基于航迹挖掘的船舶行为估计方法及软件实现
2023-12-12梁晶晶魏乾
梁晶晶 魏乾
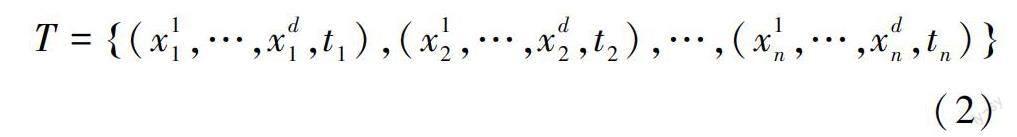

摘 要:船舶活动规律分析尤其是船舶的行为研判问题,一直是研究的难点。聚焦船舶的活动规律分析问题,提出了一种基于大量船舶历史航迹聚类的频繁模式挖掘方法,用于对船舶未来行为进行估计,并给出了软件实现。首先提出航迹的综合相似性度量方法,并介绍基于航迹聚类的频繁模式挖掘含义;其次对经典密度聚类算法进行适应性改造,给出基于综合相似性的聚类算法的实施方法;然后,提取虚拟主干航迹计算最相似簇,经统计得出对当前船舶行为的估计结果;最后,给出了基于C/S架构的软件总体设计和试验效果。试验表明该方法能够给出航迹关联行为描述,软件得到的行为估计结果能够辅助研判。
关键词:船舶行为估计;频繁模式挖掘;综合相似度;聚类;软件设计
中图分类号:U675.79文献标志码:ADOI:10.3969/j.issn.1673-3819.2023.06.10
Ship behavior estimation method and software implementation based on track mining
LIANG Jingjing, WEI Qian
(Unit 91001 of PLA, Beijing 100036, China)
Abstract:It is always difficult to analyze the law of ship movement, especially the behavior of ship. In this paper, a frequent pattern mining method based on a large number of historical track clustering of ships is proposed to estimate the future behavior of ships, and the software implementation is presented. In this paper, a comprehensive similarity measurement method of track is proposed and the meaning of frequent pattern mining based on track clustering is introduced. Secondly, the adaptive transformation of the classical density clustering algorithm is carried out and the implementation method of the clustering algorithm based on comprehensive similarity is given. Then, the most similar cluster of virtual trunk track calculation is extracted, and the estimation results of current ship behavior are obtained by statistics. Finally, the software design and test results based on C/S architecture are given. Experimental results show that this method can describe the behavior of track association, and the behavior estimation results obtained by the software can assist the research and judgment.
