雨天下基于注意力机制与特征融合的交通标志识别
2023-12-12查超能罗素云
查超能,罗素云,何 佳
(上海工程技术大学 机械与汽车工程学院, 上海 201620)
0 引言
交通标志识别(traffic sign recognition,TSR)技术是高级驾驶辅助系统(advanced driving assistance system,ADAS)和自动驾驶系统(automated driving system,ADS)的重要组成部分,它可以帮助驾驶员和自动驾驶车辆捕捉重要的道路信息。
TSR可分为2种:一是交通标志检测,主要包括获取图像、预处理和阈值分割;二是交通标志识别,主要包括交通标志特征提取和分类[1]。交通标志检测是交通标志识别的前提,交通标志检测是否正确,将直接影响到最终识别结果。
而在现实环境中,交通标志的检测识别极易受到环境、天气和车速等因素的干扰,需要在无法预知的复杂天气及环境下进行检测识别,其检测速度和精度往往会受到极大影响。如何减少外界干扰使TSR系统在已有移动计算设备支持下较准确地完成交通标志的检测和识别,同时保证算法的实时性是本文着重解决的问题。
王文成等[2]提出了一种雨、雪天气中的道路交通标志识别方法。在图像去雨方面,主要使用低通滤波处理方法将不同类型的雨雪特征进行分类;在交通标志识别方面,主要根据交通标志特有的颜色、形状、梯度以及位置建立了多层特征显著性模型,从而提升了分类的效率和准确度[3]。Mohamed等[4]使用马来西亚交通标志数据集(malaysia traffic sign dataset,MTSD)测试3种方法(自动白平衡(automatic white balance,AWB)、策略增强和图像到图像转换(image-to-image-translation,I2IT)技术)对雨天交通标志检测性能的影响。
虽然以上方法对雨天环境进行了不同程度的研究探讨,但大多采用传统的先验去雨算法,较少使用深度学习的去雨算法,其可靠性有待考证,也很少涉及对TT100K中涵盖多个小目标检测识别任务进行研究。
本文对雨天环境下交通标志检测识别进行研究,首先对现有数据集进行处理,生成雨天环境下的交通标志数据集,并提出一种基于YOLOv5的改进交通标志检测识别网络YOLOv5s-traffic。在图像预处理阶段添加了去雨模块和图像增强模块,针对交通标志检测识别的需求,通过引入4种改进方法,显著提高网络的整体性能,提出的算法可针对晴天和雨天环境灵活切换使用。
1 雨天环境下交通标志检测识别架构
如图1所示,YOLOv5s-traffic整体架构主要由3部分组成,分别为去雨模块、图像增强模块与基于注意力机制与特征融合方法改进的YOLOv5交通标志检测识别网络。

图1 YOLOv5s-traffic整体架构示意图
去雨模块采用的是基于对抗生成网络的去雨算法,由于该网络是基于深度学习方法,可根据不同雨天环境个性化训练达到良好的去雨效果。
图像增强模块采用的是MIRNetv2图像增强模块,该网络可自由调节不同的增强方法达到不同的增强效果,而由于雨天环境通常会模糊图像,本文中采用超分辨率(super resolution,SR)方法对模糊图像进行视觉增强,去除一定的模糊干扰,降低后续检测识别的难度。
