结合对比学习的新闻文本与评论相似度计算
2023-12-13王红斌
王红斌,张 卓,赖 华
(昆明理工大学 信息工程与自动化学院,昆明 650500) (昆明理工大学 云南省人工智能重点实验室,昆明 650500) (昆明理工大学 云南省计算机技术应用重点实验室,昆明 650500)
1 引 言
随着互联网的发展,网络新闻在各个平台广泛传播.针对某一事件的多方位报道以及对于这一事件的网络舆论就形成了网络新闻,网民可以对新闻内容进行多角度的评论,然而这些评论中有一部分评论与新闻文本有很强的相关性,另一部分评论与新闻文本的相关性较弱.因此通过计算新闻评论与新闻文本的相似度,去除与新闻相似度较低的评论,只保留与新闻相似度较高的评论,对后续的舆情分析以及评论的观点倾向性分析有着重大意义.新闻文本与新闻评论的相关性分析本质上是长文本与短文本的相似度计算,而文本相似度的计算与长文本的表示是该任务的核心内容.文本相似度计算具有代表性的方法主要分为以下3类:基于字符串的方法[1]、基于统计的方法[2]、基于深度学习的方法[3].
基于字符串的方法主要体现在对不同文本进行字符层面的计算,通过分析文本字符串之间的字符共现程度与重复程度,从而得到不同文本之间的相似度.主要使用的方法为编辑距离(Levenshtein Distance,LD)[4],该方法通过随机模型学习得到字符串的编辑距离函数,并结合相似度计算函数解决字符串的相似度分类问题.Xu等人[5]提出与最长公共子序列(Longest Common Subsequence,LCS)[6]进行序列相似性计算的快速并行算法,提高了LCS的计算效率.Kondrak[7]提出了N-Gram,该方法通过窗口提取文本特征,弥补了LCS对上下文不敏感的缺点.Huang 等人[8]结合N-gram将文本分解为二元模型,通过文本之间的共现语块以及顺序结构计算其相似性.Niwattanakul等人[9]通过检测单词中的 Jaccard相似系数用于度量词语的相似性,该方法在计算拼写错误的单词相似性时也表现出了较好的稳定性.
基于统计的方法主要体现在将文本使用假设性分布概率转换为向量表示,通过计算文本向量在向量空间的距离作为文本相似度的度量.基于统计的方法主要分为向量空间模型(Vector Space Model,VSM)和主题模型(Topic Model).Huang等人[10]等人结合单词的词频-逆文档频率(TF-IDF)对文本中的词项进行加权后将文本映射为权重向量,每个权重大小代表文本中每个词的重要程度,最后计算向量间的夹角余弦值得到文本之间的相似度.基于主题模型的方法主要思想是对文本数据进行分析以确定一组文本的主题词,这组主题词能充分表达出文本的内容,通过计算不同文本主题词之间的相似度作为文本的相似度.Landauer等人[11]结合单词的分布假设,通过文本中单词的上下文计算出该单词的向量,使用得到的文本主题分布概率矩阵推导出文本的主题.基于主题模型的方法还包括概率潜在语义分析(Probabilistic Latent Semantic Analysis,PLSA)模型[12]以及隐含狄利克雷分布(Latent Dirichlet Distribution,LDA)模型[13]等.
基于深度学习的方法是指通过训练神经网络模型生成文本向量,以此计算文本之间的相似度的方法.早期具有代表性的方法主要有Word2Vec[14]和GloVe[15]等.Word2vec以大量文本作为输入,并生成一个向量空间,使得文本中的每个唯一的单词都有一个空间中的向量与之匹配.GloVe方法为当前语料库中的所有单词构造共现矩阵,然后从共现矩阵中推导出单词之间的语义关系,最后通过单词的局部上下文关系与全局的词共现关系来获得词向量并进行文本相似度计算.由于单词在文本中的不同位置可能有着不同的含义,Word2Vec或GloVe只能为每个单词输出一个词向量,这种词向量生成方法对下游任具有一定的局限性.为了解决这一问题,近年来集成大规模外部语料知识的预训练语言模型成为了主流的词向量生成模型,常见的模型有ELMo模型[16]、BERT模型[17]等.预训练语言模型充分考虑了输入文本的词序问题,通过引入位置编码并结合上下文的语义,使得同一个单词在文本中不同位置的权重大小不一致,从而实现了动态词向量生成的目的.
