联合胶囊和双向LSTM网络的VPN加密流量识别
2023-12-11杨忠富罗金燕
杨忠富,常 俊,许 妍,罗金燕,吴 彭
云南大学 信息学院,昆明 650500
随着通信感知一体化、5G、边缘计算等信息技术的蓬勃发展,对网络的管理提出了更高的要求。网络流量分类作为提高网络控制能力的必要技术之一,通过区分网络应用类型,不仅能够提供更好的服务质量(QoS),而且能够有效地监督和管理网络。近年来,随着个人信息隐私保护和数据安全意识的提高,加密技术在互联网网络通信中得到了广泛的应用。然而,网络流量加密技术的发展也导致了网络安全管理面临许多挑战。目前,大多数恶意软件和攻击通过使用加密技术,使得可以避开防火墙和网络安全系统的检测。因此,如何高效准确地识别出加密流量类型成为当下研究热点。
在早期阶段,大多数研究侧重于基于端口的流量识别,使用TCP或UDP数据报头的指定端口[1-2],而随着随机端口和伪装技术在网络通信上的应用,该方法对流量识别率较低,已不再适用于当前网络环境。文献[3]使用基于数据包载荷的深度包检测(DPI)方法,解决了基于端口分类的问题,却不适合数据被加密的网络。文献[4-5]使用基于统计的方法提取流量的特征,然后通过机器学习对特征进行识别分类,如随机森林、支持向量机(SVM)、朴素贝叶斯等[6]。机器学习模型因其处理高维复杂时空数据的能力而优于传统模型,但是,在这些方法中,统计特征是手动提取的,需要大量的时间和专家经验[7]。深度学习[8]作为一种端到端的方法应运而生,可以学习输入和输出之间的非线性关系,不需要额外地提取复杂的特征。与传统机器学习模型相比,深度学习模型在网络流量识别任务中取得了优异的性能。Wang 等人[9]提出了一种利用1D-CNN 来实现加密流量分类的方法,该模型是端到端的框架,不需要人工设计流量特征,直接使用Pcap格式的原始数据流量,通过对12类别的网络流量分类准确率达到了86.6%。Zhang等人[10]提出了一种加密流量分类方法,可以独立过滤和标记未知应用流量。Lotfollahi等人[11]提出一种叫“深度包”的流量分类框架,将经过预处理后的IP 包的前1 500 Byte 作为网络输入,然后使用SAE 和一维卷积CNN 网络进行分类,结果表明F1 值高达95%。文献[12]使用LSTM来提取流量数据包之间的时序特征。文献[13]结合CNN 和LSTM 来提取流量数据的空间与时序特征,其平均准确率与1D-CNN 相比平均提高了5%,在精确率和召回率上达到了最高值。在文献[14]中,对1D-CNN进行了改进,并同样联合使用了LSTM,在训练阶段为每个流量类别设置不同的权重参数,使数据平衡,结果显示,对加密流量数据集进行分类,其准确率超过98%。据查阅文献可知,在目前的基于深度学习的网络流量分类方法中,采用CNN 和LSTM 的联合模型的分类效果最好,主要原因是网络流量数据本身的“数据流-数据包-字节”递进结构,具有明显的空间和时序特征。