Key words:ship behavior estimation; frequent pattern mining; comprehensive similarity; clustering; software design
收稿日期:2023-05-10
修回日期:2023-06-14
作者简介:
梁晶晶(1982—),男,高级工程师,研究方向为指挥信息系统。
魏 乾(1974—),男,正高级工程师。
随着计算机网络和数字通讯技术的进步,诞生了船舶自动识别系统(Automatic Identification System,AIS),使人们能够实时掌握船舶的基本信息、具体位置、运行状态和航向航速等,保障航行安全。同时,大数据技术分析AIS的信息系统歷史航迹数据,可以为海上目标活动规律分析提供数据支撑,使挖掘历史数据中的潜在知识以辅助未来情况研判成为可能。
目前关于船舶历史数据的分析应用和基于大量数据的规律挖掘研究较多。唐艺灵等研究了通过AIS数据聚类得出航迹点归属等级,计算异常值以给出区域告警的方法[1];刘又嘉研究AIS航迹并给出了航路提取方法并设计了航路提取系统[2];孙杨研究了大数据船舶分析系统,实现了港口的识别和预测[3];程立龙基于AIS数据对船舶航迹停留特征进行了分析[4];钟原等给出了面向海量AIS数据的态势显示系统设计方法,基于共享内存管理提升了海量船舶数据显示的性能[5];金梁对AIS数据进行了可视化分析研究[6]。成磊峰、吴达等都基于历史数据进行了一些挖掘分析,以实现对实时目标的识别和预测[7-9]。由此可见,基于海量船舶历史数据挖掘的应用软件领域正在成为研究热点。
虽然目前有不少关于船舶历史数据的分析研究,但是关于软件自动预判船舶活动行为一直是研究的难点。本文提出一种基于航迹频繁模式挖掘的船舶行为估计方法和软件实现流程,针对海量历史数据架构软件,拓展应用频繁模式挖掘等经典算法挖掘潜在规律,从航迹规律角度给出行为的估计结果,供用户分析参考。
1 航迹频繁模式挖掘
1.1 航迹的定义和表示
船舶航迹数据可表示为以时间t为自变量的连续函数f(t),通过船舶运动航迹函数模型实现从时间到空间的映射,获得指定时刻t(t∈R+)下船舶在所处空间Rd中的位置,其中d是空间的维度(本文针对船舶活动分析,活动空间为基于墨卡托投影的二维平面)。
理想的时空轨迹模型是连续的,但是AIS船舶航迹是离散的数据点,因此,船舶航迹数据可以表示为
其中,序列T的每一个元组表示船舶对象tn时刻在空间Rd中的位置信息。通常航迹数据是一种二维空间序列,记录了船舶在海上的历史经纬度坐标,能够在一定程度上反映船舶的运行情况和航路特征,但为了后续准确地分析,航速和航向等也成为组元的必要要素。
1.2 船舶航迹的综合相似性度量
船舶航迹的相似性度量即航迹间的相似程度,是航迹聚类、异常分析等航迹数据挖掘应用的基础。最常见的航迹相似性度量是计算欧氏距离,它的优点是符合人类对于距离的理解,比较直观,也是很多其他相似性度量方法的基础。假设有两条长度相同的航迹Li、Lj,则它们的相似性度量可以定义为