随着BERT等预训练模型的提出,基于预训练模型的文本相似度计算方法也取得了比较好的效果.Reimers等人[18]提出了SBERT,该方法使用孪生网络和三重网络,目的是将输入句子通过预训练模型生成大小相同的向量.使用相似度度量,找到语义相似的句子,以此来微调预训练模型.Li等人[19]提出了Bert-Flow,文章指出BERT的语义空间是非光滑的各向异性(non-smooth anisotropic)的语义空间,不利于用于语义相似度计算任务,通过normalizing flows空间转换将其转换为光滑的各向同性的高斯分布来解决这一问题.Yan等人[20]提出了ConSERT,该方法在预训练模型的Embedding层进行数据增强并结合对比学习生成优质的句向量,之后通过计算文本相似度微调模型的参数.
在长文本的处理方面,目前大多是使用基于BERT预训练模型对长文本进行处理,由于BERT预训练模型支持的最大输入序列长度为512,因此使用BERT预训练模型进行文本分类的首要任务是对长度大于512的文本进行处理.Chi等人[21]对长文本使用3种截取操作,分别为截取文本的前510个字符,或结尾510个字符,或前128和后382个字符,实验证明前128和后382个字符的截取方式在文本分类的任务中达到了最佳效果.Sebastian等人[22]提出了一个局部自注意力机制与滑动窗口结合的长文本处理方法,该方法使用滑动窗口将长文本分割为多个有重叠的句子,句子最短长度为窗口大小,然后使用局部自注意力对每个句子进行特征提取,之后采取聚合策略还原长文本的特征.
传统的长文本处理方法存在与文章主题无关的信息占比较大,容易对文本相似度计算造成干扰、只能突出文章的少数主题,针对新闻其他主题的评论识别效果较差、遗漏文章部分信息以及无法筛选出针对这部分新闻的评论等问题.针对以上问题,本文提出了结合对比学习的新闻评论相关性计算方法.该方法通过无监督的方法对新闻文本进行关键词提取,再把新闻标题与得到的关键词序列进行拼接作为新闻文本的表示;接下来使用对比学习的方法构造训练数据的正负样本,并通过相对熵损失函数正则化模型的输出;最后计算出评论与文本的相似度得分.
实验结果表明,本文提出的新闻文本与评论相似度计算方法准确率达到76.28%,较传统长文本处理方法提升了3.6%,并且本文方法在中文语义相似度计算的公共数据集上也取得了较好的效果.
本文的主要贡献包括以下两个方面:
1)提出了利用关键词提取方法对新闻文本进行处理,充分发挥关键词在评论相似度计算中的作用;
2)提出了利用相对熵损失函数正则化对比学习模型的输出,有效解决了dropout后模型输出分布不均匀的问题.
2 模型介绍
本文提出了结合对比学习的新闻文本与评论相似度计算方法.首先对新闻文本进行分词和词性标注等处理,使用正则表达式生成候选关键词,通过文本分句后计算候选关键词与文本的相似度,提取出新闻文本的关键词,该步骤的目的是减小新闻文本长度,使其满足预训练模型的输入长度要求,同时去除文本中的冗余信息;然后将新闻文本的关键词序列与新闻标题进行拼接得到新闻文本的表示;接下来利用无监督对比学习的方法,将同一篇新闻的关键词和标题序列传递给BERT预训练模型的编码器两次,通过应用独立采样的dropout mask获得两个作为正样本的嵌入,同时将同一个batch里剩余新闻(关键词和标题序列)的两次嵌入作为负样本;最后通过交叉熵和相对熵损失函数对预训练模型进行微调.模型结构如图1所示,整个模型分为两个部分,即新闻文本关键词提取和评论与新闻文本的相似度计算.
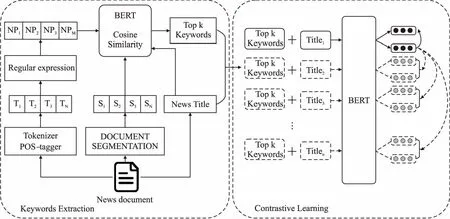
图1 模型结构图Fig.1 Structure of model
2.1 关键词提取
为使文本输入满足BERT预训练模型的输入序列要求,本文用新闻标题与关键词的拼接序列作为新闻文本的表示,模型的输入为完整的新闻文本,输出为k个关键词与新闻标题的拼接序列.首先对新闻文本进行分词、去除停止词和词性标注操作,将新闻文本拆分为带有词性标注的词序列W=(w1,w2,…,wn),然后使用正则表达式对相邻位置的形容词与名词、名词与动词等进行拼接,组成名词短语,将这些短语作为候选关键词NP=(NP1,NP2,…,NPi).