在目前众多的加密流量检测中,基于深度学习的模型仍然采用CNN 来学习流量特征进行分类。然而,基于CNN 的空间特征提取有一定的局限性。首先,CNN只学习了数据报中的空间特征,忽略了内部字符串之间的相对位置、局部特征和整体之间的关系。其次,池化操作会主动丢弃大量信息。另外,针对网络流量的表征形式,目前的处理方法分为语义和二进制表征[15]。语义表征是根据每个数据包报头的语义字段,如IP、TCP 和UDP长度字段,然后将这些语义字段整合成一个完整的表征形式,但是该方法不保留数据包中的选项字段。而二进制表征类似于每个数据包的“图像”,即将Bit 对应转换成0~255 的像素,然后做成图像数据集,但却忽略了许多复杂的细节,容易造成错位,在模型中引入噪声,可能导致两个数据包的特征向量对同一特征具有不同的解释。
针对以上问题,本文设计了一种联合使用CapsNet和BiLSTM 网络的端到端加密流量分类方法。首先利用改进后的胶囊网络的卷积层来提取网络流量的底层特征,接着用胶囊层将卷积层的标量转化成胶囊向量,向量的方向和长度分别对高级特征的状态和特征的检测概率进行编码,其中,胶囊长度表示流量类别的概率,使用“动态路由”机制,捕获流量字节数据之间的高级空间属性,最后,利用BiLSTM结构来捕获CapsNet学习到的空间特征中的层次时间依赖关系。CapsNet能够很好地呈现出网络流量内部结构的语义关系,在很大程度上解决了传统CNN 中存在的问题。实验结果表明,结合CapsNet和BiLSTM的框架优于多个最先进的流量分类基线模型。
1 网络概述
1.1 CapsNet模块
Geoffrey Hilton 教授提出胶囊神经网络是一个三层的网络[16],当Capsule 识别出图像某一区域的特定物体时,其输出是一个胶囊向量,向量模长表示识别物体的概率,方向表示对象所包含的内部信息,如相对位置和方向,如果对象有轻微的变化,如旋转、平移、方向、大小等,输出向量模长不会改变,但是,方向将会有所改变,所以Capsule可以表征物体的变化规律。
胶囊网络的功能类似于卷积神经网络,将输入图像自下而上映射到特征空间。胶囊网络模型主要由三部分组成:卷积层、初始胶囊层(primary capsule layer)和数字胶囊层(digital capsule layer),网络结构如图1所示。第一层是普通的卷积层,在输入尺寸为28×28的图片后,使用256个9×9的卷积核对图片提取底层特征,步长为1,激活函数为ReLU 非线性函数。第二层为初始胶囊层,它将卷积层提取出来的标量特征图转换成向量胶囊,该层采用了通道数为32的卷积,这个通道数也就是胶囊数量,每个胶囊中含有8个卷积核大小为9×9,步长为2 的卷积单元,利用Squash 函数挤压向量,实现0-1 的压缩,保持其方向不变,每个向量是一个胶囊单元,胶囊的长度表示流量所属类别的概率,胶囊方向代表流量的属性(如固定字符串的位置、数据包之间的顺序),最终每个胶囊的输出是一个8 维向量。第三层是数字胶囊层,与全连接层类似,该层一共有N个胶囊,每个胶囊代表一个网络应用服务类别,初始胶囊层和数字胶囊层之间的耦合系数是通过动态路由算法来更新的,再次利用Squash激活函数挤压向量保证特征的位置关系,其中||L2||表示对数字胶囊的向量求模,输出的向量模大小即为某个类别的概率。

图1 胶囊网络结构Fig.1 Structure of capsule network