针对TT100K小目标数据集,基于注意力机制与特征融合方法的YOLOv5交通标志检测识别网络在4个方面对网络进行了改进。通过向主干网络(backone)引入Transformer模块、在网络颈部(neck)中加入CA注意力机制、在网络检测头(head)中加入ASFF特征融合机制和将原先的CIoU(complete-IOU)改进为SIoU (SCYLLA-IoU)检测框损失函数对网络的性能进行了全方位增强。
而为保证交通标志检测识别网络对于准确性和实时性的平衡,对去雨模块与图像增强模块作出相应改进,通过对特征提取次数的减少和方式的改进来适应网络对于实时性的要求,实验证明可通过这种方法在网络实时性大幅提升的同时,略微降低其处理效果。
最后,为使得网络可模块化搭配使用,满足不同的环境需求(晴天和雨天)与性能需求(精确度与实时性),将去雨模块和图像增强模块图像处理前后大小进行了统一,即保证模块输出前后的图像大小一致,同时设置了2条处理捷径。因此,图像在进入网络后可根据环境需求选择是否去雨,并可根据是否需要更精确的识别进行图像增强,来满足不同环境和性能的需求。
1.1 去雨模块
处理交通标志检测识别因雨滴带来的外部干扰主要有2个困难,首先是没有给出被雨滴遮挡的区域,其次是遮挡区域的背景环境信息大部分完全丢失。
因此,为解决这2个问题,从问题根源着手,将基于对抗生成网络(generative adversarial network,GAN)[5]的去雨算法融入到交通标志检测识别算法中,通过视觉上去除雨滴来解决根本问题。从而将带有雨滴的图像转化为干净的图像,大大减少后续目标检测识别网络的阻碍[6]。
图2所示为去雨模块深度架构,图像从输入到输出的大小没有变化,而在中间部分通过卷积、池化、反卷积和反射填充操作来缩放图像大小和深度,以获得浅层次和深层次的雨滴及其周围环境特征,达到良好的去雨效果。原网络共有165层,6 747 789个参数。
本文中去雨模块的主要想法是将视觉注意力注入生成器(generator)和辨别器(discriminator)[7],首先通过生成器找到雨滴特征并恢复为无雨形象,接着通过辨别器引导注意力地图来判别图像受雨滴影响主要部分的真实性,最终将结果传回生成器来优化其去雨效果。该生成对抗网络的损失函数如式(1)所示。
minGmaxDER~Pclean[log(D(R))]+
El~praindrop[log(1-D(G(I)))]
(1)
式中:G表示生成网络;D表示判别网络;I表示从雨天图像池中抽取的样本;R表示从干净图像中选取的样本。
图3展示了生成器和辨别器的网络架构。对于生成器部分,每张图片在输入后需要经过由5层ResNet、卷积LSTM和1个生成2D注意力地图(attention map)的卷积层组成的注意力循环网络(attentive-recurrent network)来进行雨滴特征提取,随后进入1个上下文自编码器(contextual autoencoder)生成去雨图像。对于辨别器部分,输入图像首先在7个卷积层中提取特征,然后在1个全连接层中判别图像真假。
本文中对该网络结构进行进一步简化处理,通过牺牲部分去雨效果来换取更多的实时性。同时,该网络结构作为目标检测识别网络中的图像预处理模块,仅需保留生成器部分来输出处理图像,可大大节省算力。具体处理方法是将原先的特征提取部分进行简化,使网络结构从165层下降为134层,参数量下降167 809;当输入100×100的三通道图像,所需内存大小仅为326.31 MB,比原先下降约20%。
