注意力机制与Involution算子改进的人脸表情识别
2023-12-11郭靖圆董乙杉刘晓文卢树华
郭靖圆,董乙杉,刘晓文,卢树华,2
1.中国人民公安大学 信息网络安全学院,北京 102600
2.公安部安全防范技术与风险评估重点实验室,北京 102600
面部表情是人类表达内心情感的一种重要方式,通过分析人的面部表情,可以判断其心理状态。人脸表情自动识别技术在智能审讯、自动驾驶、辅助医疗、消费者分析和临床心理学等人机交互领域应用广泛,成为计算机视觉领域中非常重要的研究课题[1-3]。
现有的自动表情识别的研究主要针对宏表情和微表情。微表情自动识别研究对象为在面部短暂出现的、人眼难以察觉的面部表情。贲晛烨等[4]总结了基于传统方法的微表情识别;Li等[5]采用深度学习方法进行微表情识别,利用深层分层卷积递归神经网络和基于主成分分析的递归神经网络分别提取局部和全局特征;Wang等[6]将传统方法与深度学习相结合进行微表情识别,将堆叠的光流序列与PCANet+相结合自动学习有较强判别力的时空特征。宏表情自动识别即人脸表情识别研究针对人眼可见的,如高兴、悲伤、惊讶等常见的几种表情。微表情识别常用于商业谈判、犯罪侦查等特定情景下,而宏表情在人们的日常交往中应用更为广泛,因而,本文针对宏表情研究其识别方法。
传统的人脸表情识别广泛采用机器学习的方法提取手工设计特征,主要依赖设计者的知识经验,缺乏足够的可靠性,准确率亦受到限制。近年来,随着深度学习的快速发展,卷积神经网络可实现端到端自动提取特征和分类,人脸表情识别的稳健性和准确率显著提高,尤其是在CK+等实验室数据集上,表情识别准确率可高达95%以上[7-9]。但是随着表情识别逐渐走向实际场景应用,自然条件下的人脸表情识别引起较多关注。Li等[10]提出了一种针对自然条件下面部表情识别的网络LBANIL,LBAN 将局部二值卷积与标准卷积相结合,在提取稀疏表情特征的同时修剪多余参数,降低了模型复杂度;IL通过增加向量振幅来提高类间差异增强网络的辨别能力,提高了自然条件下人脸表情识别准确率。为避免丢失关键信息,文献[11-12]报道采用多分支网络同时学习全局和局部特征,提取互补信息。为提高表情识别性能,结合面部特征点检测来增强网络面部表情特征提取能力亦受到关注[13-14]。此外,一些方法还引入注意力机制抑制背景干扰[2-3,15-16],融合深度学习特征和传统方法丰富特征信息[2,17-18],表情识别准确率得到显著提高。但是自然条件下的人脸表情识别依然面临诸多挑战,包括复杂背景干扰、姿态大角度变化以及空间信息分布不均匀等,其识别准确率有待进一步提高[19-22]。针对上述问题,本文以VGG19为基本架构,提出一种注意力机制和Involution 算子改进的人脸表情识别方法,主要内容及创新点总结如下:
(1)融合卷积注意力机制(convolutional block attention module,CBAM)对复杂背景中的重要特征重加权,引入联合正则化策略平衡数据分布,加入密集连接[23]强化关键信息复用,提高识别准确率;