其中,n为航迹的点数,p为航迹的维度,对于AIS船舶航迹而言,p=2。该方法计算简单,时间复杂度为O(n),比较适合处理较大量的航迹数据,但这种计算前提是航迹点数相同,这对于AIS种类的船舶航迹采样是不现实的。
动态时间规整(Dynamic Time Warping,DTW)算法是一种全区间变换对应相似的航迹相似性标识方法,它在时间维上,允许航迹数据进行局部拉伸或收缩,能够找到两个航迹序列的最佳对齐方式且保证航迹点时间顺序不变,定义如下[10]:
其中,m和n分别为航迹对象Li和Lj的航迹点数目,dist(Li,Lj)表示这对航迹第一个点之间的欧氏距离,Rest(Li)和Rest(Lj)代表航迹Li和Lj分别删除首点后的航迹子序列。若两条航迹点数均为0,則DTW也为0;若有且仅有一条为0,则DTW距离为无穷大;否则,就继续递归计算。根据DTW公式,DTW用于标识不等长航迹段之间的相似性,因此能够在时间维度上进行局部缩放后寻找到相似航迹,避免了采样率或尺度不同时难以计算航迹相似度的问题。
然而,在实际应用中,通常会出现两艘船完全逆向航行,而DTW值较小,即相似度较高的情况,然而这两条逆向航迹对应的行为往往不同。因此,航迹相似性度量不能单纯依靠位置相似度,考虑到AIS船舶航迹信息中还包含航速、航向,可以将其引入相似度计算中来,通过归一化加权求和,获得航迹之间的综合相似性度量。
如图1所示,航向c由正北方向与船舶航向的顺时针夹角表示;航速v在两个轴(即经纬度两个方向上)进行水平和垂直投影,即根据航向角度分解为两个航速分量v∥和v⊥。
则不同航迹点i,j之间的速度差异可通过两个分量求差表示,如下式:
Δv∥=|vi∥-vj∥|
Δv⊥=|vi⊥-vj⊥| (6)
那么加权求和为
dLi,Lj=ω1·Δv∥+ω2·Δv⊥+ω3·distLi,Lj(7)
将式(4)中的distLi,Lj替换成式(7)的dLi,Lj,即为航迹之间的综合相似性度量。式(7)中,权重因子满足ωi≥0,i=1,2,3,且∑ωi=1。
另外,在航迹长度差别较大时,航迹距离与相似性度量的关联程度较低,为避免该问题,本文在计算相似度值时,采取航线截断处理的方式;而对于航迹点极少的航迹,不具有参考价值,本文不予考虑。
本文软件的航迹频繁模式,可获得同类航迹集合,以支撑后续分析。
2 基于航迹聚类的行为估计
2.1 基于航迹综合相似度的密度聚类实现
船舶活动的频繁区域和频繁路径挖掘研究常使用密度聚类算法。
最经典的一种密度聚类算法是DBSCAN(Density-based Spatial Clustering of Applications with Noise),核心思想是通过定义密度可达、直接密度可达和密度相连等概念,以空间邻域为搜索半径,不断遍历符合条件的数据点,当数据集中遍历不到其余符合条件的点时则产生一个新的簇并继续遍历,直至遍历完所有点为止。该算法是预先设定两个参数Eps和MinPts,其中Eps表示扫描半径,也称邻域半径ε,MinPts表示最小包含点数阈值,用于筛选可以向外扩展的核心点。DBSCAN算法可以在噪声干扰下发现任意形状的样本集,即簇C,且具有不需要提前已知簇的数目的优点,非常适合通过航迹点进行频繁区域和路径挖掘的场景[11-12]。
考虑航迹的综合相似性,为获取航迹分类,本文采用基于综合相似性度量改造DBSCAN算法,将符合聚类条件的综合相似性度量值的临界值抽象为算法中的邻域半径Eps,其余相关规定如下:
1)邻近点距离:由一个距离函数计算任意两航迹p和q的综合相似度,标记为D(p,q)。