因为新闻文本的长度远远大于BERT模型的最大输入长度,同时为从候选关键词中筛选出新闻文本的关键词,还需对新闻文本进行分句.本文设置MSL(minimum sequence length)为最小序列长度,将新闻文本分成大于或等于MSL的m个句子S=(S1,S2,…,Sm),通过分句解决了BERT预训练模型输入长度的限制,提高了模型的计算效率.
由于文档被分为m个句子,模型失去了文档的完整上下文语义,会影响模型的性能.同时,由于BERT预训练模型的self-attention机制,同一个词在不同的语境有着不同的词嵌入.因此,本文使用嵌入对齐的方法来保持文本的上下文语义以及获取候选关键词NPi的词嵌入.候选关键词NPi的词嵌入如公式(1)所示:
(1)
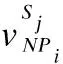
得到关键词候选集NP和新闻文本的句子集S后,计算关键词与新闻文本的相似度:对于每个候选关键词NPi,通过公式(2)计算单个候选关键词与文本的相似度:
(2)
(3)
公式(2)中,VNPi表示关键词NPi的词向量,Vd表示文档的向量,VSj表示第j个句子的向量,本文使用当前关键词与文章所有句子的余弦相似度的和作为当前关键词与新闻文本的相似度.
对于关键词候选集里的所有关键词,通过公式(2)得到每一个关键词与新闻文本的相似度,最后将相似度通过softmax并结合关键词与新闻标题的相似度,得到所有关键词与新闻文本的相似度.如公式(6)、公式(7)所示:
St=sim(VTitle,VNPi)
(4)
Sd=sim(Vd,VNPi)
(5)
SNPi=φSt+(1-φ)softmax(Sd)
(6)
(7)
其中,VTitle表示新闻标题的向量,φ是超参数,本文取值为0.5,本文认为标题涵盖了新闻文本的主要内容,通过引入φ使最终得到的关键词与标题的相关程度更高.得到候选关键词与新闻文本的相似度后,选取相似度最高的k个词作为新闻文本的关键词.最后本文将新闻标题与提取的k个关键词拼接得到的文本作为新闻文本的表示D,如公式(8)所示:
D=title⊕w1⊕…⊕wk
(8)
其中,title表示新闻文本的标题,w表示关键词,⊕表示拼接操作.通过关键词序列与标题拼接,从而在保留新闻文本有效信息的情况下,将较长的新闻文本转换成较短的文本.
2.2 新闻文本与评论相似度计算
经过关键词提取后,本文把新闻长文本缩短为由标题与关键词的拼接序列,该序列的长度满足BERT模型的输入要求,可以直接用于训练.为了实现无监督的新闻文本与评论相似度计算,本文使用对比学习方法对BERT预训练模型进行微调.
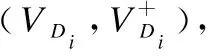
(9)
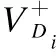
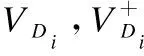
(10)
loss=Li+Lk
(11)
模型训练完一个batch的数据后,使用当前模型对新闻文本(标题与关键词序列)和对应的评论进行编码,然后计算向量相似度作为评论与新闻文本的相似度,最后通过设定的相似度阈值对评论进行筛选.
3 实验结果与分析
3.1 实验数据集
由于现阶段公开的新闻文本与评论相关性分析的公共数据集数量较少,因此本文使用爬虫工具从主流新闻媒体网站爬取新闻文本和与之对应的新闻评论,所爬取的新闻文本涵盖科技、社会、时政、体育、财经等10个领域.取得数据后本文对新闻评论进行标注,标签“0”表示评论与新闻相关性较弱,标签“1”表示评论与新闻相关性较强,针对新闻文本中出现的人物、描述的事件、该事件发生的地点以及所涉及的社会机构等表达出主观态度的评论与新闻的相关性较强,反之相关性较弱.本文的训练集数据为10000篇新闻文本,验证集与测试集分别为10个领域的30篇新闻文本,每篇新闻平均对应200条评论,评论总数为6000条,验证集中标签为“1”的评论3083条,标签为“0”的评论2917条;测试集中标签为“1”的评论2858条,标签为“0”的评论3142条.数据集分布如表1所示.