初始胶囊层与数字胶囊层的网络参数是通过动态路由迭代算法来更新的。在胶囊网络中,为了得到由初始胶囊层提取到的网络流量的局部特征和高级特征之间的空间关系,则需要进行以下计算:
式中,ui为初始胶囊层的第i个输出向量,代表低层胶囊提取到的局部特征,Wij为权重矩阵,是编码低层特征和高级特征的空间关系矩阵,通过反向传播进行学习,为预测向量,Sj为第j个胶囊的输入,是低层胶囊ui的线性加权和,cij为动态路由迭代确定的耦合系数,可以通过下式得出:
cij由Softmax函数计算得出,每个高层胶囊和低层胶囊之间都有一个对应的耦合系数,并且该系数和为1。bij表示初始胶囊i和高级胶囊j之间耦合的对数先验概率,初值为0,迭代过程中通过当前层的输出向量vj和上一层预测向量的内积之间的一致性来不断更新。
此外,胶囊网络使用一种被称为Squash的非线性函数作为胶囊的激活函数,其计算表达式为:
其中,vj是胶囊j的输出向量。该公式的作用是压缩,如果Sj很长,则将其压缩到约为1 的长度,如果Sj很短,那么就将压缩至约等于0,因此,胶囊输出向量的长度可以表示提取的局部特征存在的概率。
1.2 BiLSTM模块
双向LSTM神经网络在兼顾上下文特征的同时,解决了循环神经网络(RNN)对输入数据的长距离依赖问题,而在网络流量中有的数据流比较长,因此非常适合流量识别任务。BiLSTM的计算公式如下:
其中,it、ot分别代表输入、输出门,σ、W、分别表示激活函数、权重参数和记忆单元,ht代表t时刻的隐藏状态。BiLSTM用于学习胶囊层的输出,以增强网络特征的拟合效果,结构如图2所示。
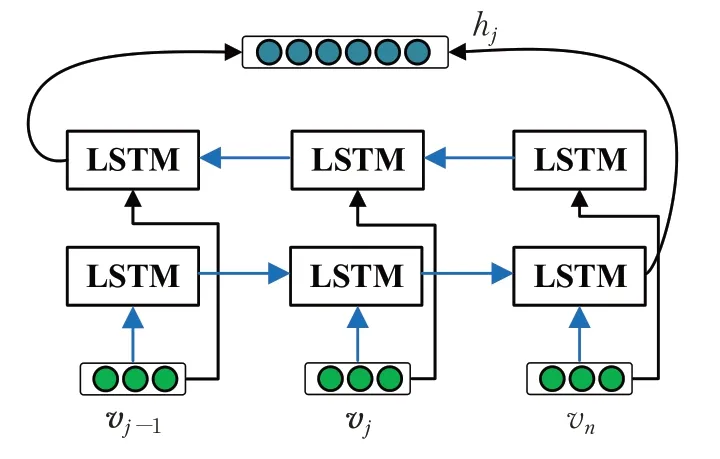
图2 BiLSTM网络结构Fig.2 Structure of BiLSTM network
2 数据集及数据预处理
2.1 数据集
训练模型最关键的是要有具有代表性的数据集,在本文的分类任务中,使用Lashkai 等人在2016 年发布的ISCX VPN-nonVPN 数据集[17],该数据集提供了150 个原始流量文件,其文件为Pcap格式,不过并无标签。按加密类型分为7种常规加密流量和7种协议封装(VPN)流量,但对于Browser 和VPN Browser 两类流量,例如Facebook-video既属于Browser也属于Streaming,因此,本文按照文献[9]将该数据集进行标注,将其分为12类:6种常规加密流量,6种VPN加密流量,本文所用数据集统计如表1所示。

表1 数据集统计信息Table 1 Data set statistics
2.2 数据预处理
由于深度学习模型对输入的数据有统一的格式,因此,需要将Pcap 格式流量文件进行预处理该方法总共分为以下几个过程。
(1)流量切分:将原始数据包切分成网络流至关重要,现有五种类型的网络流量切分方式:Tcp连接、流、会话、服务和主机。目前,研究广泛的是基于流和会话的切分方法。流是指具有相同的五元组(源IP地址、源端口、目的IP、目的端口、传输层协议)的所有报文,会话是由双向流组成的所有报文,即五元组的源地址是可互换的。根据文献[9]的结果表明,会话包含了双方的交互信息,且对加密流量的识别本身就是依靠双方交互的明文信息,所以本文选择了会话进行实验。利用SplitCap工具将原始的Pcap文件按照五元组信息切分成会话形式。
