渝东南多语地区语言类型学形式验证的科学视角
2023-12-12王小穹
王小穹
(重庆理工大学 外国语学院, 重庆 400054)
当代语言学最重要的三大理论流派是形式语言学、功能语言学和语言类型学[1]18,[2]1。寻求人类语言的普遍规律是这三者共同的理论追求。在寻找人类语言的共性和差异的道路上,形式语言学强调语言天赋的自主生成性,功能语言学强调语言交际使用、社会因素等语言外部因素的影响,而语言类型学则没有形式语言学和功能语言学那样明确的语言内或语言外的语言观。语言类型学家们在进行语言类型研究前就基本认定了语言之间既有共性也有差异。
关于语言的共性和差异,有些与语言系统本身有关,有些则与语言系统之外的因素有关。语言类型学追求的终级目标是语言的共性,即寻求语言和语言之间的差异本质上是由哪些极其有限的共性因素造成的。语言类型学的中心任务是在承认差异的基础上,致力于研究丰富多样的结构变化并探求人类语言的内在统一。因此,语言类型学家需要尽量多地考察不同的语言,需要使用数据统计、逻辑推理归纳等多种分析手段概括人类语言的正偏态分布、寻找影响语序优势的因素,以及阐述、回答、预测人类语言的结构倾向。语言类型学的研究宗旨体现了语言类型研究的交叉属性。
渝东南地区地处乌江流域下游、武陵山腹地,与黔、湘、鄂等省结合相连,是我国历史上土司管辖的边陲区域,也是宋、元、明、清时期中原移民躲避战乱的藏匿之所。该地带语言生态丰富,因多民族分布及语言接触的历史层次复杂深刻等特点,被现今学界称为武陵民族走廊。该地区主要以土家族、苗族等少数民族聚居区为主,语言多属于汉藏语系的苗瑶语族和壮侗语族。本文以渝东南民族多语地区的土家语材料为基础结合世界其他地区的语言,尽可能多地占有不同类型的语言材料,从语序类型、形态类型以及语言类型的逻辑验证等三大核心板块勾勒语言类型学的科学面貌,为人类语言的类型研究提供理论和实践参考。
一、语序类型
语序涉及到现实语言中S、V、O等3个主要成分,由形态研究转向语序研究是传统类型学发展为现代类型学的重要标志。语序,其英文表达是word order,直译成汉语是“词序”,汉语“词序”的概念仅涉及词与词之间的顺序,没有考虑到比词更小的语素顺序,也没有考虑到比词更大的短语和小句等结构单元的顺序,而语言类型学的word order是用来表达语言结构成分之间的先后顺序的,为了正确理解word order包含的类型学意义,学者们皆把word order表述为“语序”[3]。语序这一术语最早由Greenberg提出[3],语序在当时没有得到太大的重视,但这一概念引发了语言学界有关验证人类语言特征的深入思考,为今天的语言类型学研究奠定了坚实的基础。
(一)基本语序
语言类型学家们着眼于“基本”,将语言的基本语序标准归纳为语用中性(Pragmatic Neutrality)、频率(Frequency)和标记(Markedness)。Siewierska指出,句子的语用中性表现为:语序不依赖具体语境,主语是确定的有生命的施事,宾语是语义受事,动词是可及物的动作行为。具有语用中性特点的直陈句子往往没有特定的语用功能,被优先视为基本语序[4]8;频率和标记[2]88,[5]12-16是衡量基本语序的另外两个标准,频率越高越被优先视为基本语序,无语法标记和无分布标记比有语法标记和有分布标记的被优先看作基本语序。
语序除了指S、V、O这三者的顺序外,还指小句内其他成分之间的语序。在名词层面上,主要有:形容词与核心名词的语序(AN/NA)、指示词与核心名词的语序(DemN/NDem)、领属词与核心名词的语序(GN/NG)、数词与核心名词的语序(NumN/NNum)、关系小句与核心名词的语序(NRel/RelN)、复数词与核心名词的语序(PlurN/NPlur),以及介词与名词的语序(PrepN/NPrep/PrepNPostp)等等。在实际语料中,名词常常带有几个修饰语,而充当修饰语的代词、指别词、数词、形容词、名词等等多项定语也需要遵循一定的规则排序。渝东南地区的土家语,不同于汉语普通话,核心名词和修饰性成分的语序是核心名词在前,修饰性成分在后,如:
例(1) a. jie35│bi35小手
手│小
b. ji21│bi35小脚
脚│小
c. wu35│bi35 小牛
牛│小
d. re53│bi35孙儿
孙│小
以上土家语名词后面的修饰性成分bi35表示“小”和“儿”,置于核心名词“手”“脚”“牛”“孙”之后。
在动词层面上,主要有:否定小词与动词的语序(NegV/VNeg)、介词短语与动词的语序(VAdpP/AdpPV)、助动词与主要动词的语序(AuxV/VAux)、系动词与述谓词的语序(CopPred/PredCop)等等。
在词的形态层面上,词内部语素间的顺序也按规则排列,名词有“格—数—词根”与“词根—数—格”,动词有“人称—语态—时—体—词根”与“词根—体—时—语态—人称”的镜像对立式的排序。而渝东南地区土家语名词的词内部语素间的顺序,兼具两种镜像对立式的排序,如:
土家语亲属称谓的词根前有时加词缀a21或an55,词内部语素间的顺序是“词缀—词根”:
例(2) a. a21-ko53哥哥
PREF-哥
b. a21-da53姐姐
PREF-姐
c. an55-ngai53弟弟
PREF-弟
d. an55-bai55叔叔
PREF-叔
但是,在表示动物的生理雄性(不同于形态语言的阳性)时,雄性词缀ba53和雌性词缀ni21ga21皆分别置于词根后。词内部语素间的顺序是“词根—词缀”,如:
例(3) a. wu35│wu35-ba53公牛
牛│牛-SUFF
b. wu35-ni21ga21母牛
牛-SUFF
可见,土家语名词语素的顺序兼具了“词缀—词根”与“词根—词缀”这两种镜像对立式的排序特点。
(二)共性原则
以Greenberg为代表的语言类型家们基于30种语言样本,并结合观察30种语言之外的大量语言,归纳出45条可能的共性原则(Universal Grammar,简称“GU”),Greenberg的GU原则有如下特点:
其一,语序原则是最重要的原则,45条原则中有25条与语序相关。例如Greenberg的共性原则中的GU1、GU2、GU17(1)文中所列的语言共性规则(GU)均来自In Universals of Language(Greenberg 1963)书后附录,故下文不再专门标注页码。:
GU1:有S和O的陈述句,优势语序是S在O之前。
GU3:VSO语言往往使用前置词。
GU17:VOS语言的形容词在名词之后。
Greenberg构建的共性原则都是无例外的,其目的在于发现严格条件下人类语言的变异。他指出,如果语言类型学家的首要任务是定义人类语言,那么就必须努力去寻求人类语言的无例外共性。
其二,语言类型学的共性原则采用逻辑蕴含形式“⊃”来表达事物之间单向的不可逆的相关关系,如GU25。
GU25:如果代词宾语位于V之后,则名词宾语一定位于V之后。
Greenberg的GU25以代词宾语位于V后为前提,说明了V与O的排序,但这条标准却并没有说明如果代词宾语位于V前时名词宾语的排序情况,因此其共性原则是不能保证事物间的双向关系的。而事实上,我们也发现很多语言的代词宾语前置于V前时,名词宾语是放在V后的。如,同为罗曼语族的法语、西班牙语和意大利语,这些语言的代词宾语放在V后面时,名词宾语都不会前置于V前,这就是为什么Greenberg蕴含共性原则只能是“p⊃q”而不是“q⊃p”。
其三,主张以不同视角来设定语序参项。为了推测未知语言的语序,Greenberg语序类型的普遍规则GU3、GU4就是通过语序参项的设定而得出的:
GU3:VSO语言往往使用前置词。
VSO语序的语言很少见,学界常以不列巅岛西南的Welsh[6]3为例:
例(4) a. Gwelodd│y│bachgen│ddyn│ddoe
saw│the│boy│man│yesterday
“The boy saw a man yesterday.”