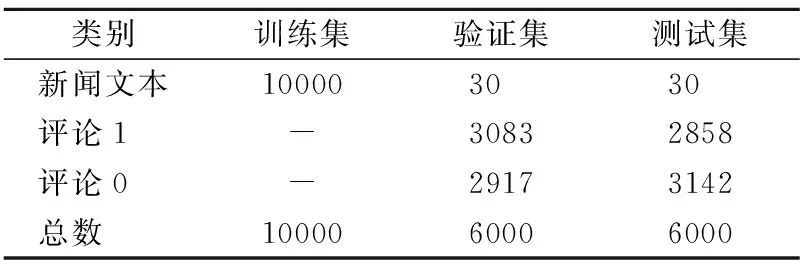
表1 数据集分布Table 1 Distribution of data set
在模型的训练过程中,由于本文使用新闻文本实现正负样本的构造,所以训练集只有新闻文本,而没有新闻评论.验证集与测试集的作用为:当模型训练完一个batch的数据后,使用模型计算验证集里的评论与新闻文本的相似度,并使用准确率对模型效果进行检验;当模型计算出当前评论的得分高于准确率阈值时,判定当前评论为正样本,反之为负样本;最后保存准确率最高的模型,训练结束后使用测试集对该模型的效果进行测试.
3.2 评价指标
在该任务中,因为正负样本的比例接近1:1,所以使用准确率(Accuracy)作为评价指标,准确率计算公式如公式(12)所示:
(12)
其中TP表示模型判断为与新闻文本相关并且标签为“1”的评论数,TN表示模型判断为与新闻文本不相关并且标签为“0”的评论数,Total表示评论的总数.
3.3 参数设置
本文设置的文本最大序列为120,batch size为64,学习率为1e-5,关键词数量为30,相似度阈值为0.3,超参数τ取值为0.05,训练时使用相对熵与交叉熵损失函数微调BERT模型的参数.
3.4 实验效果
本文在4个中文预训练模型上进行实验效果对比,中文预训练模型分别为BERT-wwm[24]、BERT-wwm-ext[24]、 RoBERT[24]和RoBERT-large[24],实验效果如表2所示.其中cls向量为BERT预训练模型编码器隐藏层的最后一层输出向量,pooler向量为在cls向量基础上进行线性变换得到的向量,last-avg向量为编码器隐藏层最后一层的所有向量取平均值得到的,first-last-avg向量为编码器隐藏层的第一层与最后一层的输出向量取平均值得到的.从表2可以看出,在4种输出向量中BERT-wwm-ext的cls向量效果为74.33,BERT-wwm的pooler向量效果为73.63,RoBERT-large的last-avg向量效果为75.23,RoBERT的cls向量效果为76.28,所以RoBERT的cls向量取得了最好的效果.
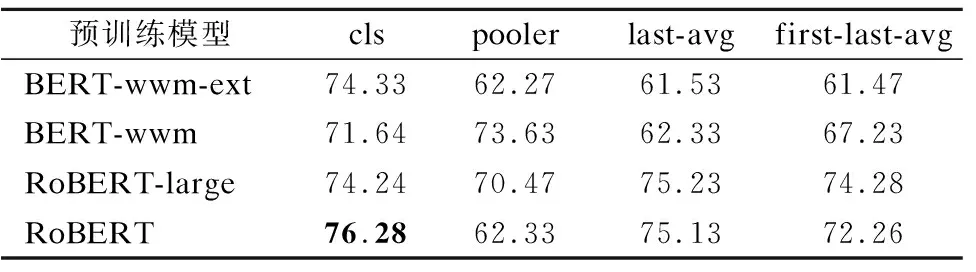
表2 不同预训练模型的实验结果Table 2 Experimental results of different pre-training models
本文通过对比学习的方法,在训练过程使用dropout实现正负例的构建,并在每一个batch训练结束后使用验证集检验模型效果,模型训练开始与结束时验证集前1000条评论的分布情况如图2所示.通过图2可以看出,灰色为标签为“0”的样本(与新闻文本不相关的评论),黑色为标签为“1”的样本(与新闻文本相关的评论),中间为圆心在原点且半径为相似度阈值的圆,本文使用参数方程将正负样本投影到坐标系上,样本与圆心的距离为样本与新闻文本的相似度.