(2)去除无用信息:因为ISCX VPN-nonVPN 数据集是在数据链路层进行采集的,该层的信息对于与流量分类无关,因此首先删除数据链路层数据。其次,删除用来连接确认的无关数据包,在TCP 传输过程中,会有一些仅用于建立或者终止的数据包,例如ACK、SYN和FIN 标志数据包,这些数据中不包含流量分类信息,因此,可通过判断TCP 数据包头的标志信息来进行删除。用于域名解析的字段(DNS)也与流量服务识别无关,也应删除。最后,重复和空白的数据会影响神经网络模型的训练,降低分类准确率,因此删除这些数据。
(3)五元组信息匿名化:数据在采集过程中,使用的固定几个IP地址进行数据采集,有些数据甚至来自于同一个IP,所以为了防止MAC地址和IP地址对模型造成分类影响,特别是造成过拟合,因此,使用16 进制的0x00来替换五元组信息。
(4)统一长度:为了尽可能全面地包含网络流量特征信息,实现更准确的网络流量分类,截取固定长度为784 Byte的负载数据,文件超过784 Byte的进行删除,不足的在末尾补上0x00。
(5)生成数据集:将784 Byte 的会话二进制后转化成长度为784的数组,按顺序将每个字节都转化成一个uint8数据格式的8位像素,一个字节大小[0~255]对应于灰度像素,转换为二维灰度图像,并以PNG格式存储。最后,我们将灰度图像按8∶2的比例分成训练集和测试集。
对上述预处理的结果进行可视化分析,每个图像像素为28×28,如图3所示。图3(a)显示了所有12类流量的可视化结果,且各流量中随机选取一张图片,从结果可看出,12种类型流量的图片之间具有很好的分辨度,而且VPN 加密流量图片间的纹理相差较大,更加容易区分,这是因为VPN 协议之间伪随机数的发生器不一样,会导致产生的流量完全不同。图3(b)为随机选取的两类流量里的9张图片,该结果显示了同类流量具有很高的一致性。
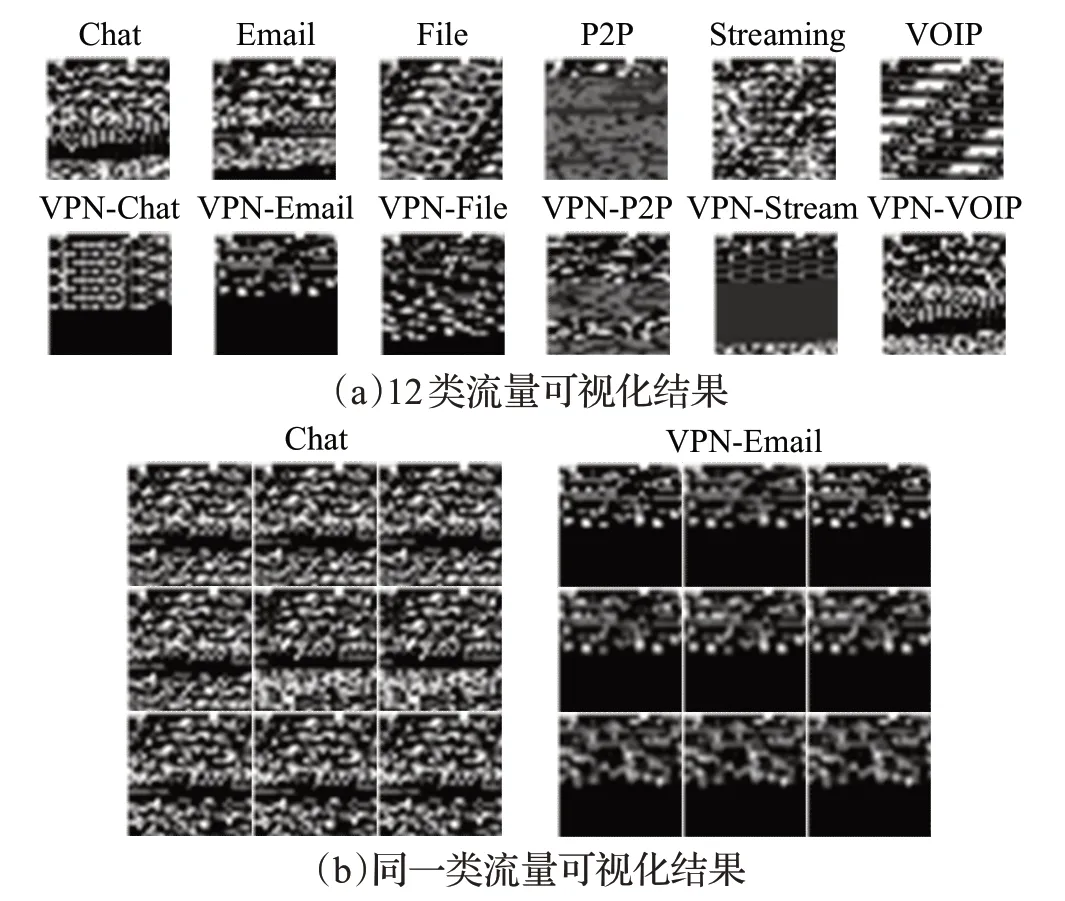
图3 加密流量可视化示意图Fig.3 Visualization diagram of encrypted traffic
3 本文方法
网络流量数据是一个显著的时空层次化结构实体,其实质是一系列的流量字节串,然后根据网络协议将字节组合成数据包,最后按照通信协议把数据包又组合为网络流,它包含了包大小、流大小、上下行数据流字节数之比、数据包到达顺序等局部特征,具有一定的排列规律和相对的空间信息。此外,对于相同IP报头的TCP数据包和UDP 数据包拥有完全不同的信息,并不是所有的IP数据包都含有选项字段信息,传统的标量表征容易造成同一特征的误解,因此,本文设计了一个CapsNet-BiLSTM 架构。如图4 所示,该架构由4 个卷积层、1 个胶囊网络单元、1个双向LSTM层和1个Softmax分类器组成,用于提取网络流量的空间特征和时序特征,实现更加高效的网络应用服务识别。
3.1 网络模型
3.1.1 卷积层提取底层空间特征