b. trwy│Gaerdydd
through│Cardiff
“through Cardiff”
在例(4)中,a例展示了Welsh语是动词前置语言,b例反映了Welsh语只使用前置词。
GU4:SOV语言倾向于使用后置词。
渝东南地区的土家语为SOV语序的语言,如:
例(5) a. la35qie55│hu21 喝一次
一 次│喝
b. po21pa55│re35│hu21父亲喝酒
父亲│酒│喝
c. nga35│bi35zi55ka53│sou35 我是土家族人
我│土家族人│是
例(5)中,c句的土家语本无判断词,在借用了汉语“是”后,早期土家语的判断词按语序被置于O后,但是,现在的土家语由于受汉语影响越来越大,判断句已经由SOV变成SVO语序了。如:
例(6) nga35│sou53│bi35zi55ka53我是土家族人
我│是│土家族人
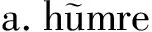
man│PST│dog│beat
“The man beat the dog.”
b. pur│kam
field│in
“in the field”
Greenberg用语序参项来推断旁置词adpositions(前置词prepositions和后置词postpositions)的分布,见上文GU3、GU4,而旁置词的分布也可用来推断属格与中心名词的位置,如GU2。
GU2:使用前置词的语言,领属语几乎总是后置于中心名词,而使用后置词的语言,领属语几乎总是前置于中心词。
根据该条规则,不列巅岛的Welsh语只使用前置词,则领属语就该是置于中心名词之后的,而南美洲的Canela-Krah语只使用后置词,则领属语应该是置于中心名词之前的。
其四,阐释语素排列与语序的关系,扩展语序类型学的研究范围,如GU27。
GU27:仅后缀语素的语言使用后置词,仅前缀语素的语言使用前置词。
现调查到的只有后缀语素或只有前缀语素的语言很少见,渝东南地区的土家语是使用后置词(PP)的语言,但是据前文所述,渝东南地区的土家语既有前缀语素又有后缀语素。如:
例(8) a. ni35│ke35-lie55│en21ji35?您从哪里来?
您│哪里-PP│来
b. nga35│long35san55│lie55│en21ji35我从龙山来。
我│龙山-PP│来
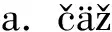
horse-NOM│it run-PST│field-in
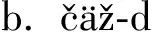
horse-NAR│it run-PST│field-in
“The horse ran in the field”
当今语言类型学的研究以形态语言为研究材料,将旁置词(包括前置词和后置词)参项和VO/OV参项视为确定语序原则的两个最基本的参项。但实际上,这两个参项并不同时适用于所有语言,比如渝东南地区的汉语方言、土家语、苗语和世界上大部分语言一样,其语序缺少旁置词参项的限制,而是主要受VO/OV参项的制约。
二、形态类型
形态类型关注词的结构以及词形变化所反映的语法范畴类型,是比语序类型更早的类型学研究。早期的类型学家根据词的形态把世界上的语言分成4种类型:屈折语、孤立语、黏着语和复综语。这种按词形变化程度的形态学分类曾在19世纪和20世纪初处于主流地位,之后一度被诟病,但形态学以世界上某个/某些普遍性语言形态作为研究参照的研究范式,仍然是语言类型学研究的核心内容之一。目前,语言类型学在形态类型方面的成果主要是格范畴和一致关系。
(一)格范畴模式
格范畴也称“格标记(Case Marking)”,反映的是名词、代词的语义角色或语义地位。Mallionson和 Blake从SOV语言中取样41种,发现有34种格标志语言[8],Siewierska从SOV语言取样69种,发现格标志语言49种[9],这些格标志归纳起来分为4类:主受格模式(Nominative-accusative)、施通格模式(Ergative-absolutive)、三分模式(Tripartite)和活动模式(AP/S)。语言类型学将S、A、P定义为格标志的3个语法—语义基元:用斜体S区别于sentence的S,代表不及物动词唯一的核心论元,是不及物句子的逻辑主语;A代表施事,是及物句子的逻辑主语;P代表受事,是及物句子的逻辑宾语。如:

图1 格标志的5种逻辑组合
1.主受格模式
主受格模式的语言,A、S使用相同的格标记,P使用不同的格标记。如英语:
例(11) a. He│bought│them.