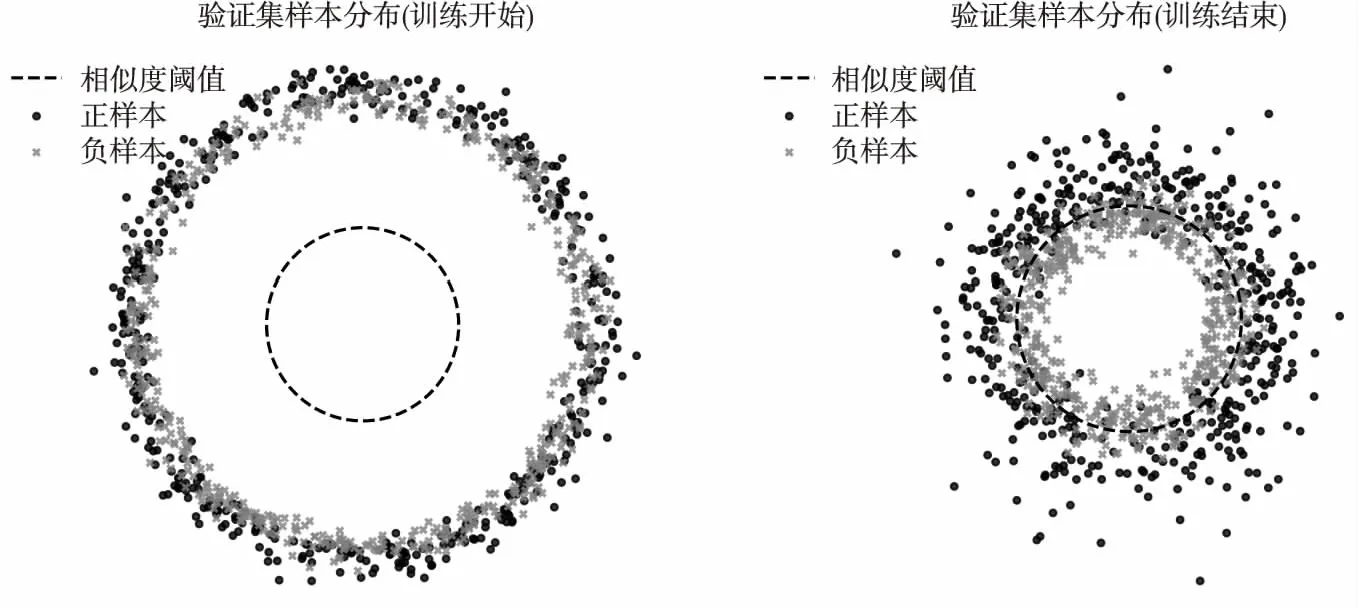
图2 验证集样本分布情况Fig.2 Sample distribution of the validation set
在训练开始时,正负样本为均匀分布,并且距离较近,说明负样本的相似度较高,此时不利于分类;随着训练进行,正负样本之间的距离逐渐拉远,并且负样本靠近圆心的速度快于正样本,且部分正样本距离变化较小,说明负样本的相似度下降速度较快,而正样本的相似度下降速度较慢,从而实现拉远正负样本之间的距离.
3.5 消融实验
本文使用了关键词与标题拼接作为长文本的表示,因此与3种长文本处理方法作为对比,以此证明本方法的有效性.3种方法说明如下:
文本等长分句[21]:对新闻文本进行等长、不重复的句子切分,将切分后的多个句子通过预训练模型得到句子的向量,然后通过池化处理组合句子向量,得到文本的向量表示.
截取方法[21]:截取文本的前510个字符,或结尾510个字符,或前128个字符和后382个字符,文本的剩余部分全部丢弃,只用截取的部分作为文本的表示,然后使用预训练模型提取文本的特征.
滑动窗口方法[22]:文章提出了一种基于局部自注意力机制的滑动窗口,并且每个词向量只关注同一窗口中的其他词向量.在整个文档上,这种局部注意力只会带来一部分计算和内存注意力成本,节省存储空间.最后使用一个学习过的饱和函数和两个阶段的池化策略得到文本的表示.实验结果如表3所示.