(2)为加强网络多样性空间特征感知能力,网络中嵌入Involution算子[24]替代部分卷积层,降低部分遮挡、光照不平衡及姿势变化等对表情识别的影响;
(3)所提方法在CK+[25]、FER2013[26]和RAF-DB[27-28]等3个标准公开数据集上进行了实验和测试,结果表明,所提方法优于当前诸多先进方法,具有良好的准确性。
1 相关工作
传统的人脸表情识别通过提取灰度、纹理、颜色及几何形状等手工特征识别面部表情,如HOG(histogram of oriented gradients)[29]、LBP(linear binary pattern)[30]、SIFT(scale-invariant feature transform)[31]等都是早期人脸表情识别研究中较为常用的方法。
近年来,卷积神经网络(convolutional neural network,CNN)被广泛应用于计算机视觉领域,进一步推动了人脸表情识别的发展[32]。不同于严重依赖复杂规则的传统机器学习算法,深度学习模型能够自动地学习各类表情的典型特征。常用于人脸表情识别的卷积神经网络架构有AlexNet[33]、VGGNet[34]、GoogleNet[35]和ResNet[36]。其中,VGGNet[34]的显著特点是所有卷积层均使用大小为3×3 的卷积核以减少参数量,包括VGG16和VGG19。Li等[37]提出一种局部面部区域门控卷积神经网络(PG-CNN),PG-CNN以VGG16为骨干网络,加入PG 单元自动感知面部遮挡区域,使网络关注未遮挡区域,解决了表情识别中遮挡导致准确率下降的问题。
注意力机制是近几年在深度神经网络研究领域取得显著成效的一类优化模块。注意力机制把图像中的重要特征通过重新计算权重的方式将其标记,以抑制背景干扰,识别图像中所需信息量丰富的区域。Li等[15]在基于注意力机制的卷积神经网络中加入门单元学习自适应权重,依据权重大小区分出被遮挡的面部区域,使网络关注信息丰富的非遮挡区域,进一步提高了遮挡条件下的FER 性能。Li 等[2]将LBP 特征与注意力模型结合起来进行面部表情识别,将注意力模型嵌入到网络中,允许网络对输入不同部分给予不同的注意力权重,使网络更加关注有用特征。Wang 等[3]提出了一个区域注意力网络,加入自注意力模块和关系注意力模块,以端到端的方式学习每个区域的注意力权重,提高了遮挡和姿势变化条件下的面部表情识别的稳健性。Wang 等[16]提出了一个自疗网络,利用自注意力机制对主干网络生成的特征图加权,降低不确定性图片权重,减少了不确定性图片和错误标签对网络训练的影响。
融合多级特征,提取更丰富、更多样的表情特征亦受到诸多关注。Zadeh等[17]使用Gabor滤波器提取图片边缘和纹理信息,然后使用深度卷积神经网络提取深层特征,提高了模型的训练速度和准确性。Xi等[18]在模型前端采用灰度共现矩阵提取了8 种不同的面部表情纹理特征,并将其与原始图像进行融合后输入卷积神经网络、残差网络和胶囊网络组成的并行网络,提取与面部表情变化高度相关的精确特征。Li等[2]构建了一个新型网络架构,由特征提取模块、注意力模块、重构模块和分类模块四个模块组成,在特征提取模块融合传统方法LBP提取图像纹理信息,加入密集连接和膨胀卷积以提高网络性能,由此提升表情识别准确率。
