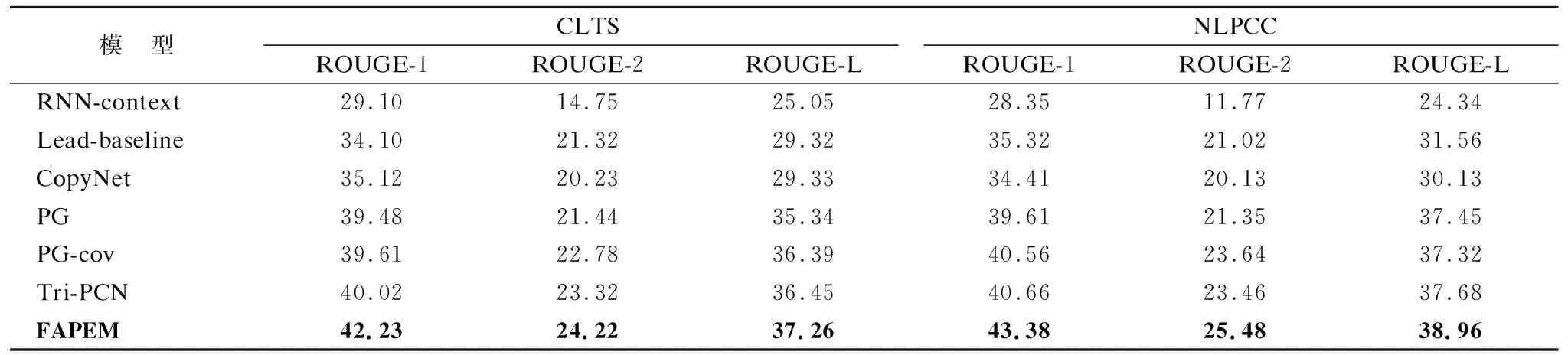
表2 不同模型在两个数据集上的结果Table 2 Results of different models on two datasets
从表2中可以看出,相比于其他模型,FAPEM模型在CLTS和NLPCC两个数据集上均表现最优.具体而言,在两个不同的数据集上,相比于模型PG-cov,在ROUGE-1、ROUGE-2和ROUGE-L评价指标上,本文所提的模型在CLTS数据集上分别有2.62%、1.44%、0.87%的提升;在NLPCC数据集上分别有2.82%、1.84%、1.64%的提升,与现有的模型相比各项评价指标也均有所提升.说明融合流注意力机制可以捕获源文全局语义信息,通过并行编码器对源文的语义信息进行融合,加强了模型对源文全局语义信息的关注,使模型在编码阶段获取的语义信息更加丰富,生成的摘要更加流畅.实验结果验证了融合流注意力机制的并行编码器模型的有效性.
4.6 摘要生成结果分析
为进一步直观的验证所提模型的有效性,将模型生成的摘要与参考摘要进行比较.实验结果如表3所示.从生成的结果可以看出,PG模型在生成摘要的过程中过度关注局部信息,使得生成的摘要中存在语义信息重复的问题,例如生成摘要中“收受贿赂”的关键信息存在语义重复的现象.PG-cov基线模型生成的摘要关注到了源文的关键信息,但存在源文部分关键信息和全局语义信息缺失的现象,如源文中的“一审被判21年”,是源文事件的结果信息,在摘要的过程中未被关注到.Tri-PCN模型对源文中的关键信息总结不够完整,例如“被判有期徒刑”关键信息未被完整表述.FAPEM模型更加关注源文的语义信息,从生成的结果可以看出,FAPEM模型对文本内容进行整体理解,关注到了源文中事件的结果信息,生成的摘要更加全面概括源文的内容.从模型生成的摘要可以看出,未出现未登录词的问题,说明将语义信息融合到指针网络有利于缓解生成摘要过程中未登录词的出现.

表3 模型生成的摘要结果Table 3 Summary results generated of models
4.7 消融实验结果
为验证本文所提出模块的有效性,本节对模型的不同模块进行了实验.实验结果如表4所示,其中,MFAM-N表示未使用流注意力机制的并行编码器,MFAM表示使用一个流注意力机制的并行编码器.
