DenseNet结合空间通道注意力机制的环境声音分类
2023-12-12董绍江
董绍江,刘 伟
(重庆交通大学 机电与车辆工程学院, 重庆 400074)
0 引言
人类周围的声音大致可以分为3类:环境声音[1]、音乐、语音,因此智能声音识别(ISR)包括环境声音分类(ESC)、音乐信息识别(MIR)和自动语音识别(ASR)。其中,ESC在生活中应用十分广阔,常应用于电力设备[2]、医院和地铁站的异常监测等场景。但是,环境声音具有复杂变化的时频特性,因此ESC比MIR和ASR更难。
针对上述问题,许多学者对ESC进行了大量的研究。总体而言,ESC主要由特征提取和分类网络两部分组成,通过计算获得过零率(ZCR)[3]和梅尔频率倒谱系数(MFCC)[4]等特征表示,然后通过矩阵分解、支持向量机等机器学习模型进行特征提取,但是通常这类方法比较耗时且缺乏创新性。
注意力机制在很多领域都有应用,如目标检测、数据挖掘等。在环境声音识别领域,Tripathi等[5]将神经网络与注意力机制结合,在ESC数据集中取得了相当好的结果。SE[6]模块是通道注意力机制,而CBAM[7]模块是空间通道注意力机制,它们都属于典型的注意力机制。其中,通道注意力机制首先会计算不同特征通道的重要程度,然后分配相应的权重以适配通道的重要性,但是SE注意力机制模块会将二维特征图压缩为一维,这会导致某些空间位置信息丢失。空间通道注意力机制除了利用不同通道特征外,还利用不同空间位置信息,一定程度上是优于通道注意力机制的。
为了充分利用从环境声中提取的Log-Mel谱图的空间与通道相关性,提出了一种基于密集连接卷积网络(DenseNet)的空间通道注意力机制,可以使网络模型更加关注语义相关和突出的特征,从而提高ESC算法分类准确率。此外,为了解决声音数据不足引起的模型过拟合现象,将混合在线数据增强方法应用于Log-Mel谱图,并在2个公开数据集ESC-50和ESC-10上测试验证了所提方法的适用性。结果表明,提出的空间通道注意力机制模型能够使神经网络更加关注显著特征。
1 方法
1.1 频谱特征提取
在给定环境声音信号的场景下,采用Librosa库[8]提取LogMel谱图。窗口长度设置为2 048,步长设置为512,梅尔滤波器的数量设置为128,最后将像素值限制在0~255。经过上述步骤后,将ESC-10和ESC-50数据集的Log-Mel谱图大小设置为128*431*1(对应频率*时间*通道数),然后将特征谱图作为网络的输入。ESC-50数据集的Log-Mel谱图示例如图1所示。