he-NOM-A│bought-PST│them-ACC
b. He│smoke│again.
he-NOM-S│smoke-PST│again
上例a 句“he(A)”“them(P)”,b句“he(S)”,其中A、S同格,P使用了不同的格形式。
2.施通格模式
A使用有别于P、S的格形式,且P、S使用相同的格形式。Blake[10]8发现澳洲的Yalarnnga语就是一种施通格语言,如:
例(12) a. ŋia│waka-mu
I-NOM-S│fall-PST
“I fell.”
b.kupi-ŋku│ŋja│taca-mu
fish-NOM-ERG-A│me-ACC-P│bite-PST
“A fish bit me.”
在例(12)a中,不及物动词的主语S和b句中动作行为的受事P都使用了相同的ŋia,而b句的施事“kupi(A)”使用了有别于S、P的格形式-ŋku。
3.三分模式
三分模式指A、S、P分别使用不同的格标志形式,以三分模式为格标记的语言很少,澳洲的Wangkumara土著语[8]1-50, [11]125常用来作为分析的例子。如:
man-NOM-ERG-A│hit-PST│dog-F-ACC-P
“The man hit the bitch.”

man-NOM-S│die-PST
“The man died.”
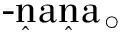
4.活动模式
活动模式是极少数语言用到的格标志模式,这些语言因为使用不同的时态,名词的格标志会发生从X到Y的变化。Comrie[11]125曾发现伊朗境内有一种叫鲁斯兰语(Rushan)的语言,这种语言正在从早期的施通格模式向主受格模式迁移,这种变化仅需改变名词性成分的形式。帕米尔语是鲁斯兰语的原型语言,原型帕米尔语只有直格(Direct)和旁格(Oblique),这两个格根据现在时和过去时采用不同的形式,即,现在时的情况下使用主受格模式(AS/P),过去时的情况下使用施通格形式(A/SP)。鲁斯兰语在过去时的情形下,A、P各自使用不同的格标志,S有时与A同格有时与P同格,在A、P之间流动。
(二)一致性原则
在SOV、SVO、VSO、VOS、OVS和OSV这6种基本语序中,格标记是确定名词性论元的标志,是鉴别施受等语义关系的极其重要的语法范畴,而缺乏或没有格标记的语言,施受关系则需要借助词形变化和使用功能词等其他方式来辨别。6种基本语序中有4种语言(SOV、VOS、VSO、OSV)的S、O是彼此靠近的,如果不使用格标志的话,常常难以辨别施受关系,因此有形态标记的语言都倾向使用格标记将名词性成分的论元区分开来,例如:
例(14)VOS型
ASP-TER/SG-TER/PL-ate│clothes│rats
“Rats ate the clothes.”
例(15)SOV型
Boku ga│tomodati ni│hana o │ageta.(日语)
I-NOM│friend-DAT│flowers-ACC│gave
“I gave flowers to my friend.”