2)邻近点:指对于任意的航迹p和q,抽象为符合条件{q∈T|D(p,q)≤Eps}(即距离核心对象综合相似性度量值小于Eps的航迹集合)。
3)核心对象:如若给定对象ε圆形邻域内的样本数量不小于给定的MinPts,则称其为核心对象,此时本质为航迹。
4)直接密度可达:给定一个航迹对象集合T包含p和q,假定p在q的ε邻域内,且q为该航迹集中的一个核心对象,则称p从q出发是直接密度可达的。
5)密度可达:对于航迹样本集合T包含一个“点”对象链p1,p2,p3…,pn,p1=q,pn=p对于pi∈D1≤i≤npi+1,pi+1是从pi关于ε邻域和MinPts直接密度可达,则p是从q关于ε和MinPts密度可达。
6)密度相连:如果存在航迹对象o∈T,使p和q都是从o关于ε和MinPts密度可达的,那么对象p到q是关于ε和MinPts密度相连。
7)基于密度的簇:通常是满足下列条件之一:
a. ?p,q,如果p,q∈C,并且p在符合Eps和MinPts条件下,p直接密度可达q。
b. ?p,q∈C:p是在符合Eps和MinPts条件下的密度相连的点。
8)边界点:如果p点满足p不是核心点,p密度可达其他的核心点,则p称为边界点。
9)噪声点:对于数据集T聚成的簇C1,…,Ck,噪声点表示不属于任何簇Ck,即i=1,…,k,noise=p∈T|?i:pCi,此时指不满足条件s的航迹。
2.2 实施步骤
聚类结果结构如图2所示,聚类结果在海图上的显示结果如图3所示。改造的聚类算法实施步骤如下。
1)分类提取航迹:对选定区域的AIS船舶分类提取航迹,是因为不同国籍、类型的船舶,通常会有不同的任务,即船舶的行为会不同。因此频繁航线、目的地以及热点活动区域等也会有所不同,将它们的历史航迹不作区分放在一起进行规律挖掘,增加挖掘难度,显然不具有客观性。比如商船往往选择始发地和目的港口之间的最近、最安全航路航行;美日参与军事行动的海洋监测船,通常在一些争议区域游弋或者拖缆。因此,可以预先在選定区域根据船舶属国、类型进行分类提取,以增加后续挖掘规律等研究结果的可靠性。
2)航迹预处理:考虑到短时间的AIS船舶航迹数据挖掘,结果可能缺少说服力,而长时段大批量的航迹,计算起来又比较耗时,因此,对提取到的航迹数据进行过滤和稀释处理。这样能够剔除掉航迹集中的飞点且在保留航迹关键特征点的前提下,滤除一些点,使计算压力减小。
3)DBSCAN聚类处理:将DBSCAN应用于船舶航迹聚类,参数Eps反映的是不同航迹聚成一类需满足的最低相似程度,而MinPts刻画的是不同航迹聚成一类需满足的最少数量,航迹之间综合相似性度量值Dp,q可由式(2)和(7)计算得到。挖掘算法服务会将聚合为一类的航迹移动并标识到一个簇号下。聚类的结果就是形成不同的簇文件。算法提取一簇航迹,也可以用来表示一类航迹的活动热点区域或航路特征。噪声点作为无法归类的航迹,不作为后续行为分析的凭据。
2.3 行为估计实现方法
首先,对于提取的所有关注船舶的历史航迹,需要进行行为标注。标注是在接入AIS数据的海洋信息系统上进行的,是日常积累的结果。所有被标记的目标航迹都会在数据库中记录,而缺少人为标注的关注目标航迹,在该段航迹入库结束后,系统根据AIS所报始发点和目的地给出默认标记。
其次,在聚类挖掘形成的多个簇中,提取每个簇的虚拟主干航迹,以表征航迹簇的整体特征[13]。如图4所示,平均航向用蓝色箭头表示,橘黄色线与平均航向垂直,红色轨迹表示通过计算每一航迹点的平均值得到的平均航迹,具体步骤描述如下:
1)通过某一簇内所有航迹向量求出平均向量;