1.2 网络结构
因为密集连接卷积网络[9](DenseNet)在图像识别领域有成功应用的先例,所以提出了基于DenseNet的网络结构。DenseNet的本质是增加后续层输入的变量,并通过连接不同层学习的特征图来提高效率。图2为DenseNet的主要结构。
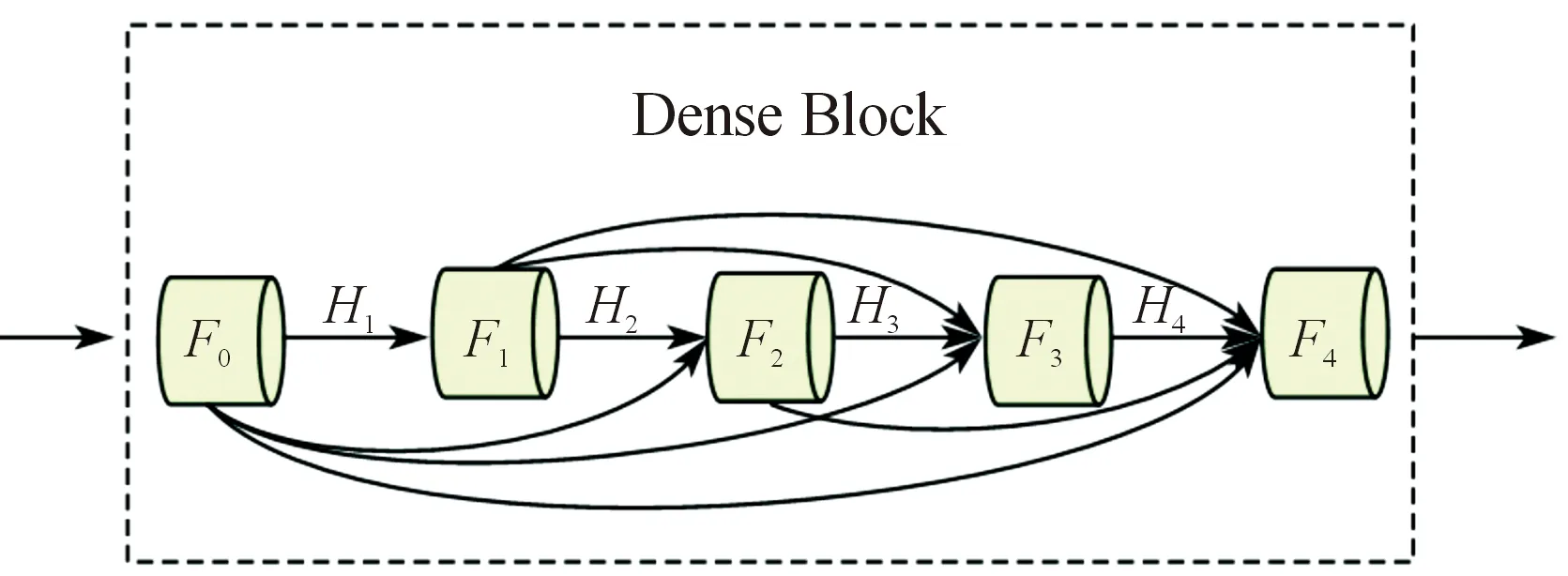
图2 DenseNet的主要结构
具体来说,第N层将先前层F0、…、FN-1处理后的特征图作为输入:
FN=HN[concat(F0,F1,…,FN-1)]
(1)
式中:concat是沿通道进行的拼接操作;HN被定义为3种连续操作的复合函数,即批量归一化(BN)、线性整流函数(ReLU)和卷积核大小为(3,3)的卷积操作。对densnet网络不同层的描述如表1所示。

表1 对densnet网络不同层的描述
表1中的每个“conv”层表示顺序操作BN-ReLU-Conv,其中网络的输出层包含的节点等于不同数据集中种类数。图3为所提出的网络模型框架。
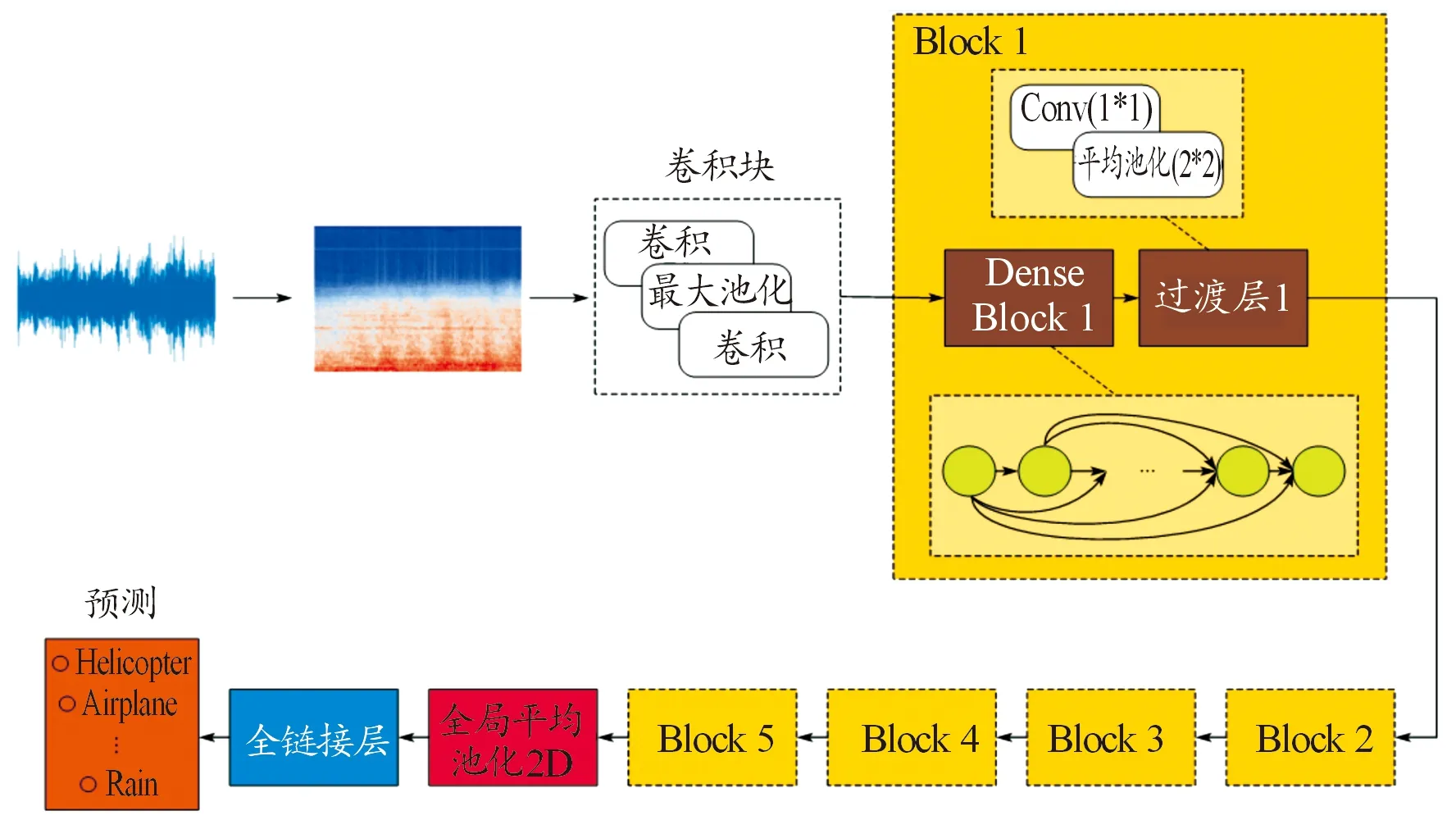
图3 网络模型框架
1.3 注意力模型
1.3.1空间注意力模型
当环境声音受到无声片段影响时,意味着应该为相应的帧级特征分配不同的权重。为了解决ESC中普遍存在的问题,引入了空间注意力模块来关注特征图的空间位置信息,从而提高ESC中网络的性能。空间注意力模型如图4所示。

图4 空间注意力模型
获得空间注意力特征图的主要步骤如下:
将一个大小为(H*W*C)的特征图M输入网络,通过卷积核(H*1)和(1*W)分别沿横轴和纵轴对每个通道进行编码,因此第c通道在频率h,时间w处的输出可表示为:
(2)
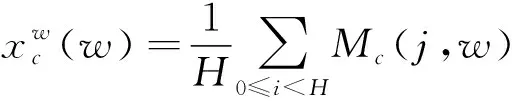
(3)
将式(2)和式(3)得到的特征图进行拼接,最后进行卷积运算,如式(4)所示。
(4)
式中:ReLU为激活函数;conv为一种卷积运算,卷积核大小为(1,1);BN为批量归一化;f∈R(H+W)C/r是融合特征图,涵盖2个方向上的空间信息,即水平和垂直方向;r为沿通道维度的压缩比,设置为8;f是沿空间维度被分割成的2个独立张量,即fh∈RH×C/r和fh∈RW×C/r,后面是2个卷积运算convh和convw,包含的卷积核总数等于输入特征图M的通道数,卷积核大小为(1,1)。