Tzutujil语的动词位于句首,动词词根-tij前的-ø和-kee既表示动词和名词之间的语法功能和语义关系,也用来表示名词的人称和数,但由于后面的两个名词都没有格标记,其施受论元不容易区分,只能通过语境来判断。上例日语中的名词后面的ga、ni、o分别表示前面的名词论元为主格、与格和宾格,格标记较为清晰。
SVO、OVS是S和O之间有其他成分隔开的语言,尽管这两种语序的语言有V将名词性成分前后分开,但不少语言也要使用格标记。就SVO来说,它们对格标记的使用分3种情况:第一种,不使用格标记,如汉语;第二种,部分使用格标记,如英语;第三种,使用格标记,如波兰语。在汉语“张三打李四”和“李四打张三”中,“张三”“李四”这两个名词性成分没有可见的施受标记。在英语“The man laughed at woman”和“The woman laughed at the man”中,“man”和“woman”也没有可见的施受标记,可是在“He laughed at her”和“She laughed at him”中,则按论元所属语义角色的格范畴类型分别使用了主格he/she和宾格him/her。波兰语名词性成分的论元角色都带有格标记,如:
例(16)SVO型
lost-PRI/SG-PST│man-TER/SG-ACC│who-GEN│love-PRI/SG
“I lost the man I love.”
波兰语宾格位置上的名词一定会采用相应的宾格形式。上例facet为阳性名词,在句中作宾语,词缀-a是阳性名词作宾语的宾格标记。而且,如果作宾语的名词前有形容词,即“形容词+名词”作宾语,名词的宾格也决定其前面的形容词要用宾格,这就是格范畴的一致性原则。如:
例(17) a. On│ma│sympatyczną│matk.(波兰语)
he│has│affable-F-SG-ACC│mother-F-SG-ACC
b. Ja│mam│dobrego│brata.
I│have│nice-M-SG-ACC│brother-M1-SG-ACC
you-SG│have│nice-M-SG-ACC│dog-M2-SG-ACC
we│have│nice-M3-SG-ACC│car-M3-SG-ACC
they│have│small-N-SG-ACC│child-N-SG-ACC
格关系保持一致只是格范畴一致性的内涵之一,格范畴的一致性还包括形容词在性、数等其他语法范畴方面也要与所修饰的名词保持一致。如上例a句matk是阴性名词,其前面的形容词sympatyczny后面的词缀-ą,就是形容词的阴性标记;b、c句的名词brata、psa分别是一类阳性和二类阳性名词,其前面的形容词dobry、adny后面的词缀-ego就是阳性标记;而d、e句的samochód、dziecko分别是无生命阳性名词和中性名词,其前的形容词则采用了原形形式,即,零性或中性标记。
修饰名词的形容词在数的范畴上也要与名词保持一致。上例名词是单数,故前面的形容词也是单数,如果作为中心语的名词是复数,那么修饰名词的形容词也必须用复数。如:
例(18) a. sympatycznym│nauczycielem(波兰语)
affable-M-SG-INSTR│teacher-M-SG-INSTR
b. sympatycznymi│nauczycielami
affable-M-PL-INSTR│teacher-M-PL-INSTR
在例(18)a句nauczyciel是阳性名词工具格的单数,前面的形容词sympatyczny除了用阳性工具格形式外,也是单数形式,b句nauczyciel后面有复数标记-ami,它前面的形容词sympatyczny也必须加上复数标记-(m)i的词缀。
三、语言类型的逻辑验证
语言类型学研究不同类型语言的语法特点并对语言共性加以概括。语言共性涉及语言的共享特征,有非限制性共性和限制性共性两种表述类型。语言共性用来说明给定范围内的语言特性的完全分布,具有周遍性质,如:
A.所有的语言都有元音。
B.对于所有的语言,如果有浊音b,那么一定也有清音p。