2)用一条扫描线,扫描该簇内的各条航迹线:每次扫过一条航迹的起止点时都进行一次判断,若此时与扫描线相交的航迹条数大于等于最小线段阈值,记为MinLns,则根据各交点计算一个中心点并记录在列表中,否则就忽略。算法最终生成点迹列表,即为虚拟主干航迹的点集。
然后,算法计算当前目标船舶的已知航迹与同类船舶各个簇提取的虚拟主干航迹的综合相似性。
最后,算法取与当前目标船舶的已知航迹相似度最高(即综合相似性度量值最小)的簇,统计簇中各航迹的所标记的行为,将按在该簇中所占比例由高到低排列。由此,算法估计当前船舶的未来行为,选择占比较高的行为进行预测。
3 软件实现
3.1 软件架构
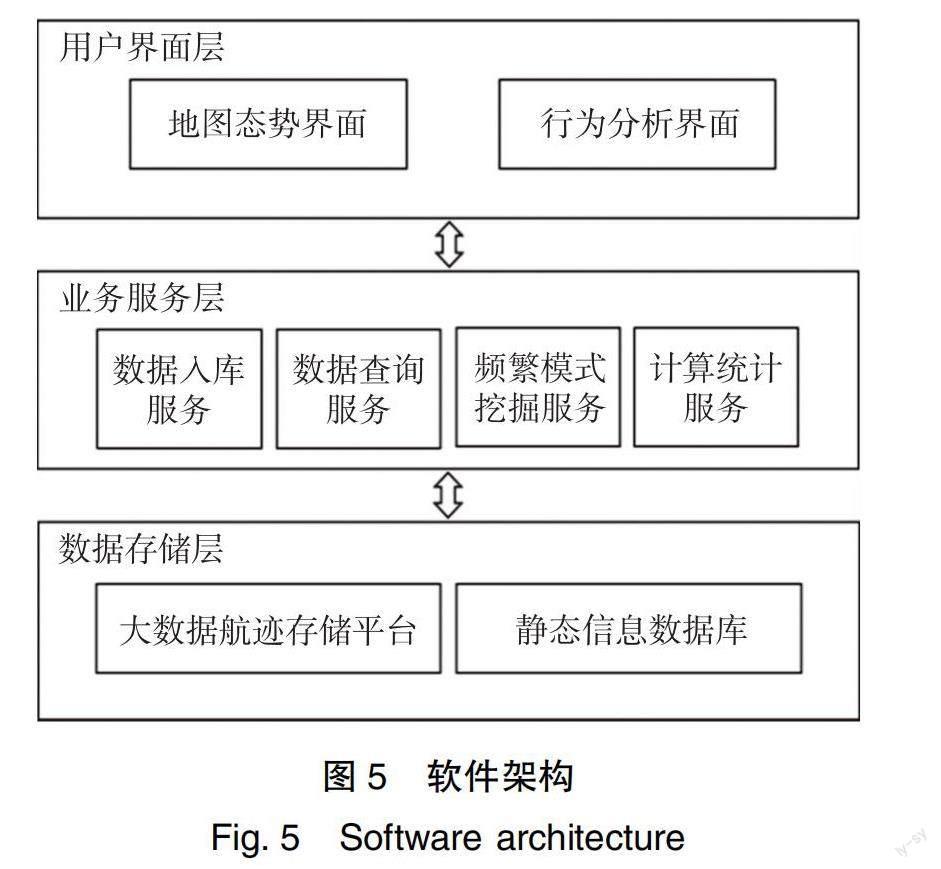
基于上述方法,软件采用C/S三层架构设计,具体设计如图5所示。
用户界面层即为客户端,主要包括地图态势显示软件和行为显示软件界面,用来支持用户拾取目标、查看可视化结果、展示行为估计结果等。行为结果显示软件采用饼状图的形式,展示经过后台挖掘分析之后,得到的可能性最高的几个行为以及占比情况,输出示意如图6所示。客户端通过数据访问服务接口连接业务服务层。
业务服务层主要提供数据的入库服务、数据查询服务、频繁模式挖掘服务和计算统计服务等算法服务。数据入库服务支持对实时目标航迹的预处理和存储;数据查询服务支持分类提取航迹数据并进行稀释等预处理;频繁模式挖掘服务支持进行标记历史航迹间的相似度计算和聚类处理(由于计算量大,给出设置接口,默认每天空闲时间根据新增数据进行一次挖掘,得到的分类结果或其他规律(如热点区域)可以供前台请求并显示,也可以供其他服务进一步计算分析);计算统计服务提供提取主干航迹、计算相似度和统计结果等算法。
数据存储层采用MySQL存储目标静态信息和标记信息,采用大数据平台存储船舶历史航迹信息,由分布式回放存储模块(HBase)以列式存储的方式存储航迹数据,支持业务服务层的查询和写入等操作。
3.2 软件总体流程
行为估计软件是通过进行大量历史目标航迹的规律挖掘,将所得规律信息与日常记录的行为标记信息进行分析和统计,根据相似性和占比等要素得出可能性最高的几种结果,从航迹规律的角度给出参考,辅助人们进行海上活动的研判。软件支持用户对船舶行为进行人工研判后修改标注信息并入庫,以支持后续分析,总体流程如图7所示。
3.3 试验结果
试验采用历史航迹段和行为标记数据作为挖掘分析的样本集,采用部分船舶标记数据和历史航迹段作为测试集(每条船舶包含大量航迹段),在地图态势界面随机拾取,得出统计结果,准确度如图8所示。由图8可知,占比最高的估计结果准确度为73%左右;占比前三的估计结果中包含正确行为的有87%左右,占比前五的估计结果包含正确行为的有97%左右。
4 结束语
本文针对船舶的活动行为分析问题,提出了一种基于大量船舶历史航迹聚类的频繁模式挖掘方法,给出了基于C/S架构的软件实现思路,并对关键技术实施方法进行了详细描述。考虑运算量大,后台服务支持空闲计算,以保证尽量减少系统资源占用。软件支持在地图目标态势界面用鼠标拾取目标分析,然后交由后台服务根据当天挖掘所得簇,经计算统计出行为估计结果,以饼状图的形式展示可能性较高的几种行为,供用户分析参考。目前软件对常见关注船舶的预估结果具有较高准确度,同时,船舶行为影响因素复杂,仅从航迹规律角度分析的结果仍有相对的局限性,后续随着数据的积累,仍有继续优化的空间。
参考文献:
[1] 唐艺灵.基于AIS数据的民船行为预测与区域告警方法研究[J].指挥控制与仿真,2022,44(5):97-101.