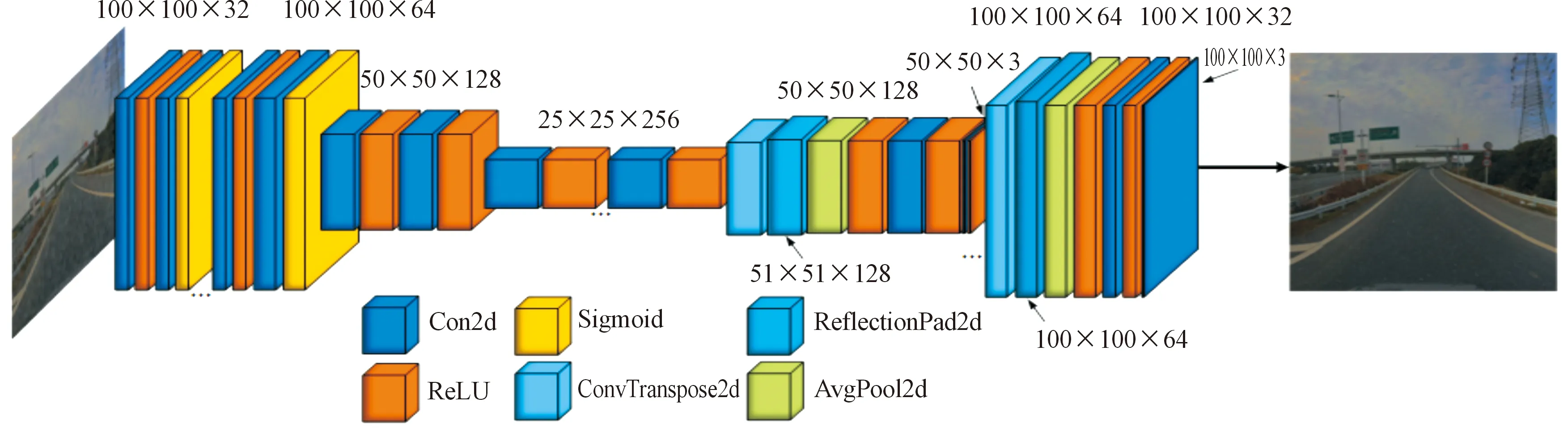
图2 去雨模块深度架构示意图
在训练过程中,放入TT100K的有雨和无雨环境对进行训练,视觉注意力会学习雨滴区域及其周围环境,通过观察这些区域,判别网络将能够评估恢复区域的局部一致性[8]。具体做法是将自制TT100K雨天数据集和原数据集输入到网络训练得到相应权重,并且通过将不同程度的雨天环境数据集代入对抗生成网络进行个性化训练,得到不同的去雨效果,模块的去雨能力具有极大的灵活性。经实验证明,使用该模块能极大地恢复雨天环境下的交通标志数据集,降低雨天环境对交通标志检测识别可靠性的阻碍。
1.2 图像增强模块
一个优良的感知网络,不仅是网络自身检测识别的能力,同时也包含去干扰以适应各种环境的能力。将图像增强模块加入网络前处理部分,可以极大地降低后续网络检测识别的难度。
MIRNet-v2[9]的整体目标是通过整个网络保持空间精确的高分辨率表示,并从低分辨率表示接收互补的上下文信息[10]。该方法的核心是一个多尺度残留块,其核心思想在于:用于提取多尺度特征的并行多分辨率卷积流、跨多分辨率流的信息交换、用于捕获上下文信息的非局部注意力机制,以及基于注意的多尺度特征聚合[11]。如式(2)所示,使用Charbonnier loss优化该网络,其中I*表示地面真实图像,ε是一个常数。
(2)
图4所示为MIRNet-v2框架,图像从左侧输入完成图像增强后输出到右侧。该框架可学习丰富的特征表示,用于图像恢复和增强。

图4 MIRNet-v2框架示意图
将图像处理网络MIRNet-v2嵌入交通标志检测识别网络,以增加网络适应各种雨天环境的能力,同时通过减少MIRNet-v2中RRG和MRB的层数以加快网络推理速度。MIRNet-v2以原始分辨率处理特征,保留空间细节,同时有效地融合来自多个并行分支的上下文信息,在图像处理时便能保证不会破坏原始信息。由于TT100K交通标志数据集是小目标检测,所以本文中使用MIRNet-v2中的超分辨率网络以尽量减小雨天环境下带来的模糊干扰。
2 基于注意力机制与特征融合方法的YOLOv5多重改进模型
YOLOv5整个网络模型分为4个部分:输入层、主干层、颈部层和预测层。图5展示了YOLOv5s-traffic的网络结构和各模块的详细结构。

图5 YOLOv5s-traffic结构示意图
不同于原先的网络结构,本文中通过向主干网络引入Transformer模块(C3TR模块)、在网络颈部中加入CA注意力机制(C3CA模块)、在网络检测头中加入ASFF特征融合机制(ASFF-Detect模块)和将原先的CIoU改进为SIoU检测框损失函数对网络的性能进行增强。
2.1 添加Transformer模块
图6所示为VIT[12](vision transformer)结构,该网络通过标准的视觉Transformer对图像进行处理。首先对图像进行切片分割,然后通过位置和Transformer编码实现多头注意力机制(multi-head attention)图像处理,最后经过多层感知机(multilayer perceptron,MLP)对图像进行缩放操作后进行交通标志分类。