A涵盖了所有语言的共性,是最简单最具有预测性的表述类型,属非限制性共性,也称非蕴含共性。B除了给定周遍性范围外,还给定了共性表述的限制条件,让我们可以辨明某个语言子集的存现有确定无疑的分布,这就是限制性共性,也称蕴含共性。现代语言类型学最突出的贡献就是把古典类型学对不同语言要素的相关性观察变成了明晰的蕴涵性共性[12]29。蕴含共性理论在经历了半个多世纪的构建后,逐渐形成了一套科学的推导方式,致力于对世界语言的类型进行形式逻辑上的验证。
(一)四缺一逻辑表达式
Greenberg以30种语言为调查对象,建立了许多与语序有关的重要共性。Greenberg得到的蕴涵性共性有两种逻辑表达形式,一种是蕴涵性命题,一种是四缺一逻辑模式。
逻辑学中的蕴含命题是这样的:如果A,那么B。有A则有B,有B则不一定有A,A是B出现的充分条件。例如:如果下雨了,那么地面是湿的。下雨是地面湿的充分但不必要条件,原因是,如果不下雨,地面也可能是湿的。根据数学上的排列组合,这样一个“若A则B”的逻辑蕴含命题可以有4种可能性:

表1 蕴含共性的四缺一逻辑模式
A真B真、A真B假、A假B真、A假B假。这4种可能性中,第2种可能性是不存在的,语言类型学将这4种可能性纵横排列,称为四缺一逻辑模式,也叫四分表(见表1)。
在形式逻辑中,如果A(比如下雨)是B(比如地面湿)的充分条件,那么可能存在4种可能性:
Ⅰ A真B真:AB(下雨,地面湿)
Ⅱ A真B假:A-B(下雨,地面不湿)
Ⅲ A假B真:-AB(没下雨,地面湿)
Ⅳ A假B假:-A-B(没下雨,地面没湿)
这4个逻辑命题中只有第2个(A-B)是假,也就是说,上面4个命题组成的逻辑真值表缺少A-B这种组合形式,而只具有其他各种组合形式的四缺一模式。我们以屈折动词与特指疑问词蕴含关系[3]111为例,可以用四缺一模式表述出来(见表2)。

表2 屈折动词与特指疑问词蕴含关系的四缺一模式
上面四缺一模式所表现的规则是:当一种语言的屈折动词居于主语之前时,那么这种语的特指疑问词通常居于句首,不存在这样的可能性,即:屈折动词在主语之前而特指疑问词不在句首。屈折动词不在主语前时,特指疑问词可以在句首,也可以不在句首。
因此,四缺一模式被认为是逻辑蕴含关系最简单最直观的表现形式。
(二)蕴含共性的推导方式
蕴含共性一定是发生在一个以上的事物之间,通过A和B的蕴含共性来推测C。Greenberg提出的蕴含共性原则[3]4,有的以普遍现象推导出某种具体现象(即,一般→个别),如:
GU5:若是SOV语序且领属语位于核心名词之后,那么形容词也位于名词之后。
而有的则以具体现象推导出普遍规则(即,个别 → 一般),如:
GU21:若某种语言的副词位于形容词之后,那么形容词也位于名词之后,其优势语序是V位于O之前。
语言类型学强调语言样本的多样性和现实性,认为“个别 → 一般”的归纳过程比“一般→个别”的演绎过程更有价值[12],GU21相比于GU5,就体现了这一观点。
(三)蕴含共性理论的发展
Greenberg提出的蕴含共性理论是单向的、无例外的语序共性,反映了语序客观上的不对称。在语序例外的情况下,单向的无例外的理论无法包打天下,Greenberg本人也发现了这一矛盾,他在提出蕴含共性时就直陈SVO与VSO、SOV语言存在交叉情况。例如,在阐述介词的分布位置时,他指出PrN和NPo这两种语序在SVO、VSO、SOV都有体现[3]69。因此,有学者[1]45指出,Greenberg的蕴含共性理论一开始就存在优势语序与语序和谐有所矛盾的两个方面。作为Greenberg蕴含共性理论的继承者,Hawkins完善了单向性无例外的语序共性理论[5],Dryer则发展了Greenberg的语序和谐理论[13-14]。