2 基本原理
2.1 网络结构
本文选取VGG19 为基础框架,提出注意力机制和Involution算子改进的人脸表情识别网络,结构如图1所示。网络中,引入5 个CBAM 为重要特征重加权,前4个CBAM卷积核为7,处理大尺度特征,最后1个模块后CBAM 卷积核为3,处理小尺度特征。在网络前端,每层卷积后引入联合正则化机制,即过滤器响应正则化和批量正则化(BFN),实例正则化和组正则化(IGN),以平衡和改善数据分布;在网络后端,采用密集连接以加强高层有效特征复用并缓解梯度消失问题,引入Involution 算子取代部分卷积层,提高多样性空间信息提取和传递能力,然后,将提取到的特征图送入全连接层进行分类,输出表情识别结果。
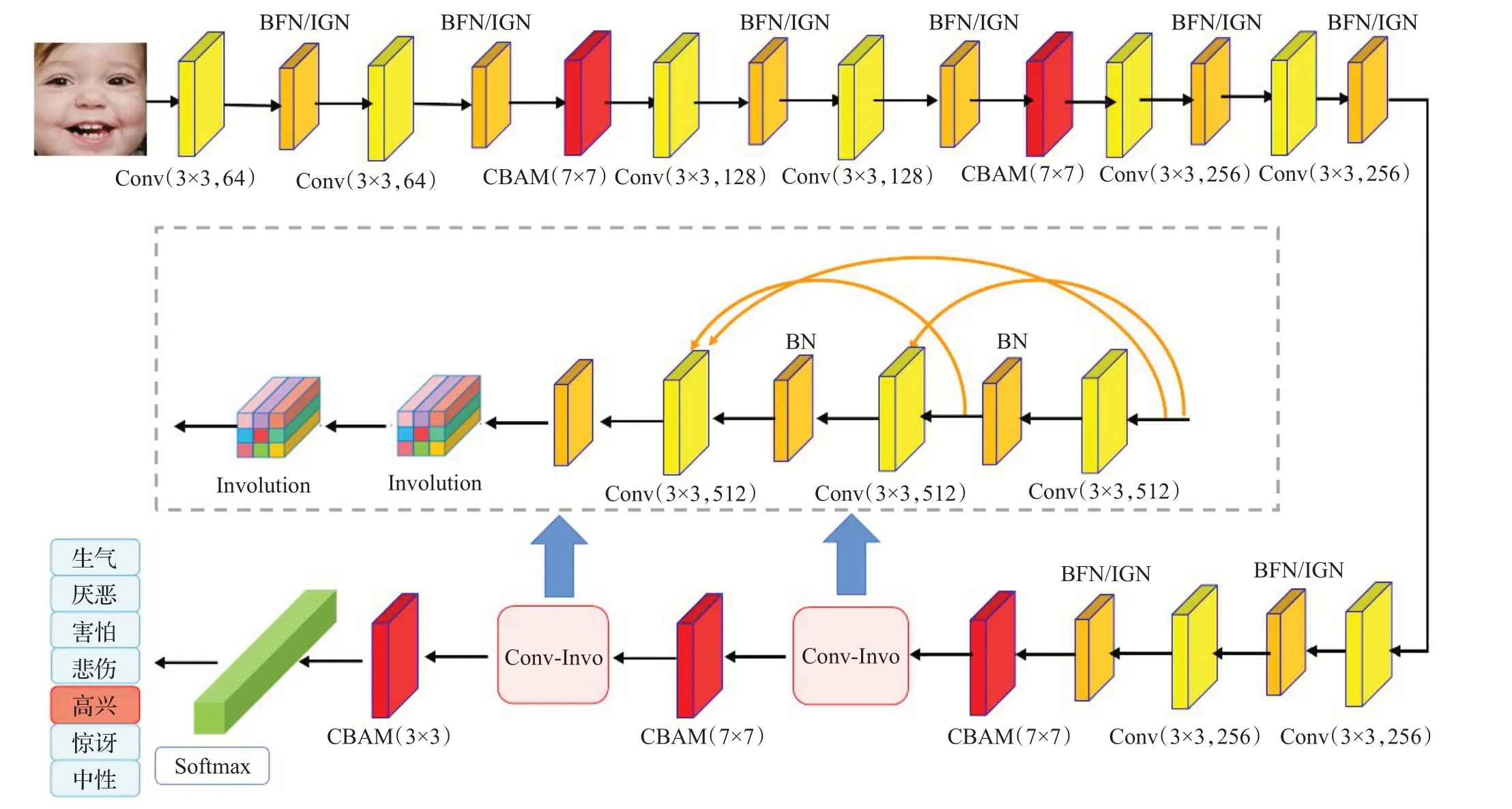
图1 注意力机制与Involution算子改进的网络结构Fig.1 Network architecture based on attention mechanism and Involution operator
2.2 卷积注意力模块(CBAM)
CBAM[21]包括通道注意力(channel attention module,CAM)和空间注意力(spatial attention module,SAM)两种注意力机制,将这两类注意力模块串行连接在一起,相比于单独的CAM和SAM更关注特征图中关键信息。如图2所示,特征图Fi输入CAM后,分别经过全局最大池化和全局平均池化得到AvgPool(Fi)和MaxPool(Fi),再将它们分别送入多层感知机(multilayer perceptron,MLP),并将MLP得到的输出加和,生成特征图FCAM,最后将其与输入特征图Fi相乘得到FCAMout。其计算公式如下:

图2 CBAM注意力模块结构Fig.2 Structure of CBAM attention mechanism
式中,⊙表示逐点相乘;σ(x)表示激活函数Sigmoid。特征图Fi输入SAM 后分别经过全局最大池化和全局平均池化并将得到的特征图按通道拼接后,经过一层卷积核大小为k×k的卷积层进行降维操作(此处k常取值为7),生成最终的注意力特征提取图,将其与输入特征图相乘,为更需要关注的特征加权。其计算公式如下:
式中,⊙表示逐点相乘,⊕表示级联,M(Fi)为全局最大池化运算,A(Fi)为全局平均池化运算。如图所示,每个模块特征图F输出后,先送入CAM提取通道注意力特征再经过SAM 提取空间注意力特征,得到输出Fout。具体计算如下:
2.3 密集连接