TANG Y L. Research on civil ship behavior prediction and area alarm Method based on AIS data[J]. Command Control & Simulation,2022,44(5):97-101.
[2] 刘又嘉. 基于AIS的船舶轨迹航路提取方法及系统实现[D]. 大连: 辽宁师范大学, 2021.
LIU Y J. Extraction method and system implementation of ship trajectory route based on AIS[D]. Dalian: Liaoning Normal University, 2021.
[3] 孙杨. 基于AIS大数据的船舶轨迹分析系统的设计与实现[D]. 北京: 北京邮电大学, 2021.
SUN Y. Design and implementation of ship trajectory analysis system based on AIS big data[D]. Beijing: Beijing University of Posts and Telecommunications, 2021.
[4] 程立龙. 基于AIS数据的船舶轨迹停留特征时空分析研究[D]. 南京: 南京师范大学, 2020.
CHENG L L. Research on spatio-temporal analysis of stay characteristics of vessels trajectory based on AIS data[D]. Nanjing: Nanjing Normal University, 2020.
[5] 钟原, 郑文龙, 李祥, 等. 基于共享内存管理的海量AIS目标态势显示系统[J]. 网络安全技术与应用, 2021(3): 35-36.
ZHONG Y, ZHENG W L, LI X, et al. Massive AIS target situation display system based on shared memory management[J]. Network Security Technology & Application, 2021(3): 35-36.
[6] 金梁. 基于AIS数据的船舶行为可视分析研究[D]. 武汉: 武汉理工大学, 2016.
JIN L. Research on visual analysis of ship behavior based on AIS data[D]. Wuhan: Wuhan University of Technology, 2016.
[7] 成磊峰. 基于历史规律的目标行为变化预测方法[J]. 指挥信息系统与技术, 2022, 13(1): 30-33, 50.
CHENG L F. Method for target-action change predictions based on historical law[J]. Command Information System and Technology, 2022, 13(1): 30-33, 50.
[8] 吴达, 吕锐, 杨宇, 等. 基于动态时间规整下密度聚类的轨迹识别研究[J]. 火力与指挥控制, 2021, 46(10): 73-78.
WU D, LYU R, YANG Y, et al. Research on improvement of DTW maneuver trajectory recognition based on DBSCAN[J]. Fire Control & Command Control, 2021, 46(10): 73-78.
[9] 陈浩, 任卿龙, 滑艺, 等. 基于模糊神经网络的海面目标战术意图识别[J]. 系统工程与电子技术, 2016, 38(8): 1847-1853.
CHEN H, REN Q L, HUA Y, et al. Fuzzy neural network based tactical intention recognition for sea targets[J]. Systems Engineering and Electronics, 2016, 38(8): 1847-1853.
[10]王超. 基于軌迹聚类的频繁模式挖掘方法[D]. 杭州: 浙江大学, 2021.
WANG C. The method of mining frequent patterns based on trajectory clustering[D]. Hangzhou: Zhejiang University, 2021.
[11]顾昱骅. 地理时空大数据高效聚类方法研究[D]. 杭州: 浙江大学, 2018.
GU Y H. The methods of high efficient clustering on spatiotemporal big data[D]. Hangzhou: Zhejiang University, 2018.
[12]刘勇. 基于DBSCAN的空间聚类算法研究与实现[D]. 昆明: 云南大学, 2017.
LIU Y. Research and implementation of DBSCAN algorithm based on spatial clustering[D]. Kunming: Yunnan University, 2017.
[13]王莉莉, 彭勃. 基于特征航迹简化模型的中心航迹提取研究[J]. 计算机应用研究, 2019, 36(1): 49-52.
WANG L L, PENG B. Research on central flight track extraction based on simplified track model[J]. Application Research of Computers, 2019, 36(1): 49-52.
(责任编辑:胡前进)