本文串联使用了4个3×3的卷积来代替1层9×9的卷积,多个小卷积核所需的参数量减小及降低了梯度消失的风险,而且与大卷积核感受野相同,较之拥有更多的非线性变化。本文所使用的ISCX VPN-nonVPN 数据集由于数据不平衡,有的类别数据量属于小数据集,神经网络参数量过大很容易出现过拟合现象,所以,为了防止模型过拟合,在4个卷积层中加入了L2正则化,并且使用了批量归一化(batch normalization,BN),BN具有较高的初始学习率,能加速模型收敛过程。假设输入的数据为xi,经过卷积层后的输出Convi则为:
其中,Wconv和bi分别为卷积网络的卷积核与偏置项,R为ReLU激活函数。
3.1.2 胶囊单元学习高级空间特征
首先,初始胶囊层使用卷积操作和Squash函数将卷积层输出的标量特征转为向量胶囊Prim,胶囊数量为32,然后使用动态路由机制将Prim与数字胶囊层进行全连接,得到整个CapsNet网络的输出Dig,其表达如下:
式中,Wprim、bprim分别是初始胶囊层的卷积核和偏置项,Wdig、bdig为数字胶囊层的权重和偏置,S代表Squash激活函数。在该层中,设置路由迭代次数为5,最终输出的高级胶囊数则为分类类别数N。
3.1.3 BiLSTM学习时序特征
胶囊网络的输出Dig由N个胶囊向量组成,包含了网络数据流的空间特征,同时,这些胶囊向量如同网络交互的数据包一样,具有很明显的时间顺序结构,因此,采用了一个BiLSTM,依次从正向和反向读取两个方向的时序特征。其隐藏层数设置为128。
最后使用Softmax函数将综合得到的时空特征向量转换为N×1 矩阵,得到输出预测向量。
3.2 损失函数
对于CapsNet-BiLSTM 网络,定义了一个联合损失函数,由边缘损失和交叉熵函数组成。
由于胶囊网络需要同时对多个对象进行识别,不能使用传统的交叉熵损失函数,因此,使用了边缘损失函数代替。
式中,类别用c表示,Tc是存在函数,只有0和1两种取值,类别c存在即为1,不存在为0,m+、m-分别表示上界和下界,取值为0.9 和0.1,分别用来惩罚假阳性(false positive)和假阴性(false negative),将实际存在的类别预测为不存在就是假阳性,将不存在的预测为存在就是假阴性,‖vc‖为胶囊的模长,表示概率,λ是比例系数,取值为0.5,用来调整两者比例。
LSTM网络采用交叉熵作为损失函数:
4 评估实验
4.1 实验环境
本文使用的计算机配置如下:处理器为Intel i5-8100,操作系统为Windows10,使用的开发语言为python3.6,采用tensorflow1.2作为深度学习框架。训练过程中使用Adam optimizer 对网络进行优化,Batch_size 与Epoch分别设为128和100。
4.2 评价指标
本文采用了准确率(Accuracy)、精确度(Precision)、召回率(Recall)和F1值(F1-score)四个指标来评估提出的方法。其中,准确率评价了分类模型的整体性能,精度和召回率反映了方法在单独类别中的识别效率。F1值是基于召回率与精确率的调和平均,即通过综合精度和召回率得到的评价指标。计算公式如下:
由于样本数量的不平衡,会导致数据量较大的类别对准确率的影响占主要因素,因此,本文也使用了混淆矩阵来进行评估。
4.3 实验结果及分析