本文中通过在骨干网络中加入Transformer模块,引入位置编码机制,来解决传统卷积神经网络对交通标志检测识别的自注意力机制(self-attention)排列不变(permutation-invariant)问题。对于机器学习而言,特征之间没有空间位置关系,输入序列顺序的调整不会影响输出结果,而对于卷积神经网络而言,需要Transformer中的位置编码机制来解决特征之间关于空间位置关系的问题。
将C3替换为C3TR,C3与C3TR模块的不同之处在于将Bottleneck替换为Transformer Block(如图7所示),即通过将Bottleneck中原先的 1×1卷积降维、3×3卷积升维和相加操作改进为Transformer结构,实现可学习的嵌入方法。该结构对图像使用Transformer对自然语言特有的处理方法,结构中的Attention和MLP模块可控制循环次数,通过引入空间位置关系,达到传统卷积网络无法达到的良好分类效果,从而大大提升如TT100K这样的小目标检测识别任务的精确度。
2.2 融合CA注意力机制
坐标注意力(coordinate attention,CA)机制[13]旨在增强移动网络学习特征的表达能力,可以对网络中的任意中间特征张量进行转化变化后输出同样尺寸的张量[14]。通过捕获位置信息和通道关系,增强移动网络的特征表示。
本文中将CA注意力模块嵌入到YOLOv5网络中,对于交通标志检测识别而言,可进一步强化网络对方向和位置等信息的敏感度,提升网络性能。
2.3 添加ASFF特征融合方法
金字塔特征融合策略(adaptively spatial feature fusion,ASFF)[15]能够在空域过滤冲突信息以抑制不一致特征,如图8所示,可提升网络对不同尺度目标的特征融合能力。
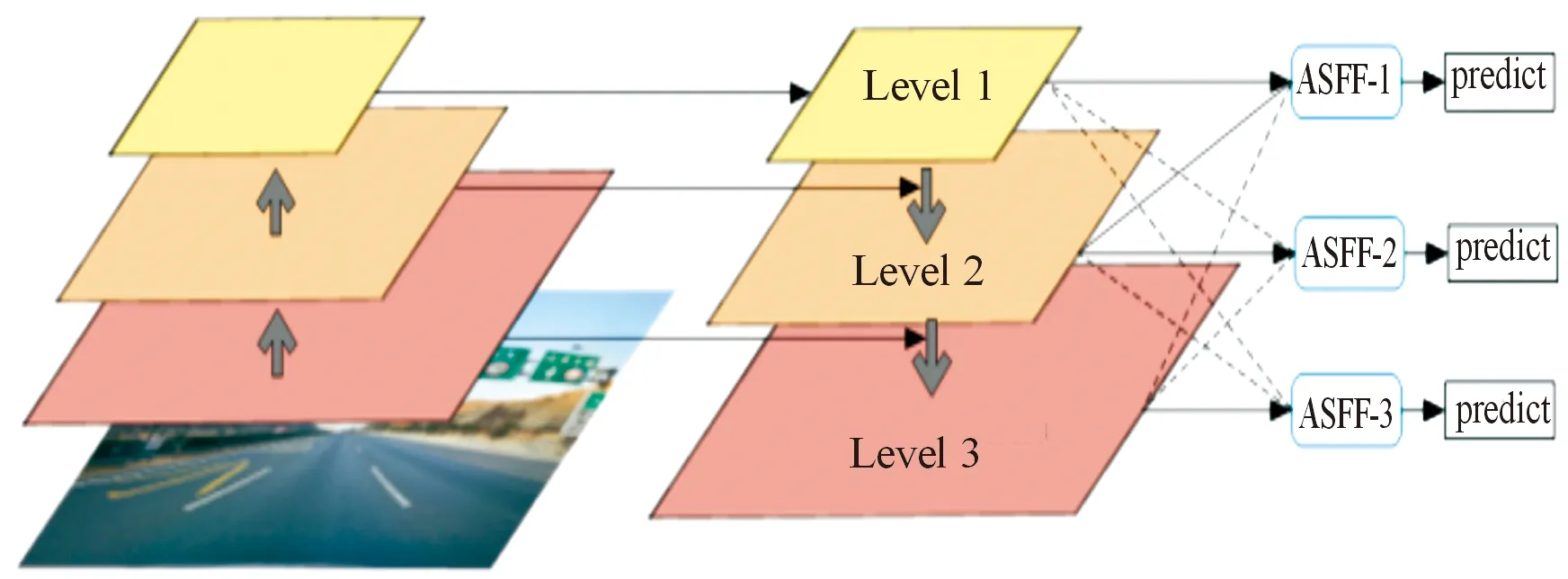
图8 ASFF特征融合过程示意图
本文中将ASFF特征融合方法加入网络的检测头部分,使得网络能够直接学习如何在其他级别对特征进行空间滤波,从而仅保留有用的信息以进行组合。
将ASFF加入YOLOv5网络有2个优势:一方面,由于搜索最优融合的操作是可微的,可使网络更好地利用回归算法进行反向传播学习;另一方面,其实现较为简单,与基础网络无关,附加计算代价极其小。因此,在交通标志检测识别网络准确性和实时性方面[16],ASFF特征融合方法可通过学习不同特征图之间的联系来解决特征金字塔的内部不一致性问题的同时,兼顾计算代价。
2.4 损失函数改进
原YOLOv5中使用的损失函数为CIoU[17],而本文将原先的CIoU改进为SIoU,除考虑CIoU已经考虑的3个要素(预测框和真实框的距离、重叠区域和纵横比)外,加入了角度因素,解决了使用CIoU训练模型时方向不匹配的问题。
SIoU[18]中的角度因素用于辅助两框之间的距离计算,由于在目标检测的起始训练中,大多数的预测框是跟真实框不相交的,所以如何快速地收敛两框之间的距离是值得考虑的。
图9所示为SIoU回归示意图。不同于CIoU,SIoU在考虑两框角度和距离时引入了角度参数α和γ,角度的大小决定着模型的回归方向。当角度小于45°时,使用α角度,模型沿着x轴使预测框相接近;而当角度大于45°时,模型切换到β角度,模型将预测带到y轴继续接近。同样对于γ参数而言,通过观察Λ角度参数相对于1的大小,来判断两框之间的距离和角度对于整体loss的贡献。
