燃气轮机故障知识图谱构建方法与应用研究*
2023-12-12王明达吴志生朱光辉李云飞
王明达,吴志生,朱光辉,李云飞,张 榜
(1.中国石油大学(华东) 机电工程学院,山东 青岛 266580;2.国家石油天然气管网集团有限公司 山东省分公司,山东 济南 250002)
0 引言
近年来,天然气在我国工业生产和民用生活中大规模普及[1]。燃气轮机作为天然气集输站场的核心动力设备,其运行状态直接影响着整个长输管道的安全[2-3]。然而,燃气轮机一旦发生故障,极易引起系统停机并导致重大安全事故的发生。燃气轮机经过多年的运行维护和故障检修,已积累大量的故障文本数据,但这些故障文本数据具有分布广泛、数据量庞大、格式规范化不统一等特点,且文本中存在描述不规范等问题,加重故障知识的复杂性,导致维修人员难以利用现有的文本知识数据进行故障诊断[4-5]。因此,本文引入知识图谱技术,将燃气轮机故障文本知识结构化,以实现对燃气轮机故障的快速分析与诊断。
目前国内外许多领域已开展故障知识图谱构建研究工作。Liu等[6]通过构建铁路操作故障因果知识图谱,揭示故障的潜在规则,并据此提出预防措施;Tang等[7]构建多源异构电力设备知识图谱,提高电力设备的管理效率,为故障诊断的应用奠定知识基础;Qu等[8]构建电力无线专网使用终端故障信息知识图谱,实现故障诊断与决策制定;盛林等[9]利用知识图谱将旋转机械领域内零散的知识、案例和专家经验关联,并将其用于故障原因推理,辅助解决旋转机械故障问题。上述研究利用知识图谱技术解决数据之间信息孤立问题,并利用图数据库将非结构化数据规范储存,提升领域内故障知识的利用率。然而上述研究大多仅对实体进行识别,且针对燃气轮机故障领域,目前尚鲜有相关的知识图谱构建研究。
因此,本文以燃气轮机多维故障文本数据为例,梳理燃气轮机故障文本知识体系,构建基于深度学习的燃气轮机故障知识图谱,进行燃气轮机故障实体及实体关系抽取,实现非结构化数据的结构化存储与管理,通过Neo4j图数据库进行可视化分析,并将其运用于辅助故障诊断,以期为故障维修人员提供知识支持。
1 燃气轮机故障知识图谱构建
1.1 故障知识图谱构建框架
知识图谱是1种基于图模型描述知识与客观事物间的关联关系的技术手段,由节点和边组成[10]。知识图谱的构建需要结合具体的领域场景、语义模型与业务模型,其构建方式分为自顶向下和自底向上2种[11]。燃气轮机故障知识图谱构建采用自顶向下和自底向上相结合的方式,如图1所示。
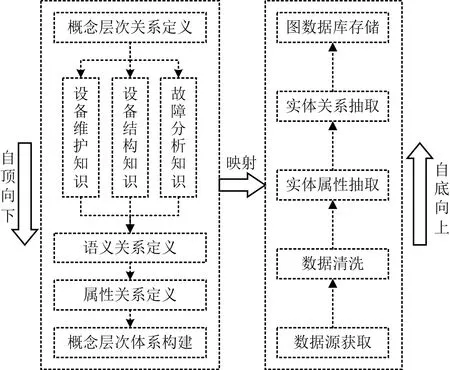
图1 故障知识图谱构建流程Fig.1 Process of fault knowledge graph construction
燃气轮机故障知识图谱的构建分为2层,即模式层构建和数据层构建。首先,根据数据源的种类不同将其分为设备结构知识、故障分析知识与设备维护知识3类,并根据领域数据的特点建立故障知识的本体表达模型,此工作即知识图谱模式层的构建。然后,在设备资料等外部知识的指导下完成对抽取的半自动化标注以减轻人力和时间的消耗,并利用自然语言处理从故障文本中进行实体与关系的抽取,完成知识抽取即数据层的构建工作。最后,将实体与关系按照本体层的模式存入Neo4j图数据库,可视化并完成知识图谱的相关应用。
1.2 燃气轮机故障知识来源