为了验证本文算法在加密流量多分类任务上的有效性,采用上述预处理后的ISCX VPN-nonVPN数据集进行了实验,本文实验总共分为两个6分类和一个12分类,即6种常规加密业务分类、6种VPN加密业务分类及12 种加密业务分类,以下分别简称6_VPN、6_nonVPN、12_VPN non VPN。
首先验证本文优化的CapsNet 性能,即针对改动的卷积层进行实验,在此,只单独使用胶囊网络。图4 显示了改动的卷积层层数与原始CapsNet 在准确率上的对比结果。
由图5 可知,使用卷积核尺寸为3×3 的2、3、4、5 层卷积的平均准确率分别为:96.93%、97.48%、98.75%及97.59%,1层9×9的卷积平均准确率为97.33%。与原始的CapsNet 模型相比,本文提出的4 层卷积网络相对提高了1.26%。原因是原始CapsNet 只有一个卷积层,对于ISCX VPN-non VPN 数据集来说,其捕获底层特征的能力受到限制,而采用多层卷积能够更好地捕获网络流量的细节信息,故而证明了本文提出的4层小卷积模块在加密流量分类上的有效性。另外,还可以从结果看出,在3类分类实验中,6_VPN的识别率都是最高的,12分类最次,是因为VPN 加密流量和普通加密流量在进行加密时使用的加密协议不同导致,VPN加密流量协议之间的数据分布具有较大的区别,而普通加密流量使用的协议之间的差别不是很大,符合预期结果。

图5 卷积层准确率对比Fig.5 Accuracy comparison of convolutional layer
图6 显示了本文的CapsNet-BiLSTM 模型在3 种分类实验上的训练和测试准确率曲线。结果表明,整体结果都达到了高平稳状态。6_VPN、6_nonVPN及12_VPN non VPN的测试准确率分别为99.61%、99.19%和98.97%,与单独使用CapsNet模型相比平均高出了1个百分点以上,这表明在胶囊层后面加入BiLSTM模型计算输入的多个胶囊向量,能够进一步提取网络流量特征,因此,可以认为本文提出的模型能够胜任具有时空特征的加密流量识别任务。

图6 分类准确率变化图Fig.6 Changes in classification accuracy
单独的准确率指标在面对数据不平衡时具有很大不足,为此,表2、3 和4 显示了CapsNet-BiLSTM 模型在每个加密流量服务识别任务上的精确率、召回率和F1值。可以看出,3个分类实验中,3个指标结果都在97%以上,说明CapsNet-BiLSTM 模型充分发挥了提取流量数据空间和时序特征的优势。

表2 6_nonVPN评价指标结果Table 2 Evaluation index results of 6_nonVPN单位:%

表3 6_VPN评价指标结果Table 3 Evaluation index results of 6_VPN单位:%

表4 12_VPN non VPN评价指标结果Table 4 Evaluation index results of 12_VPN non VPN单位:%