密集连接[23],即将CNN 中每一层都通过级联操作与其他层连接,使得网络中每一层都接受它前面所有层的特征作为输入。标准的卷积神经网络每一层与其前一层和后一层相连,而采用密集连接的卷积神经网络所有层都相互连接,保存了较浅层特征,实现了通道维度的特征复用,缓解了梯度消失问题。如图3 所示,第L层输出xL与第L+1 层输出xL+1在通道维度上级联后输入L+2 层得到xL+2,xL、xL+1、xL+2再级联后输入L+3 层得到xL+3。具体计算如下:
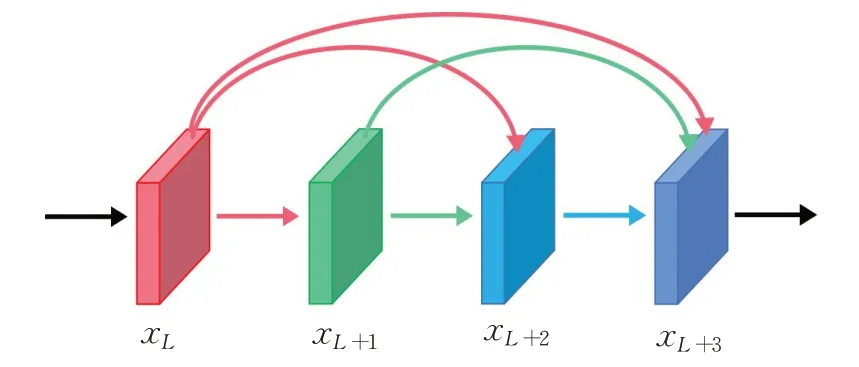
图3 密集连接结构Fig.3 Structure of dense connection convolution layers
式中,Conv为卷积(卷积核大小为3×3)运算,BN为正则化操作,ReLU为非线性运算,⊕为级联运算。
2.4 Involution算子
Involution[24]是一种不同于Convolution的新型算子。Convolution具有空间不变性和通道特异性。Involution特性与Convolution 相反,具有通道不变性和空间特异性。通道不变性指Involution算子在通道维度上共享卷积核,一定程度上减少了核冗余问题,进而减少了参数的冗余;空间特异性即Involution 算子在空间维度上不共享参数,但在不同空间位置上,Involution算子仍具有知识共享和迁移能力。这一特性使得Involution算子能够更灵活地提取多样性空间特征,在更大范围的空间内聚合上下文信息,强化了关键空间上下文信息的利用,并且重点关注空间维度信息最丰富的元素。
如图4 所示,特征图Fin(大小为H×W×Cin)输入Involution算子后,提取其中大小为1×1×Cin的张量fi,j(i=1,2,…,H,j=1,2,…,W)做通道压缩运算,将其从Cin压缩到Cout,得到大小为1×1×Cout的fc,通道压缩运算公式如下:

图4 Involution结构图Fig.4 Structure of Involution
式中,r为压缩率。再将fc转换为大小为K×K×G(K为Involution 算子卷积核的大小,G指将通道数C分为G组)的张量fk,转换公式如下:
fk即Involution算子的卷积核。每组卷积核对输入特征图进行处理后,生成相应的输出Fk,大小为K×K×Cin,而后将Fk在通道维度上聚合得到对应于fi,j的。H×W个共同组成了输出特征图Fout。聚合运算如下:
式中,x1,1,x2,1,x1,2,…,xK,K表示Fk中元素,⊕表示通道维度上对应像素相加。
3 实验与结果分析
3.1 数据集
CK+是人脸表情数据库CK 的扩展数据集,包含有持续时间从10 帧到60 帧不等的593 个图像序列,其中327 个序列基于面部动作编码系统(FACS)被标记为愤怒、蔑视、厌恶、恐惧、快乐、悲伤、惊讶7 个基本表情标签,其中蔑视、恐惧、悲伤表情图片较少,蔑视54 张,恐惧75 张,悲伤84 张。本文从这327 个序列中提取了每个序列的最后3帧,共包含981张表情图片,其中882张作为训练集,99张作为测试集。