燃气轮机故障领域知识包括设备结构知识、设备维护知识、故障分析知识3类,具体选用要素如表1所示。设备结构知识包括设计原理图、使用说明书等资料,从中提取的结构知识可为燃气轮机的故障诊断与日常维护工作提供支持;设备维护知识包括设备工作状态、故障诊断知识、维修经验等,从中提取的维护知识可为现场的设备维护与故障诊断工作提供辅助决策;故障分析知识包括专家经验知识、FMEA、故障案例、FTA等,从中提取的分析知识能够为现场设备维修人员提供知识支持。

表1 燃气轮机故障多源数据Table 1 Multi-source data of gas turbine fault
1.3 故障知识本体概念类别划分
故障知识本体概念类别划分主要是针对故障部件及其属性类别的划分和定义,根据故障分析(FMECA)数据,故障知识本体O由1个或多个零部件故障F构成,其结构信息可描述为式(1):
O∈{∑Fc∪∑Ftr∪∑Ftl∪∑Fs}
(1)
式中:Fc为复杂型零部件故障;Ftr为反向树形零部件故障;Ftl为正向树形零部件故障;Fs为单串链形零部件故障。
1个完整的部件故障信息F由5个要素组成,其结构描述如式(2)所示:
F∈{E,T,R,I,L}
(2)
式中:E为故障设备;T为故障模式;R为故障原因;I为故障影响;L为风险等级。
1.4 故障知识本体层次定义
故障知识本体是指与燃气轮机故障知识有关的概念与属性的规范化定义[12]。知识图谱的模式层通常使用本体库进行管理,本体中的概念与关系决定知识图谱中的概念节点和关联关系,是构建知识图谱的重要依据,相当于知识库中的模具。
常用的本体构建方法有TOVE法、骨架法和七步法等[13]。本文结合骨架法与七步法2种本体构建流程,构建多维故障知识本体表达模型,其构建的具体过程包括:1)确定燃气轮机故障领域的研究范围、本体需求;2)检查是否存在燃气轮机故障本体,并考虑是否可以重用。如可重用,则可在已有本体模型基础上进行扩展补充,反之则需要重新构建本体模型;3)对领域知识进行分类,并使用统一的术语描述概念;4)定义概念间的层次关系,明确其层次结构;5)定义类的属性和约束关系,包括对象属性与数据属性;6)对构建的燃气轮机故障领域本体模型质量进行评估,包括本体的语义冲突和领域知识相符2方面,此过程依赖于专家(人工)检查以保证本体中知识表示的准确性;7)实例填充以完成知识管理系统的底层构建。经过此过程,最终构建1个具有实用性、通用性的燃气轮机故障知识本体模型,具体如图2所示。
1.5 故障知识抽取技术
知识抽取技术包括命名实体识别与关系抽取,目的是从文本中提取关键信息的技术,在知识图谱构建过程中指抽取文本中的目标实体、属性与关系等信息[14]。
1.5.1 命名实体识别
燃气轮机故障文本中包含大量有用的知识信息,而实体识别的目的就是将文本中有价值的实体信息识别并标注[15]。按照上文定义的实体概念类型进行识别和标注,本文采用基于混合神经网络的BERT-BiLSTM-CRF命名实体识别模型,其模型架构如图3所示。图3中Ei指输入的字;Ti为模型输出结果;Trm(Transformer)为编码模块;ht为LSTM单元的输出结果;pt为隐;Y={Y1,Y2,…,Yt}为标签序列。

图3 BERT-BiLSTM-CRF命名实体识别模型Fig.3 BERT-BiLSTM-CRF named entity recognition model