为了进一步详细分析,绘制了如图7所示的混淆矩阵,横轴为预测标签,纵轴为真实标签,在此只展示12_VPN non VPN实验的混淆矩阵,因为其他两个实验具有类似的结果。从整体上看,各个类别都带有较深的红色,且最低预测概率为97%,最高可达100%,证明了本文模型在加密流量识别上的可行性。从这个图中,显示出不管是6_VPN还是6_nonVPN,预测概率最低的类别是File 流量,可以看出本文模型倾向于将File 文件类别分类到VoIP 文件,主要原因是File 文件中的流量由Skype进行传输,而Skype是VoIP客户端。最后,从混淆矩阵上可以看到,各个类别的分类错误只会发生在6_VPN和6_nonVPN内部,不会出现VPN加密流量类别被误判为non VPN类别这种情况,反之亦然,再次说明了VPN加密流量与普通加密流量所用协议之间的差别。

图7 12_VPN non VPN混淆矩阵Fig.7 Confusion matrix of 12_VPN non VPN
4.4 对比分析
为了更好地分析CapsNet-BiLSTM在加密流量识别中的优越性,实验选择文献[9,11,13]的结果进行比较。文献[9]中的实验将数据集划分成non VPN 及VPN,即进行与本文相似的实验组合,文献[11,13]中的实验只进行加密流量服务分类,即本文的12 分类,因此,首先与文献[9]进行6_nonVPN 和6_VPN 两组实验的对比,与其他方法则进行12_VPN non VPN分析。
从表5 可以看出,本文的6_nonVPN 实验的识别准确率比1dCNN提高了16.19个百分点,精确率、召回率及F1 值提高了13 个以上的百分点,6_VPN 实验准确率相比提高了1.01个百分点,另外3个指标也相对有所提高。

表5 6_nonVPN和6_VPN实验对比Table 5 Experimental comparison of 6_nonVPN and 6_VPN 单位:%
图8 显示了与文献[11,13]在12_VPN non VPN 分类中精确率、召回率、F1值上的结果对比,结果表明,与最优的结果即文献[11]相比,本文模型在3 个指标上都有了极大提升。本文与文献[11]在数据预处理上几乎相似,仅除了网络输入尺寸,但最终的结果却相差较大,主要原因是本文模型很好地提取了网络流量的层次化特征,而文献[11]只针对流量的空间特征,并且,如前文所说,CNN忽略了网络流量的特性。因此,可以认为本文提出的CapsNet-BiLSTM模型在加密流量任务识别上具有很好的效果。

图8 不同模型结果对比Fig.8 Comparison results of different models
5 结束语
本文提出了一种基于时空特征的加密流量识别方法。Caps-BiLSTM 模型考虑了固定字符串的位置和数据包之间的顺序,尤其是CapsNet网络使用的神经元是向量,它能准确刻画出流量中数据包和字节的属性,因此适合于加密流量分类任务,此外,网络流量数据包具有很明显的顺序结构,使用双向LSTM能更好地提取前后信息,最后,使用联合损失函数比单一的边缘损失函数能更好地胜任该模型。实验结果表明,与最先进的方法相比,本文方法在ISCX VPN-nonVPN数据集上取得了显著的成果。由于目前的加密流量种类太多,且网络复杂度日渐上升,现有的模型在真实网络环境中识别的实时性和鲁棒性上均有所欠缺,未来的研究工作应该在真实环境中进行识别并提高准确率。