表3 消融实验Table 3 Ablation experiment
实验结果说明:本文提出的关键词和标题拼接的长文本处理方法在准确率评价指标下取得了最佳效果,证明了该方法的有效性.因为大部分评论都是针对新闻文本的某一个或者两个点做出的评价,而新闻的关键词可以有效的涵盖评论针对的对象,所以关键词提取可以达到不丢失新闻文本的主要内容同时识别出多数评论.
其他方法效果不佳的原因在于:文本截取只提取出文章的开头和结尾两个部分,忽略了中间的内容,容易遗漏文章部分信息,无法筛选出针对这部分信息的评论,所以该方法效果最差.
文本等长分句会导致与文章主题无关的信息占比较大,原因在于分句长度过长时,文章的冗余信息过多,从而无法突显出文章的主题,造成文章主题不明确.在之后的特征提取时,模型不能有效地提取文章主题特征,导致模型在计算与文本不相关的评论时效果不佳;滑动窗口解决了前两种方法的不足,既考虑了整篇文章的信息,又降低了文本不相关信息的比重,但是经过池化处理后,滑动窗口只能提取出文章的部分主题,从而无法有效地针对部分与文本相关的评论.
3.6 参数对实验结果的影响
3.6.1 关键词数量对实验结果的影响
由于本文对新闻文本进行关键词提取处理,因此提取的关键词个数对实验结果影响较大,图3展示了不同关键词数量的实验效果.
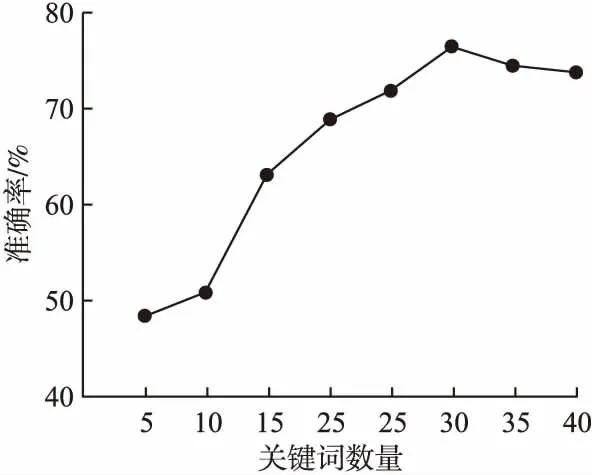
图3 不同关键词数量的实验结果Fig.3 Experimental results of different number of keywords
从图3可以看出,关键词数量为5时,模型的性能最差,随着增加关键词数量,模型的性能也有较大提升;当关键词数量达到30时,模型性能达到最佳;当关键词数量为35时,模型性能开始下降,原因在于多出的关键词与文章的主题无关,但是这些关键词与负样本的相似度较高,导致模型将负样本判断为正样本,所以关键词数量过多会降低模型的性能.因此,本文的关键词数选取为30.
3.6.2 相似度阈值对实验结果的影响
本文使用准确率作为模型的评价指标,所以相似度阈值的选择会对结果产生较大的影响,图4展示了不同的相似度阈值的实验效果.
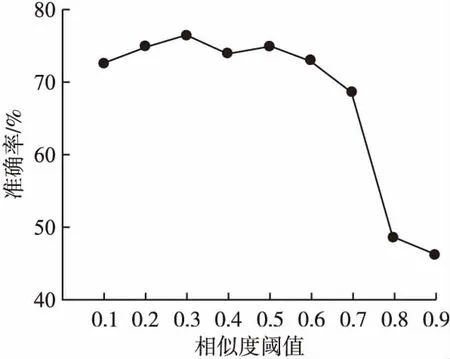
图4 不同相似度阈值的实验效果Fig.4 Experimental results of different similarity threshold
从图4可以看出,相似度阈值取值为0.3时,模型效果达到最优;当相似度阈值为0.1与0.2时,效果不佳,原因为相似度阈值过低,部分负样本的相似度无法降低到阈值之下,导致模型将相似度高于阈值的负样本预测为正样本;当相似度阈值取值为0.8与0.9时,模型性能最差,原因为大部分正样本的相似度小于此时的相似度阈值,模型将相似度低于阈值的正样本预测为负样本.因此,本文的相似度阈值设置为0.3.