BERT-BiLSTM-CRF模型包括4部分:1)预处理文本数据,包括文本清洗、去停用词等步骤;2)引入BERT模型作为故障文本的字符向量化表示,表示结果用于BiLSTM层的输入;3)采用BiLSTM模型获取上下文的特征向量,输出命名实体识别的结果,并作为CRF层的输入;4)使用CRF模型输出预测实体类别结果。其中,对一部分的故障文本数据的文本预处理流程具体如下:1)文本清洗:即分词,采用Jieba分词工具,并结合自构建的燃气轮机设备故障专业词库,确保分词结果的准确性;2)去停用词:即去除文本中的空格、标点符号等干扰数据,以及去除无实际意义的字符,如“的”、“在”、“了”等,从而提升模型训练的效率;3)实体标注:本文采用BMEO序列标注法,部分标注标签类型如表2所示。以故障设备(fault equipment,EQU)为例,“B”为“Begin”,表示实体的第1个字符;“M”为“Middle”,表示实体字符中部的字符;“E”为“End”,表示实体字符的最后1个字;“EQU”表示该实体的名称缩写标签。
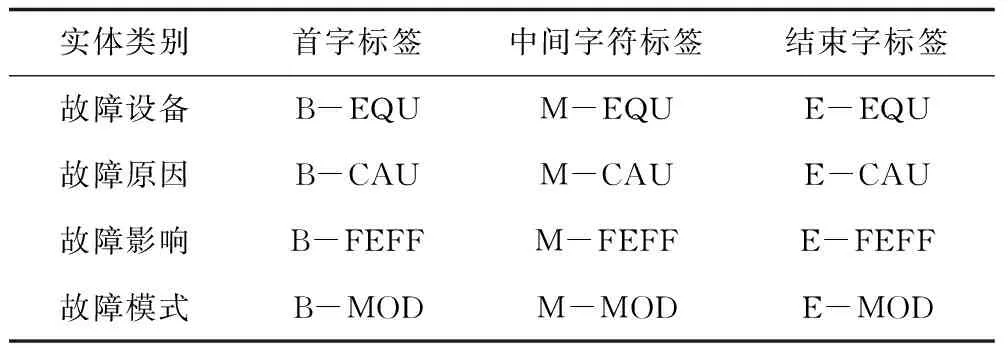
表2 实体标注示例(部分)Table 2 Example of entity annotation (part)
1.5.2 关系抽取
完成实体抽取后,需要建立实体间的关系和实体属性间的关系,从故障文本中抽取得到关系的过程即为关系抽取[16]。基于深度学习的关系抽取方法在提高关系分类效率与准确度方面具有很大的优势,因此本文在前者命名实体识别模型的基础上,引入Attention模型替代CRF模型来实现关系抽取。
与实体识别模型类似,用于关系抽取的数据源于已经完成实体识别的数据。根据知识图谱“<实体-关系-实体>”和“<实体-属性-属性值>”的表述方式,将故障训练语料按照“头实体-关系-尾实体”的形式整理,基于关系抽取的故障文本预处理规程,具体如表3所示。
1.6 知识融合
从文本中抽取得到的知识一般含有大量的模糊和冗余的信息,且存在较多的语义相似,如“压缩机”,虽在不同文本中表述相同,但是具体属性、规格等信息不同,实质表示2种不同实体。
本文采用计算概念名称相似度、属性相似度和综合相似度相结合的方式计算燃气轮机故障文本中实体的相似度,通过设定阈值判断实体是否具有相同含义,实现知识融合,其对应的计算步骤如下。
1)步骤1:计算概念名称相似度。
本文采用ISub字符串映射算法判断全局本体概念与局部本体概念的名称相似度如式(3)所示。对于给定的全局本体概念cG和局部本体概念cL,首先对其进行序列化与去冗余处理,然后进行相似度计算。
(3)
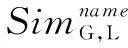
(4)
式中:bG表示全局本体中概念字符串;bL表示局部本体中概念字符串;comm(bG,bL)表示概念字符相同的部分;diff(bG,bL)表示概念字符不同的部分;winkler表示修正系数。
2)步骤2:计算实体的属性相似度。
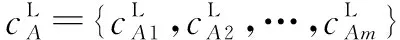
(5)
式中:SA为属性相似度;wi是属性权重。
3)步骤3:计算实体综合相似度。
在名称相似度算法与属性相似度算法的基础上,提出综合相似度(SF(cL,cG))算法,具体计算如式(6)所示,以提升实体融合的准确性。
(6)
式中:WN为名称相似度权值;WA为属性相似度权值。
查找目标实体的概念,计算概念名称相似度、概念综合相似度与属性相似度,对知识抽取得到的实体信息与属性信息进行融合,并设定阈值,若2个实体的综合相似度大于设定阈值,则进行融合,否则将这2个实体分别储存。
1.7 Neo4j图谱构建
本文使用图数据库Neo4j实现对燃气轮机故障文本数据的存储工作。相较于传统关系型数据库,Neo4j图数据库能够高效地实现节点与关系查询,且基于Cypher语言的查询与管理机制,能够较为容易实现Web端的开发与应用[17]。
2 燃气轮机故障知识图谱构建实例及应用