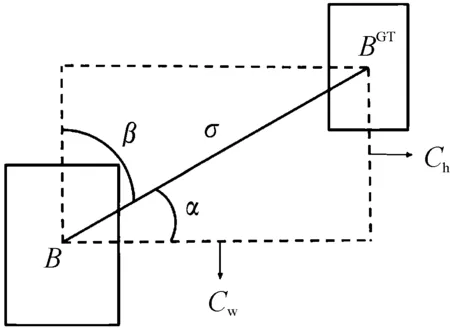
图9 SIoU回归示意图
如式(3)所示,最终损失函数由分类损失(classification loss)和坐标损失(box loss)组成,其中Lcls为焦点损失,Wbox和Wcls分别为坐标损失和分类损失权重。
L=WboxLbox+WclsLcls
(3)
在交通标志检测识别中使用SIoU可以极大地改善模型的整体性能。通过在损失函数中引入方向性,降低损失自由度,在训练阶段实现了更快和更准确的收敛,并且在推理方面具有更好的性能。
3 实验结果及分析
3.1 数据集构建
对于在雨天环境下的交通标志检测识别,必须具备雨天环境下的交通标志数据集。图10所示为原环境与3种雨天环境(小雨、中雨及大雨)数据集的前后对比。不同种类的雨天图像较原图像加入了不同程度的雨滴干扰并进行了模糊化和暗化处理,在不改变图像分辨率的情况下3种雨天环境使得图像质量分别下降约20%、30%及40%,对于小目标检测识别任务而言,难度显著增加。
而数据集的构建分为数据处理和数据划分两步骤:
第一步是数据处理,由于户外拍摄新数据集无法横向比较网络的可靠性,所以本文通过使用pix2pixHD条件对抗生成网络(conditional GANs,cGANs)结合Automold自动驾驶环境构建库来对TT100K(Tsinghua-Tencent 100K)交通标志数据集进行处理以最大限度还原雨天场景,且通过控制pix2pixHD网络训练的输入(雨天环境雨滴的强度)以及使用Automold库调整场景能见度来有效还原3种雨天环境。确保每张图片还原雨天环境的真实性以检验网络对雨天场景的适应能力,且通过不改变图像大小以保证官方标签的准确性。
由于不同种类的雨天场景对目标检测的干扰程度不同,为检验本文中网络处于不同类型雨天环境的实际检测能力,使用峰值信噪比(peak signal to noise ratio,PSNR)与结构相似性(structural similarity,SSIM)指标来综合衡量所构建不同类型雨天场景相对于原环境的真实差异。
将原环境数据集的数据与其对应的3种雨天环境中的数据一一对应计算PSNR与SSIM,并对其取均值以获取3种雨天环境相对原环境的阈值,如表1所示。设定PSNR≥28 dB且SSIM≥0.7为小雨;26 dB≤PSNR<28 dB且0.6≤SSIM<0.7为中雨;25 dB≤PSNR<26 dB且0.5≤SSIM<0.6为大雨。
对比而言,3种雨天环境相对于原环境的PSNR与SSIM均有不同程度的下降,且雨天强度越大,能见度越低,两值越低。

表1 不同雨天环境对比
第二步是数据划分,将图像按照 8∶2 的比例划分训练集和测试集,共计图像3 415张,包含训练集2 390张,测试集1 025张。同时,为丰富数据量并减少过拟合,在加入雨天环境后,对整体数据集进行了数据增强并重新进行了标注。而由于交通标志的翻转会带来错误的特性(例如左转和右转),放弃了翻转和镜像2种增强方式,仅通过图像缩放和旋转2种方式对原始图像进行数据增强。
3.2 评价指标
通过平均精度值(mAP)、帧率(FPS)和模型复杂度(GFLOPs)等指标来评估网络性能,使用原数据集和雨天数据集分开对网络进行评价。
(4)
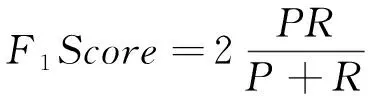