Hawkins极大地扩充了Greenberg的30种语言样本,他采用336种语言样本来统计语序共性,用科学计量的方法将验证共现与预测共现区分开来。Hawkins的主要贡献之一是使用理论原则来解释违背语序类型的反例,他提出两个相互关联但彼此对立的原则“恒定序列原则(the Heaviness Serialization Principle,i,e.HSP)”和“迁移原则(Movility Principle,i.e.MP)”。他认为蕴含和分散是两种不同类型的共性,后者只是延展了语言共性研究的量化维度[5]319。为了语言量化更客观更精确,Hawkins提出了“跨范畴和谐原则(the Principle of Cross-Category Harmony,i.e.PCCH)”并以之来解释Greenberg原始样本和他自已的扩充样本中的语序共性[5]49,[15]214。他认为,对语序相关性的解释实际上也是对语序共性解释的寻求,二者在某种程度上可以通过十分简单的运行原则予以解释。他提出了“最初直接成分原则(the Principle of Early Immediate Constituents,i.e.PEIC)”[16],指出语序相关性或者语序共性在真实语言中体现为快速有效地处理信息。在基于语言成分按一定顺序排列的假设下,PEIC认为内在的句法结构或两两组合的最小直接成分在现实语言中能被快速有效地辨识出来。成分排列不同,其结构复杂度也不同,复杂结构影响人们辨识直接组成成分的效率。人类语言的基本语序是信息处理最快最高效的顺序,反映的也是语言实践的惯例和最佳顺序。
Dryer则赞同OV/VO是人类语言最基本的两种语序类型,他对基本语序的研究也体现了这一思想[17-20]。他的观点基于两个目标:(1)确定与V、O语序相关的对子成分语序;(2)解释V、O语序与对子成分的语序为什么具有相关性。也就是说,寻求语序与对子成分和谐对应的解释。他对Lehmann和Vennemann所推崇的“中心词理论(the Head-Dependent Theory,i.e.HDT)”提出质疑,他认为尽管HDT能解释名词和领属语、动词和方式状语等6对成分,但实际样本中还有一些与V、O没有任何关联的对子成分语序与HDT的预测是完全相反的。于是,Dryer提出了基于词组和词汇语序一致性的“分支方向理论(the Branching Direction Theory,i.e.BDT)”[13]108。BDT对语序的推测是:右分支语言的词组范畴在词汇范畴的后面,左分支语言的词组范畴在词汇范畴之前,VO语言和OV语言根本的区别就是它们在分支方向上是相反的,前者是右分支,如例(13)的英语,而后者是左分支,如例(14)的朝鲜语。图2的三角形表示分支/词组范畴。

图2 词汇与词组单位的分支方向
BDT模型是Dryer用来解释语序和谐对应的一个假说。这个假说认为,一种语言倾向于向同一方向分支,即:不可分支的词汇单位在一侧,可以分支的词组单位在另外一侧。该理论似乎可以较好地解释和谐功能的作用范围,即Greenberg提出的交叉类似现象。但是,Dryer的BDT模型仍然有不少不尽如人意的地方,证据之一是Dryer没有对NumrN 和NNumr这一对子成分进行分类,观点也前后矛盾。BDT模型在逻辑上能表达英语AdjN的相反语序NAdj,可是至于英语为什么没有NAdj这种语序,BDT无法作出解释。Dryer后来对BDT进行了修订,相继提出了“修订的分支方向理论”和“替换的分支方向理论”[14]80-101。不过,仍有人认为[1]56,Dryer强调的语序和谐只是语序共性的一个方面,BDT只关心结构的层次问题而不关心结构的关系类别,所以Dryer提出的原则还不能成为语序共性的总原则。
四、结语
渝东南民族多语地区的土家语由于受汉语方言和苗语等其他语言的影响,其语言类型正在由SOV语序向SVO语序变化,这种变化与世界上不同类型的语言所经历的不同程度的语序同化过程是一致的。语言类型学的研究需要语言类型学家们尽量多地占有不同语言的材料,需要借鉴统计学、逻辑学等其他学科的方法进行跨语言比较、对人类语言的共性规律进行科学的实证研究。语序类型、形态类型以及语言类型的逻辑验证构成了语言类型学科学性的核心内容。语序类型着眼于人类语言的基本语序和语序共性原则,形态类型聚焦格范畴和语法结构关系的一致性。蕴含共性的逻辑表达、推导方式以及不断完善的蕴含共性理论表明,语言类型学家们正是通过推演语序规则并对规则进行证实或证伪从而将人类语言的研究真正立足于实证科学的基础之上。