FER2013数据集包含35 887张图片,其中训练集部分28 708张图片,公开测试集部分3 589张图片,私有测试集部分3 589张图片。FER2013数据集中每张图片经过裁剪对齐后都被统一调整至大小为48×48 的灰度图像,每张图片还标注有对应生气、厌恶、害怕、高兴、伤心、惊讶以及中性的7 种表情标签,其中标签为厌恶的图片只有436张训练图片,其余表情图片数量都在3 000张以上。实验中,将公开测试集部分作为验证集,将私有测试集作为测试集。
RAF-DB 数据集包含了30 000 张从互联网下载而来的基本或复合表情的面部图像。通过人工标注,该数据集中图片被分为包括生气、厌恶、害怕、高兴、伤心、惊讶、中性的7类基本表情和12类复合表情,7类基本表情中,表情为害怕和厌恶的图像较少,分别有281 和717张。实验中,仅使用了基本表情图像,其中12 271 张图像作为训练数据,3 068张图像作为测试数据。
3.2 实验参数
实验操作系统为Ubuntu16.04,以Python2.7、Pytorch0.4.1 作为基础环境编写和运行程序,训练使用的GPU为NVIDIA GeForce GTX 1080Ti。训练的过程中使用交叉熵损失函数,并采用SGD优化器优化模型。
训练CK+数据集时将初始学习率设置为0.01,设置总批次为100、初始衰减批次为20,每2个批次进行一次衰减,衰减率为0.9。训练FER2013 数据集和RAF-DB数据集时将初始学习率设置为0.01,训练总批次设置为300,初始衰减批次设置为80,每5 个批次进行一次衰减,衰减率为0.9。为避免过拟合,采用数据增强策略。对于CK+和FER2013数据集,将大小为48×48的原始图片随机裁剪成大小为44×44的10张图片,并对图片进行水平翻转操作,达到扩增数据集的目的。对于RAF-DB数据集,用MTCNN对数据集中人脸图像进行检测和对齐,并将图片大小由100×100放大至224×224,而后对其进行归一化处理以加速模型收敛。
3.3 结果和分析
所提方法在CK+,FER2013和RAF-DB数据集上进行了训练与测试,并将测试结果与多个先进方法进行比较,结果如表1 和表2 所示。CK+为实验室数据集,FER2013和RAF-DB数据集为自然条件数据集。FER2013数据集存在部分错误标签,准确率最高位于约75%,由表1能够看出,所提方法在FER2013数据集上表情识别准确率达到73.806%,相较于Xie[38]、LBAN-IL[10]、Tri21+DisSupTri+PosSupTri[39]等方法提高了1.336、0.696、0.026个百分点。总体而言,所提方法在FER2013数据集上具有较好的竞争性。

表1 FER2013数据集识别准确率Table 1 Recognition accuracy on FER2013 dataset
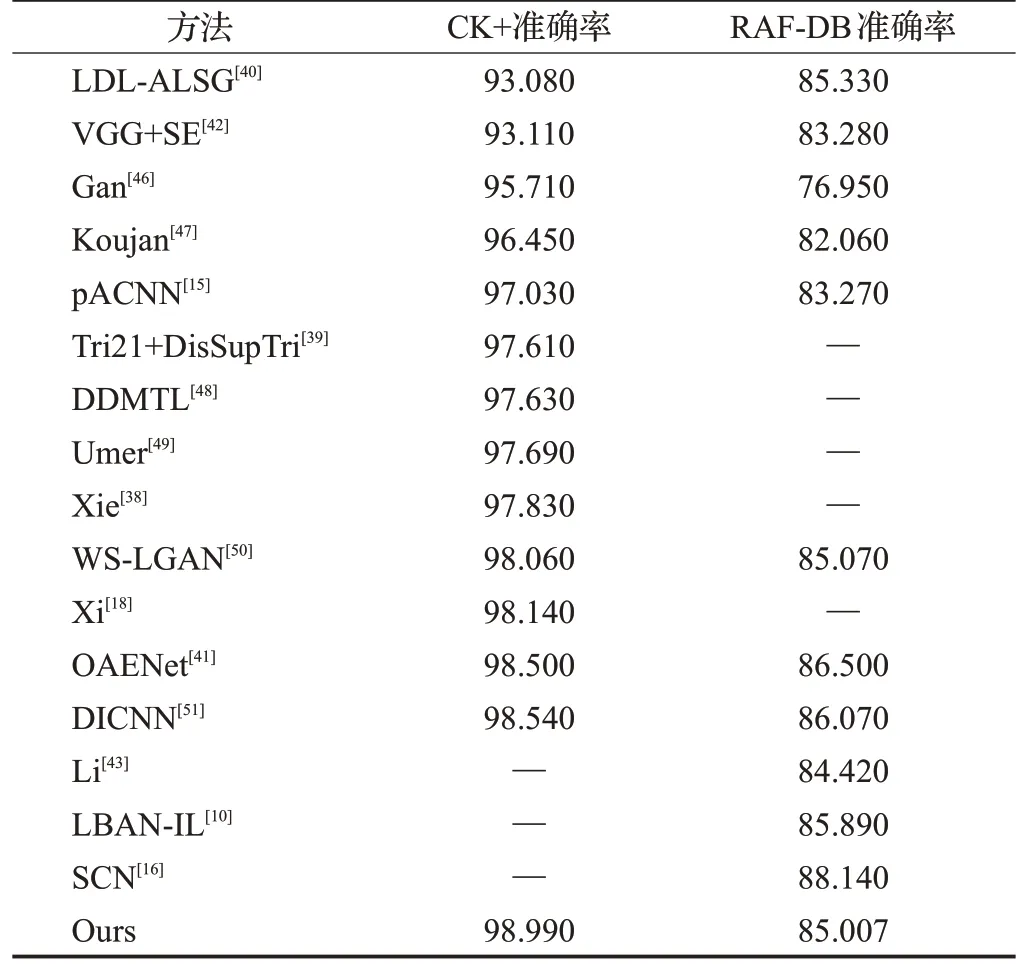
表2 CK+和RAF-DB数据集识别准确率Table 2 Recognition accuracy on CK+and RAF-DB dataset单位:%