(5)

(6)
如式(4)(5)(6)所示,其中mAP是整体性能的指标,由对多个验证集个体求平均AP值得到; 使用精确率(P)和召回率(R)这2个指标来衡量模型的好坏,并使用F1score来权衡考虑两者以提升模型决策效率;而FPS衡量检测方法实时性的指标,代表检测网络每秒可以处理的图像数量。
3.3 实验环境
采用Pytorch深度学习框架,使用Python编程语言,Ubuntu 20.04.3操作系统,硬件配置为GeForce RTX 3080显卡,10 GB显存。具体训练环境如表2所示。
表2 基于Pytorch训练环境
设置初始学习率为0.01,使用余弦退火算法和warm-up学习率优化方法。Batch size设为16,在130个epoch后停止训练。
3.4 实验结果分析
改进YOLOv5s-traffic算法在不加入去雨和图像增强模块时,对于原TT100K数据集,其平均识别准确率达到了88.6%,与原YOLOv5算法相比提升了5.4%,FPS达到50.4帧/s,较原网络仅下降了18.3帧/s,说明改进后的YOLOv5算法对原环境下可以在保证实时性的同时能更准确地对交通标志进行检测识别。图11所示为改进后训练和验证过程中整体损失变化,在网络改进之后训练损失相对验证损失收敛速度明显更快,训练损失和验证损失都逐渐下降至较小值,且验证过程的最终损失明显更小。
在雨天环境下,包含去雨模块和图像增强模块的YOLOv5s-traffic算法,其对雨天的准确率达到了75.3%,相较于不使用两模块和主网络改进方法提升了12.5%,FPS达到了49.4帧/s,说明改进后的YOLOv5算法对于雨天环境也可以在保证实时性的同时大幅提升对交通标志进行检测识别的精度。而当不包含图像增强模块时,其算法准确率仅上升了5.3%,说明了在去雨模块与YOLOv5网络间嵌入图像增强模块的必要性。
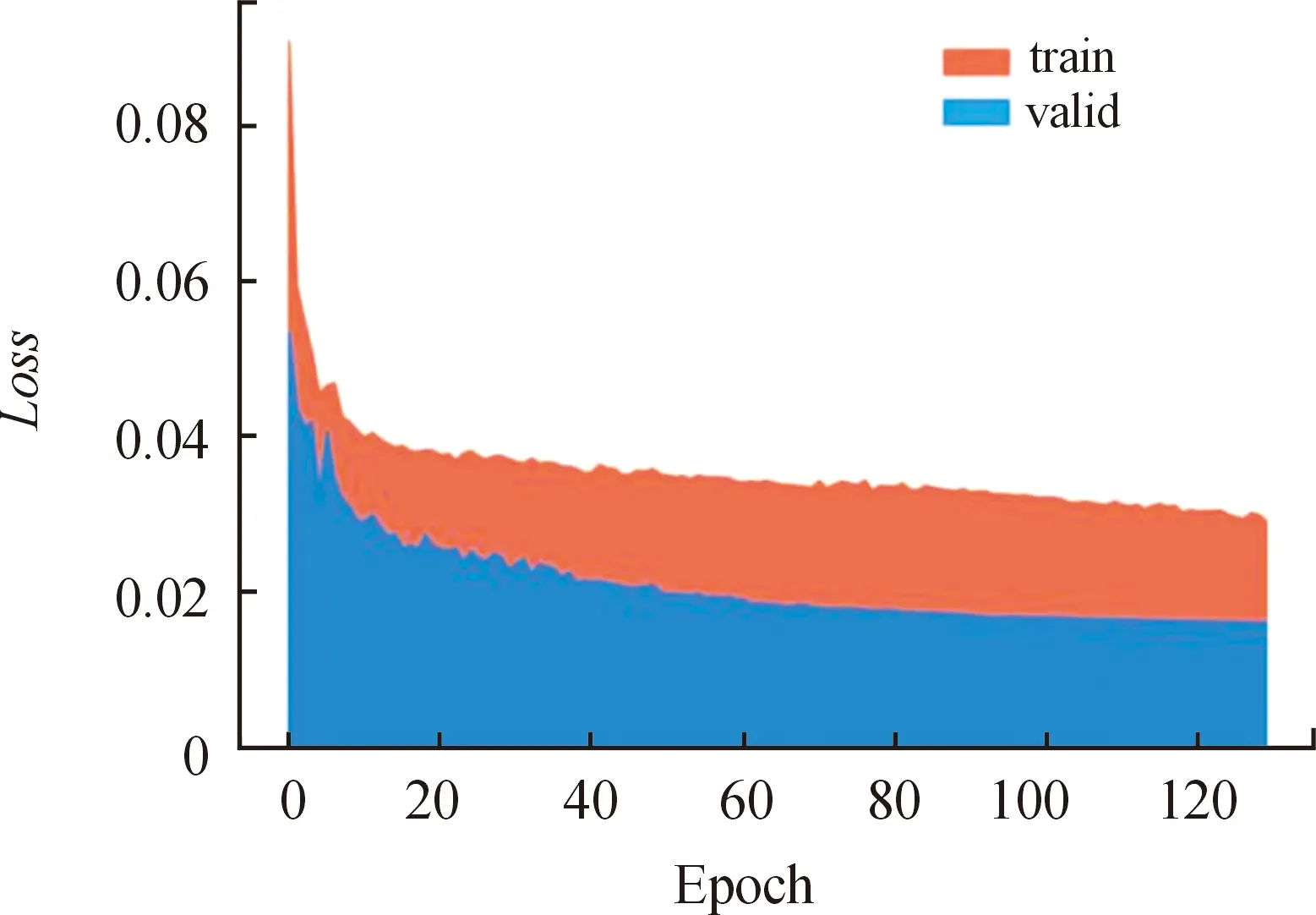
图11 损失变化曲线
3.4.1模型大小对比
首先从模型的大小进行对比分析,将原YOLOv5模型与加入各种改进方法的模型进行对比实验,同时也将Faster RCNN与YOLOv4作为参考目标纳入对比范围。
表3列出了衡量不同模型大小的两项重要指标。可以看出,仅修改网络结构而未加入去雨和图像增强模块的YOLOv5s-traffic的参数量为11.26 M,GLOPs为21.4。其参数量与原YOLOv5s相比提升了4.2M,模型复杂度与原YOLOv5s相比上升了约24%,但仍远远小于Faster RCNN和YOLOv4,分别为其8.5%和71.5%,表明了YOLOv5s-traffic相比于其精度的提升并不会增加太多的参数量和模型复杂度。
而模型在加入去雨模块后,其参数量分别提升了6.2M,其GLOPs提升了14%,仍远小于Faster RCNN和YOLOv4的数据量和复杂度,对于雨天这样的复杂环境而言在可接受范围内。
在模型中继续加入图像增强模块后,其参数量再次提升了3.8M,其GLOPs提升了22%,模型仍然平衡和准确性和实时性,其计算成本的消耗带来了的是精度的显著增加。
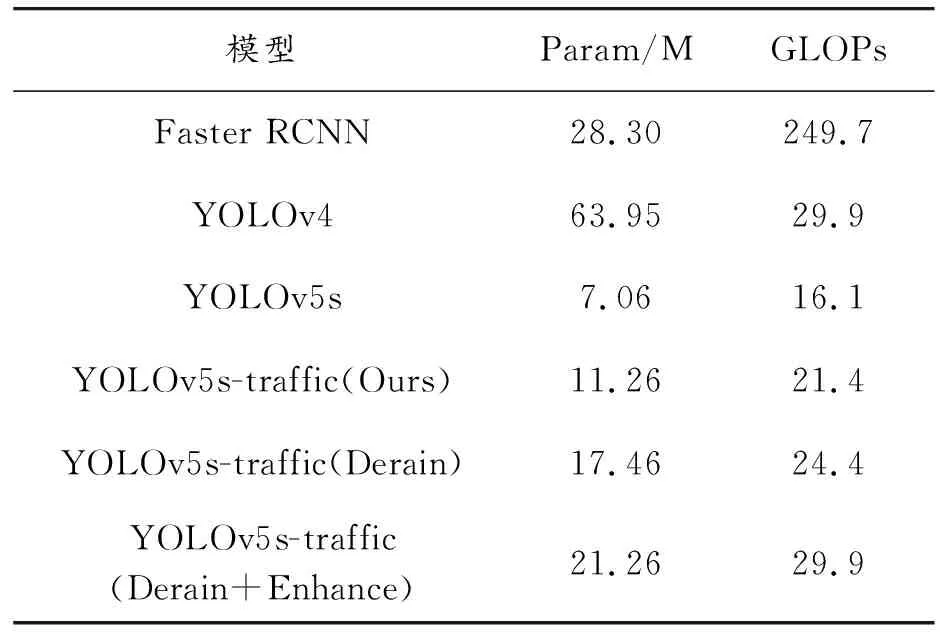
表3 模型大小指标
3.4.2消融实验