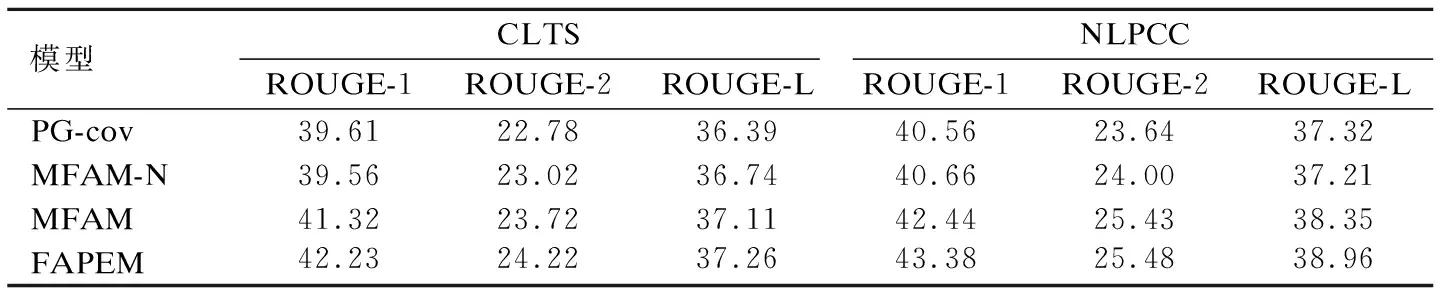
表4 消融实验结果Table 4 Result of ablation experiment
由表4的实验结果可以看出,MFAM-N模型只使用两个Bi-LSTM组合成一个并行编码器,与基线模型相比,MFAM-N模型的部分指标得分略高于基线模型,说明将两个Bi-LSTM组合成一个并行编码器可以有效的关注源文上下文信息.但Bi-LSTM是由双向的LSTM组合而成的,虽然可以同时利用前向和后向的信息,但由于LSTM中存在遗忘门,使得LSTM在进行模型学习的过程中会存在语义信息丢失的问题,因此Bi-LSTM也会存在这种问题,同时,Bi-LSTM存在对输入文本中的全局语义信息提取不够充分的问题,使得模型在训练过程中不能关注到全局语义信息,因此只使用Bi-LSTM对源文进行语义信息学习的过程中会存在全局语义信息损失的问题.因此,为使模型在训练的过程中获取更多源文语义信息,MFAM模型对MFAM-N模型进行改进,通过添加多头流注意力机制加强对源文语义信息的关注,多头流注意力机制可以对输入的文本通过不同子空间捕获源文语义信息,由此可以获取到全局语义信息,然后再输入到Bi-LSTM进行编码,使得模型在训练的过程中更加关注源文的全局语义信息,生成的摘要更加流畅,模型的性能得到进一步的提升.FAPEM模型在MFAM模型的基础上,再次加入流注意力机制对Bi-LSTM编码后的信息进行关注,将并行编码器得到的结果进行融合用于指针概率的生成,用于控制摘要的生成,使得生成的摘要更加准确,从而进一步提升了模型的性能.从表4的实验结果可以得出,并行编码器和流注意力机制均有助于模型学习文本中的信息,二者相结合的方式更加有助于模型关注源文的全局语义信息,使得生成摘要的可读性进一步提升.
4.8 流注意力头数对性能的影响
为验证流注意力头数对模型性能的影响,本节在两个数据集上进行了流注意力头数对模型性能表现的实验.在CLTS和NLPCC两个数据集上的实验结果如图3和图4所示.
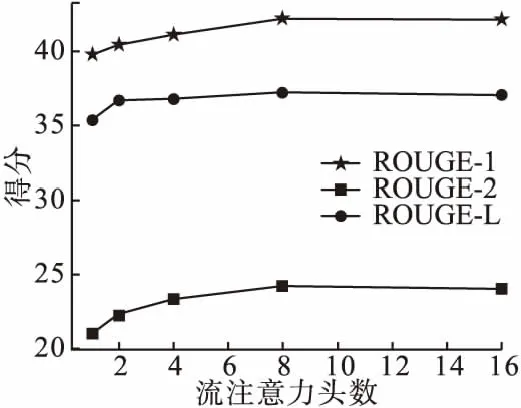
图3 注意力头数在CLTS上的实验结果Fig.3 Results of attention head count on CLTS
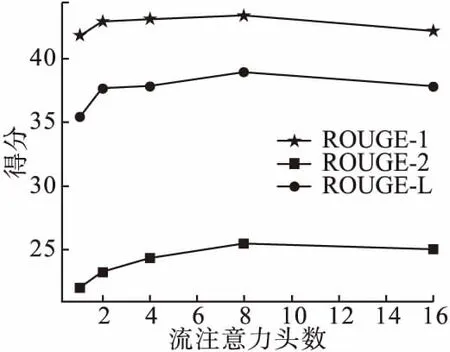
图4 注意力头数在NLPCC上的实验结果Fig.4 Results of attention head count on NLPCC
图3是在CLTS数据集上流注意力的头数对模型性能影响的实验结果.由图3的实验结果可知,随着流注意力头数的增加,模型的评价指标存在一定的上升趋势,但随着流注意力头数的持续增大,模型的部分评价指标趋于平稳.
图4是在NLPCC数据集上流注意力的头数对模型性能影响的实验结果,由图4的实验结果可知,随着流注意力头数的增加,模型的各项评价指标先上升后趋于平稳,随着流注意力头数的不断增大,模型的性能出现下降的趋势.
本文使用多头流注意力的目的是获取更多文本全局语义信息.由图3和图4的实验结果可知,随着注意力头数的增加,模型能够同时关注到文本不同位置上的信息,模型的性能不断增强,评价指标存在一定的上升趋势.但随着头数的继续增加,模型关注到的文本信息不断增多,获取到的信息存在交叉现象,甚至出现冗余的情况,导致模型的性能趋于平稳甚至变差,各项评价指标也会趋于平稳或下降.故从两个数据集上的实验结果综合考虑本文多头流注意力机制的头数.
5 结束语
针对中文摘要生成过程中全局语义信息缺失问题,本文提出了融合流注意力机制的并行编码器模型.首先使用单颗粒的处理方式对源文进行分词.然后,通过流注意力机制捕获源文的全局语义信息,使用并行编码器进行编码.其次,将并行编码之后的结果进行融合,加强模型对全局语义信息的关注.最后,模型在编码阶段引入指针生成网络减少未登录词的出现,使得生成的摘要更加完整.模型在两个数据集上进行实验,实验结果表明,FAPEM模型在所有实验数据集上均表现最优,从而证明了本文所提模型的有效性.
文本摘要生成任务是一项复杂的任务,生成的摘要概括性仍有较大的提升空间,后期会对模型进行优化调整,以改进文本特征的提取方法,使得模型更多的关注文本关键语义信息,生成的摘要更加符合源文的主旨.由于图神经网络能够更好的捕获源文的语义结构信息,未来的工作考虑将图神经网络与现有的模型进行结合,从而提升生成摘要的准确性.