zh=σ(convh(fh))
(5)
zw=σ(convw(fw))
(6)
将式(4)的结果分别代入式(5)和式(6),得到zh和zw,分别为包含沿水平方向和垂直方向信息的张量,其中σ是sigmoid激活函数。最后,将式(5)和式(6)的结果代入式(7),得到最终的注意力特征图S。
(7)
从式(7)可以看出,最后的注意力特征图Sc(i,j)的每个位置的值是通过原始特征图Mc(i,j) 乘以包含水平方向信息和垂直方向信息的张量加权而得来的,这样可以精确定位特征图的突出区域。
1.3.2通道注意力模型
要使网络更加关注显著特征的通道,应用通道注意力机制将十分有效。在众多通道注意力机制中,SE注意力机制[10]是典型的通道注意力机制,图5为SE通道注意力机制模型。通常SE分为2个步骤操作:压缩和激励。压缩是一种获得全局特征向量的方式,具体操作是全局平均池化特征图的空间维度。而激励操作是将压缩后的特征向量输入两层全链接层,获得注意力权重矩阵,之后再与原始特征图的对应通道相乘,得到增强后的特征图。
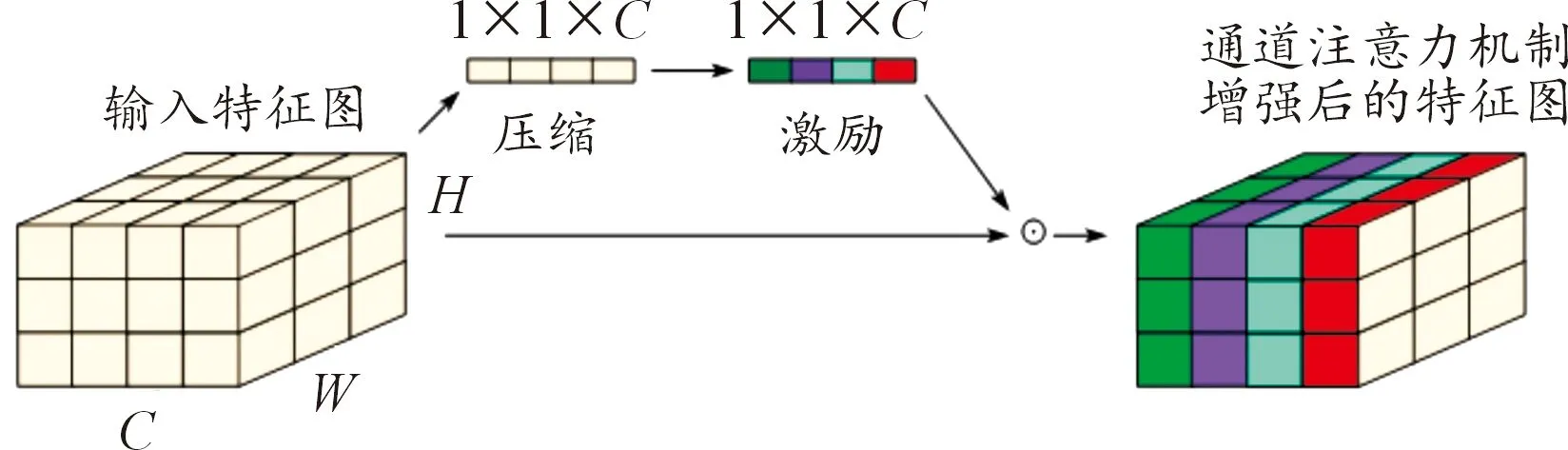
图5 SE通道注意力机制模型
输入的特征图xc(i,j)首先要全局平均池化,池化公式如下:
(8)
然后通过激励操作获得每个特征通道对应的权重,可由式(9)定义。
wc=σ[conv2(ReLU(conv1(gc)))]
(9)
式中:wc代表第c个通道对应的注意力权重;σ代表sigmoid激活函数;conv1代表含有C/r个卷积核,卷积核大小为(1,1);conv2为含有C个卷积核的卷积运算,卷积核大小也为(1,1),卷积核中会进行卷积运算;r是特征通道维数压缩比,设置为8。
经过增强后的特征图可由式(10)得到。
zc=wc⊙fc
(10)
式中:zc表示经过增强的第c个特征图;⊙为对应通道相乘;fc∈RH×W表示第c个原始特征图。
1.3.3空间通道注意力模型
由于卷积运算获得的跨通道信息与空间信息之间的关系错综复杂,因此增加对二者的注意力机制,突出关键特征至关重要。具体来说,通道注意力机制更加关注显著特征的通道,空间注意力机制有助于突出特征图中特定的空间位置信息,因此可以将通道和空间2种注意力机制结合,从而得到更好的处理结果。图6为提出的空间通道注意力机制模型。