为验证YOLOv5s-traffic各成分的有效性,对所有模块进行了消融实验,所有实验均在同一交通标志数据集(TT100K)上完成,并将其分为原环境和雨天环境以展示网络在不同环境下的表现。在TT100K中随机选取了2 215张图像对模型进行评估,去雨和图像增强都是在这基础上进行,保证了原环境和雨天环境的统一性。当统一设置输入图像分辨率为640×640, Bitch-size为1时,认为FPS大于30帧/s可达到实时处理。由于去雨模块和图像增强模块都属于图像预处理,因此不会改变模型结构、影响推理速度[19]。
表4所示为原环境下YOLOv5网络在是否加入图像增强模块和主网络改进方法(主干网络、颈部、检测头和损失函数)的消融实验。从中可知,在分开加入图像增强模块和主网络改进方法后,后者较之前者mAP有显著提升,而当将两者一同加入后叠加效果产生了7.2%的大幅提升。对比后文雨天环境下图像增强模块的使用可大幅增加mAP,说明即使图像增强模块中的多尺度残留块可较好地融合上下文特征,达到高低分辨率特征相互巩固的效果,但由于晴天环境下原图像的质量本身就足够高,因此其对于图像识别精度提升不大。相对而言,注意力机制和特征融合方法在晴天环境下可显著提升mAP,且FPS仅下降了18.3帧/s,仍能远超图像实时处理的基准。
如表5、表6及表7所示,为雨天环境下YOLOv5网络在是否加入去雨模块、图像增强模块及主网络改进方法(主干网络、颈部、检测头和损失函数)的分别针对3种雨天环境的消融实验。
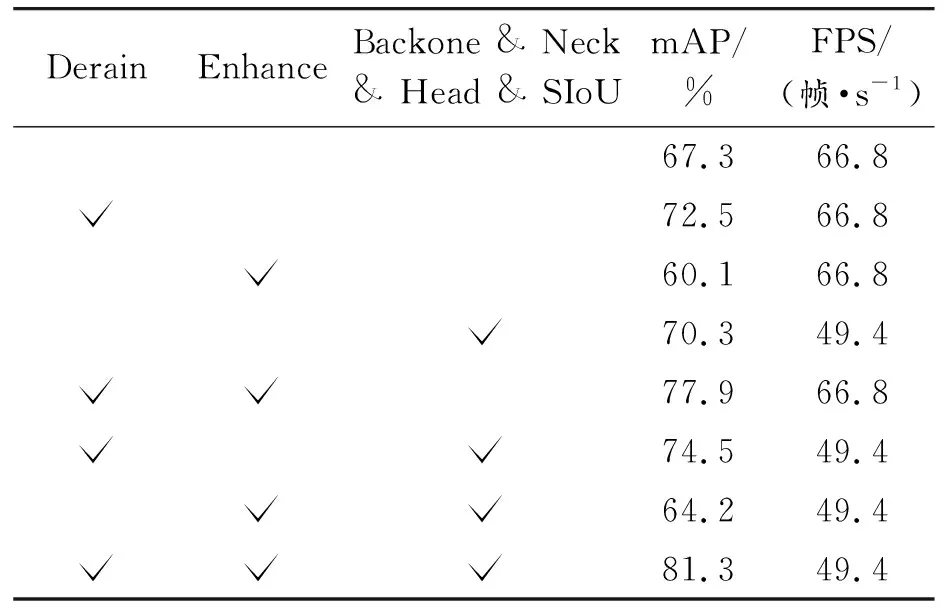
表5 消融实验(小雨环境)
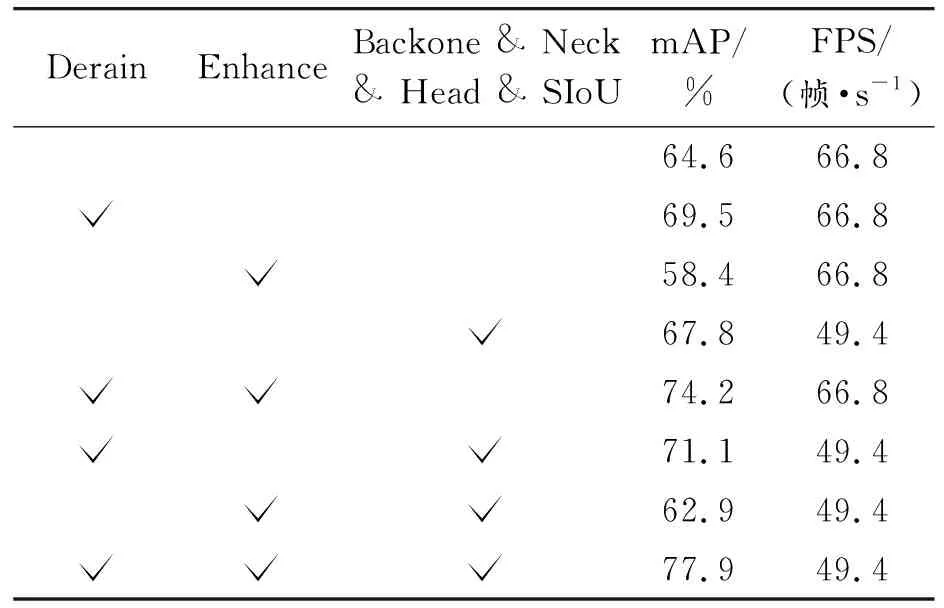
表6 消融实验(中雨环境)
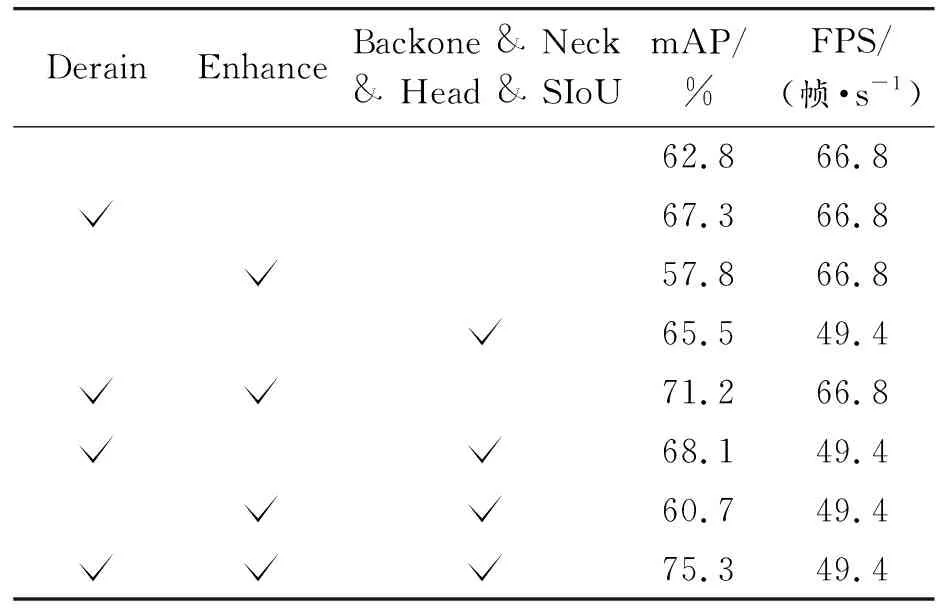
表7 消融实验(大雨环境)
中雨与大雨环境相对于小雨环境的mAP有不同程度的下降,其中中雨较小雨的下降幅度整体略大于大雨较中雨的下降幅度。在加入所有改进模型后,中雨较小雨与大雨较中雨的mAP分别下降了3.4%与2.6%。
为充分展现本文中算法对于雨天环境的适应能力,在此具体对比分析大雨环境相对原环境各指标的变化。在分开加入去雨模块和主网络改进方法后,mAP分别提升了4.5%和2.7%,证明去雨模块可很好地提取浅层次和深层次的雨滴及其周围环境特征,达到良好的去雨效果,且主网络中的多种改进方法相互配合可较好地在雨天环境下捕获位置信息和通道关系,并解决特征金字塔内部不一致性,同时极大地提升网络整体推理性能;而单独加入图像增强后下降较多,这是由于图像增强会连同雨滴干扰一同增强,说明在雨天环境下图像增强前必须先加入去雨模块尽量减少雨滴干扰才会有良好的精度效果。而在组合使用3种方法时,组合1(去雨和图像增强)达到了71.2%的mAP,组合2(去雨和主网络改进方法)有些许下降;同样是由于未使用去雨模块,组合3(图像增强和主网络改进方法)的mAP大幅下降;而3种方法一同叠加网络精度效果最好可达75.3%的mAP,说明YOLOv5s-traffic构建的雨天环境下交通标志检测识别网络中的两前处理模块可明显降低雨天环境带了的外部干扰,三者配合可达到最好的精度效果,而FPS下降了17.4帧/s,同样超过实时处理的基准。
3.4.3模型识别效果对比