从表2可以看出,所提方法在CK+数据集上取得了98.99%的准确率,相较于LDL-ALSG[40]、Tri21+DisSupTri[39]、Xie[38]、OAENet[41]等方法提高了5.91、1.38、1.16、0.49 个百分点,在所比较的几种先进算法中,达到了最高,表明所提方法在实验室数据集上的优异性能。此外,所提方法在RAF-DB 数据集上表情识别准确率达到85.007%,相较于pACNN[15]、VGG+SE[42]、Li[43]等方法分别提高了1.737、1.727、0.587个百分点,与准确率最高的LBAN-IL[10]的结果85.89%也较为接近,表明所提方法具有较好的先进性。所提方法使用的损失函数为交叉熵损失函数,而方法LBAN-IL[10]加入IL损失函数以提高类间差异、增强网络辨别力,因此所得准确率更高,但IL损失函数输出网络层参数、softmax 损失函数参数和islet 损失函数参数,相对交叉熵损失函数参数量、计算量都有所增加。所提方法与SCN[16]有较大差距,SCN对图片标签进行了修正,而所提方法使采用数据集原始标注,因数据集标注存在较大不确定性,可能是识别准确率比SCN低的潜在重要因素。
图5展示了所提模型在CK+、FER2013以及RAF-DB数据集上的混淆矩阵。由图5 可知,在识别过程中,表情“厌恶”“害怕”“悲伤”“生气”容易相互误判,这可能是因为这些表情均有皱眉和嘴角向下等特征,很容易相互混淆,导致识别性能较差。

图5 所提模型在CK+、FER2013和RAF-DB数据集上的混淆矩阵Fig.5 Confusion matrices of proposed models on CK+,FER2013 and RAF-DB dataset
从图5(a)中可以看出,CK+数据集表情“蔑视”“恐惧”“悲伤”识别准确率均为100%,尽管这3种表情图片数量较少,但其识别准确率仍较高,这表明数据分布不均衡对该实验室数据集分类性能影响不显著;图5(b)中识别准确率最低的表情为“害怕”,与图片数量最少的“厌恶”表情不一致,FER2013数据集中存在部分标签错误,数据分布不平衡对该数据集的参考意义不大;从图5(c)中可以看出,在识别RAF 数据集时,表情“害怕”和“厌恶”准确率较低,与RAF-DB数据集中这两类表情图片数量较少一致,对于监督学习模型来说,较少的图片数量,使网络缺乏对应表情的训练,导致准确率较低[10,50],表明数据分布不平衡对自然条件下表情识别存在一定影响。
3.4 消融实验
为分析所提模型中不同优化策略的效能,以VGG19为基线网络,在数据集CK+、FER2013 和RAF-DB 上开展消融实验,实验结果如表3所示,可以看出,在CK+数据集上引入CBAM后,准确率显著提升,提高了4.04个百分点,加入密集连接和IGN 后准确率均有提升,模型VGG19+CBAM+IGN+DEN达到最高准确率98.99%,相较于VGG19基线网络提升了7.07个百分点。