3.6.3 参数τ的取值对实验结果的影响
本文引入参数τ来提升模型效果,适当的τ值可以帮助模型从正负例中学习,因此通过调整参数τ的大小来验证该参数的重要性,实验结果如表4所示.

表4 不同τ取值的实验结果Table 4 Experimental results of different τ values
从表4可以看出,不同的参数τ对实验结果影响较大,选择适当的取值会使模型性能明显提升.因此本文参数τ的取值为0.05.
3.7 公共数据集上的实验
为了检验本文方法的泛化能力,本文在BQ[25]、STS-B[26]、PAWSX[27]和ATEC(蚂蚁金服金融领域语义相似度计算数据集)4个中文语义相似度计算公共数据集上进行了对比实验.同时,本文与最近几年的无监督语义相似度计算模型进行了对比,从而说明本文模型性能的优越性.实验对比的模型为Sentence-Bert、SimCSE和Bert-whitening模型,下面对这3种模型进行介绍.
Sentence-Bert(Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks)[18],由Gurevych等人提出孪生网络和三重网络,目的是将输入句子通过预训练模型生成长度相同的向量.使用相似度度量,找到语义相似的句子,以此来微调预训练模型.
SimCSE(SimCSE:Simple Contrastive Learning of Sentence Embeddings)[23],由Gao等人提出,核心思想是使用dropout来构建样本的正负例,通过对比学习使相似的样本距离更近,不相似的样本距离更远.
Bert-whitening(Whitening Sentence Representations for Better Semantics and Faster Retrieval)[28],由Su等人提出,核心思想是通过传统数据挖掘中的白化操作,构建数据的协方差矩阵,使用新的坐标基实现对文本向量的降维处理,加快向量的检索速度,同时达到了较好的效果.
因为目前大部分无监督语义相似度计算的模型在公共数据集上使用的是spearman相关系数评价指标(只依赖于预测分数与标签的相关性,并且不依赖于阈值),所以本文在公共数据集上也使用spearman评价指标,并且所有实验的预训练模型为RoBERT.实验效果如表5所示.
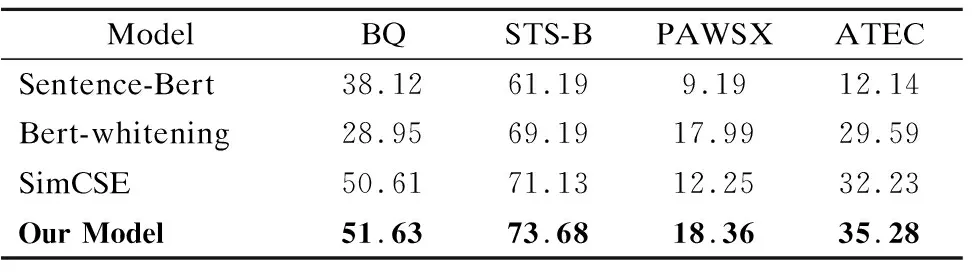
表5 公共数据集上的实验Table 5 Experiments on public data sets
从实验结果可以看出,本文提出的方法在4个语义相似度计算公共数据集上均达到了最优的效果.在使用相同预训练模型的条件下,该模型与使用了dropout方法的SimCSE模型相比,在4个数据集上分别提升了1.02%、2.55%、6.11%和3.05%,充分证明了使用相对熵损失函数正则化对比学习模型的输出的有效性.
4 结束语
本文针对新闻文本与评论的相似度计算,提出了一种结合关键词提取的对比学习文本相似度计算方法,该方法利用关键词提取对新闻文本进行压缩,使新闻文本满足预训练模型输入要求,同时减少新闻文本中的冗余信息.由于缺少新闻文本与评论的相关性计算数据集,本文提出的方法并没有用到大规模的新闻文本与评论数据,而是基于BERT预训练模型,使用dropout方法构造训练数据的正负例,最后通过对比学习以及相对熵损失函数对预训练模型进行微调.实验结果证明本文提出的方法对于新闻文本与评论的相似度计算有很好的效果,通过合适的关键词数量与标题拼接可以提高相似度计算的准确率.在公共数据集上实验验证,本文的方法也取得了较好的效果,说明该方法不仅适用于新闻文本与评论数据集,而且也具有一定的泛化能力.