本文分别展现了原环境和雨天环境、去雨模块前后应用和图像增强模块前后应用的效果对比图(左侧为原图,右侧为效果图)。从中可以看到,主网络在改进之后,识别效果有明显提升;而在加入去雨模块后,模型对雨天环境的适应性明显提升;再加入图像增强模块后,模型对雨天环境的识别精度再次提升,达到YOLOv5s-traffic的最好识别效果。
图12展现了原环境和雨天环境下模型对交通标志检测识别的效果。从图12中可以看到,改进模型不但提升了相对易检标志(pl50、p11和pn)的置信度,而且避免了难检标志(w57)的漏检问题,说明改进后的网络可较好地对模糊特征信息加以捕获,提升整体识别性能。

图12 原环境效果
图13—图16分别展现了去雨模块和图像增强模块在3种雨天环境下对交通标志检测识别的效果。类似于原环境,低置信度标志的提升要远好于高置信度标志,在雨天环境下由于环境干扰会导致许多标志无法检测,而加入去雨模块后可有效减少干扰,但会因环境干扰存在部分误检情况;应用去雨模块后,不同类型的雨天环境对于标志识别带来的不同程度的干扰大多是对其置信度的改变;而加入图像增强模块后可进一步增加识别精度,将大部分标志检测并正确识别,有效避免误检。

图13 小雨环境去雨效果

图14 中雨环境去雨效果

图15 大雨环境去雨效果

图16 图像增强效果
由此说明,改进的YOLOv5交通标志检测识别系统对于原环境可明显提高识别精度,对于小目标检测识别有良好的效果。而雨天环境的干扰会明显造成检测和识别的障碍,并显著降低置信度。在加入去雨和图像增强模块后,改进的YOLOv5交通标志检测识别系统对于雨天环境下的交通标志检测识别首先通过去雨模块生成的注意力地图准确找到雨滴特征替换为无雨形象,然后以图像增强模块融合高低分辨率的上下文信息生成特征信息更为明显的图像,最后输入到融合了多种特征提取方法适用于小目标检测的YOLOv5网络,可准确地获得交通标志特征信息,保证较高的识别准确率。
4 结论
针对当前目标检测识别模型极难在雨天环境下准确且实时地完成交通标志检测识别任务,基于YOLOv5提出了一种雨天环境下适用于交通标志检测识别模型YOLOv5s-traffic,该模型能极大地减少外部环境干扰,在小目标检测识别任务中取得良好效果。
该网络的前处理部分为一个基于对抗生成网络的去雨算法和一个基于多尺度残留块的图像增强算法,主干网络为融合了Transformer模块、CA注意力机制、ASFF特征融合方法和SIoU损失函数的YOLOv5网络,该融合方法可使网络无论在晴天还是雨天环境下均可在保证实时性的前提下显著提升检测识别精度。此外,通过对原始数据集进行大规模处理和重构,模拟了雨天环境中交通标志检测识别。实验表明,雨天环境对该任务有极大地干扰,而相对于原网络,mAP为75.3%,提升12.5%,且FPS达到49.4帧/s,网络在显著提升精度的同时可保证其实时性。对于ADAS和ADS来说,它是交通标志识别系统的一个进步;对于计算机视觉来说,它是对目标检测识别任务的一个贡献。
目前,主流的TSR方法和公共数据集主要涉及白天正常的天气情景,对于各种复杂环境如雨天、雾天和暴风雪环境涉及较少,且无法达到精度和实时性的良好平衡,从未有一种网络可适用于各类环境的交通标志检测识别任务。未来,将重点关注各种复杂环境下的交通标志检测识别任务,解决各类环境下的外部干扰问题,尝试构建一种网络适用于各类复杂环境下的交通标志检测识别网络。