2.1 知识抽取结果
本文采用的燃气轮机故障文本数据集由600份故障记录文本和960条故障分析文本组成。将数据语料按照4∶1∶1的比例划分为训练集、测试集和验证集,即随机选取400份故障文本与560条故障分析记录用于训练BERT-BiLSTM-CRF命名实体识别模型与BERT-BiLSTM-Attention关系抽取模型。
抽取结果准确性的评价方法采用深度学习领域常用的正样本与负样本评价方法,评价指标包括精确度(precision)、召回率(recall)和综合评价指标F1值,计算公式如式(7)所示:
(7)
式中:TP表示模型预测正确且标注正确的样本数量;FP表示模型预测错误但标注正确的样本数量;FN表示模型预测错误且标注错误的样本数量。
为验证基于深度学习的BERT-BiLSTM-CRF命名实体识别模型对燃气轮机故障文本中实体识别的有效性,本文选取BiLSTM-CRF模型,BERT-CRF模型和Word2Vec-BiLSTM-CRF模型进行对比分析。实验过程中,均使用相同的训练数据、测试数据和相同的实验环境,不同模型的实验结果如图4所示。
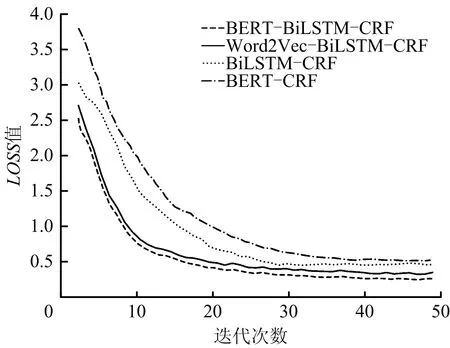
图4 各模型耗损收敛对比Fig.4 Comparison of depletion convergence of each model
由图4可知,4种模型迭代次数在30~50次时趋于稳定,且本文构建的BERT-BiLSTM-CRF模型较之于BiLSTM-CRF等对比模型训练LOSS值更低,性能更高,其模型的精确度、召回率和F1值的平均值分别达到93.84%,95.07%,94.44%,实体抽取对比如表4所示。
与BiLSTM-CRF模型相比,BERT-BiLSTM-CRF的F1值提高7.98个百分点,这是因为BERT模型能够获取动态字符,在一定程度上增强BiLSTM模型获取上下文的能力,因而能够最大程度提取文本中的复杂特征。而与Word2Vec方式相比,BERT-BiLSTM-CRF模型的F1值提高0.89个百分点,这可能与实验过程中引入燃气轮机故障词库的原因有关。同时,基于BERT模型的字符嵌入是1种动态嵌入方式,相较于Word2Vec的静态嵌入方法,能够有效解决一词多义的问题。
BERT模型是1种预先训练的神经网络模型,不同于Word2Vec需要依靠大量训练才能生成准确的词向量,在文本数量有限的情况下,该模型就能取得较好的训练效果。BERT-CRF模型的精确度达到81.22%,而增加双向长短期记忆网络的BERT-BiLSTM-CRF模型,进一步提取上下文序列特征,其精确度等指标均有10个百分点左右的提升。因此,本文提出的命名实体识别模型较对比模型的实验效果好。
同时,为验证本文提出的BERT-BiLSTM-Attention关系抽取模型的准确性,进行1组对比实验。BERT模型在已公开的数据集知识抽取实验中已取得显著效果,但在燃气轮机故障数据关系抽取工作中还未开展应用,故本文选择BiLSTM-Attetion模型、BiLSTM-CRF模型与研究模型进行对比实验,实验结果如表5所示。

表5 关系抽取模型对比实验分析Table 5 Comparative experimental analysis of relation extraction models 单位:%