由式(10)可得到经过空间通道注意力模型增强后的特征图。
Rc(i,j)=zc⊙Sc(i,j)
(11)
式中:⊙代表对应通道相乘;zc和Sc(i,j)代表由通道注意力模型和空间注意力模型得到的增强后的特征图。

图6 空间通道注意力机制模型
1.4 数据增强
为了解决数据不足导致的过拟合问题,采用混合[11]数据增强方法对离散样本空间进行线性插值,以提高邻域的平滑度。混合算法定义如下。
(12)
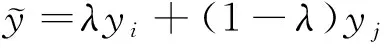
(13)
式中:xi和xj是来自训练数据集中的2个样本特征,为随机选取且具有泛化性;yi和yj是相应的one-hot标签;λ是服从参数为α和β的Beta分布,即λ~Beta(α,β),其中α和β都为0.2。图7为几个ESC-10数据集中的Log-Mel谱图混合增强的例子,用红色框圈出来的数值表示的是2种不同类型的Log-Mel谱图的混合比例,两者混合比例之和为1。可以将2种不同类别的Log-Mel谱图以随机比例混合形成新的特征图,以实现数据的混合增强。
2 实验结果
2.1 数据集
在2个公开的声音识别数据集上(ESC-10、ESC-50[12])对所提方法的优劣进行了验证实验。这2个数据集是通过Freesound项目公开获得的录音中的声音片段构建的,声音样本以44.1 kHz,单通道,192 kbit/s的Ogg-Voorbis格式进行压缩,数据集的格式为wav。对2个数据集的描述如下。
ESC-50数据集:该数据集的音频总时长为2.8 h,它是拥有2 000个环境声音音频的集合,其中的每个音频的时长有5 s。整个集合共有50个语义类(其中每类都有40个样本例子),可粗略的分为5大类声音:自然环境音、动物叫声、流水声、人类非交流声以及室内室外声。数据集预先划分为5个部分,以便于后续的交叉验证。
ESC-10数据集:该数据集可以看成是ESC-50数据集的一个子集,类别总数为10类(海浪声、狗吠声、雨声、婴儿啼哭声、时钟滴答声、打鼾声、直升机飞行声、公鸡打鸣声、电锯声、火焰燃烧声)。每个类别也包含40条音频。
2.2 实验环境
实验是在Window 10操作系统,显存8 GB,内存32 GB,显卡为英伟达RTX2080的硬件环境下完成的。深度学习框架为Python-Tensorflow-2.5.0版本,采用Python语言编程。