在FER2013数据集上对比不同改进方法的效果,可见,引入CBAM后准确率提升0.621%,采用密集连接准确率提升0.780个百分点,再嵌入BFN 后达到最高准确率73.806 个百分点,相较于单纯使用VGG19网络提升了1.223个百分点。在RAF-DB 数据集上,通过融合CBAM,加入联合正则化策略,引入密集连接和Involution算子,模型的性能不断提高,最高准确率达到85.007%,相较于单纯使用VGG19网络提升了3.647个百分点。

表3 CK+、FER2013和RAF-DB数据集上的消融实验研究Table 3 Ablation study on CK+,FER2013 and RAF-DB dataset 单位:%
单独引入Involution后,模型在FER2013和RAF-DB数据集上准确率均有提升,然而在CK+数据集上准确率不仅没有提升反而有所下降,其原因可能是Involution算子在通道维度上共享Involution 核,Involution 核基于单个像素而不考虑相邻像素,导致所提模型在获得更大范围空间内聚合上下文信息的同时一定程度上限制了像素间的信息交换,且过大空间上下文范围可能会削弱目标像素信息。但是,Involution 算子能够提取多样性空间特征,利用关键空间上下文信息克服复杂背景和噪声等干扰,因此Involution 算子更适用于需要提取关键空间上下文信息和多样性空间特征的复杂条件下的人脸表情识别。FER2013 和RAF-DB 这两个数据集中包含有许多遮挡、光照不平衡及姿势不同的图片,需要结合上下文信息来提取图片中的有用特征,并通过提取多样性空间特征适应图片多样性;而CK+数据集采集于实验室,其中图片变化较少,且均为无遮挡正面人脸图片,表情强相关特征集中在面部中间,过多采集多样性空间特征和空间上下文信息反而会削弱目标像素信息,导致关键特征减少,表情识别准确率下降。
在加入CBAM、密集连接和联合正则化策略后再引入Involution 的情况下,模型在CK+数据集上的准确率不再下降,这可能是因为CBAM 已经将图片中的表情强相关特征提取出来,消除了Involution 对目标像素信息的影响。
4 结语
本文以VGG19 作为基础网络框架,融合CBAM 和联合正则化策略提取重要特征并优化数据分布,采用密集连接加强特征复用并缓解梯度消失问题,改进了模型性能,引入Involution 算子加强了模型上下文信息聚合范围,提高了模型多样性空间特征提取能力。
所提模型VGG19+CBAM+IGN+DEN 在小型实验室数据集CK+上准确率达到98.99%;VGG19+CBAM+BFN+DEN 在大型自然条件数据集FER2013 上取得了73.806%的准确率;VGG19+CBAM+IGN+DEN+INV 在自然条件数据集RAF-DB 上准确率为85.007%,结果较当前诸多人脸表情识别先进方法表现优异,展现了所提模型具有较好的先进性和稳健性。所提方法虽然超过了一些主流方法,但准确率还有待进一步提升,下一步探索多样性特征提取及图片标注不确定性等问题。