由表5可知,相较于BiLSTM-CRF,BiLSTM-Attention,BERT-BiLSTM-Attention模型能够更好地捕捉文本中的长距离依赖关系,因此在处理长文本任务时可能具有更高的准确性。BERT-BiLSTM-Attention模型较BiLSTM-CRF模型、BiLSTM-Attention模型取得更好的结果,其F1值分别提高8.49个百分点和5.73个百分点。
BERT-BiLSTM-Attention关系抽取具体结果如表6所示。由表6可知,本文提出的BERT-BiLSTM-Attention模型能较好地对故障文本中的实体关系进行抽取,尤其对“从属”、“原因”、“位于”类型的关系抽取效果较好,这可能与引入燃气轮机故障专业词汇信息有关。

表6 BERT-BiLSTM-Attention模型关系抽取结果Table 6 BERT-BiLSTM-Attention model relation extraction results
2.2 知识融合结果
按照知识融合算法流程,参考关键字检索方法,实验中将融合结果分为3类。A类:实体融合正确,即相同含义的实体全部融合;B类,实体融合错误,即融合2个不同含义的实体;C类:实体未融合,即相同含义的实体未被融合。以“故障处理措施”和“故障设备”2类实体进行融合为例,经过多次实验表明,相似度计算阈值w=0.6时效果最好,实验结果如表7所示。
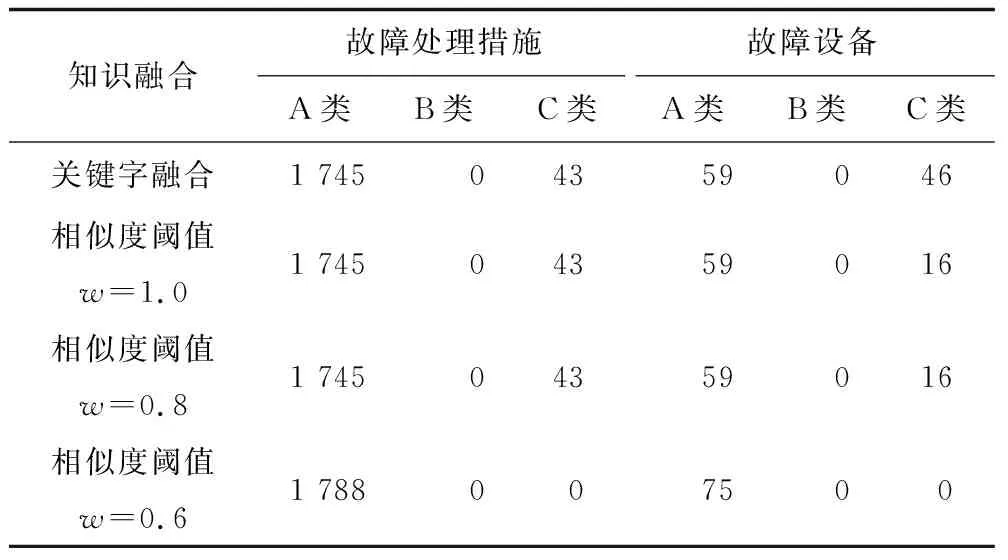
表7 关键字融合与相似度融合结果对比Table 7 Comparison of keyword fusion and similarity fusion results
2.3 基于知识图谱的辅助故障分析
将燃气轮机故障文本中抽取得到的实体与关系,分别作为Neo4j图数据中的节点与连接节点的边,以完成燃气轮机故障知识图谱的构建工作。
燃气轮机故障知识图谱由设备结构知识、设备维护数据和故障分析数据3类数据文本组成,能够提供故障处理经验、设备可靠性等多方面的知识,因而能够应对大型复杂机械设备的故障诊断任务。以PGT25+SAC/PCL800系列燃驱压缩机组辅助组成系统中“压气机异常振动”故障为例获取有关故障信息的多维数据,得到该故障的图谱如图5所示。图5中包含导致压气机异常振动的可能原因、发生概率以及对应的故障处理措施。
通过图5可逐个分析故障原因,如通过检查X20-3号端子的输出电压大小来判断是否为传感器损坏导致的异常震动,同样的方式可以判断信号回路是否故障。但有些故障原因无法提供故障数据,如阀门的故障率。因此,有必要参考设备的故障率辅助故障诊断,尤其是当仅靠传感器数据不能确定部分设备故障原因时,可参考历史故障率。
综上,本文构建的燃气轮机故障知识图谱能够为现场工作人员的故障处理工作提供多维的综合数据支持,辅助现场工作人员对设备进行综合故障分析,在一定程度上使人员摆脱对知识、经验的依赖,降低知识获取的门槛。同时,减少故障发生对设备的停机时间的影响。
3 结论
1)以燃气轮机多维故障文本数据为对象,分析并构建燃气轮机故障知识本体,研究多维故障文本数据知识图谱构建方法。
2)提出的燃气轮机领域知识实体与关系抽取方法,能够对非结构故障文本自动化知识抽取,同时解决传统故障知识库构建中人工依赖度强、代价高且规模有限的问题,提高领域内故障知识的利用率和共享率。
3)采用Neo4j数据库将燃气轮机故障知识图谱进行可视化分析,可以进行快速的数据查询与分析,大大提高人工检索的效率。
4)本文所构建的故障知识图谱还存在一些不足,如FMECA数据和故障文本仅依靠集输站场提供,导致知识的全面性有所下降。在后续的研究中,还将进一步扩展数据来源并动态更新知识图谱,并研究知识图谱在燃驱压缩机组故障诊断领域的应用。