在训练阶段,采用的损失函数为交叉熵函数,迭代次数设置为300,初始学习率为0.000 02,然后每迭代50次后将学习率缩小10倍,batchsize设置为32。样本在训练前是乱序的,网络权重是随机初始化的,Adam优化器用于优化损失函数。在测试阶段,网络的最终准确率为交叉验证后的平均准确率。训练和测试阶段涉及的Log-Mel谱图均采用训练集的全局平均值和标准差进行归一化操作。
2.3 实验结果
表2为所提出的网络与现有最好的环境声音分类方法的最佳准确率,模型的最终准确率为交叉验证后的平均准确率。
由表2可以看出,所提网络模型在2个数据集上的识别准确率分别为94.3%和79.3%,与大部分现有网络相比,准确率有明显提升。与MCTA-CNN相比,所提模型在2个数据集上的识别准确率下降了0.2%和7.8%,这是由于MCTA-CNN是通过多通道时间注意力机制和离线数据增强的方法(ESC-10为1 600个样本,ESC-50为8 000 个样本)来训练的,使用Log-Mel谱图、一阶变量和二阶变量的特征图沿通道维度进行堆叠作为输入,整个过程十分繁杂耗时。所提的方法实施起来是比较简单的,但代价是准确率略有下降,但已能够满足生活中大部分声音识别的场景。

表2 所提网络和现有网络的识别准确率 %
2.3.1模型在ESC-10上的分类效果
图8为所提网络模型在ESC-10数据集的混淆矩阵,模型的平均准确率为94.3%。

图8 在ESC-10数据集上的混淆矩阵
从图8可以看出,电锯(Chainsaw)、直升机(Helicopter)和打鼾(Sneezing)的声音都获得了100%的识别率。大多数声音识别的准确率都高于90%(36/40)。其中婴儿啼哭声(Crying baby)识别准确率最低,为85.0%(34/40),分别有10%(4/40)、2.5%(1/40)和2.5%(1/40)的样本被误分类为时钟滴答声(Clock tick)、犬吠声(Dog)和火焰燃烧声(Crackling fire),因为上述这些环境声音特征非常相似,所以可能导致分类错误。
如图9所示,为了便于体现所提出的模型的有效性,从2个角度(即二维视图(2D)和三维视图(3D))使用t-SNE算法,分别对ESC-10的原始数据集和训练后得到的特征分布通过Softmax层进行可视化表示。需要注意在图9中的同一声音类别的样本点颜色相同。
由图9可以发现,ESC-10的原始数据集的潜在特征分布是混乱无序的,不同类别之间相互交错,可分性差。通过网络模型训练后,潜在特征分布变得更加紧凑,同一类别的大多数样本会汇聚在一起,并且可分离性较强。

图9 模型训练前后ESC-10数据集潜在特征分布
2.3.2模型在ESC-50上的分类效果
图10为所提模型在ESC-50数据集上的混淆矩阵,模型的平均识别准确率为79.3%。从图10可以看出,雨声(Rain)的识别准确率为20%(8/40),是所有声音类型中识别率最低的,大多数的雨声被错误地识别为犬吠声(Dog)(6/40)、猫叫声(Cat)(5/40)、水滴声(Water drops)(4/40)和海浪声(Sea waves)(4/40),这主要是雨的频率响应范围很宽造成的。此外,响雷声(Thunderstorm)、烟花爆竹声(Fireworks)、脚步声(Footsteps)和玻璃破碎声(Glass breaking)有97.5%(39/40)的识别准确率,是所有声音类型中识别率最高的。

图10 在ESC-50数据集上的混淆矩阵
2.4 实际场景测试
除了在公共数据集上验证网络模型性能外,还收集了现实世界中的一些环境声音片段,并用训练好的网络模型识别其声音类别,如图11所示。

图11 环境声音采集场景
以上每个场景都收集了3段5 s的声音片段,所以总共有12段环境声音片段进行实际场景测试。经过预处理后,上述场景声音的Log-Mel谱图示例如图12所示。

图12 实际声音场景的Log-Mel谱图
随后,将采集的音频输入训练好的模型进行分类,检验其识别准确率,测试结果的混淆矩阵如图13所示。

图13 采集的环境声音片段的混淆矩阵
从图13可以看出,网络模型对于采集的环境声音片段的分类准确率约为91.67%,没有准确识别所有音频的原因可能是分类有误的两类声音时频域特征比较相似。还需要注意的是上述环境声音片段是利用手机麦克风进行采集的,并没有使用专业的录音设备。
3 结论
1) 空间和通道结合的注意力机制模型相比于单一的通道注意力机制或空间注意力机制模型更有优势,用来训练网络效果更佳。
2) 采用混合增强保证数据的多样性,可以提高模型的泛化能力以及识别的准确率。
未来将尝试利用计算机视觉领域的方法,找出更简单、更可行、更有效的方法来解决环境声音分类的关键问题。
